real-world data is dirty data cleansing and the merge/purge problem hernandez & stolfo: columbia...
TRANSCRIPT

Real-World Data Is Dirty
Data Cleansing and the Merge/Purge ProblemHernandez & Stolfo: Columbia University - 1998
Class Presentation by Rhonda Kost, 06.April 2004

rmk 06.April.2004
TOPICS
IntroductionA Basic Data Cleansing SolutionTest & Real World ResultsIncremental Merge Purge w/ New DataConclusionRecap

Introduction

rmk 06.April.2004
The problem:
Some corporations acquire large amounts of information every monthThe data is stored in many large databases (DB)These databases may be heterogeneous Variations in schema
The data may be represented differently across the various datasetsData in these DB may simply be inaccurate

rmk 06.April.2004
Requirement of the analysis
The data mining needs to be done Quickly Efficiently Accurately

rmk 06.April.2004
Examples of real-world applications
Credit card companies Assess risk of potential new
customers Find false identities
Match disparate records concerning a customer Mass Marketing companies Government agencies

A Basic Data Cleansing Solution

rmk 06.April.2004
Duplicate Elimination
Sorted-Neighborhood Method (SNM)This is done in three phases Create a Key for each record Sort records on this key Merge/Purge records

rmk 06.April.2004
SNM: Create key
Compute a key for each record by extracting relevant fields or portions of fieldsExample:
First Last Address ID Key
Sal Stolfo 123 First Street
45678987
STLSAL123FRST456

rmk 06.April.2004
SNM: Sort Data
Sort the records in the data list using the key in step 1This can be very time consuming O(NlogN) for a good algorithm, O(N2) for a bad algorithm

rmk 06.April.2004
SNM: Merge records
Move a fixed size window through the sequential list of records.This limits the comparisons to the records in the window

rmk 06.April.2004
SNM: Considerations
What is the optimal window size while Maximizing accuracy Minimizing computational cost
Execution time for large DB will be bound by Disk I/O Number of passes over the data set

rmk 06.April.2004
Selection of Keys
The effectiveness of the SNM highly depends on the key selected to sort the recordsA key is defined to be a sequence of a subset of attributesKeys must provide sufficient discriminating power

rmk 06.April.2004
Example of Records and Keys
First Last Address ID Key
Sal Stolfo 123 First Street 45678987 STLSAL123FRST456
Sal Stolfo 123 First Street 45678987 STLSAL123FRST456
Sal Stolpho
123 First Street 45678987 STLSAL123FRST456
Sal Stiles 123 Forest Street
45654321 STLSAL123FRST456

rmk 06.April.2004
Equational Theory
The comparison during the merge phase is an inferential processCompares much more information than simply the keyThe more information there is, the better inferences can be made

rmk 06.April.2004
Equational Theory - Example
Two names are spelled nearly identically and have the same address It may be inferred that they are the same
person
Two social security numbers are the same but the names and addresses are totally different Could be the same person who moved Could be two different people and there is an
error in the social security number

rmk 06.April.2004
A simplified rule in English
Given two records, r1 and r2IF the last name of r1 equals the last name
of r2,AND the first names differ slightly,AND the address of r1 equals the address of r2
THENr1 is equivalent to r2

rmk 06.April.2004
The distance function
A “distance function” is used to compare pieces of data (usually text)Apply “distance function” to data that “differ slightly” Select a threshold to capture obvious typographical errors. Impacts number of successful matches
and number of false positives

rmk 06.April.2004
Examples of matched records
SSN Name (First, Initial, Last)
Address
334600443
334600443
Lisa BoardmanLisa Brown
144 Wars St.144 Ward St.
525520001
525520001
Ramon BonillaRaymond Bonilla
38 Ward St.38 Ward St.
00
Diana D. AmbrosionDiana A. Dambrosion
40 Brik Church Av.40 Brick Church Av.
789912345
879912345
Kathi KasonKathy Kason
48 North St.48 North St.
879912345
879912345
Kathy KasonKathy Smith
48 North St.48 North St.

rmk 06.April.2004
Building an equational theory
The process of creating a good equational theory is similar to the process of creating a good knowledge-base for an expert systemIn complex problems, an expert’s assistance is needed to write the equational theory

rmk 06.April.2004
Transitive Closure
In general, no single pass (i.e. no single key) will be sufficient to catch all matching recordsAn attribute that appears first in the key has higher discriminating power than those appearing after them If an employee has two records in a DB with
SSN 193456782 and 913456782, it’s unlikely they will fall under the same window

rmk 06.April.2004
Transitive Closure
To increase the number of similar records merged Widen the scanning window size, w Execute several independent runs of
the SNM Use a different key each time Use a relatively small window Call this the Multi-Pass approach

rmk 06.April.2004
Transitive Closure
Each independent run of the Multi-Pass approach will produce a set of pairs of recordsAlthough one field in a record may be in error, another field may notTransitive closure can be applied to those pairs to be merged

rmk 06.April.2004
Multi-pass Matches
Pass 1 (Lastname discriminates)KSNKAT48NRTH789 (Kathi Kason 789912345 )KSNKAT48NRTH879 (Kathy Kason 879912345 )
Pass 2 (Firstname discriminates)KATKSN48NRTH789 (Kathi Kason 789912345 )KATKSN48NRTH879 (Kathy Kason 879912345 )
Pass 3 (Address discriminates)48NRTH879KSNKAT (Kathy Kason 879912345 )48NRTH879SMTKAT (Kathy Smith 879912345 )

rmk 06.April.2004
Transitive Equality Example
IF A implies BAND B implies C
THEN A implies CFrom example:789912345 Kathi Kason 48 North St. (A)879912345 Kathy Kason 48 North St. (B)879912345 Kathy Smith 48 North St. (C)

Test Results

rmk 06.April.2004
Test Environment
Test data was created by a database generator Names are randomly chosen from a list of
63000 real names
The database generator provides a large number of parameters: size of the DB, percentage of duplicates, amount of error…

rmk 06.April.2004
Correct Duplicate Detection

rmk 06.April.2004
Time for each run
rmk 06.April.2004
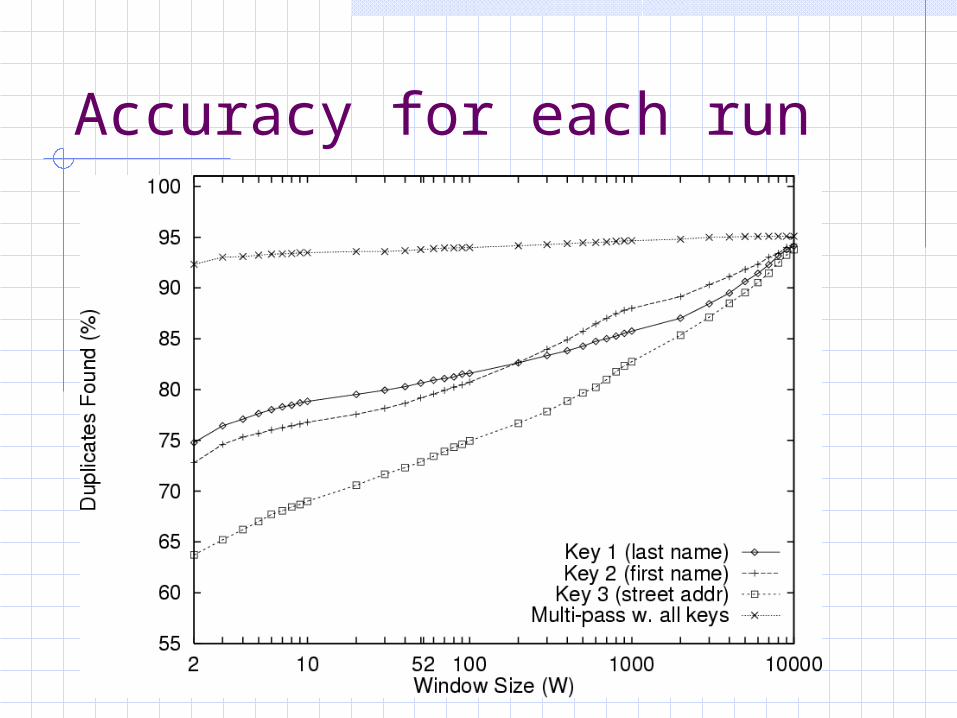
Accuracy for each run

rmk 06.April.2004
Real-World Test
Data was obtained from the Office of Children Administrative Research (OCAR) of the Department of Social and Health Services (State of Washington)OCAR’s goals How long do children stay in foster care? How many different homes do children
typically stay in?

rmk 06.April.2004
OCAR’s Database
Most of OCAR’s data is stored in one relationThe DB contains 6,000,000 total recordsThe DB grows by about 50,000 records per month

rmk 06.April.2004
Typical Problems in the DB
Names are frequently misspelledSSN or birthdays are either missing or clearly wrongCase number often changes when the child’s family moves to another part of the stateSome records use service provider names instead of the child’sNo reliable unique identifier

rmk 06.April.2004
OCAR Equational Theory
Keys for the independent runs Last Name, First Name, SSN, Case
Number First Name, Last Name, SSN, Case
Number Case Number, First Name, Last Name,
SSN

rmk 06.April.2004
OCAR Results

Incremental Merge/Purge w/ New Data

rmk 06.April.2004
Incremental Merge/Purge
Lists are concatenated for first time processingConcatenating new data before reapplying the merge/purge process may be very expensive in both time and spaceAn incremental merge/purge approach is needed: Prime Representatives method

rmk 06.April.2004
Prime-Representative: Definition
A set of records extracted from each cluster of records used to represent the information in the clusterThe “Cluster Centroid” or base element of equivalence class

rmk 06.April.2004
Prime-Representative creation
Initially, no PR existsAfter the execution of the first merge/purge create clusters of similiar recordsCorrect selection of PR from cluster impacts accuracy of resultsNo PR can be the best selection for some clusters

rmk 06.April.2004
3 Strategies for Choosing PR
Random Sample Select a sample of records at random
from each cluster
N-Latest Most recent elements entered in DB
Syntactic Choose the largest or more complete
record

rmk 06.April.2004
Important Assumption
No data previously used to select each cluster’s PR will be deleted Deleted records could require
restructuring of clusters (expensive)
No changes in the rule-set will occur after the first increment of data is processed Substantial rule change could
invalidate clusters.

rmk 06.April.2004
Results
Cumulative running time for the Incremental Merge/Purge algorithm is higher than the classic algorithmPR selection methodology could improve cumulative running time Total running time of the Incremental Merge/Purge algorithm is always smaller

Conclusion

rmk 06.April.2004
Cleansing of Data
Sorted-Neighborhood Method is expensive due to the sorting phase the need for large windows for high accuracy
Multiple passes with small windows followed by transitive closure improves accuracy and performance for level of accuracy increasing number of successful matches decreasing number of false positives

Recap

rmk 06.April.2004
2 major reasons merging large databases becomes a difficult problem: The databases are heterogeneous The identifiers or strings differ in how
they are represented within each DB

rmk 06.April.2004
The 3 steps in SNM are: Creation of key(s) Sorting records on this key Merge/Purge records

rmk 06.April.2004
Prime representative - set of records from cluster considered to be representative of data contained in cluster 3 strategies for selecting a PR: Random Sample N-Latest Syntactic

rmk 06.April.2004
Questions: