policy consideration for development and deployment of ... · policy consideration for development...
TRANSCRIPT

1
Policy Consideration for Development and Deployment of Local Languages
Computing and Content
Hammam [email protected] for the Assessment and Application of Technology (BPPT)Ministry of Research and Technology, Republic of Indonesia
Regional Conference on Localized ICT Development and Dissemination across Asia 12-16 January 2009, Vientiane, Laos

Concept of Knowledge Societies
FreedomInclusivenessDiversityEmpowerment
Source: UNESCO 2007

State of the World: Digital Divide
Access to ICTs grows steadily, but ‘digital divide’ persists.
Proportion of world population with telephonesubscriptions, PCs and internetconnections, 1990-2004 (Percentage)
Source:The Millennium Development Goals Report 2006

History of Language Survey in Indonesia
Esser (1951) 200 languagesAlisyahbana (1954) ~200 languagesSalzmer (1960) 96 languagesLembaga Bahasa Nasional (1972) 418 languagesGrimes (1988) ~672 languagesSIL (2006) 742 languages

Language Survey – Latest Result
National Language Survey at 2815 Observation Area discovered 442 languages (Peta Bahasa di Indonesia, National Language Center 2008)Project started in 1992-2008Dialectrometri vs Lexicostatistics
Dialectrometri method is used to identify the language, dialect, or sub dialect variations
Lexicostatistics is an approach to comparative linguistics that involves quantitative comparison of lexical cognates.
Based on 400 word list, taking 80% threshold comparing both phonology and lexicon of each languageCollection of speech resource was very limited

Distribution of 13 Major Languages of Indonesia
Speakers (million)
Jawa 75.2
Sunda 27.0
Melayu 20.0
Madura 13.7
Minangkabau 6.5
Batak 5.2
Bugis 4.0
Bali 3.8
Aceh 3.0
Sasak 2.1
Makasar 1.6
Lampung 1.5
Rejang 1.0
713 languages 45.4

Digital Language DivideLanguage Preservation
From the survey of indigenous local languages, we can observe digital language divideLocal computing policy will be developed for major local languagesLess Privileged languages are identified and preserved by means of ICTLanguage resources collection for major local languages (2009-2010)

Chinese, Japanese and Korean are excluded from the analysis
Hebrew, Thai, Turkish, Vietnamese, Arabic, Tatar, Farsi, Javanese, Indonesian, Malay, Sundanese, Hindi, Dari, Uzbek, Mongolian, Kazakh, Madurese, Uighur, Kashmiri Pushtu, Balochi, Turkmen, Minangkabau, Bikol, Kyrgyz, Balinese, Punjabi, Sindhi, Acehnese, Sinhala, Kapampangan, Iloko, Bengali & Assamese, Filipino, Waray, Bugisnese, Burmese, Kurdish, Tajiki, Azeri, Tamil, Hiligaynon, Dhivehi, Bhojpuri, Tibetan, Cebuano, Telugu, Saraiki, Lao, Gujarati, Pashto, Kannada, Urdu, Khmer, Hani
Scanning Asian languages on Internet – Discovered 55

LOCAL & CROSS-BORDER LANGUAGES
0%10%20%30%40%50%60%70%80%90%
100%
bn id kh la my mm ph sg th tp vn
South East Asia
% Local Languages % English % Other Cross Boader Languages
Note:Cross-Border Languages in Indonesia:English, Arabic, Chinese, French, German, Dutch, Japanese, etc.

Language EmpowermentA Holistic View
language community
gov
OSSdevelopers
IT firms
users
languageportal
mediapress
motherlanguage
for creation
highereducation
local language
search engines
electronic delivery of
public services
����������
����������
localization of application SW
based on standard
creation of local contents
literacy
��������OCR, TTS, ��
mother language use in higher
education
promotion of NLPOCR, TTS, MTe-dictionary, etc

Standardization and Basic Localization for Bahasa Nusantara
Encoding of scripts, e.g. in UnicodeKeyboard layoutFonts and renderingLocale (e.g. CLDR, ICU)Local language interfaceBasic language resource kit (BLARK)Application localization
Document processor, web browser, email client, etc.

Advanced Applications
Online content access applicationsText to Speech (TTS)Search/information retrieval (IR)
Content generation applicationsOptical Character Recognition system (OCR)Machine Translation (MT) Automatic Speech Recognition (ASR)Summarization

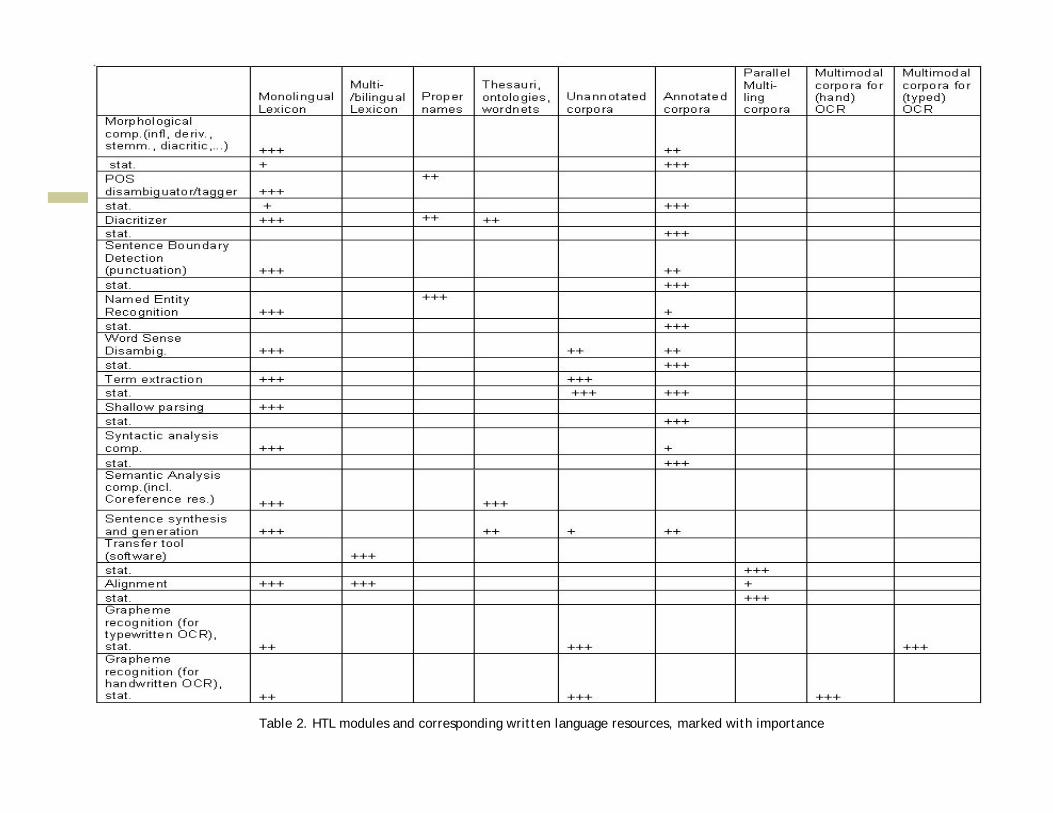
Table 2. HTL modules and corresponding written language resources, marked with importance

Table 3. Speech application and corresponding speech modules, marked with importance

Table 4. Speech modules and corresponding spoken language resources, marked with importance

ACEH – 32 local languages

EAST JAVA – 6 local languages

Future Work
We advocate and expect P2P Platform, once proposed in an open-access mode on the Web, to be willingly and freely operated by other researchers, under an agreed collaborative framework to be set up, with minimal method and technical consent on collecting procedures and corpus characteristic profiles, in order to bring building and sharing of raw multilingual speech corpora to a more rapid expansion.Collaborative annotation work could take place as well, again with simple agreed procedures on content and descriptor files formats, and on a public use scheme. Such tools, and their open use, could as well underlie valuable action towards supportive protection of “less privileged languages"

Thank You
Language is the heart of a culture. A lost of a language, is a lost for
humanity.