qubole - big data in cloud
TRANSCRIPT

AUG 05, 2016
Qubole - Big Data in CloudKiryl Sultanau

2CONFIDENTIAL
BIG DATA CHALLENGES

3CONFIDENTIAL
BIG DATA BELONGS TO THE CLOUD

4CONFIDENTIAL
BIG DATA BELONGS TO THE CLOUD

5CONFIDENTIAL
BIG DATA BELONGS TO THE CLOUD

6CONFIDENTIAL
QUBOLE HISTORY
7CONFIDENTIAL
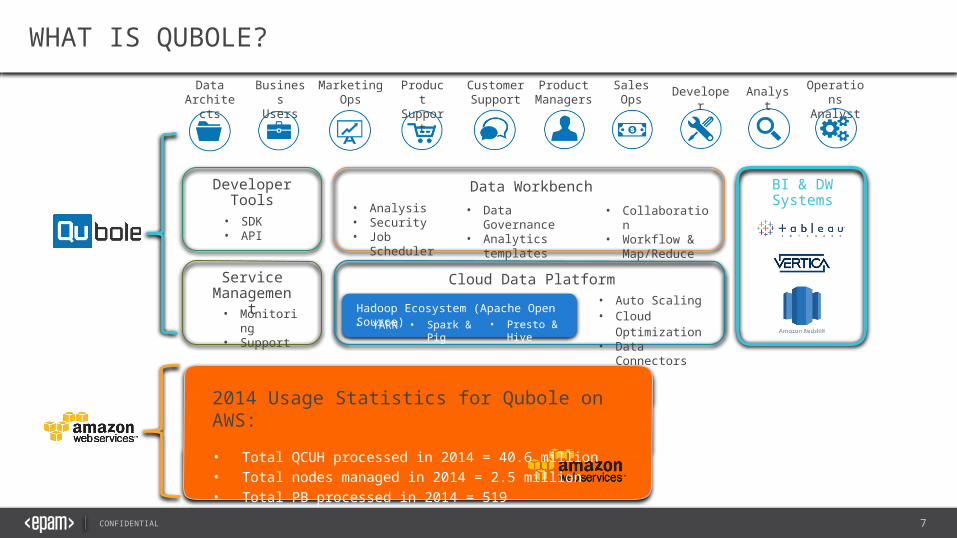
WHAT IS QUBOLE?
2014 Usage Statistics for Qubole on AWS:• Total QCUH processed in 2014 = 40.6 million• Total nodes managed in 2014 = 2.5 million• Total PB processed in 2014 = 519
Operations Analyst
Marketing Ops AnalystData
Architects
Business
Users
Product
Support
Customer Support DeveloperSales
OpsProduct
Managers
DeveloperTools
Service Manageme
nt
Data Workbench
Cloud Data Platform
BI & DWSystems
• SDK• API
• Analysis• Security• Job
Scheduler
• Data Governance
• Analytics templates
• Monitoring
• Support
• Collaboration• Workflow &
Map/Reduce
• Auto Scaling• Cloud
Optimization• Data Connectors
• YARN • Presto & Hive
• Spark & PigHadoop Ecosystem (Apache Open Source)

8CONFIDENTIAL
QDS Cluster Types

9CONFIDENTIAL
CURRENTLY SUPPORTED QDS COMPONENTSQDS Component Currently Supported VersionsCascading Compatible with all versionsHadoop 1 0.20.1Hadoop 2 2.6.0HBase 1.0Hive 0.13.1 and 1.2MapReduce 0.20.1 and 2.6.0Pig 0.11 and 0.15Presto 0.142
Spark 1.3.1, 1.4.0, 1.4.1, 1.5.0, 1.5.1, 1.6.0, 1.6.1
Sqoop 0.20.1 ??? (No)Tez 0.7Zeppelin (notebooks) 1.0 ??? (0.6 or 0.5.6)

10CONFIDENTIAL
QDS INSTANCE SELECTION

11CONFIDENTIAL
CENTRALIZED HIVE METASTORE

12CONFIDENTIAL
INTERCLUSTER METASTORE

13CONFIDENTIAL
QUBOLE COMMUNICATION AND SECURITY

14CONFIDENTIAL
RIGHT TOOL FOR RIGHT WORKLOAD
Large scale ETL
Interactive Discovery Queries
Machine Learning/Real time queries
High Performance DW Queries/Reporting backend

15CONFIDENTIAL
TIPS & TRICKS
S3 is a default storage1
HDFS is temporary storage
2
Cluster start time ≈ 90 sec3
Be ready to eventual consistency issue
4
Multiple clusters are optimized for different workloads
5
Use spot instances6
Use Metastore API7
Cluster restart is useful8
Use Quark if possible9

16CONFIDENTIAL
3rd Party Services
StreamX
RubiXQuark
Connectors & HandlersAirflow

17CONFIDENTIAL
STREAMX: KAFKA CONNECT FOR S3
StreamX is a kafka-connect based connector to copy data from Kafka to Object Stores like Amazon s3, Google Cloud Storage and Azure Blob Store. It focusses on reliable and scalable data copying. One design goal is to write the data in format (like parquet), so that it can readily be used by analytical tools.
Features:• Support for writing data in Avro and Parquet formats.• Provides Hive Integration where the connector creates partitioned hive table and
periodically adds partitions once it is written in new partition on S3• Pluggable partitioner :
• default partitioner : Each Kafka partition will have its data copied under a partition specific directory
• time based partitioner : Ability to write data on hourly basis• field based partitioner : Ability to use a field in the record as custom partitioner
• Exactly-once guarantee using WAL• Direct output to S3 (Avoid writing to temporary file and renaming it.• Support for storing Hive tables in Qubole's hive metastore (coming soon)

18CONFIDENTIAL
STREAMX: KAFKA CONNECT FOR S3
Configuration (core-site.xml):• fs.AbstractFileSystem.s3.impl=org.apache.hadoop.fs.s3a.S3A• fs.s3a.impl=org.apache.hadoop.fs.s3a.S3AFileSystem• fs.s3a.access.key=xxxxx• fs.s3a.secret.key=xxxxx
Sample Run connect-distributed in Kafka : bin/connect-distributed.sh config/connect-distributed.xml{"name":"twitter connector", "config":{ "name":"twitter connector", "connector.class":"com.qubole.streamx.s3.S3SinkConnector",
"tasks.max":"1", "flush.size":"100000", "s3.url":"<S3 location>", "wal.class":"com.qubole.streamx.s3.wal.DBWAL", "db.connection.url":"<jdbc:mysql://localhost:3306/kafka>", "db.user":"<username_required>", "db.password":"<password_required>", "hadoop.conf.dir":"<directory where hadoop conf files are stored. Example /usr/lib/hadoop2/etc/hadoop/>",
"topics":"twitter1p"}}

19CONFIDENTIAL
RUBIX: LIGHT-WEIGHT DATA CACHING FRAMEWORK
RubiX is a light-weight data caching framework that can be used by Big-Data engines. RubiX can be extended to support any engine that accesses data in cloud stores using Hadoop FileSystem interface via plugins. Using the same plugins, RubiX can also be extended to be used with any cloud store
Supported Engines and Cloud Stores:• Presto: Amazon S3 is supported• Hadoop-1: Amazon S3 is supported
How to use it:RubiX has two components: a BookKeeper server and a FileSystem implementation for engine to use.Start the BookKeeper server. It can be started via hadoop jar command, e.g.: hadoop jar rubix-bookkeeper-1.0.jar com.qubole.rubix.bookkeeper.BookKeeperServer
Engine side changes:To use RubiX, you need to place the appropriate jars in the classpath and configure Engines to use RubiX filesystem to access the cloud store. Sections below show how to get started on RubiX with supported plugins

20CONFIDENTIAL
QUARK: COST-BASED SQL OPTIMIZER
Quark optimizes access to data by managing relationships between tables across all databases in an organization. Quark defines materialized views and olap cubes, using them to route queries between tables stored in different databases. Quark is distributed as a JDBC jar and will work with most tools that integrate through JDBC.
Create & manage optimized copies of base tables:• Narrow tables with important attributes only. • Sorted tables to speed up filters, joins and aggregation• Denormalized tables wherein tables in a snowflake schema have been joined.OLAP Cubes: Quark supports OLAP cubes on partial data (last 3 months of sales reports for example). It also supports incremental refresh.Bring your own database: Quark enables you to choose the technology stack. For example, optimized copies or OLAP cubes can be stored in Redshift or RDB and base tables can be in S3 or HDFS and accessed through Hive.Rewrite common bad queries: A common example is to miss specifying partition columns which leads to a full table scan. Quark can infer the predicates on partition columns if there are related columns or enforce a policy to limit the data scanned.

21CONFIDENTIAL
QUARK: COST-BASED SQL OPTIMIZER Administration: Database administrators are expected to register datasources, define views and cubes. Quark can pull metadata from a multitude of data sources through an extensible Plugin interface. Once the data sources are registered, the tables are referred to as data_source.schema_name.table_name. Quark adds an extra namespace to avoid conflicts. DBAs can define or alter materialized views with DDL statements such as:
Internals: Quark’s capabilities are similar to a database optimizer. Internally it uses Apache Calcite which is a cost-based optimizer. It uses the Avatica a sub-project of Apache Calcite to implement the JDBC client and server.Quark parses, optimizes and routes the query to the most optimal dataset. For example, if the last months of data in hive.default.page_views are in a data warehouse, Quark will execute queries in the data warehouse instead of the table in Apache Hive.
create view page_views_partition as select * from hive.default.page_views where timestamp between “Mar 1 2016”
and “Mar 7 2016”and group in (“en”, “fr”, “de”)
stored in data_warehouse.public.pview_partition

22CONFIDENTIAL
QDS: CONNECTORS & HANDLERS
Hive Storage Handler for Kinesis helps users read from and write to Kinesis Streams using Hive, enabling them to run queries to analyze data that resides in Kinesis.
Hive Storage Handler for JDBC is a fork of HiveJdbcStorageHandler, helps users read from and write to JDBC databases using Hive, and also enabling them to run SQL queries to analyze data that resides in JDBC tables. Optimizations such as FilterPushDown have also been added.
CREATE TABLE TransactionLogs ( transactionId INT, username STRING, amount INT ) ROW FORMAT SERDE 'org.openx.data.jsonserde.JsonSerDe' STORED BY 'com.qubole.hive.kinesis.HiveKinesisStorageHandler' TBLPROPERTIES ('kinesis.stream.name'='TransactionStream');
CREATE EXTERNAL TABLE HiveTable(id INT, names STRING) STORED BY 'org.apache.hadoop.hive.jdbc.storagehandler.JdbcStorageHandler' TBLPROPERTIES ( "mapred.jdbc.driver.class"="com.mysql.jdbc.Driver", "mapred.jdbc.url"="jdbc:mysql://localhost:3306/rstore", "mapred.jdbc.username"="root", "mapred.jdbc.input.table.name"="JDBCTable", "mapred.jdbc.output.table.name"="JDBCTable", "mapred.jdbc.password"="", "mapred.jdbc.hive.lazy.split"= "false");

23CONFIDENTIAL
QDS: CONNECTORS & HANDLERS
Kinesis Connector for Presto allows the use of Kinesis streams as tables in Presto, such that each data-blob (message) in a kinesis stream is presented as a row in Presto. A flexible table mapping approach lets us treat fields of the messages as columns in the table.
{ "tableName": "test_table", "schemaName": "otherworld", "streamName": "test_kinesis_stream", "message": {
"dataFormat": "json", "fields": [ { "name": "client_id",
"type": "BIGINT", "mapping":
"body/profile/clientId", "comment": "The client ID field" },
{ "name": "routing_time", "mapping":
"header/routing_time", "type": "DATE", "dataFormat": "iso8601" } ]
} }

24CONFIDENTIAL
AIRFLOW AUTHOR, SCHEDULE AND MONITOR WORKFLOWS
Use Airflow to author workflows as directed acyclic graphs (DAGs) of tasks. The Airflow scheduler executes your tasks on an array of workers while following the specified dependencies. Rich command line utilities make performing complex surgeries on DAGs a snap. The rich user interface makes it easy to visualize pipelines running in production, monitor progress, and troubleshoot issues when needed.Principles:• Dynamic - Airflow pipelines are configuration as code (Python), allowing for dynamic
pipeline generation. This allows for writing code that instantiates pipelines dynamically.• Extensible - Easily define your own operators, executors and extend the library so that it
fits the level of abstraction that suits your environment.• Elegant - Airflow pipelines are lean and explicit. Parameterizing your scripts is built into
the core of Airflow using the powerful Jinja templating engine.• Scalable - Airflow has a modular architecture and uses a message queue to orchestrate an
arbitrary number of workers. Airflow is ready to scale to infinity.

25CONFIDENTIAL
QDS APIs & SDKs
Qubole REST API
Qubole Python SDKQubole Java SDK

26CONFIDENTIAL
QDS REST APIs
The Qubole Data Service (QDS) is accessible via REST APIs.
Access URL: https://api.qubole.com/api/${V}/ where ${V} version of the API (v1.2 … latest).Authentication: Qubole API Token set API token to the AUTH_TOKEN environment variable.API Types:
•Account API •Cluster API •Command Template API •DbTap API •Groups API •Hive Metadata API •Reports API •Roles API •Scheduler API •Users API •Command API
• Hive commands• Hadoop jobs• Pig commands• Presto commands• Spark commands• DbImport commands• DbExport commands• Shell commands

27CONFIDENTIAL
QDS HIVE METADATA APIQDS Hive Metadata API Types:
•Schema or Database•Get Table Definition•Store Table Properties•Get Table Properties
•Delete Table Properties
Get Table Properties:
Store Table Properties:
curl -i -X GET -H "Accept: application/json" -H "Content-type: application/json" -H "X-AUTH-TOKEN: $AUTH_TOKEN" "https://api.qubole.com/api/v1.2/hive/default/daily_tick/table_properties"
cat pl.json { "interval": "1", "interval_unit": "days", "columns": {
"stock_exchange": "", "stock_symbol": "", "year": "%Y", "date": "%Y-%m-%d" } } curl -i -X POST -H "Accept:application/json" -H "Content-type:application/json“ -H "X-AUTH-TOKEN: $AUTH_TOKEN" --data @pl.json https://api.qubole.com/api/v1.2/hive/default/daily_tick/properties
{ "location": "s3n://paid-qubole/data/stock_tk", "owner": "ec2-user", "create-time": 1362388416, "table-type": "EXTERNAL_TABLE", "field.delim": ",", "serialization.format": "," }

28CONFIDENTIAL
QDS HIVE COMMAND APIThis API is used to submit a Hive query.
Parameter Descriptionquery Specify Hive query to run. Either query or script_location is requiredscript_location Specify a S3 path where the hive query to run is stored. Either query or script_location is required.
AWS storage credentials stored in the account are used to retrieve the script file.command_type Hive commandlabel Cluster label to specify the cluster to run this commandretry Denotes the number of retries for a job. Valid values of retry are 1, 2, and 3.macros Expressions to evaluate macros used in the hive command. Refer to Macros in Scheduler for more
details.sample_size Size of sample in bytes on which to run the query for test mode.approx_mode_progress Value of progress for constrained run. Valid value of float between 0 and 1approx_mode_max_rt Constrained run max runtime in secondsapprox_mode_min_rt Constrained run min runtime in secondsapprox_aggregations Convert count distinct to count approx. Valid values are bool or NULL
nameAdd a name to the command that is useful while filtering commands from the command history. It does not accept & (ampersand), < (lesser than), > (greater than), ” (double quotes), and ‘ (single quote) special characters, and HTML tags as well. It can contain a maximum of 255 characters.
tagAdd a tag to a command so that it is easily identifiable and searchable from Commands History. Add a tag as a filter value while searching commands. Max 255 characters. Comma is separator for several tags.

29CONFIDENTIAL
QDS HIVE COMMAND APICount the number of rows in the table:
Response:
export QUERY="select count(*) as num_rows from miniwikistats;" curl -X POST -H "X-AUTH-TOKEN: $AUTH_TOKEN" -H "Content-Type: application/json" -H "Accept: application/json" -d '{ "query":"$QUERY", "command_type": "HiveCommand" }' "https://api.qubole.com/api/${V}/commands/"
HTTP/1.1 200 OK
{ "command": { "approx_mode": false, "approx_aggregations": false, "query": "select count(*) as num_rows from
miniwikistats;", "sample": false },
"qbol_session_id": 0000,…"progress": 0, "meta_data": {
"results_resource": "commands\/3852\/results", "logs_resource": "commands\/3852\/logs" } }

30CONFIDENTIAL
QDS HIVE COMMAND APIRun a query stored in a S3 file location:
Run a parameterized query stored in a S3 file location:
Submitting a Hive Query to a Specific Cluster:
cat payload.json { "script_location":"<S3 Path>",
"command_type": "HiveCommand" } curl -X POST -H "X-AUTH-TOKEN: $AUTH_TOKEN" -H "Content-Type: application/json" -H "Accept: application/json" -d @payload "https://api.qubole.com/api/${V}/commands/"
cat payload.json { "script_location":"<S3 Path>",
"macros":[{"date":"moment('2011-01-11T00:00:00+00:00')"},{"formatted_date":"date.clone().format('YYYY-MM-DD')"}],
"command_type": "HiveCommand" } curl -X POST -H "X-AUTH-TOKEN: $AUTH_TOKEN" -H "Content-Type: application/json" -H "Accept: application/json" -d @payload "https://api.qubole.com/api/${V}/commands/"
curl -X POST -H "X-AUTH-TOKEN: $AUTH_TOKEN" -H "Content-Type: application/json" -H "Accept: application/json" -d '{"query":"show tables;", "label":"HadoopCluster", "command_type": "HiveCommand"}' "https://api.qubole.com/api/${V}/commands"

31CONFIDENTIAL
QDS SPARK COMMAND APIThis API is used to submit a Spark command.
Parameter Descriptionprogram Provide the complete Spark Program in Scala, SQL, Command, R, or Python.
language Specify the language of the program, Scala, SQL, Command or Python. Required only when a program is used.
arguments Specify the spark-submit command line arguments here.user_program_arguments
Specify the arguments that the user program takes in.
cmdline Alternatively, you can provide the spark-submit command line itself. If you use this option, you cannot use any other parameters mentioned here. All required information is captured in command line itself.
command_type Spark command
label Cluster label to specify the cluster to run this command
app_id ID of an app, which is a main abstraction of the Spark Job Server API. An app is used to store the configuraton for a Spark application. See Understanding the Spark Job Server for more information.
nameAdd a name to the command that is useful while filtering commands from the command history. It does not accept & (ampersand), < (lesser than), > (greater than), ” (double quotes), and ‘ (single quote). Max 255 characters.
tagAdd a tag to a command so that it is easily identifiable and searchable from Commands History. Add a tag as a filter value while searching commands. Max 255 characters. Comma is separator for several tags.

32CONFIDENTIAL
QDS SPARK COMMAND APIExample Python API Framework:
Example to Submit Spark Scala Program:
import sys, pycurl, json
c= pycurl.Curl()url="https://api.qubole.com/api/v1.2/commands"auth_token = <provide auth token here>c.setopt(pycurl.URL, url)c.setopt(pycurl.HTTPHEADER, ["X-AUTH-TOKEN: "+ auth_token, "Content-Type:application/json", "Accept: application/json"])c.setopt(pycurl.POST,1)
prog = '''import scala.math.randomimport org.apache.spark._object SparkPi { def main(args: Array[String]) { val conf = new SparkConf().setAppName("Spark Pi") val spark = new SparkContext(conf) val slices = if (args.length > 0) args(0).toInt else 2 val n = math.min(100000L * slices, Int.MaxValue).toInt // avoid overflow val count = spark.parallelize(1 until n, slices).map { i => val x = random * 2 - 1 val y = random * 2 - 1 if (x*x + y*y < 1) 1 else 0 }.reduce(_ + _) println("Pi is roughly " + 4.0 * count / n) spark.stop() }}'''data=json.dumps({"program":prog,"language":"scala","arguments":"--class SparkPi", command_type":"SparkCommand"})c.setopt(pycurl.POSTFIELDS, data)c.perform()

33CONFIDENTIAL
QDS SPARK COMMAND APIExample to Submit Spark Command in SQL:
Example to Submit a Spark Command in SQL to a Spark Job Server App:
Where app_id = Spark Job Server app ID. See Understanding the Spark Job Server for more information.
curl -i -X POST -H "X-AUTH-TOKEN: $AUTH_TOKEN" -H "Content-Type: application/json" -H "Accept: application/json" -d ‘{ "sql":"select * from default_qubole_memetracker limit 10;", "language":"sql","command_type":"SparkCommand", "label":"spark" }' "https://api.qubole.com/api/${V}/commands"
curl -i -X POST -H "X-AUTH-TOKEN: $AUTH_TOKEN" -H "Content-Type: application/json" -H "Accept: application/json" -d '{ "sql":"select * from default_qubole_memetracker limit 10;", "language":"sql","command_type":"SparkCommand", "label":"spark","app_id":"3" }' "https://api.qubole.com/api/${V}/commands"

34CONFIDENTIAL
QDS SCHEDULE APIThis API creates a new schedule to run commands automatically at certain frequency.Parameter Description
command_type
A valid command type supported by Qubole. For example, HiveCommand, HadoopCommand, PigCommand.
command JSON object describing the command. Refer to the Command API for more details.Sub fields can use macros. Refer to the Qubole Scheduler for more details.
start_time Start datetime for the scheduleend_time End datetime for the schedule
frequency Specify how often the job should run. Input is an integer. For example, frequency of one hour/day/month is represented as {"frequency":"1"}
time_unit Denotes the time unit for the frequency. Its default value is days. Accepted value is minutes, hours, days, weeks, or months.
… …concurrency Specify how many job actions can run at a time. Default value is 1.
dependency_info
Describe dependencies for this job.Check the Hive Datasets as Schedule Dependency for more information.
Notification Parameters
It is an optional parameter that is set to false by default. You can set it to true if you want to be notified through email about instance failure. Notification Parameters provides more information.

35CONFIDENTIAL
QDS SCHEDULE APIThe query shown below aggregates the data for every stock symbol, every day:
curl -i -X POST -H "X-AUTH-TOKEN: $AUTH_TOKEN" -H "Accept: application/json" -H "Content-type: application/json" -d '{ "command_type":"HiveCommand",
"command": { "query": "select stock_symbol, max(high), min(low), sum(volume)
from daily_tick_data where date1='$formatted_date$' group by stock_symbol" },
"macros": [ { "formatted_date": "Qubole_nominal_time.format('YYYY-MM-DD')" } ],
notification:{"is_digest": false, "notification_email_list":["[email protected]"],
"notify_failure": true, "notify_success": false}`"start_time": "2012-07-01T02:00Z", "end_time": "2022-07-01T02:00Z", "frequency": "1", "time_unit": "days", "time_out":"10", "dependency_info": {} }'
"https://api.qubole.com/api/v1.2/scheduler"

36CONFIDENTIAL
QUBOLE DATA SERVICE JAVA SDKA Java library that provides the tools you need to authenticate with and use the Qubole API.
Installation
UsageAllocate a QdsClient object:
Then, make api calls as needed…
<dependency> <groupId>com.qubole.qds-sdk-java</groupId> <artifactId>qds-sdk-java</artifactId>
<version>0.7.0</version></dependency>
QdsConfiguration configuration = new DefaultQdsConfiguration(YOUR_API_KEY); QdsClient client = QdsClientFactory.newClient(configuration);

37CONFIDENTIAL
QUBOLE DATA SERVICE JAVA SDKAPI call:
API call (with Jersey's callback mechanism):
Future<CommandResponse> hiveCommandResponseFuture = client .command().hive().query("show tables;").invoke();CommandResponse hiveCommandResponse = hiveCommandResponseFuture.get();
InvocationCallback<CommandResponse> callback = new InvocationCallback<CommandResponse>(){ @Override public void completed(CommandResponse clusterItems) { // ... } @Override public void failed(Throwable throwable) { // ... }};client.command().hive().query("show tables;").withCallback(callback).invoke();...

38CONFIDENTIAL
QUBOLE DATA SERVICE JAVA SDKWaiting for Results (Blocking):
Waiting for Results (with callback):
Paging:
ResultLatch latch = new ResultLatch(client, queryId);ResultValue = latch.awaitResult();
ResultLatch.Callback callback = new ResultLatch.Callback(){ @Override public void result(String queryId, ResultValue resultValue) {// use results } @Override public void error(String queryId, Exception e) {// handle error }};ResultLatch latch = new ResultLatch(client, queryId);latch.callback(callback);
// return page 2 using 3 per pageclient.command().history().forPage(2, 3).invoke();

39CONFIDENTIAL
QUBOLE DATA SERVICE PYTHON SDKA Python module that provides the tools you need to authenticate with and use the Qubole API.
Installation
orCLI Usage (qds.py allows running Hive, Hadoop, Pig, Presto and Shell commands against QDS. Users can run commands synchronously - or submit a command and check its status):
Pass in api token from bash environment variable
$ pip install qds-sdk $ python setup.py install
$ qds.py --token 'xxyyzz' hivecmd run --query "show tables" $ qds.py --token 'xxyyzz' hivecmd run --script_location /tmp/myquery $ qds.py --token 'xxyyzz' hivecmd run --script_location s3://my-qubole-location/myquery
$ export QDS_API_TOKEN=xxyyzz $ qds.py hadoopcmd run streaming -files 's3n://paid-qubole/HadoopAPIExamples/WordCountPython/mapper.py,s3n://paid-qubole/HadoopAPIExamples/WordCountPython/reducer.py' -mapper mapper.py -reducer reducer.py -numReduceTasks 1 -input 's3n://paid-qubole/default-datasets/gutenberg' -output 's3n://example.bucket.com/wcout'
$ qds.py hivecmd check 12345678 {"status": "done", ... }

40CONFIDENTIAL
QUBOLE DATA SERVICE JAVA SDK
Programmatic Usage (Python application needs to do the following):1) Set the api_token:
2) Use the Command classes defined in commands.py to execute commands. To run Hive cmd:
from qds_sdk.qubole import Qubole
Qubole.configure(api_token='ksbdvcwdkjn123423')
from qds_sdk.commands import *
hc=HiveCommand.create(query='show tables')print "Id: %s, Status: %s" % (str(hc.id), hc.status)

41CONFIDENTIAL
QDS QUICK TOUR

42CONFIDENTIAL
QDS: MAIN NAVIGATION

43CONFIDENTIAL
QDS: PRODUCT OFFERINGS
44CONFIDENTIAL
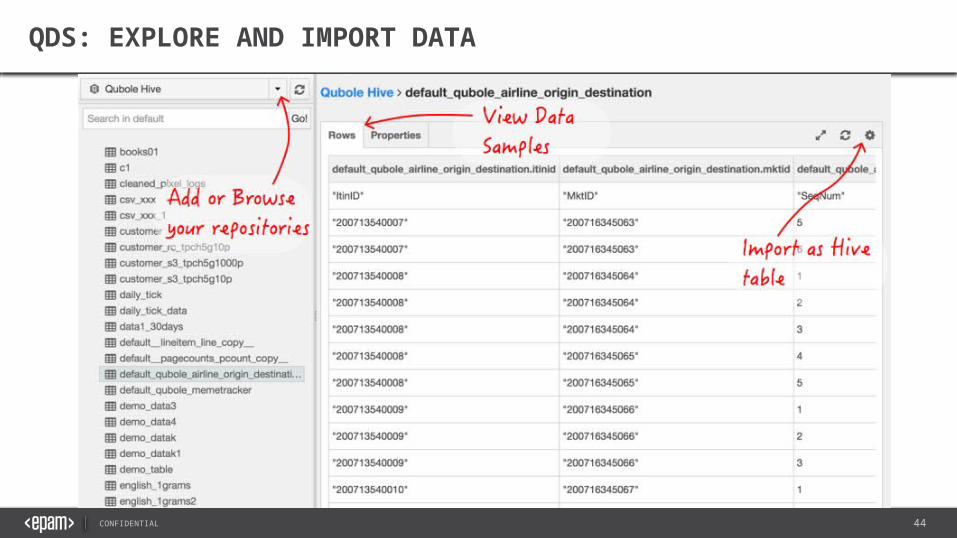
QDS: EXPLORE AND IMPORT DATA

45CONFIDENTIAL
QDS: ANALYZE DATA

46CONFIDENTIAL
QDS: CLUSTER SETTINGS

47CONFIDENTIAL
QDS: Dashboard