reducing energy usage through a novel file synchronization
TRANSCRIPT

Reducing Energy Usage Through a Novel FileSynchronization Algorithm
Frederic SalaLORIS Lab, UCLA
Joint work with:Nicolas Bitouze (UCLA)Clayton Schoeny (UCLA),
S. M. Sadegh Tabatabaei Yazdi (Qualcomm),Lara Dolecek (UCLA)
Laboratory for Robust Information Systems (LORIS)Department of Electrical Engineering, UCLA
1 / 23

Motivation
Combined data center electricity usage is already at 1.5% of allelectricity used in the world.
J. Koomey, “Growth in data center electricity use 2005 to2010”, 2011.
A major contributing factor: large data storage requirements. Inpart, these requirements are due to the unnecessary storage ofsuperfluous data:
Multiple copies of the same file.
Multiple versions of a file.
2 / 23

Motivation
Combined data center electricity usage is already at 1.5% of allelectricity used in the world.
J. Koomey, “Growth in data center electricity use 2005 to2010”, 2011.
A major contributing factor: large data storage requirements. Inpart, these requirements are due to the unnecessary storage ofsuperfluous data:
Multiple copies of the same file.
Multiple versions of a file.
2 / 23

Motivation
Combined data center electricity usage is already at 1.5% of allelectricity used in the world.
J. Koomey, “Growth in data center electricity use 2005 to2010”, 2011.
A major contributing factor: large data storage requirements. Inpart, these requirements are due to the unnecessary storage ofsuperfluous data:
Multiple copies of the same file.
Multiple versions of a file.
2 / 23

Reducing Data Storage Demand
When files are identical, we can use deduplication tools.
What if files are similar, but not identical?
We need algorithms to synchronize multiple versions of a file.
Existing algorithms, such as RSYNC, su↵er from highcommunication costs.
Goal: Develop a more e�cient synchronization algorithm.
3 / 23

Reducing Data Storage Demand
When files are identical, we can use deduplication tools.
What if files are similar, but not identical?
We need algorithms to synchronize multiple versions of a file.
Existing algorithms, such as RSYNC, su↵er from highcommunication costs.
Goal: Develop a more e�cient synchronization algorithm.
3 / 23

Reducing Data Storage Demand
When files are identical, we can use deduplication tools.
What if files are similar, but not identical?
Synchronization from Insertions and DeletionsUnder a Non-Binary, Non-Uniform Source
Nicolas Bitouze and Lara DolecekElectrical Engineering Department
University of California, Los AngelesLos Angeles, USA
Email: [email protected], [email protected]
Abstract—We study the problem of synchronizing two files Xand Y at two distant nodes A and B that are connected through a
two-way communication channel. We assume that file Y at node
B is obtained from file X at node A by inserting and deleting
a small fraction of symbols in X . More specifically, we consider
the case where X is a non-binary non-uniform string, and
deletions and insertions happen uniformly with rates �d and �i,
respectively. We propose a synchronization protocol between node
A and node B that needs to transmit O(CX(�d+�i)n log
1�d+�i
)
bits (where n is the length of X and CX is a constant that depends
on the statistical properties of X) and reconstructs X at node
B with error probability exponentially low in n. This protocol
readily generalizes the recent result by Tabatabaei Yazdi and
Dolecek that dealt with synchronization from binary uniform
source and under only deletion errors.
I. INTRODUCTIONMotivated by the pervasive use of file synchronization in
modern data storage technologies, in this work we seek todevelop a synchronization protocol that is more efficient thanthe existing algorithms. In particular, the popular RSYNCmethod can be in general very inefficient and the number oftransmitted bits can be exponentially larger than the optimalnumber.
Our starting point is an information-theoretically orientedscheme recently developed in [1]. In [1], a synchronizationprotocol that synchronizes an altered copy of the binary filewith the original version of the file was proposed. In thisscheme, the owner of the altered file requests additionalinformation from the owner of the original file to ensure propersynchronization. It was assumed that the altered copy wasobtained from the original copy by i.i.d. deletions at the bit-level and that the original file was generated from an i.i.d.uniform binary source. It was then shown that the rate of theproposed scheme asymptotically matches the optimal rate forthis channel, developed earlier in [2]. That is, in the scheme of[1], the number of bits needed to synchronize two files can bekept very small while achieving exponentially low probabilityof error.
There are many practical scenarios where the files cannotbe modeled as binary and uniform. For example, a file isusually not structured by bits, but by bytes or by even longeratomic elements. If the source is a text file, not only aresome characters more frequent than others, but there is a largeautocorrelation within the file. Additionally, some symbolsmay be inserted as well as deleted. As a result, our objective
is to suitably generalize the scheme in [1], while maintaininglow cost of transmission and low error of mis-synchronization.
Specifically, our model encapsulates the following general-izations of the model in [1]:
1) We consider errors as being insertions or deletions insteadof being restricted to deletions only,
2) We consider non-binary source symbols,3) We allow the source symbols to have an arbitrary distri-
bution; uniform distribution is then a special case.The rest of the paper is organized as follows. In Section II
we outline the overall synchronization protocol. Necessarynotation and background results are presented in Section III.Two key components of our synchronization protocol, thematching module and the edit recovery module, are discussedin detail in Sections IV and V, respectively. Section VIconcludes the paper.
II. THE SYNCHRONIZATION PROTOCOLIn [1], the following setup is considered: two distant nodes
A and B are connected by a low-bandwidth high-latencynetwork. A contains a file X which is a uniform i.i.d. binarystring of length n, and B contains a file Y of length n0 that isobtained by deleting bits of X independently with probability� ⌧ 1.
We consider a generalized setting in which the file X =
X1
, . . . , Xn is i.i.d. on alphabet X = {0, . . . , Q � 1}, wherefor all 1 t n, Xt’s are distributed according to µ(x). Forsimplicity, we consider Q to be a power of two, say Q = 2
q .Insertions and deletions occur respectively with probability �i
and �d. Let us define an edit pattern E = E1
, . . . , En as astring in {�1, 0, 1}n such that Y is obtained from X in thefollowing way: for t from 1 to n,
• if Et = 0, transmit Xt,• if Et = �1, delete (do not transmit) Xt,• if Et = 1, transmit Xt, then insert (transmit) a new
symbol of X drawn with distribution µ(x).For instance, consider X and Y defined over a quaternary
alphabet, X = 00
D122133
D10 and Y = 0120
I23
I10
I310. Here
Y is derived from X by 2 deletions and 3 insertions wheredeleted (inserted) symbols are denoted by D (I). The editpattern is thus E = (0,�1, 0, 1, 1, 1, 0,�1, 0, 0). Node Baims to synchronize its file Y with the (original) file X byrequesting carefully chosen additional information from A
We need algorithms to synchronize multiple versions of a file.
Existing algorithms, such as RSYNC, su↵er from highcommunication costs.
Goal: Develop a more e�cient synchronization algorithm.
3 / 23

Reducing Data Storage Demand
When files are identical, we can use deduplication tools.
What if files are similar, but not identical?
Synchronization from Insertions and DeletionsUnder a Non-Binary, Non-Uniform Source
Nicolas Bitouze and Lara DolecekElectrical Engineering Department
University of California, Los AngelesLos Angeles, USA
Email: [email protected], [email protected]
Abstract—We study the problem of synchronizing two files Xand Y at two distant nodes A and B that are connected through a
two-way communication channel. We assume that file Y at node
B is obtained from file X at node A by inserting and deleting
a small fraction of symbols in X . More specifically, we consider
the case where X is a non-binary non-uniform string, and
deletions and insertions happen uniformly with rates �d and �i,
respectively. We propose a synchronization protocol between node
A and node B that needs to transmit O(CX(�d+�i)n log
1�d+�i
)
bits (where n is the length of X and CX is a constant that depends
on the statistical properties of X) and reconstructs X at node
B with error probability exponentially low in n. This protocol
readily generalizes the recent result by Tabatabaei Yazdi and
Dolecek that dealt with synchronization from binary uniform
source and under only deletion errors.
I. INTRODUCTIONMotivated by the pervasive use of file synchronization in
modern data storage technologies, in this work we seek todevelop a synchronization protocol that is more efficient thanthe existing algorithms. In particular, the popular RSYNCmethod can be in general very inefficient and the number oftransmitted bits can be exponentially larger than the optimalnumber.
Our starting point is an information-theoretically orientedscheme recently developed in [1]. In [1], a synchronizationprotocol that synchronizes an altered copy of the binary filewith the original version of the file was proposed. In thisscheme, the owner of the altered file requests additionalinformation from the owner of the original file to ensure propersynchronization. It was assumed that the altered copy wasobtained from the original copy by i.i.d. deletions at the bit-level and that the original file was generated from an i.i.d.uniform binary source. It was then shown that the rate of theproposed scheme asymptotically matches the optimal rate forthis channel, developed earlier in [2]. That is, in the scheme of[1], the number of bits needed to synchronize two files can bekept very small while achieving exponentially low probabilityof error.
There are many practical scenarios where the files cannotbe modeled as binary and uniform. For example, a file isusually not structured by bits, but by bytes or by even longeratomic elements. If the source is a text file, not only aresome characters more frequent than others, but there is a largeautocorrelation within the file. Additionally, some symbolsmay be inserted as well as deleted. As a result, our objective
is to suitably generalize the scheme in [1], while maintaininglow cost of transmission and low error of mis-synchronization.
Specifically, our model encapsulates the following general-izations of the model in [1]:
1) We consider errors as being insertions or deletions insteadof being restricted to deletions only,
2) We consider non-binary source symbols,3) We allow the source symbols to have an arbitrary distri-
bution; uniform distribution is then a special case.The rest of the paper is organized as follows. In Section II
we outline the overall synchronization protocol. Necessarynotation and background results are presented in Section III.Two key components of our synchronization protocol, thematching module and the edit recovery module, are discussedin detail in Sections IV and V, respectively. Section VIconcludes the paper.
II. THE SYNCHRONIZATION PROTOCOLIn [1], the following setup is considered: two distant nodes
A and B are connected by a low-bandwidth high-latencynetwork. A contains a file X which is a uniform i.i.d. binarystring of length n, and B contains a file Y of length n0 that isobtained by deleting bits of X independently with probability� ⌧ 1.
We consider a generalized setting in which the file X =
X1
, . . . , Xn is i.i.d. on alphabet X = {0, . . . , Q � 1}, wherefor all 1 t n, Xt’s are distributed according to µ(x). Forsimplicity, we consider Q to be a power of two, say Q = 2
q .Insertions and deletions occur respectively with probability �i
and �d. Let us define an edit pattern E = E1
, . . . , En as astring in {�1, 0, 1}n such that Y is obtained from X in thefollowing way: for t from 1 to n,
• if Et = 0, transmit Xt,• if Et = �1, delete (do not transmit) Xt,• if Et = 1, transmit Xt, then insert (transmit) a new
symbol of X drawn with distribution µ(x).For instance, consider X and Y defined over a quaternary
alphabet, X = 00
D122133
D10 and Y = 0120
I23
I10
I310. Here
Y is derived from X by 2 deletions and 3 insertions wheredeleted (inserted) symbols are denoted by D (I). The editpattern is thus E = (0,�1, 0, 1, 1, 1, 0,�1, 0, 0). Node Baims to synchronize its file Y with the (original) file X byrequesting carefully chosen additional information from A
Synchronization from Insertions and DeletionsUnder a Non-Binary, Non-Uniform Source
Nicolas Bitouze and Lara DolecekElectrical Engineering Department
University of California, Los AngelesLos Angeles, USA
Email: [email protected], [email protected]
Abstract—We study the problem of synchronizing two files Xand Y at two distant nodes A and B that are connected through a
two-way communication channel. We assume that file Y at node
B is obtained from file X at node A by inserting and deleting
a small fraction of symbols in X . More specifically, we consider
the case where X is a non-binary non-uniform string, and
deletions and insertions happen uniformly with rates �d and �i,
respectively. We propose a synchronization protocol between node
A and node B that needs to transmit O(CX(�d+�i)n log
1�d+�i
)
bits (where n is the length of X and CX is a constant that depends
on the statistical properties of X) and reconstructs X at node
B with error probability exponentially low in n. This protocol
readily generalizes the recent result by Tabatabaei Yazdi and
Dolecek that dealt with synchronization from binary uniform
source and under only deletion errors.
I. INTRODUCTION
Motivated by the pervasive use of file synchronization inmodern data storage technologies, in this work we seek todevelop a synchronization protocol that is more efficient thanthe existing algorithms. In particular, the popular RSYNCmethod can be in general very inefficient and the number oftransmitted bits can be exponentially larger than the optimalnumber.
Our starting point is an information-theoretically orientedscheme recently developed in [1]. In [1], a synchronizationprotocol that synchronizes an altered copy of the binary filewith the original version of the file was proposed. In thisscheme, the owner of the altered file requests additionalinformation from the owner of the original file to ensure propersynchronization. It was assumed that the altered copy wasobtained from the original copy by i.i.d. deletions at the bit-level and that the original file was generated from an i.i.d.uniform binary source. It was then shown that the rate of theproposed scheme asymptotically matches the optimal rate forthis channel, developed earlier in [2]. That is, in the schemeof [1], the number of bits needed to synchronize two files canbe kept very small while achieving exponentially low error ofmis-synchronization.
There are many practical scenarios where the files cannotbe modeled as binary and uniform. For example, a file isusually not structured by bits, but by bytes or by even longeratomic elements. If the source is a text file, not only aresome characters more frequent than others, but there is a largeautocorrelation within the file. Additionally, some symbolsmay be inserted as well as deleted. As a result, our objective
is to suitably generalize the scheme in [1], while maintaininglow cost of transmission and low error of mis-synchronization.
Specifically, our model encapsulates the following general-izations of the model in [1]:
1) We consider errors as being insertions or deletions insteadof being restricted to deletions only,
2) We consider non-binary source symbols,3) We allow the source symbols to have an arbitrary distri-
bution; uniform distribution is then a special case.The rest of the paper is organized as follows. In Section II
we outline the overall synchronization protocol. Necessarynotation and background results are presented in Section III.Two key components of our synchronization protocol, thematching module and the edit recovery module, are discussedin detail in Sections IV and V, respectively. Section VIconcludes the paper.
II. THE SYNCHRONIZATION PROTOCOLIn [1], the following setup is considered: two distant nodes
A and B are connected by a low-bandwidth high-latencynetwork. A contains a file X which is a uniform i.i.d. binarystring of length n, and B contains a file Y of length n0 that isobtained by deleting bits of X independently with probability� ⌧ 1.
We consider a generalized setting in which X =
X1
, . . . , Xn is an i.i.d. file on alphabet X = {0, . . . , Q� 1},where for all 1 t n, Xt’s are distributed accordingto µ(x). For simplicity, we consider Q to be a power oftwo, say Q = 2
q . Insertions and deletions occur respectivelywith probability �i and �d. Let us define an edit patternE = E
1
, . . . , En as a string in {�1, 0, 1}n such that Y isobtained from X in the following way: for t from 1 to n,
• if Et = 0, transmit Xt,• if Et = �1, delete (do not transmit) Xt,• if Et = 1, transmit Xt, then insert (transmit) a new
symbol of X drawn with distribution µ(x).For instance, consider X and Y defined over a quaternary
alphabet, X = 00
D122133
D10 and Y = 0120
I23
I10
I310. Here
Y is derived from X by 2 deletions and 3 insertions wheredeleted (inserted) symbols are denoted by D (I). The editpattern is thus E = (0,�1, 0, 1, 1, 1, 0,�1, 0, 0). Node Baims to synchronize its file Y with the (original) file X byrequesting carefully chosen additional information from A
We need algorithms to synchronize multiple versions of a file.
Existing algorithms, such as RSYNC, su↵er from highcommunication costs.
Goal: Develop a more e�cient synchronization algorithm.
3 / 23

Reducing Data Storage Demand
When files are identical, we can use deduplication tools.
What if files are similar, but not identical?
Synchronization from Insertions and DeletionsUnder a Non-Binary, Non-Uniform Source
Nicolas Bitouze and Lara DolecekElectrical Engineering Department
University of California, Los AngelesLos Angeles, USA
Email: [email protected], [email protected]
Abstract—We study the problem of synchronizing two files Xand Y at two distant nodes A and B that are connected through a
two-way communication channel. We assume that file Y at node
B is obtained from file X at node A by inserting and deleting
a small fraction of symbols in X . More specifically, we consider
the case where X is a non-binary non-uniform string, and
deletions and insertions happen uniformly with rates �d and �i,
respectively. We propose a synchronization protocol between node
A and node B that needs to transmit O(CX(�d+�i)n log
1�d+�i
)
bits (where n is the length of X and CX is a constant that depends
on the statistical properties of X) and reconstructs X at node
B with error probability exponentially low in n. This protocol
readily generalizes the recent result by Tabatabaei Yazdi and
Dolecek that dealt with synchronization from binary uniform
source and under only deletion errors.
I. INTRODUCTIONMotivated by the pervasive use of file synchronization in
modern data storage technologies, in this work we seek todevelop a synchronization protocol that is more efficient thanthe existing algorithms. In particular, the popular RSYNCmethod can be in general very inefficient and the number oftransmitted bits can be exponentially larger than the optimalnumber.
Our starting point is an information-theoretically orientedscheme recently developed in [1]. In [1], a synchronizationprotocol that synchronizes an altered copy of the binary filewith the original version of the file was proposed. In thisscheme, the owner of the altered file requests additionalinformation from the owner of the original file to ensure propersynchronization. It was assumed that the altered copy wasobtained from the original copy by i.i.d. deletions at the bit-level and that the original file was generated from an i.i.d.uniform binary source. It was then shown that the rate of theproposed scheme asymptotically matches the optimal rate forthis channel, developed earlier in [2]. That is, in the scheme of[1], the number of bits needed to synchronize two files can bekept very small while achieving exponentially low probabilityof error.
There are many practical scenarios where the files cannotbe modeled as binary and uniform. For example, a file isusually not structured by bits, but by bytes or by even longeratomic elements. If the source is a text file, not only aresome characters more frequent than others, but there is a largeautocorrelation within the file. Additionally, some symbolsmay be inserted as well as deleted. As a result, our objective
is to suitably generalize the scheme in [1], while maintaininglow cost of transmission and low error of mis-synchronization.
Specifically, our model encapsulates the following general-izations of the model in [1]:
1) We consider errors as being insertions or deletions insteadof being restricted to deletions only,
2) We consider non-binary source symbols,3) We allow the source symbols to have an arbitrary distri-
bution; uniform distribution is then a special case.The rest of the paper is organized as follows. In Section II
we outline the overall synchronization protocol. Necessarynotation and background results are presented in Section III.Two key components of our synchronization protocol, thematching module and the edit recovery module, are discussedin detail in Sections IV and V, respectively. Section VIconcludes the paper.
II. THE SYNCHRONIZATION PROTOCOLIn [1], the following setup is considered: two distant nodes
A and B are connected by a low-bandwidth high-latencynetwork. A contains a file X which is a uniform i.i.d. binarystring of length n, and B contains a file Y of length n0 that isobtained by deleting bits of X independently with probability� ⌧ 1.
We consider a generalized setting in which the file X =
X1
, . . . , Xn is i.i.d. on alphabet X = {0, . . . , Q � 1}, wherefor all 1 t n, Xt’s are distributed according to µ(x). Forsimplicity, we consider Q to be a power of two, say Q = 2
q .Insertions and deletions occur respectively with probability �i
and �d. Let us define an edit pattern E = E1
, . . . , En as astring in {�1, 0, 1}n such that Y is obtained from X in thefollowing way: for t from 1 to n,
• if Et = 0, transmit Xt,• if Et = �1, delete (do not transmit) Xt,• if Et = 1, transmit Xt, then insert (transmit) a new
symbol of X drawn with distribution µ(x).For instance, consider X and Y defined over a quaternary
alphabet, X = 00
D122133
D10 and Y = 0120
I23
I10
I310. Here
Y is derived from X by 2 deletions and 3 insertions wheredeleted (inserted) symbols are denoted by D (I). The editpattern is thus E = (0,�1, 0, 1, 1, 1, 0,�1, 0, 0). Node Baims to synchronize its file Y with the (original) file X byrequesting carefully chosen additional information from A
Synchronization from Insertions and DeletionsUnder a Non-Binary, Non-Uniform Source
Nicolas Bitouze and Lara DolecekElectrical Engineering Department
University of California, Los AngelesLos Angeles, USA
Email: [email protected], [email protected]
Abstract—We study the problem of synchronizing two files Xand Y at two distant nodes A and B that are connected through a
two-way communication channel. We assume that file Y at node
B is obtained from file X at node A by inserting and deleting
a small fraction of symbols in X . More specifically, we consider
the case where X is a non-binary non-uniform string, and
deletions and insertions happen uniformly with rates �d and �i,
respectively. We propose a synchronization protocol between node
A and node B that needs to transmit O(CX(�d+�i)n log
1�d+�i
)
bits (where n is the length of X and CX is a constant that depends
on the statistical properties of X) and reconstructs X at node
B with error probability exponentially low in n. This protocol
readily generalizes the recent result by Tabatabaei Yazdi and
Dolecek that dealt with synchronization from binary uniform
source and under only deletion errors.
I. INTRODUCTION
Motivated by the pervasive use of file synchronization inmodern data storage technologies, in this work we seek todevelop a synchronization protocol that is more efficient thanthe existing algorithms. In particular, the popular RSYNCmethod can be in general very inefficient and the number oftransmitted bits can be exponentially larger than the optimalnumber.
Our starting point is an information-theoretically orientedscheme recently developed in [1]. In [1], a synchronizationprotocol that synchronizes an altered copy of the binary filewith the original version of the file was proposed. In thisscheme, the owner of the altered file requests additionalinformation from the owner of the original file to ensure propersynchronization. It was assumed that the altered copy wasobtained from the original copy by i.i.d. deletions at the bit-level and that the original file was generated from an i.i.d.uniform binary source. It was then shown that the rate of theproposed scheme asymptotically matches the optimal rate forthis channel, developed earlier in [2]. That is, in the schemeof [1], the number of bits needed to synchronize two files canbe kept very small while achieving exponentially low error ofmis-synchronization.
There are many practical scenarios where the files cannotbe modeled as binary and uniform. For example, a file isusually not structured by bits, but by bytes or by even longeratomic elements. If the source is a text file, not only aresome characters more frequent than others, but there is a largeautocorrelation within the file. Additionally, some symbolsmay be inserted as well as deleted. As a result, our objective
is to suitably generalize the scheme in [1], while maintaininglow cost of transmission and low error of mis-synchronization.
Specifically, our model encapsulates the following general-izations of the model in [1]:
1) We consider errors as being insertions or deletions insteadof being restricted to deletions only,
2) We consider non-binary source symbols,3) We allow the source symbols to have an arbitrary distri-
bution; uniform distribution is then a special case.The rest of the paper is organized as follows. In Section II
we outline the overall synchronization protocol. Necessarynotation and background results are presented in Section III.Two key components of our synchronization protocol, thematching module and the edit recovery module, are discussedin detail in Sections IV and V, respectively. Section VIconcludes the paper.
II. THE SYNCHRONIZATION PROTOCOLIn [1], the following setup is considered: two distant nodes
A and B are connected by a low-bandwidth high-latencynetwork. A contains a file X which is a uniform i.i.d. binarystring of length n, and B contains a file Y of length n0 that isobtained by deleting bits of X independently with probability� ⌧ 1.
We consider a generalized setting in which X =
X1
, . . . , Xn is an i.i.d. file on alphabet X = {0, . . . , Q� 1},where for all 1 t n, Xt’s are distributed accordingto µ(x). For simplicity, we consider Q to be a power oftwo, say Q = 2
q . Insertions and deletions occur respectivelywith probability �i and �d. Let us define an edit patternE = E
1
, . . . , En as a string in {�1, 0, 1}n such that Y isobtained from X in the following way: for t from 1 to n,
• if Et = 0, transmit Xt,• if Et = �1, delete (do not transmit) Xt,• if Et = 1, transmit Xt, then insert (transmit) a new
symbol of X drawn with distribution µ(x).For instance, consider X and Y defined over a quaternary
alphabet, X = 00
D122133
D10 and Y = 0120
I23
I10
I310. Here
Y is derived from X by 2 deletions and 3 insertions wheredeleted (inserted) symbols are denoted by D (I). The editpattern is thus E = (0,�1, 0, 1, 1, 1, 0,�1, 0, 0). Node Baims to synchronize its file Y with the (original) file X byrequesting carefully chosen additional information from A
Synchronization from Insertions and DeletionsUnder a Non-Binary, Non-Uniform Source
Nicolas Bitouze and Lara DolecekElectrical Engineering Department
University of California, Los AngelesLos Angeles, USA
Email: [email protected], [email protected]
Abstract—We study the problem of synchronizing two files Xand Y at two distant nodes A and B that are connected through a
two-way communication channel. We assume that file Y at node
B is obtained from file X at node A by inserting and deleting
a small fraction of symbols in X . More specifically, we consider
the case where X is a non-binary non-uniform sequence, and
deletions and insertions happen uniformly with rates �d and �i,
respectively. We propose a synchronization protocol between node
A and node B that needs to transmit O(CX(�d+�i)n log
1�d+�i
)
bits (where n is the length of X and CX is a constant that depends
on the statistical properties of X) and reconstructs X at node
B with error probability exponentially low in n. This protocol
readily generalizes the recent result by Tabatabaei Yazdi and
Dolecek that dealt with synchronization from binary uniform
source and under only deletion errors.
I. INTRODUCTIONMotivated by the pervasive use of file synchronization in
modern data storage technologies, in this work we seek todevelop a synchronization protocol that is more efficient thanthe existing algorithms. In particular, the popular RSYNCmethod can be in general very inefficient and the number oftransmitted bits can be exponentially larger than the optimalnumber.
Our starting point is an information-theoretically orientedscheme recently developed in [1]. In [1], a synchronizationprotocol that synchronizes an altered copy of the binary filewith the original version of the file was proposed. In thisscheme, the owner of the altered file requests additionalinformation from the owner of the original file to ensure propersynchronization. It was assumed that the altered copy wasobtained from the original copy by i.i.d. deletions at the bit-level and that the original file was generated from an i.i.d.uniform binary source. It was then shown that the rate of theproposed scheme asymptotically matches the optimal rate forthis channel, developed earlier in [2]. That is, in the scheme of[1], the number of bits needed to synchronize two files can bekept very small while achieving exponentially low probabilityof error.
There are many practical scenarios where the files cannotbe modeled as binary and uniform. For example, a file isusually not structured by bits, but by bytes or by even longeratomic elements. If the source is a text file, not only aresome characters more frequent than others, but there is a largeautocorrelation within the file. Additionally, some symbolsmay be inserted as well as deleted. As a result, our objective
is to suitably generalize the scheme in [1], while maintaininglow cost of transmission and low error of mis-synchronization.
Specifically, our model encapsulates the following general-izations of the model in [1]:
1) We consider errors as being insertions or deletions insteadof being restricted to deletions only,
2) We consider non-binary source symbols,3) We allow the source symbols to have an arbitrary distri-
bution; uniform distribution is then a special case.The rest of the paper is organized as follows. In Section II
we outline the overall synchronization protocol. Necessarynotation and background results are presented in Section III.Two key components of our synchronization protocol, thematching module and the edit recovery module, are discussedin detail in Sections IV and V, respectively. Section VIconcludes the paper.
II. THE SYNCHRONIZATION PROTOCOLIn [1], the following setup is considered: two distant nodes
A and B are connected by a low-bandwidth high-latencynetwork. A contains a file X which is a uniform i.i.d. binarystring of length n, and B contains a file Y of length n0 that isobtained by deleting bits of X independently with probability� ⌧ 1.
We consider a generalized setting in which the file X =
X1
, . . . , Xn is i.i.d. on alphabet X = {0, . . . , Q � 1}, wherefor all 1 t n, Xt’s are distributed according to µ(x). Forsimplicity, we consider Q to be a power of two, say Q = 2
q .Insertions and deletions occur respectively with probability �i
and �d. Let us define an edit pattern E = E1
, . . . , En as astring in {�1, 0, 1}n such that Y is obtained from X in thefollowing way: for t from 1 to n,
• if Et = 0, transmit Xt,• if Et = �1, delete (do not transmit) Xt,• if Et = 1, transmit Xt, then insert (transmit) a new
symbol of X drawn with distribution µ(x).For instance, consider X and Y defined over a quaternary
alphabet, X = 00
D122133
D10 and Y = 0120
I23
I10
I310. Here
Y is derived from X by 2 deletions and 3 insertions wheredeleted (inserted) symbols are denoted by D (I). The editpattern is thus E = (0,�1, 0, 1, 1, 1, 0,�1, 0, 0). Node Baims to synchronize its file Y with the (original) file X byrequesting carefully chosen additional information from A
We need algorithms to synchronize multiple versions of a file.
Existing algorithms, such as RSYNC, su↵er from highcommunication costs.
Goal: Develop a more e�cient synchronization algorithm.
3 / 23

Reducing Data Storage Demand
When files are identical, we can use deduplication tools.
What if files are similar, but not identical?
Synchronization from Insertions and DeletionsUnder a Non-Binary, Non-Uniform Source
Nicolas Bitouze and Lara DolecekElectrical Engineering Department
University of California, Los AngelesLos Angeles, USA
Email: [email protected], [email protected]
Abstract—We study the problem of synchronizing two files Xand Y at two distant nodes A and B that are connected through a
two-way communication channel. We assume that file Y at node
B is obtained from file X at node A by inserting and deleting
a small fraction of symbols in X . More specifically, we consider
the case where X is a non-binary non-uniform string, and
deletions and insertions happen uniformly with rates �d and �i,
respectively. We propose a synchronization protocol between node
A and node B that needs to transmit O(CX(�d+�i)n log
1�d+�i
)
bits (where n is the length of X and CX is a constant that depends
on the statistical properties of X) and reconstructs X at node
B with error probability exponentially low in n. This protocol
readily generalizes the recent result by Tabatabaei Yazdi and
Dolecek that dealt with synchronization from binary uniform
source and under only deletion errors.
I. INTRODUCTIONMotivated by the pervasive use of file synchronization in
modern data storage technologies, in this work we seek todevelop a synchronization protocol that is more efficient thanthe existing algorithms. In particular, the popular RSYNCmethod can be in general very inefficient and the number oftransmitted bits can be exponentially larger than the optimalnumber.
Our starting point is an information-theoretically orientedscheme recently developed in [1]. In [1], a synchronizationprotocol that synchronizes an altered copy of the binary filewith the original version of the file was proposed. In thisscheme, the owner of the altered file requests additionalinformation from the owner of the original file to ensure propersynchronization. It was assumed that the altered copy wasobtained from the original copy by i.i.d. deletions at the bit-level and that the original file was generated from an i.i.d.uniform binary source. It was then shown that the rate of theproposed scheme asymptotically matches the optimal rate forthis channel, developed earlier in [2]. That is, in the scheme of[1], the number of bits needed to synchronize two files can bekept very small while achieving exponentially low probabilityof error.
There are many practical scenarios where the files cannotbe modeled as binary and uniform. For example, a file isusually not structured by bits, but by bytes or by even longeratomic elements. If the source is a text file, not only aresome characters more frequent than others, but there is a largeautocorrelation within the file. Additionally, some symbolsmay be inserted as well as deleted. As a result, our objective
is to suitably generalize the scheme in [1], while maintaininglow cost of transmission and low error of mis-synchronization.
Specifically, our model encapsulates the following general-izations of the model in [1]:
1) We consider errors as being insertions or deletions insteadof being restricted to deletions only,
2) We consider non-binary source symbols,3) We allow the source symbols to have an arbitrary distri-
bution; uniform distribution is then a special case.The rest of the paper is organized as follows. In Section II
we outline the overall synchronization protocol. Necessarynotation and background results are presented in Section III.Two key components of our synchronization protocol, thematching module and the edit recovery module, are discussedin detail in Sections IV and V, respectively. Section VIconcludes the paper.
II. THE SYNCHRONIZATION PROTOCOLIn [1], the following setup is considered: two distant nodes
A and B are connected by a low-bandwidth high-latencynetwork. A contains a file X which is a uniform i.i.d. binarystring of length n, and B contains a file Y of length n0 that isobtained by deleting bits of X independently with probability� ⌧ 1.
We consider a generalized setting in which the file X =
X1
, . . . , Xn is i.i.d. on alphabet X = {0, . . . , Q � 1}, wherefor all 1 t n, Xt’s are distributed according to µ(x). Forsimplicity, we consider Q to be a power of two, say Q = 2
q .Insertions and deletions occur respectively with probability �i
and �d. Let us define an edit pattern E = E1
, . . . , En as astring in {�1, 0, 1}n such that Y is obtained from X in thefollowing way: for t from 1 to n,
• if Et = 0, transmit Xt,• if Et = �1, delete (do not transmit) Xt,• if Et = 1, transmit Xt, then insert (transmit) a new
symbol of X drawn with distribution µ(x).For instance, consider X and Y defined over a quaternary
alphabet, X = 00
D122133
D10 and Y = 0120
I23
I10
I310. Here
Y is derived from X by 2 deletions and 3 insertions wheredeleted (inserted) symbols are denoted by D (I). The editpattern is thus E = (0,�1, 0, 1, 1, 1, 0,�1, 0, 0). Node Baims to synchronize its file Y with the (original) file X byrequesting carefully chosen additional information from A
Synchronization from Insertions and DeletionsUnder a Non-Binary, Non-Uniform Source
Nicolas Bitouze and Lara DolecekElectrical Engineering Department
University of California, Los AngelesLos Angeles, USA
Email: [email protected], [email protected]
Abstract—We study the problem of synchronizing two files Xand Y at two distant nodes A and B that are connected through a
two-way communication channel. We assume that file Y at node
B is obtained from file X at node A by inserting and deleting
a small fraction of symbols in X . More specifically, we consider
the case where X is a non-binary non-uniform string, and
deletions and insertions happen uniformly with rates �d and �i,
respectively. We propose a synchronization protocol between node
A and node B that needs to transmit O(CX(�d+�i)n log
1�d+�i
)
bits (where n is the length of X and CX is a constant that depends
on the statistical properties of X) and reconstructs X at node
B with error probability exponentially low in n. This protocol
readily generalizes the recent result by Tabatabaei Yazdi and
Dolecek that dealt with synchronization from binary uniform
source and under only deletion errors.
I. INTRODUCTION
Motivated by the pervasive use of file synchronization inmodern data storage technologies, in this work we seek todevelop a synchronization protocol that is more efficient thanthe existing algorithms. In particular, the popular RSYNCmethod can be in general very inefficient and the number oftransmitted bits can be exponentially larger than the optimalnumber.
Our starting point is an information-theoretically orientedscheme recently developed in [1]. In [1], a synchronizationprotocol that synchronizes an altered copy of the binary filewith the original version of the file was proposed. In thisscheme, the owner of the altered file requests additionalinformation from the owner of the original file to ensure propersynchronization. It was assumed that the altered copy wasobtained from the original copy by i.i.d. deletions at the bit-level and that the original file was generated from an i.i.d.uniform binary source. It was then shown that the rate of theproposed scheme asymptotically matches the optimal rate forthis channel, developed earlier in [2]. That is, in the schemeof [1], the number of bits needed to synchronize two files canbe kept very small while achieving exponentially low error ofmis-synchronization.
There are many practical scenarios where the files cannotbe modeled as binary and uniform. For example, a file isusually not structured by bits, but by bytes or by even longeratomic elements. If the source is a text file, not only aresome characters more frequent than others, but there is a largeautocorrelation within the file. Additionally, some symbolsmay be inserted as well as deleted. As a result, our objective
is to suitably generalize the scheme in [1], while maintaininglow cost of transmission and low error of mis-synchronization.
Specifically, our model encapsulates the following general-izations of the model in [1]:
1) We consider errors as being insertions or deletions insteadof being restricted to deletions only,
2) We consider non-binary source symbols,3) We allow the source symbols to have an arbitrary distri-
bution; uniform distribution is then a special case.The rest of the paper is organized as follows. In Section II
we outline the overall synchronization protocol. Necessarynotation and background results are presented in Section III.Two key components of our synchronization protocol, thematching module and the edit recovery module, are discussedin detail in Sections IV and V, respectively. Section VIconcludes the paper.
II. THE SYNCHRONIZATION PROTOCOLIn [1], the following setup is considered: two distant nodes
A and B are connected by a low-bandwidth high-latencynetwork. A contains a file X which is a uniform i.i.d. binarystring of length n, and B contains a file Y of length n0 that isobtained by deleting bits of X independently with probability� ⌧ 1.
We consider a generalized setting in which X =
X1
, . . . , Xn is an i.i.d. file on alphabet X = {0, . . . , Q� 1},where for all 1 t n, Xt’s are distributed accordingto µ(x). For simplicity, we consider Q to be a power oftwo, say Q = 2
q . Insertions and deletions occur respectivelywith probability �i and �d. Let us define an edit patternE = E
1
, . . . , En as a string in {�1, 0, 1}n such that Y isobtained from X in the following way: for t from 1 to n,
• if Et = 0, transmit Xt,• if Et = �1, delete (do not transmit) Xt,• if Et = 1, transmit Xt, then insert (transmit) a new
symbol of X drawn with distribution µ(x).For instance, consider X and Y defined over a quaternary
alphabet, X = 00
D122133
D10 and Y = 0120
I23
I10
I310. Here
Y is derived from X by 2 deletions and 3 insertions wheredeleted (inserted) symbols are denoted by D (I). The editpattern is thus E = (0,�1, 0, 1, 1, 1, 0,�1, 0, 0). Node Baims to synchronize its file Y with the (original) file X byrequesting carefully chosen additional information from A
Synchronization from Insertions and DeletionsUnder a Non-Binary, Non-Uniform Source
Nicolas Bitouze and Lara DolecekElectrical Engineering Department
University of California, Los AngelesLos Angeles, USA
Email: [email protected], [email protected]
Abstract—We study the problem of synchronizing two files Xand Y at two distant nodes A and B that are connected through a
two-way communication channel. We assume that file Y at node
B is obtained from file X at node A by inserting and deleting
a small fraction of symbols in X . More specifically, we consider
the case where X is a non-binary non-uniform sequence, and
deletions and insertions happen uniformly with rates �d and �i,
respectively. We propose a synchronization protocol between node
A and node B that needs to transmit O(CX(�d+�i)n log
1�d+�i
)
bits (where n is the length of X and CX is a constant that depends
on the statistical properties of X) and reconstructs X at node
B with error probability exponentially low in n. This protocol
readily generalizes the recent result by Tabatabaei Yazdi and
Dolecek that dealt with synchronization from binary uniform
source and under only deletion errors.
I. INTRODUCTIONMotivated by the pervasive use of file synchronization in
modern data storage technologies, in this work we seek todevelop a synchronization protocol that is more efficient thanthe existing algorithms. In particular, the popular RSYNCmethod can be in general very inefficient and the number oftransmitted bits can be exponentially larger than the optimalnumber.
Our starting point is an information-theoretically orientedscheme recently developed in [1]. In [1], a synchronizationprotocol that synchronizes an altered copy of the binary filewith the original version of the file was proposed. In thisscheme, the owner of the altered file requests additionalinformation from the owner of the original file to ensure propersynchronization. It was assumed that the altered copy wasobtained from the original copy by i.i.d. deletions at the bit-level and that the original file was generated from an i.i.d.uniform binary source. It was then shown that the rate of theproposed scheme asymptotically matches the optimal rate forthis channel, developed earlier in [2]. That is, in the scheme of[1], the number of bits needed to synchronize two files can bekept very small while achieving exponentially low probabilityof error.
There are many practical scenarios where the files cannotbe modeled as binary and uniform. For example, a file isusually not structured by bits, but by bytes or by even longeratomic elements. If the source is a text file, not only aresome characters more frequent than others, but there is a largeautocorrelation within the file. Additionally, some symbolsmay be inserted as well as deleted. As a result, our objective
is to suitably generalize the scheme in [1], while maintaininglow cost of transmission and low error of mis-synchronization.
Specifically, our model encapsulates the following general-izations of the model in [1]:
1) We consider errors as being insertions or deletions insteadof being restricted to deletions only,
2) We consider non-binary source symbols,3) We allow the source symbols to have an arbitrary distri-
bution; uniform distribution is then a special case.The rest of the paper is organized as follows. In Section II
we outline the overall synchronization protocol. Necessarynotation and background results are presented in Section III.Two key components of our synchronization protocol, thematching module and the edit recovery module, are discussedin detail in Sections IV and V, respectively. Section VIconcludes the paper.
II. THE SYNCHRONIZATION PROTOCOLIn [1], the following setup is considered: two distant nodes
A and B are connected by a low-bandwidth high-latencynetwork. A contains a file X which is a uniform i.i.d. binarystring of length n, and B contains a file Y of length n0 that isobtained by deleting bits of X independently with probability� ⌧ 1.
We consider a generalized setting in which the file X =
X1
, . . . , Xn is i.i.d. on alphabet X = {0, . . . , Q � 1}, wherefor all 1 t n, Xt’s are distributed according to µ(x). Forsimplicity, we consider Q to be a power of two, say Q = 2
q .Insertions and deletions occur respectively with probability �i
and �d. Let us define an edit pattern E = E1
, . . . , En as astring in {�1, 0, 1}n such that Y is obtained from X in thefollowing way: for t from 1 to n,
• if Et = 0, transmit Xt,• if Et = �1, delete (do not transmit) Xt,• if Et = 1, transmit Xt, then insert (transmit) a new
symbol of X drawn with distribution µ(x).For instance, consider X and Y defined over a quaternary
alphabet, X = 00
D122133
D10 and Y = 0120
I23
I10
I310. Here
Y is derived from X by 2 deletions and 3 insertions wheredeleted (inserted) symbols are denoted by D (I). The editpattern is thus E = (0,�1, 0, 1, 1, 1, 0,�1, 0, 0). Node Baims to synchronize its file Y with the (original) file X byrequesting carefully chosen additional information from A
We need algorithms to synchronize multiple versions of a file.
Existing algorithms, such as RSYNC, su↵er from highcommunication costs.
Goal: Develop a more e�cient synchronization algorithm.
3 / 23

Reducing Data Storage Demand
When files are identical, we can use deduplication tools.
What if files are similar, but not identical?
Synchronization from Insertions and DeletionsUnder a Non-Binary, Non-Uniform Source
Nicolas Bitouze and Lara DolecekElectrical Engineering Department
University of California, Los AngelesLos Angeles, USA
Email: [email protected], [email protected]
Abstract—We study the problem of synchronizing two files Xand Y at two distant nodes A and B that are connected through a
two-way communication channel. We assume that file Y at node
B is obtained from file X at node A by inserting and deleting
a small fraction of symbols in X . More specifically, we consider
the case where X is a non-binary non-uniform string, and
deletions and insertions happen uniformly with rates �d and �i,
respectively. We propose a synchronization protocol between node
A and node B that needs to transmit O(CX(�d+�i)n log
1�d+�i
)
bits (where n is the length of X and CX is a constant that depends
on the statistical properties of X) and reconstructs X at node
B with error probability exponentially low in n. This protocol
readily generalizes the recent result by Tabatabaei Yazdi and
Dolecek that dealt with synchronization from binary uniform
source and under only deletion errors.
I. INTRODUCTIONMotivated by the pervasive use of file synchronization in
modern data storage technologies, in this work we seek todevelop a synchronization protocol that is more efficient thanthe existing algorithms. In particular, the popular RSYNCmethod can be in general very inefficient and the number oftransmitted bits can be exponentially larger than the optimalnumber.
Our starting point is an information-theoretically orientedscheme recently developed in [1]. In [1], a synchronizationprotocol that synchronizes an altered copy of the binary filewith the original version of the file was proposed. In thisscheme, the owner of the altered file requests additionalinformation from the owner of the original file to ensure propersynchronization. It was assumed that the altered copy wasobtained from the original copy by i.i.d. deletions at the bit-level and that the original file was generated from an i.i.d.uniform binary source. It was then shown that the rate of theproposed scheme asymptotically matches the optimal rate forthis channel, developed earlier in [2]. That is, in the scheme of[1], the number of bits needed to synchronize two files can bekept very small while achieving exponentially low probabilityof error.
There are many practical scenarios where the files cannotbe modeled as binary and uniform. For example, a file isusually not structured by bits, but by bytes or by even longeratomic elements. If the source is a text file, not only aresome characters more frequent than others, but there is a largeautocorrelation within the file. Additionally, some symbolsmay be inserted as well as deleted. As a result, our objective
is to suitably generalize the scheme in [1], while maintaininglow cost of transmission and low error of mis-synchronization.
Specifically, our model encapsulates the following general-izations of the model in [1]:
1) We consider errors as being insertions or deletions insteadof being restricted to deletions only,
2) We consider non-binary source symbols,3) We allow the source symbols to have an arbitrary distri-
bution; uniform distribution is then a special case.The rest of the paper is organized as follows. In Section II
we outline the overall synchronization protocol. Necessarynotation and background results are presented in Section III.Two key components of our synchronization protocol, thematching module and the edit recovery module, are discussedin detail in Sections IV and V, respectively. Section VIconcludes the paper.
II. THE SYNCHRONIZATION PROTOCOLIn [1], the following setup is considered: two distant nodes
A and B are connected by a low-bandwidth high-latencynetwork. A contains a file X which is a uniform i.i.d. binarystring of length n, and B contains a file Y of length n0 that isobtained by deleting bits of X independently with probability� ⌧ 1.
We consider a generalized setting in which the file X =
X1
, . . . , Xn is i.i.d. on alphabet X = {0, . . . , Q � 1}, wherefor all 1 t n, Xt’s are distributed according to µ(x). Forsimplicity, we consider Q to be a power of two, say Q = 2
q .Insertions and deletions occur respectively with probability �i
and �d. Let us define an edit pattern E = E1
, . . . , En as astring in {�1, 0, 1}n such that Y is obtained from X in thefollowing way: for t from 1 to n,
• if Et = 0, transmit Xt,• if Et = �1, delete (do not transmit) Xt,• if Et = 1, transmit Xt, then insert (transmit) a new
symbol of X drawn with distribution µ(x).For instance, consider X and Y defined over a quaternary
alphabet, X = 00
D122133
D10 and Y = 0120
I23
I10
I310. Here
Y is derived from X by 2 deletions and 3 insertions wheredeleted (inserted) symbols are denoted by D (I). The editpattern is thus E = (0,�1, 0, 1, 1, 1, 0,�1, 0, 0). Node Baims to synchronize its file Y with the (original) file X byrequesting carefully chosen additional information from A
Synchronization from Insertions and DeletionsUnder a Non-Binary, Non-Uniform Source
Nicolas Bitouze and Lara DolecekElectrical Engineering Department
University of California, Los AngelesLos Angeles, USA
Email: [email protected], [email protected]
Abstract—We study the problem of synchronizing two files Xand Y at two distant nodes A and B that are connected through a
two-way communication channel. We assume that file Y at node
B is obtained from file X at node A by inserting and deleting
a small fraction of symbols in X . More specifically, we consider
the case where X is a non-binary non-uniform string, and
deletions and insertions happen uniformly with rates �d and �i,
respectively. We propose a synchronization protocol between node
A and node B that needs to transmit O(CX(�d+�i)n log
1�d+�i
)
bits (where n is the length of X and CX is a constant that depends
on the statistical properties of X) and reconstructs X at node
B with error probability exponentially low in n. This protocol
readily generalizes the recent result by Tabatabaei Yazdi and
Dolecek that dealt with synchronization from binary uniform
source and under only deletion errors.
I. INTRODUCTION
Motivated by the pervasive use of file synchronization inmodern data storage technologies, in this work we seek todevelop a synchronization protocol that is more efficient thanthe existing algorithms. In particular, the popular RSYNCmethod can be in general very inefficient and the number oftransmitted bits can be exponentially larger than the optimalnumber.
Our starting point is an information-theoretically orientedscheme recently developed in [1]. In [1], a synchronizationprotocol that synchronizes an altered copy of the binary filewith the original version of the file was proposed. In thisscheme, the owner of the altered file requests additionalinformation from the owner of the original file to ensure propersynchronization. It was assumed that the altered copy wasobtained from the original copy by i.i.d. deletions at the bit-level and that the original file was generated from an i.i.d.uniform binary source. It was then shown that the rate of theproposed scheme asymptotically matches the optimal rate forthis channel, developed earlier in [2]. That is, in the schemeof [1], the number of bits needed to synchronize two files canbe kept very small while achieving exponentially low error ofmis-synchronization.
There are many practical scenarios where the files cannotbe modeled as binary and uniform. For example, a file isusually not structured by bits, but by bytes or by even longeratomic elements. If the source is a text file, not only aresome characters more frequent than others, but there is a largeautocorrelation within the file. Additionally, some symbolsmay be inserted as well as deleted. As a result, our objective
is to suitably generalize the scheme in [1], while maintaininglow cost of transmission and low error of mis-synchronization.
Specifically, our model encapsulates the following general-izations of the model in [1]:
1) We consider errors as being insertions or deletions insteadof being restricted to deletions only,
2) We consider non-binary source symbols,3) We allow the source symbols to have an arbitrary distri-
bution; uniform distribution is then a special case.The rest of the paper is organized as follows. In Section II
we outline the overall synchronization protocol. Necessarynotation and background results are presented in Section III.Two key components of our synchronization protocol, thematching module and the edit recovery module, are discussedin detail in Sections IV and V, respectively. Section VIconcludes the paper.
II. THE SYNCHRONIZATION PROTOCOLIn [1], the following setup is considered: two distant nodes
A and B are connected by a low-bandwidth high-latencynetwork. A contains a file X which is a uniform i.i.d. binarystring of length n, and B contains a file Y of length n0 that isobtained by deleting bits of X independently with probability� ⌧ 1.
We consider a generalized setting in which X =
X1
, . . . , Xn is an i.i.d. file on alphabet X = {0, . . . , Q� 1},where for all 1 t n, Xt’s are distributed accordingto µ(x). For simplicity, we consider Q to be a power oftwo, say Q = 2
q . Insertions and deletions occur respectivelywith probability �i and �d. Let us define an edit patternE = E
1
, . . . , En as a string in {�1, 0, 1}n such that Y isobtained from X in the following way: for t from 1 to n,
• if Et = 0, transmit Xt,• if Et = �1, delete (do not transmit) Xt,• if Et = 1, transmit Xt, then insert (transmit) a new
symbol of X drawn with distribution µ(x).For instance, consider X and Y defined over a quaternary
alphabet, X = 00
D122133
D10 and Y = 0120
I23
I10
I310. Here
Y is derived from X by 2 deletions and 3 insertions wheredeleted (inserted) symbols are denoted by D (I). The editpattern is thus E = (0,�1, 0, 1, 1, 1, 0,�1, 0, 0). Node Baims to synchronize its file Y with the (original) file X byrequesting carefully chosen additional information from A
Synchronization from Insertions and DeletionsUnder a Non-Binary, Non-Uniform Source
Nicolas Bitouze and Lara DolecekElectrical Engineering Department
University of California, Los AngelesLos Angeles, USA
Email: [email protected], [email protected]
Abstract—We study the problem of synchronizing two files Xand Y at two distant nodes A and B that are connected through a
two-way communication channel. We assume that file Y at node
B is obtained from file X at node A by inserting and deleting
a small fraction of symbols in X . More specifically, we consider
the case where X is a non-binary non-uniform sequence, and
deletions and insertions happen uniformly with rates �d and �i,
respectively. We propose a synchronization protocol between node
A and node B that needs to transmit O(CX(�d+�i)n log
1�d+�i
)
bits (where n is the length of X and CX is a constant that depends
on the statistical properties of X) and reconstructs X at node
B with error probability exponentially low in n. This protocol
readily generalizes the recent result by Tabatabaei Yazdi and
Dolecek that dealt with synchronization from binary uniform
source and under only deletion errors.
I. INTRODUCTIONMotivated by the pervasive use of file synchronization in
modern data storage technologies, in this work we seek todevelop a synchronization protocol that is more efficient thanthe existing algorithms. In particular, the popular RSYNCmethod can be in general very inefficient and the number oftransmitted bits can be exponentially larger than the optimalnumber.
Our starting point is an information-theoretically orientedscheme recently developed in [1]. In [1], a synchronizationprotocol that synchronizes an altered copy of the binary filewith the original version of the file was proposed. In thisscheme, the owner of the altered file requests additionalinformation from the owner of the original file to ensure propersynchronization. It was assumed that the altered copy wasobtained from the original copy by i.i.d. deletions at the bit-level and that the original file was generated from an i.i.d.uniform binary source. It was then shown that the rate of theproposed scheme asymptotically matches the optimal rate forthis channel, developed earlier in [2]. That is, in the scheme of[1], the number of bits needed to synchronize two files can bekept very small while achieving exponentially low probabilityof error.
There are many practical scenarios where the files cannotbe modeled as binary and uniform. For example, a file isusually not structured by bits, but by bytes or by even longeratomic elements. If the source is a text file, not only aresome characters more frequent than others, but there is a largeautocorrelation within the file. Additionally, some symbolsmay be inserted as well as deleted. As a result, our objective
is to suitably generalize the scheme in [1], while maintaininglow cost of transmission and low error of mis-synchronization.
Specifically, our model encapsulates the following general-izations of the model in [1]:
1) We consider errors as being insertions or deletions insteadof being restricted to deletions only,
2) We consider non-binary source symbols,3) We allow the source symbols to have an arbitrary distri-
bution; uniform distribution is then a special case.The rest of the paper is organized as follows. In Section II
we outline the overall synchronization protocol. Necessarynotation and background results are presented in Section III.Two key components of our synchronization protocol, thematching module and the edit recovery module, are discussedin detail in Sections IV and V, respectively. Section VIconcludes the paper.
II. THE SYNCHRONIZATION PROTOCOLIn [1], the following setup is considered: two distant nodes
A and B are connected by a low-bandwidth high-latencynetwork. A contains a file X which is a uniform i.i.d. binarystring of length n, and B contains a file Y of length n0 that isobtained by deleting bits of X independently with probability� ⌧ 1.
We consider a generalized setting in which the file X =
X1
, . . . , Xn is i.i.d. on alphabet X = {0, . . . , Q � 1}, wherefor all 1 t n, Xt’s are distributed according to µ(x). Forsimplicity, we consider Q to be a power of two, say Q = 2
q .Insertions and deletions occur respectively with probability �i
and �d. Let us define an edit pattern E = E1
, . . . , En as astring in {�1, 0, 1}n such that Y is obtained from X in thefollowing way: for t from 1 to n,
• if Et = 0, transmit Xt,• if Et = �1, delete (do not transmit) Xt,• if Et = 1, transmit Xt, then insert (transmit) a new
symbol of X drawn with distribution µ(x).For instance, consider X and Y defined over a quaternary
alphabet, X = 00
D122133
D10 and Y = 0120
I23
I10
I310. Here
Y is derived from X by 2 deletions and 3 insertions wheredeleted (inserted) symbols are denoted by D (I). The editpattern is thus E = (0,�1, 0, 1, 1, 1, 0,�1, 0, 0). Node Baims to synchronize its file Y with the (original) file X byrequesting carefully chosen additional information from A
We need algorithms to synchronize multiple versions of a file.
Existing algorithms, such as RSYNC, su↵er from highcommunication costs.
Goal: Develop a more e�cient synchronization algorithm.
3 / 23

Synchronization Protocols
Original File
Alice’s Version Bob ’s VersionEdits Edits
4 / 23

Synchronization Protocols
Original File
Alice’s Version Bob ’s VersionEdits Edits
4 / 23

Synchronization Protocols
Original File
Alice’s Version Bob ’s VersionEdits Edits
Synchronization Protocol
so that Bob’s version matches Alice’s
4 / 23

Synchronization Protocols
Original File
Alice’s Version Alice’s VersionEdits Edits
Synchronization Protocol
so that Bob’s version matches Alice’s
4 / 23

Problem Setting
File X : h d c e a t g b k u j r v c x f q. . .
File Y : h d e a k t g v b j r v c r f s q. . .
Small rate of edits �.
File length: |X |=n, |Y |=m⇡n.
5 / 23

Problem Setting
File X : h d c e a t g b k u j r v c x f q. . .
File Y : h d e a k t g v b j r v c r f s q. . .
Small rate of edits �.
File length: |X |=n, |Y |=m⇡n.
5 / 23

Problem Setting
File X : h d c e a t g b k u j r v c x f q. . .
File Y : h d e a k t g v b j r v c r f s q. . .
Small rate of edits �.
File length: |X |=n, |Y |=m⇡n.
5 / 23

Problem Setting
File X : h d c e a t g b k u j r v c x f q. . .
File Y : h d e a k t g v b j r v c r f s q. . .
D
Small rate of edits �.
File length: |X |=n, |Y |=m⇡n.
5 / 23

Problem Setting
File X : h d c e a t g b k u j r v c x f q. . .
File Y : h d e a k t g v b j r v c r f s q. . .
D
Small rate of edits �.
File length: |X |=n, |Y |=m⇡n.
5 / 23

Problem Setting
File X : h d c e a t g b k u j r v c x f q. . .
File Y : h d e a k t g v b j r v c r f s q. . .
D
Small rate of edits �.
File length: |X |=n, |Y |=m⇡n.
5 / 23

Problem Setting
File X : h d c e a t g b k u j r v c x f q. . .
File Y : h d e a k t g v b j r v c r f s q. . .
DI
Small rate of edits �.
File length: |X |=n, |Y |=m⇡n.
5 / 23

Problem Setting
File X : h d c e a t g b k u j r v c x f q. . .
File Y : h d e a k t g v b j r v c r f s q. . .
DI
Small rate of edits �.
File length: |X |=n, |Y |=m⇡n.
5 / 23

Problem Setting
File X : h d c e a t g b k u j r v c x f q. . .
File Y : h d e a k t g v b j r v c r f s q. . .
DI
Small rate of edits �.
File length: |X |=n, |Y |=m⇡n.
5 / 23

Problem Setting
File X : h d c e a t g b k u j r v c x f q. . .
File Y : h d e a k t g v b j r v c r f s q. . .
D DD DI I I I
Small rate of edits �.
File length: |X |=n, |Y |=m⇡n.
5 / 23

Problem Setting
File X : h d c e a t g b k u j r v c x f q. . .
File Y : h d e a k t g v b j r v c r f s q. . .
D DD DI I I I
File X
Node A
File Y
Node B
Two-way Channel
(Noiseless)
Goal: Interactive Communication Scheme
Allow Node to B recover X from Y :
with low probability of error,
with low communication cost.
5 / 23
Related Work
Scheme that corrects a single edit (binary & non-binary):
V. I. Levenshtein, “Binary codes with correction of deletions,insertions and reversals”, 1965.G. M. Tenengolts, “Nonbinary codes, correcting single deletionor insertion”, 1984.
Scheme that corrects a fixed number of edits (binary):
R. Venkataramanan, H. Zhang, and K. Ramchandran,“Interactive low-complexity codes for synchronization fromdeletions and insertions”, 2010.
Theoretical bound for the fixed rate of edits case:N. Ma, K. Ramchandran and D. Tse, “E�cient filesynchronization: a distributed source coding approach”, 2011.
6 / 23

Related Work
Scheme that corrects a single edit (binary & non-binary):
V. I. Levenshtein, “Binary codes with correction of deletions,insertions and reversals”, 1965.G. M. Tenengolts, “Nonbinary codes, correcting single deletionor insertion”, 1984.
Scheme that corrects a fixed number of edits (binary):
R. Venkataramanan, H. Zhang, and K. Ramchandran,“Interactive low-complexity codes for synchronization fromdeletions and insertions”, 2010.
Theoretical bound for the fixed rate of edits case:N. Ma, K. Ramchandran and D. Tse, “E�cient filesynchronization: a distributed source coding approach”, 2011.
6 / 23

Related Work
Scheme that corrects a single edit (binary & non-binary):
V. I. Levenshtein, “Binary codes with correction of deletions,insertions and reversals”, 1965.G. M. Tenengolts, “Nonbinary codes, correcting single deletionor insertion”, 1984.
Scheme that corrects a fixed number of edits (binary):
R. Venkataramanan, H. Zhang, and K. Ramchandran,“Interactive low-complexity codes for synchronization fromdeletions and insertions”, 2010.
Theoretical bound for the fixed rate of edits case:N. Ma, K. Ramchandran and D. Tse, “E�cient filesynchronization: a distributed source coding approach”, 2011.
6 / 23

Our Contributions
Scheme for fixed rate of edits:
N. Bitouze and L. Dolecek, “Synchronization from insertionsand deletions under a non-binary, non-uniform source”, IEEEISIT, Jul. 2013.S. M. S. Tabatabaei and L. Dolecek, “A deterministic,polynomial-time protocol for synchronizing from deletions”,IEEE Trans. I.T., 2013.N. Bitouze, F. Sala, S. M. S. Tabatabaei, and L. Dolecek, “Apractical framework for e�cient file synchronization”, Allerton,Oct. 2013.
7 / 23

Synchronization Scheme: Overview
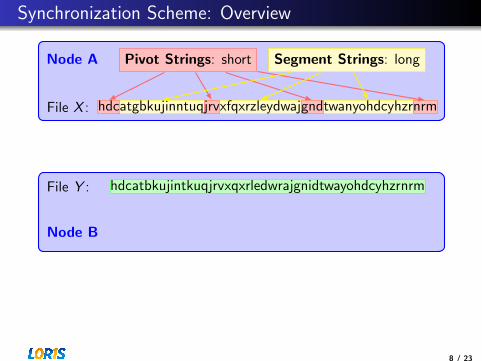
hdcatgbkujinntuqjrvxfqxrzleydwajgndtwanyohdcyhzrnrmFile X :
Pivot Strings: short Segment Strings: long
Node A
hdcatbkujintkuqjrvxqxrledwrajgnidtwayohdcyhzrnrm
hdcatgbkujinntuqjrvxfqxrzleydwajgndtwanyohdcyhzrnrm
File Y :
Matched Pivots
Node B
8 / 23
Synchronization Scheme: Overview
hdcatgbkujinntuqjrvxfqxrzleydwajgndtwanyohdcyhzrnrmFile X :
Pivot Strings: short Segment Strings: longNode A
hdcatbkujintkuqjrvxqxrledwrajgnidtwayohdcyhzrnrm
hdcatgbkujinntuqjrvxfqxrzleydwajgndtwanyohdcyhzrnrm
File Y :
Matched Pivots
Node B
8 / 23

Synchronization Scheme: Overview
hdcatgbkujinntuqjrvxfqxrzleydwajgndtwanyohdcyhzrnrmFile X :
Pivot Strings: short Segment Strings: longNode A
hdcatbkujintkuqjrvxqxrledwrajgnidtwayohdcyhzrnrm
hdcatgbkujinntuqjrvxfqxrzleydwajgndtwanyohdcyhzrnrm
File Y :
Matched Pivots
Node B
Send the pivots:
hdc jrv gnd nrm
8 / 23

Synchronization Scheme: Overview
hdcatgbkujinntuqjrvxfqxrzleydwajgndtwanyohdcyhzrnrmFile X :
Pivot Strings: short Segment Strings: longNode A
hdcatbkujintkuqjrvxqxrledwrajgnidtwayohdcyhzrnrm
hdcatgbkujinntuqjrvxfqxrzleydwajgndtwanyohdcyhzrnrm
File Y :
Matched PivotsNode B
Send the pivots:
hdc jrv gnd nrm
1 Matching Module: Matches the pivot strings.
8 / 23

Synchronization Scheme: Overview
hdcatgbkujinntuqjrvxfqxrzleydwajgndtwanyohdcyhzrnrmFile X :
Pivot Strings: short Segment Strings: longNode A
hdcatbkujintkuqjrvxqxrledwrajgnidtwayohdcyhzrnrm
hdcatgbkujinntuqjrvxfqxrzleydwajgndtwanyohdcyhzrnrm
File Y :
Matched PivotsNode B
1 Matching Module: Matches the pivot strings.
8 / 23

Synchronization Scheme: Overview
hdcatgbkujinntuqjrvxfqxrzleydwajgndtwanyohdcyhzrnrmFile X :
Pivot Strings: short Segment Strings: longNode A
hdcatbkujintkuqjrvxqxrledwrajgnidtwayohdcyhzrnrm
hdcatgbkujinntuqjrvxfqxrzleydwajgndtwanyohdcyhzrnrm
File Y :
Matched Pivots Non-Synced SegmentsNode B
1 Matching Module: Matches the pivot strings.
8 / 23

Synchronization Scheme: Overview
hdcatgbkujinntuqjrvxfqxrzleydwajgndtwanyohdcyhzrnrmFile X :
Pivot Strings: short Segment Strings: longNode A
hdcatbkujintkuqjrvxqxrledwrajgnidtwayohdcyhzrnrm
hdcatgbkujinntuqjrvxfqxrzleydwajgndtwanyohdcyhzrnrm
File Y :
Matched Pivots Non-Synced SegmentsNode B
1 Matching Module: Matches the pivot strings.
2 Edit Recovery Module: Synchronizes the segment strings.
8 / 23

Synchronization Scheme: Overview
hdcatgbkujinntuqjrvxfqxrzleydwajgndtwanyohdcyhzrnrmFile X :
Pivot Strings: short Segment Strings: longNode A
hdcatgbkujinntuqjrvxfqxrzleydwajgndtwanyohdcyhzrnrmFile Y :
Matched Pivots Synchronized SegmentsNode B
1 Matching Module: Matches the pivot strings.
2 Edit Recovery Module: Synchronizes the segment strings.
8 / 23

Synchronization Scheme: Overview
hdcatgbkujinntuqjrvxfqxrzleydwajgndtwanyohdcyhzrnrmFile X :
Pivot Strings: short Segment Strings: longNode A
hdcatgbkujinntuqjrvxfqxrzleydwajgndtwanyohdcyhzrnrmFile Y :
Matched Pivots Synchronized SegmentsNode B
1 Matching Module: Matches the pivot strings.
2 Edit Recovery Module: Synchronizes the segment strings.
3 Channel Coding Module: Recovers from residual errors if any.
8 / 23

1 Matching Module
Matching Module
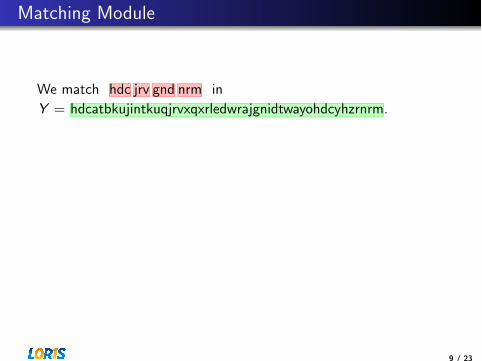
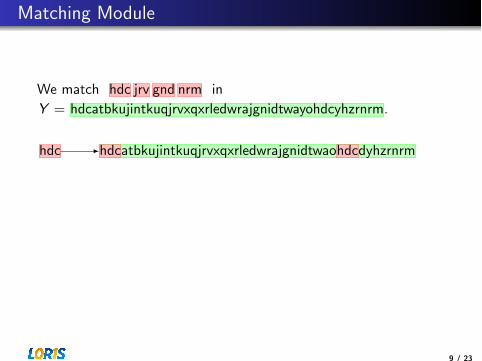
We match hdc jrv gnd nrm in
Y = hdcatbkujintkuqjrvxqxrledwrajgnidtwayohdcyhzrnrm.
hdc hdcatbkujintkuqjrvxqxrledwrajgnidtwaohdcdyhzrnrm
jrv hdcatbkujintkuqjrvxqxrledwrajgnidtwaohdcdyhzrnrm
gnd hdcatbkujintkuqjrvxqxrledwrajgnidtwaohdcdyhzrnrm
nrm hdcatbkujintkuqjrvxqxrledwrajgnidtwaohdcdyhzrnrm
9 / 23
Matching Module
We match hdc jrv gnd nrm in
Y = hdcatbkujintkuqjrvxqxrledwrajgnidtwayohdcyhzrnrm.
hdc hdcatbkujintkuqjrvxqxrledwrajgnidtwaohdcdyhzrnrm
jrv hdcatbkujintkuqjrvxqxrledwrajgnidtwaohdcdyhzrnrm
gnd hdcatbkujintkuqjrvxqxrledwrajgnidtwaohdcdyhzrnrm
nrm hdcatbkujintkuqjrvxqxrledwrajgnidtwaohdcdyhzrnrm
9 / 23

Matching Module
We match hdc jrv gnd nrm in
Y = hdcatbkujintkuqjrvxqxrledwrajgnidtwayohdcyhzrnrm.
hdc hdcatbkujintkuqjrvxqxrledwrajgnidtwaohdcdyhzrnrm
jrv hdcatbkujintkuqjrvxqxrledwrajgnidtwaohdcdyhzrnrm
gnd hdcatbkujintkuqjrvxqxrledwrajgnidtwaohdcdyhzrnrm
nrm hdcatbkujintkuqjrvxqxrledwrajgnidtwaohdcdyhzrnrm
9 / 23

Matching Module
We match hdc jrv gnd nrm in
Y = hdcatbkujintkuqjrvxqxrledwrajgnidtwayohdcyhzrnrm.
hdc hdcatbkujintkuqjrvxqxrledwrajgnidtwaohdcdyhzrnrm
jrv hdcatbkujintkuqjrvxqxrledwrajgnidtwaohdcdyhzrnrm
gnd hdcatbkujintkuqjrvxqxrledwrajgnidtwaohdcdyhzrnrm
nrm hdcatbkujintkuqjrvxqxrledwrajgnidtwaohdcdyhzrnrm
9 / 23

Matching Module
We match hdc jrv gnd nrm in
Y = hdcatbkujintkuqjrvxqxrledwrajgnidtwayohdcyhzrnrm.
hdc hdcatbkujintkuqjrvxqxrledwrajgnidtwaohdcdyhzrnrm
jrv hdcatbkujintkuqjrvxqxrledwrajgnidtwaohdcdyhzrnrm
gnd hdcatbkujintkuqjrvxqxrledwrajgnidtwaohdcdyhzrnrm
nrm hdcatbkujintkuqjrvxqxrledwrajgnidtwaohdcdyhzrnrm
9 / 23

Matching Module
We match hdc jrv gnd nrm in
Y = hdcatbkujintkuqjrvxqxrledwrajgnidtwayohdcyhzrnrm.
hdc hdcatbkujintkuqjrvxqxrledwrajgnidtwaohdcdyhzrnrm
jrv hdcatbkujintkuqjrvxqxrledwrajgnidtwaohdcdyhzrnrm
gnd hdcatbkujintkuqjrvxqxrledwrajgnidtwaohdcdyhzrnrm
nrm hdcatbkujintkuqjrvxqxrledwrajgnidtwaohdcdyhzrnrm
9 / 23

Matching Module: Larger Example
1
2
3
4
5
6
1 1 11
2 2
333
44 4
555
66 6
y1y2 . . . . . . ym
10 / 23
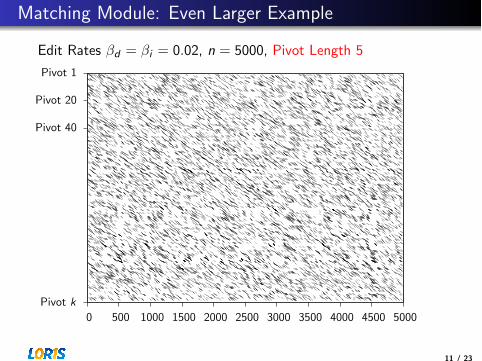
Matching Module: Even Larger Example
Edit Rates �d = �i = 0.02, n = 5000, Pivot Length 5
Pivot k
Pivot 40
Pivot 20
Pivot 1
0 500 1000 1500 2000 2500 3000 3500 4000 4500 5000
11 / 23

Matching Module: Even Larger Example
Edit Rates �d = �i = 0.02, n = 5000, Pivot Length 6
Pivot k
Pivot 40
Pivot 20
Pivot 1
0 500 1000 1500 2000 2500 3000 3500 4000 4500 5000
11 / 23
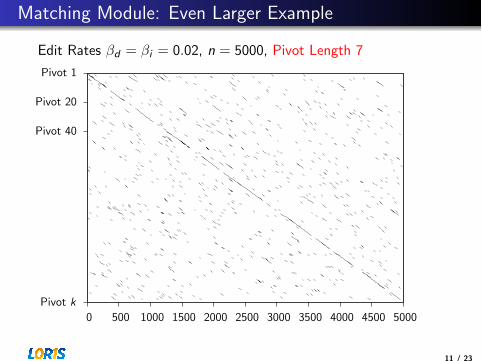
Matching Module: Even Larger Example
Edit Rates �d = �i = 0.02, n = 5000, Pivot Length 7
Pivot k
Pivot 40
Pivot 20
Pivot 1
0 500 1000 1500 2000 2500 3000 3500 4000 4500 5000
11 / 23

Matching Module: Cost and Error Probability
Errors
Pivots are short enough to avoid edits,
Pivots are long enough so that pivot collisions are unlikely,
“Wrong” thick edges exist, but wrong thick paths do not.
Communication
With pivot length O⇣log 1
�
⌘,
With segment length O⇣
1�
⌘,
O(n�) pivots are transmitted, totalling O⇣n� log 1
�
⌘bit.
12 / 23

Matching Module: Cost and Error Probability
Errors
Pivots are short enough to avoid edits,
Pivots are long enough so that pivot collisions are unlikely,
“Wrong” thick edges exist, but wrong thick paths do not.
Communication
With pivot length O⇣log 1
�
⌘,
With segment length O⇣
1�
⌘,
O(n�) pivots are transmitted, totalling O⇣n� log 1
�
⌘bit.
12 / 23

Matching Module: Cost and Error Probability
Summary
The module transmits O⇣n� log 1
�
⌘bits
(in a single channel use).
With probability 1� O(2�n):
We match a fraction 1� O⇣� log 1
�
⌘of the pivots.
These matches are incorrect with probability < � + o(�).
12 / 23

2 Edit Recovery Module

Edit Recovery Module: Correcting Single Edits
When two files di↵er by a single edit, synchronization:
can be done in a single round of communication,
in a perfect manner (no error),
communicating ⇠ log L+ log q bits (from A to B),where L and L± 1 are the lengths of the files.
G. M. Tenengolts, “Nonbinary codes, correcting single deletionor insertion”, 1984.
13 / 23

Edit Recovery Module
R. Venkataramanan, H. Zhang, and K. Ramchandran,“Interactive low-complexity codes for synchronization fromdeletions and insertions”, 2010.
Goal: X = j r v x q x r l e d w r a j g n i d t w a y o h d c y h z r n r m
Given: Y = j r v x f q x r z l e y d w a j g n d t w a n y o h d c y h z r n r m
j r v x q x r l e d w a j g n i d t w a y o h d c y h z r n r mj r v x f q x r z l e y d w a j g n d t w a n y o h d c y h z r n r m
26
29
12 12
14 / 23

Edit Recovery Module
R. Venkataramanan, H. Zhang, and K. Ramchandran,“Interactive low-complexity codes for synchronization fromdeletions and insertions”, 2010.
Goal: X = j r v x q x r l e d w r a j g n i d t w a y o h d c y h z r n r m
Given: Y = j r v x f q x r z l e y d w a j g n d t w a n y o h d c y h z r n r m
j r v x q x r l e d w a j g n i d t w a y o h d c y h z r n r mj r v x f q x r z l e y d w a j g n d t w a n y o h d c y h z r n r m
26
29
12 12
Lengths di↵er by more than 1:Send a central delimiter.
14 / 23

Edit Recovery Module
R. Venkataramanan, H. Zhang, and K. Ramchandran,“Interactive low-complexity codes for synchronization fromdeletions and insertions”, 2010.
Goal: X = j r v x q x r l e d w r a j g n i d t w a y o h d c y h z r n r m
Given: Y = j r v x f q x r z l e y d w a j g n d t w a n y o h d c y h z r n r m
j r v x q x r l e d w a j g n i d t w a y o h d c y h z r n r mj r v x f q x r z l e y d w a j g n d t w a n y o h d c y h z r n r m
26
29
12 12
Delimiter i d has no match:Choose a di↵erent delimiter.
14 / 23

Edit Recovery Module
R. Venkataramanan, H. Zhang, and K. Ramchandran,“Interactive low-complexity codes for synchronization fromdeletions and insertions”, 2010.
Goal: X = j r v x q x r l e d w r a j g n i d t w a y o h d c y h z r n r m
Given: Y = j r v x f q x r z l e y d w a j g n d t w a n y o h d c y h z r n r m
j r v x q x r l e d w a j g n i d t w a y o h d c y h z r n r mj r v x f q x r z l e y d w a j g n d t w a n y o h d c y h z r n r m
26
29
12 12
New “central” delimiter g n is matched:Repeat on both sides.
14 / 23

Edit Recovery Module
Goal: X = j r v x q x r l e d w r a j g n i d t w a y o h d c y h z r n r m
Given: Y = j r v x f q x r z l e y d w a j g n d t w a n y o h d c y h z r n r m
j r v x q x r l e d w a j g n i d t w a y o h d c y h z r n r mj r v x f q x r z l e y d w a j g n d t w a n y o h d c y h z r n r m
26
29
12 12
10 14
13 14
Left side:
Lengths di↵er by more than 1:Send a delimiter.
Right side:
Lengths are equal:
Test if strings are equal (hash),
No: Send a delimiter.
14 / 23

Edit Recovery Module
Goal: X = j r v x q x r l e d w r a j g n i d t w a y o h d c y h z r n r m
Given: Y = j r v x f q x r z l e y d w a j g n d t w a n y o h d c y h z r n r m
j r v x q x r l e d w a j g n i d t w a y o h d c y h z r n r mj r v x f q x r z l e y d w a j g n d t w a n y o h d c y h z r n r m
26
29
12 12
And so on...
until every subproblem is solved.
14 / 23

Edit Recovery Module
Goal: X = j r v x q x r l e d w r a j g n i d t w a y o h d c y h z r n r m
Given: Y = j r v x f q x r z l e y d w a j g n d t w a n y o h d c y h z r n r m
j r v x q x r l e d w a j g n i d t w a y o h d c y h z r n r mj r v x f q x r z l e y d w a j g n d t w a n y o h d c y h z r n r m
26
29
12 12
4
6
4
5
6
6
6
6
And so on...
until every subproblem is solved.
14 / 23

Edit Recovery Module
Goal: X = j r v x q x r l e d w r a j g n i d t w a y o h d c y h z r n r m
Given: Y = j r v x f q x r z l e y d w a j g n d t w a n y o h d c y h z r n r m
j r v x q x r l e d w a j g n id t w a y o h d c y h z r n r mj r v x f q x r z l e d w a j g n d t w a n y o h d c y h z r n r m
26
29
12 12
And so on...
until every subproblem is solved.
14 / 23

Edit Recovery Module
Goal: X = j r v x q x r l e d w r a j g n i d t w a y o h d c y h z r n r m
Given: Y = j r v x f q x r z l e y d w a j g n d t w a n y o h d c y h z r n r m
j r v x q x r l e d w a j g n id t w a y o h d c y h z r n r mj r v x f q x r z l e d w a j g n d t w a n y o h d c y h z r n r m
26
29
12 12
1 1 2 2
2 2 1 3
And so on...
until every subproblem is solved.
14 / 23

Edit Recovery Module
Goal: X = j r v x q x r l e d w r a j g n i d t w a y o h d c y h z r n r m
Given: Y = j r v x f q x r z l e y d w a j g n d t w a n y o h d c y h z r n r m
j r v x q x r l e d w a j g n id t w a y o h d c y h z r n r mj r v x q x r l e d w a j g n id t w a y o h d c y h z r n r m
26
29
12 12
And so on... until every subproblem is solved.
14 / 23

Edit Recovery Module: Cost and Error Probability
Errors
Come from Hash Collisions,
Increase hash length:More communication,Less collisions.
Communication
Hashes (from A to B),
Delimiters (from A to B),
Syndromes (from A to B),
Control (from B to A).
15 / 23

Edit Recovery Module: Cost and Error Probability
Errors
Come from Hash Collisions,
Increase hash length:More communication,Less collisions.
Communication
Hashes (from A to B),
Delimiters (from A to B),
Syndromes (from A to B),
Control (from B to A).
15 / 23

Edit Recovery Module: Cost and Error Probability
Summary
The module transmits O⇣n� log 1
�
⌘bits
(in a few rounds of communication).
With probability 1� O(2�n),only a fraction o(�) of the segments is mis-synchronized.
15 / 23

3 Channel Coding Module

Channel Coding Module: Motivation
Possible Errors
Pivots mismatched by the Matching Module.
Delimiters mismatched by the Edit Recovery Module.
Hash collisions.
After these two modules,the symbol-error probability is < 2� + o(�).
) Correct these errors with the Channel Coding Module.
16 / 23

Channel Coding Module: Motivation
Possible Errors
Pivots mismatched by the Matching Module.
Delimiters mismatched by the Edit Recovery Module.
Hash collisions.
After these two modules,the symbol-error probability is < 2� + o(�).) Correct these errors with the Channel Coding Module.
16 / 23

Channel Coding Module
Node A
Node B
X
Output ⇡X from Edit Recov. Mod.(Same length as X )
C
Systematic part q-ary Checks
Codeword from Systematic LDPC Code
C
X C
Channel Coding Module: LDPC Decoder
17 / 23
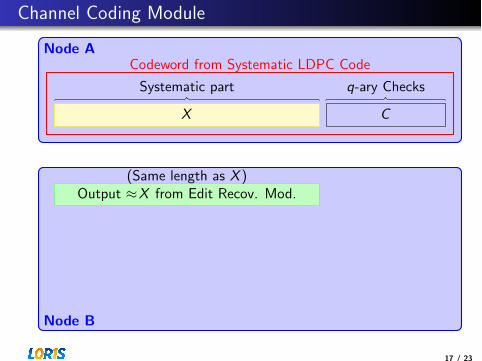
Channel Coding Module
Node A
Node B
X
Output ⇡X from Edit Recov. Mod.(Same length as X )
C
Systematic part q-ary Checks
Codeword from Systematic LDPC Code
C
X C
Channel Coding Module: LDPC Decoder
17 / 23

Channel Coding Module
Node A
Node B
X
Output ⇡X from Edit Recov. Mod.(Same length as X )
C
Systematic part q-ary Checks
Codeword from Systematic LDPC Code
C
X C
Channel Coding Module: LDPC Decoder
Send
17 / 23

Channel Coding Module
Node A
Node B
X
Output ⇡X from Edit Recov. Mod.
(Same length as X )
C
Systematic part q-ary Checks
Codeword from Systematic LDPC Code
C
X C
Channel Coding Module: LDPC Decoder
Send
17 / 23
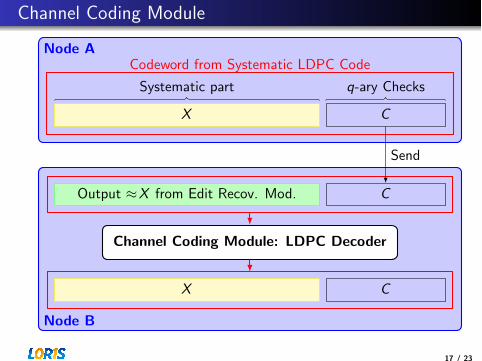
Channel Coding Module
Node A
Node B
X
Output ⇡X from Edit Recov. Mod.
(Same length as X )
C
Systematic part q-ary Checks
Codeword from Systematic LDPC Code
C
X C
Channel Coding Module: LDPC Decoder
Send
17 / 23

Channel Coding Module: Cost and Error Probability
Communication
Residual error probability from previous modules:2� + o(�).
Additional data required to correct these errors:
Const · n · H(2� + o(�)) = O⇣n� log 1
�
⌘bits.
Summary
The module transmits O⇣n� log 1
�
⌘bits
(in a single channel use).
With probability 1� O(2�n),Y is synchronized with no remaining error.
18 / 23

Channel Coding Module: Cost and Error Probability
Communication
Residual error probability from previous modules:2� + o(�).
Additional data required to correct these errors:
Const · n · H(2� + o(�)) = O⇣n� log 1
�
⌘bits.
Summary
The module transmits O⇣n� log 1
�
⌘bits
(in a single channel use).
With probability 1� O(2�n),Y is synchronized with no remaining error.
18 / 23

Comparison with RSYNC when n varies
� = 0.01 and � = 0.002, i.i.d. file, i.i.d. edits, q = 52,Our pivot length: 5, segment length: 1/�.
0
100000
200000
300000
400000
0 20000 40000 60000 80000 100000
Bitstransm
itted
File length (n)
Factor 5.5
Factor 12.5
our scheme (� = 0.002)our scheme (� = 0.010)
rsync (� = 0.002)rsync (� = 0.010)
19 / 23

Comparison with RSYNC when � varies
n = 50000, i.i.d. file, i.i.d. edits, q = 52,Our pivot length: 5, segment length: 1/�.
0
100000
200000
300000
0 0.002 0.004 0.006 0.008 0.01
Bitstransm
itted
Edit rate (�)
Factor 10
our schemersync
20 / 23

Comparison with Venkataramanan et al. scheme
� = 0.01, i.i.d. file, i.i.d. edits, q = 52,
Our pivot length: 5, segment length: 1/�.
Bandwidth (in bits)
n 20k 40k 60k 100k
MedianOur scheme 18k 35k 54k 87k
Venkataramanan 19k 41k 63k 87k
Worst-caseOur scheme 52k 96k 95k 95k
Venkataramanan 390k 845k 1,216k 346k
Rounds of communication required
Our scheme completes in about half less rounds.
Errors prior to Channel Coding
Our error rate per symbol is also about half lower.
21 / 23

Applications
In addition to reducing data storage demand, our algorithm can beused for:
Synchronization in general data storage (Dropbox),
Synchronization in particular data repositories: source control(Github, SVN, etc...), video (YouTube, Vimeo),
Database searches: determining whether two records aresimilar.
22 / 23

Applications
In addition to reducing data storage demand, our algorithm can beused for:
Synchronization in general data storage (Dropbox),
Synchronization in particular data repositories: source control(Github, SVN, etc...), video (YouTube, Vimeo),
Database searches: determining whether two records aresimilar.
22 / 23

Applications
In addition to reducing data storage demand, our algorithm can beused for:
Synchronization in general data storage (Dropbox),
Synchronization in particular data repositories: source control(Github, SVN, etc...), video (YouTube, Vimeo),
Database searches: determining whether two records aresimilar.
22 / 23

Applications
In addition to reducing data storage demand, our algorithm can beused for:
Synchronization in general data storage (Dropbox),
Synchronization in particular data repositories: source control(Github, SVN, etc...), video (YouTube, Vimeo),
Database searches: determining whether two records aresimilar.
22 / 23

Ongoing Work
Allow for more complex edit patterns(e.g., in practical scenarios, edits are often “bursty”),
Specialize our scheme to application-dependent types of files(e.g., if the files are source code, exploit that structure),
Optimize the implementation (e.g., in terms of bothcomputation and network usage).
23 / 23

Ongoing Work
Allow for more complex edit patterns(e.g., in practical scenarios, edits are often “bursty”),
Specialize our scheme to application-dependent types of files(e.g., if the files are source code, exploit that structure),
Optimize the implementation (e.g., in terms of bothcomputation and network usage).
23 / 23

Ongoing Work
Allow for more complex edit patterns(e.g., in practical scenarios, edits are often “bursty”),
Specialize our scheme to application-dependent types of files(e.g., if the files are source code, exploit that structure),
Optimize the implementation (e.g., in terms of bothcomputation and network usage).
23 / 23