rdma on vsphere - vmware octo · 4 why rdma: performance ultra low latency •< 1 microsecond...
TRANSCRIPT

© 2010 VMware Inc. All rights reserved
Ultra-Low Latency on vSphere with RDMA
Bhavesh Davda, Office of CTO
VMworld 2012, August 28th, 2012

2
Agenda
RDMA primer
RDMA based applications
Options for RDMA access in vSphere virtual machines
RDMA advantages for vSphere hypervisor services
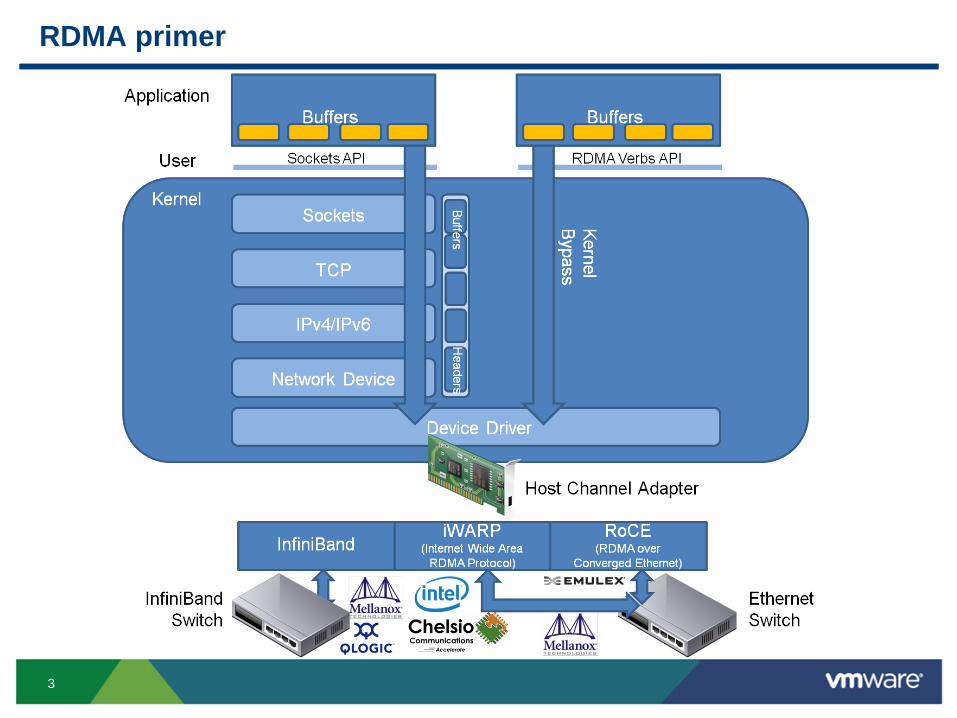
3
RDMA primer

4
Why RDMA: performance
Ultra low latency
• < 1 microsecond one-way for small messages with Mellanox CX3 FDR HCA in
bare-metal (non-virtualized) environment
High throughput
• > 50 Gbps one-way for large messages with Mellanox CX3 PCIe3 FDR HCA in
bare-metal (non-virtualized) environment
CPU efficiency
• Offloads CPU of running any protocol stack in software, freeing up the CPU to
either lower power consumption or run other useful tasks

5
Who uses RDMA: bare-metal applications
High performance computing applications relying on various
message passing libraries like MPI
Clustered databases
• IBM DB2 pureScale
• Oracle ExaData/RAC
Distributed filesystems
• IBM GPFS
• Open source Lustre
• Red Hat Storage Server (GlusterFS)
Distributed caches
• Dell (RNA Networks)
Financial trading applications
BigData (Hadoop: Mellanox Unstructured Data Accelerator)

6
Options for RDMA access to vSphere virtual machines
1. Full-function DirectPath I/O (passthrough)
2. SR-IOV VF DirectPath I/O (passthrough)
3. Paravirtual RDMA HCA (vRDMA) offered to VM

7
Full-function DirectPath I/O
Direct assign physical RDMA HCA
(IB/RoCE/iWARP) to VM
Physical HCA cannot be shared
between VMs or by the ESXi
hypervisor
DirectPath I/O is incompatible with
many important vSphere features:
• Memory Overcommit, Fault Tolerance, Snapshots, Suspend/Resume, vMotion
I/O MMU
Physical RDMA HCA
Guest OS
Device Driver (RDMA HCA)
Virtualization
Layer
RDMA
Stack

8
SR-IOV VF DirectPath I/O
Single-Root IO Virtualization (SR-
IOV): PCI-SIG standard
Physical (IB/RoCE/iWARP) HCA
can be shared between VMs or by
the ESXi hypervisor
• Virtual Functions direct assigned to VMs
• Physical Function controlled by hypervisor
Still DirectPath I/O, which is
incompatible with many important
vSphere features
RDMA HCA
VF Driver
RDMA HCA
VF Driver
I/O MMU
PF Device
Driver
VF VF VF
PF SR-IOV
RDMA HCA
Guest OS
RDMA HCA
VF Driver
Guest OS Guest OS
Virtualization
Layer
RDMA
stack
RDMA
stack
RDMA
stack
RDMA HCA
VF Driver
RDMA HCA
VF Driver

9
Paravirtual RDMA HCA (vRDMA) offered to VM
New paravirtualized driver in
Guest OS
• Implements “Verbs” interface
RDMA emulated in ESXi
hypervisor
• Translates Verbs from Guest to Verbs to ESXi “RDMA Stack”
• Guest physical memory regions mapped to ESXi and passed down to physical RDMA HCA
• Zero-copy DMA directly from/to guest physical memory
• Completions/interrupts “proxied” by emulation
vRDMA HCA Device Driver
Physical RDMA HCA
Device Driver
Physical RDMA HCA
vRDMA Device Emulation
Guest OS RDMA
stack
ESXi RDMA
stack I/O
Stack

10
Performance Comparison

11
InfiniBand with DirectPath I/O

12
InfiniBand with DirectPath I/O
RDMA Performance in Virtual Machines with QDR InfiniBand on vSphere 5
http://labs.vmware.com/publications/ib-researchnote-apr2012

13
Summary: VM/Guest level RDMA
Full function DirectPath I/O already used by some customers
SR-IOV DirectPath I/O supported in vSphere 5.1
vRDMA paravirtual driver/device being prototyped in Office of CTO

14
RDMA advantages for vSphere hypervisor services
10 GbE
Virtual Switch
RDMA
stack
10/40 GbE (RoCE)
VM VM VM
ESXi
hypervisor

15
vMotion using RDMA transport
vMotion: live migration of virtual machines
• Key enabler for Distributed Resource Scheduler (DRS) and Distributed Power
Management (DPM)
vMotion data transfer mechanism
• Currently network (TCP/IP/BSD sockets/mbufs) based
Why RDMA? Performance
• Zero copy send & receive == Reduced CPU utilization
• Lower latency
• Eliminate TCP/IP protocol & processing overheads

16
Test setup
Two HP ProLiant ML 350 G6 machines, 2x Intel Xeon (E5520,
E5620), HT enabled, 60 GB RAM
Mellanox 40GbE RoCE cards
• ConnectX-2 VPI PCIe 2.0 x8, 5.0 GT/s
SPECjbb2005 50GB workload
• 56 GB, 4 vCPU Linux VM
• Run-time config switch for TCP/IP or RDMA transport
• Single stream helper for RDMA transport vs. two for TCP/IP transport

17
Total vMotion Time (seconds)
70.63
45.31
0
10
20
30
40
50
60
70
80
TCP/IP RDMA
36 % faster

18
Precopy bandwidth (Pages/sec)
330,813.66
432,757.73
0 50000 100000 150000 200000 250000 300000 350000 400000 450000 500000
TCP/IP
RDMA
30% Higher
14.18 Gbps
10.84 Gbps

19
CPU Utilization
0:00 0:05 0:11 0:16 0:21 0:26 0:31 0:36 0:41 0:46 0:51 0:56 1:01 1:06 1:11 1:16
TCP/IP 0 20.11 46.38 46.13 46.58 41.68 46.38 43.69 42.53 42.64 38.69 33.53 33.93 33.49 39.68 35.13
RDMA 0 5.58 5.92 6.24 6.11 5.73 5.71 5.96 3.92 3.83
0
5
10
15
20
25
30
35
40
45
50
% C
ore
Uti
liza
tio
n u
se
d b
y v
Mo
tio
n
92% Lower
Destination CPU utilization 92% lower
Source CPU utilization 84% lower

20
Overall summary
Hypervisor-level RDMA
• Proven benefits for hypervisor services (vMotion, etc.)
• Currently under discussion internally
Passthrough InfiniBand delivers credible performance
Paravirtual vRDMA most attractive option for VM-level RDMA
• Maintains key virtualization capabilities
• Delivers better latencies than other approaches
• Prototyping underway

21
Acknowledgements
VMware
• Adit Ranadive (Intern), Anupam Chanda, Gabe Tarasuk-Levin, Josh Simons,
Margaret Petrus, Scott Goldman
Mellanox
• Ali Ayoub, Dror Goldenberg, Gilad Shainer, Liran Liss, Michael Kagan, Motti
Beck
System Fabric Works:
• Bob Pearson, Paul Grun