resource scheduling using apache mesos in cloud native environments
TRANSCRIPT

Heterogeneous Resource Scheduling Using Apache Mesos for Cloud Native Frameworks
Sharma PodilaSenior Software Engineer
Netflix
June 2015

Scale to Internet traffic

Scale to Internet traffic
… embrace failure

Context
● Operational intelligence, Edge Engineering

Context
● Operational intelligence, Edge Engineering● Near real time detection of anomalies from
customers' streaming experience

Context
● Operational intelligence, Edge Engineering● Near real time detection of anomalies from
customers' streaming experience● Stream processing platform to run ad hoc
queries on live event streams

Context
● Operational intelligence, Edge Engineering● Near real time detection of anomalies from
customers' streaming experience● Stream processing platform to run ad hoc
queries on live event streams● Iterative detection of coarse grain and fine
grain signals

Efficient platform

Efficient platform
● do it cheap

Efficient platform
● do it cheap● do it quick

Efficient platform
● do it cheap● do it quick● scale with Netflix traffic

Mantis: reactive stream processing
● Cloud native

Mantis: reactive stream processing
● Cloud native● Lightweight jobs

Mantis: reactive stream processing
● Cloud native● Lightweight jobs● Dynamic jobs

Mantis: reactive stream processing
● Cloud native● Lightweight jobs● Dynamic jobs● Custom SLAs

Bi-directional data sourcingS
ourc
e ap
p in
stan
ces
01
2
999
0
1
23
45
Source connectorjob
Subscribe with query
Data pushed with subscription ID
UserJob 1
UserJob 2
UserJob 3
Subsc
riptio
n
Dis
cove
ry

Mantis system overview
MantisMantis
Apache MesosApache Mesos
Mantis
Apache Mesos
ASGASG
ASGFenzo
MesosFramework
ZooKeeper
Inst
ance
Apache MesosSlave Cluster

Mantis scheduling model
JobJobJob
SourceStage1Stage2Sink
Jobs may be perpetual oron-demand/interactive
Slave instances

Apache Mesos

Apache Mesos Architecture
Mesos slave
FrmWrk2 executor
TaskTask
Mesos slave
FrmWrk2 executor
FrmWrk1 executor
TaskTask
Mesos master Standby master Standby master
Mesos slave
FrmWrk1 executor
TaskTask
FrmWrk1 FrmWrk2ZooKeeper
quorum

Why Apache Mesos in a Cloud?

Resource granularity
Instance 1Instance 1
Task A
Instance 2
Task B
Instance 1
Task A
Instance 1
Task A
Task B
Task C Task Dvs.

Task start latency
vs.
Instance startup in mins. Mesos task startup in <1sec

Do we need yet another Mesos framework?

A choice of Mesos frameworks exists in the community

Likely easy to write a new framework

Likely easy to write a new frameworkWhat about scale, performance, fault tolerance, and availability?

Likely easy to write a new frameworkWhat about scale, performance, fault tolerance, and availability?
Scheduling is a hard problem to solve

Long term justification needed to create a new Mesos framework

Our motivations for new framework
● Cloud native○ Large variation in peak to trough usage○ Servers are more ephemeral

Our motivations for new framework
● Cloud native○ Large variation in peak to trough usage○ Servers are more ephemeral
● Resource usage optimizations

Cluster autoscaling challenge
Host 1 Host 2 Host 3 Host 4

Cluster autoscaling challenge
Host 1 Host 2 Host 3 Host 4
Host 1 Host 2 Host 3 Host 4vs.

Cluster autoscaling challenge
Host 1 Host 2 Host 3 Host 4
Host 1 Host 2 Host 3 Host 4vs.

Stream locality challenge
Data stream
Host A
Task1
Host B
Task2
Host C
Task3

Stream locality challenge
Data stream
Host A
Task1
Host B
Task2
Host C
Task3
Data stream
Host X
Task1
Task2
Task3
vs.
Reduces network bandwidth usage

Backpressure challenge
On back pressure, scale horizontally
Processor task
Sou
rce
Sta
ge 1
Sta
ge 2
Sta
ge 3
Sin
k
Hot source Vs. cold source

Fenzo task scheduler

Fenzo task scheduler
Generic task scheduler
Heterogeneous
AutoscaleVisibility
Plugins forConstraints, Fitness
High speed

Fenzo usage in frameworksMesos master
Mesos framework
Tasksrequests
Availableresource
offers
Fenzo taskscheduler
Task assignment result• Host1
• Task1• Task2
• Host2• Task3• Task4
Persistence

Scheduling problem
Fitness
Pending
Assigned
Urg
ency
N tasks to assign from M possible slaves
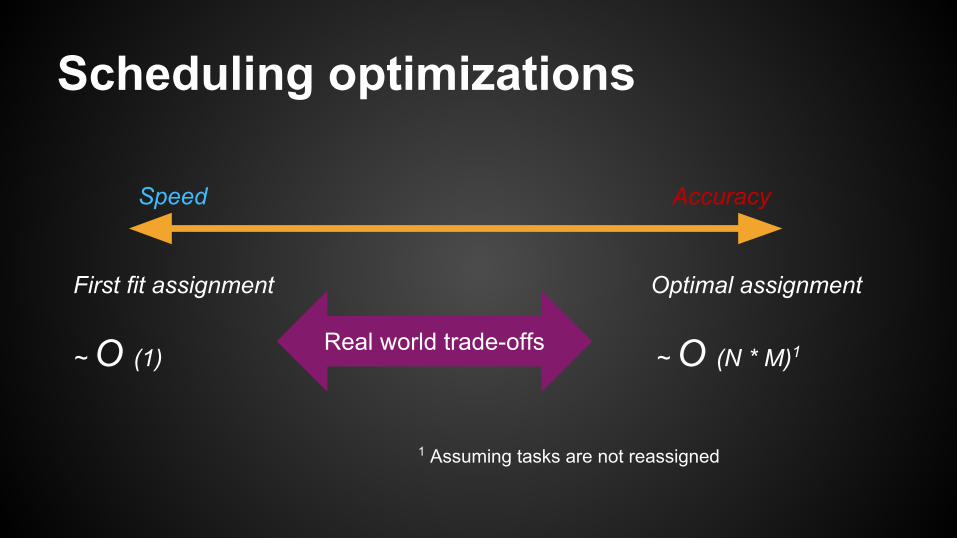
Scheduling optimizations
Speed Accuracy
First fit assignment Optimal assignment
Real world trade-offs~ O (1) ~ O (N * M)1
1 Assuming tasks are not reassigned

Scheduling strategyFor each task
Validate constraintsEval fitness on each host
Until fitness good enough, and
A minimum #hosts evaluated

Task constraints
SoftHard

Task constraints
SoftHardSome built-in
Host attribute basedCo-tasks based
Extensible

Fitness evaluation
Degree of fitness
Composable

Bin packing fitness calculator
Fitness for
Host1 Host2 Host3 Host4 Host5
fitness = usedCPUs / totalCPUs

Bin packing fitness calculator
Fitness for 0.25 0.5 0.75 1.0 0.0
Host1 Host2 Host3 Host4 Host5
fitness = usedCPUs / totalCPUs

Bin packing fitness calculator
Fitness for 0.25 0.5 0.75 1.0 0.0
✔
Host1 Host2 Host3 Host4 Host5
fitness = usedCPUs / totalCPUs

Stream locality fitnessStream locality fitness
= percentage of tasks connecting to the same stream

Composable fitness calculatorsFitness
= ( BinPackFitness * BinPackWeight +RuntimePackFitness * RuntimeWeight +StreamLocalityFitness * StreamWeight) / 3.0

Cluster autoscaling in Fenzo
ASG/Cluster: mantisagentMinIdle: 8MaxIdle: 20CooldownSecs: 360
ASG/Cluster: mantisagentMinIdle: 8MaxIdle: 20CooldownSecs: 360
ASG/cluster: computeCluster
MinIdle: 8MaxIdle: 20CooldownSecs: 360
Fenzo
ScaleUp action:
Cluster, N
ScaleDown action:Cluster, HostList

Rules based cluster autoscaling● Set up rules per host attribute value
○ E.g., one autoscale rule per ASG/cluster, one cluster for network-intensive jobs, another for CPU/memory-intensive jobs
● Sample:○ ClusterName, MinIdle, MaxIdle, CoolDownSecs○ NwkClstr,10,20,360; CmputeClstr,5,20,300
#Idlehosts
Trigger down scale
Trigger up scalemin
max

Shortfall based cluster autoscaling
● Rule-based scale up has a cool down period○ What if there’s a surge of incoming requests?
● Pending requests trigger shortfall analysis○ Scale up happens regardless of cool down period○ Remembers which tasks have already been covered

Combining predictive autoscaling● EC2 Auto Scaling groups have 3 numbers to control● Fenzo sets “desirable” value● Set max value to limit scale up● Scryer can set min value
1 http://techblog.netflix.com/2013/11/scryer-netflixs-predictive-auto-scaling.html

Job autoscalingAutoscale resources of a job’s stage based on backpressure or its usage of CPU, memory, network

Job autoscalingjob’s network bandwidth usage
number of job processes
Example from a job that reads from a queue to process data across multiple processes

To summarize...

Why Apache Mesos in a Cloud?
Resource granularity
Task start latency

Fenzo task scheduler
Generic task scheduler
Heterogeneous
AutoscaleVisibility
Plugins forConstraints, Fitness
High speed

Mantis system overview
MantisMantis
Apache MesosApache Mesos
Mantis
Apache Mesos
ASGASG
ASGFenzo
MesosFramework
ZooKeeper
Inst
ance
Apache MesosSlave Cluster

Heterogeneous Resource Scheduling Using Apache Mesos for Cloud Native Frameworks
Sharma Podila
@podila