regresiÓn lineal simple - …asesorias.cuautitlan2.unam.mx/laboratoriovirtualdeestadistica... ·...
TRANSCRIPT

Universidad Nacional Autónoma de México Facultad de Estudios Superiores Cuautitlán
ANÁLISIS DE REGRESIÓN
http://www.cuautitlan.unam.mx Regresión Lineal Simple
Al continuar con el estudio de la relación
entre dos variables X y Y, ahora es
pertinente considerar el caso en que es
necesario pronosticar la variable
dependiente Y con base en la variable
independiente X, es decir, que nos puede
interesar pronosticar el nivel de glucosa
en la sangre de un varón adulto que
tenga X peso.
¿Qué es el análisis de regresión?
Es la técnica empleada para realizar la predicción del valor de la variable
dependiente Y, con base en un valor seleccionado de la variable independiente
X
Nota: La palabra regresión la utilizó por primera vez Sir Francis Galton en 1877
en su estudio de los factores hereditarios. Descubrió que las estaturas de los
descendientes de padres altos, tendían a una regresión (es decir a volver o
retornar) hacia la estatura promedio de la población.
Al observar el diagrama de dispersión,
se puede considerar que una línea recta
parece describir mejor la ubicación
promedio de los puntos, por lo que se
determinará mediante una ecuación
matemática correspondiente a una línea
recta.
¿Qué es la ecuación de regresión?
REGRESIÓN LINEAL SIMPLE
Es una expresión matemática que define la relación entre dos variables,
llamada también recta de regresión. Se pueden trazar manualmente varias
rectas que pasen aproximadamente cerca de todos los puntos, pero el
concepto de “cerca” se debería al juicio de cada persona que realiza el ajuste;
para evitar esta subjetividad y elegir la recta que mejor se ajuste a los puntos,
utilizaremos el método de mínimos cuadrados.

Universidad Nacional Autónoma de México Facultad de Estudios Superiores Cuautitlán
http://www.cuautitlan.unam.mx Regresión Lineal Simple
el método de mínimos
sticados o estimados de
Y (de la recta).
ión de
gresión o recta de regresión, es
n donde:
Y’
o estimado de la variable Y, para un
alor seleccionado de X.
a
e puede decir que es el valor estimado de Y cuando
vale cero
b
Y’, por cada
nidad de cambio en la variable independiente X.
X es cualquier valor seleccionado para la variable independiente.
iable independiente X, le denominaremos
omo coeficiente de regresión.
¿Qué es
cuadrados?
Es una técnica empleada para llegar a la
ecuación de regresión, minimizando la
suma de los cuadrados de las distancias
o desviaciones verticales entre los
valores Y verdaderos (de los puntos) y
los valores prono
La forma general de la ecuac
re
bXaY +='
E
es el valor pronosticado
v
es la ordenada al origen de la recta o la intersección con el eje
Y; también s
X
es la pendiente de la recta, es decir, el cambio promedio
(incremento o decremento según sea el signo) en
u
Como la pendiente b indica el comportamiento o actitud que tiene la variable
dependiente Y con respecto a la var
c

Universidad Nacional Autónoma de México Facultad de Estudios Superiores Cuautitlán
http://www.cuautitlan.unam.mx Regresión Lineal Simple
Cómo se calculan el coeficiente de regresión y la ordenada al origen?
aciones
neales normales, podemos definir las dos fórmulas correspondientes.
o bien
¿
Con base en el planteamiento y solución de un sistema de dos ecu
li
XyY son los promedios o medias de las variables X y Y.
nivel de glucosa en la sangre para un valor del peso de un varón
dulto:
Continuando con nuestro ejemplo, con los valores de la siguiente tabla,
calcularemos la ecuación de la recta de regresión, que estima o pronostica el
valor de
a
X Y X2 XY Y2
64.7 98 4,186.09 6,340.6 9,604
75.3 109 5,670.09 8,207.7 11,881
73.0 88 5,329.00 6,424.0 7,744
82.1 107 6,740.04 8,784.7 11,449
76.2 93 5,806.44 7,086.6 8,649
95.7 121 9,158.49 11,579.7 14,641
59.4 79 3,528.36 4,692.6 6,241
93.4 118 8,723.56 11,021.2 13,924
82.5 109 6,806.25 8,992.5 11,881
78.9 85 6,225.21 6,706.5 7,225
781.2 1,007 62,173.90 79,836.1 103,239
Calculamos ahora los valores de a y b:
22 )() −())()(
XXnYXXYnb
∑∑(∑ − ∑ ∑
=
nnXbYa ∑ ∑= −
XbYa −=
02.156.465,116.692,11
)2.178()90.173,62(10)007,1)(2.781()1.836,79(10
2 ==−
−=b
03.21)12.78(02.17.100)10
2.781(02.110007,1
=−=−=a
Universidad Nacional Autónoma de México Facultad de Estudios Superiores Cuautitlán
http://www.cuautitlan.unam.mx Regresión Lineal Simple
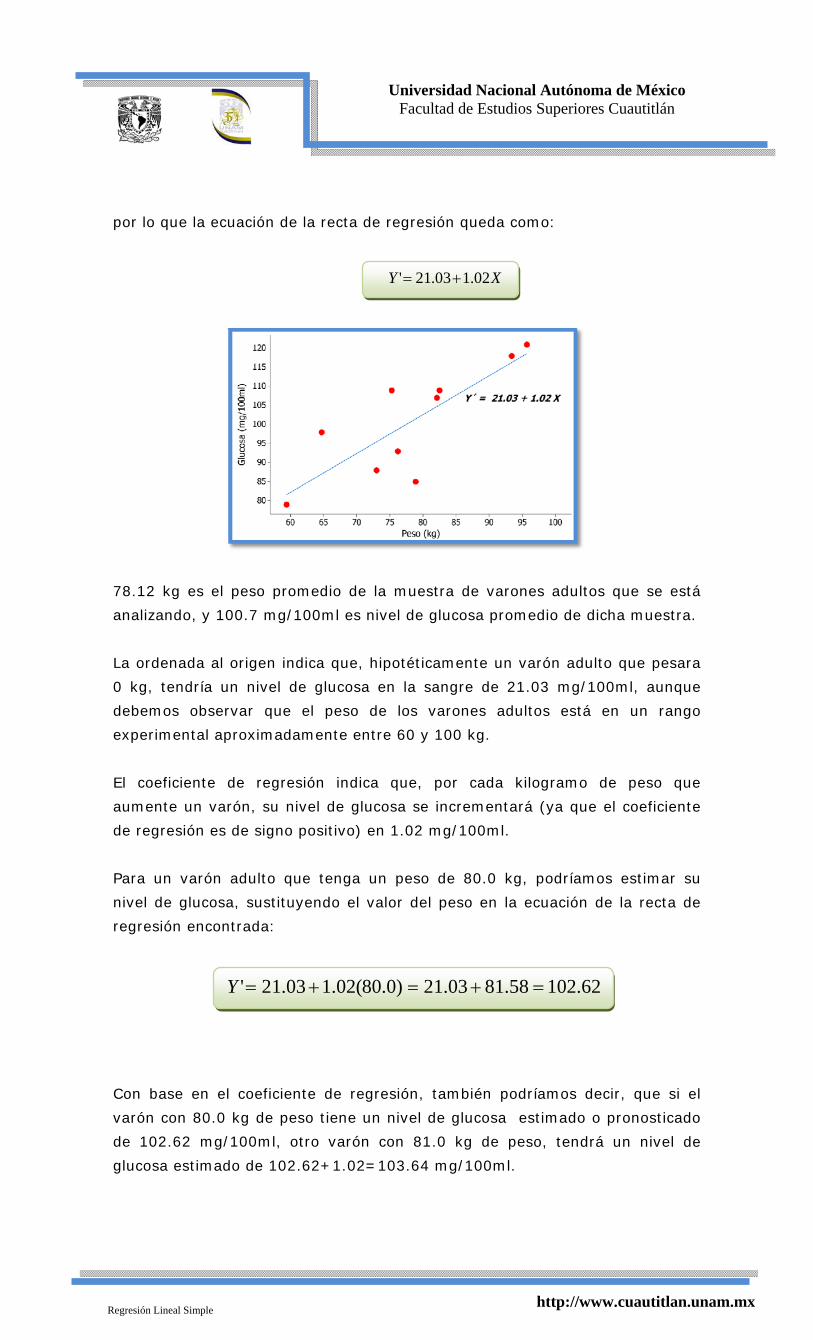
or lo que la ecuación de la recta de regresión queda como:
nalizando, y 100.7 mg/100ml es nivel de glucosa promedio de dicha muestra.
s está en un rango
xperimental aproximadamente entre 60 y 100 kg.
rá (ya que el coeficiente
e regresión es de signo positivo) en 1.02 mg/100ml.
uyendo el valor del peso en la ecuación de la recta de
gresión encontrada:
so, tendrá un nivel de
lucosa estimado de 102.62+1.02=103.64 mg/100ml.
p
78.12 kg es el peso promedio de la muestra de varones adultos que se está
a
La ordenada al origen indica que, hipotéticamente un varón adulto que pesara
0 kg, tendría un nivel de glucosa en la sangre de 21.03 mg/100ml, aunque
debemos observar que el peso de los varones adulto
e
El coeficiente de regresión indica que, por cada kilogramo de peso que
aumente un varón, su nivel de glucosa se incrementa
d
Para un varón adulto que tenga un peso de 80.0 kg, podríamos estimar su
nivel de glucosa, sustit
re
Con base en el coeficiente de regresión, también podríamos decir, que si el
varón con 80.0 kg de peso tiene un nivel de glucosa estimado o pronosticado
de 102.62 mg/100ml, otro varón con 81.0 kg de pe
g
XY 02.103.21' + =
62.10258.8103.21)0.80(02.103.21' =+=+=Y

Universidad Nacional Autónoma de México Facultad de Estudios Superiores Cuautitlán
¿Cómo trazar la recta de regresión en el diagrama de dispersión?
Para dibujar una línea recta, sólo
necesitamos las coordenadas de dos
puntos, las cuales se pueden obtener
substituyendo dos valores
(cualesquiera, de preferencia dentro del
rango de los valores originales) de la
variable independiente X o abscisas, en
la ecuación de regresión y obteniendo
dos valores estimados de Y’ u ordenadas. Dibujando estos dos puntos en el
diagrama de dispersión, se puede fácilmente trazar la recta de regresión.
http://www.cuautitlan.unam.mx Regresión Lineal Simple
Es conveniente indicar que el punto de coordenadas P(0,a) de la intersección de la recta con el eje Y, y el punto de coordenadas P( ),( YX de las medias de
las dos variables, pertenecen a la recta de regresión.
En nuestro ejemplo, para trazar la recta
de regresión debemos saber que contamos
con los siguientes puntos que pertenecen
a la recta:
El punto P(0, 21.03) correspondiente a la
intersección de la recta con el eje Y de la
variable dependiente (nivel de glucosa en
la sangre), y el punto P(78.12, 100.7) correspondiente a las medias de las dos
variables, pertenecen a la recta de regresión
. XY 02.103.21' +=
Podemos encontrar dos puntos dentro del rango experimental, sustituyendo
por ejemplo los valores de 60.0 y 100.0 kg de peso en la ecuación de la recta
de regresión
mlmgY 100/22.82)0.60(02.103.21' =+= mlmgY 100/01.123)0.100(02.103.21' =+=
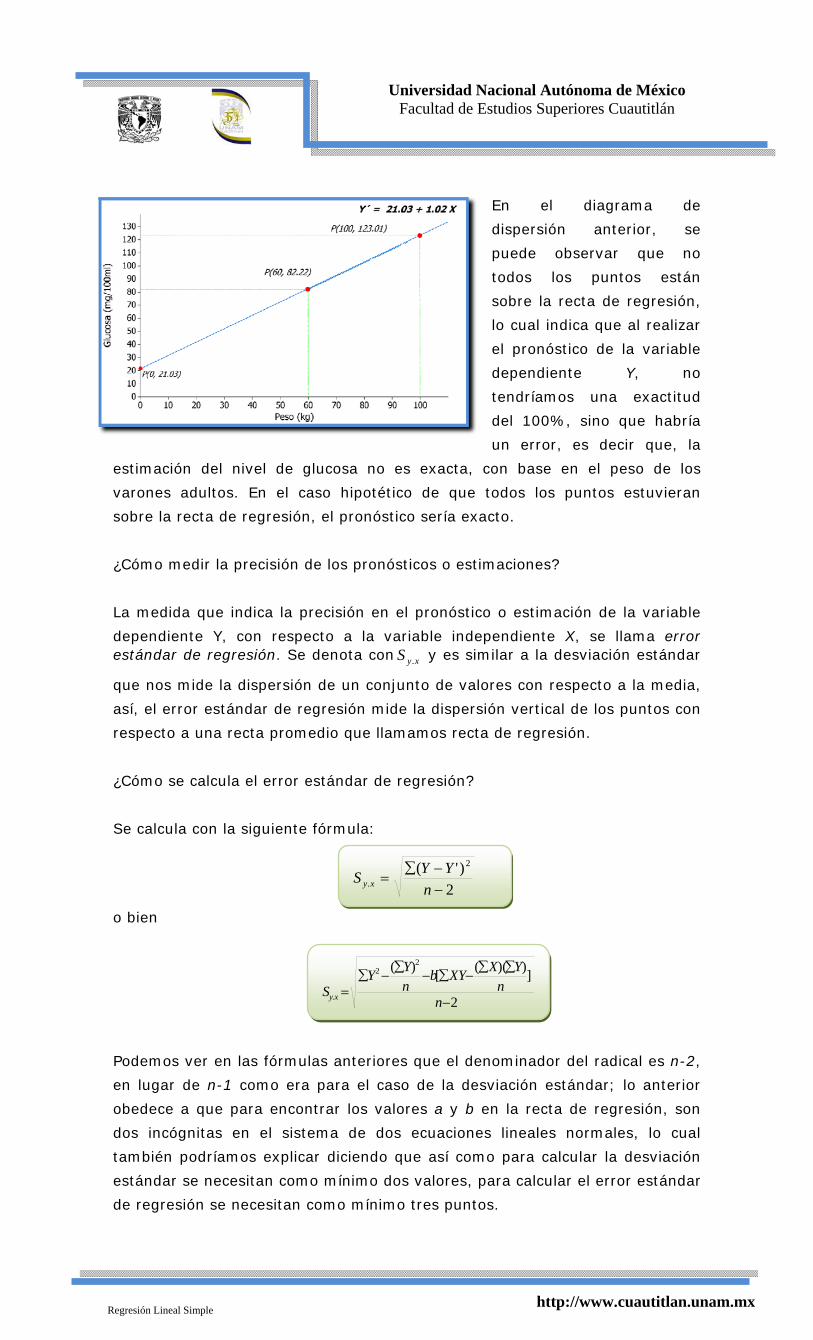
Por lo que, por los puntos P(60.0, 82.22) y P(100.0, 123.01) se puede trazar la
recta de regresión
Universidad Nacional Autónoma de México Facultad de Estudios Superiores Cuautitlán
En el diagrama de
dispersión anterior, se
puede observar que no
todos los puntos están
sobre la recta de regresión,
lo cual indica que al realizar
el pronóstico de la variable
dependiente Y, no
tendríamos una exactitud
del 100%, sino que habría
un error, es decir que, la
estimación del nivel de glucosa no es exacta, con base en el peso de los
varones adultos. En el caso hipotético de que todos los puntos estuvieran
sobre la recta de regresión, el pronóstico sería exacto.
¿Cómo medir la precisión de los pronósticos o estimaciones?
La medida que indica la precisión en el pronóstico o estimación de la variable
dependiente Y, con respecto a la variable independiente X, se llama error estándar de regresión. Se denota con y es similar a la desviación estándar
que nos mide la dispersión de un conjunto de valores con respecto a la media,
así, el error estándar de regresión mide la dispersión vertical de los puntos con
respecto a una recta promedio que llamamos recta de regresión.
xyS .
¿Cómo se calcula el error estándar de regresión?
Se calcula con la siguiente fórmula:
o bien
2)'( 2
. −−∑
=n
YYS xy
2
]))(([)( 22
. −
∑∑−∑−
∑−∑
=n
nYXXYb
nYY
S xy
Podemos ver en las fórmulas anteriores que el denominador del radical es n-2,
en lugar de n-1 como era para el caso de la desviación estándar; lo anterior
obedece a que para encontrar los valores a y b en la recta de regresión, son
dos incógnitas en el sistema de dos ecuaciones lineales normales, lo cual
también podríamos explicar diciendo que así como para calcular la desviación
estándar se necesitan como mínimo dos valores, para calcular el error estándar
de regresión se necesitan como mínimo tres puntos.
http://www.cuautitlan.unam.mx Regresión Lineal Simple

Universidad Nacional Autónoma de México Facultad de Estudios Superiores Cuautitlán
Para calcular el error estándar de regresión en nuestro ejemplo, de acuerdo a
la primer fórmula, debemos calcular los residuos, es decir, las distancias o
desviaciones verticales entre los valores observados del nivel de glucosa en la
sangre (Y) y los correspondientes valores estimados (Y’); por el método de
mínimos cuadrados, la suma de estos residuos debe ser igual a cero, es decir ; reiterando que se puede hacer fácilmente con los paquetes de
software estadístico, lo hacemos en la siguiente tabla
0)'( =−∑ YY
X Y Y’ Y-Y’ (Y-Y’)2
64.7 98 87.01 10.99 120.686575.3 109 97.82 11.18 124.899473.0 88 95.48 -7.48 55.9297 82.1 107 104.76 2.24 5.0229 76.2 93 98.74 -5.74 32.9703 95.7 121 118.63 2.37 5.6258 59.4 79 81.61 -2.61 6.8085 93.4 118 116.28 1.72 2.9496 82.5 109 105.17 3.83 14.6939 78.9 85 101.50 -16.50 272.0997
781.2 1,007 0.00 641.6864
Calculamos el error estándar muestral, con las dos fórmulas
96.82108.8086864.641
2106864.641
. ===−
=xyS
o bien
8)26.169,1(02.11.834,1
210
]10
)007,1)(2.781(1.836,79[02.110
)007,1(239,1032
.−
=−
−−−=xyS
96.82108.8086864.641
84136.192,11.834,1
. ===−
=xyS
El error estándar de regresión tiene un valor de 8.96 mg/100ml
Relación entre coeficiente de correlación y el error estándar de regresión:
Cuando en el diagrama de dispersión, los puntos están muy cerca de la recta
de regresión, podemos afirmar que la intensidad de la relación entre las dos
variables es fuerte, es decir, que el coeficiente de correlación (r) es muy
cercano a , pero también podemos decir que el error estándar de regresión ( ) es casi cero; por el contrario, cuando la relación entre dos
variables es nula, los puntos en el diagrama están totalmente dispersos con respecto a la recta de regresión, lo que conlleva que
00.1±xyS .
0=r y que . ∞=xyS .
http://www.cuautitlan.unam.mx Regresión Lineal Simple

Universidad Nacional Autónoma de México Facultad de Estudios Superiores Cuautitlán
¿Cuáles son los supuestos básicos para la regresión lineal?
El análisis de la regresión lineal, se sustenta en que se cumplan o satisfagan
los siguientes supuestos:
http://www.cuautitlan.unam.mx Regresión Lineal Simple
1. Para cada valor de la variable
independiente X, existe un conjunto
de valores Y, que tienen distribución
normal. Se le conoce como supuesto
de normalidad; si la distribución sólo
es aproximadamente normal, para el
análisis de regresión se puede decir
que se satisface el supuesto.
2. Las medias ( ) de las distribuciones normales de valores Y, se
encuentran todas en la recta de regresión. Se le conoce como supuesto
de linealidad.
xy /μ
3. Las desviaciones estándares ( ) de dichas distribuciones normales, ahora representadas por el error estándar de regresión ( ), son
iguales. Se le conoce como supuesto de homoscedasticidad; este
supuesto es importante que se cumpla para el uso del método de
mínimos cuadrados.
σxyS .
4. Para cada valor de la variable independiente X, se presenta un error, es
decir, la distancia o desviación vertical entre un valor observado Y y su
correspondiente valor pronosticado o estimado Y’; es necesario que se
cumpla la suposición de que estos errores sean independientes para
cada valor de X; se le conoce como supuesto de independencia de error.
Si las distribuciones de los valores Y para cada valor de X son
aproximadamente normales, entonces existen las mismas relaciones que tienen los valores de y en la distribución normal, es decir, con una
muestra suficientemente grande, aproximadamente:
μ σ
• abarca o comprende el 68.26% centrado de los valores
observados.
xySY .1'±
• abarca o comprende el 95.44% centrado de los valores
observados.
xySY .2'±
• abarca o comprende el 99.74% centrado de los valores
observados.
xySY .3'±

Universidad Nacional Autónoma de México Facultad de Estudios Superiores Cuautitlán
En nuestro ejemplo, si tomamos un varón adulto de X=75.0 kg de peso y
estimamos su nivel de glucosa en la sangre con
mlmgY 100/52.9749.7603.21)0.75(02.103.21' =+=+=
Entonces:
Entre mlmgyentredecires 100/47.10656.88,,96.852.97)96.8(152.97 ±=± de
nivel de glucosa en la sangre, se encuentra el 68.26% centrado, de los varones
con 75.0 kg de peso.
Entre mlmgyentredecires 100/43.11561.79,,91.1752.97)96.8(252.97 ±=± de
nivel de glucosa en la sangre, se encuentra el 95.44% centrado, de los varones
con 75.0 kg de peso.
Entre mlmgyentredecires 100/39.12465.70,,87.2652.97)96.8(352.97 ±=± de
nivel de glucosa en la sangre, se encuentra el 99.74% centrado, de los varones
con 75.0 kg de peso.
Casi todas las variables independientes que se han estudiado, son de tipo
cuantitativo, es decir, proporcionan valores numéricos de medición, pero en el
análisis de regresión a veces es necesario utilizar como variables
independientes, las que son de tipo cualitativo, es decir que sus valores son
categorías que proporcionan el concepto de atributo, como por ejemplo el
sexo, la nacionalidad, el grupo racial, la profesión u ocupación, la zona de
residencia, etc.
Para utilizar una variable independiente cualitativa en el análisis de regresión,
ésta debe tener la posibilidad de ser cuantificada, lo anterior puede lograrse
utilizando una variable ficticia.
¿Qué es una variable ficticia?
Es una variable que solo toma un número finito de valores enteros positivos
(incluyendo a veces al cero), para identificar las diferentes categorías de una
variable cualitativa.
Como por ejemplo: Variable
Cualitativa Variable Ficticia
Sexo X
Masculino 0 Femenino 1
http://www.cuautitlan.unam.mx Regresión Lineal Simple

Universidad Nacional Autónoma de México Facultad de Estudios Superiores Cuautitlán
Cuando la variable independiente cualitativa
es el tiempo (hora, día, mes, año, etc.), al
análisis de regresión respectivo, se le llama
análisis de series de tiempo. Al dibujar el
diagrama de dispersión, se acostumbra unir
los puntos con una línea quebrada, ya que los
valores del tiempo como variable cualitativa,
están equidistantes
Tomemos como ejemplo las ventas mensuales (en miles de pesos) de una
empresa como la variable dependiente, durante el periodo de agosto de 2005 a
julio de 2006; este periodo de tiempo sería la variable independiente
cualitativa, que transformamos en una variable ficticia en la siguiente tabla:
Variable
independiente cualitativa
Variableficticia
Variable dependiente
(ventas)
Mes X Y X2 XY Y2
Agosto 1 486 1 486 236,196 Septiembre 2 626 4 1,252 391,876 Octubre 3 630 9 1,890 396,900 Noviembre 4 809 16 3,236 654,481 Diciembre 5 925 25 4,625 855,625 Enero 6 546 36 3,276 298,116 Febrero 7 870 49 4,350 756,900 Marzo 8 368 64 2,944 135,424 Abril 9 426 81 3,834 181,476 Mayo 10 694 100 6,940 481,636 Junio 11 523 121 5,753 273,529 Julio 12 562 144 6,744 315,844 78 7,465 650 45,330 4,978,003
Primero calculamos la recta de regresión
33.22
716,1310,38
)78()650(12)465,7)(78()330,45(12
2 −=−
=−
−=b
http://www.cuautitlan.unam.mx Regresión Lineal Simple
20.7675.6)33.22(08.622
1278)33.22(
12465,7
=−−=−−=a
por lo que la ecuación de la recta de regresión queda como:
XY 33.2220.767' −=
Podemos pronosticar las ventas para diciembre de 2006, con el valor ficticio de
X=17 y sustituyéndolo en la ecuación de regresión
pesosdemilesY 67.387)17(33.2220.767' =−=

Universidad Nacional Autónoma de México Facultad de Estudios Superiores Cuautitlán
Esta estimación puede no ser muy exacta pues tenemos un error que puede
ser muy grande.
Calculemos ahora el error estándar de regresión y los coeficientes de
correlación, determinación y no determinación:
212
]12
)465,7)(78(330,45)[33.22(12
)465,7(003,978,42
. −
−−−−=xyS
1080.877,262
1012.273,7192.150,334
10)50.192,3)(33.22(92.150,334
. =−
=−−−
=xyS
pesosdemilesS xy 14.16278.287,26. ==
7868.02133.0112133.0)4618.0(
4618.080.950,82
310,38676,835,880,6
310,38
)811,009,4)(716,1(310,38
])465,7()003,978,4(12][)78()650(12[)465,7)(78()330,45(12
2
22
22
=−=−
=−=
−=−
=−
=
−=
−−
−=
rr
r
r
Lo que indica que sólo el 21.33% de la variación en las ventas, está explicado
por la variación en el tiempo, en tanto que el 78.68% muchísima variación no
está explicada, es decir que el coeficiente de correlación indica un grado de
intensidad débil entre las dos variables.
TRANSFORMACIONES
Cuando al analizar un diagrama de dispersión encontramos que los puntos no
están mas o menos en una tendencia lineal, sino que sería una curva la que
mejor se ajustaría a los puntos observados, entonces, si equivocadamente
insistimos en medir la correlación lineal entre X y Y, y encontrar la recta de
regresión para pronosticar los valores de la variable dependiente Y con
respecto a la variable independiente X, vamos a encontrar un valor de r moderado o débil, es decir cercano a cero y un valor de muy grande, lo
que nos indicaría que es incorrecto el pronóstico que deseamos hacer de la
variable dependiente Y.
xyS .
http://www.cuautitlan.unam.mx Regresión Lineal Simple

Universidad Nacional Autónoma de México Facultad de Estudios Superiores Cuautitlán
Para evitar que suceda lo mencionado en el párrafo anterior, se puede realizar
el análisis de dos formas:
1. Transformaciones de curvas no lineales a rectas de regresión.
2. Correlación y regresión polinomial, que se aplica cuando no se conoce la
forma funcional exacta de la curva de regresión y un polinomio de grado
n sirve para ajustar la curva y pronosticar el valor de la variable dependiente Y; el polinomio es npXdXcXbXaY +++++= 32'
(Este tema se abordará en otro fascículo). Transformaciones de curvas no lineales a rectas de regresión.
Si en el diagrama de dispersión cambiamos uno o los dos ejes por una escala
de transformación adecuada, podemos observar que se enderezan (por así
decirlo) los puntos y podemos realizar el análisis como si le ajustáramos una
recta de regresión y calculáramos una correlación lineal.
Para poder presentar los resultados en forma adecuada, debemos deshacer las
transformaciones realizadas, quedando valores y unidades de medida en la
forma original.
Algunos ejemplos de transformación, son los siguientes:
Función exponencial.
La función que representa los datos originales de las
variables es Función exponencial
XBAY •=
Si tomamos logaritmos decimales o naturales, la
función transformada queda como una función lineal
en X
BXAY logloglog +=
Los valores originales de la variable dependiente Y,
quedan transformados a
Ylog
http://www.cuautitlan.unam.mx Regresión Lineal Simple

Universidad Nacional Autónoma de México Facultad de Estudios Superiores Cuautitlán
Función recíproca.
La función que representa los datos originales de las variables es
BXA
Y+
=1
Si tomamos el inverso en ambos miembros de la ecuación, la función
transformada queda como una función lineal en X
http://www.cuautitlan.unam.mx Regresión Lineal Simple
BXAY
+=1
Los valores originales de la variable dependiente Y, quedan transformados a
Y1
Función de potencia.
La función que representa los datos originales de las variables es
BXAY •=
Si tomamos logaritmos decimales o naturales, la función transformada queda
como una función lineal en X
XBAY logloglog +=
Los valores originales de la variable independiente X, quedan transformados a
Xlog
Y los valores originales de la variable dependiente Y, quedan transformados a
Ylog
Por ejemplo, consideremos como variable independiente X a los miles de km
de recorrido de una llanta radial para automóvil compacto y como variable
dependiente Y al porcentaje de vida útil que aún le queda a la llanta.
Dibujando el diagrama de dispersión, observamos que los puntos se acomodan
aproximadamente en una forma exponencial, es decir que se ajustaría una
curva exponencial con ecuación XBAY •=

Universidad Nacional Autónoma de México Facultad de Estudios Superiores Cuautitlán
Si dibujamos el diagrama de dispersión,
cambiando el eje Y por el eje Z = logY,
podemos observar que los puntos se
“enderezan” y es factible encontrar una recta
de regresión cuya ecuación será:
http://www.cuautitlan.unam.mx Regresión Lineal Simple
b
a
Z
BBbAAaYYZdondebXaZ
10log10log10log
'
==
==
==
+=
Realizamos los cálculos del método de mínimos cuadrados, utilizando la
siguiente tabla:
X Y Z=logY X2 XZ Z2
1 98.2 1.9921 1 1.9921 3.9685 2 91.7 1.9624 4 3.9247 3.8509 5 81.3 1.9101 25 9.5505 3.6484 10 64.0 1.8062 100 18.0618 3.2623 20 36.4 1.5611 400 31.2220 2.4370 30 32.6 1.5132 900 45.3965 2.2898 40 17.1 1.2330 1,600 49.3198 1.5203 50 11.3 1.0531 2,500 52.6539 1.1090 158 13.0311 5,530 212.1214 22.0863
2
8(212.1214) (158)(13.0311) 361.9495 0.01888(5,530) (158) 19,276
b − −= =
−= −
13.0311 158( 0.0188) 1.6289 ( 0.0188)19.75 1.6298 0.3708 1.99978 8
a = − − = − − = + =
la ecuación transformada queda
' 1.9997 0.0188Z X= −

Universidad Nacional Autónoma de México Facultad de Estudios Superiores Cuautitlán
y la ecuación original en forma exponencial queda como:
por lo que
' 99.94(0.96)XY =
1.9997 0.018810 99.94 10 0.96A y B −= = = =
Si deseamos pronosticar el valor del porcentaje de vida útil Y’, para una llanta
radial que lleve recorridos 65,300 km por ejemplo, podemos sustituir el valor
de X=65.3 en cualquiera de las dos ecuaciones de regresión anteriores:
' 1.9997 0.0188(65.3) 1.9997 1.2262 0.7736Z = − = − =
Por lo que queda
0.7736' 10 5.94 %Y = = de vida útil
o también puede calcular
65.3' 99.94(0.96) 5.94 %Y = = de vida útil
El error estándar de regresión queda como:
útilvidadeS
S
S
xy
xz
xz
%10.1
0416.00017.06
0104.06
8496.08599.06
)2437.45)(0188.0(8599.028
]8
)0311.13)(158(1214.212)[0188.0(8
)0311.13(0863.22
.
.
2
.
=
===−
=−−−
=
−
−−−−=
que es un valor pequeño, porqué los puntos están muy cerca de la línea recta.
Los coeficientes de correlación, determinación y no determinación se calculan
como:
0120.09880.0119880.0)9940.0(
9940.01497.3649495.361
0197.605,1329495.361
)8793.6)(276,19(9495.361
])0311.13()0863.22(8][)158()530,5(8[)0311.13)(158()1214.212(8
222
22
=−=−==
−=−
=−
=
−=
−−
−=
rr
r
r
http://www.cuautitlan.unam.mx Regresión Lineal Simple

Universidad Nacional Autónoma de México Facultad de Estudios Superiores Cuautitlán
http://www.cuautitlan.unam.mx Regresión Lineal Simple
Lo que nos indica un grado de intensidad muy
fuerte para la relación entre los km recorridos de
una llanta radial y su porcentaje de vida útil, ya
que podemos afirmar que el 98.80% de la
variación en el porcentaje de vida útil, está
explicado por la variación en los km recorridos.
Para concluir, se puede mencionar que también
existe la correlación y regresión lineal múltiple
(se tratará en otro fascículo), en la cual podemos
incluir dos o más variables aleatorias
independientes y entonces medir el grado de
intensidad de relación entre tres o más variables, mediante la correlación
múltiple lineal, y tratar de pronosticar el valor de la variable dependiente Y,
para valores específicos de las diferentes variables independientes, con la
regresión múltiple lineal; lo anterior mediante la ecuación:
.
kk XbXbXbXbaY +++++= 332211'