rise of intermediate apis - beam and alluxio at alluxio meetup 2016
TRANSCRIPT

Eric AndersonProduct Manager@ericmander
Rise of Intermediary APIs(Beam and Alluxio)https://goo.gl/Fa95XZ

Google Cloud Platform 2
About Me
Product Manager at Google on Cloud DataflowWork closely with the most of the Apache Beam committersProject Management Committee for AlluxioContributed Google Compute Engine support to Alluxio
Originally from Salt Lake City, UTFather of 3 kids!
Twitter: @ericmander

Google Cloud Platform 3
Intermediary API?
Jesse Anderson (formerly Cloudera) in blog post: Strata+Hadoop Trends
I’m open to a better name if you have ideas

Google Cloud Platform 4
In the beginning...
There was only one approach to data processing
HDFS GFS
Hadoop MapReduce
Open Source Google

Google Cloud Platform 5
In the beginning...
And it required just two APIs, one for job description, one for storage
HDFS API GFS API
Hadoop API MapReduce API
Hadoop MR
HDFS GFS
Open Source Google

Google Cloud Platform 6
Then there was an evolution
But MapReduce was really hard (data processing in assembly language)
MapReduce API
MR

Google Cloud Platform 7
Flume (2010)
Flume was a programming model (API) innovation(FlumeJava not Apache Flume)
MapReduce API
Flume
MR
Programming Model
Higher level abstractions- PCollections (RDDs)- PTransforms
Directed Acyclical Graphs (DAGs)Pipeline optimization (fusing)
Google Cloud Platform 8
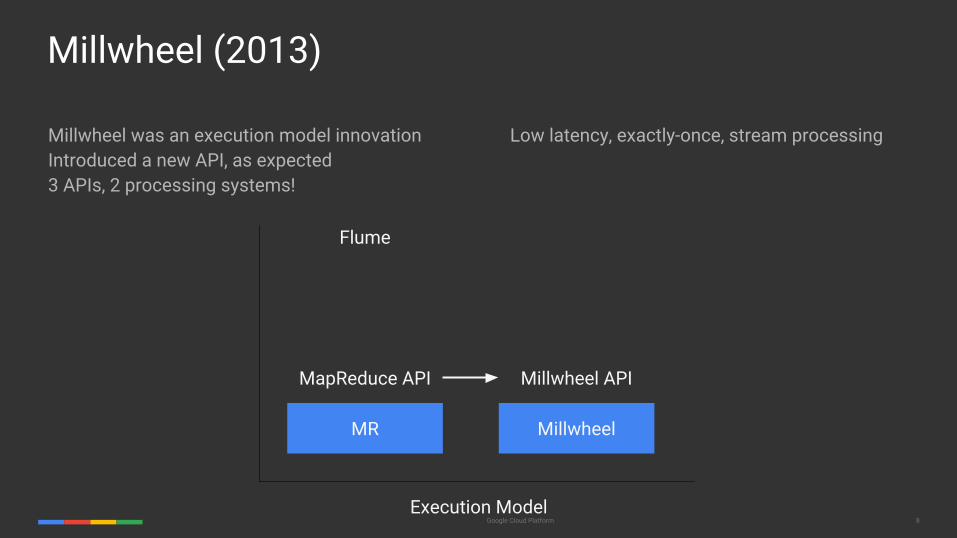
Millwheel (2013)
Millwheel was an execution model innovationIntroduced a new API, as expected3 APIs, 2 processing systems!
MapReduce API Millwheel API
Flume
MR Millwheel
Execution Model
Low latency, exactly-once, stream processing

Google Cloud Platform 9
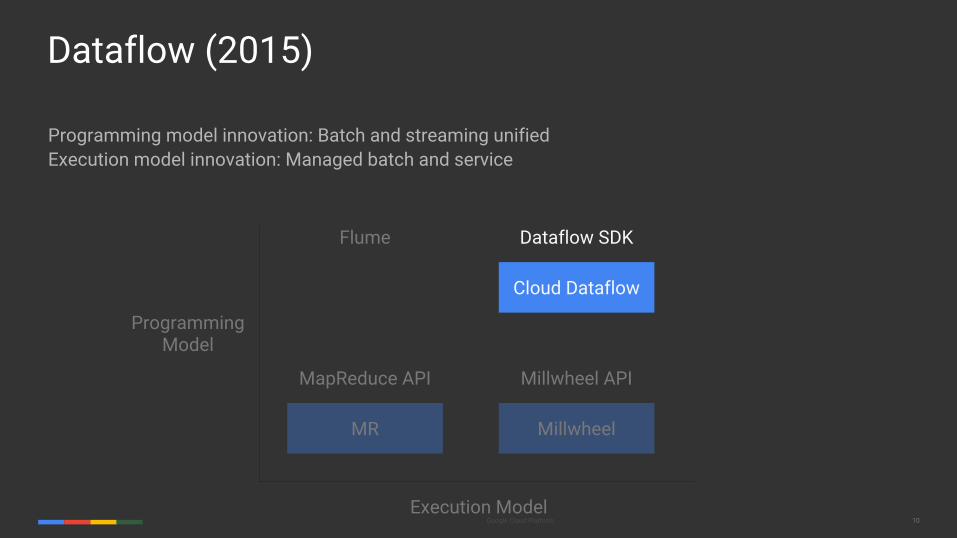
Programming model innovation: Batch and streaming unifiedExecution model innovation: Managed batch and service
Dataflow (2015)
MapReduce API Millwheel API
Flume Dataflow SDK
Cloud Dataflow
MR Millwheel
Programming Model
Execution Model
Google Cloud Platform 10
Dataflow (2015)
MapReduce API Millwheel API
Flume Dataflow SDK
Cloud Dataflow
MR Millwheel
Programming Model
Execution Model
Programming model innovation: Batch and streaming unifiedExecution model innovation: Managed batch and service

Google Cloud Platform 11
“We believe that [...] the Beam model is the future reference programming model for writing data applications in both stream and batch”- Kostas Tzoumas, CEO of data Artisans and Flink co-creator
Apache Beam (2016)
Flink API Dataflow SDK
Cloud DataflowFlink Spark
Spark API
Local
Apache Beam

Google Cloud Platform 12
Apache Beam
1. The Beam Programming Model (unifies streaming/batch)a. Transformationsb. Windowingc. Watermarks + Triggersd. Accumulation
2. SDKs for writing Beam pipelinesa. Java (Scala thanks to Spotify)b. Python
3. Runners for existing distributed processing backendsa. Apache Flink (thanks to data Artisans)b. Apache Spark (thanks to Cloudera and PayPal)c. Google Cloud Dataflow (fully managed service from Google)d. Local runner for testinge. Other runners in progress: Gear Pump, Apache Apex

Google Cloud Platform 13
There is once again, only one library we need for data processing, except this time:- It’s easy/expressive- And we can still choose from the best execution technology
Apache Beam (2017?)
Flink API Dataflow SDK
DataflowFlink Spark
Spark API
Local
Apache Beam
Gear Pump Apache Apex

Google Cloud Platform 14
Coming full circle
There is once again, only one library we need for data processing, except this time:- It’s easy/expressive- And we can still choose from the best execution technology
Yet, we’ve tried this before...
Hadoop API MapReduce API
Hadoop MR

Google Cloud Platform 15
Apache Crunch (2012)
Apache Crunch is an open source Flume-like API on Hadoop and now Spark.
MapReduce API
Crunch
Hadoop
Programming Model
MapReduce
Flume

Google Cloud Platform 16
Apache Crunch (2012)
Interest in Apache Crunch vs Apache Beam
Why? Perhaps...● Limited portability need / value● Missed the streaming revolution● Community support

Google Cloud Platform 17
What about storage?
And it required just two APIs, one for job description, one for storage
HDFS API GFS API
Hadoop API MapReduce API
Hadoop MR
HDFS GFS
Open Source Google

Google Cloud Platform 18
Need for Intermediary Storage API
Again, an explosion of options
No reason to believe this will ever end. There will always be innovation on storage and the file system
HDFS API Swift API
HDFS SwiftGCS / S3
GCS / S3 APIs
Gluster FS
GlusterFS API

Google Cloud Platform 19
Model for expressing storage lifecycle
There are patterns we want to express:● Caching● Retention policy● ACLs● Down-tiering old or stale data
Across storage systems:● Unified namespace

Google Cloud Platform 20
PRD: Intermediate Storage API
1. Model for expressing storage lifecycle2. Write to the popular storage systems3. Pluggable APIs extend to other systems4. Read from the popular processing frameworks

Google Cloud Platform 21
Pluggable under storage
Unified namespace + Tiered storage + LineageSupports at least a half dozen
Supports at least a half dozen
Alluxio
1. Model for expressing storage lifecycle2. Write to the popular storage systems3. Pluggable APIs extend to other systems4. Read from the popular processing frameworks
Alibaba OSSSwift HDFSGCS / S3
Alluxio
GlusterFS NFS
HadoopFlink SparkLocal HBase Presto

Google Cloud Platform 22
Survival tests
Survival tests Apache Beam Alluxio
Portability need / value Lots of frameworks with varying performance profiles
Lots of frameworks and storage systems with varying performance profiles
Catch the technology wave Leading stream processing revolution
Leading in-memory revolution
Community support Top names in data processing Fastest growing contributor base

Google Cloud Platform 23
My particular excitement about Alluxio
It’s a particularly interesting intermediary API because:
● Data has gravity, Alluxio allows enterprises to adopt tech alongside legacy storage.
● Alluxio’s unification of sources is valuable within a single job. Beam is used with one framework at a time, so it’s portable across jobs.
● Alluxio has standalone value from its built-in open source in-memory filesystem. Beam requires an underly execution engine like Dataflow

Google Cloud Platform 24
Intermediary APIs = Data processing nirvana
Coder:● Ability to express my data processing job or storage lifecycle logically, independent of
physical constraints.
Deployer:● Code portability● Swap in technology at will
System/Technology Creators:● Easy path to adoption● Focus on features and performance, not APIs/connectivity

Google Cloud Platform 25
Apache Beam
Alluxio
Stack of the future?
DataflowFlink SparkLocal Gear Pump Apache Apex
Alibaba OSSSwift HDFSGCS / S3 GlusterFS NFS

Google Cloud Platform 26
Questions?https://goo.gl/Fa95XZ