real-time analytics with kafka, cassandra and storm
TRANSCRIPT

REAL-TIME ANALYTICS WITH KAFKA, CASSANDRA
& STORM
Dr. John GeorgiadisModio Computing

Modio Computing
USE CASES• Collecting/processing measurements from large
sensor networks (e.g. weather data).
• Aggregated processing of financial trading streams.
• Customer activity monitoring for advertising purposes, fraud detection, etc.
• Real-time security log processing.

Modio Computing
SOLUTION APPROACH
• Real-time Updates: Employ streaming instead of batch analytics.
• Apache Storm: Large installation base. Streaming & micro-batch.
• Apache Spark: Uniform API for batch & micro-batch. On top of YARN/HDFS. Micro-batch less mature but catching-up quickly.
• Large data sets + Time Series + Write-Intensive + Data Expiration = Apache Cassandra

Modio Computing
ARCHITECTURE

Modio Computing
APACHE KAFKA• N Nodes
• T Topics
• Replication Factor: Defines high availability
• Partitions: They define parallelism level. A single consumer per partition.
• Consumer discovers cluster nodes through Zookeeper
• Consumer partition state is just an integer: the partition offset.

Modio Computing
STORM
• Storm is a distributed computing platform. In Storm a distributed computation is a directed graph of interconnected processors (topology) that exchange messages.
• Spouts: Processors that inject messages into the topology.
• Bolts: Processors that process messages including sending to 3rd parties (.e.g persistence).
• Trident: High-level operations on message batches. Support batch replay in case of failure. Translates to a graph of low-level spouts and bolts.

Modio Computing
STORM :: NIMBUS• A single controller (Nimbus)
where topologies are submitted. Nimbus breaks topologies in tasks and forwards to supervisors which spawn one or more workers(processes) per task.
Nimbus redistributes tasks in case a supervisor fails.
Nimbus is not HA. If Nimbus fails, running topologies are not affected.

Modio Computing
STORM :: SUPERVISOR• 1 supervisor per host.
• Supervisor registers with ZK at startup and thus it’s discoverable by Nimbus.
• Supervisor spawns Worker JVMs: one process per topology.
• JAR submitted to Nimbus is copied to Worker classpath.
• When a Supervisor dies, all Worker tasks are migrated to the remaining Supervisors.

Modio Computing
STORM :: TRIDENT• When to use Micro-batch (aka Trident) instead
of Streaming.
• Millisecond latency not required. Typical Trident latency threshold: 500ms.
Allows batch mode persistence operations.
High-level abstractions: partitionBy, partitionAggregate, stateQuery, partitionPersist.
Batch processing timeout/exception will cause a replay of the batch provided the Spout supports replays (Kafka does): At-least-once semantics.

Modio Computing
STORM :: PARALLELISM• Parallelism = Number of threads executing a topology cluster-wide.
• Parallelism <= CPU threads/worker x Workers
• Define per-topology max #workers (explicitly) and max parallelism (implicitly).
• Define explicitly topology step parallelism. Max parallelism = Σ(step parallelism).
• Trident merges multiple steps into the same thread/node. Last parallelism statement is the effective parallelism.
• Repartition operations define step merging boundaries.
• Repartition operations (shuffle, partitionBy, broadcast, etc.) imply network transfer and are expensive. In some cases they are disastrous to performance!

Modio Computing
STORM :: PERFORMANCE TUNING• Spouts must match upstream parallelism: one spout per Kafka partition.
• Little’s Law: Batch Size = Throughput x Latency
• Adjust batch size: (Kafka Partitions) x (Kafka fetch size)Larger batch size = {higher throughput, higher latency}Increase batch size gradually until latency starts increasing sharply.
• Identify the slowest stage (I/O or CPU bound):
• You can’t have better throughput than the throughput of your slowest stage.
• You can’t have better latency than the sum of individual latencies.
• If CPU bound, increase parallelism. If I/O bound increase downstream (i.e storage) capacity.

Modio Computing
CASSANDRA :: THE GOOD• Great write performance. Decent read performance.
• Write latency: 20μs-120μs
• 15K writes/sec on a single node
• Extremely stable. Very low record of data corruption.
• Decentralized setup: all cluster nodes have the same setup.
• Multi-datacenter setups.
• Configurable consistency of updates: ONE, QUORUM, ALL.
• TTL per cell (row & column).
• Detailed metrics: #operations, latencies, thread pools, memory, cache performance.

Modio Computing
CASSANDRA :: THE “FEATURES”• All partition keys must be set in queries.
• All primary keys preceding an initialized primary key with a value must also be initialized in queries.
• TTL is not allowed on cells containing counters.
• NULL values are not supported on primary keys.
• Range queries can only be applied on the last column of the composite primary key that appears in the query.
• Disjunction operator (OR) is not available. The IN keyword can be used in some cases instead.
• Row counting is a very expensive operation.

Modio Computing
CASSANDRA :: PERFORMANCE• Design the schema around the partition key.
• Keep each partition size small (no more than a few 100s entry) as reading will fetch the whole partition.
• Leverage Key cache
• Avoid making time fragments part of the partition key as this will direct all activity to the node that is the partition owner at a given date.
• Query/Update Plan:
• Avoid range queries and the IN operator as it requires contacting multiple nodes and assembling the results at the coordinator node.
• Use prepared statements to avoid repeated statement parsing.
• Prefer async writes combined with a max pending statements threshold.
• Best performance out of batches containing statements with the same partition key.
Modio Computing
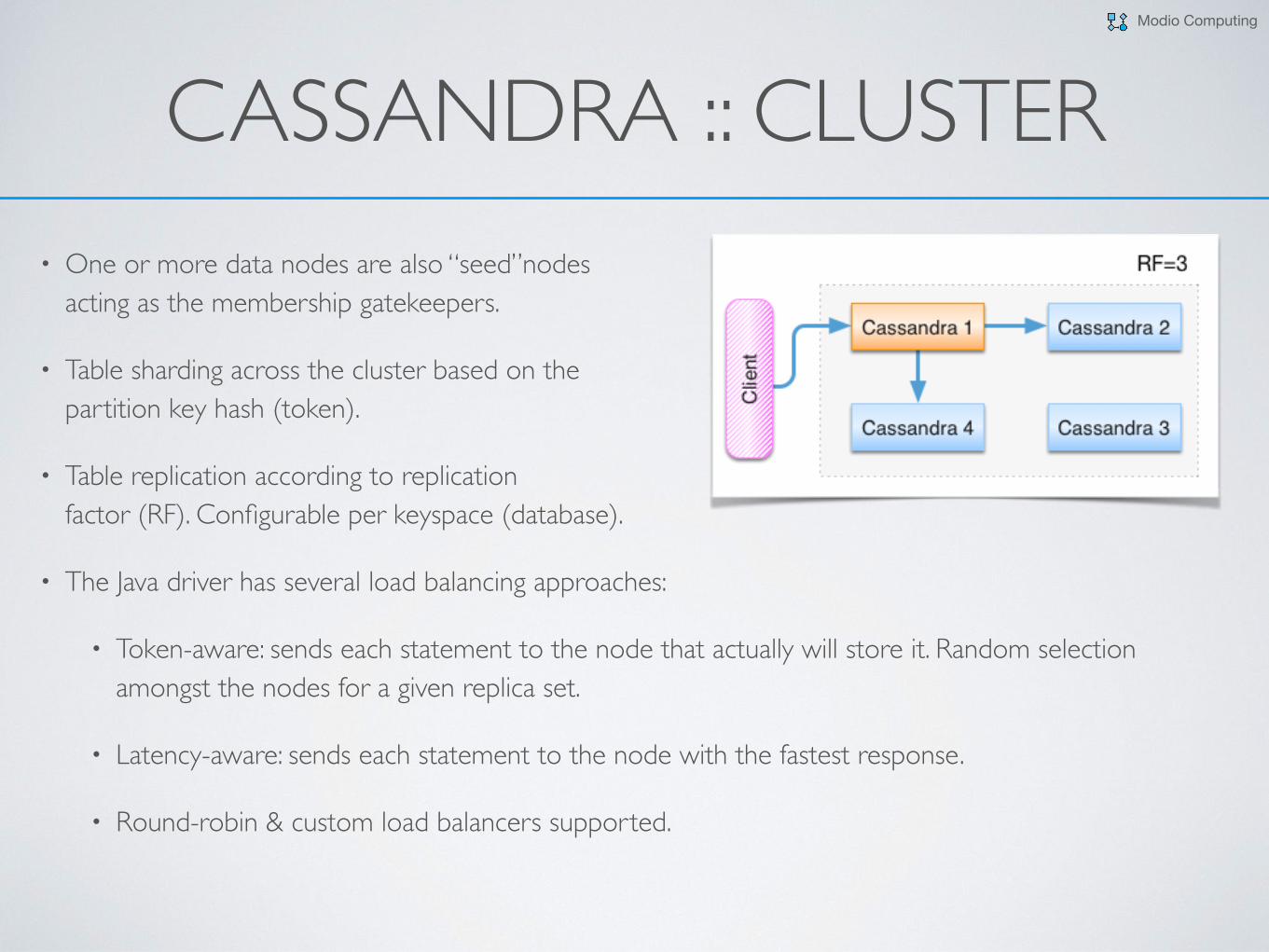
CASSANDRA :: CLUSTER• One or more data nodes are also “seed”nodes
acting as the membership gatekeepers.
• Table sharding across the cluster based on the partition key hash (token).
• Table replication according to replication factor (RF). Configurable per keyspace (database).
• The Java driver has several load balancing approaches:
• Token-aware: sends each statement to the node that actually will store it. Random selection amongst the nodes for a given replica set.
• Latency-aware: sends each statement to the node with the fastest response.
• Round-robin & custom load balancers supported.

Modio Computing
• Kafka
• N-way replication: N-1 node failures.
• Clients dynamically reconfigured if accessing through Zookeeper.
• Storm
• For cluster size N, X supervisor failures provided (N-X) nodes have memory to accommodate X JVM worker processes.
• Incomplete batches replayed: At-least-once semantics.
• Cassandra
• N-way replication: N-1 node failures if using ONE consistency, if using QUORUM consistency.
• Clients require a list of all cluster nodes.
• Zookeeper
• Majority voting is required: At most F failures in cluster with 2F+1 nodes. Leader re-election very fast (200ms).
• Sizes bigger than 3-5 not recommended due to decreasing write performance.
• If majority voting is lost, Storm will stop. Kafka will fail to commit client offsets. If majority is regained Storm will resume. Kafka brokers will resume in most cases.
FAILURE SCENARIOS