recall: goal of this class - university of hong konghso/classes/rcclass/handouts/03-power... ·...
TRANSCRIPT

10.1.31
1
Performance, Power & Energy
ELEC8106/ELEC6102
Spring 2010
Hayden Kwok-Hay So
Recall: Goal of this class
H. So, Sp10 Lecture 3 - ELEC8106/6102 2
Reconfiguration
Per
form
ance
Power/ Energy
PERFORMANCE EVALUATION
H. So, Sp10 Lecture 3 - ELEC8106/6102 3
What is good performance? Time needed to
finish certain task(s) Number of tasks
finished per unit time
H. So, Sp10 Lecture 3 - ELEC8106/6102 4
Latency Throughput
Latency vs Throughput (1) Low latency High throughput?
High throughput Low Latency?
High latency low throughput?
Low throughput high latency?
H. So, Sp10 Lecture 3 - ELEC8106/6102 5
Latency vs Throughput (2)
Computer 1 Finish task
• A takes 15s • B takes 20s • C takes 50s
Latency = 15s + 20s+ 50s = 85s
Throughput = 3 / 85s = 0.035 tasks / s
Computer 2 Finish task
• A takes 20s • B takes 25s • C takes 45s
Latency = 20s + 25s + 45s = 90s
Throughput = 3 / 90s = 0.03 tasks/s
H. So, Sp10 Lecture 3 - ELEC8106/6102 6
Is Computer 1 “faster” than Computer 2?
Computer 1 and 2 must finish task A,B,C

10.1.31
2
Latency vs Throughput (3)
Computer 1 Finish task
• A takes 15s • B takes 20s • C takes 50s
Latency = 15s + 20s+ 50s = 85s
Throughput = 3 / 85s = 0.035 tasks / s
Computer 2 Finish task
• A takes 20s • B takes 25s • C takes 45s
Latency = 45s
Throughput = 3 / 45s = 0.067 tasks/s
H. So, Sp10 Lecture 3 - ELEC8106/6102 7
Is Computer 2 “faster” than Computer 1?
What if Computer 2 can perform 3 tasks at the same time?
Latency vs Throughput (4)
Computer 1 A:15, B:20, C:50
Latency = 50s
Throughput = 3 / 50s = 0.06 tasks / s
Computer 2 A:20, B:25, C:45
Latency = 45s
Throughput = 3 / 45s = 0.067 tasks/s
H. So, Sp10 Lecture 3 - ELEC8106/6102 8
Which computer is “faster”?
What if both Computer 1 and 2 can perform 2 tasks at the same time?
C A B
C A B
Latency vs Throughput (5)
Computer 1 A:15, B:20, C:50
First result = 15s
Last result = 50s
Throughput = 3 / 50s = 0.06 tasks / s
Computer 2 A:20, B:25, C:45
First result = 20s
Last result = 45s
Throughput = 3 / 45s = 0.067 tasks/s
H. So, Sp10 Lecture 3 - ELEC8106/6102 9
Both Computer 1 and 2 can perform 2 tasks at the same time. Define latency as time to get first result.
C A B
C A B
Latency vs Throughput (6)
Computer 1 A:15, B:20, C:50
First result = 15s
Last result = 85s
Throughput = 6 / 85s = 0.07 tasks / s
Computer 2 A:20, B:25, C:45
First result = 20s
Last result = 90s
Throughput = 3 / 45s = 0.067 tasks/s
H. So, Sp10 Lecture 3 - ELEC8106/6102 10
Both Computer 1 and 2 can perform 2 tasks at the same time. Tasks = ABCABC
C A B C A B C
A B C
A B
Latency vs Throughput Summary
Latency Time to first data/
response arrive
Time for task to finish
Indicates the “responsiveness” of a system
Throughput Sustained rate of task
completion
Matters most when there are a lot of continuous input
Especially with streaming input
A long term efficiency measurement
H. So, Sp10 Lecture 3 - ELEC8106/6102 11
Latency vs Throughput Summary Latency and throughput measure
important in different scenarios
The two has close tie to each other, but no obvious relationship
Many factors affect latency/throughput • Data input / Workload • Scheduling • etc
H. So, Sp10 Lecture 3 - ELEC8106/6102 12

10.1.31
3
Performance: task completion Time to complete 1 task is a good way
to measure general purpose computers
Time to complete 1 task (latency):
H. So, Sp10 Lecture 3 - ELEC8106/6102 13
€
L =no. of instrs×CPI
fclk
How to improve speed?
H. So, Sp10 Lecture 3 - ELEC8106/6102 14
€
L =no. of instrs×CPI
fclk
Decrease number of instruction Decrease cycles per
instruction
Increase clock frequency
Increase clock frequency Linear increase in
performance But … heat
dissipation has prohibited simple clock frequency boost
H. So, Sp10 Lecture 3 - ELEC8106/6102 15
Figure courtesy of Kunle Olukotun, Lance Hammond, Herb Sutter, and Burton Smith
Improving speed
NOTE: the number of instructions of a program is closely related to its CPI • CPI changes depending on the app.
H. So, Sp10 Lecture 3 - ELEC8106/6102 16
€
L =no. of instrs×CPI
fclk
(micro) computer architecture compiler
Review: CPI vs # of instructions A program executes the following instruction profile:
With a clock cycle time of 1ns, how long does the program takes to finish? What is the average CPI of the processor?
H. So, Sp10 Lecture 3 - ELEC8106/6102 17
Instruction Type Number Clock Cycle Add 2000 1 Multiply 1000 5 Division 500 20 Load 1000 8 Store 500 2
L = (2000*1 + 1000*5 + 500*20 + 1000*8 + 500*2) * 1ns = 26 us
Avg. CPI = 26,000 / 5000 = 5.2
Amdahl’s Law Overall speedup due to
improving a fraction P with speed up of S is:
E.g. if P = 0.2, S=5, then overall speed up is
If the same improvement can be applied to a larger portion with P=0.9, then speedup =
H. So, Sp10 Lecture 3 - ELEC8106/6102 18
€
1
(1− P) +PS
€
1(1− 0.2) + 0.2 5
=1.19
€
1(1− 0.9) + 0.9 5
= 3.57
Always optimize for the common cases.
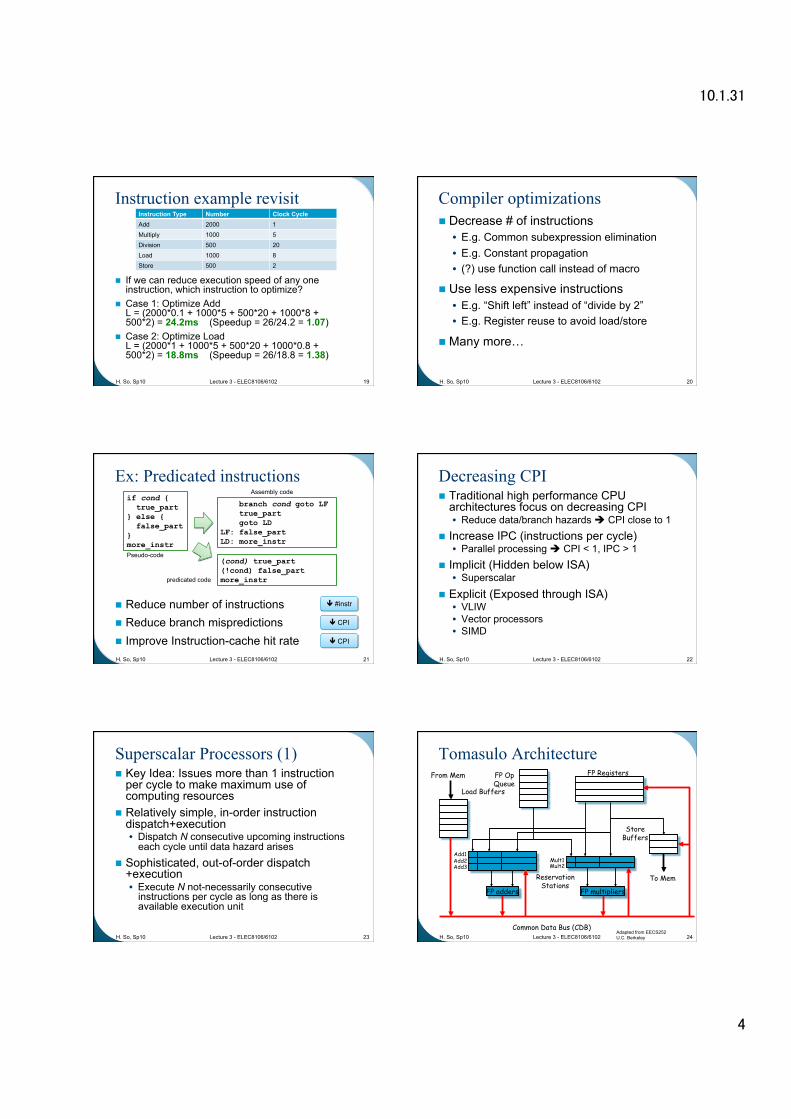
10.1.31
4
Instruction example revisit
If we can reduce execution speed of any one instruction, which instruction to optimize?
Case 1: Optimize Add L = (2000*0.1 + 1000*5 + 500*20 + 1000*8 + 500*2) = 24.2ms (Speedup = 26/24.2 = 1.07)
Case 2: Optimize Load L = (2000*1 + 1000*5 + 500*20 + 1000*0.8 + 500*2) = 18.8ms (Speedup = 26/18.8 = 1.38)
H. So, Sp10 Lecture 3 - ELEC8106/6102 19
Instruction Type Number Clock Cycle Add 2000 1 Multiply 1000 5 Division 500 20 Load 1000 8 Store 500 2
Compiler optimizations Decrease # of instructions • E.g. Common subexpression elimination • E.g. Constant propagation • (?) use function call instead of macro
Use less expensive instructions • E.g. “Shift left” instead of “divide by 2” • E.g. Register reuse to avoid load/store
Many more…
H. So, Sp10 Lecture 3 - ELEC8106/6102 20
Ex: Predicated instructions
Reduce number of instructions Reduce branch mispredictions Improve Instruction-cache hit rate H. So, Sp10 Lecture 3 - ELEC8106/6102 21
if cond { true_part } else { false_part } more_instr Pseudo-code
branch cond goto LF true_part goto LD LF: false_part LD: more_instr
Assembly code
(cond) true_part (!cond) false_part more_instr predicated code
#instr
CPI
CPI
Decreasing CPI Traditional high performance CPU
architectures focus on decreasing CPI • Reduce data/branch hazards CPI close to 1
Increase IPC (instructions per cycle) • Parallel processing CPI < 1, IPC > 1
Implicit (Hidden below ISA) • Superscalar
Explicit (Exposed through ISA) • VLIW • Vector processors • SIMD
H. So, Sp10 Lecture 3 - ELEC8106/6102 22
Superscalar Processors (1) Key Idea: Issues more than 1 instruction
per cycle to make maximum use of computing resources
Relatively simple, in-order instruction dispatch+execution • Dispatch N consecutive upcoming instructions
each cycle until data hazard arises Sophisticated, out-of-order dispatch
+execution • Execute N not-necessarily consecutive
instructions per cycle as long as there is available execution unit
H. So, Sp10 Lecture 3 - ELEC8106/6102 23
Tomasulo Architecture
H. So, Sp10 Lecture 3 - ELEC8106/6102 24
FP adders
Add1 Add2 Add3
FP multipliers
Mult1 Mult2
From Mem FP Registers
Reservation Stations
Common Data Bus (CDB)
To Mem
FP Op Queue
Load Buffers
Store Buffers
Adapted from EECS252 U.C. Berkeley

10.1.31
5
VLIW Very Long Instruction Word (VLIW) machines
• Each instruction is in fact composed of multiple smaller, “standard” instructions
• 4 to 8 “standard” instructions per cycle • Compiler looks for instructions from the original
program that can be issued at the same cycle and pack them into one mega-instruction
• No dynamic instruction analysis on hardware
H. So, Sp10 Lecture 3 - ELEC8106/6102 25
IF reg
EX $
reg
EX $
A simplistic VLIW
Vector Processors Processor that operates on vectors as
basic data type • Compared to scalar processor
Vector instructions • E.g. Add 2 vectors: set_vector_len 64 add vectorR, vectorA, vectorB
A form of data-parallelism
Reduces no. of instructions
H. So, Sp10 Lecture 3 - ELEC8106/6102 26
SIMD Single instruction multiple data A class of computation architecture Only one instruction stream is presented, which operates
on multiple data streams • Vector processing is special form of SIMD in which all data
are indeed vectors E.g. Intel’s MMX, SSE, SSE2 extensions
• To implement r1=a1+b1, r2=a2+b2, r3=a3+b3 and r4=a4+b4 in one instruction:
add r1,a1,b1,r2,a2,b2,r3,b3,c3,r4,b4,c4
Save no. of instructions May pack 4 8-bit adds into a single 32-bit add
• Reuse the 32-bit hardware adder (with small modifications)
H. So, Sp10 Lecture 3 - ELEC8106/6102 27
Explicit vs Implicit (1) Instruction Set Architecture (ISA) is the contract between the
software and hardware The hardware guarantee certain behavior to the software
according to the ISA • E.g. if an instruction i1 comes before instruction i2, then the effect
of i1 will definitely be reflected when i2 is executed Without changing the ISA, the hardware must extract all the
instruction-level parallelism (ILP) behind the scene yet keeping the promised behavior to software • Very complicated hardware design
Keeping the ISA maintain binary compatibility • Applications compiled to run on an Intel 8086 can still be run on a
modern Intel Core i7!!! Good division of labor easy development
• Change in HW won’t affect SW SW cannot foresee data-dependent run-time behavior of the
program
H. So, Sp10 Lecture 3 - ELEC8106/6102 28
Explicit vs Implicit Exposing the underlying parallel architecture to
software allows software to bear the burden of extracting parallelism from the application • simple hardware • Software can take a long time to do the best job
because it is a one-off effort Any change to the hardware requires major
change to the software tools No division of labor Data-dependent behavior cannot be anticipated
during compile time • SW cannot fully exploit all possible
parallelization opportunities
H. So, Sp10 Lecture 3 - ELEC8106/6102 29
Performance Summary Key to computer performance:
Clock frequency determined by circuit implementations The number of instructions and CPI both depends on the
tight interaction between the compiler and the computer micro-architecture
Implicit parallelism hidden behind the ISA puts the burden on low-level hardware implementations to extract ILP
Explicit parallelism expose underlying architecture to the compiler and leave the burden to software to extract ILP
H. So, Sp10 Lecture 3 - ELEC8106/6102 30
€
L =no. of instrs×CPI
fclk

10.1.31
6
POWER AND ENERGY
H. So, Sp10 Lecture 3 - ELEC8106/6102 31
Power and Energy Power consumption of a circuit is the energy
consumed per unit time Power measure how much energy is being used/
dissipated at any one time • Affects heat dissipation • Affects input power supply • Slightly affect battery lifetime
Energy consumption is the measure of the absolute amount of energy used to perform certain operation • Affects battery capacity • Concerns embedded system designers
Both metrics important for RC designs • Some techniques lower power but not energy
H. So, Sp10 Lecture 3 - ELEC8106/6102 32
Power, Energy and Performance
H. So, Sp10 Lecture 3 - ELEC8106/6102 33
€
Ptotal =α CL ⋅Vsw ⋅Vdd ⋅ fclk( ) + Isc ⋅Vdd + Ileakage ⋅Vdd
Activity factor (amount of circuit
switching)
Load Capacitance
(size of circuit)
Voltage Swing
Supply Voltage
Clock frequency
Dynamic Static
Energy per “operation”
€
Eop ≈ Pdyn / fclk =α ⋅CL ⋅Vsw ⋅Vdd
Total Energy Consumption
€
Etotal = Eop × no. of operations
Power Consumption
Total Run Time
€
Ttotal = no. of operations×CPI / fclk
Dynamic Power Dissipation
Energy stored from Vdd to CL during 01 transition Energy drained from CL to ground during 10 transition In the absence of static/leakage power consumption, the
capacitance keeps the energy stored until discharged
H. So, Sp10 Lecture 3 - ELEC8106/6102 34
Vin Vout
Vdd
CL
€
E0→1 = CLVdd2
€
ER = 12CLVdd
2
€
EC = 12CLVdd
2
Dynamic Power Consumption
Power dissipation depends on data input statistics • The more data transitions, the more power
is consumed
H. So, Sp10 Lecture 3 - ELEC8106/6102 35
€
Pdynamic = Energy/transition× transition rate× P(transition)
= CLVdd2 × fclk ×α
=αCLVdd2 fclk
= CeffVdd2 fclk
Switching activities Both input switches randomly: i.e. 50%
chance that it has 01 transition
Probability that Q has a 01 transition:
H. So, Sp10 Lecture 3 - ELEC8106/6102 36
A B Q=A&B 0 0 0 0 1 0 1 0 0 1 1 1
€
P(Q0→1) =14×34
=316
AND gate

10.1.31
7
Transistor Leakage Transistors are not completely turned off even
when they should be. Main contribution from sub-threshold current
• function of Vth and Vdd
H. So, Sp10 Lecture 3 - ELEC8106/6102 37
Vin = Vdd Vout
Vdd
CL
Ileak
Vin = 0 Vout
Vdd
CL
Ileak Should be OFF
What are the Options?
H. So, Sp10 Lecture 3 - ELEC8106/6102 38
€
Ptotal =α CL ⋅Vsw ⋅Vdd ⋅ fclk( ) + Isc ⋅Vdd + Ileakage ⋅Vdd
Activity factor (amount of circuit
switching)
Load Capacitance
(size of circuit)
Voltage Swing
Supply Voltage
Clock frequency
Dynamic Static
Energy per “operation”
€
Eop ≈ Pdyn / fclk =α ⋅CL ⋅Vsw ⋅Vdd
Total Energy Consumption
€
Etotal = Eop × no. of operations
Power Consumption
Total Run Time
€
Ttotal = no. of operations×CPI / fclk