raw 2014 over-clocking of linear projection designs through device specific optimisations rui...
TRANSCRIPT

RAW 2014
Over-Clocking of Linear Projection Designs Through Device Specific Optimisations
Rui Policarpo Duarte1, Christos-Savvas Bouganis [email protected], [email protected]
Department of Electrical and Electronic EngineeringImperial College London, United Kingdom
1Would like to thank the support from Fundação para a Ciência e Tecnologia (Foundation for Science and Technology in Portugal) through PhD grant SFRH/BD/69587.
21st Reconfigurable Architectures Workshop May 19-20, 2014, Phoenix, USA

RAW 2014
2
Introduction
Ever increasing demand for DSP applications processing more data and faster
Linear Projection is a widely adopted algorithm in DSP applications
FPGAs offer high performance, low-power, reconfigurabillity and small size implementation

RAW 2014
3
Introduction Linear Projection examples:
Data compression, face recognition, synthetic apperture radar (high-performance) EEG, ECG (low-power)
Images from http://eeg.neurophysiology.ca/, http://groups.psych.northwestern.edu/mbeeman/PLoS_Supp.htm, http://radar.kharkov.com/images/products/Frame_Stitching.gif

RAW 2014
4
KLT Algorithm Karhunen-Loéve Transform
Describe data from a higher dimensional space in a smaller one using an orthogonal basis matrix Λ.
N data points in original space: Projected data points: Recover data in the original space via: Using the Λ that best describes the data by
minimising the objective function:
RAW 2014
5
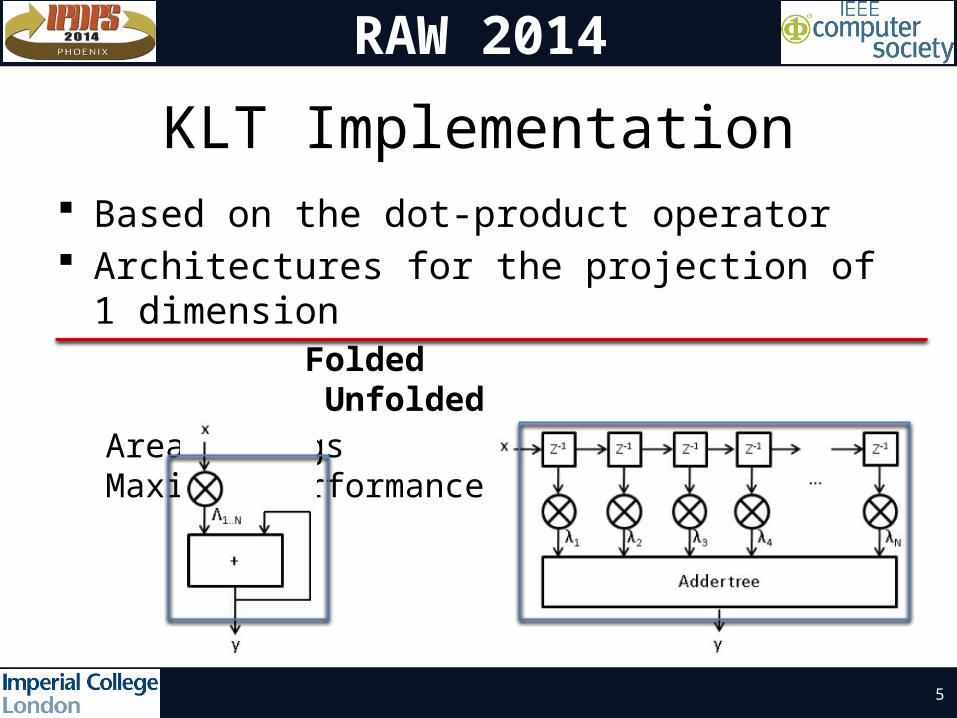
KLT Implementation Based on the dot-product operator Architectures for the projection of 1
dimension Folded UnfoldedArea savings Maximum performance

RAW 2014
6
Extreme Over-Clocking
Tools are conservative in their estimates
Go beyond error-free regime tested on the board
Applications that can tolerate some errors.
RAW 2014
7
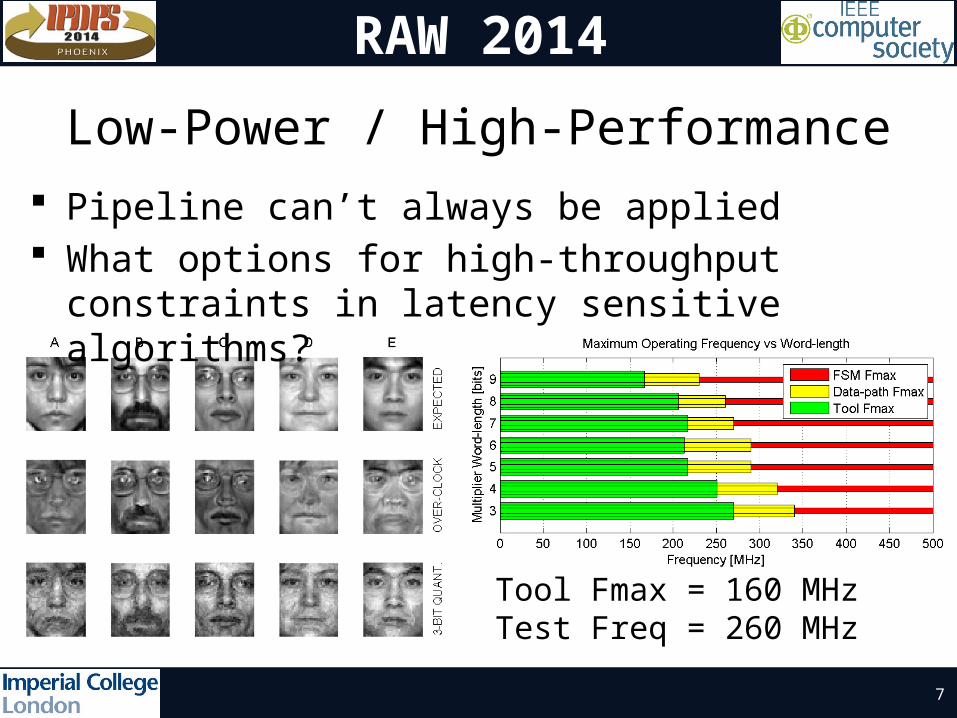
Low-Power / High-Performance Pipeline can’t always be applied What options for high-throughput constraints
in latency sensitive algorithms?
Tool Fmax = 160 MHzTest Freq = 260 MHz

RAW 2014
8
Optimisation Framework (OF)
• Pre-characterisation of the arithmetic units under over-clocking
• Error and area models• Problem parameters
+ input data• Output VHDL with
values for coefficients
• Generic RTL
RAW 2014
9
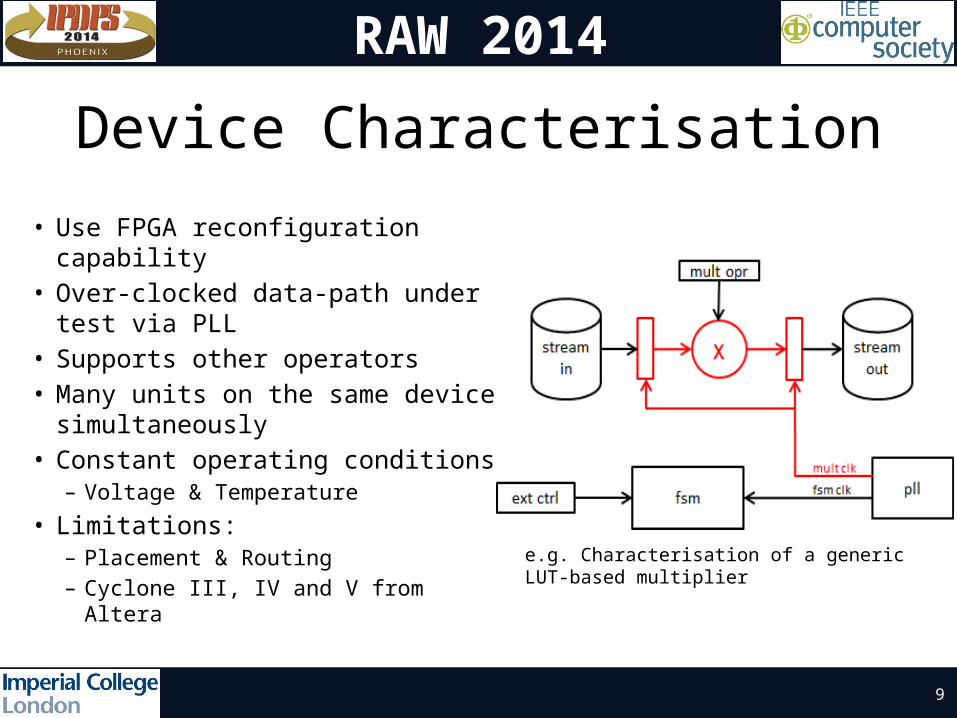
Device Characterisation
• Use FPGA reconfiguration capability
• Over-clocked data-path under test via PLL
• Supports other operators • Many units on the same device
simultaneously• Constant operating conditions
– Voltage & Temperature
• Limitations:– Placement & Routing– Cyclone III, IV and V from Altera
e.g. Characterisation of a generic LUT-based multiplier
RAW 2014
10
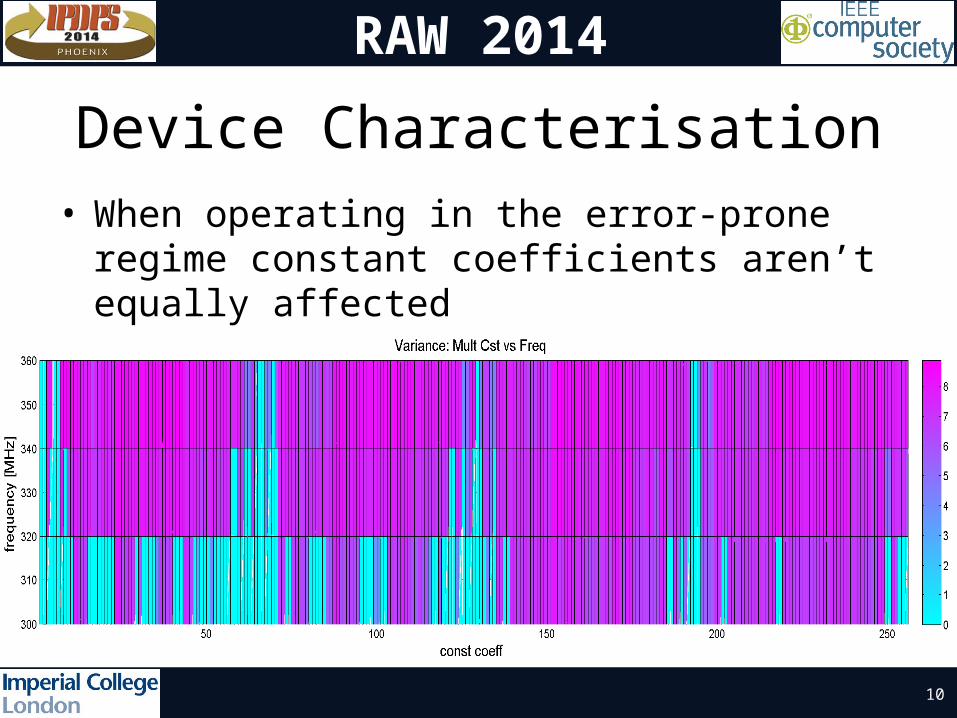
Device Characterisation• When operating in the error-prone regime
constant coefficients aren’t equally affected
• Gap in performance more than 60 MHz

RAW 2014
11
Device CharacterisationConstant coefficient 222
Differencies in the error profiles for both locations due to varation in placement and routing and process variation

RAW 2014
12
Design Generation Bayesian Factor Analysis model
assumes error terms are independent and multivariate normally distributed with zero mean
Probability for each observed case:
As a result of a linear projection:
The framework iteratively samples, from a posterior distribution, (Gibbs) projection vectors for different word-lengths,
Selects the ones that minimise the objective function (i.e. MSE of back-projection)

RAW 2014
13
Test Case• Linear Projection Z6 to Z3
– Folded dot-product operator
• Data sets:– Model: 100 cases– Test: 5k cases
• Reference design: KLT• KLT Fmax: 160MHz • Target clock frequency: 310 MHz – 1.85x speedup
RAW 2014
14
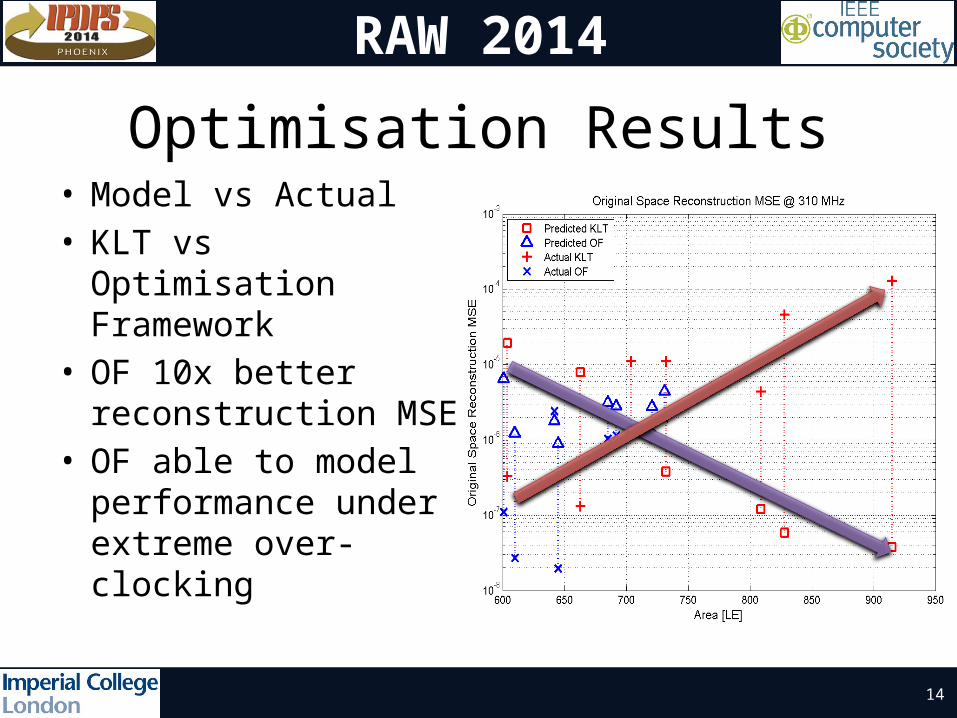
Optimisation Results• Model vs Actual• KLT vs Optimisation
Framework• OF 10x better
reconstruction MSE• OF able to model
performance under extreme over-clocking
RAW 2014
15
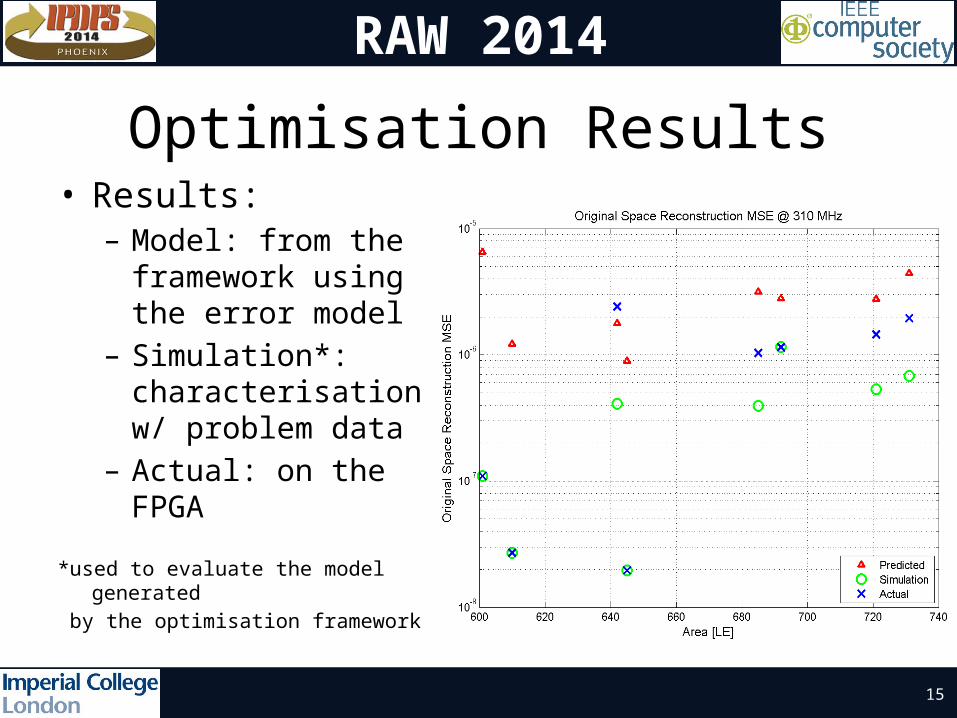
Optimisation Results• Results:– Model: from the
framework using the error model
– Simulation*: characterisation w/ problem data
– Actual: on the FPGA
*used to evaluate the model generated
by the optimisation framework

RAW 2014
16
Conclusions
Novel unified methodology for implementation of extreme over-clocked Linear Projection designs on FPGAs
It combines the problem of data approximation and error minimisation under over-clocking
Performed better than typical implementation without extra resources
Demonstrated at 1.85x the maximum clock frequency while providing best area-errors tradeoff

RAW 2014
17
Ongoing Developments Low-power Designs (voltage variation) Variation of operating temperatures
Temperature is very expensive to control and its variation changes the error models
DSP-based arithmetic units Fixed P&RRui Policarpo Duarte, Christos-Savvas Bouganis, A Unified Framework for Over-Clocking Linear Projections on FPGAs under PVT Variation., pp. 49-60, 2014, ARC, http://dx.doi.org/10.1007/978-3-319-05960-0_5
Bayesian formulation of other problems (e.g. FIR)
Acceleration of the sampling process

RAW 2014
18
Thank you
• Questions/Comments ?