relational database systems 2 - tu braunschweig · structured organization is necessary, but also...
TRANSCRIPT

Wolf-Tilo Balke
Jan-Christoph Kalo
Institut für Informationssysteme
Technische Universität Braunschweig
http://www.ifis.cs.tu-bs.de
Relational Database Systems 214. Beyond Relational Databases

14.1 Knowledge-based Systems
and Deductive DBs
14.2 Distributed Databases
14.3 Information Retrieval and
Web Search Engines
14.4 Spatial databases and GIS
14.5 Multimedia Databases
14.6 Data Warehousing
14 Non-Standard Applications
Datenbanksysteme 2 – Wolf-Tilo Balke – Institut für Informationssysteme – TU Braunschweig 2

• People always dreamed of intelligent machines
– The Turk of Wolfgang von Kempelen (1770)
– Golden robots of Hephaestus
• In the 20th century, A.I. (Artificial
Intelligence) became popular
– 1967: Marvin Minsky
• "Within a generation ... the problem of creating
'artificial intelligence' will substantially be solved."
• In the mid seventies, the great visions died
– A long series of failures took its toll (A.I. winter)
Datenbanksysteme 2 – Wolf-Tilo Balke – Institut für Informationssysteme – TU Braunschweig 3
14.1 Knowledge-based Systems and Deductive DBs

• Main critique – Hubert Dreyfus (UC Berkeley, USA)– Expertise cannot readily be extracted
from human experts
– Much knowledge is not explicit,but somehow embodied
• In the 1980ies, A.I. focused onwell-defined problem domains– Knowledge-based systems
• Idea: Create a system which can drawconclusions and thus support decisions– Main idea: extract knowledge of experts
and just cheaply copy it to all places you might need it
Datenbanksysteme 2 – Wolf-Tilo Balke – Institut für Informationssysteme – TU Braunschweig 4
14.1 Knowledge-based Systems and Deductive DBs

• Usually Expert Systems are based on interference rules and specific problem data– Rule: All frogs are green
– Fact: Hektor is a frog
– Implies new fact: Hektor is green
• Also, uncertainly can be supported– Rule: Almost all birds can fly except ostriches, chicken
and penguins
– Fact: Tweety is a bird
– Query: Can Tweety fly?• Only few species are ostrichs, chicken or penguins
• Tweety can fly with high probability
Datenbanksysteme 2 – Wolf-Tilo Balke – Institut für Informationssysteme – TU Braunschweig 5
14.1 Expert Systems
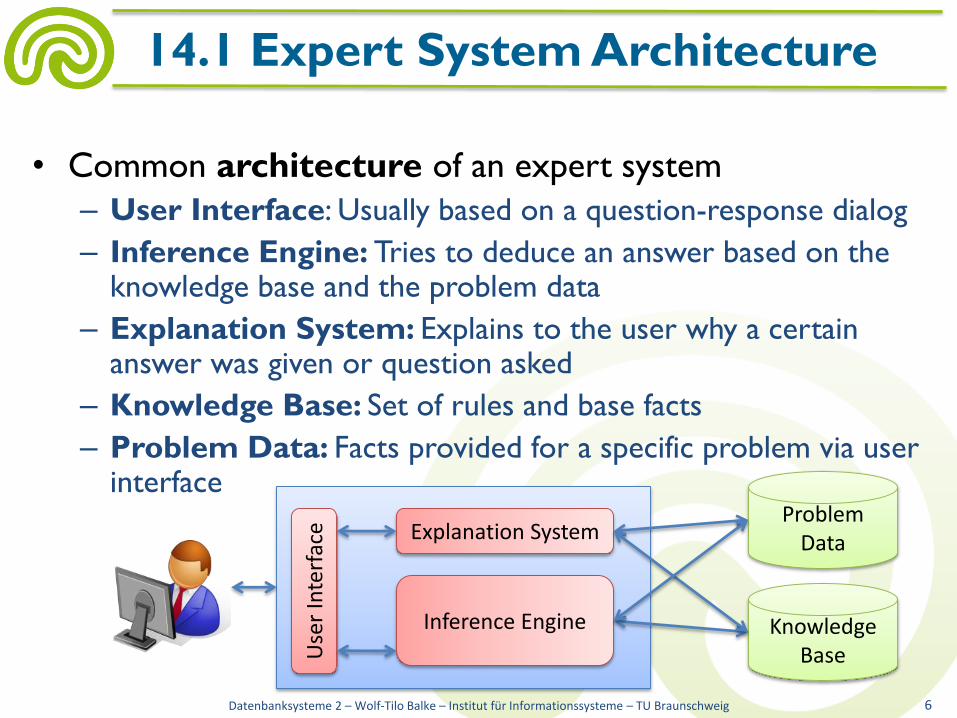
• Common architecture of an expert system
– User Interface: Usually based on a question-response dialog
– Inference Engine: Tries to deduce an answer based on the knowledge base and the problem data
– Explanation System: Explains to the user why a certain answer was given or question asked
– Knowledge Base: Set of rules and base facts
– Problem Data: Facts provided for a specific problem via user interface
Datenbanksysteme 2 – Wolf-Tilo Balke – Institut für Informationssysteme – TU Braunschweig 6
14.1 Expert System Architecture
Use
r In
terf
ace Explanation System
Inference Engine
Problem Data
Knowledge Base

• Expert systems have to keep and manage
valuable data in their knowledge base
– Basically expert systems just support another query
type, but have the same requirements like a normal
database system
• A deductive DBS is a database system with
limited support for reasoning• All the goodies of databases (transactions, recovery, etc.)
• Queries based on recursive views are possible
• Efficient query optimization
Datenbanksysteme 2 – Wolf-Tilo Balke – Institut für Informationssysteme – TU Braunschweig 7
14.1 Expert Systems

• System may deduce new facts using rules
– Leads to inference chains
• Most systems heavily rely on mathematical logics
– First-Order Predicate Logics
Datenbanksysteme 2 – Wolf-Tilo Balke – Institut für Informationssysteme – TU Braunschweig 8
14.1 Logics

• Deductive queries/programs are often stated in
Prolog or Datalog
– Prolog is a logical programming language created in
1972
– Datalog is a subset of Prolog especially designed for
deductive databases
• No predicates are allowed as arguments
• Only fix-point iteration
• Efficient bottom-up evaluation
Datenbanksysteme 2 – Wolf-Tilo Balke – Institut für Informationssysteme – TU Braunschweig 9
14.1 Datalog

• Up to now we have only considered scenarios
where a central DBMS is responsible for
– Keeping the data consistent and persistent
– Optimizing query plans and minimizing disk accesses
– Guaranteeing the ACID properties of interaction
– Controlling the data security and privacy
• Especially, all meta-information about the
processes is concentrated at the DBMS
Datenbanksysteme 2 – Wolf-Tilo Balke – Institut für Informationssysteme – TU Braunschweig 10
14.2 Distributed Databases

• But organizations usually have a variety of
different systems to keep data records
– Customer database, human resources, product
catalogs, financial records
• How can a complete view of the distributed
data be provided, keeping all the advantages of a
single central database system?
– Integrate data, but avoid
single point of failure
Datenbanksysteme 2 – Wolf-Tilo Balke – Institut für Informationssysteme – TU Braunschweig 11
14.2 Distributed Databases

• A distributed database is a database
– Under the control of a central database management
system
– Operations run on multiple computers located in the
same physical location, or may be dispersed over a
network of interconnected computers
– Storage devices are not all
attached to a common CPU
– Collections of data can be distributed
across multiple physical locations
Datenbanksysteme 2 – Wolf-Tilo Balke – Institut für Informationssysteme – TU Braunschweig 12
14.2 Distributed Databases

• Database fragmentation
– Horizontal (row distribution)
– Vertical (column and/or
table distribution)
• Distributing databases (top-down)
– How to split and allocate data to individual sites?
• Integrating databases (bottom-up)
– Combine existing databases
– How to deal with heterogeneity & autonomy?
Datenbanksysteme 2 – Wolf-Tilo Balke – Institut für Informationssysteme – TU Braunschweig 13
14.2 Distributed Databases

• Major advantages
– Reflects organizational structure
• Database fragments are located in the departments they relate to
– Local autonomy
• A department can control its own data and enforce policies
– Improved availability
• A fault in one database system will only affect one fragment,
instead of the entire database
– Improved performance
• The database fragments enable parallelized operations, allowing
load on the databases to be balanced among servers
Datenbanksysteme 2 – Wolf-Tilo Balke – Institut für Informationssysteme – TU Braunschweig 14
14.2 Distributed Databases

• But not only managed data access within some structured organization is necessary, but also data access via the Internet
– Distributed information sources
– Deep Web / Hidden Web
– E-Commerce, comparison shopping
• Data transfer over the Web makes up for a large amount of bandwidth
– About 90% of network resources (including file sharing applications)
Datenbanksysteme 2 – Wolf-Tilo Balke – Institut für Informationssysteme – TU Braunschweig 15
14.2 Distributed Databases

• Avoiding a single point of failure is mostly
beneficial for organizations
– The company’s central database is down, the complete
company is out of business?
– On the other hand multiple points of access may pose
severe security issues…
• For unstructured data the
peer-to-peer (P2P) paradigm
is often used for content access
Datenbanksysteme 2 – Wolf-Tilo Balke – Institut für Informationssysteme – TU Braunschweig 16
14.2 Distributed Databases

• P2P systems are overlay architectures, with
the following characteristics
– Two logically separate networks
– Mostly IP based signaling
– Decentralized and self organizing
– Employ distributed shared resources
Datenbanksysteme 2 – Wolf-Tilo Balke – Institut für Informationssysteme – TU Braunschweig 17
14.2 Distributed Databases

• First application: file sharing
– Classical application of P2P systems
• Large distributed database of files (music , videos, etc.) for free download
– First large scale occurrence of digital copyright infringement
• But also legal distribution of software/updates
– Basic idea of distributing softwareupdates or patches in a P2P fashion
– Technology used
• Today mostly BitTorrent (Block-based File Swarming)
• Microsoft’s Avalanche (File Swarming with Network Coding)
Datenbanksysteme 2 – Wolf-Tilo Balke – Institut für Informationssysteme – TU Braunschweig 18
14.2 Distributed Databases

• Extremely relevant for practical applications is the
retrieval of textual documents
– The importance of information retrieval (IR) was
already recognized in the 1940ies
– In contrast to relational data, texts are unstructured
– The goal is to find documents
from a large collection that
are relevant with respect to
an information need
Datenbanksysteme 2 – Wolf-Tilo Balke – Institut für Informationssysteme – TU Braunschweig 19
14.3 IR & Web Search

• Origins in period immediately after World War II
– Tremendous scientific progress during the war
– Rapid growth in amount of scientific publications available
• The Memex Machine
– Conceived by Vannevar Bush,Roosevelt's science advisor
– 1945 Atlantic Monthly articletitled “As We May Think”
– Foreshadows the development of hypertext (the Web) and information retrieval system
Datenbanksysteme 2 – Wolf-Tilo Balke – Institut für Informationssysteme – TU Braunschweig 20
14.3 IR & Web Search

• First systems used the bag of words model
– The content of a text is characterized by the termsthat it contains
• Treat all the words in a document as index terms for that document
• Disregard order, structure, meaning, etc. of the words
– Relevance regarding a query is measured using the matching between text terms and query terms and the (normalized) number of term occurrences
• Simple, but effective…
Datenbanksysteme 2 – Wolf-Tilo Balke – Institut für Informationssysteme – TU Braunschweig 21
14.3 IR & Web Search

• But there is more to it: words in documents have
a certain importance for the document
• Idea: Hans Peter Luhn (IBM), 1958
– Terms that appear often in a document should
get high weights
– Terms that appear in many documents
should get low weights
– Leads to the idea of term frequency
and inverse document frequency
Datenbanksysteme 2 – Wolf-Tilo Balke – Institut für Informationssysteme – TU Braunschweig 22
14.3 IR & Web Search

• First and most influential system was the
SMART system by Gerald Salton
(Cornell, 1965)
– Weighting with TF-IDF measure
– Documents and queries are considered
as points in a high dimensional vector
space
– The cosine similarity assesses
the relevance of a document
with respect to a query
Datenbanksysteme 2 – Wolf-Tilo Balke – Institut für Informationssysteme – TU Braunschweig 23
14.3 IR & Web Search
t1
d2
d1
d3
d4
d5
t3
t2
θφ

• But text search is far more complicated
– Synonyms, hyponyms, etc.
– Phrases and distance between terms (n-grams)
– Citations and references to other documents
– …
• Moreover, retrieval efficiency and effectiveness
is crucial for the user
– Inverted file indexes, stop-word lists,...
– Relevance feedback, query refinement,…
Datenbanksysteme 2 – Wolf-Tilo Balke – Institut für Informationssysteme – TU Braunschweig 24
14.3 IR & Web Search

• The WWW started with a telephone book
kept up by Sir Tim Berners-Lee at CERN and
quickly developed into a vast variety of
interconnected Web servers
– Berners-Lee’s first
Web server
Datenbanksysteme 2 – Wolf-Tilo Balke – Institut für Informationssysteme – TU Braunschweig 25
14.3 IR & Web Search

• The advent of the World Wide Web opened up
another challenge in IR: distributed IR
– Basically the Web is a large document collection
scattered over a multitude of servers
• How can the best pages in the WWW be
found efficiently?
– First search engines just relied on crawling Web
sites and building up a large index
– Traditional IR techniques then were used on that
index and returned a list of best matching pages
Datenbanksysteme 2 – Wolf-Tilo Balke – Institut für Informationssysteme – TU Braunschweig 26
14.3 IR & Web Search

• The first engines (1993-1994) all relied only on
IR techniques
– Infoseek, Lycos, AltaVista, Inktomi, HotBot, etc.
• In 1998 Google also took the structure of the
Web into account
– Link analysis favored pages that are pointed to from
many others and from more important pages
Datenbanksysteme 2 – Wolf-Tilo Balke – Institut für Informationssysteme – TU Braunschweig 27
14.3 IR & Web Search

• Actually link analysis plus IR techniques
proved to be a quantum leap in result relevance
Datenbanksysteme 2 – Wolf-Tilo Balke – Institut für Informationssysteme – TU Braunschweig 28
14.3 IR & Web Search
46,47
17,16
13,76
12,87
9,74
worldwide market share as of Dec. 2007
Yahoo!
Baidu
MSN
others

• Actually link analysis plus IR techniques
proved to be a quantum leap in result relevance
– Market Share as of Juli 2015
Datenbanksysteme 2 – Wolf-Tilo Balke – Institut für Informationssysteme – TU Braunschweig 29
14.3 IR & Web Search

• The innovation was the PageRankalgorithm invented by Google’s founders Larry Page and Sergey Brin
– The relative importance of a site is derived from the hyperlinks pointing to it
– Links propagate scores through the system
– Getting many links from important sites improves the ‘belief ’ that a site is relevant regarding a topic
Datenbanksysteme 2 – Wolf-Tilo Balke – Institut für Informationssysteme – TU Braunschweig 30
14.3 IR & Web Search

• What about queries with a spatial dimension?
– List all bookstores within ten miles of Hannover
– List the average amounts for purchases of customers who live in Braunschweig
• A Geographical Information System is capable of providing geographically referenced information
• For storing and querying the information a spatial database is used
– Highly optimized to store and query data related to objects in space, including points, lines and polygons
Datenbanksysteme 2 – Wolf-Tilo Balke – Institut für Informationssysteme – TU Braunschweig 31
14.4 Spatial Databases and GIS

• The basic idea is to integrate special spatial
functionality into (or on top of) a DBMS
• Applications for geographic information system
technology are…
– Scientific investigations,
resource management,
urban planning,
cartography, criminology,
history, sales, marketing,
and logistics
Datenbanksysteme 2 – Wolf-Tilo Balke – Institut für Informationssysteme – TU Braunschweig 32
14.4 Spatial Databases and GIS
Spat
ial a
pp
licat
ion
DB
MS
Inte
rfac
e t
o D
BM
S
Inte
rfac
e t
o s
pat
ial a
pp
licat
ion
Taxonomy
Data types
Operations
Query language
Algorithms
Access methods
Core Spatial Functionality

• Basically there are three types of queries
– Basic spatial operations on all data types
• E.g., IsEmpty, Envelope, Boundary,…
– Topological/set operators
• E.g., Disjoint, Touch, Contains,…
– Spatial analysis operators
• E.g., Distance, Intersection, SymmDiff,…
33
14.4 Spatial Queries
Datenbanksysteme 2 – Wolf-Tilo Balke – Institut für Informationssysteme – TU Braunschweig

• A main issue is the indexing in spatial databases, since geographical data is high dimensional
– 3 spatial dimensions
– Often also a temporal dimension
– Dimensions for the actual data attributes
• Typical high-dimensional index structures include R-Trees, Grid File indexes, etc.
14.4 Spatial Indexing
Datenbanksysteme 2 – Wolf-Tilo Balke – Institut für Informationssysteme – TU Braunschweig 34

• For traversing indexes space filling curves can
be utilized (e.g., Hilbert curve, Z-curve)
– They achieve a better ordering of multidimensional
objects in a tree node
– This ordering has to be good, in the sense that it
should group similar data rectangles together to
minimize the area and perimeter of the resulting
minimum bounding rectangles
14.4 Spatial Indexing
Datenbanksysteme 2 – Wolf-Tilo Balke – Institut für Informationssysteme – TU Braunschweig 35

• Relational databases efficiently store and retrieve structured data
– Bank accounts, customer data,…
• How to achieve persistent storage of media like– Text documents
– Vectorgraphics, CAD
– Image, audio, video
• What about content-based retrieval?– Efficiently searching media content
– Standardization of meta-data (e.g., MPEG-7, MPEG-21)
Datenbanksysteme 2 – Wolf-Tilo Balke – Institut für Informationssysteme – TU Braunschweig 36
14.5 Multimedia Databases

• Find all images in the database that show a sun
set!
• What are their common characteristics? Can
we only retrieve them by meta-data annotations?
Datenbanksysteme 2 – Wolf-Tilo Balke – Institut für Informationssysteme – TU Braunschweig 37
14.5 Multimedia Databases

• Characterization by low level features
– Color information may help to discriminate images
– A frog is no sun set
– But not all frogs are green…
Datenbanksysteme 2 – Wolf-Tilo Balke – Institut für Informationssysteme – TU Braunschweig 38
14.5 Multimedia Databases

• Different types of features can be combined
with other features to aid retrieval
– For instance Fourier transform for textures
Datenbanksysteme 2 – Wolf-Tilo Balke – Institut für Informationssysteme – TU Braunschweig 39
14.5 Multimedia Databases

• Also continuous data can be described
– For perception of audio data psychoacoustic models are helpful
– Waveforms can actually bedescribed by some features similar to image features
Datenbanksysteme 2 – Wolf-Tilo Balke – Institut für Informationssysteme – TU Braunschweig 40
14.5 Multimedia Databases

• Harmonies in music allow to recognize and
compare melodies
– Query by Humming and ‘sounds like’ search
Datenbanksysteme 2 – Wolf-Tilo Balke – Institut für Informationssysteme – TU Braunschweig 41
14.5 Multimedia Databases

• Videos combine many techniques used in audio and
image retrieval and interleave them respecting the
structure of the video
Datenbanksysteme 2 – Wolf-Tilo Balke – Institut für Informationssysteme – TU Braunschweig 42
14.5 Multimedia Databases
Story Unit Story Unit Story Unit
StructuralUnit
StructuralUnit
StructuralUnit
StructuralUnit
StructuralUnit
Shot Shot Shot Shot ShotShot
Frames
Key Frame

• The Video is broken down to its shots and the
shots are individually compared for similarity
– Efficient methods needed for shot detection and
effective video similarity measures
Datenbanksysteme 2 – Wolf-Tilo Balke – Institut für Informationssysteme – TU Braunschweig 43
14.5 Multimedia Databases

• Clustering techniques allow to estimate the
similarity of entire video sequences and movies
– Very interesting, e.g., for finding movies of similar
genre, or detecting copyright infringements
Datenbanksysteme 2 – Wolf-Tilo Balke – Institut für Informationssysteme – TU Braunschweig 44
14.5 Multimedia Databases

• Result presentation for videos is another
major problem for the interface design
– Automatic generation of storyboards or trailers
– Results from film theory hint at how directors achieve
certain effects and can be exploited
• E.g., extracting special effects or characteristic scenes
– The audio track of movies can be used to find
important phrases or keywords
Datenbanksysteme 2 – Wolf-Tilo Balke – Institut für Informationssysteme – TU Braunschweig 45
14.5 Multimedia Databases

• Multi-dimensional indexing techniques
provide means for efficient retrieval
– Filter and refine
– Karhunen-Loeve transform
– R-trees, X-trees, M-trees
Datenbanksysteme 2 – Wolf-Tilo Balke – Institut für Informationssysteme – TU Braunschweig 46
14.5 Multimedia Databases

• For business-oriented data relational systems build a good foundation, but…
– There is a huge flood of updates in productive databases
– For data analysis purposes data often has to be transformed and aggregated
– Reports have to be generated quickly to support important decisions
• Should such stress be put on top of operational database systems’ workloads?
Datenbanksysteme 2 – Wolf-Tilo Balke – Institut für Informationssysteme – TU Braunschweig 47
14.6 Data Warehousing

• Basic idea: Don’t put stress on your crucial
DBMSs, but use a second independent system
– Data Warehouses
• provide a unified view of business data and
• provide retrieval of data without slowing down the
operational systems
• facilitate decision support system applications such as
trend reports or market analysis
Datenbanksysteme 2 – Wolf-Tilo Balke – Institut für Informationssysteme – TU Braunschweig 48
14.6 Data Warehousing

• The concept of data warehousing dates back to the
1980ies
– In 1983 Teradata introduces a database
management system specifically designed for decision
support
– In 1988 Barry Devlin and Paul Murphy introduce the
term ‘business data warehouse’ (IBM Systems Journal)
– From 1990 on several warehousing systems are
released (Red Brick Systems, Prism Solutions,…)
– In 1997 Oracle releases version 8i with support for
star queries
Datenbanksysteme 2 – Wolf-Tilo Balke – Institut für Informationssysteme – TU Braunschweig 49
14.6 Data Warehousing
8i

• A data warehouse provides a common data model for all data of interest regardless of the data's source
– Data is usually scattered over several systems in companies: sales invoices, order receipts, production data, etc.
– For reporting and analysis the data would have to be retrieved from each respective source, transformed into a common model and then aggregated
• Before loading into the warehouse all data are cleaned
– Inconsistencies are identified and resolved
Datenbanksysteme 2 – Wolf-Tilo Balke – Institut für Informationssysteme – TU Braunschweig 50
14.6 Data Warehousing

• Global enterprise data models are optimized for
efficient retrieval
– The most simple schema is the star model
– The model consists of a (few) central fact tables that are are
connected to multiple dimensions
– All dimensions are denormalized with each dimension being
represented by a single table
• If dimensions are normalized into
several related tables with minimized
redundancy, the snowflake model
evolves
51
14.6 Data Warehousing

• Example
– Each dimension table has a primary key Id, relating to one of the primary key columns of the fact table
– The non-primary key Units_Sold of the fact table represents a measure or metric that can be used in calculations and analysis
– The non-primary key columns of the dimension tables represent additional attributes of the dimensions
Datenbanksysteme 2 – Wolf-Tilo Balke – Institut für Informationssysteme – TU Braunschweig 52
14.6 Data Warehousing

• Queries on data warehouses follow the paradigm
of online analytical processing (OLAP)
– Exploiting the multidimensional data model of
the warehouse allows for complex analytical and ad-
hoc queries with a rapid execution time
– The heart of any OLAP system is
an OLAP cube consisting of
numeric facts called measures
that are categorized by dimensions
Datenbanksysteme 2 – Wolf-Tilo Balke – Institut für Informationssysteme – TU Braunschweig 53
14.6 Data Warehousing

• The OLAP cube metadata is typically directly
created from a star or snowflake schema
– Measures are derived from the records in the fact
table and dimensions are derived from the
dimension tables
• The output of an OLAP query is typically
displayed in a matrix format
– The dimensions form the row and column of the
matrix, and the measures determine the values
Datenbanksysteme 2 – Wolf-Tilo Balke – Institut für Informationssysteme – TU Braunschweig 54
14.6 Data Warehousing

• The most important mechanism in OLAP for performance is the use of aggregations
– Aggregations are built from the fact table by changing the granularity on specific dimensions and aggregating data along these dimensions
– The number of possible aggregations is determined by every possible combination of dimension granularities
• The combination of all possible aggregations and the base data contains the answers to every query which can be answered from the data
Datenbanksysteme 2 – Wolf-Tilo Balke – Institut für Informationssysteme – TU Braunschweig 55
14.6 Data Warehousing

• Potentially a large number of aggregations has
to be precalculated
– Often only a predetermined number are fully
calculated, while the remainder are solved on demand
• The problem of deciding which aggregations to
calculate is called the view selection problem
– The objective of view selection is typically to
minimize the average time to answer OLAP queries
– View selection is NP-complete, but many strategies
are used: greedy or genetic algorithms, A* search,…
Datenbanksysteme 2 – Wolf-Tilo Balke – Institut für Informationssysteme – TU Braunschweig 56
14.6 Data Warehousing