quantifying model specification risk in practice actuarial teachers’ and researchers’ conference...
TRANSCRIPT

Quantifying Model Specification Riskin PracticeActuarial Teachers’ and Researchers’ Conference
Edinburgh, 2nd December 2014
Alan Forrest
RBS Group Risk Analytics Independent Model Validation
Information Classification –

2
Disclaimer
Disclaimer
The opinions expressed in this document are solely the author’s and do not necessarily reflect those of The Royal Bank of Scotland Group or any of its subsidiaries.
Any graphs or tables shown are based on mock data and are for illustrative purposes only.

3
Overview
Background
Background to Model Risk – the risk of using a model.
Model Risk Quantification
Model specification risk as a Data-shift Problem.
Quick estimates of specification risk using geometric and information-theoretic approaches to the data-shift problem.

4
Model Risk Background
The US Regulator (Fed / OCC 2011-12a )
“The use of models invariably presents model risk, which is the potential for adverse consequences from decisions based on incorrect or misused model outputs and reports.”
– Using a model presents a risk.
FSA - Turner Review - March 2009
“Misplaced reliance on sophisticated maths”
– The assumptions and limitations of the models were not communicated adequately to the pricing and lending decision-makers.
BoE - The Dog and the Frisbee – Haldane, August 2012
“… opacity and complexity… It is close to impossible to tell whether results from [internal risk models] are prudent.”
– If we cannot say why we trust a model, are we right to use it?

5
Fed / OCC 2011-12a
“Model Risk should be managed like other types of risk.”
– Identify– Quantify / assess– Act / manage– Monitor
Focus on specification risk:
The part of model risk connected with model selection.
– Model risk also includes risks of model implementation, use and interpretation.
Quantification of specification risk:
How differently could the model have been built under different conditions?
Model Risk Background

6
Example Model Risk
A Probability of Default model is proposed for implementation
The model includes a factor W that has 20% missing values.
The missing values have been filled in, all with the same “mean” value, and the preferred model has been built with this imputed factor.
Missing values tend to be associated with older accounts.

7
Example Model Risk
Hypothetical alternative model builds – based on different development data:
With “missing” as a special class.
With a different method of imputation
Explore the possible bias over time by forcing (at random) new missing values among more recent accounts.

8
Quantifying Model Risk – Bottom Up
The key to specification risk quantification is sensitivity analysis;
and most sensitivity analysis can be expressed as a Data-shift Problem.
If the data used to build a model shifts, how far and in what way does the model shift?
In practice, we could have 100 data-shifts to test, and models require much resource to build.
Modellers need a quick and reliable way of assessing the likely impact of data shifts without needing to build models:
– Prioritising analysis;– Getting immediate assurance on shifts that are immaterial;– Making the appropriate model changes.

9
Original data
Model space
Shifted data
Type 3 (or type 0) Error
Over-fitting Over-sensitive / discontinuous
Just right
Geometry and Model Sensitivity
The sensitivity of a model to data-shift has a geometric interpretation.
Model fitting looks “geometric”: the model is found “closest” to the data.
Geometry and curvature expresses data-shift sensitivity.

10
Simplifications and Conventions
Banking Book Credit Risk Models allow the following assumptions:
All factors and outcomes are categorical / classed / discrete
The development data-set is completely described by its frequency table: i.e. whole number entries in a finite contingency table.
The space of all data is finite dimensional.
Fixed-effects regression based on an exponential family of distributions
Includes all the classical regressions: logistic, multinomial, poisson etc.
Maximum Likelihood Estimation (MLE)

11
Simplifications and Conventions
A model is a description of the data on which it is developed:
a model is another point in data space.
The preferred model is chosen from a limited set of possible descriptions – the model space.
This model space is a subspace of data space, chosen for its convenience, simplicity or usefulness.
What about inputs and outputs?
Some dimensions of the data-space are inputs, others are outputs.
If the model space covers marginally all input populations, then* the development data and the MLE optimised description have the same input population distributions: this allows a model outcome to be defined for any input population.
* non-trivial theorem
12
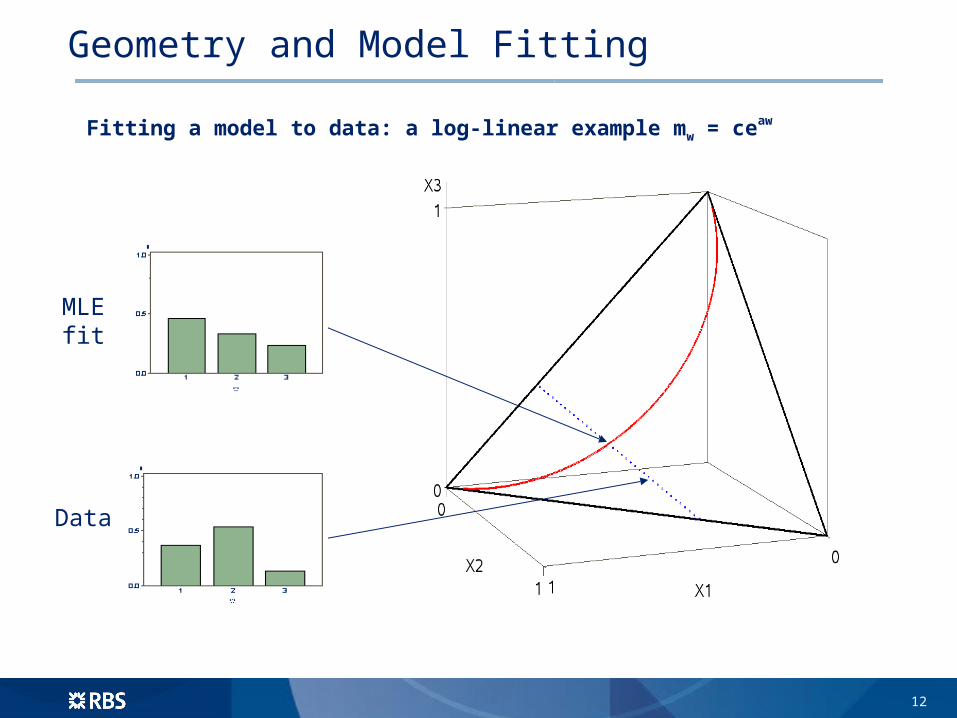
Geometry and Model Fitting
Fitting a model to data: a log-linear example mw = ceaw
MLE fit
Data

13
Information Principles
Dual optimisation principles for exponential families
The red model spaces are generated multiplicatively / ‘tropically’.
Data points are drawn to the MLE model along the blue spaces, which are linear.
Principle of Maximum Likelihood– The model that maximises likelihood, for
data d, is the point, m, in red space that minimises KL divergence I(d,m).
Principle of Maximum Entropy– If m’ is any model in the red space then,
within each blue space, the red point m minimises KL divergence, I(m,m’) .
Principles of Inference– if m is the MLE fit to data d, and m’ is
another model from the model space, then I(d,m’) = I(d,m) + I(m,m’) .

14
Geometry and Model Sensitivity
Geometry of the data space
The natural metric is ds2 = w dxw2 / xw
– Locally equal to Kullback-Leibler divergence and to Hellinger distance.
– “Local Chi-squared”.– “Boot-strapping geometry”.
Isometric to a portion of a sphere.– 2x = u2 connects this space isometrically with
Euclidean space.
The model fitting foliations are orthogonal in this metric.– The model space curvature reflects true model
sensitivity.
15
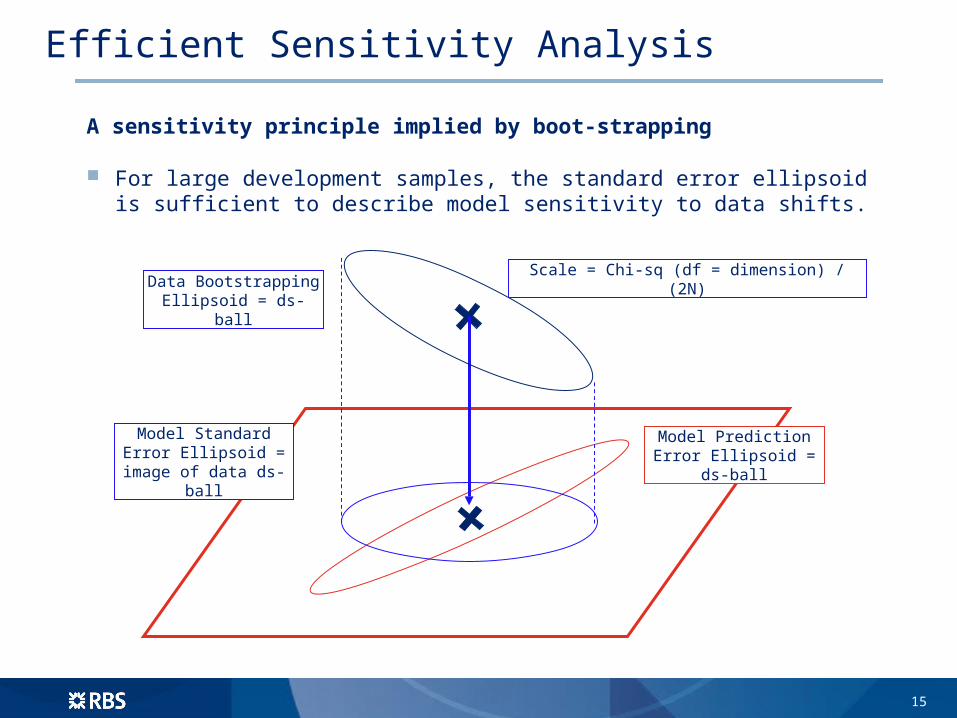
Efficient Sensitivity Analysis
A sensitivity principle implied by boot-strapping
For large development samples, the standard error ellipsoid is sufficient to describe model sensitivity to data shifts.
Model Prediction Error Ellipsoid = ds-ball
Model Standard Error Ellipsoid = image of data
ds-ball
Data Bootstrapping Ellipsoid = ds-ball
Scale = Chi-sq (df = dimension) / (2N)

16
Geometry and Model Sensitivity
0.2536
0.0054 +
0.0030
0.0443
Example: Sensitivities for factor with 20% missing values– Distances (squared) between hypothetical alternative datasets, computed in spherical
metric from marginals illustrated.– Additional distance estimated by KL information value relative to marginals.

17
Managing Sensitivities
Model Risk - 20% missing values - example revisited :
PD has been built from a pool of 12 classed factors:– Dimension of the data space (roughly = number of cross-tab cells), D = 50,000.
PD model built by MLE on sample of N = 500,000 records.
Bootstrap scale is D/2N = 0.05 .
Sensitivity TestData Shift
distance-squaredObservation Action
Force missing values among new
accounts0.008
Correlation of missingness with age of accounts is unlikely to cause significant
change in model build.No need to investigate.
Missing at Randomv. Mean Allocation 0.045
These two imputation options are likely to result in same factor selections, but
different factor weights.Low priority
Missing as a separate category 0.254
Model build is likely to be materially different if missing is treated as a
separate category. High priority

18
Conclusions
Quantifying Model Risk
Quantitative model risk assessment is needed for– consistent management and maintenance of a bank’s models, and– effective communication of model weaknesses and limitations to decision-makers and
users.
The key to bottom up quantitative model risk assessment is sensitivity analysis.
The key to practical sensitivity analysis is data-shift.
Data-shift is a deep problem, well-known in geometric statistics, information theory and artificial intelligence, and rich in mathematical interest.
Simplified approximate solutions to the data-shift problem can be used in practice to quantify and prioritise model risk assessment in banking book credit risk.

19
An incomplete bibliography
The geometric approach to statistics is rich and well-established, classically starting with Rao in the 1940s
Its connection with information and KL divergence is also developed in great generality
Centsov (1965, et seq.), making geometric the original developments of Kullback and Leibler.
Efron (1978 et seq.), Lauritzen (1980s), Critchley et al. (1993 et seq.), etc.
Amari et al. (1982 et seq.) develops Akiake’s insights using differential geometry
The application to the data shift problem is comparatively recent but growing
Recent developments in Machine Learning, by Kanamori, Shimodaira (2009) and others, are particularly relevant to sensitivity analysis.
Hulse et al. (2013) recently explored its implications in Financial Modelling.