predicting execution bottlenecks in map-reduce clusters edward bortnikov, ari frank, eshcar hillel,...
TRANSCRIPT

Predicting Execution Bottlenecks
in Map-Reduce Clusters
Edward Bortnikov, Ari Frank, Eshcar Hillel, Sriram RaoPresenting: Alex Shraer
Yahoo! Labs

- 2 - Yahoo! Confidential
The Map Reduce (MR) Paradigm Architecture for scalable information processing
Simple API Computation scales to Web-scale data collections
Google MR Pioneered the technology in early 2000’s
Hadoop: open-source implementation In use at Amazon, eBay, Facebook, Yahoo!, … Scales to 10K’s nodes (Hadoop 2.0)
Many proprietary implementations MR technologies at Microsoft, Yandex, …

- 3 - Yahoo! Confidential
Computational Model
M1
M2
M3
M4
R1
R2
Out
put (
on D
FS)
Inpu
t (on
DFS
)
Synchronous execution: every R starts computing
after all M’s have completed
Slowest task (straggler)affects the job latency

- 4 - Yahoo! Confidential
Predicting Straggler Tasks Straggler tasks are an inherent bottleneck
Affect job latency, and to some extend throughput
Two approaches to tackle stragglers Avoidance – reduce the probability of straggler emergence Detection – once a task goes astray, speculatively fire a
duplicate task somewhere else
This work – straggler prediction Fits with both avoidance and detection scenarios

- 5 - Yahoo! Confidential
Background Detection, Speculative Execution
First implemented in Google MR (OSDI ’04) Hadoop employs a crude detection heuristic
LATE scheduler (OSDI ‘08) addresses the issues of heterogeneous hardware. Evaluated on small scale.
Microsoft MR (Mantri project, OSDI ‘10)
Avoidance Local/rack-local data access is preferred for mappers
… Network less likely to become the bottleneck
All optimizations are heuristic

- 6 - Yahoo! Confidential
Machine-Learned vs Heuristic Prediction Heuristics are hard to …
Tune for real workloads Catch transient bottlenecks
Some evidence from Hadoop grids at Yahoo! Speculative scheduling is non-timely and wasteful
90% of the fired duplicates are eventually killed Data-local computation amplifies contention
Can we use the wealth of historical grid performance data to train a machine-learned bottleneck classifier?

- 7 - Yahoo! Confidential
Why Should Machine Learning Work?
Recurrence
(over 5 months)
Fraction of jobs
Fraction of maps
Fraction of reduces
1 3.3% 0.1% <0.1%2 2% 0.2% 0.1%3-5 11.4% 0.3% 0.5%6-10 6.2% 0.8% 0.5%11-20 7.9% 1.1% 1.0%21-50 10.9% 2.6% 2.7%51-100 11% 2.9% 7.2%101-200 32.9% 6.2% 9.2%201-500 4.5% 9.8% 5.2%501-1000 1.3% 5.6% 2.0%1001+ 8.6% 68.5% 71.5%
Huge recurrence of large jobs in production grids
95% of mappers and reducers belong to jobs that ran 50+ times in a 5-month sample
Target workload

- 8 - Yahoo! Confidential
The Slowdown Metric Task slowdown factor
Ratio between the task’s running time and the median running time among the sibling tasks in the same job.
Root causes Data skew – input or output significantly exceeds the
median for the job Tasks with skew > 4x happen really seldom.
Hotspots – all the other reasons Congested/misconfigured/degraded nodes, disks, or network. Typically transient. The resulting slow can be very high.

- 9 - Yahoo! Confidential
Jobs with Mapper Slowdown > 5x
Mapper Slowdown
5
10
15
20
25
30
35
40
45
0 10000 20000 30000 40000 50000 60000 70000
Mapper Tasks per Job
Slo
wd
ow
n F
acto
r
1% among all jobs 5% among jobs with 1000 mappers or more
40% due to data skew (2x or above), 60% due to hotspots
Sample of ~50K jobs

- 10 - Yahoo! Confidential
Jobs with Reducer Slowdown > 5xReducer Slowdown
5
15
25
35
45
55
65
75
85
95
0 500 1000 1500 2000 2500
Reducer tasks per job
Slo
wd
ow
n F
acto
r
5% among all jobs 50% among jobs with 1000 reducers or more
10% due to data skew (2x or above), 90% due to hotspots
Sample of ~60K jobs

- 11 - Yahoo! Confidential
Locality is No Silver Bullet
1.304E+12
1.306E+12
1.308E+12
1.31E+12
1.312E+12
1.314E+12
1.316E+12
3500 3600 3700 3800 3900 4000 4100 4200 4300 4400 4500
Tim
es
tam
p
Node id
Outliers among Local Mappers
The same nodes are constantly lagging behind Weaker CPUs (grid HW is heterogeneous), data hotspots, etc.
Pushing for locality too hard amplifies the problem!
Top contributorof straggler tasks
over 6 hours

- 12 - Yahoo! Confidential
Slowdown Predictor An oracle plugin into a Map Reduce system
Input: node features + task features Output: slowdown estimate
Features M/R metrics (job- and task-level) DFS metrics (datanode-level) System metrics (host-level: CPU, RAM, disk I/O, JVM, …) Network traffic (host-, rack- and cross-rack-level)

- 13 - Yahoo! Confidential
Slowdown Prediction - MappersMap Tasks
R2 = 0.7978
-3
-2
-1
0
1
2
3
-3 -2 -1 0 1 2 3
Actual Slowdown (log scale)
Pred
icte
d Sl
owdo
wn
(log
scal
e)
Mis-predicted, need improvement

- 14 - Yahoo! Confidential
Slowdown Prediction - ReducersReduce Tasks
R2 = 0.4083
-3
-2
-1
0
1
2
3
4
-3 -2 -1 0 1 2 3
Actual Slowdown (log scale)
Pred
icte
d Sl
owdo
wn
(log
scal
e)
More dispersed than the mappers

- 15 - Yahoo! Confidential
Some Conclusions Data skew is the most important signal, but there are
many more that are important Node HW generation is a very significant signal for both
mappers and reducers Large grids undergo continuous HW upgrades
Network traffic features (intra-rack and cross-rack) is much more important for reducers than for mappers How to collect efficiently in a real-time setting?
Need to enhance data sampling/weighting to capture outliers better

- 16 - Yahoo! Confidential
Takeaways Slowdown prediction
ML approach to straggler avoidance and detection
Initial evaluation showed viability Need to enhance training to capture outliers better
Challenge: runtime implementation A good blend with the modern MR system architecture?

- 17 - Yahoo! Confidential
Thank you

- 18 - Yahoo! Confidential
Machine Learning Technique
Gradient Boosted Decision Trees (GBDT) Additive regression model Based on ensemble of binary decision trees 100 trees, 10 leaf nodes each
…

- 19 - Yahoo! Confidential
Challenges – Hadoop Use Case Hadoop 1.0 – centralized architecture
The single Job Tracker process manages all task assignment and scheduling
Full picture of Map and Reduce slots across the cluster Hadoop 2.0 – distributed architecture
Resource management and scheduling functions split Thin centralized Resource Manager (RM) creates application
containers (e.g., for running a Map Reduce job) Per-job App Master (AM) does scheduling within a container
May negotiate resource allocation with the RM
Challenge: working with a limited set of local signals
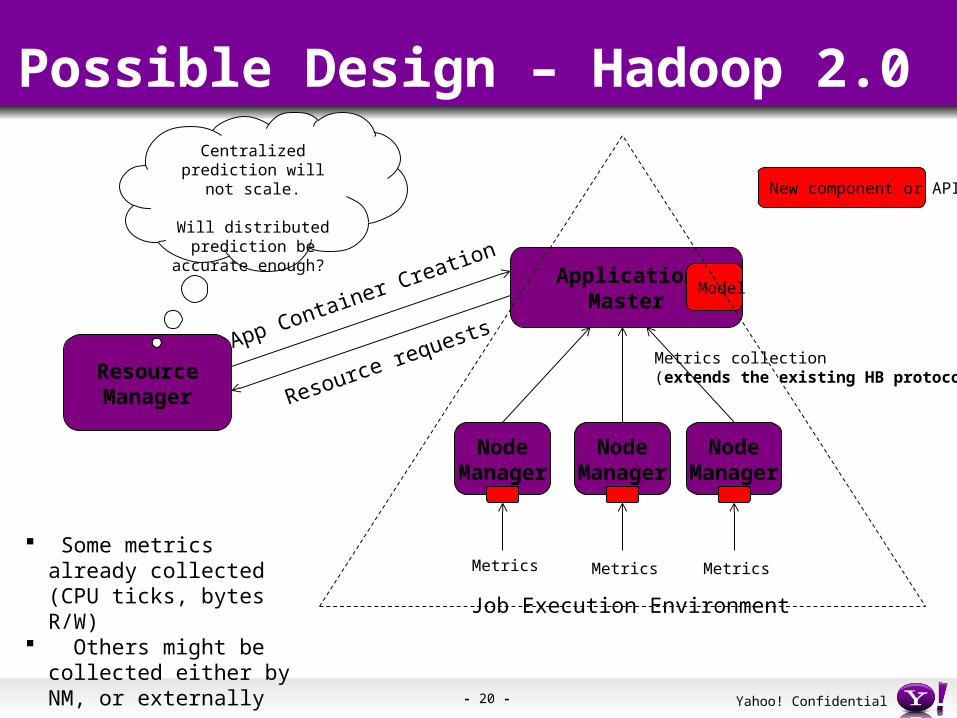
- 20 - Yahoo! Confidential
Possible Design – Hadoop 2.0
ApplicationMaster
ResourceManager
NodeManager
NodeManager
NodeManager
Model
Metrics Metrics Metrics
Resource requestsApp Container Creation
Metrics collection(extends the existing HB protocol)
New component or API
Job Execution Environment
Some metrics already collected (CPU ticks, bytes R/W)
Others might be collected either by NM, or externally
Centralized prediction will not scale.
Will distributed prediction be accurate
enough?