personalized job recommendation system at linkedin: practical challenges and lessons learned
TRANSCRIPT

Personalized Job Recommendation
System at LinkedIn: Practical
Challenges and Lessons Learned
Krishnaram Kenthapadi
Staff Software Engineer - LinkedIn
Benjamin Le
Senior Software Engineer - LinkedIn
Ganesh Venkataraman
Engineering Manager - Airbnb
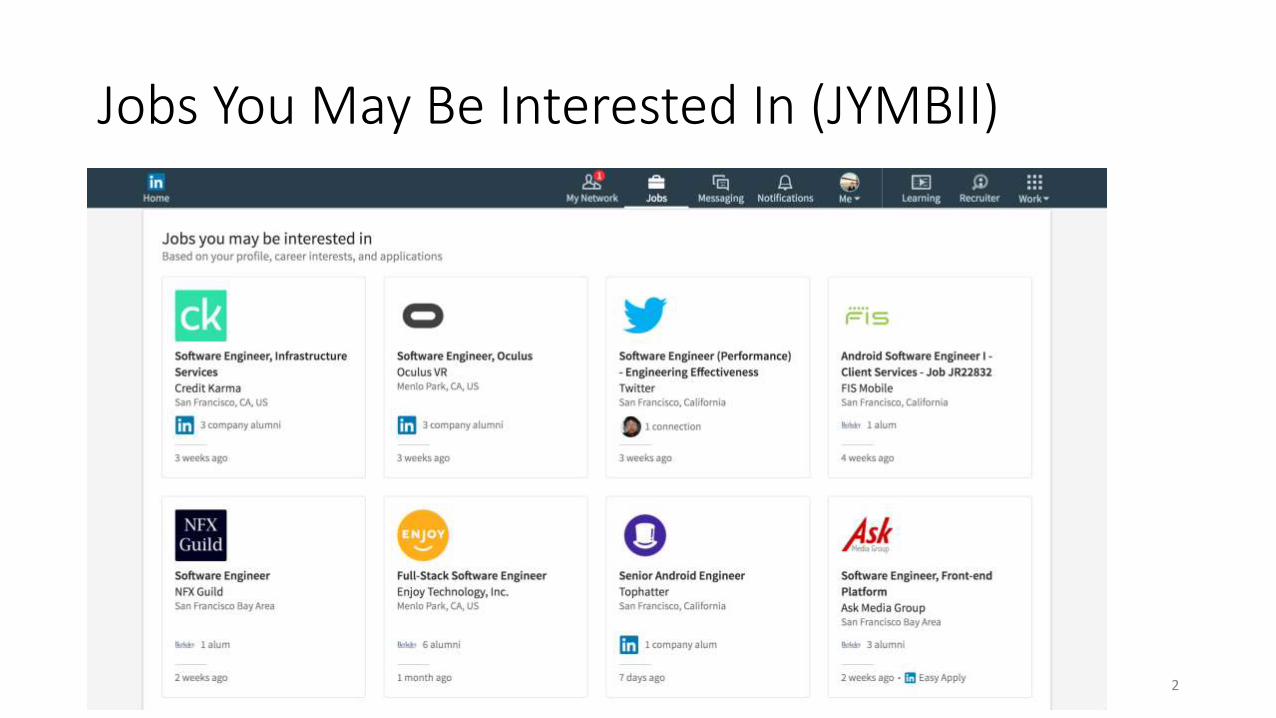
Jobs You May Be Interested In (JYMBII)
2

Practical Challenges in JYMBII
• Candidate Selection
• Personalized Relevance Models at Scale
• Jobs Marketplace
3

Candidate Selection

Why Candidate Selection?
•Need to meet latency requirements of an online recommendation system
•Only subset of jobs is relevant to a user based on their domain and expertise
• Enables scoring with more complex and computationally expensive models
5
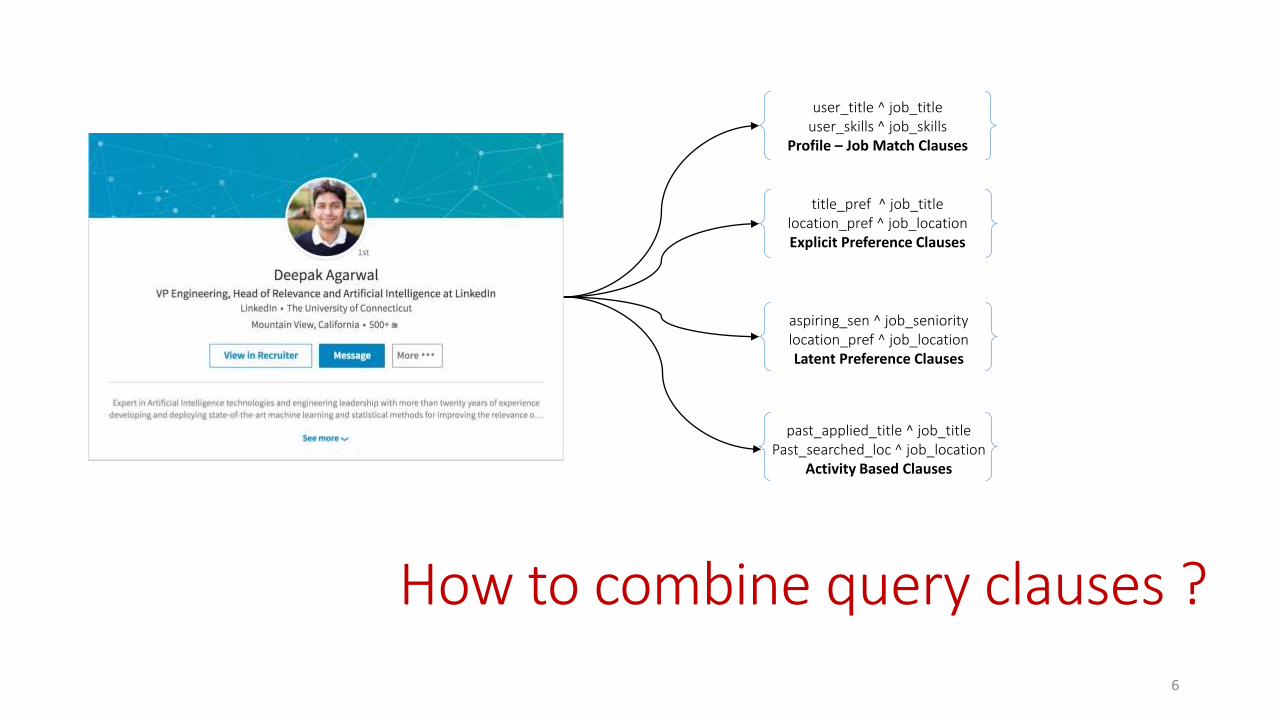
past_applied_title ^ job_titlePast_searched_loc ^ job_location
Activity Based Clauses
How to combine query clauses ?
user_title ^ job_titleuser_skills ^ job_skills
Profile – Job Match Clauses
title_pref ^ job_titlelocation_pref ^ job_locationExplicit Preference Clauses
aspiring_sen ^ job_senioritylocation_pref ^ job_locationLatent Preference Clauses
6
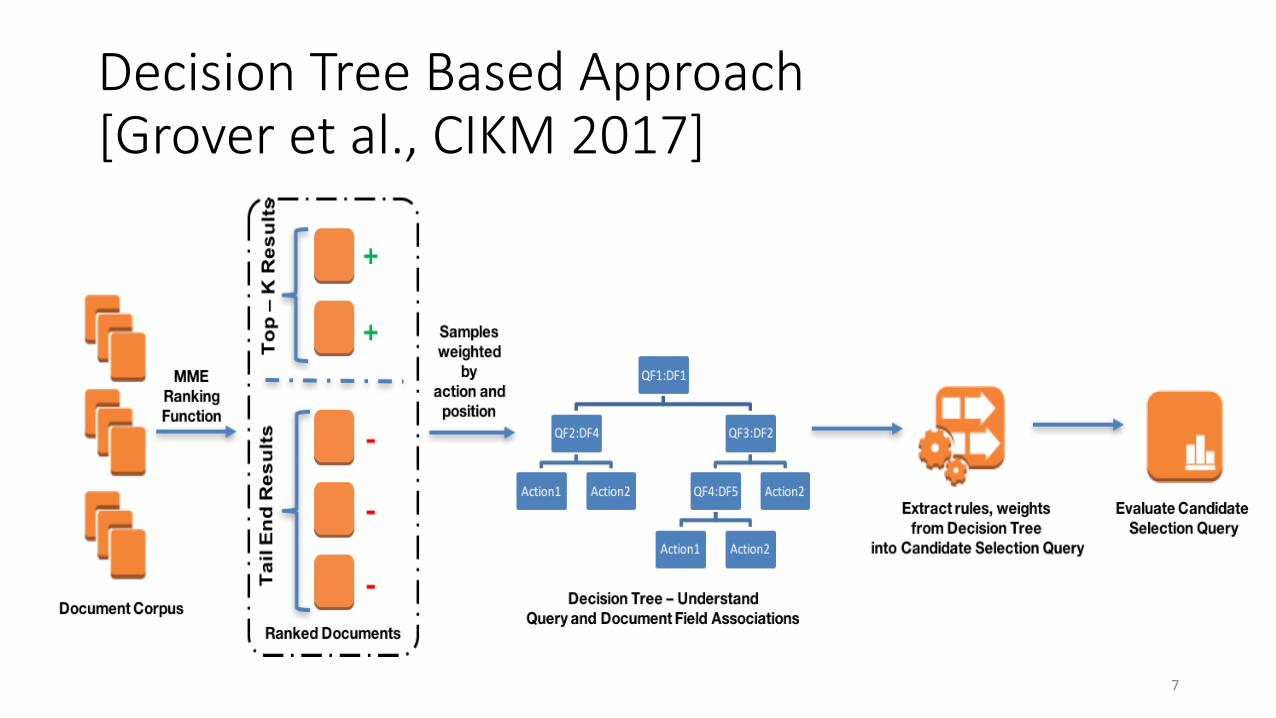
Decision Tree Based Approach [Grover et al., CIKM 2017]
7
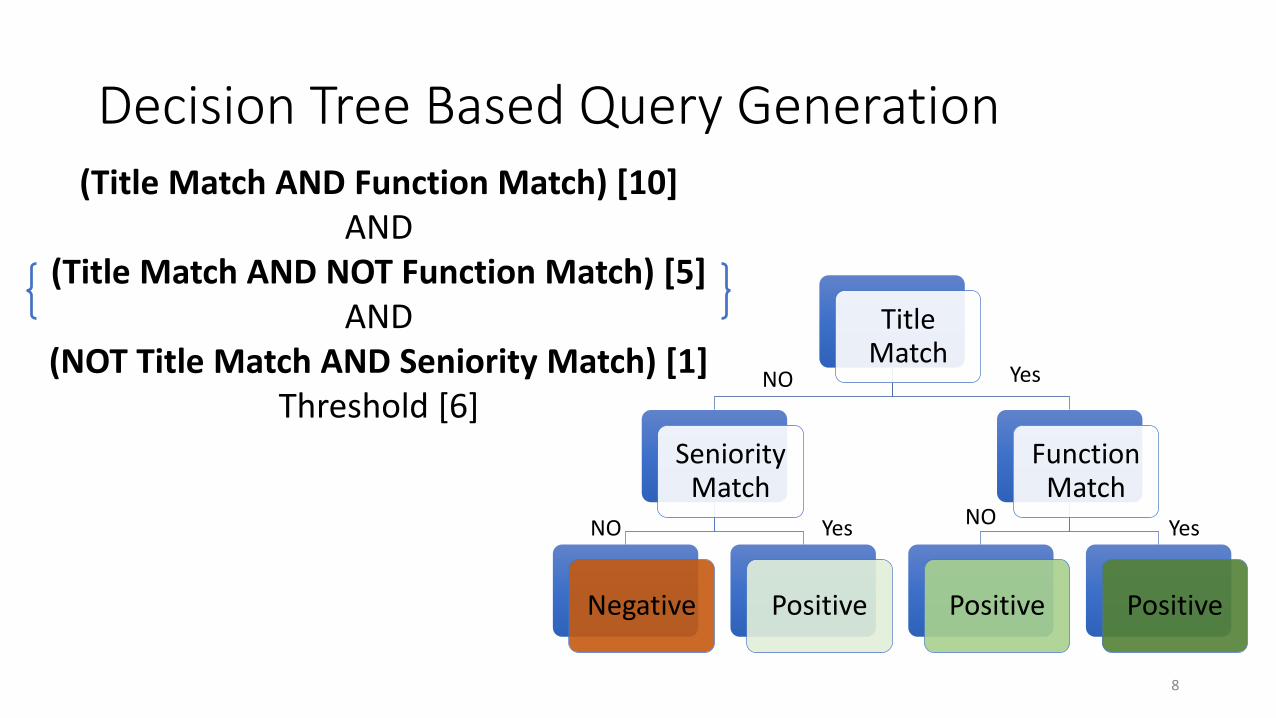
Decision Tree Based Query Generation
Title Match
Seniority Match
Negative Positive
Function Match
Positive Positive
NO Yes
YesYes NONO
8
(Title Match AND Function Match) [10] AND
(Title Match AND NOT Function Match) [5]AND
(NOT Title Match AND Seniority Match) [1]Threshold [6]
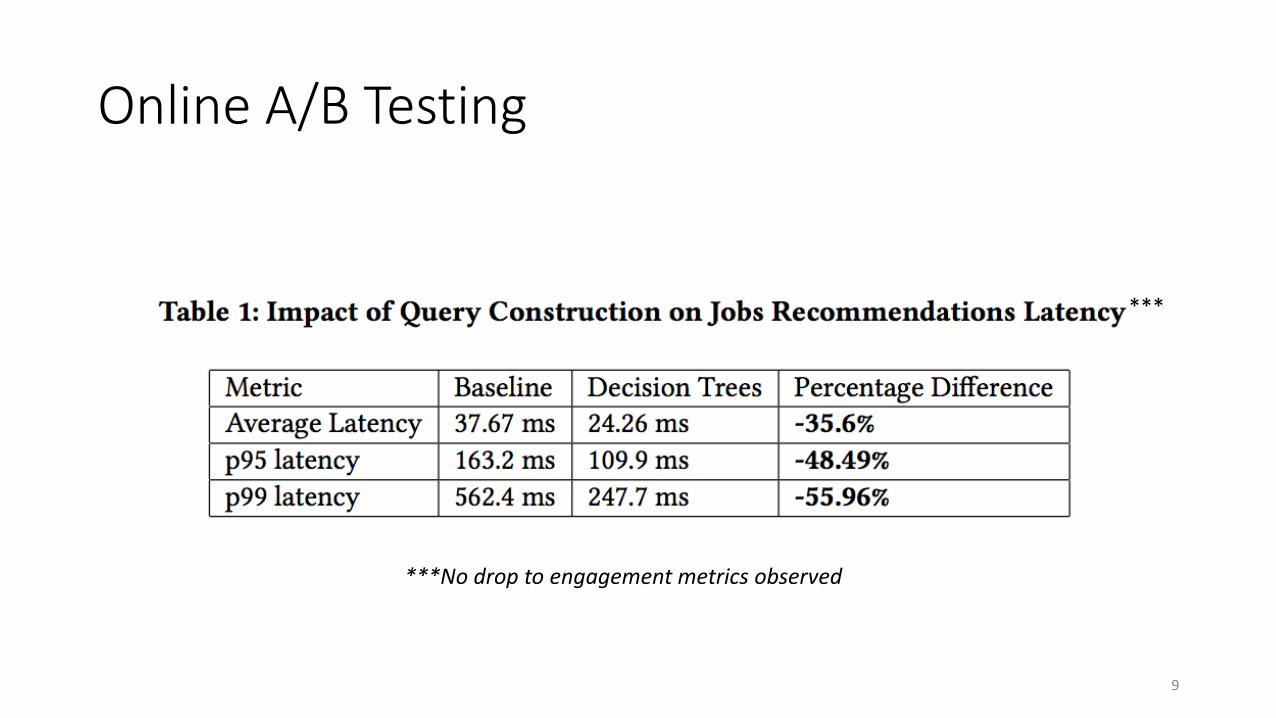
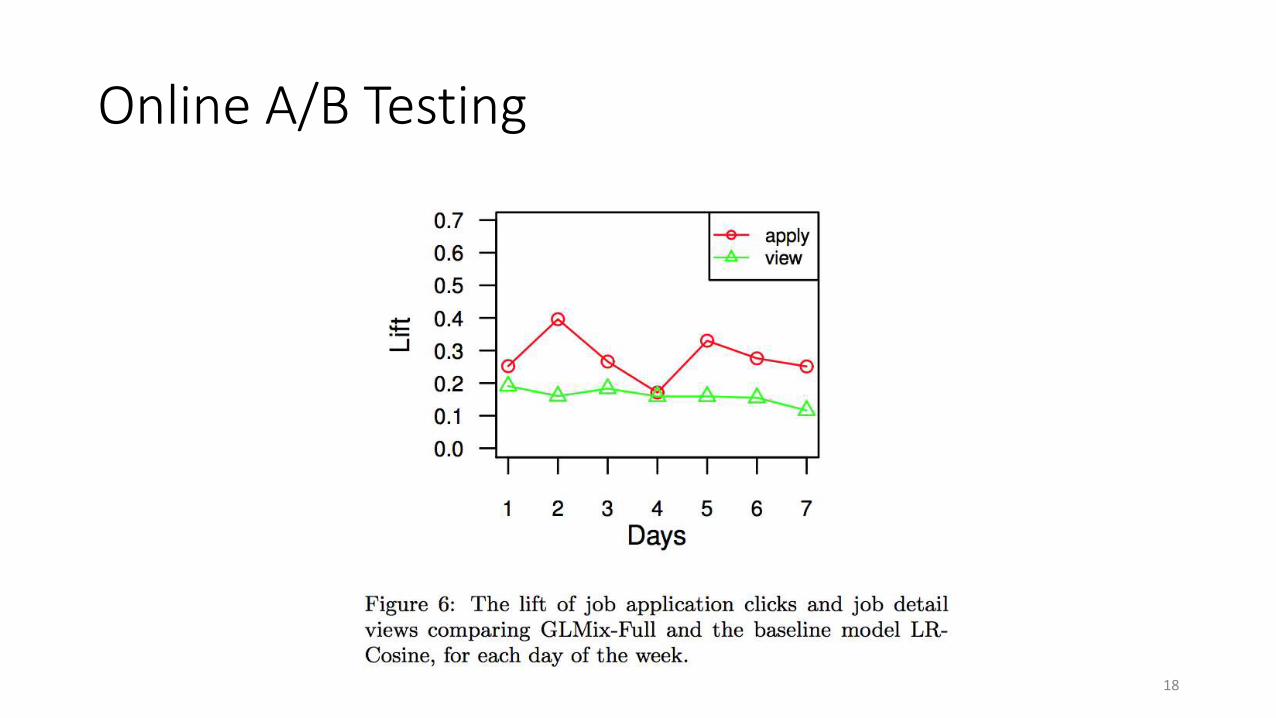
Online A/B Testing
9
***No drop to engagement metrics observed
***

Personalized Relevance
Models

Generalized Linear Mixed Models (GLMM)
• Mixture of linear models into an additive model• Fixed Effect – Population Average Model
• Random Effects – Entity Specific Models
Response Prediction (Logistic Regression)
User 1 Random Effect Model
User 2Random Effect Model
Personalization
Job 2Random Effect Model
Job 1Random Effect Model
Collaboration
Global Fixed Effect Model
Content-Based Similarity
11

Features
• Dense Vector Bag of Words Similarity Features in global model for Generalization• i.e: Similarity in title text good predictor of response
• Sparse Cross Features in global,user, and job model for Memorization• i.e: Memorize that computer science students will transition to entry engineering roles
Vector BoW Similarity FeatureSim(User Title BoW,Job Title BoW)
Global Model Cross FeatureAND(user = Comp Sci. Student,job = Software Engineer)
User Model Cross FeatureAND(user = User 2,job = Software Engineer)
Job Model Cross FeatureAND(user = Comp Sci. Student,job = Job 1)
12

Training a GLMM at Scale
• Millions of random effect models * thousands of features per model = Billions of parameters
• Infeasible to run traditional fitting methods on this very large linear model with industry scale datasets
• Key Idea: For each entity's random effect, only the labeled data associated with that entity is needed to fit its model
13

Parallel Block-wise Coordinate Descent [Zhang et al., KDD 2016]
14
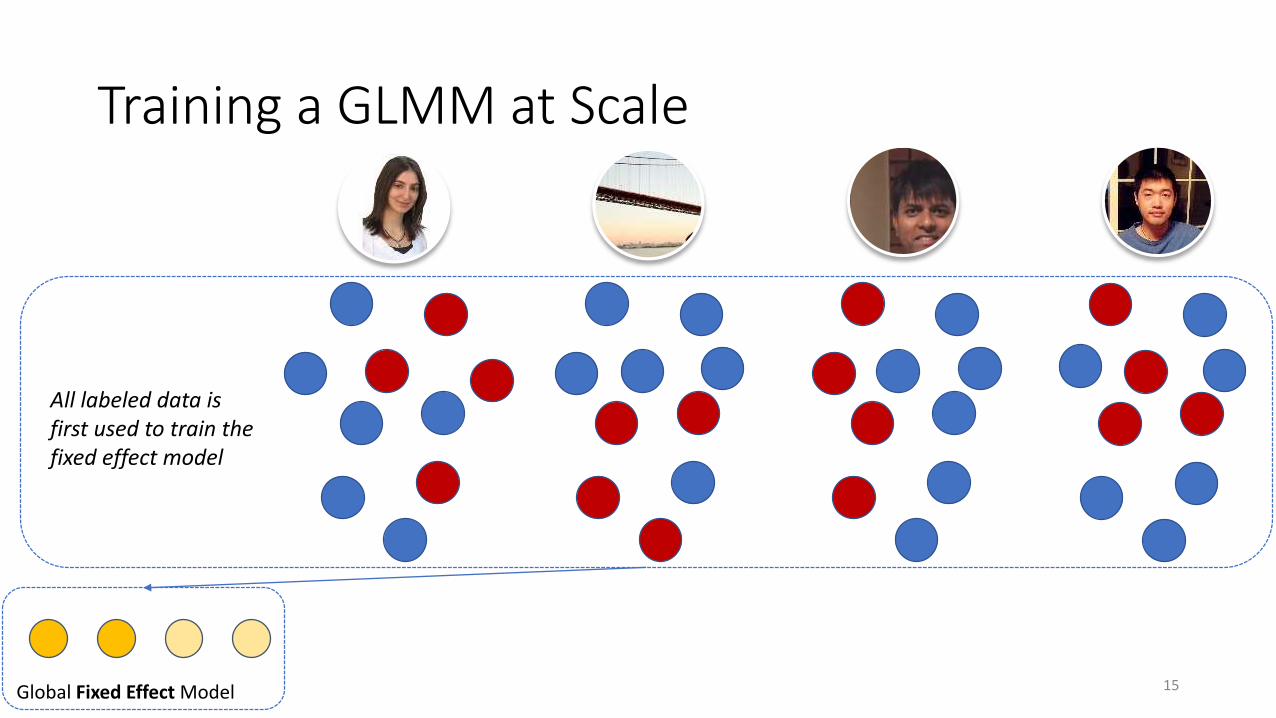
Training a GLMM at Scale
15Global Fixed Effect Model
All labeled data is first used to train the fixed effect model
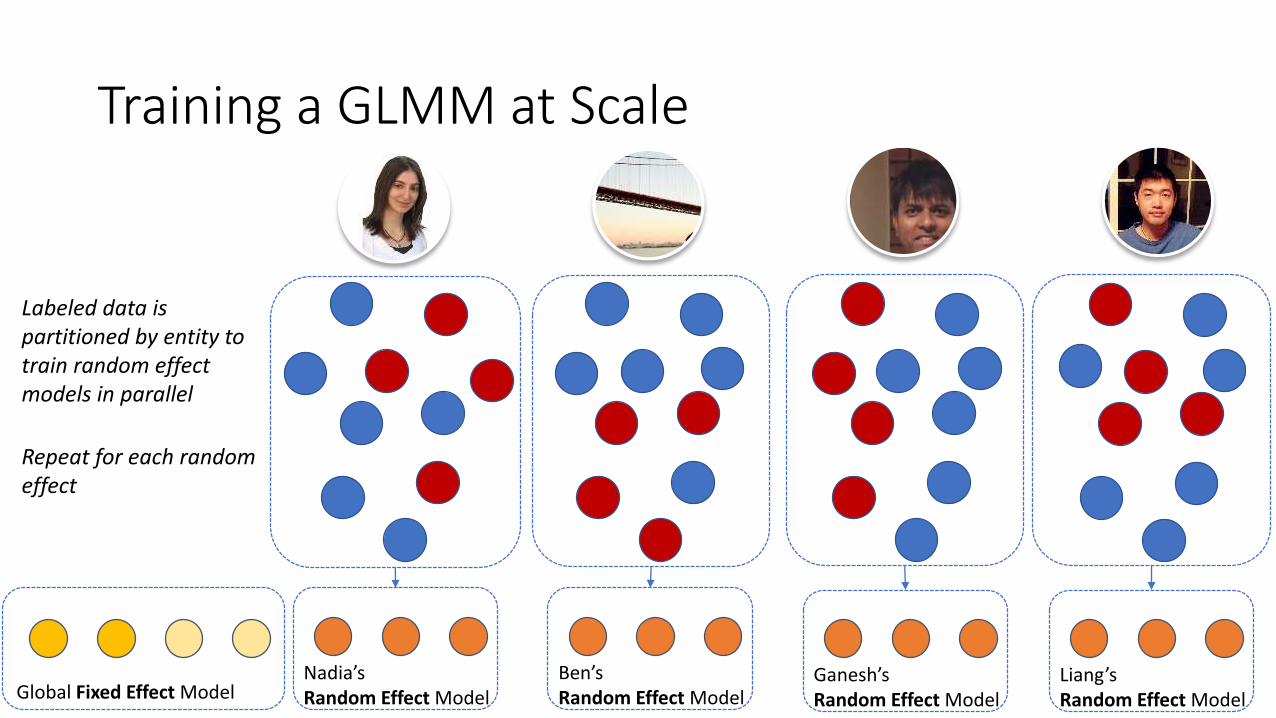
Training a GLMM at Scale
16Global Fixed Effect ModelNadia’sRandom Effect Model
Ben’sRandom Effect Model
Ganesh’sRandom Effect Model
Liang’s Random Effect Model
Labeled data is partitioned by entity to train random effect models in parallel
Repeat for each random effect
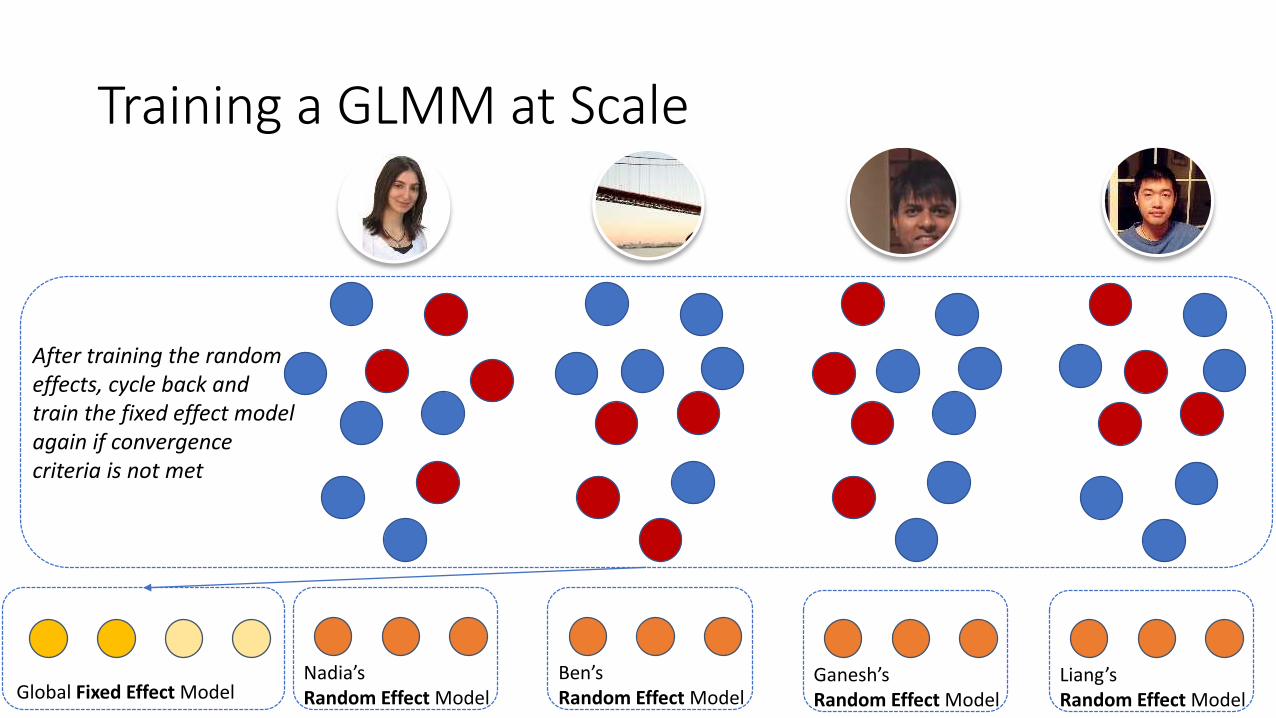
Training a GLMM at Scale
17Global Fixed Effect Model
After training the random effects, cycle back and train the fixed effect model again if convergence criteria is not met
Nadia’sRandom Effect Model
Ben’sRandom Effect Model
Ganesh’sRandom Effect Model
Liang’s Random Effect Model
Online A/B Testing
18

Jobs Marketplace

The Ideal Jobs Marketplace
• Maximize number of confirmed hires while minimizing number of job applications• This maximizes utility of job seeker and job posters
• Ranking by 𝑃 User 𝑢 applies to Job 𝑗 𝑢, 𝑗) only optimizes for user engagement
1. Recommend highly relevant jobs to users
2. Ensure each job posting • Receives sufficient number of applications from qualified candidates to
guarantee a hire• But not overwhelm the job poster with too many applications
20

The Ideal Jobs Marketplace
21

Potential Solution?
• Rank by likelihood that user will apply for the job and pass the interview and accept the job offer?• Data on whether a candidate passed an interview is confidential
• Data about the offer to the candidate is confidential too
• More importantly, modeling this requires careful understanding on potential bias and unfairness of a model due to societal bias in the data
• Practically, we solve the job application redistribution problem instead• Ensure a job does not receive too many or too few applications
22
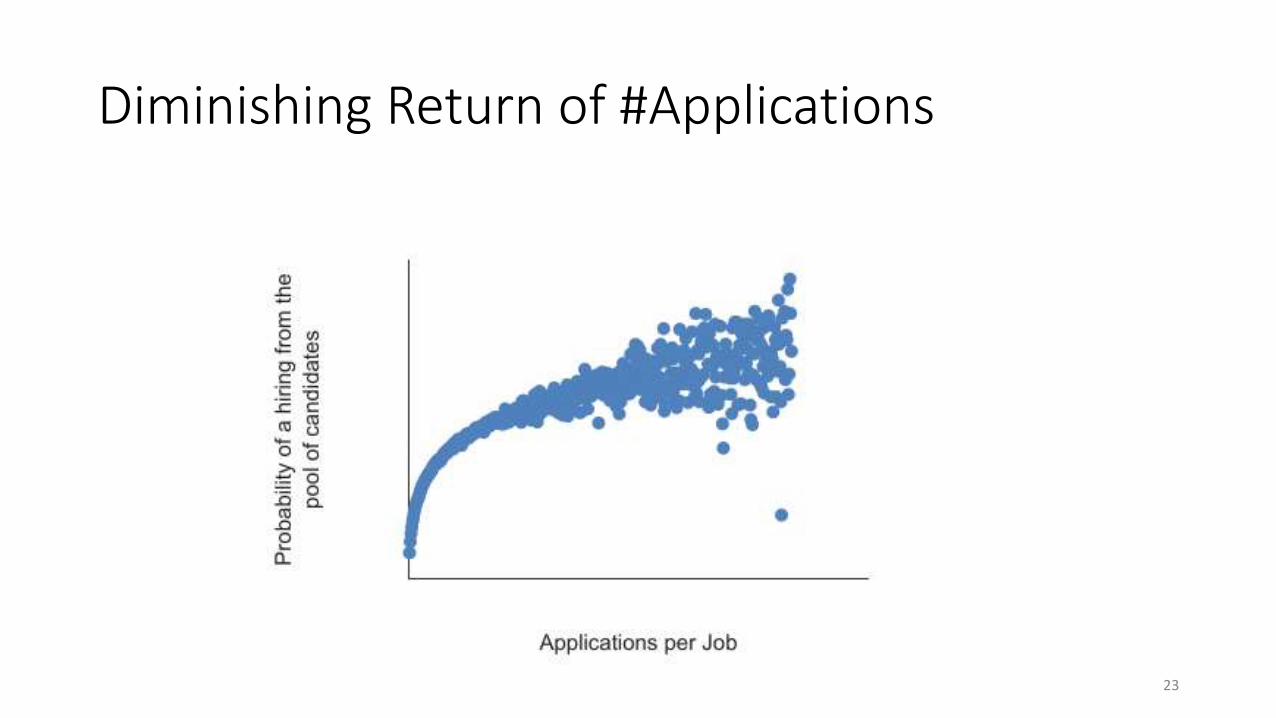
Diminishing Return of #Applications
23

Our High-level Idea: Early Intervention [Borisyuk et al., KDD 2017] • Say a job expires at time T
• At any time t < T• Predict #applications it would receive at time T
• Given data received from time 0 to t• If too few => Boost ranking score 𝑃 User 𝑢 applies to Job 𝑗 𝑢, 𝑗)• If too many => Penalize ranking score 𝑃 User 𝑢 applies to Job 𝑗 𝑢, 𝑗)• Otherwise => No intervention
• Key: Forecasting model of #applications per Job, using signals from:• # Applies / Impressions the job has received so far• Other features (xjt): e.g.
• Seasonality (time of day, day of week)• Job attributes: title, company, industry, qualifications, …
24

• Control Model for Ranking : Optimize for user engagement only
• Split the jobs into 3 buckets every day:• Bucket 1: Received <8 applications up to now
• Bucket 2: Received [8, 100] applications up to now
• Bucket 3: Received >100 applications up to now
Re-distribute
Online A/B Testing
25

Summary
• Model candidate selection query generation using decision trees
• Personalization at Scale through GLMM
• Realizing the ideal jobs marketplace through application redistribution• But a lot of research work still needed to
• Reformulate problem to model optimizing for a healthy marketplace directly
• Understand and quantify bias and fairness in those potential new models
26

References
• [Borisyuk et al., 2016] CaSMoS: A framework for learning candidate selection models over structured queries and documents, KDD 2016
• [Borisyuk et al., 2017] LiJAR: A System for Job Application Redistribution towards Efficient Career Marketplace, KDD 2017
• [Grover et al., 2017] Latency reduction via decision tree based query construction, CIKM 2017
• [Zhang et al., 2016] GLMix: Generalized Linear Mixed Models For Large-Scale Response Prediction, KDD 2016
27


Appendix
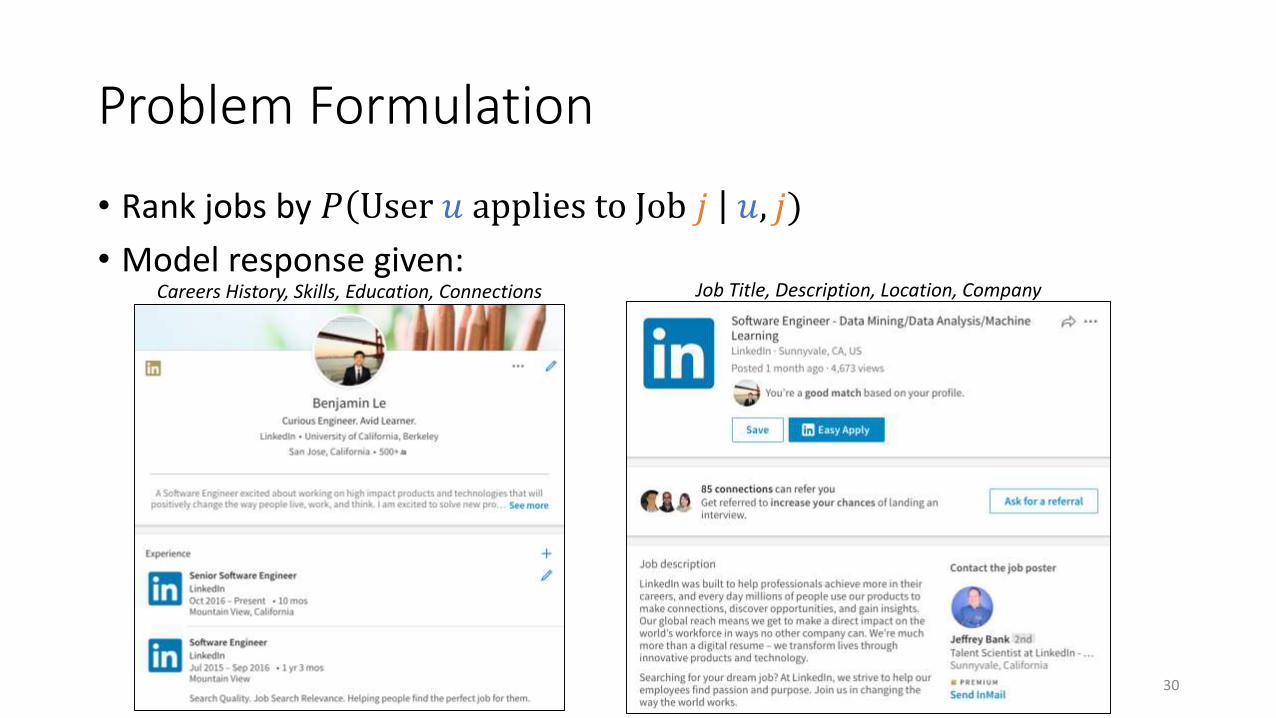
Problem Formulation
• Rank jobs by 𝑃 User 𝑢 applies to Job 𝑗 𝑢, 𝑗)
• Model response given:
30
Careers History, Skills, Education, Connections Job Title, Description, Location, Company
30
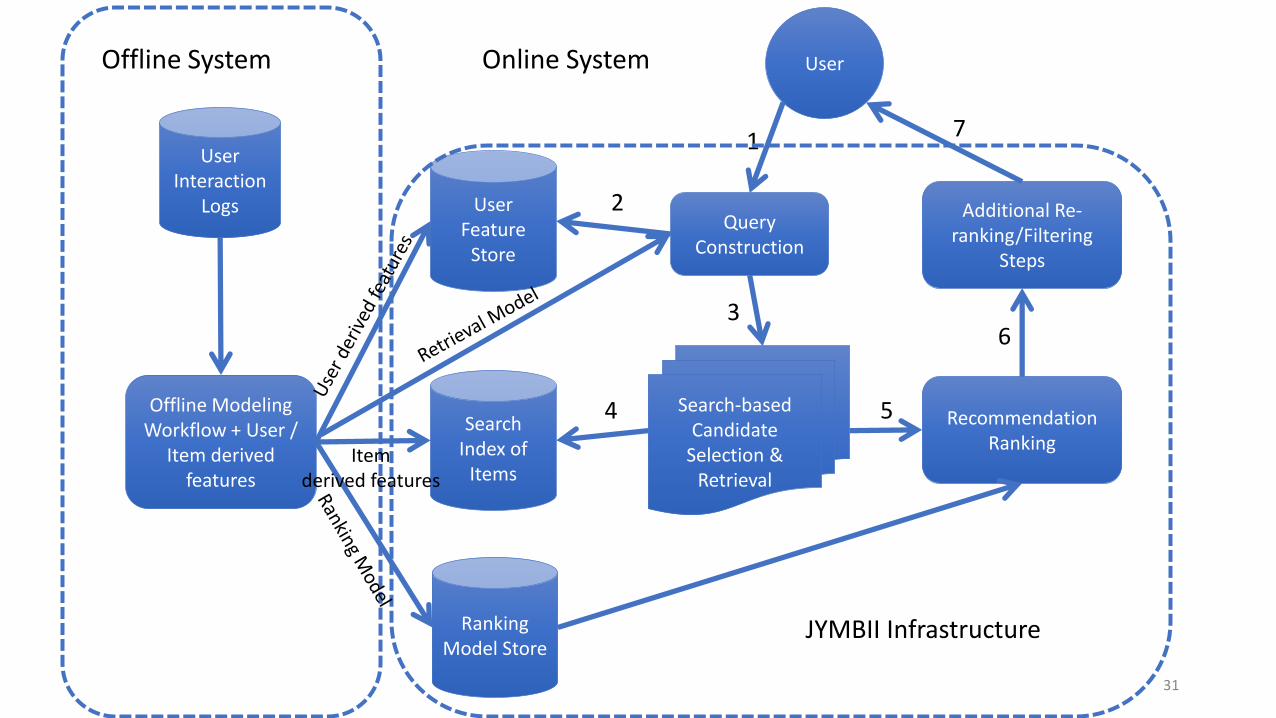
User Interaction
Logs
Offline Modeling Workflow + User /
Item derived features
User
Search-based Candidate
Selection & Retrieval
Query Construction
User Feature
Store
Search Index of
Items
Recommendation Ranking
Ranking Model Store
Additional Re-ranking/Filtering
Steps
1
2
3
4 5
6
7
Offline System Online System
Itemderived features
JYMBII Infrastructure
31

Understanding WAND QueryQuery : “Quality Assurance Engineer”
AND Query: “Quality AND Assurance AND Engineer”
✅ ❌32

Understanding WAND QueryQuery : “Quality Assurance Engineer”
WAND : “(Quality[5] AND Assurance[5] AND Engineer[1]) [10]”
✅ ✅33
Offline Evaluation
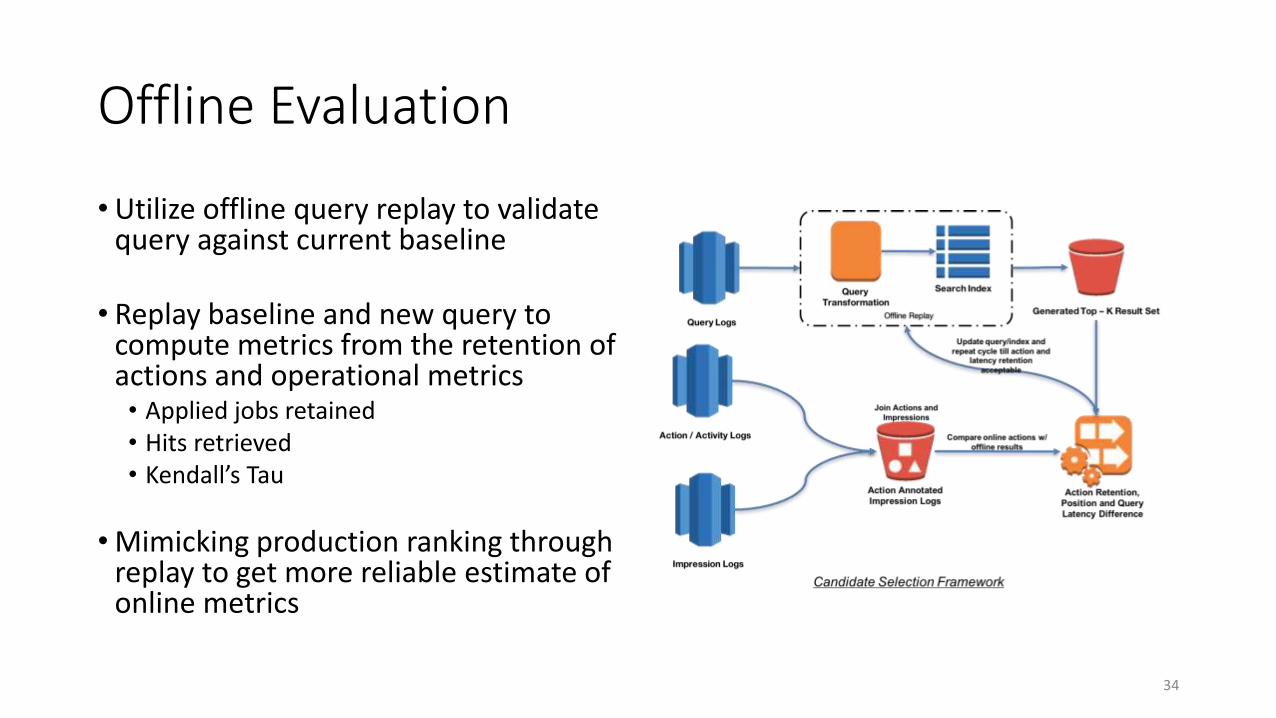
• Utilize offline query replay to validate query against current baseline
• Replay baseline and new query to compute metrics from the retention of actions and operational metrics• Applied jobs retained• Hits retrieved• Kendall’s Tau
• Mimicking production ranking through replay to get more reliable estimate of online metrics
34