replication, transcription, translation2012
TRANSCRIPT

Replication, Transcription, Translation

Make up of DNA
• DNA is a polymer of nucleotides, each consisting of a nitrogenous base, a sugar, and a phosphate group
• Sugar: deoxyribose• Nitrogenous base: Adenine, Thymine,
Cytosine, Guanine

Figure 16.5 Sugar–phosphatebackbone
Nitrogenous bases
Thymine (T)
Adenine (A)
Cytosine (C)
Guanine (G)
Nitrogenous base
Phosphate
DNA nucleotide
Sugar(deoxyribose)
3′ end
5′ end

Figure 16.6b
(b) Franklin’s X-ray diffractionphotograph of DNA

3.4 nm
1 nm
0.34 nm
Hydrogen bond
(a) Key features ofDNA structure
(b) Partial chemical structure
3′ end
5′ end
3′ end
5′ end
T
T
A
A
G
G
C
C
C
C
C
C
C
C
C
C
C
G
G
G
G
G
G
G
G
G
T
T
T
T
T
T
A
A
A
A
A
A
Figure 16.7a

Figure 16.UN01
Purine + purine: too wide
Pyrimidine + pyrimidine: too narrow
Purine + pyrimidine: widthconsistent with X-ray data

Chargaff’s rule
• A = T, and the amount of G = C

Figure 16.8
Sugar
Sugar
Sugar
Sugar
Adenine (A) Thymine (T)
Guanine (G) Cytosine (C)

DNA replication
• Ensures that new cells will have a complete set of DNA
• During replication the DNA molecule separates into 2 strands, then produces 2 new complementary strands
• Each original strand serves as a template for the new strands to form from
• Each new DNA is composed of an old strand and a new complementary strand

Figure 16.9-3
(a) Parent molecule (b) Separation ofstrands
(c) “Daughter” DNA molecules,each consisting of oneparental strand and onenew strand
A
A
A
A
A
A
A
A
A
A
A
A
T
T
T
T
T
T
T
T
T
T
T
T
C
C
C
C
C
C
C
C
G
G
G
G
G
G
G
G

Semiconservative Model of Replication
• When DNA replicates, each daughter molecule will have one old strand (derived or “conserved” from the parent molecule) and one newly made strand
• Competing models were the conservative model (the two parent strands rejoin) and the dispersive model (each strand is a mix of old and new)

Figure 16.10
(a) Conservativemodel
(b) Semiconservativemodel
(c) Dispersive model
Parentcell
Firstreplication
Secondreplication

DNA replication
• The copying of DNA is remarkable in its speed and accuracy
• More than a dozen enzymes and other proteins participate in DNA replication

DNA replication speed
• In prokaryotes DNA replication begins at one point then spreads in 2 directions until the entire chromosome is replicated
• In eukaryotes DNA replication occurs at hundreds of places at once and proceeds in both directions until the entire chromosome is copied.
• Replication forks- sites where separation (of the double helix) and replication are occurring

The players
• Helicases are enzymes that untwist the double helix at the replication forks
• Single-strand binding proteins bind to and stabilize single-stranded DNA
• Topoisomerase corrects “overwinding” ahead of replication forks by breaking, swiveling, and rejoining DNA strands
• DNA polymerases: add nucleotides to the 3′ end of DNA
• The initial nucleotide strand is a short RNA primer

• Primase: enzyme that makes the RNA primer; (uses the parental DNA as a template)
• The primer is short (5–10 nucleotides long), and the 3′ end serves as the starting point for the new DNA strand

Antiparallel elongation
• The antiparallel structure of the double helix affects replication
• DNA polymerases add nucleotides only to the free 3′ end of a growing strand; therefore, a new DNA strand can elongate only in the 5′ to 3′ direction

• Along one template strand of DNA, the DNA polymerase synthesizes a leading strand continuously, moving toward the replication fork
• To elongate the other new strand, called the lagging strand, DNA polymerase must work in the direction away from the replication fork
• The lagging strand is synthesized as a series of segments called Okazaki fragments, which are joined together by DNA ligase

Proofreading and repairing DNA
• DNA polymerases proofread newly made DNA, replacing any incorrect nucleotides
• In mismatch repair of DNA, repair enzymes correct errors in base pairing
• DNA can be damaged by exposure to harmful chemical or physical agents such as cigarette smoke and X-rays; it can also undergo spontaneous changes
• In nucleotide excision repair, a nuclease cuts out and replaces damaged stretches of DNA

Figure 16.UN03
DNA pol III synthesizesleading strand continuously
ParentalDNA DNA pol III starts DNA
synthesis at 3′ end of primer,continues in 5′ → 3′ direction
Origin ofreplication
Helicase
Primase synthesizesa short RNA primer
DNA pol I replaces the RNAprimer with DNA nucleotides
3′
3′
3′5′
5′
5′
5′
Lagging strand synthesizedin short Okazaki fragments,later joined by DNA ligase

Basic Principles of Transcription and Translation
• RNA is the bridge between genes and the proteins for which they code
• Transcription is the synthesis of RNA under the direction of DNA
• Transcription produces messenger RNA (mRNA)
• Translation is the synthesis of a polypeptide, using information in the mRNA
• Ribosomes are the sites of translation

• In prokaryotes, translation of mRNA can begin before transcription has finished
• In a eukaryotic cell, the nuclear envelope separates transcription from translation
• Eukaryotic RNA transcripts are modified through RNA processing to yield finished mRNA

Figure 17.UN01
DNA RNA Protein

Figure 17.3
DNA
mRNARibosome
Polypeptide
TRANSCRIPTION
TRANSLATION
TRANSCRIPTION
TRANSLATION
Polypeptide
Ribosome
DNA
mRNA
Pre-mRNARNA PROCESSING
(a) Bacterial cell (b) Eukaryotic cell
Nuclearenvelope

How do nucleotide bases code for amino acids?
• 4 nucleotide bases• 20 amino acids• 3 bases= 1 codon= 1 amino acid

Figure 17.4
DNAtemplatestrand
TRANSCRIPTION
mRNA
TRANSLATION
Protein
Amino acid
Codon
Trp Phe Gly
5′
5′
Ser
U U U U U3′
3′
5′3′
G
G
G G C C
T
C
A
A
AAAAA
T T T T
T
G
G G G
C C C G GDNAmolecule
Gene 1
Gene 2
Gene 3
C C

• During transcription, one of the two DNA strands, called the template strand, provides a template for ordering the sequence of complementary nucleotides in an RNA transcript
• The template strand is always the same strand for a given gene
• During translation, the mRNA base triplets, called codons, are read in the 5′ to 3′ direction

Cracking the code
• All 64 codons were deciphered by the mid-1960s• Of the 64 triplets, 61 code for amino acids; 3
triplets are “stop” signals to end translation• The genetic code is redundant (more than one
codon may specify a particular amino acid) but not ambiguous; no codon specifies more than one amino acid
• Codons must be read in the correct reading frame (correct groupings) in order for the specified polypeptide to be produced

Figure 17.5 Second mRNA base
Firs
t mRN
A b
ase
(5′ e
nd o
f cod
on)
Thir
d m
RNA
bas
e (3
′ end
of c
odon
)
UUU
UUC
UUA
CUU
CUC
CUA
CUG
Phe
Leu
Leu
Ile
UCU
UCC
UCA
UCG
Ser
CCU
CCC
CCA
CCG
UAU
UACTyr
Pro
Thr
UAA Stop
UAG Stop
UGA Stop
UGU
UGCCys
UGG Trp
GC
U
U
C
A
U
U
C
C
CA
U
A
A
A
G
G
His
Gln
Asn
Lys
Asp
CAU CGU
CAC
CAA
CAG
CGC
CGA
CGG
G
AUU
AUC
AUA
ACU
ACC
ACA
AAU
AAC
AAA
AGU
AGC
AGA
Arg
Ser
Arg
Gly
ACGAUG AAG AGG
GUU
GUC
GUA
GUG
GCU
GCC
GCA
GCG
GAU
GAC
GAA
GAG
Val Ala
GGU
GGC
GGA
GGGGlu
Gly
G
U
C
A
Met orstart
UUG
G

Transcription
• Making mRNA starts with RNA polymerase, which pries the DNA strands apart and hooks together the RNA nucleotides
• The RNA is complementary to the DNA template strand
• RNA synthesis follows the same base-pairing rules as DNA, except that uracil substitutes for thymine

• The DNA sequence where RNA polymerase attaches is called the promoter; in bacteria, the sequence signaling the end of transcription is called the terminator

Figure 17.7-4 Promoter
RNA polymeraseStart point
DNA
5′3′
Transcription unit
3′5′
Elongation
5′3′
3′5′
Nontemplate strand of DNA
Template strand of DNARNAtranscriptUnwound
DNA2
3′5′3′5′
3′
RewoundDNA
RNAtranscript
5′
Termination3
3′5′
5′Completed RNA transcript
Direction of transcription (“downstream”)
5′3′
3′
Initiation1

mRNA editing
• Enzymes in the eukaryotic nucleus modify pre-mRNA (RNA processing) before mRNA leave the cytoplasm
• During RNA processing, both ends of the primary transcript are usually edited
• Also, usually some interior parts of the molecule are cut out, and the other parts spliced together

• Each end of a pre-mRNA molecule is modified in a particular way
– The 5′ end receives a modified nucleotide 5′ cap– The 3′ end gets a poly-A tail
• These modifications share several functions– They seem help mRNA leave the nucleus– They protect mRNA from hydrolytic enzymes– They help ribosomes attach to the 5′ end

RNA splicing
• Most eukaryotic genes and their RNA transcripts have long noncoding stretches of nucleotides that lie between coding regions
• These noncoding regions are called intervening sequences, or introns
• The other regions are called exons because they are eventually expressed, usually translated into amino acid sequences
• RNA splicing removes introns and joins exons, creating an mRNA molecule with a continuous coding sequence

GeneDNA
Exon 1 Exon 2 Exon 3Intron Intron
Transcription
RNA processing
Translation
Domain 3
Domain 2
Domain 1
Polypeptide
Figure 17.13

The Basis of Translation
• A cell translates an mRNA message into protein with the help of transfer RNA (tRNA)
• tRNA transfer amino acids to the growing polypeptide in a ribosome
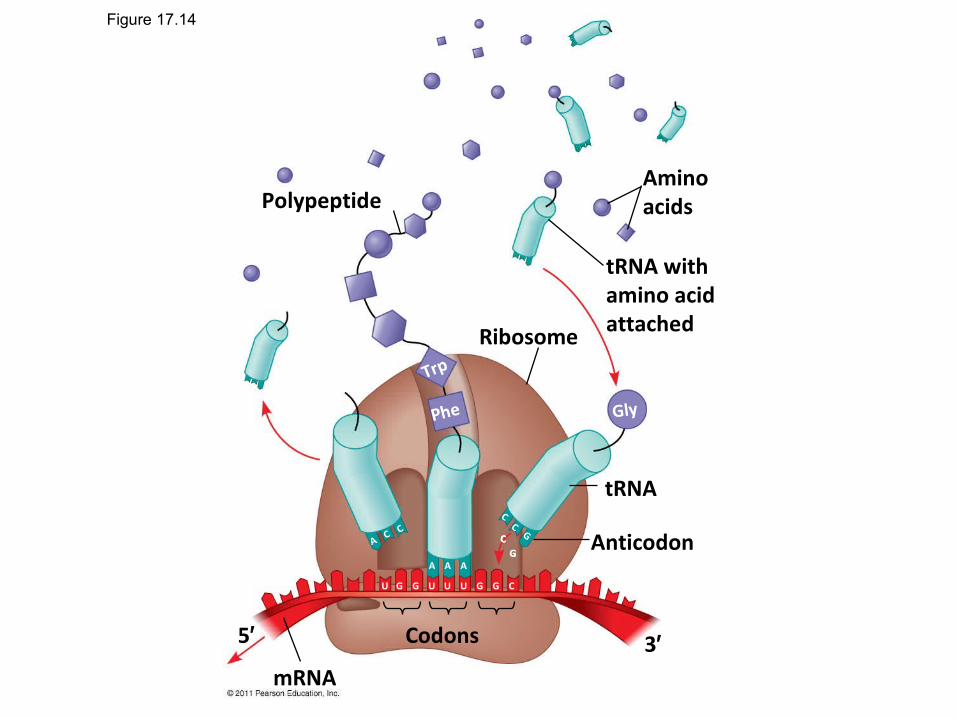
Figure 17.14
Polypeptide
Ribosome
Trp
Phe Gly
tRNA withamino acidattached
Aminoacids
tRNA
Anticodon
Codons
U U U UG G G G C
AC C
C
CG
A A A
CGC
G
5′ 3′mRNA

tRNA
• Molecules of tRNA are not identical– Each carries a specific amino acid on one end– Each has an anticodon on the other end; the
anticodon base-pairs with a complementary codon on mRNA

Ribosomes
• Ribosomes help join tRNA anticodons with mRNA codons in protein synthesis
• The two ribosomal subunits (large and small) are made of proteins and ribosomal RNA (rRNA)

Figure 17.17b
Exit tunnel
A site (Aminoacyl-tRNA binding site)
Smallsubunit
Largesubunit
P A
P site (Peptidyl-tRNAbinding site)
mRNAbinding site
(b) Schematic model showing binding sites
E site (Exit site)
E

Ribosome binding sites
• A ribosome has three binding sites for tRNA– The P site holds the tRNA that carries the
growing polypeptide chain– The A site holds the tRNA that carries the next
amino acid to be added to the chain– The E site is the exit site, where discharged
tRNAs leave the ribosome

Figure 17.17c
Amino end
mRNA
E
(c) Schematic model with mRNA and tRNA
5′ Codons
3′
tRNA
Growing polypeptide
Next aminoacid to beadded topolypeptidechain

Termination of polypeptide
• Termination occurs when a stop codon in the mRNA reaches the A site of the ribosome
• The A site accepts a protein called a release factor
• The release factor causes the addition of a water molecule instead of an amino acid
• This reaction releases the polypeptide, and the translation assembly then comes apart

Mutations
• changes in the genetic material of a cell or virus
• Point mutations are chemical changes in just one base pair of a gene
• The change of a single nucleotide in a DNA template strand can lead to the production of an abnormal protein

Types of Substitution Mutations
• Silent mutations have no effect on the amino acid produced by a codon because of redundancy in the genetic code
• Missense mutations still code for an amino acid, but not the correct amino acid
• Nonsense mutations change an amino acid codon into a stop codon, nearly always leading to a nonfunctional protein

Frameshift mutations
• Insertions and deletions are additions or losses of nucleotide pairs in a gene
• may alter the reading frame

Figure 17.24e
DNA template strand
mRNA5′
5′
Protein
Amino endStopCarboxyl end
3′3′
3′
5′
Met Lys Phe Gly
A
A
A A
A A A A
A AT
T T T T T
T T TT
C C C C
C
C
G G G G
G
G
A
A A A AG GGU U U U U
(b) Nucleotide-pair insertion or deletion: frameshift causingextensive missense
Wild type
missing
missing
A
U
A A AT T TC C A T TC C G
A AT T TG GA A ATCG G
A G A A GU U U C A AG G U 3′
5′3′
3′5′
Met Lys Leu Ala
1 nucleotide-pair deletion
5′

Figure 17.26TRANSCRIPTION DNA
RNApolymerase
ExonRNAtranscript
RNAPROCESSING
NUCLEUS
Intron
RNA transcript(pre-mRNA)
Poly-A
Poly-A
Aminoacyl-tRNA synthetase
AMINO ACIDACTIVATION
Aminoacid
tRNA
5′ Cap
Poly-A
3′
GrowingpolypeptidemRNA
Aminoacyl(charged)tRNA
Anticodon
Ribosomalsubunits
A
AETRANSLATION
5′ Cap
CYTOPLASM
P
E
Codon
Ribosome
5′
3′