receiver-driven layered multicast paper by- steven mccanne, van jacobson and martin vetterli – acm...
TRANSCRIPT

Receiver-driven Layered Multicast
Paper by- Steven McCanne, Van Jacobson and Martin Vetterli – ACM SIGCOMM 1996
Presented By – Manoj Sivakumar

Overview
Introduction Approaches to Rate-Adaptive
Multimedia Issues and challenges RLM - Details Performance Evaluation Conclusions

Introduction
Consider a typical streaming Application
What rate should the source send data at ?
Internet ReceiverSource128 Kb/s X Kb/s

Approaches to Rate-Adaptive Multimedia
Rate Adaptation at Source – based on available network capacity Works well for a Unicast environment How about multicast ?
source Receiver 2128 Kb/s X2 Kb/s
Receiver 1
Receiver 3
X1 Kb/s
X3 Kb/s
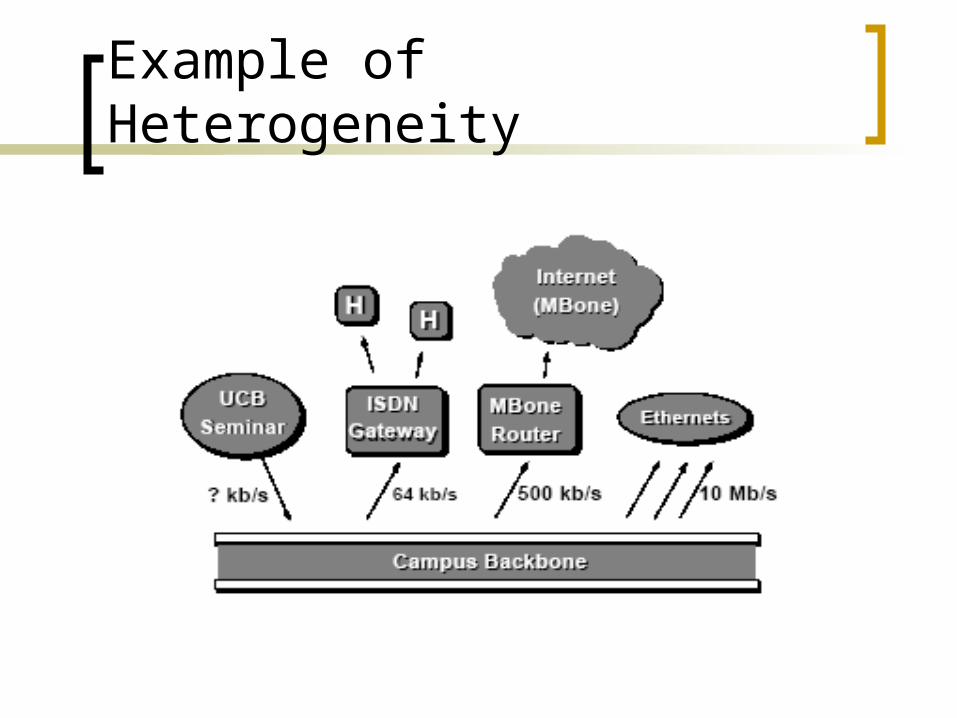
Example of Heterogeneity

Issues and Challenges
Optimal link utilization Best possible service to all receivers Ability to cope with Congestion in the
network All this should be done with just best
effort service on the internet

Layered Approach
Rather than sending a single encoded video signal the source sends several layers of encoded signal – each layer incrementally refining the quality of the signal
Intermediate Routers drop higher layers when congestion occurs

Layered Approach
Each layer is sent to one multicast group
If a receiver wants higher quality – subscribes to all higher level layer multicast groups

Issue in Layered Approach
No framework for explicit signaling between the receivers and routers
A mechanism to adapt to both static heterogeneity and dynamic variations in network capacity is not present Solution - RLM

RLM – Network Model
Works with IP Multicast Assume
Best effort (packets may be out of order, lost or arbitrarily delayed)
Multicast (traffic flows only along links with downstream recipients)
Group oriented communication (senders do not know of receivers and receivers can come and go)
Receivers may specify different senders

RLM - Video Streams
One channel per layer Layers are additive Adding more channels gives better
quality Adding more channels requires more
bandwidth

RLM Sessions
Each session composed of layers, with one layer per group
Layers can be separate (i.e. each layer is higher quality) or additive (add all to get maximum quality) Additive is more efficient
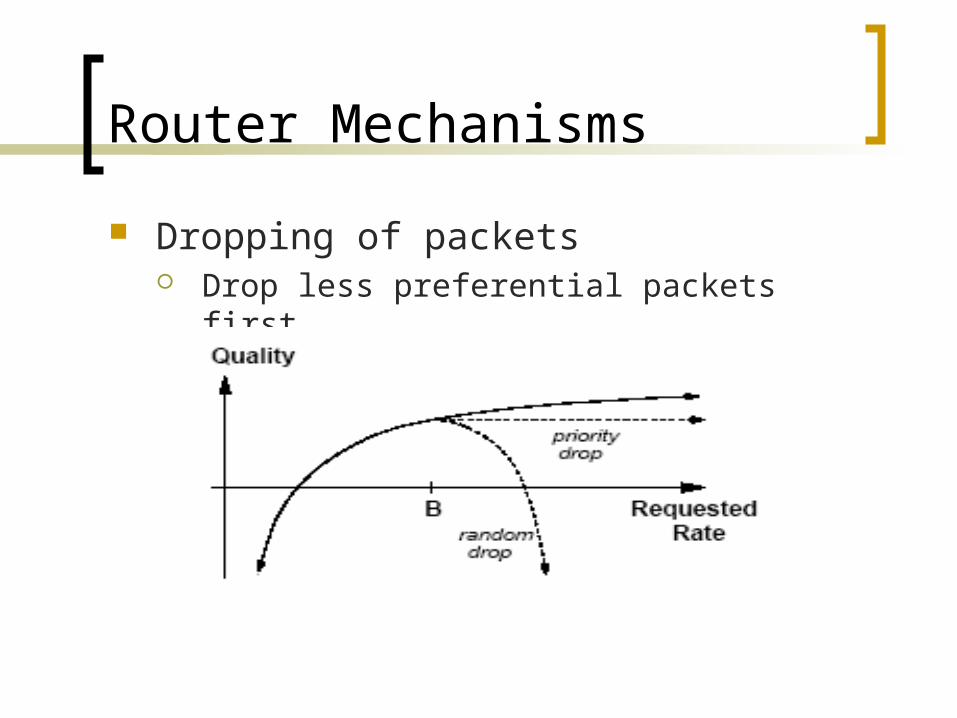
Router Mechanisms
Dropping of packets Drop less preferential packets first
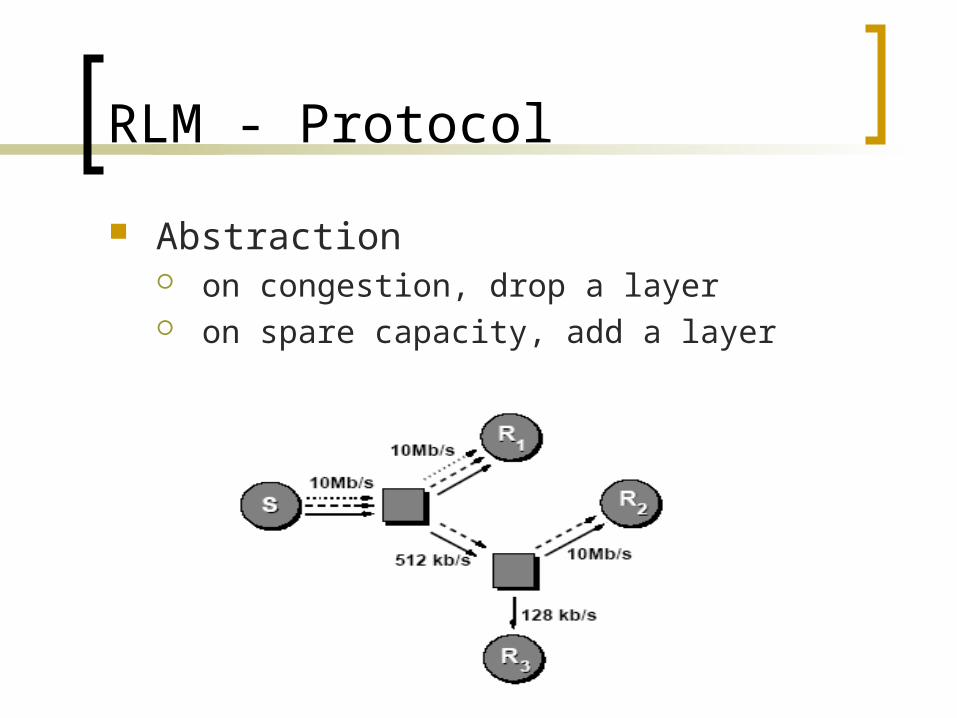
RLM - Protocol
Abstraction on congestion, drop a layer on spare capacity, add a layer

RLM – Adding and Dropping layers
Drop layer when packet loss Add does not have counter-part signal Need to try adding at well-chosen
times Called join experiment

RLM – Adding and Dropping layers
If join experiment fails Drop layer, since causing congestion
If join experiment succeeds One step closer to operating level
But join experiments can cause congestion Only want to try when might succeed

RLM – Join Experiments
Get lowest layer and start timer for next probe Initially timer small If higher level fails then increase timer
duration else proceed to next layer and start time for the layer above it
Repeat until optimum
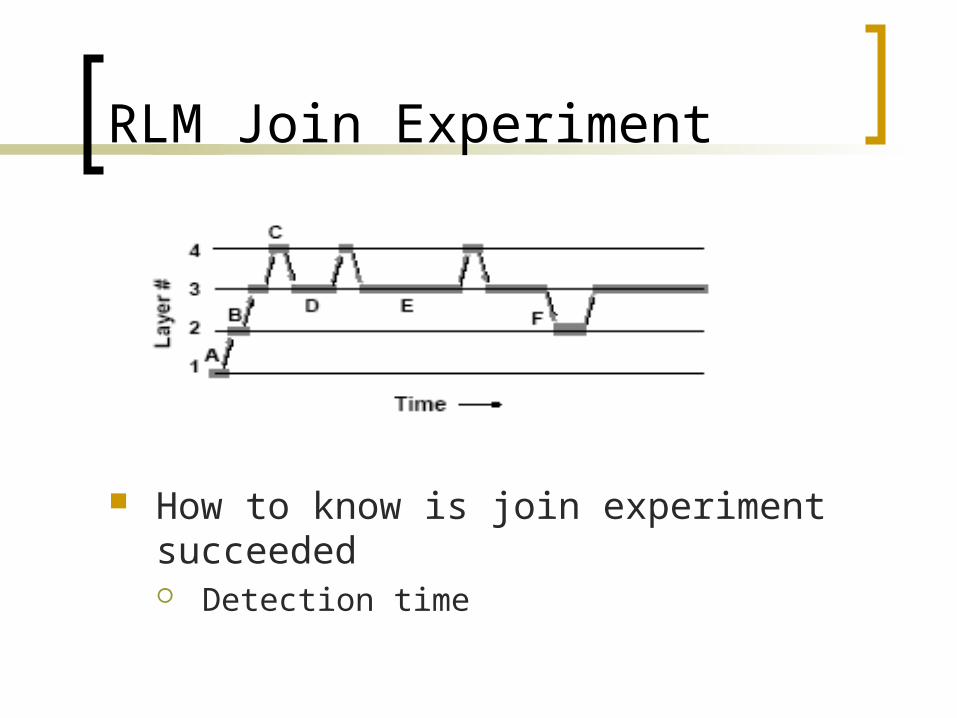
RLM Join Experiment
How to know is join experiment succeeded Detection time

Detection Time
Hard to estimate Can only be done experimentally Initially start with a large value Progressively update the detection
time based on actual values

RLM - Issues with Joins
Is this Scalable What if each node does join experiments
and the same time for different layers Wrong info to node that requests lower
layer if the other node had requested higher layer
Solution – Shared Learning

RLM – Shared Learning
Each node broadcasts its intent to the group Adv’s – other nodes can learn from the
result of this node’s experiment Reduction in simultaneous experiments
Is this still foolproof ??

RLM - Evaluation
Simulations performed in NS Video modeled as CBR Parameters
Bandwidth: 1.5 Mbps Layers: 6, each 32 x 2m kbps (m = 0 … 5) Queue management :Drop Tail Queue Size (20 packets) Packet size (1 Kbytes) Latency (varies) Topology (next slide)
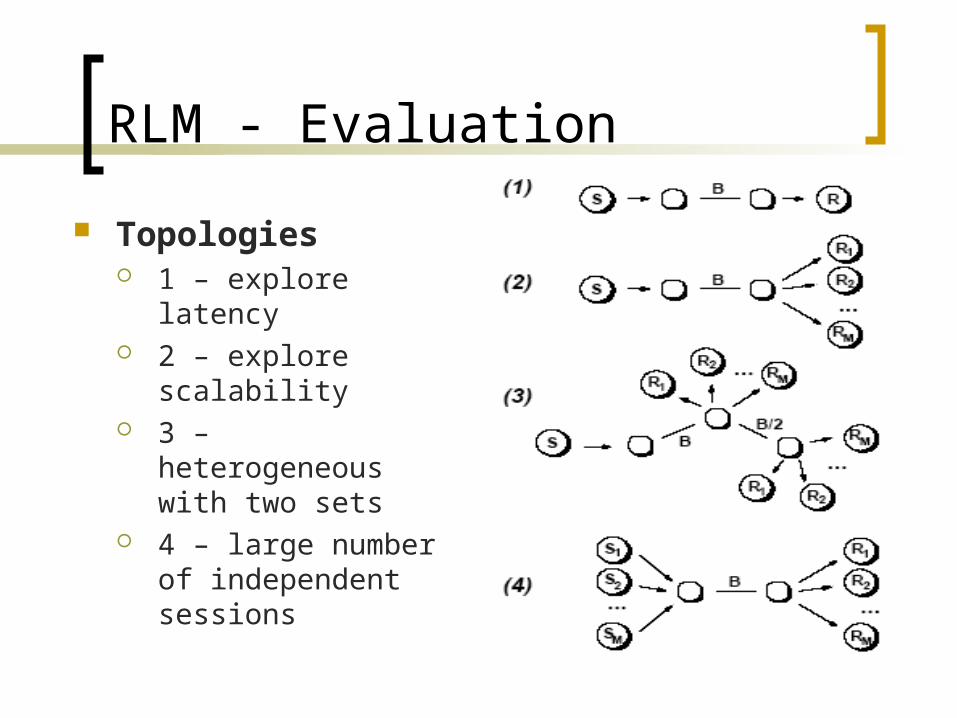
RLM - Evaluation
Topologies 1 – explore latency 2 – explore
scalability 3 – heterogeneous
with two sets 4 – large number of
independent sessions

RLM – Performance Metrics
Worse-case lost rate over varying time intervals Short-term: how bad transient congestion is Long-term: how often congestion occurs
Throughput as percent of available But will always be 100% eventually So, look at time to reach optimal
Note, neither alone is ok Could have low loss, low throughput High loss, high throughput
Need to look at both

RLM – Performance Results
Latency Results

RLM – Performance Results
Latency Results
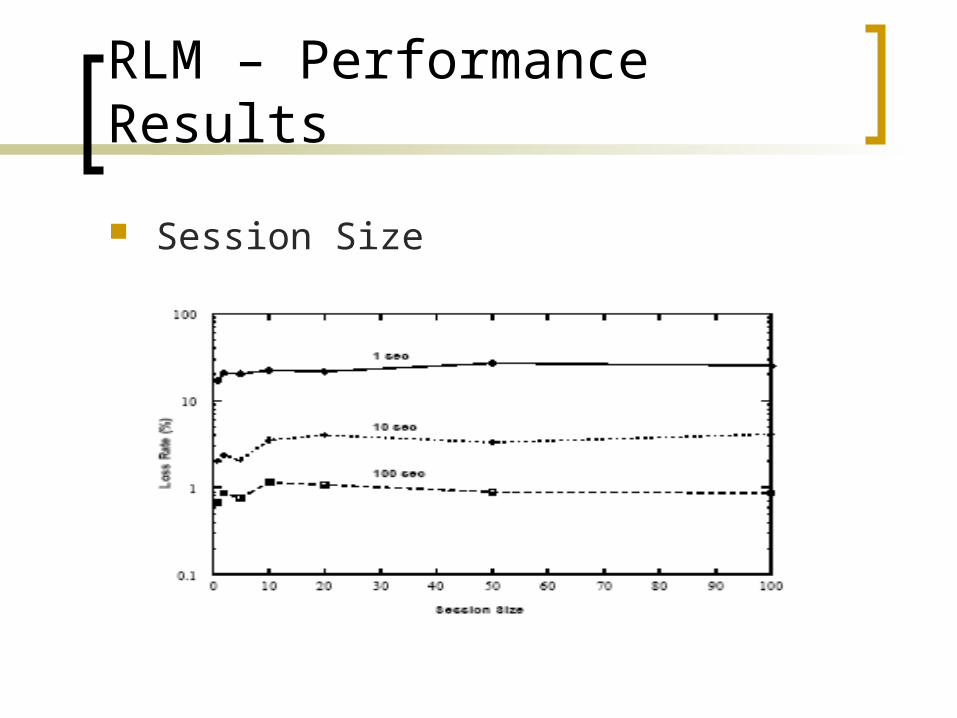
RLM – Performance Results
Session Size
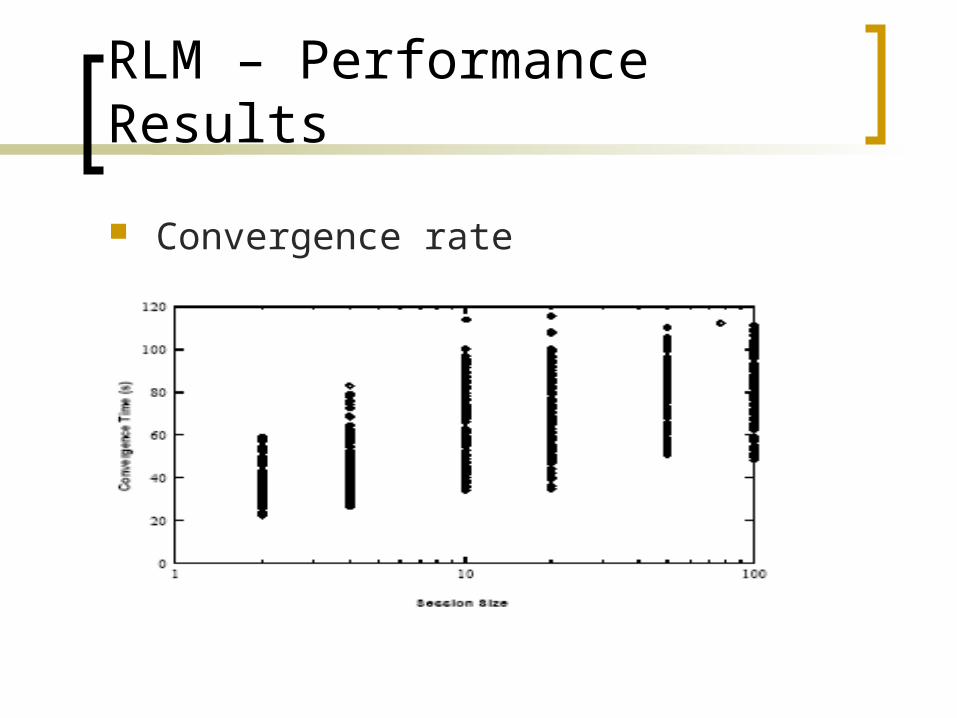
RLM – Performance Results
Convergence rate
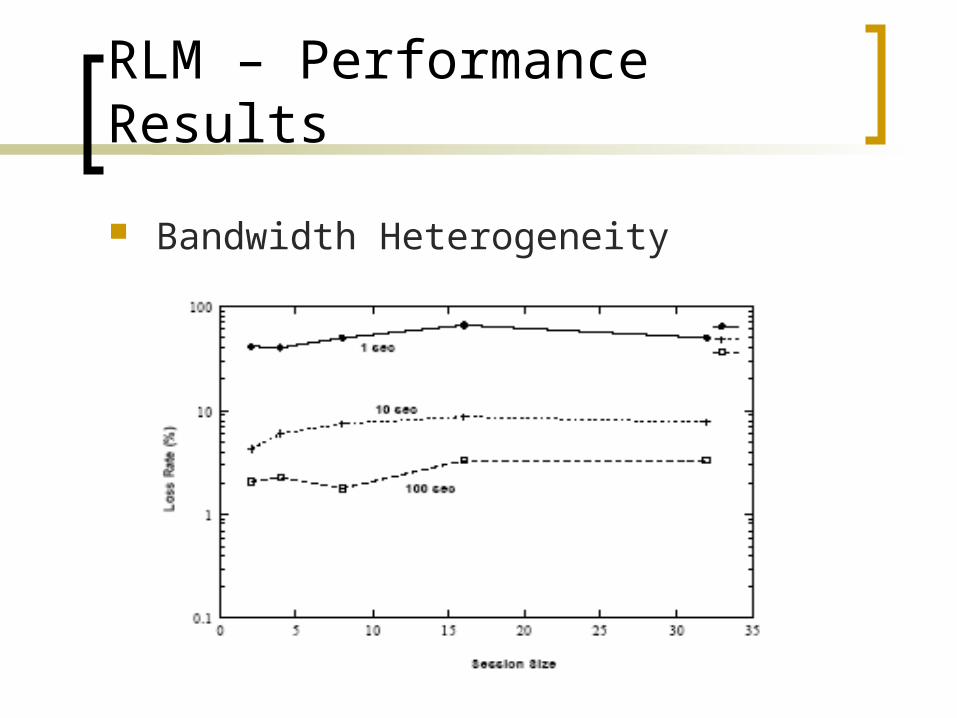
RLM – Performance Results
Bandwidth Heterogeneity

Conclusions
Possible Pitfalls Shared Learning assumes only multicast
traffic Is this valid ?? Is congestion produced by Multicast
traffic alone Simulation does not other traffic
requests!!

Conclusions
Overall – a nice architecture and mechanism to regulate traffic and have the best utilization
But still needs refinement

References
S. McCanne, V. Jacobson, and M. Vetterli, "Receiver-driven layered multicast," in Proc. SIGCOMM'96, ACM, Stanford, CA, Aug. 1996, pp. 117--130.