real time social data mining rart documento de diseÑo de...
TRANSCRIPT

Real Time Social Data Mining
RART
DOCUMENTO DE DISEÑO DE SOFTWARE
12 de octubre de 2016
Daniel Alejandro Calambás Marín
Jaime Andrés Mendoza Mendoza

1. Historial de Cambios Fecha Descripción del cambio
12/10/2016 Creación del documento.
15/10/2016 Vista lógica del sistema
15/10/2016 Vista física del sistema
16/10/2016 Primera revisión y corrección de errores
22/10/2016 Persistencia
22/10/2016 Comportamiento del sistema
26/10/2016 Segunda revisión y corrección de errores

2. Tabla de Contenidos
Contenido 1. Historial de Cambios ............................................................................................................. 2
2. Tabla de Contenidos .............................................................................................................. 3
3. Lista de Figuras ...................................................................................................................... 4
4. Lista de Tablas ........................................................................ ¡Error! Marcador no definido.
5. Introducción .......................................................................................................................... 5
6. Arquitectura .......................................................................................................................... 6
6.1. Vista Lógica del Sistema ................................................................................................ 6
6.2. Vista Física del Sistema.................................................................................................. 9
6.3. Vista de Procesos del Sistema ..................................................................................... 11
7. Diseño Detallado ................................................................................................................. 13
7.1. Estructura del Sistema ................................................................................................ 13
7.2. Comportamiento del Sistema ..................................................................................... 15
7.3. Persistencia ................................................................................................................. 20
7.4. Interfaz de Usuario ...................................................................................................... 22
8. Referencias .......................................................................................................................... 26

3. Lista de Figuras Figura 1- Diagrama de Arquitectura y Componentes ................................................................... 6
Figura 3 - Diagrama de Despliegue ............................................................................................... 9
Figura 4 - Diagrama BPMN Proceso de Extracción ...................................................................... 11
Figura 5 - Diagrama BPMN Proceso de Consulta ........................................................................ 12
Figura 6 - Diagrama de Clases Componente Extracción de Datos .............................................. 13
Figura 7 - Diagrama de Clases Componente Carga y Transformación de Datos ......................... 14
Figura 8 - Diagrama de Secuencia: Ingresar al Sistema ............................................................... 15
Figura 9 - Diagrama de Secuencia: Ingresar Página (caso id) ...................................................... 15
Figura 10 - Diagrama de Secuencia: Ingresar Página (caso nombre)¡Error! Marcador no
definido.
Figura 11 - Diagrama de Secuencia: Cargar Archivo Páginas ......... ¡Error! Marcador no definido.
Figura 12 - Diagrama de Secuencia: Buscar Publicación ............................................................. 17
Figura 13 - Diagrama de Secuencia: Ver Detalle Publicación ...................................................... 18
Figura 14 - Diagrama de Secuencia: Buscar Página Base de Datos ............................................. 18
Figura 15 - Diagrama de Secuencia: Visualizar Publicaciones Página¡Error! Marcador no
definido.
Figura 16 - Diagrama de Secuencia: Filtrar Publicación .............................................................. 19
Figura 17 - Diagrama de Secuencia: Graficar Reacciones ........................................................... 20
Figura 18 - Diagrama de Persistencia .......................................................................................... 20

4. Introducción Este documento conocido como SDD (por sus siglas en inglés Software Design Document)
contiene la descripción detallada del diseño del Framework RART. Este proyecto es realizado
como trabajo de grado de la carrera de ingeniería de sistemas de la Pontificia Universidad
Javeriana. Este documento es de suma importancia debido a que contiene toda la información
relacionada al diseño del software y es fundamental para conocer la forma en que estará
estructurado.

5. Arquitectura
5.1. Vista Lógica del Sistema A continuación, se presenta el diagrama de arquitectura y componentes el cual hace parte de
la vista lógica del sistema, y permite entender la estructura y funcionamiento del Framework.
Este diagrama corresponde al que se presenta en la figura 1.
Figura 1- Diagrama de Arquitectura y Componentes

Diagrama de Arquitectura y componentes
La arquitectura propuesta para el Framework RART está representada en el diagrama
mostrado en la figura 1 con sus respectivos componentes. Esta arquitectura está basada en el
patrón de Arquitectura en capas y consta de las siguientes capas [1]:
1. Fuente de Datos: esta es la capa que corresponde a la fuente de datos de donde se va
a adquirir información, para el caso de RART, Facebook es la única fuente de datos de
la cual se alimentará el sistema.
2. Extracción de Datos: dentro de esta capa se realiza un proceso ETL en cual consiste en
extraer la información de la fuente, transformara de acuerdo al modelo de la base de
datos y realizar el debido proceso de persistencia. Dentro de esta capa se encuentran
los siguientes componentes:
a. Extracción: este componente se encarga de realizar el proceso de extracción
de información de Facebook por medio del API. Consta de los siguientes
componentes:
i. Controlador extracción: componente encargado de controlar los
procesos de búsqueda y extracción de información de Facebook.
ii. Consultor: componente encargado de hacer consultas y búsquedas de
información dentro de Facebook.
iii. Extractor: componente encargado de realizar extracción masiva de
información de Facebook. Además, este componente proporciona los
datos en bruto al componente de transformación.
b. Transformación: este componente se encarga de transformar la información
extraída de acuerdo al modelo de la base de datos para guardarla dentro de la
base de datos.
i. Recibidor Transformación: este componente es en encargado de
recibir la información extraída de Facebook en bruto para luego
transformarla.
ii. Transformador: este componente recibe la información organizada y
realiza el proceso de transformación y la envía al componente
encargado de la carga.
c. Carga: esta capa se encarga de realizar el proceso de guardar la información
dentro de las dos bases de datos existentes. Consta de los siguientes
componentes:
i. Recibidor Carga: componente encargado de recibir la información
transformada de acuerdo al modelo de la base de datos.
ii. Cargador Mongo DB: componente encargado de realizar la
persistencia de la información semiestructurada dentro de la base de
datos Mongo.
iii. Cargador Solr DB: componente encargado de realizar la persistencia de
la información NO estructurada dentro de la base de datos Solr.
3. Carga y Transformación de Datos: esta capa tiene dos servicios principales, el primero
es brindar – y la segunda es acceder a la base de datos para realizar tareas de consulta
de información dentro de la misma. Dentro de esta capa se encuentran los siguientes
componentes:

a. Prestador de Servicios: esta capa es la encargada de brindar los servicios tanto
de extracción como de consulta de información. Consta del siguiente
componente:
i. Controlador: este componente es en encargado de recibir las
peticiones de extracción de consulta y dirigirlas al componente
encargado de cada tarea.
b. Acceso DB: este componente es en encargado de consultar información
dentro de la base de datos. Consta de los siguientes componentes:
i. Controlador DB: este componente es el encargado de recibir las
peticiones de consulta y además realizar el proceso de orquestar la
extracción de información en las bases de datos.
ii. DB Consultor Mongo DB: este componente es el encargado de extraer
información dentro de la base de datos Mongo de acuerdo a los
parámetros indicados por el componente controlador DB.
iii. DB Consultor Solr DB: este componente es el encargado de extraer
información dentro de la base de datos Solr de acuerdo a los
parámetros indicados por el componente controlador DB.
4. Almacenamiento: esta capa brinda el almacenamiento de la información extraída por
el Framework y es transversal a las capas de Extracción de Datos y Carga y
Transformación de Datos debido a que estas guardan y consultan información en la
base de datos respectivamente. La siguiente figura muestra la estructura en la que se
almacena la información:
a. Mongo DB: dentro de esta base de datos se almacena la información
semiestructurada previamente extraída.
b. SOLR DB: dentro de este motor de búsqueda se realiza el almacenamiento de
la información NO estructurada que tiene relación con la información
semiestructurada de la base de datos Mongo.
5. Visualización e Interfaces: esta capa brinda dos servicios. El primero son los servicios
que se le brindan al usuario por medio de la interfaz gráfica para que éste pueda
realizar tanto procesos de extracción como procesos de consulta de información.
Dentro de esta capa se encuentran los siguientes componentes:
a. Web App: componente encargado de proporcionar las interfaces necesarias
para que el usuario pueda realizar los procesos de consulta y extracción de
información. Consta del siguiente componente:
i. Solicitud: este componente recibe las peticiones de extracción y
consulta por parte del usuario y es quien finalmente le proporciona al
usuario una respuesta de su solicitud.
b. JSON WS: este componente proporciona a otros sistemas consumir por medio
de servicios web realizar procesos de consulta y extracción de información.
Consta del siguiente componente:
i. WS Provider: Es componente proporciona los servicios web de
consulta y extracción de información y es el encargado de convertir la
información a ser entregada en objetos JSON para transferirlos por los
servicios web.

5.2. Vista Física del Sistema Esta vista representa la arquitectura del sistema como una distribución del software en sus
correspondientes componentes de hardware y se visualiza por medio de un diagrama de
despliegue [6] el cual se muestra en la figura 2.
Figura 2 - Diagrama de Despliegue (1)
1. Servidor Facebook: este nodo corresponde al servidor donde se encuentra alojado
Facebook al cual se tiene acceso por el API llamado RESTfb [2] y contiene el siguiente
componente el cual corresponde a la capa de Data Source dentro de la arquitectura:
a. Facebook: Facebook es la aplicación correspondiente a la red social desde la
cual se extrae información.
2. Cliente: este nodo corresponde al computador desde el cual el usuario del sistema
ingresa para realizar procesos de extracción y consulta de información. Contiene los
siguientes componentes:
a. Navegador: corresponde a la aplicación en la cual se mostrará al usuario la
interfaz gráfica del Framework.
b. Consumidor WS: corresponde a la interfaz de un sistema el cual consume, por
medio de servicios web, los servicios que ofrece RART para extraer y consultar
información.
3. Servidor RART: corresponde al servidor de producción en el cual de ejecuta RART.
Consta de los siguientes componentes:
a. GlassFish 4.1: este nodo corresponde al servidor de aplicaciones dentro del
cual se realizará el despliegue de los siguientes componentes de la aplicación,
los cuales corresponden a las capas de la arquitectura lógica anteriormente
mencionadas:
i. Visualización e Interfaces
ii. Extracción de Datos
iii. Carga y Transformación de Datos

b. Mongo DB: corresponde a la base de datos encargada de almacenar la
información semiestructurada.
4. Servidor Solr DB: este es un nodo dedicado el cual contiene la base de datos SOLR y
contiene el siguiente componente:
a. SOLR: corresponde a la base de datos encargada de almacenar la información
NO estructurada.
Otra posible arquitectura propuesta para realizar el despliegue de RART se muestra en la figura
3 y varía en que el motor de búsqueda SolrDB está inmerso dentro del nodo Servidor RART.
Figura 3 - Diagrama de Despliegue (2)
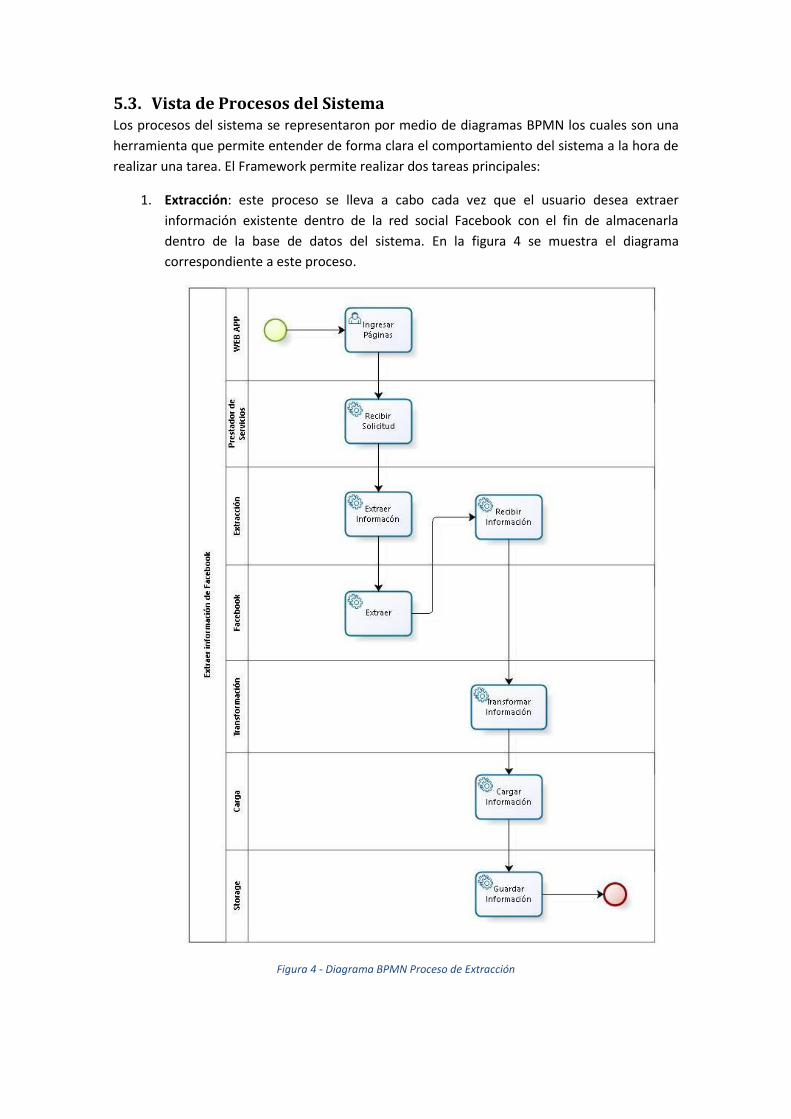
5.3. Vista de Procesos del Sistema Los procesos del sistema se representaron por medio de diagramas BPMN los cuales son una
herramienta que permite entender de forma clara el comportamiento del sistema a la hora de
realizar una tarea. El Framework permite realizar dos tareas principales:
1. Extracción: este proceso se lleva a cabo cada vez que el usuario desea extraer
información existente dentro de la red social Facebook con el fin de almacenarla
dentro de la base de datos del sistema. En la figura 4 se muestra el diagrama
correspondiente a este proceso.
Figura 4 - Diagrama BPMN Proceso de Extracción
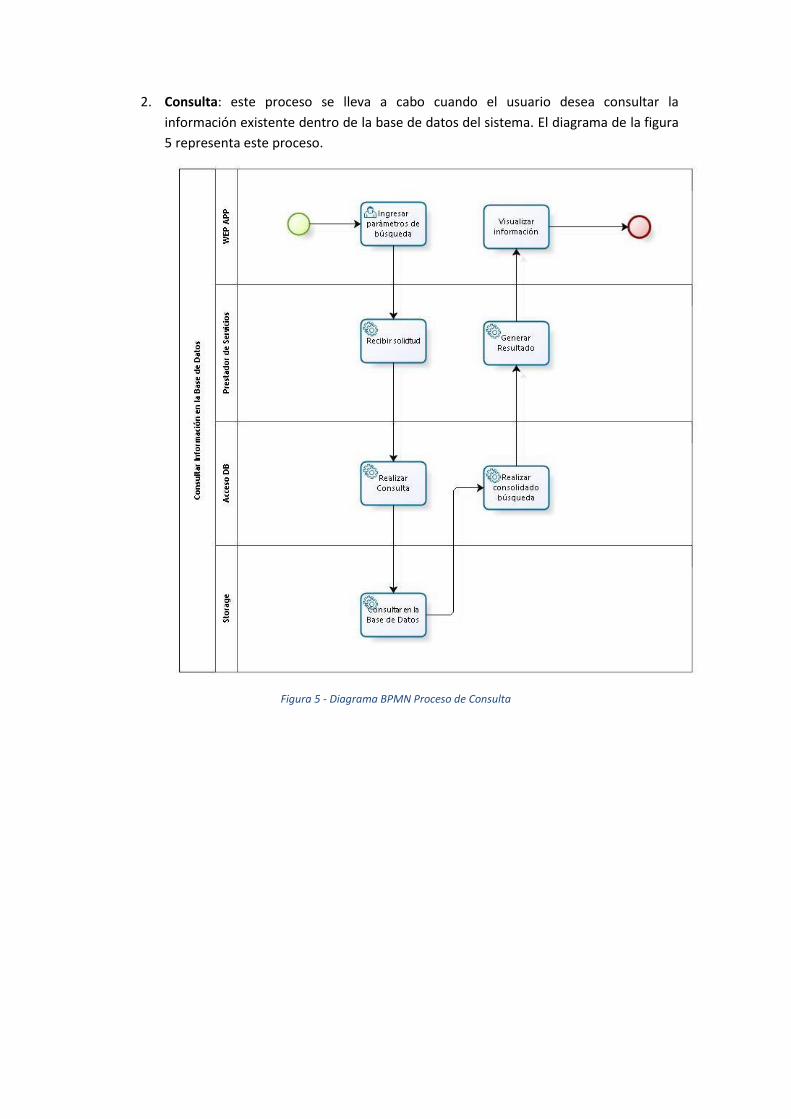
2. Consulta: este proceso se lleva a cabo cuando el usuario desea consultar la
información existente dentro de la base de datos del sistema. El diagrama de la figura
5 representa este proceso.
Figura 5 - Diagrama BPMN Proceso de Consulta

6. Diseño Detallado
6.1. Estructura del Sistema En esta sección se detalla la estructura del sistema por medio de diagramas de clase UML [3]
[4] correspondientes a los distintos componentes del sistema que se describieron en la sección
6.1 Vista Lógica del Sistema:
1. Diagrama de Clases Extracción de Datos: este diagrama muestra las clases que hacen
parte del componente encargado de extraer información de la red social Facebook y
de almacenar dicha información dentro de la base de datos del sistema. Este diagrama
se puede ver en la figura 6.
Figura 6 - Diagrama de Clases Componente Extracción de Datos

2. Diagrama de clases Carga y Transformación de Datos: este diagrama muestra las
clases que hacen parte del componente encargado de extraer información de la base
de datos del Sistema cuando el usuario desea consultarla y se puede apreciar en la
figura 8.
3. Módulo WEB
Figura 7 - Diagrama de Clases Componente Carga y Transformación de Datos
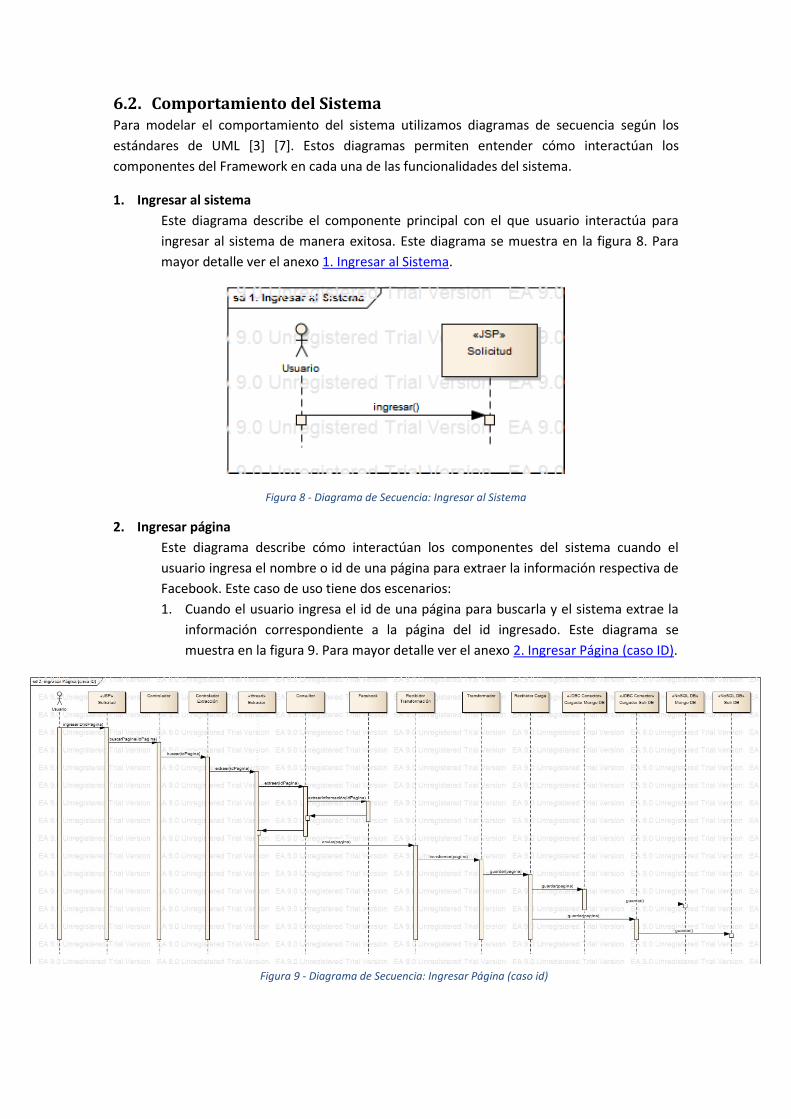
6.2. Comportamiento del Sistema Para modelar el comportamiento del sistema utilizamos diagramas de secuencia según los
estándares de UML [3] [7]. Estos diagramas permiten entender cómo interactúan los
componentes del Framework en cada una de las funcionalidades del sistema.
1. Ingresar al sistema
Este diagrama describe el componente principal con el que usuario interactúa para
ingresar al sistema de manera exitosa. Este diagrama se muestra en la figura 8. Para
mayor detalle ver el anexo 1. Ingresar al Sistema.
Figura 8 - Diagrama de Secuencia: Ingresar al Sistema
2. Ingresar página
Este diagrama describe cómo interactúan los componentes del sistema cuando el
usuario ingresa el nombre o id de una página para extraer la información respectiva de
Facebook. Este caso de uso tiene dos escenarios:
1. Cuando el usuario ingresa el id de una página para buscarla y el sistema extrae la
información correspondiente a la página del id ingresado. Este diagrama se
muestra en la figura 9. Para mayor detalle ver el anexo 2. Ingresar Página (caso ID).
Figura 9 - Diagrama de Secuencia: Ingresar Página (caso id)

2. Cuando el usuario ingresa una palabra que corresponde o está contenida en el
nombre de la página. En este caso el sistema busca dentro de Facebook las páginas
en cuyo nombre se encuentra la palabra ingresada. Este diagrama se muestra en la
figura 10. Para mayor detalle ver el anexo 2. Ingresar Página (caso nombre).
Figura 10 - Diagrama de Secuencia: Ingresar Página (caso nombre)
3. Cargar archivo páginas
Este diagrama es muy similar al del caso de uso anterior, la diferencia es que el usuario
no ingresa la información de una sola fan page, sino que ingresa un archivo TXT con la
información de un conjunto de fan page, ya sean ids o nombres. Este diagrama se
muestra en la figura 11. Para mayor detalle ver el anexo 3. Cargar archivo páginas.
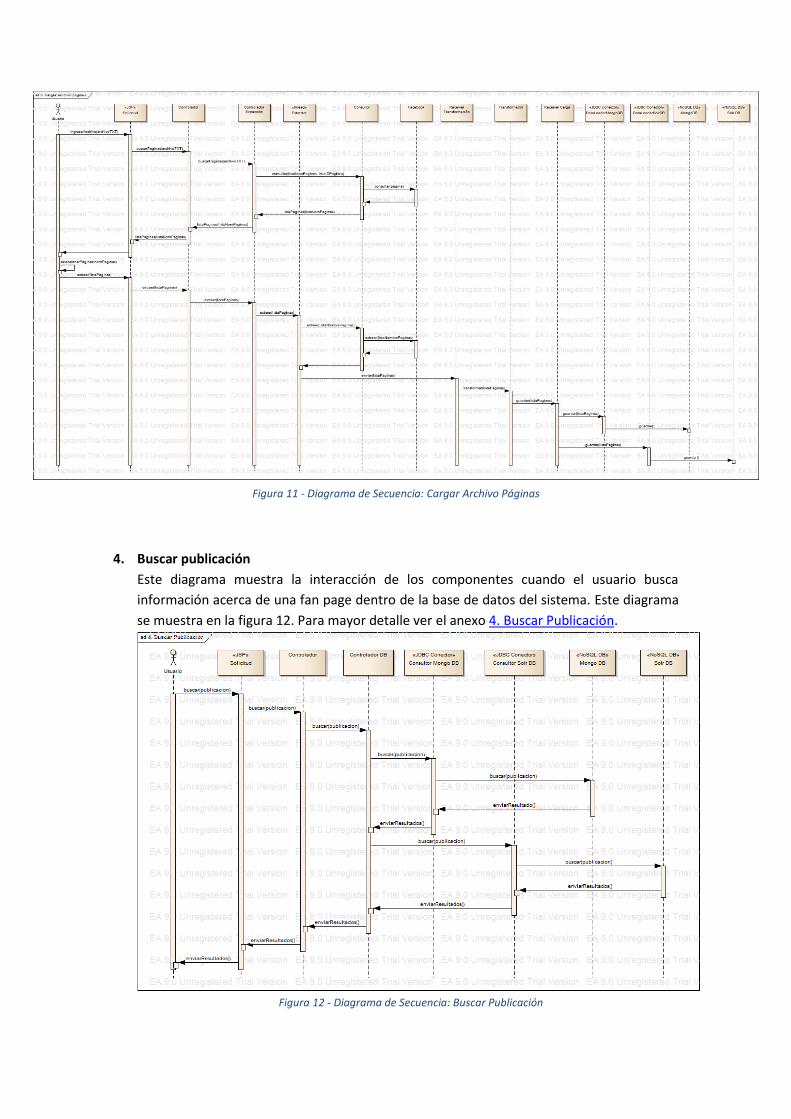
4. Buscar publicación
Este diagrama muestra la interacción de los componentes cuando el usuario busca
información acerca de una fan page dentro de la base de datos del sistema. Este diagrama
se muestra en la figura 12. Para mayor detalle ver el anexo 4. Buscar Publicación.
Figura 12 - Diagrama de Secuencia: Buscar Publicación
Figura 11 - Diagrama de Secuencia: Cargar Archivo Páginas

5. Ver detalle publicación
Este diagrama muestra cómo interactúan los componentes del sistema involucrados en el
caso de uso cuando un usuario quiere visualizar el detalle de una publicación. Este
diagrama se muestra en la figura 13. Para mayor detalle ver el anexo 5. Ver Detalle
Publicación.
Figura 13 - Diagrama de Secuencia: Ver Detalle Publicación
6. Buscar página en la base de datos
Este diagrama muestra la interacción de los componentes encargados de consultar
información dentro de la base de datos cuando el usuario desea ver las publicaciones
existentes dentro de la misma. Este diagrama se muestra en la figura 14. Para mayor
detalle ver el anexo 6. Buscar Página Base de Datos.
Figura 14 - Diagrama de Secuencia: Buscar Página Base de Datos

7. Visualizar publicaciones página
Este diagrama muestra la interacción de los componentes cuando el usuario desea
visualizar las publicaciones de una página previamente buscada. Este diagrama se muestra
en la figura 15. Para mayor detalle ver el anexo 7. Visualizar publicaciones página.
Figura 15 - Diagrama de Secuencia: Visualizar Publicaciones Página
8. Filtrar publicación
Este diagrama muestra los componentes que interactúan cuando el usuario desea filtrar,
por ciertos parámetros, la información de un conjunto de publicaciones previamente
buscadas. Este diagrama se muestra en la figura 16. Para mayor detalle ver el anexo 8.
Filtrar publicación.
Figura 16 - Diagrama de Secuencia: Filtrar Publicación
9. Grafiar reacciones
Este diagrama da a conocer los componentes necesarios para graficar las reacciones de
una publicación escogida por el usuario. Este diagrama se muestra en la figura 17. Para
mayor detalle ver el anexo 9. Grafiar reacciones.

Figura 17 - Diagrama de Secuencia: Graficar Reacciones
6.3. Persistencia Como se ha mencionado anteriormente, RART utiliza dos tecnologías de almacenamiento
Mongo DB y Apache Solr con el fin de almacenar información semiestructurada y no
estructurada respectivamente. En ambas tecnologías la información se almacena en forma de
archivos como se detallará en esta sección.
La figura 18 muestra cómo se estructura y almacena la información dentro de las dos bases de
datos.
Figura 18 - Diagrama de Persistencia
Mongo DB
Dentro de esta base de datos se almacenan los archivos que contiene información
semiestructurada como se describe a continuación:

Página:
1. idPagina: identificador de la fan page dentro de la red social Facebook.
2. nombrePagina: nombre con el que se conoce la fan page dentro de la red
social Facebook.
Publicación: este archivo contiene la información correspondiente a una publicación
realizada por una fan page de la red social Facebook
1. idPublicacion: identificador de la publicación dentro de la red social Facebook.
2. Imagen: imagen adjuntada en la publicación (en caso de tenerla).
Reacción
1. idUsuario: identificador del usuario dentro de la red social Facebook.
2. tipoReacción: tipo de la reacción obtenida en la publicación: Like, Sad, Wow,
Angry, Love, Haha.
3. nombreUsuario: nombre del usuario que reaccionó ante la publicación.
4. fechaReacción: fecha en la que se generó la reacción.
Comentarios
1. idComentario: identificador correspondiente al comentario realizado en una
publicación.
2. idUsuario: identificador del usuario que realizó el comentario en una
publicación.
3. nombreUsuario: nombre del usuario que realizó un comentario en la
publicación.
4. fechaComentario: fecha en la que el usuario realizó el comentario en la
publicación.
Solr
Dentro de esta base de datos se almacena la información no estructurada que corresponde al
mensaje escrito por una fan page en una publicación realizada y a los comentarios realizados
por los usuarios en las publicaciones:
Publicación
1. idPagina: identificador de la fan page dentro de la red social Facebook.
2. idPublicación: identificador de la publicación dentro de la red social Facebook.
3. mensaje: texto que hace parte de la publicación realizada por la fan page.
Comentario
1. idPublicacion: identificador de la publicación dentro de la red social Facebook.
2. idComentario: identificador correspondiente al comentario realizado en una
publicación.
3. comentario: texto que corresponde a un comentario realizado por un usuario
en una publicación.

6.4. Interfaz de Usuario Las interfaces gráficas diseñadas, brindan a los usuarios de RART acceder a las funcionalidades
que el Framework ofrece.
1. Página principal
La ilustración 19 muestra la página principal de RART. En ella se encuentra un menú en
la parte izquierda el cual proporciona al usuario la facilidad de acceder a las principales
funcionalidades del Framework: Extraer Información, Buscar Información, Actualizar
Información y Configuraciones.
Figura 19 - Página Principal RART
2. Menú Extraer Información
Este menú, visualizado en la ilustración 20, permite al usuario realizar las tareas de
extracción de información de la red social Facebook. Dentro de este menú se
encuentran tres botones:
1. Buscar página por ID: este botón permite al usuario ingresar a la funcionalidad
de ingresar un ID de una página existente dentro de la red social Facebook con
el fin de extraer la información de sus publicaciones.
2. Buscar Página por Nombre: este botón permite al usuario ingresar a la
funcionalidad de ingresar una palabra para que el sistema busque dentro de la
red social Facebook las páginas existentes que contengan la palabra ingresada
dentro de su nombre.
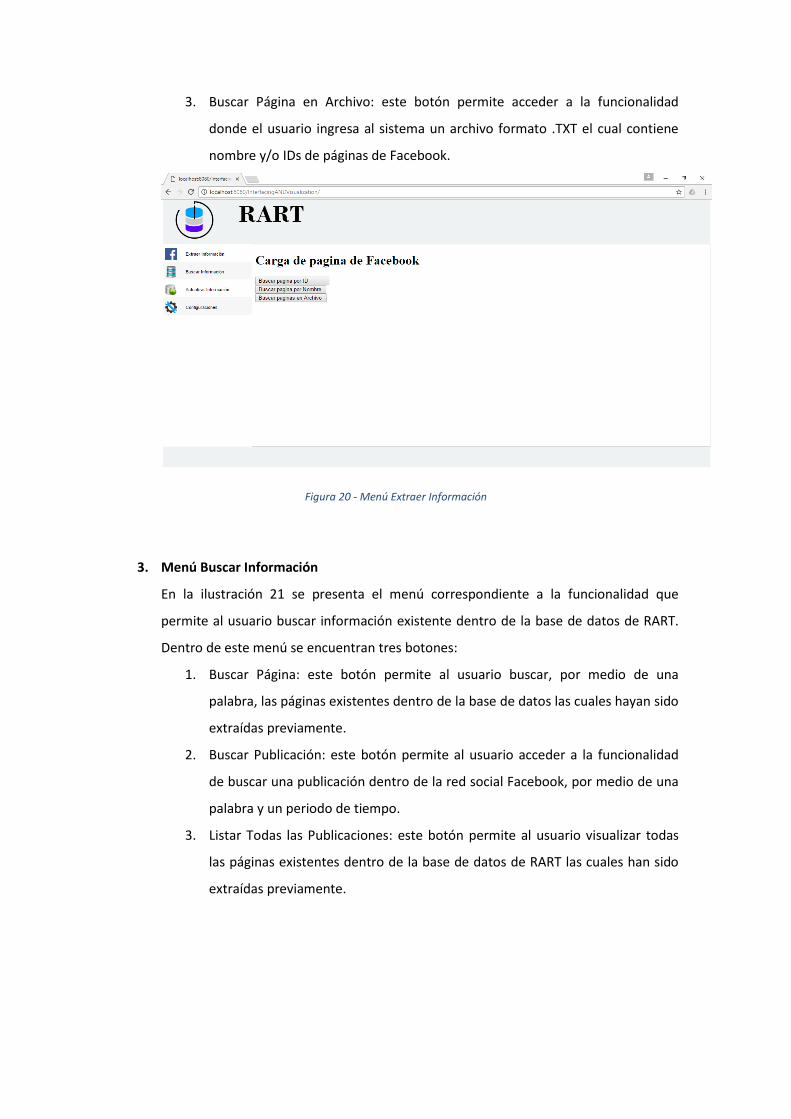
3. Buscar Página en Archivo: este botón permite acceder a la funcionalidad
donde el usuario ingresa al sistema un archivo formato .TXT el cual contiene
nombre y/o IDs de páginas de Facebook.
Figura 20 - Menú Extraer Información
3. Menú Buscar Información
En la ilustración 21 se presenta el menú correspondiente a la funcionalidad que
permite al usuario buscar información existente dentro de la base de datos de RART.
Dentro de este menú se encuentran tres botones:
1. Buscar Página: este botón permite al usuario buscar, por medio de una
palabra, las páginas existentes dentro de la base de datos las cuales hayan sido
extraídas previamente.
2. Buscar Publicación: este botón permite al usuario acceder a la funcionalidad
de buscar una publicación dentro de la red social Facebook, por medio de una
palabra y un periodo de tiempo.
3. Listar Todas las Publicaciones: este botón permite al usuario visualizar todas
las páginas existentes dentro de la base de datos de RART las cuales han sido
extraídas previamente.

Figura 21 - Menú Buscar Información
4. Menú Actualizar Información
Esta funcionalidad permite al usuario actualizar toda la información existente dentro
de la base de datos. Como se muestra en la ilustración 22, cuando el usuario oprime el
botón correspondiente, el sistema empieza a actualizar toda la información de las
páginas y sus respectivas publicaciones existentes dentro de la base de datos con la
información de Facebook.
Figura 22 - Actualizar Información

5. Menú Configuraciones
Como se muestra en ilustración 23, esta funcionalidad permite al usuario configurar en
el sistema el token de acceso a Facebook, y las IDs y puertos correspondientes a
Mongo DB y Solr DB. Esta información se encuentra detallada en el anexo Manual de
Instalación y Configuración.
Figura 23 - Menú Configuraciones

7. Referencias [1]. Pääkkönen, P., & Pakkala, D. (2015). Reference architecture and classification of
technologies, products and services for big data systems. Big Data Research, 2(4),
166-186.
[2]. Restfb 2016. RestFB is a simple and flexible Facebook Graph API client written in Java.
It is open source software released under the terms of the MIT License.
http://restfb.com/
[3]. Larman, C. (1999). UML y Patrones. Pearson.
[4]. The Unified Modeling Language (2009-2016). UML Class and Object Diagrams
Overview. Recuperado de http://www.uml-diagrams.org/class-diagrams-
overview.html
[5]. The Unified Modeling Language (2009-2016). UML Component Diagrams. Recuperado
de http://www.uml-diagrams.org/component-diagrams.html
[6]. The Unified Modeling Language (2009-2016). Deployment Diagrams Overview.
Recuperado de http://www.uml-diagrams.org/deployment-diagrams-overview.html
[7]. The Unified Modeling Language (2009-2016). UML Sequence Diagrams. Recuperado de
http://www.uml-diagrams.org/sequence-diagrams.html