reorganizations. agenda the goal mythology and other interesting anti-facts and facts…...
TRANSCRIPT

Reorganizations

Agenda
• The Goal• Mythology and other interesting anti-facts and facts…• Reorganizing Tables
– Offline– Online
• Entire table• Shrinking Space• Purging
• Reorganizing Indexes– Offline– Online
• Entire rebuild• Coalesce

Goal

The goal
• The Goal is to not have to reorganize• Do not get into “ground hog day” mode• There are long term solutions for many of the
common issues• The trick is understanding why something happens,
so you can develop a corrective action• EG: we purge old data, this leaves table 30%
empty, we want to reclaim this space– You could rebuild table– You could use partitioning to age old data out instead

MythologyAnd other interesting anti-facts and facts
(found in that inter-web thingy)

Indexes
Oracle index nodes are not physically deleted when table rows are deleted, nor are the entries removed from the index. Rather, Oracle "logically" deletes the index entry and leaves "dead" nodes in the index tree where that may be re-used if another adjacent entry is required.However, when large numbers of adjacent rows are deleted, it is highly unlikely that Oracle will have an opportunity to re-use the deleted leaf rows, and these represent wasted space in the index. In addition to wasting space, large volumes of deleted leaf nodes will make index fast-full scans run for longer periods.
Myth1.sql
If this were true, all indexes would grow, and grow and grow and grow.
If index space were not reused, all indexes would always need to be rebuilt at some
point in time.
It was never true.

Indexes
Hence, an Oracle index may have four levels, but only in those areas of the index tree where the massive inserts have occurred. Oracle indexes can support many millions of entries in three levels, and any Oracle index that has four or more levels would benefit from rebuilding.… Note that Oracle indexes will “spawn” to a fourth level only in areas of the index where a massive insert has occurred, such that 99% of the index has three levels, but the index is reported as having four levels.
If this were true, all indexes on sequence populated columns and most on
dates/timestamps would be unbalanced.
It is physically impossible to have an unbalanced index. It is most probable that
rebuilding an index with height of 4 will result in an index of height….. 4

IndexesAdd to this the various node splitting algorithms Oracle uses for non-sequential inserts and updates and you can easily see why clustering factor increases and can become out of sync with reality. An index rebuild coalesces nodes and aligns them with the underlying table. Now, in many cases this reduces the clustering factor, …
However, I may have stated things unclearly, the goal in index rebuilding is not to reduce clustering factor, that is actually a desired by-product, … Clustering factor ratios are just one of several indicators that can tell you an index needs to be investigated.
Cf.sqlMyth2.sql
The cluster factor is a metric that describes how sorted the table data is with respect to
the index key in the given index.
Rebuilding an index can never have any effect on the clustering factor
It requires a table reorganization

Indexes
The second rule of thumb is that the deleted leaf rows should be less than 20% of the total number of leaf rows. An excessive number of deleted leaf rows indicates that a high number of deletes or updates have occurred to the index column(s). The index should be rebuilt to better balance the tree. The INDEX_STATS table can be queried to determine if there are excessive deleted leaf rows in relation to the total number of leaf rows.
Myth3.sql
DEL_LF_ROWS is very unreliable as a method to detect an index that needs to be
rebuilt.Contrary to popular belief – deleted rows
are in fact cleaned outAn index that is most in need of a rebuild
from time to time will not make itself known using this ‘technique’.
An index that will be perfectly fine in a couple of minutes will be flagged
erroneously

Indexes
Indexes that undergo frequent insert, update and delete operations need to be rebuilt regularly to prevent ‘fragmentation’
If the indexed data arrives randomly (last_name for example) this is utter non-
sense. The index might end up 50% utilized – and a rebuild could make it 90% utilized – for the next couple of minutes!
Think “sweeper” index from prior slide. They are candidates for period coalesce or
rebuilds.

Indexes
Index space is not reused within a transaction. Hence DELETE+INSERT will tend to increase the size of the index greatly
fact1.sql
This is why atomic_refresh => false on a materialized view might be relevant.
This is why you want to consider partitioning and other physical structures –
if you have two index segments, and flip flop partitions, this won’t be an issue.
Knowing that this is true is the first step to solving the problem. Or at least identifying when you might want to coalesce/rebuild

Indexes
Sweeper indexes are candidates for periodic rebuilds in order to either
1. Reclaim space2. Improve the performance of “select id from t order by id” style
queries
If you leave a few stragglers behind – delete most but not all old entries – then
the left hand side of the index might become “brown”. Since you are inserting monotonically values – only the right hand
side gets hit
You could rebuild or coalesce forever. Or you could fix it with a reverse key index (but only if the only goal was to reclaim
space! Range scan issue)

Indexes
If you do large range scans, you should reorganize the table to be sorted by the index key ??
Well, rebuilding the table over and over could be an option (especially with
dbms_redefinition ORDERBY_COLS)
But so could B*Tree clustering, Hash clustering, Index organized tables, Partitioning – anything that forces
“location” on data

Indexes – corollary
Rebuild indexes that you range scan in a tablespace with a larger blocksize than the default blocksize. This will reduce logical IO’s by 50%.
Myth4.sql
This is false in most all general cases. It is true in one special case – when you access only the index and not the table and you do
so during a RANGE SCAN (not a fast full scan)
Most logical IO’s will be against the table, not the index
And the detrimental side effects? Increased contention. Special memory set aside that cannot be used for other stuff.
More management for you.

How ToFor
Tables

How do I reorg a table?
• Suppose you get the question “how do I reorg a table’• You answer quickly “Alter table T move, rebuild indexes”…
– And say they did that, what did they get?• Took 2 hours of downtime (big table, lots of indexes)• Cost $$$, they could have been doing something truly
productive• Did they achieve their goal? Not in this case, their perceived
problem was chained rows (say 1,000 of them)• After the reorg, they still had 1,000 chained rows!
• We need to ask “WHY”, what is the goal.• Before you do any reorganization you want to know why and
understand how the operation will solve that problem

How do I reorg a 50gig database
At a given customer site, I must reorganize a 50 Gigs 8.0.5 Prod DB in a single day.
Note that I do not know the environment yet (I am replacing somebody leaving on vacation without providing any analysis report. This guy only told this DB is bad, we must re-organize it and left on vacation...).
I only know the DB is running on a Windows (NT) server, the 50 Gigs DB is mission-critical (hosting the PeopleSoft Financials suite), the DB is said to be highly-fragmented at the tablespace-levels and highly chained at the table-levels but no bad-perf issue has been apparently reported.
I do not have disk space to create a new db aside the current one, I only have One Day to successfully carry out the whole thing. What would be the right approach ? Keeping in mind, not to loose anything on the way ... (i.e., low risk). What would be the best strategy ?

How do I reorg a 50gig database
• I asked “why”, “what is the goal”• Answer:
– Tablespace fragmented as reported by Toad– Chained rows, must get rid of chained rows
• Turns out peoplesoft uses lots of longs, won’t matter how many times you rebuild will it.
• Fragmented tablespace – so what? 1 extent or 500 extents. So what? They don’t drop/truncate, so “so what”
• Only answer is “don’t even think about doing this”. What would have happened had I just answered the question!

How to for Tables
• Reorganizing Tables– Offline– Online – EE only
• Entire table• Shrinking Space• Purging
– Mostly online• Materialized view trick, all editions

How to for Tables - offline
• Two basic approaches– ALTER TABLE T MOVE
• Very offline• Queries can proceed while the alter table executes• Immediately after completion, all indexes go invalid• That likely kills all queries till they are rebuilt• Downtime for modifications = time to move + time to
rebuild all indexes• Downtime for reads = time to rebuild all indexes

How to for Tables - offline
• Two basic approaches– Make read only + Create table as select + index +
constrain + drop old + rename new• About same amount of downtime for writes• Less downtime for reads (just time to drop and
rename)• Requires more space – 2 tables, 2 of each index.
ALTER MOVE just requires 2 tables for a moment plus 1 of each index. And then 1 table and 1 copy of 1 index plus individual ones as you rebuild them
• Much more work

How to for Tables - offline
• Two basic approaches– Never ever use
• exp/imp (CLM)• Expdp/impdp• Dump and load
– Given a choice, I would always choose alter move• Simplicity• No loss of anything
– Given need for continuous reads, CTAS

• Enhanced Online Table Redefinition– Easy cloning of indexes, grants, constraints, etc.
• Down to 4 easy steps
1. Create new, empty table
2. Start redef (initial copy)
3. Copy_Table_Dependents, instead of manually indexing, altering, etc
4. Finish redef– Convert from long to LOB online– Allow unique index instead of primary key
Redef.sql
How to for Tables - online

• DBMS_REDEFINITION– Ranks high on the safety scale– Direct path load – can use nologging– Dependent objects can be
• Copied automatically• Done by hand• Combination of above
– You want primary key (to avoid extra rowid column at end of redefed table that will be dropped)
– High update tables will require frequent ‘syncs’
How to for Tables - online

Online Segment Shrink
• Table fills over time• You delete rows• Lots of whitespace
– You want to get it back– You full scan and want it
smaller
• In the past– Alter table move, Alter index
rebuild– Export/Import– Offline
• Not any more…
shrink.sql

How ToFor
Indexes
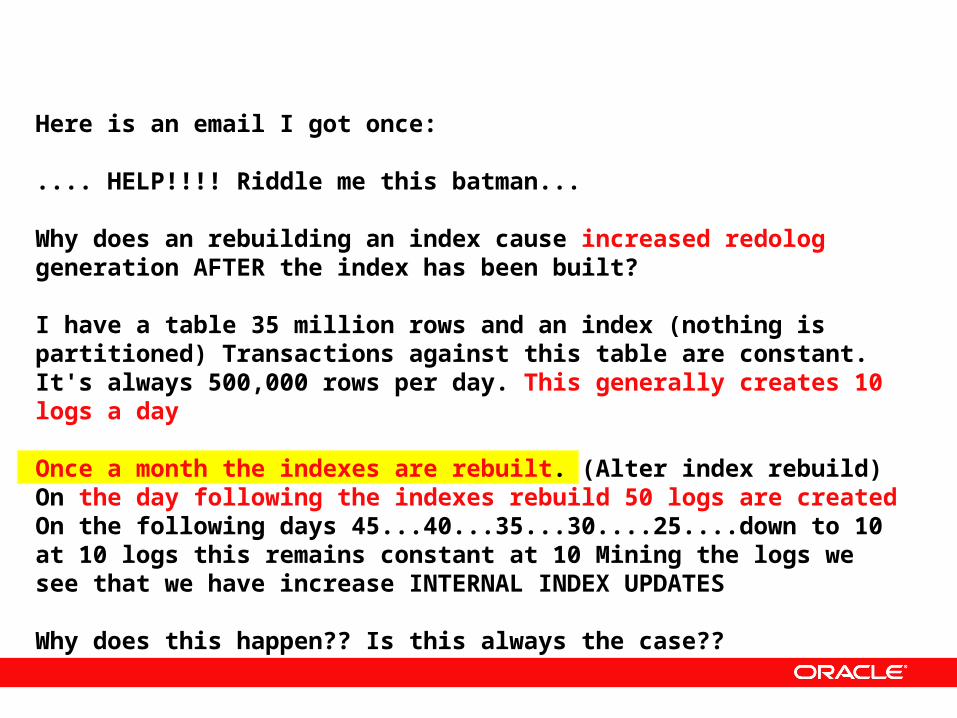
Here is an email I got once:
.... HELP!!!! Riddle me this batman...
Why does an rebuilding an index cause increased redolog generation AFTER the index has been built?
I have a table 35 million rows and an index (nothing is partitioned) Transactions against this table are constant. It's always 500,000 rows per day. This generally creates 10 logs a day
Once a month the indexes are rebuilt. (Alter index rebuild) On the day following the indexes rebuild 50 logs are created On the following days 45...40...35...30....25....down to 10 at 10 logs this remains constant at 10 Mining the logs we see that we have increase INTERNAL INDEX UPDATES
Why does this happen?? Is this always the case??

How To For Indexes
• Remember – one of three things will happen as a result of a reorganization
– It’ll go better– It’ll not change at all– It’ll be much worse than it was before

Have metrics and live up to them
• Keep metrics– Statspack/AWR for example, see if LIO’s go down– Application level statistics
• Evaluate against them– Do an index rebuild– Come back tomorrow and verify you did more good then harm– Rebuilding can be good– Coalescing – even better (online, without the overhead)– Most of the time, it is not even needed and can do more harm
then good– Does not mean I’ve said “you never have to rebuld an index”
• Bitmaps• Secondary indexes on IOT’s• Text indexes for example…

How To For Indexes
• Reorganizing Indexes– Offline– Online
• Entire rebuild• Coalesce

How to for Indexes - offline
• Two basic approaches– Drop and create
• Entirely offline– Create and swap
• Almost online in SE• Read only during index create
swap.sql

How to for Indexes - online
• Two basic approaches– Rebuild
• Optionally online• Need approximately 2 times the storage• Use existing index to copy from
o Skip sorto Less physical IO
– Coalesce • Need only current storage• Online• Combines logically adjacent index blocks as much as
possiblecompare.sql

How to for Indexes - online
• Two basic approaches– If I had my way – it would be coalesce– Always online– Least space needs– No locking issues – Does not “skinny up” the interior (riddle me this
batman…)

<Insert Picture Here>
AQ&