power processor - indico-jsc.fz-juelich.de · ibm supplied power service layer typical i/o model...
TRANSCRIPT

© 2017 IBM Corporation
POWER Processor
Technology Overview
Myron Slota
POWER Systems, IBM Systems
© 2017 IBM Corporation
603
POWER6
POWER3
-630
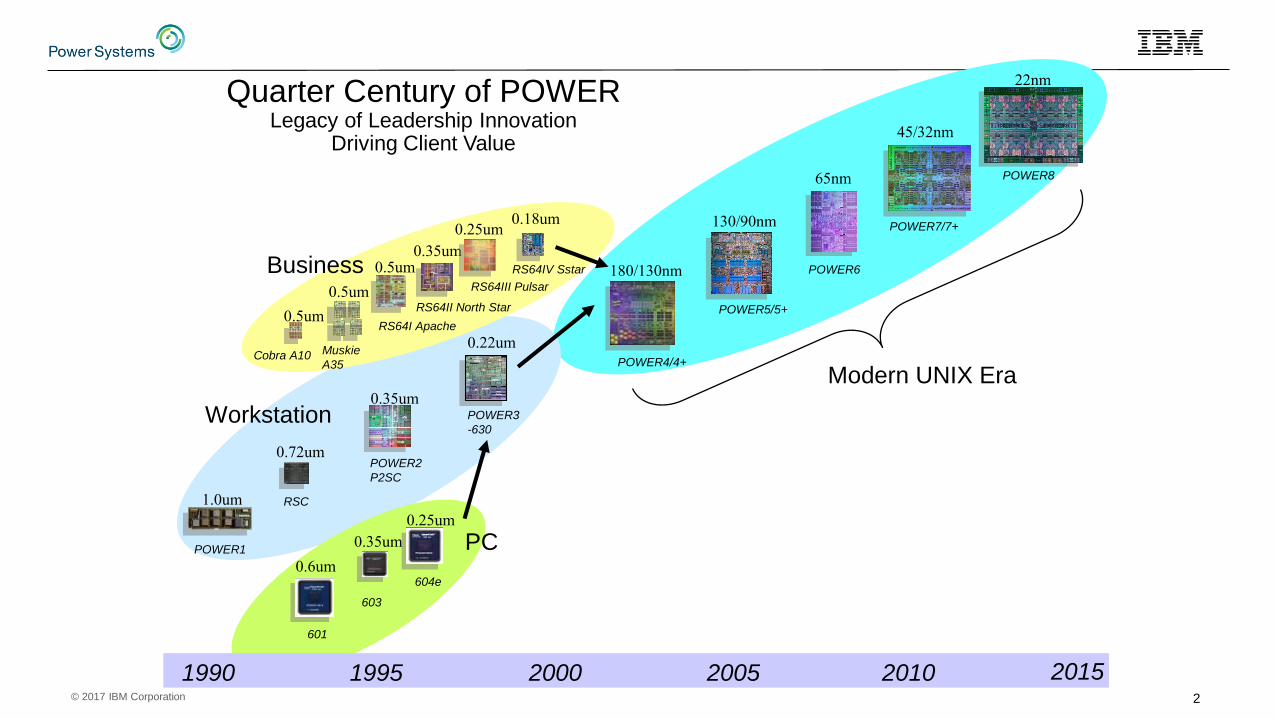
Quarter Century of POWERLegacy of Leadership Innovation
Driving Client Value
1990 1995 2000 2005 2010
POWER1
RSC
601
POWER5/5+
POWER4/4+
POWER7/7+
Cobra A10
45/32nm
65nm
130/90nm
180/130nm
0.5um
0.35um
0.25um0.18um
0.5um
0.5um
1.0um
0.72um
0.6um
0.35um
0.25um
604e
0.22um
POWER2
P2SC
0.35um
RS64I Apache
RS64II North Star
RS64III Pulsar
RS64IV Sstar
Muskie
A35
POWER8
22nm
Modern UNIX Era
Business
Workstation
PC
20152

© 2017 IBM Corporation
On-chip eDRAM (14nm)
- 6x latency improvement
- No off-chip signaling required
- 8x bandwidth improvement
- 3x less area than SRAM
- 5x less energy than SRAM
World class technology with value-added features for server business.
POWER9 is built on 14nm finFET technology transitioned to Global Foundaries
17-layer copper wire
Dense interconnect
- Faster connections
- Low latency distance paths
- High density complex circuits
- 2X wire per transistor DTDT
eDRAM Cell
IBM Optimized Semiconductor Technology
Silicon On Insulator-Faster Transistor, Less Noise
IBM Confidential
“IBM is committed to meeting the rising demands of cognitive systems and cloud computing. GF’s leading performance in 7LP process
technology, reflecting our joint Research collaboration, will allow IBM Power and Mainframe systems to push beyond limitations to
provide high-performance computing solutions while aggressively pursuing 5nm to advance our leadership for years to come.”
Tom Rosamilia, Senior Vice President, IBM Systems
© 2017 IBM Corporation
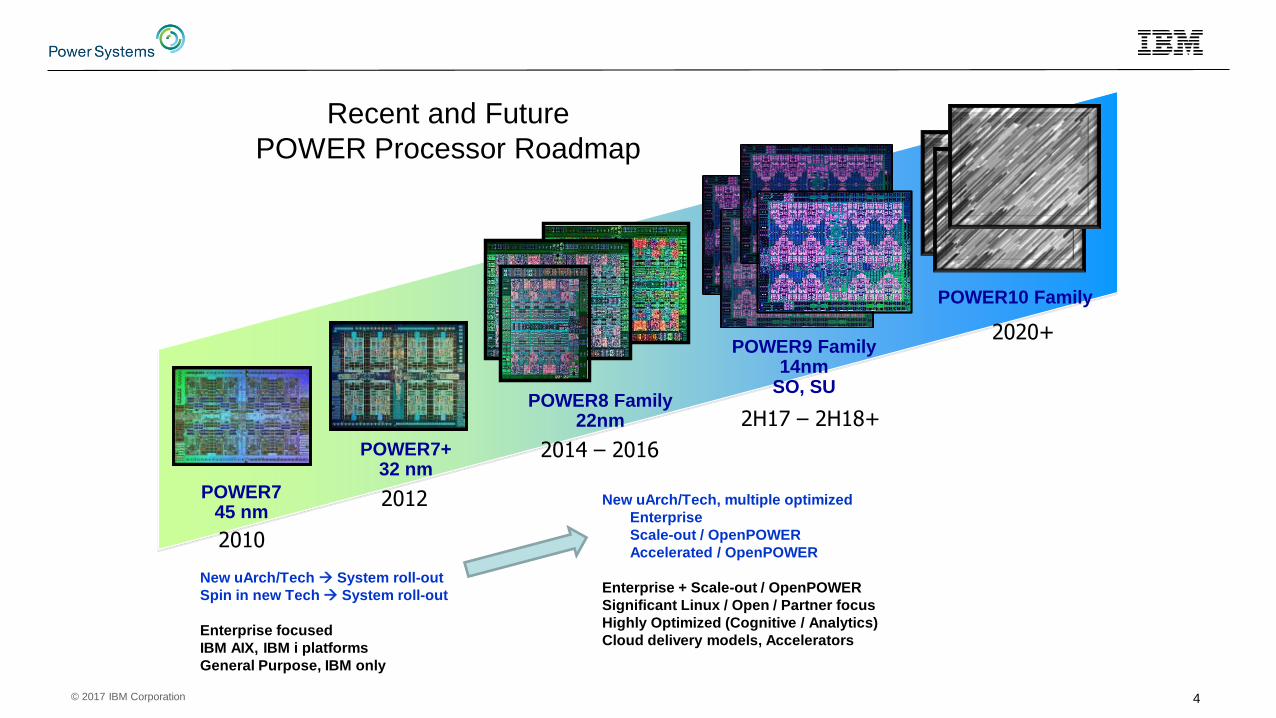
Recent and Future
POWER Processor Roadmap
2012
POWER7+32 nm
2H17 – 2H18+
2010
POWER745 nm
POWER9 Family 14nm
SO, SUPOWER8 Family
22nm
2014 – 2016
POWER10 Family
2020+
4
New uArch/Tech System roll-out
Spin in new Tech System roll-out
Enterprise focused
IBM AIX, IBM i platforms
General Purpose, IBM only
New uArch/Tech, multiple optimized
Enterprise
Scale-out / OpenPOWER
Accelerated / OpenPOWER
Enterprise + Scale-out / OpenPOWER
Significant Linux / Open / Partner focus
Highly Optimized (Cognitive / Analytics)
Cloud delivery models, Accelerators
© 2017 IBM Corporation
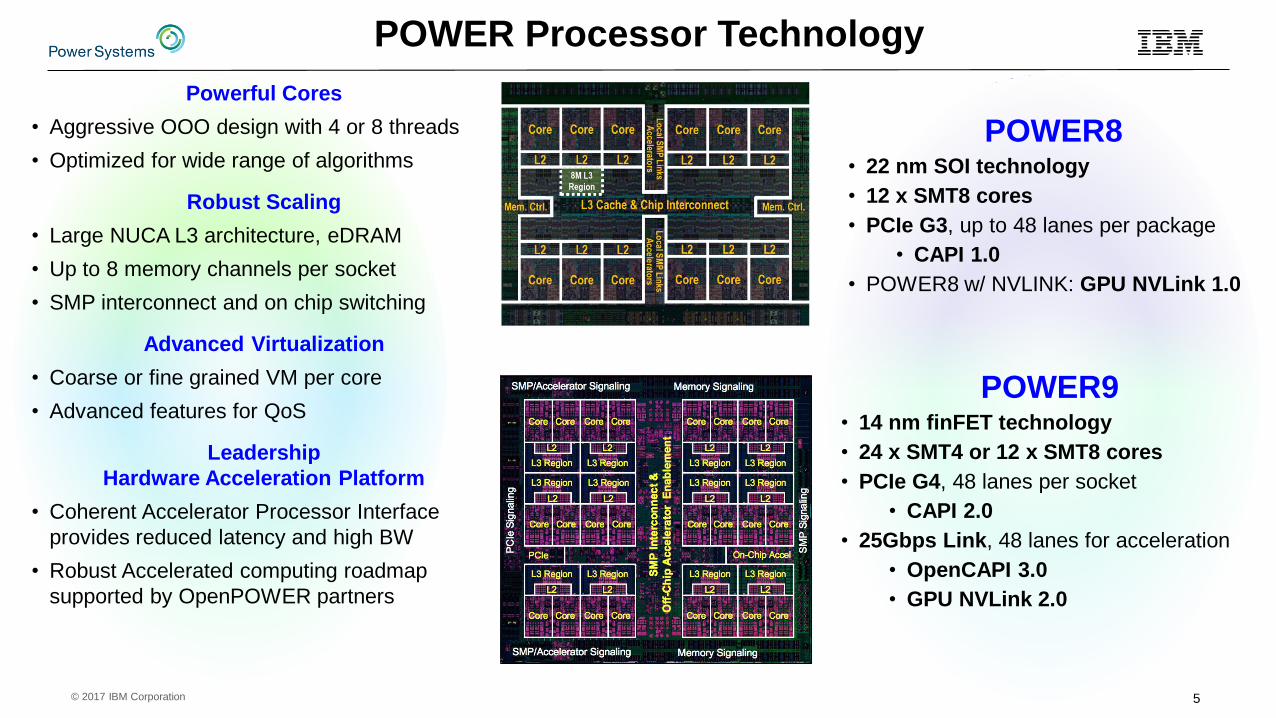
POWER Processor Technology
5
Powerful Cores
• Aggressive OOO design with 4 or 8 threads
• Optimized for wide range of algorithms
Robust Scaling
• Large NUCA L3 architecture, eDRAM
• Up to 8 memory channels per socket
• SMP interconnect and on chip switching
Advanced Virtualization
• Coarse or fine grained VM per core
• Advanced features for QoS
Leadership
Hardware Acceleration Platform
• Coherent Accelerator Processor Interface
provides reduced latency and high BW
• Robust Accelerated computing roadmap
supported by OpenPOWER partners
POWER9• 14 nm finFET technology
• 24 x SMT4 or 12 x SMT8 cores
• PCIe G4, 48 lanes per socket
• CAPI 2.0
• 25Gbps Link, 48 lanes for acceleration
• OpenCAPI 3.0
• GPU NVLink 2.0
POWER8• 22 nm SOI technology
• 12 x SMT8 cores
• PCIe G3, up to 48 lanes per package
• CAPI 1.0
• POWER8 w/ NVLINK: GPU NVLink 1.0
© 2017 IBM Corporation
OpenC
AP
I
OpenC
AP
IO
penC
AP
I
OpenC
AP
I
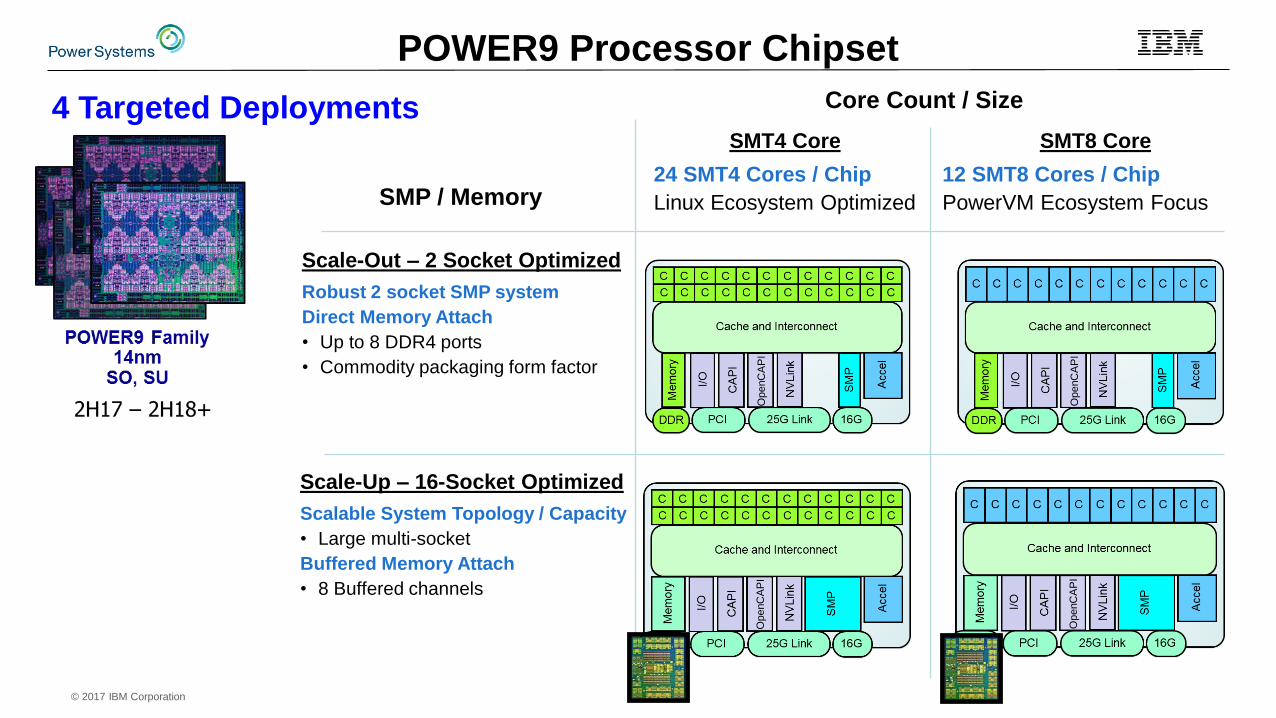
4 Targeted Deployments
Scale-Out – 2 Socket Optimized
Robust 2 socket SMP system
Direct Memory Attach
• Up to 8 DDR4 ports
• Commodity packaging form factor
Scale-Up – 16-Socket Optimized
Scalable System Topology / Capacity
• Large multi-socket
Buffered Memory Attach
• 8 Buffered channels
SMT4 Core
24 SMT4 Cores / Chip
Linux Ecosystem Optimized
SMT8 Core
12 SMT8 Cores / Chip
PowerVM Ecosystem Focus
Core Count / Size
SMP / Memory
POWER9 Processor Chipset

© 2017 IBM Corporation
POWER9: Improved Per Thread Performance with SMT4 or SMT8 Cores
7
POWER9 SMT8 Core• PowerVM Ecosystem Continuity
• Strongest Thread
• Optimized for Large Partitions
POWER9 SMT4 Core• Linux Ecosystem Focus
• Core Count / Socket
• Virtualization Granularity
SMT4 CoreSMT8 Core
• ‘Modular Execution’ enables SMT4 and SMT8 cores to be efficiently built from same DNA
• 96 threads per chip: 12 SMT8 cores or 24 SMT4 cores
– >2x threads per chip versus X86 offerings
• Each thread significantly stronger than in POWER8 due to increased HW resources

© 2017 IBM Corporation
Optimized for Cognitive Workloads and Stronger Thread Performance
• Shorter pipeline
• Increased execution bandwidth for a range of workloads including commercial, cognitive and analytics
• Sophisticated instruction scheduling & branch prediction for unoptimized code and interpretive languages
• Adaptive features for improved efficiency and performance
• Shared compute resource optimizes data-type interchange
New POWER9 Core MicroArchitecture
8
Symmetric Engines Per Data-Type for Higher Performance on Diverse Workloads

© 2017 IBM Corporation
POWER9 – Data Capacity & Throughput
17 Layers of Metal
Big Caches for Massively Parallel Compute
and Heterogeneous Interaction
Extreme Switching Bandwidth for the
Most Demanding Compute and Accelerated Workloads
eDRAM
POWER9
10M
Processing Cores
10M 10M 10M 10M 10M 10M 10M 10M 10M
7 TB/s
10M 10M
L3 Cache: 120 MB (POWER8 96 MB)
Shared Capacity NUCA Cache
• 12 Regions – one per 8 threads – provide dedicated local capacity
• Cache regions share data and capacity on demand
High-Throughput On-Chip Fabric
• POWER9: Over 7 TB/s On-chip Switch
• Move Data in/out at 256 GB/s per SMT8 Core
256 GB/s x 12
POWER9Nvidia GPU
MemoryIBM &
PartnerDevices
IBM &PartnerDevices
PCIeDevice
SM
P
NV
Lin
k 2
PC
Ie
Op
en
CA
PI
DD
R
CA
PI
9
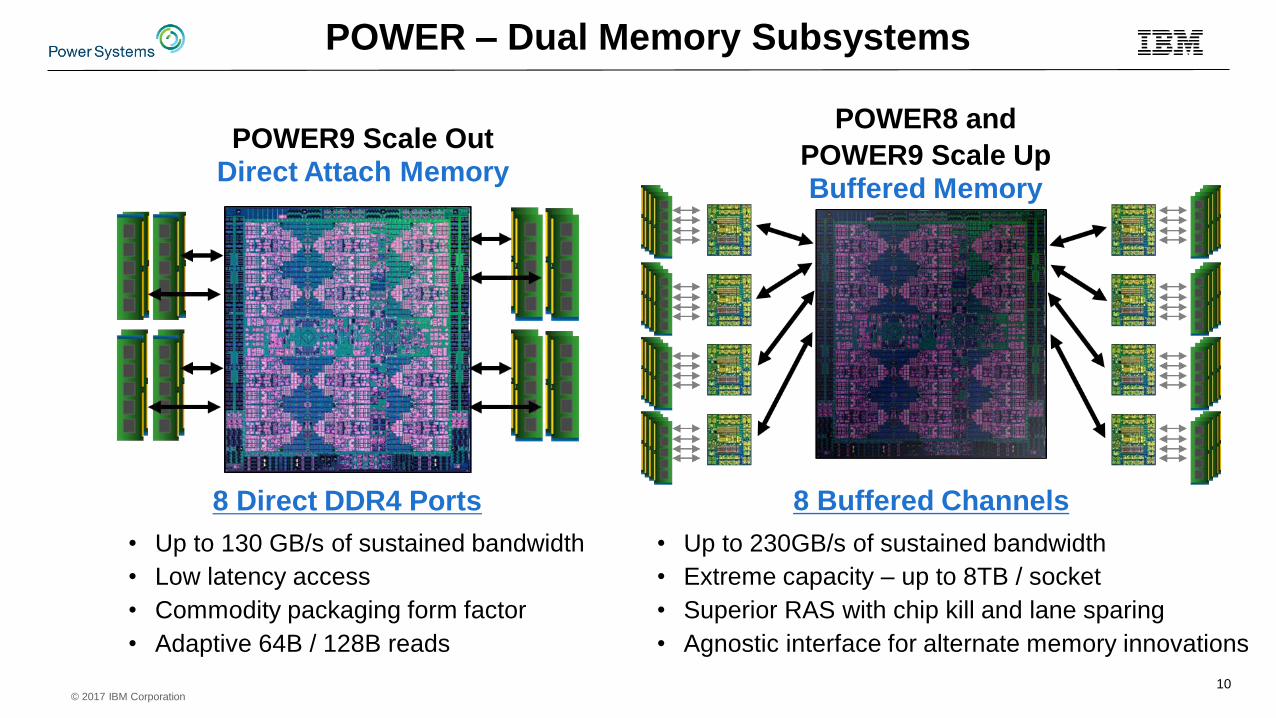
© 2017 IBM Corporation
POWER9 Scale OutDirect Attach Memory
8 Direct DDR4 Ports 8 Buffered Channels
POWER – Dual Memory Subsystems
POWER8 and
POWER9 Scale UpBuffered Memory
10
• Up to 130 GB/s of sustained bandwidth
• Low latency access
• Commodity packaging form factor
• Adaptive 64B / 128B reads
• Up to 230GB/s of sustained bandwidth
• Extreme capacity – up to 8TB / socket
• Superior RAS with chip kill and lane sparing
• Agnostic interface for alternate memory innovations
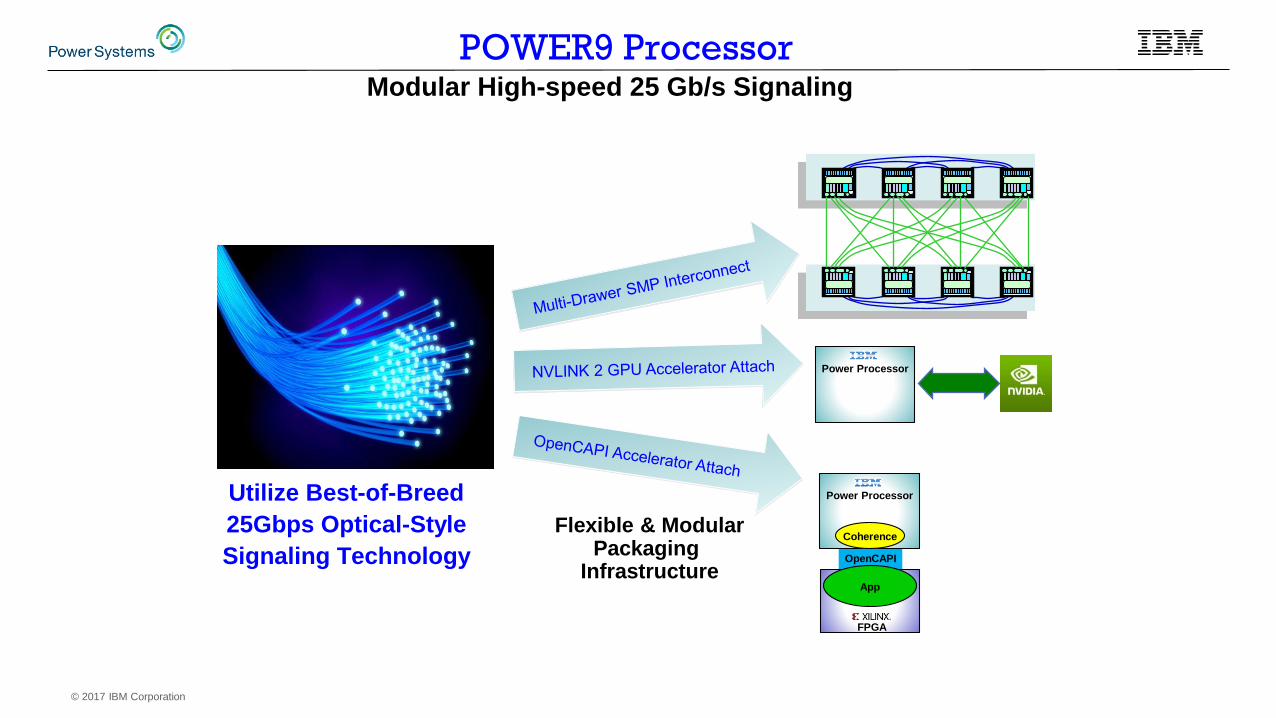
© 2017 IBM Corporation
Utilize Best-of-Breed
25Gbps Optical-Style
Signaling Technology
Flexible & ModularPackaging
Infrastructure
FPGA
Power Processor
Coherence
App
OpenCAPI
Power Processor
Modular High-speed 25 Gb/s Signaling
POWER9 Processor
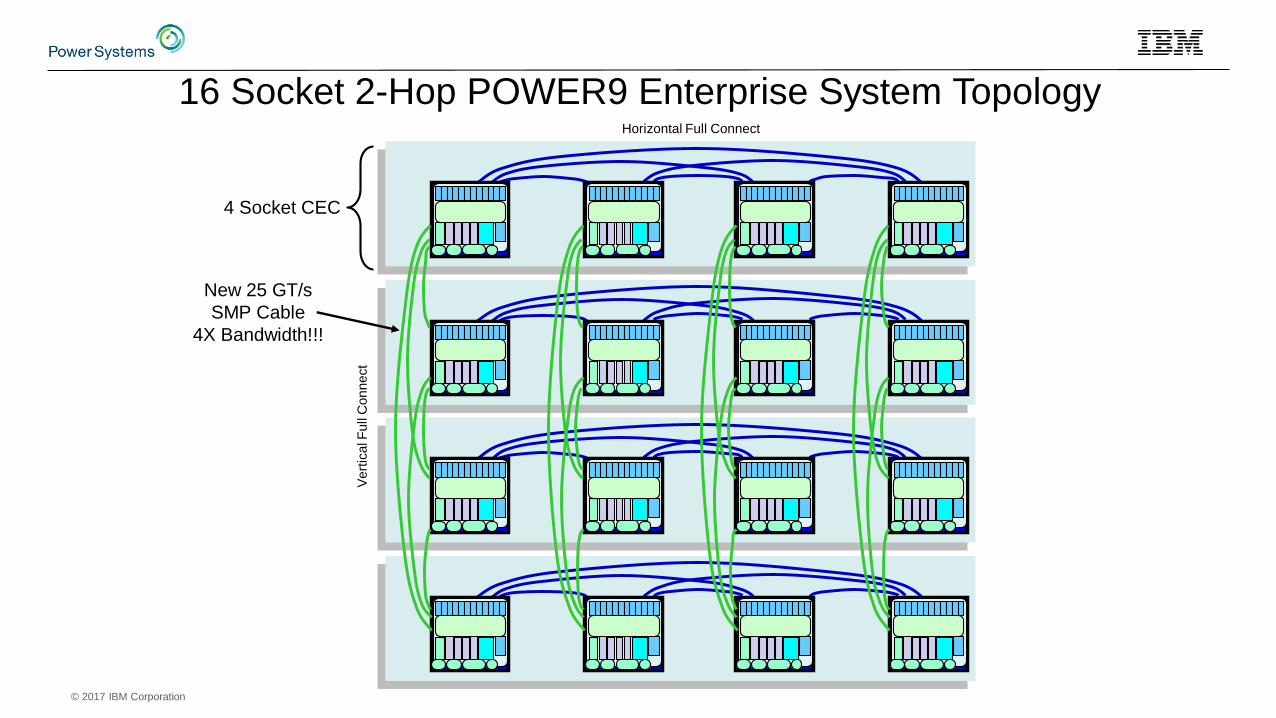
© 2017 IBM Corporation
Horizontal Full Connect
Vert
ical F
ull C
on
ne
ct
16 Socket 2-Hop POWER9 Enterprise System Topology
4 Socket CEC
New 25 GT/s
SMP Cable
4X Bandwidth!!!
© 2017 IBM Corporation
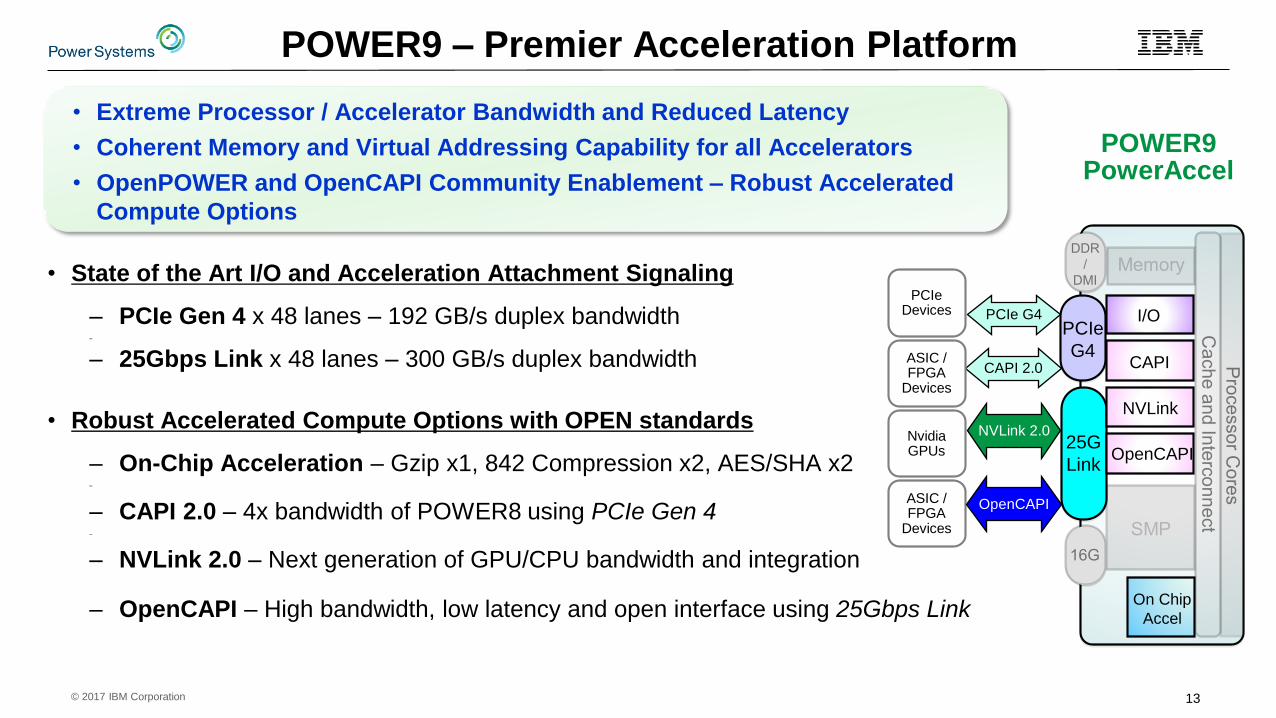
POWER9 – Premier Acceleration Platform
• Extreme Processor / Accelerator Bandwidth and Reduced Latency
• Coherent Memory and Virtual Addressing Capability for all Accelerators
• OpenPOWER and OpenCAPI Community Enablement – Robust Accelerated
Compute Options
13
• State of the Art I/O and Acceleration Attachment Signaling
– PCIe Gen 4 x 48 lanes – 192 GB/s duplex bandwidth–
– 25Gbps Link x 48 lanes – 300 GB/s duplex bandwidth
• Robust Accelerated Compute Options with OPEN standards
– On-Chip Acceleration – Gzip x1, 842 Compression x2, AES/SHA x2–
– CAPI 2.0 – 4x bandwidth of POWER8 using PCIe Gen 4–
– NVLink 2.0 – Next generation of GPU/CPU bandwidth and integration
– OpenCAPI – High bandwidth, low latency and open interface using 25Gbps Link
POWER9PowerAccel
On Chip
Accel
25G
Link
Nvidia GPUs
I/O
CAPI
NVLink
OpenCAPI
PCIe
G4CAPI 2.0
PCIe G4
ASIC / FPGA
Devices
ASIC / FPGA
Devices
PCIeDevices
NVLink 2.0
OpenCAPI

© 2017 IBM Corporation
Accelerated Solution Enablement
• POWER8: CAPI (Coherent Accelerator Processor Interface): – Enables coherent attach of external devices over PCIe Gen3 physicals
– Simplifies programming model, eliminates code-path overhead of accelerator / storage / network access
POWER9:
• CAPI 2.0: PCIe Gen4 provides 4x bandwidth of POWER8
• OpenCAPI 3.0: 100% Open Interface Architecture with low-latency, high bandwidth attach (up to 200GBps)
– Ability to connect to user-level accelerators, storage + network devices, and advanced memories
PC
Ie G
en
4
Co
here
nce
Bu
s
CA
PI
Op
en
CA
PI
CA
PI
25G
25G
Host-architecture
agnostic 200 GBps
128 GBps AdvancedMemory
(SCM)
Accelerators
Storage
Network
14
Accelerators
Storage
Network
© 2017 IBM Corporation 15
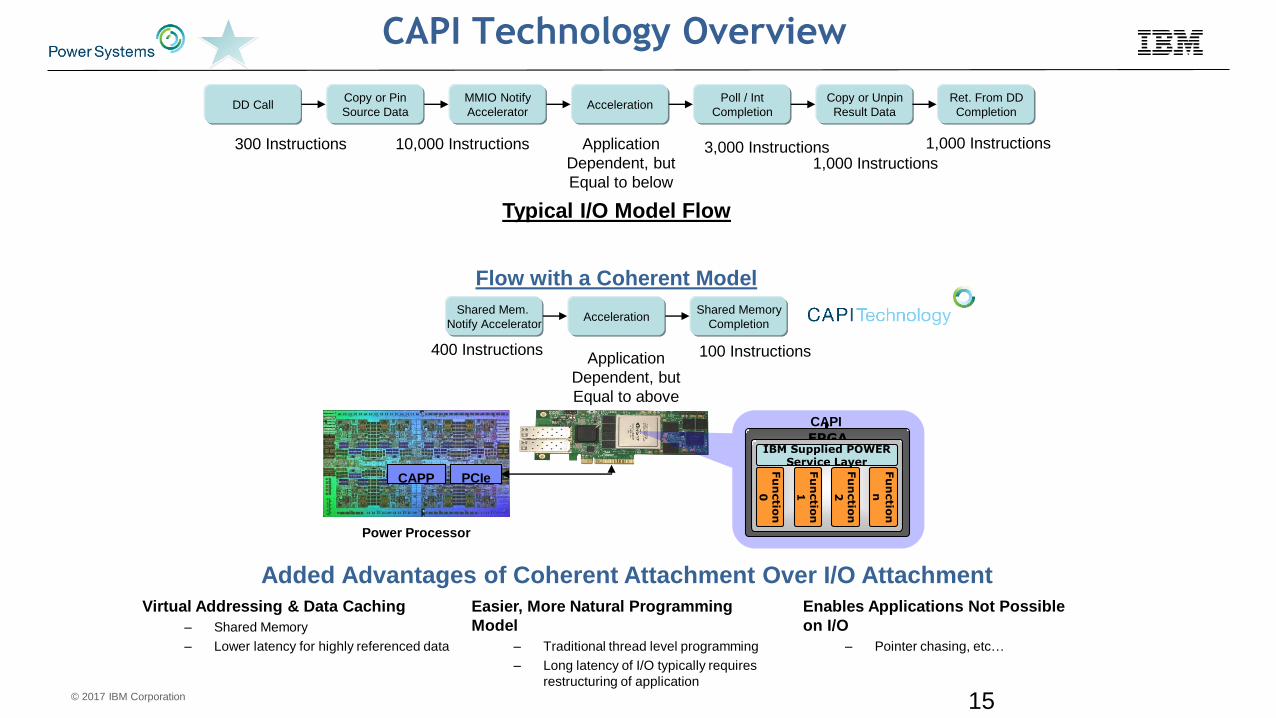
CAPI Technology Overview
CAPP PCIe
Power Processor
FPGA
Fu
nctio
n
n
Fu
nctio
n
0
Fu
nctio
n
1
Fu
nctio
n
2
CAPI
IBM Supplied POWER Service Layer
Typical I/O Model Flow
Added Advantages of Coherent Attachment Over I/O Attachment
Virtual Addressing & Data Caching
– Shared Memory
– Lower latency for highly referenced data
Easier, More Natural Programming
Model
– Traditional thread level programming
– Long latency of I/O typically requires
restructuring of application
Enables Applications Not Possible
on I/O
– Pointer chasing, etc…
DD CallCopy or Pin
Source Data
MMIO Notify
AcceleratorAcceleration
Poll / Int
Completion
Copy or Unpin
Result Data
Ret. From DD
Completion
3,000 Instructions1,000 Instructions
1,000 Instructions300 Instructions 10,000 Instructions Application
Dependent, but
Equal to below
Flow with a Coherent Model
Shared Mem.
Notify AcceleratorAcceleration
Shared Memory
Completion
400 Instructions 100 InstructionsApplication
Dependent, but
Equal to above
© 2017 IBM Corporation
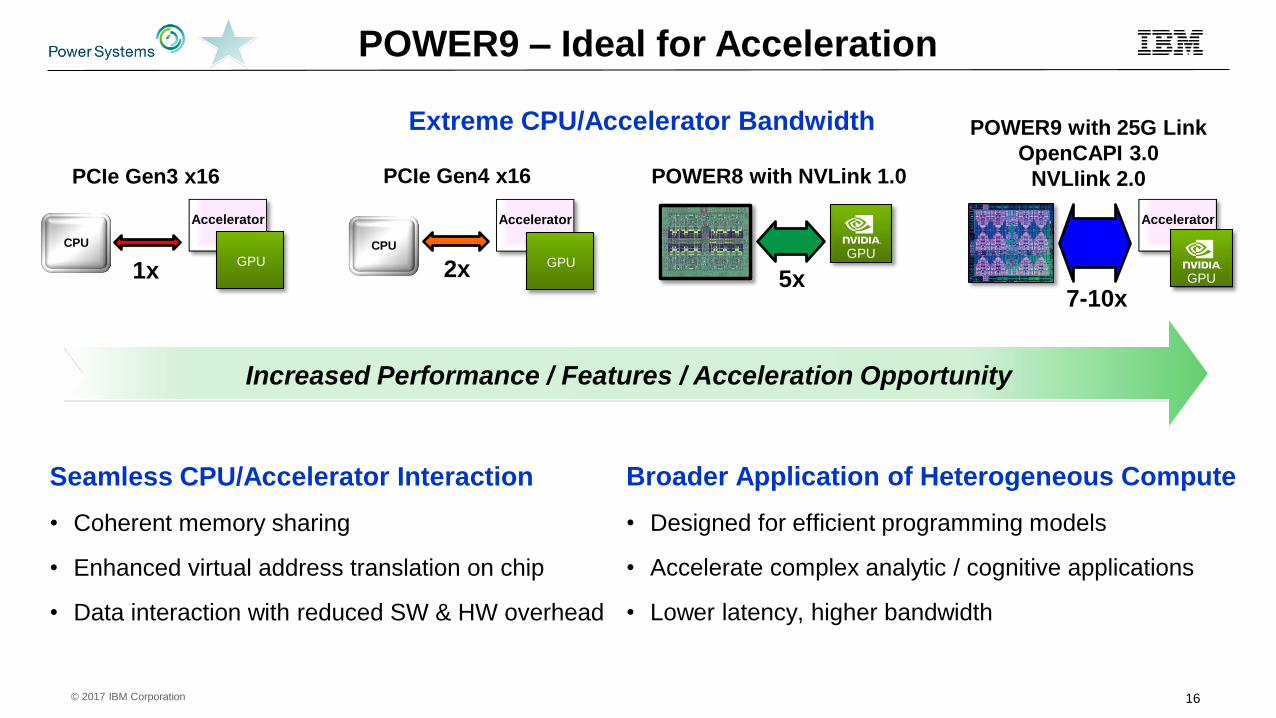
POWER9 – Ideal for Acceleration
Seamless CPU/Accelerator Interaction
• Coherent memory sharing
• Enhanced virtual address translation on chip
• Data interaction with reduced SW & HW overhead
16
2x1x
CPUGPU
Accelerator
CPU
5x7-10x
PCIe Gen3 x16
GPU
Accelerator
GPU
Accelerator
GPU
PCIe Gen4 x16 POWER8 with NVLink 1.0
POWER9 with 25G Link
OpenCAPI 3.0
NVLIink 2.0
Increased Performance / Features / Acceleration Opportunity
Extreme CPU/Accelerator Bandwidth
Broader Application of Heterogeneous Compute
• Designed for efficient programming models
• Accelerate complex analytic / cognitive applications
• Lower latency, higher bandwidth
© 2017 IBM Corporation
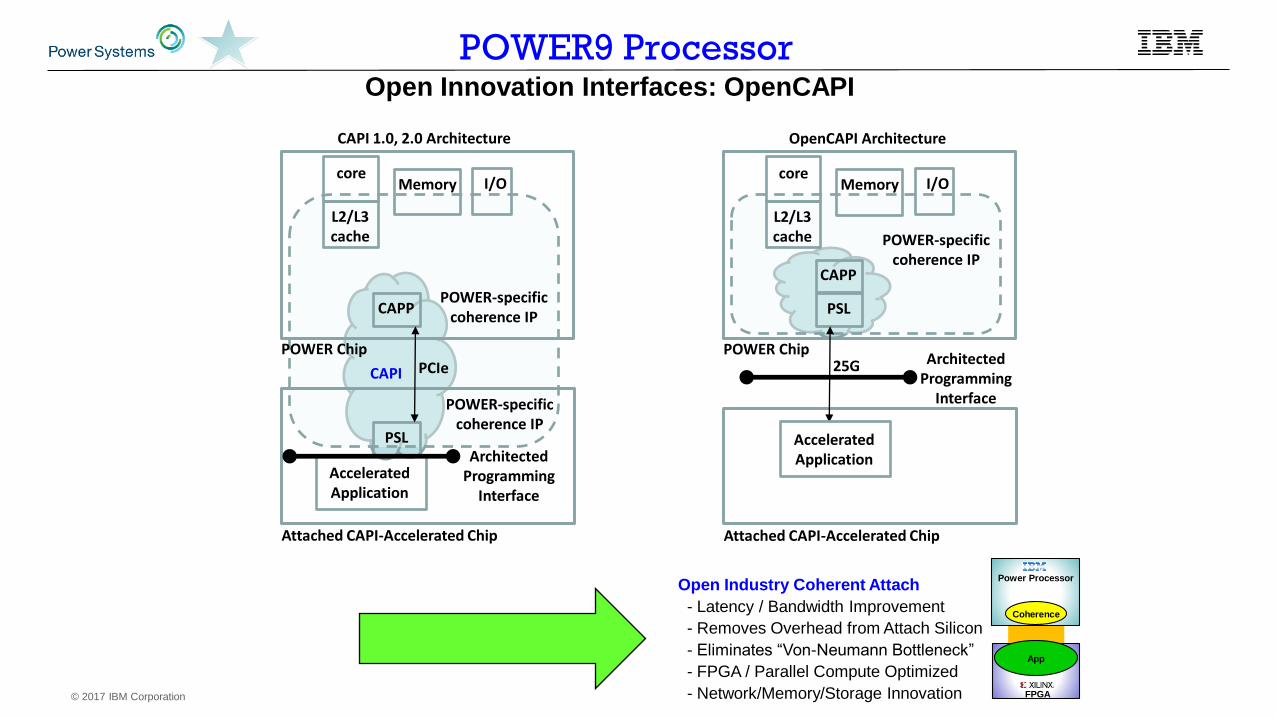
CAPI 1.0, 2.0 Architecture
POWER-specificcoherence IP
L2/L3cache
coreMemory I/O
CAPP
POWER Chip
Attached CAPI-Accelerated Chip
POWER-specificcoherence IP
PSL
AcceleratedApplication
ArchitectedProgramming
Interface
CAPI
OpenCAPI Architecture
POWER-specificcoherence IP
L2/L3cache
coreMemory I/O
CAPP
POWER Chip
Attached CAPI-Accelerated Chip
PSL
AcceleratedApplication
ArchitectedProgramming
Interface
Open Industry Coherent Attach
- Latency / Bandwidth Improvement
- Removes Overhead from Attach Silicon
- Eliminates “Von-Neumann Bottleneck”
- FPGA / Parallel Compute Optimized
- Network/Memory/Storage Innovation FPGA
Power Processor
Coherence
App
PCIe 25G
POWER9 ProcessorOpen Innovation Interfaces: OpenCAPI

© 2017 IBM Corporation
POWER ISA Version 3.0
Broad data type support & engines
• SIMD architecture and evolving instruction set (dozens of new instructions on POWER9)
– 128b native SIMD, doubleword, word, halfword, byte
– Half-precision float conversion
• Decimal float, BCD, 128b IEEE 754 Quad Precision Float, 128b Quad Precision Fixed Point and Decimal Integer
• Random Number Generation Instruction
Memory Management
• Hashed Page Table: 4k, 64k, 16M, 16G pages
• Radix Page Table: 4k, 64k, 2M, 1G pages, with full virtualization Reduce the Translation Lookaside Buffer (TLB)
• Little and big endian data handling
• Memory Atomics
• Weak ordered memory model
Cloud and Accelerator Optimization
• New Interrupt Architecture with automated partition routing
• User access to virtualized acceleration features
• QoS controls
Energy & Frequency Management
• Energy management instructions
• Workload Optimized Frequency – Manage energy between threads and cores with reduced wakeup latency
POWER Architecture at a Glance (new for POWER9 in blue)
18


Additional content:
OpenCAPI
Systems Overview
Large System SMP Topology
Core Microarchitecture
POWER Porting
20

POWER Systems Portfolio
Enterprise Systems
(4 socket to 16 sockets)• 4U 4 socket or modular 5U (1-4)
• Up to 1536 HW threads
• Up to 32-64 TB of system memory
• 3.6 to 4.3 Ghz processor speed
POWER Systems POWER Features
Leading Scale & Capacity vs. x86
• Large HW thread pool
• Large on-chip caches
• Memory bandwidth and capacity
• SMP scalability
• Accelerated computing interconnect
Robust Enterprise Capability vs. x86
• Reliability, Availability, Serviceability
(RAS)
• PowerVM system management
• Capacity on demand and high
availability fail-over
Optimized for Open
• Umbuntu, SUSE, Redhat, OpenStack,
PowerKVM
• Linux only system offerings
• OpenPower Foundation
Scale out Systems
(1-2 sockets)• 1U to 4U
• Up to 192 HW threads
• Up to 16 TB of system memory
• 2.0 to 4.2 Ghz processor speed
Price / PerformanceOpen/Industry designs + stacksCluster Optimized
ScaleReliabilityVirtualization Optimized
21

© 2016 IBM Corporation
POWER9 Core Execution Slice Microarchitecture
128b
Super-slice
DW
LSU
64b
VSU
64b
Slice
POWER9 SMT8 Core
DW
LSU
64b
VSU
DW
LSU
64b
VSU
Modular Execution Slices
Re-factored Core Provides Improved Efficiency & Workload Alignment
• Enhanced pipeline efficiency with modular execution and intelligent pipeline control
• Increased pipeline utilization with symmetric data-type engines: Fixed, Float, 128b, SIMD
• Shared compute resource optimizes data-type interchange
VSUFXU
IFU
DFU
ISU
LSU
POWER8 SMT8 Core
4 x 128b
Super-slice
22
POWER9 SMT4 Core
2 x 128b
Super-slice
LSU
IFU
ISU ISU
IFU
Exec
Slice
LSU
Exec
Slice
Exec
Slice
Exec
Slice
Exec
Slice
Exec
Slice
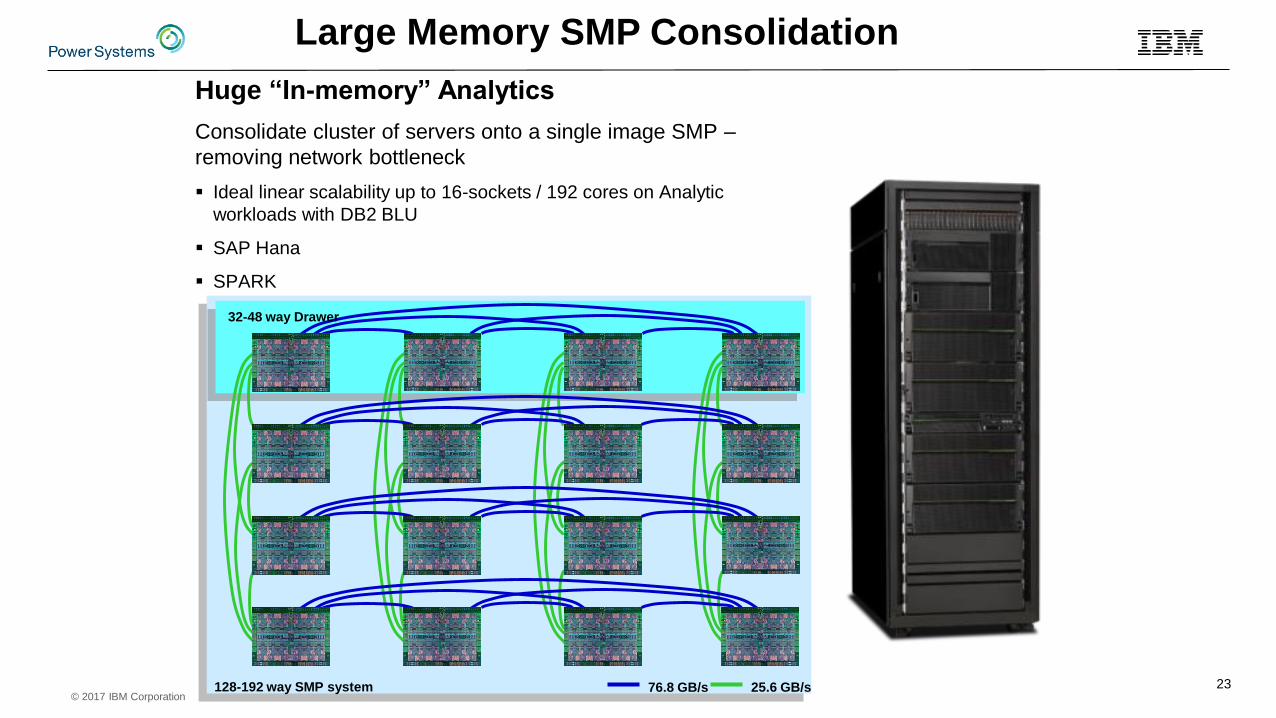
© 2017 IBM Corporation23128-192 way SMP system
32-48 way Drawer
76.8 GB/s 25.6 GB/s
Huge “In-memory” Analytics
Consolidate cluster of servers onto a single image SMP –
removing network bottleneck
Ideal linear scalability up to 16-sockets / 192 cores on Analytic
workloads with DB2 BLU
SAP Hana
SPARK
Large Memory SMP Consolidation
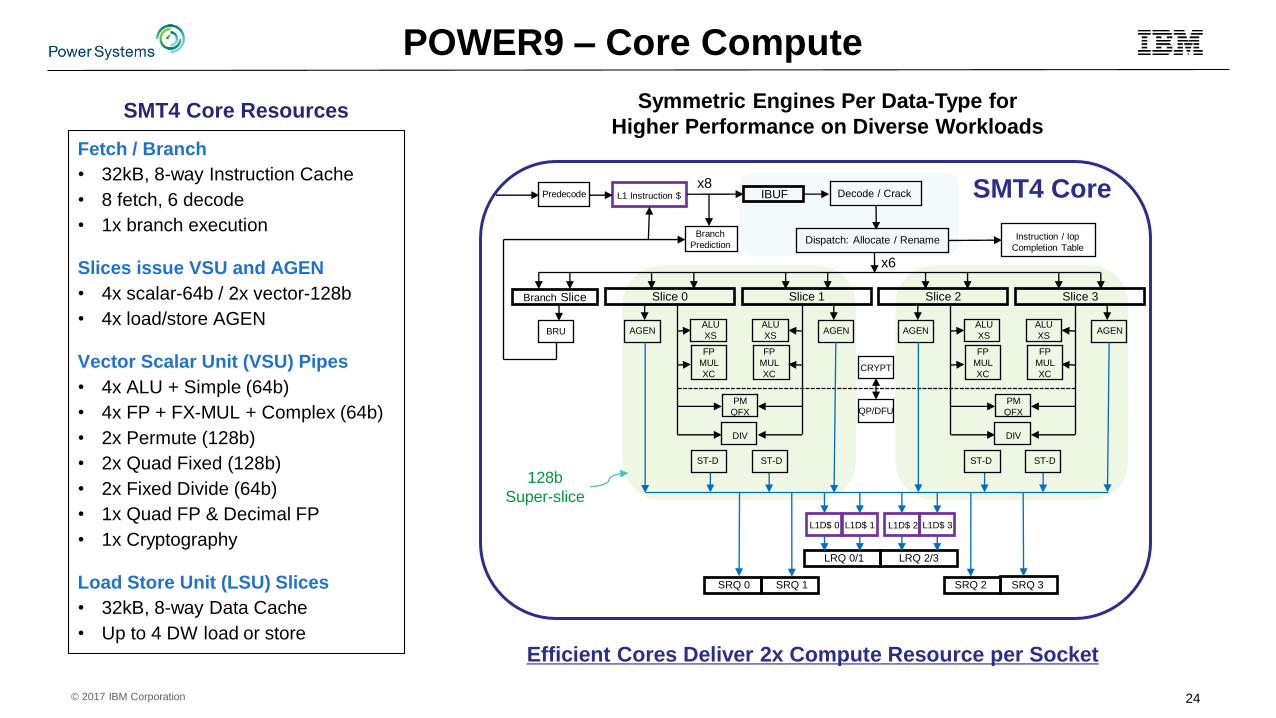
© 2017 IBM Corporation
PM
QFX
Slice 3
AGEN
Slice 2
AGEN
CRYPT
QP/DFU
Branch Slice
BRU
DIV
ALU
XS
FP
MUL
XC
ST-D
FP
MUL
XC
FP
MUL
XC
FP
MUL
XC
ALU
XS
ST-D
PM
QFX
Slice 1
AGEN
Slice 0
AGEN
DIV
ALU
XS
ST-D
ALU
XS
ST-D
LRQ 2/3
L1D$ 3L1D$ 2
SRQ 2 SRQ 3
LRQ 0/1
L1D$ 0 L1D$ 1
SRQ 1SRQ 0
Dispatch: Allocate / Rename
Decode / CrackIBUFL1 Instruction $Predecode
Branch
PredictionInstruction / Iop
Completion Table
128b
Super-slice
SMT4 Core
x6
x8
POWER9 – Core Compute
Efficient Cores Deliver 2x Compute Resource per Socket
Symmetric Engines Per Data-Type for
Higher Performance on Diverse WorkloadsFetch / Branch
• 32kB, 8-way Instruction Cache
• 8 fetch, 6 decode
• 1x branch execution
Slices issue VSU and AGEN
• 4x scalar-64b / 2x vector-128b
• 4x load/store AGEN
Vector Scalar Unit (VSU) Pipes
• 4x ALU + Simple (64b)
• 4x FP + FX-MUL + Complex (64b)
• 2x Permute (128b)
• 2x Quad Fixed (128b)
• 2x Fixed Divide (64b)
• 1x Quad FP & Decimal FP
• 1x Cryptography
Load Store Unit (LSU) Slices
• 32kB, 8-way Data Cache
• Up to 4 DW load or store
SMT4 Core Resources
24

© 2017 IBM Corporation
Special noticesThis document was developed for IBM offerings in the United States as of the date of publication. IBM may not make these offerings available in other
countries, and the information is subject to change without notice. Consult your local IBM business contact for information on the IBM offerings available in
your area.
Information in this document concerning non-IBM products was obtained from the suppliers of these products or other public sources. Questions on the
capabilities of non-IBM products should be addressed to the suppliers of those products.
IBM may have patents or pending patent applications covering subject matter in this document. The furnishing of this document does not give you any
license to these patents. Send license inquiries, in writing, to IBM Director of Licensing, IBM Corporation, New Castle Drive, Armonk, NY 10504-1785
USA.
All statements regarding IBM future direction and intent are subject to change or withdrawal without notice, and represent goals and objectives only.
The information contained in this document has not been submitted to any formal IBM test and is provided "AS IS" with no warranties or guarantees either
expressed or implied.
All examples cited or described in this document are presented as illustrations of the manner in which some IBM products can be used and the results
that may be achieved. Actual environmental costs and performance characteristics will vary depending on individual client configurations and conditions.
IBM Global Financing offerings are provided through IBM Credit Corporation in the United States and other IBM subsidiaries and divisions worldwide to
qualified commercial and government clients. Rates are based on a client's credit rating, financing terms, offering type, equipment type and options, and
may vary by country. Other restrictions may apply. Rates and offerings are subject to change, extension or withdrawal without notice.
IBM is not responsible for printing errors in this document that result in pricing or information inaccuracies.
All prices shown are IBM's United States suggested list prices and are subject to change without notice; reseller prices may vary.
IBM hardware products are manufactured from new parts, or new and serviceable used parts. Regardless, our warranty terms apply.
Any performance data contained in this document was determined in a controlled environment. Actual results may vary significantly and are dependent on
many factors including system hardware configuration and software design and configuration. Some measurements quoted in this document may have
been made on development-level systems. There is no guarantee these measurements will be the same on generally-available systems. Some
measurements quoted in this document may have been estimated through extrapolation. Users of this document should verify the applicable data for their
specific environment. Revised September 26, 2006
25

© 2017 IBM Corporation
Special notices (continued)
26
IBM, the IBM logo, ibm.com AIX, AIX (logo), IBM Watson, DB2 Universal Database, POWER, PowerLinux, PowerVM, PowerVM (logo), PowerHA, Power Architecture, Power Family, POWER Hypervisor,
Power Systems, Power Systems (logo), POWER2, POWER3, POWER4, POWER4+, POWER5, POWER5+, POWER6, POWER6+, POWER7, POWER7+, and POWER8 are trademarks or registered
trademarks of International Business Machines Corporation in the United States, other countries, or both. If these and other IBM trademarked terms are marked on their first occurrence in this information
with a trademark symbol (® or ™), these symbols indicate U.S. registered or common law trademarks owned by IBM at the time this information was published. Such trademarks may also be registered
or common law trademarks in other countries.
A full list of U.S. trademarks owned by IBM may be found at: http://www.ibm.com/legal/copytrade.shtml.
NVIDIA, the NVIDIA logo, and NVLink are trademarks or registered trademarks of NVIDIA Corporation in the United States and other countries.
Linux is a registered trademark of Linus Torvalds in the United States, other countries or both.
PowerLinux™ uses the registered trademark Linux® pursuant to a sublicense from LMI, the exclusive licensee of Linus Torvalds, owner of the Linux® mark on a world-wide basis.
The Power Architecture and Power.org wordmarks and the Power and Power.org logos and related marks are trademarks and service marks licensed by Power.org.
The OpenPOWER word mark and the OpenPOWER Logo mark, and related marks, are trademarks and service marks licensed by OpenPOWER.
Other company, product and service names may be trademarks or service marks of others.