peer recommendation using negative relevance feedback
TRANSCRIPT

Peer recommendation using negative relevance feedback
DEEPIKA SHUKLA* and C RAVINDRANATH CHOWDARY
Department of Computer Science and Engineering, Indian Institute of Technology (BHU) Varanasi,
Varanasi 221005, India
e-mail: [email protected]; [email protected]
MS received 26 May 2021; revised 30 August 2021; accepted 5 October 2021
Abstract. It is a challenging task to recommend a peer to a user based on the user’s requirement. Users may
have expertise in multiple sub-domains, due to which peer recommendation is a nontrivial task. In this paper, we
model peers as nodes in a graph and perform a community search. Weighted attributes are associated with every
node in the graph. We propose two novel methods to compute the weights of the attributes. Relevance feedback
is a popular technique used to improve the performance of retrieval systems. We propose to use negative
relevance feedback in an attributed graph for peer recommendation. We use CL-tree for indexing the nodes in
the graph. We compare the proposed system with the state-of-the-art on standard datasets, and our system
outperforms the rival system.
Keywords. Peer recommendation; negative relevance feedback; relevance feedback; nnowledge graph; co-
authorship network.
1. Introduction
Recommendation systems are information filtering systems
over dynamically generated large volumes of data that
prioritize and personalize the contents. In recent years,
many researchers are showing interest in recognizing and
characterizing the properties of large-scale graphs [1–6].
These graph-based techniques are used to improve the
performance of the recommender systems [7–11]. Peer
recommendation is a kind of community search [12, 13]
problem. The community search in graph science gives the
most fitting community containing the query node. By
giving attributed query, it provides the most likely com-
munity that is matching the query needs. In our context,
peer recommendation recommends the most suitable peers
for an attributed query.
We used a collaboration graph as a knowledge graph to
depict all the authors and their collaborations as nodes and
edges, respectively. Here, the collaboration graph is some
social graph modeling, where a node represents a user, and
an edge represents a relationship between two nodes. In
figure 1 collaboration graph is created from a coauthor-
publication bipartite graph. For example, authors P and Q
work together for publication A, so in the co-author
network,1 they will be connected, and their attributes are
taken from publication A.
Due to the data’s unexpressed nature, the quality of
results is unpredictable. Generally, we do not know the
output of the model a priori [14]. In peer recommendation
for an attributed query, the model should recommend both
the direct neighbors of the query node for matching attri-
butes/keywords and those peers with similar interests but
have not collaborated earlier. The majority of peer rec-
ommendation model focuses on nodes that are only
reachable through structural cohesiveness [15]. Relevance
feedback is a popular technique in retrieval systems to
improve performance. We propose to introduce relevance
feedback in the recommender system. The majority of the
feedback techniques depend on positive or relevant
answers. Negative relevance feedback is a particular case of
relevance feedback [16]. Here no positive answers are
available or provided documents, and answers are assumed
to be irrelevant. We use the negative relevance feedback
method, which helps to find peers that are not direct
neighbors to the query node.
The proposed peer recommendation system is person-
alized and recommends peers whose interests and exper-
tise match the attributes of the query. In this paper, we
create an attributed graph and generate an index tree for
the graph, which helps in finding the nodes having similar
interests as the query node. We propose two features to
compute the weight of nodes. These features help in
finding the most appropriate peers for the query node. The
proposed model provides flexibility in terms of choosing
the number of attributes in the query, which impacts the
quality of the recommendation. If the recommended list
*For correspondence 1A kind of collaboration graph.
Sådhanå (2021) 46:243 � Indian Academy of Sciences
https://doi.org/10.1007/s12046-021-01763-5Sadhana(0123456789().,-volV)FT3](0123456789().,-volV)

does not fulfill the predefined criteria, then negative rel-
evance feedback is used to enhance the recommended list
further.
1.1 Motivation
In an attribute-based community search model, the
choice of keywords impacts the retrieved results. If
input keywords are not appropriate, a model is likely to
retrieve irrelevant results. Thus instead of manually
verifying each recommended peer, the relevance feed-
back technique can get adequate results by refining
attributes when needed. To the best of our knowledge,
none of the existing community search literature used
the negative relevance feedback technique over large
dynamic attributed graphs [15] to improve the quality of
the retrieval system. When multiple communities for a
single attributed query are retrieved, it is very tough to
decide which would be a preferable choice. We propose
two features/heuristics to rank and choose an appropriate
community.
1.2 Contributions
• We propose two heuristics to compute the level of
expertise of the peers in the given subdomain.
• We use the negative relevance feedback technique for
community search in a dynamic collaboration graph.
This model refines the initially retrieved result in order
to get better results.
2. Related work
This section concisely reviews some peer recommender
systems and negative relevance feedback based systems.
2.1 Peer recommendation
‘‘It is often necessary to make choices without sufficient
personal experience of the alternatives’’ [17]. A rich part of
the literature on recommender systems is focused on
commercial applications and is categorized into: e-group
activities, e-government, e-commerce/e-shopping, e-li-
brary, e-learning, e-tourism, e-resource services, and
e-business [18]. The recommender systems are broadly
classified into two categories: content-based and collabo-
rative-based recommender systems. A content-based rec-
ommender system works based on the user-provided data,
either implicitly or explicitly [19]. Collaborative methods
recommend items based on the user’s past behavior [20],
where interaction records between users and items are
provided.
Of late, the increase in social activities has increased the
use of the group recommender systems (GRS). ‘‘A group
recommender system is a system that recommends items to
a group of users collectively, given their preferences’’
[21, 22]. Based on the interactions among the group
members, groups can be classified into three categories:
established group [23], random group [24] and occasional
group [25]. The various application domains of GRS
include movie [26], music [27], travel [28], TV programs
[29] etc.
Our major focus is on peer recommendation. Each
domain has different challenges, and the recommender
systems take domain-specific issues into cognizance while
generating the recommendations. This specific kind of
recommender system [30], instead of recommending items
of interest (e-commerce [31]) or friend of a circle (social
platform [32]) to follow, recommends possible collabora-
tion in a specific field of interest based on user’s interest/
requirement.
The authors in [33] spotted a lack of social relationship
(a significant factor of attrition) in Massive Open Online
Courses (MOOCs). They embedded peer recommendations
Figure 1. Attributed co-authorship graph creation from a publication-coauthor bipartite graph.
243 Page 2 of 18 Sådhanå (2021) 46:243

to enhance interaction between students that improve the
quality of learning. They used three different approaches.
These are: random recommendation, socio-demographic
features based, and progress rate in MOOC-based recom-
mendations. The authors analyzed that the recommendation
strategy using socio-demographic information is slightly
more efficient than the random one, whereas the random
recommendation is more efficient than the performance-
based recommendation. They did not consider the dyna-
mism and evolution in students’ requirements. They find
peers based on a similarity measure between learner’s
descriptions that influenced trustworthy relationships and
negatively impacted selecting appropriate members. The
authors in [34] proposed a framework for an online learning
environment aimed to recommend learning peers by using
tripartite graph and CNN.
2.2 Relevance feedback
The feedback mechanism plays a major role in the
quality of retrieved results in text retrieval applications.
Feedback is also used in a content-based image
retrieval system. The relevance feedback method is a
very useful strategy to enhance search accuracy through
feedback. Relevance feedback [35] is basically divided
into three categories i.e. implicit feedback [36], explicit
feedback [37] and blind or pseudo relevance feedback
[38, 39]. Explicit feedback uses either binary (relevant
or irrelevant) or ranking/ratings given on some fixed
scale by the user. Whereas implicit feedback is based
on implicitly captured user’s behavior for retrieved
results. The pseudo relevance automates the feedback
system by considering top k results as relevant and then
expanding query terms accordingly [40]. The negative
relevance feedback method is a special case that is
used when no retrieved results are relevant. Many
researchers explored and used this method in their
respective applications [41–43]. In general, this feed-
back system till now covered various streams, includ-
ing information retrieval [44, 45] and image retrieval
system [46, 47].
[16] discussed general strategies for negative rele-
vance feedback techniques that include query modifica-
tion and score combination strategies. They covered the
language model and vector-space model along with
several heuristics for these methods in negative feedback.
Too much negative feedback may demolish the quality
features of a query. Authors [48] noticed this issue and
then proposed a few strategies used in negative relevance
feedback.
We hypothesize that using negative relevance feedback
may yield good results, and through our experiments, we
show that our model outperforms the rival system.
Table1.
Exam
pleofattribute
weightcomparisionmatrixforauthor‘D
anielGorgen’withattributesset[‘distribute’,‘script’,‘m
obile’,‘application’,‘m
ulti-hop’,‘ad-hoc’,‘network’,
‘generic’,‘background’,‘dissemination’,‘service’,‘geographical’,‘cluster-based’,‘rout’,‘sensing-covered’,‘planar’,‘graph’,‘cluster’,‘inform
ation’,‘m
anagem
ent’,‘m
-learning’,
‘environment’].
Rival_system
Proposed_system
No.
Attributes
Weight
Attributes
Weight
1‘application’,‘network’,‘service’,‘rout’,‘cluster’
16.6196
‘distribute’,‘m
obile’,‘application’,‘service’,‘cluster’
11.6949
2‘distribute’,‘application’,‘network’,‘service’,‘inform
ation’,‘m
anagem
ent’
16.5959
‘distribute’,‘m
obile’,‘network’,‘m
anagem
ent’,‘environment’
39.7761
3‘distribute’,‘m
obile’,‘m
anagem
ent’,‘environment’
27.8614
‘distribute’,‘application’,‘network’,‘service’,‘cluster’
22.1318
4‘m
obile’,‘application’,‘service’,‘rout’,‘cluster’,‘inform
ation’,‘m
anagem
ent’,
‘environment’
2.0559
‘distribute’,‘network’,‘service’,‘rout’,‘inform
ation’
34.1372
Sådhanå (2021) 46:243 Page 3 of 18 243

Table 2. Weight matrix for author ‘Tzu-Kuo Huang’ and keywords [‘generalize’, ‘bradley-terry’, ‘model’, ‘multi-class’, ‘probability’,
‘estimate’].
No. Keyword_set Weight
1 (‘generalize’, ‘multi-class’) 71.4018
2 (‘generalize’, ‘bradley-terry’) 11.8642
3 (‘model’, ‘bradley-terry’) 23.6456
4 (‘multi-class’, ‘probability’) 39.3202
5 (‘multi-class’, ‘estimate’) 50.3420
6 (‘generalize’, ‘model’, ‘multi-class’) 41.0339
7 (‘generalize’, ‘multi-class’, ‘probability’) 13.9467
8 (‘generalize’, ‘multi-class’, ‘estimate’) 13.3776
9 (‘model’, ‘multi-class’, ‘estimate’) 32.1653
10 (‘multi-class’, ‘probability’, ‘estimate’) 13.9442
(a) (b)
Figure 2. Graphs for author ‘Nik Nailah Binti Abdullah’ using negative relevance feedback.
(a) (b)
Figure 3. Graphs for author ‘Xuexiang Huang’ using negative relevance feedback.
243 Page 4 of 18 Sådhanå (2021) 46:243

3. Peer recommendation in dynamic attributedgraphs
In this paper, we model peer recommendation as an
attributed community query (ACQ) [49] problem. Let
G(V, E, X) be an undirected attributed graph along with a
set of edges E and set of vertices V. Here, every node v 2 Vis associated with a set of attributes Xv. For a given
attributed undirected graph G(V, E, X) and a query node
q 2 V with attributes set A, ACQ returns an attributed
community (AC) Gq containing q and Gq � GðV;E;XÞsuch that Gq satisfy structural cohesiveness (i.e., maximal
connectivity among the nodes in Gq) and keyword cohe-
siveness (i.e., all the nodes with x number of keywords in
common).
The graph created in this paper is an attributed co-
authorship graph: a type of collaboration graph of published
articles where attributed nodes are authors/peers that store
information related to their area of interest and expertise,
and a link between two nodes indicate collaboration for an
article. Here the attribute values are dynamic, i.e., when-
ever there is a new link between two nodes, the corre-
sponding attributes’ values get updated. Further, these
attributes and their weights are used to rank the retrieved
communities. The computation of weight is given in
algorithm 1.
3.1 Attributed co-authorship graph creation
Entities in real-life networks have various attributes, and
each attribute has its significance in the relative domain.
Among all attributes of a node, we use some to calculate
the nodes’ interests and expertise. Algorithm 1 describes
the creation of a dynamic attributed co-authorship graph.
Attributes of the nodes in the graph are taken from all the
titles of the author’s publications. Every new publication
can update the list of authors and the associated attributes.
All the authors of a publication pi are represented as a set
Api where Api is list of authors fa1; a2; a3::ang. For everyauthor aj 2 Api , her starting year of publishing ðfyjÞ, totalnumber of publications ðpcjÞ and associated keywords’
attributes (step 2) are computed. If aj 62 G then we add aj to
G and compute its associated attributes’ values. fyj and pcjstores the year of publication ðyrÞ of pi and 1 respectively
ðsteps5� 9Þ. If aj 2 G then for pi, its pcj increments by one
(step 11).
Fa denotes all the keywords of author aj. All the key-
words taken from the title of pi are represented as fpi where
fpi is fk1; k2; k3::kng. If kl 2 fpi and kl 62 Fa then we add kl in
Fa ðsteps13� 15Þ. First-publishing-time ðikyaÞ and latest-
publishing-time ðlkyaÞ of author aj for keyword kl stores yr.
Here, ikya is the initial year when the author started pub-
lishing in a particular keyword kl and lkya is the latest year
when the author published in that keyword. Keyword-fre-
quency ðKkfaÞ of kl is the total number of publications in kl
and initially is set to one ðsteps16� 19Þ. If kl 2 Fa, Kkfa
increases by one and lkya updates by yr ðsteps18� 19Þ .
There are edges between all pairs of vertices of Api in G.
3.2 CL-tree creation
As based on the index, the efficiency of answering ACQ is
improved significantly [48], we create CL-tree for G [49]. It
is an indexed tree-like structure based on the nested k-core2
property where each node contains five attributes. These are
vertex_set (number of vertices of similar nature of con-
nectivity forming that node), parent_node, child_list,
core_number (minimum k-connectivity among all vertices
of that node), and inverted list (features:interested_vertices
pair dictionary). We use an advanced method that follows
the bottom-up approach and is more efficient than the top-
down approach (basic method) regarding real networks for
static CL-tree creation. Initially, we calculate the cores of
all vertices of G, then the recursive creation of nodes of cl-
tree goes from kmax to kmin. Here kmin is zero. All the ver-
tices of ki (kmin � ki � kmax) are considered to find the
number of components formed by these set of vertices.
Each node of the CL-tree denotes a single component of a
particular core number. To address the changes in CL-tree,
we use the incremental learning approach [15] that ensures
2The k � core of a graph is defined as the subgraph in which the
minimum degree of any vertex is k.
Sådhanå (2021) 46:243 Page 5 of 18 243

adding nodes and edges in CLtree at runtime environment.
Detailed explanation of CL-tree creation is given in [48].
3.3 Peer recommendation
We query the model in the form of (q, k, A). Here q is the
query node, k is the core number, and A is the set of
attributes. We search q in the CL-tree, and the core number
of this node should be greater than or equal to k. k in the
query indicates the process of community search, involves
only nodes3 having at least k-core. We use the decremental
algorithm discussed in [12] for community search. The
decremental algorithm uses attributes of a for searching
communities. After applying a community search, we may
get multiple communities, and these communities may have
single or multiple peers for a subset of attributes.
3.4 Weighted community
The retrieved communities include peers with homoge-
neous attributes. A node of the graph can have multiple
interests, leading her into multiple communities with dif-
ferent keywords. We address two issues with the help of
weighing the community:
1. For an attributed query, the model may give multiple
communities for a subset of query attributes.
2. If there are multiple collaborators for a single publica-
tion, the result can fulfill the maximum keyword
cohesiveness and structural cohesiveness even in the
case of very few publications of the involved peers in the
received community.
So, to select the best community, we have proposed two
heuristics to weigh communities. We further use these
weights to rank and choose the best community.
(a) (b)
Figure 4. Graphs for author ‘Yaun-Zhi Song’ for results validation.
(b)(a)
Figure 5. Graphs for author ‘Yousuke Hagiwara’ for results validation.
3CL-tree nodes.
243 Page 6 of 18 Sådhanå (2021) 46:243

1. Importance(I): Importance Ika of a node a in a subdo-
main k is computed as given in equation 1. Any node’s
importance is measured by the percentage of the total
number of publications in a particular area to the total
publication duration in that area. Here duration is the
period of continuation in a particular area. Equation 1 is
used to calculate the Ika , where Kkf a
denotes the total
number of publications by a in a particular field4 k.Duration of that publication is given by the difference to
the first time she published an article ðfkeyaÞ in a
subdomain to the time she published her latest publica-
tion ðlkkeyaÞ in the same subdomain.
If there are d co-authors with respect to publication pi, allthese d co-authors will have at least d � 1 co-authors in
G. If one of the d co-authors is publishing for the first
time, even then, her connectivity will be d � 1, so, Itakes care of this issue.
Ika ¼ Kkf a=durationpub; durationpub ¼ ðlkya � f kya þ 1Þ
ð1Þ2. Attention(T): The attention Tk
a of an author with respect
to the particular field is computed as given in equation 2,
i.e., the ratio of the publication count Kkf a
regarding a
particular area to the total number of author’s publica-
tions ðEpubaÞ till date.
Tka ¼ Kk
f a=Epuba ð2Þ
Wak ¼Xn
i¼1
ða:Rkaiþ b:Pk
aiþ c:Tk
aiþ h:IkaiÞ ð3Þ
Both the features help to identify the potential of the
nodes. If the number of authors in a qualified community
are n then the weights of each keyword for every node of
that community is calculated by equation 3 where the
values of a, b, c, and h are fixed empirically. All the
values lie between 0 and 1. Here relevance ðRkaÞ and
proximity ðPkaÞ [15] give activeness in a particular
research area and nearness of publication in that area,
respectively. The collective sum of a, b, c and h is 1.
SðKjÞ ¼Xm
k¼1
Wak=m ð4Þ
The weight of the community is later measured by the
cumulative weight of every member of the community.
For every community, equation 4 gives the normalized
score assigned to each keyword set. The score is calcu-
lated as the ratio of the cumulative sum of weight
assigned to every keyword in the keyword set to the total
number of keywords in that set (Table 1). Here, Kj refers
to the j th keyword set, and Wak refers to the weight of
author for k th keyword. Keyword cohesiveness is sat-
isfied by every community.
3.5 Relevance feedback
We use equation 5 to check the relevance of the received
community. It uses the neighborhood property. If all the
received nodes are direct neighbors of the query node, they
already worked with it. We use the negative relevance
feedback technique to explore new nodes having a similar
interest as the query node. If the score of community
S(q, C) for community C is greater than or equal to one,
some nodes are in the community that has never worked
before with the query node. Otherwise, query keywords
need refinement [16], and we penalize all the members of
Figure 6. Process diagram for peer recommendation.
4Here, the field is a keyword and each keyword is considered to
calculate Ika . Attribute, keyword, and field are interchangeably used.
Sådhanå (2021) 46:243 Page 7 of 18 243

the initially retrieved community for getting a better
response. In equation 5, NG½q� represents direct neighboursof node q in G and Cpeer denotes peers in the community C.
Sðq;CÞ ¼ jfv : v 2 Cpeer; v 62 NG½q�gj ð5ÞAs shown in figure 6, the process flow diagram gives a
complete flow of peer recommendation.
• Step 1: Attributed query is applied in the attributed
graph to get an efficient community.
• Step 2: The initially retrieved community is evaluated
for its keywords length5 and community length.6
• Step 3: If any of the above evaluations fail, then go for
a new query model by replacing irrelevant keywords
(a)
(b)
Figure 7. Sample recommendation graphs by the proposed system.
5The number of common keywords should be greater than one.6The number of nodes in the retrieved community must be greater
than or equal to two.
243 Page 8 of 18 Sådhanå (2021) 46:243

with the most appropriate keywords from the corpus
using the word2vec7 model.8
• Step 4: If the community satisfies the taken standards
for community strength, then we check the commu-
nity’s relevance.
• Step 5: If a community does not contain any new node
for the user, use negative relevance feedback that
penalizes all the community members. Replace the
keywords as described in step 3.
• Step 6: Again, we do a community search with a new
query model and go for step 2. Suppose the retrieved
community passes all three parameters. In this case,
that will be the final result, and the community with
the highest weight will be recommended.
Steps 1 to 6 are repeated at most five times.
4. Experimental setup and results
We perform experiments using dblp9 dataset. Each attri-
bute is associated with two timestamps. They are a year in
which the author published for the first time, and the
second is the most recent year the author published in the
particular field. Another attribute for the keyword is the
number of publications in that field (the field is identified
using the keyword. we assume that each keyword is a
separate field). The time attribute of a node is taken from
the year of publication. The words present in the title of
the publication are taken as attributes of interest. We filter
out the title by removing stop words10 and acronyms,11
then take more generalized words by stemming12 each
word. We take two dblp dataset samples where set1 is for
the years 2004–2008 and set2 for the years 2009–2013.
Every created graph has around 2M vertexes and 8M edges
in it. All the experiments are done on a CPU node of the
ParamShivay supercomputer, having an IntelXeonSKLG�6148 processor and 192GB of memory with a Linux
operating system. All the algorithms are implemented in
python. The retrieved results for set1 and set2 are repre-
sented as retrieved and relevant results, respectively.
4.1 Effectiveness evaluation
4.1.1 Effect of attribute weightIn this model, the importance given to the features is
determined a, b, c, and h. We empirically fixed the values
of a as 0.15, b as 0.15, c as 0.35, and h as 0.35. The
Table
3.
Exam
plesfornegativerelevance
feedback.
No.
Query_node
Initial_Keywords
Initial_Retrieved_community
Figure
2a
Nik
NailahBintiAbdullah
‘analysis’,‘synthesis’,‘learn’,‘agent’,‘communicative’,‘behavior’
‘StefanoA.Cerri’,‘N
ikNailahBintiAbdullah’
Figure
3a
XuexiangHuang’
‘special’,‘issue’,‘2006’,‘npa’
‘G.Y.Chen’,‘X
inmin
Yang’,‘X
uexiangHuang’
No.
New
_keyworks
Final_retrived_results
Figure
2b‘im
prove’,‘umts’,‘decision’,‘resource’,‘verification’,
‘m.s’
‘RolandoA.Carrasco’,‘Sam
uel
Pierre’,‘A
lejandro
Quintero’
Figure
3b‘introduction’,‘press’,‘8-cycle’
‘Jorg
Rothe’,‘A
ndrew
Whitworth’,‘K
angZhang’,‘D
enisBouyssou’,‘Sim
onParsons’,‘Francesca
Rossi’,‘JosC.M.Baeten’,‘M
ikaH
irvensalo’,‘Jonathan
Cohen’,‘G
heorgheMuresan’,‘M
ileK.Stojcev’,
‘IsabelNavazo’,‘Jonathan
Katz’,‘Frederic
Loulergue’,‘PaulDourish’,‘H
ugodeG
aris’,‘Tim
Oates’,
‘DanielMerkle’,
‘Law
rence
S.Moss’,‘M
atthew
Chalmers’
7https://code.google.com/archive/p/word2vec/.8It gives the most similar word for any keyword.9http://dblp.uni-trier.de/xml/.10https://en.wikipedia.org/wiki/Stop_word.11https://en.wikipedia.org/wiki/Acronym.12https://en.wikipedia.org/wiki/Stemming.
Sådhanå (2021) 46:243 Page 9 of 18 243
retrieved result has multiple communities, but our selection
model selects the best community. The number of common
keywords is not the only criteria to select the community
(figure 7).
Table 2 gives weights of the retrieved keyword sets for
the author ‘Tzu-Kuo Huang’. We observe that the size of
keyword sets is at most three. Though the sets of size three
are available, the model has chosen the set of size two. The
keyword set (generalize, multiclass) has more publication
in a short duration, and our model intelligently chooses this
keyword set.
4.1.2 Effect of negative relevance feedbackTable 3 shows some results after applying negative
feedback to see the effectiveness of the negative
relevance feedback. We consider all the direct neighbors
as negative points. Here relevance is measured by using
equation 5. Figures 2 and 3 give the communities for the
queries ‘Nik Nailah Abdullah’ and ‘Xuexiang Huang’,
respectively. As we can see, figures 2a and 3a are connected
to all their neighbors. The system suggests no new peers.
To get a new community, we update query keywords. After
applying negative relevance feedback, we get communities
given in figures 2b and 3b respectively. The connectivity
for every node of the retrieved community is not
compulsory as individuals are retrieved because of
keyword cohesiveness, and all the initially retrieved peers
are penalized, whereas the query node will remain intact.
The retrieved results are connected in the real graph by
nested core property.
4.1.3 Accuracy validationWe use retrieved results for recommendation and relevantresults to validate recommendations. Here validation is to
check whether the query node is using suggested peers in
the future. We take three sets of randomly selected 1000
authors and apply peer recommendations for these selected
authors. Table 4 shows a few examples of validation
process where the retrieved_community has the final peer
recommendations, and relevant_community has the actual
collaborations for the same query based on the dataset set2.
Results are illustrated in figures 4 and 5 for authors ‘Yuan-
Zhi Song’ and ‘Yousuke Hagiwara’ respectively.
Figures 4a and 5a show original peer recommendations
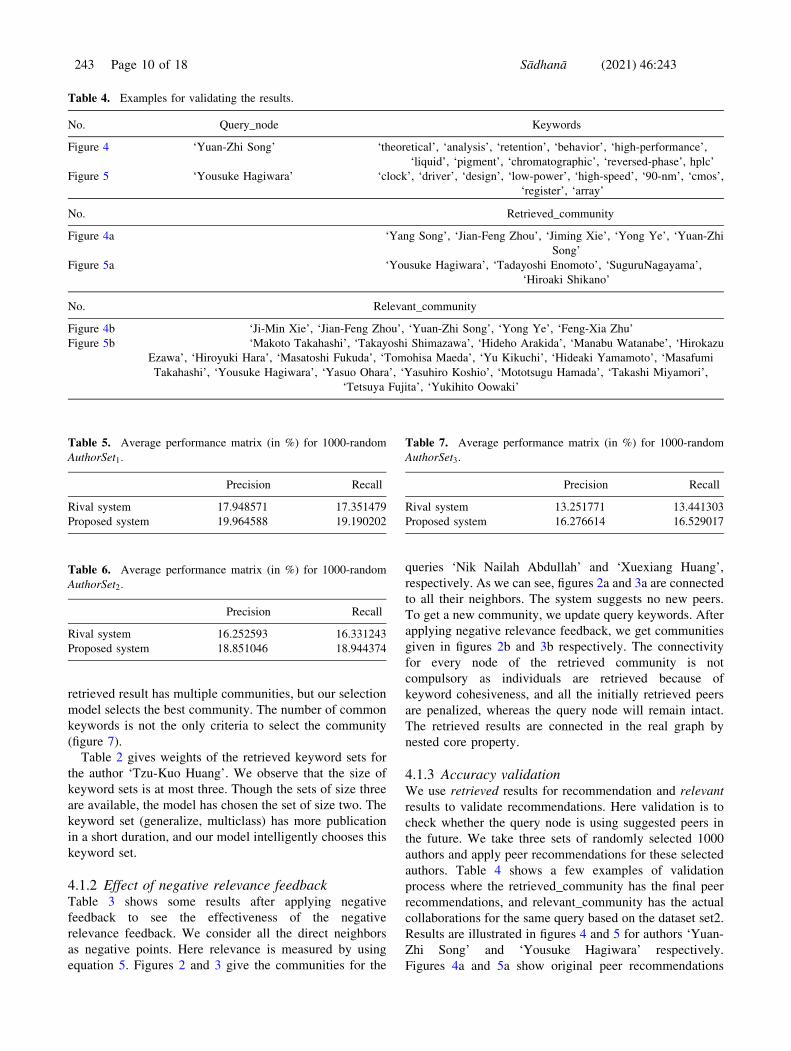
Table 4. Examples for validating the results.
No. Query_node Keywords
Figure 4 ‘Yuan-Zhi Song’ ‘theoretical’, ‘analysis’, ‘retention’, ‘behavior’, ‘high-performance’,
‘liquid’, ‘pigment’, ‘chromatographic’, ‘reversed-phase’, hplc’
Figure 5 ‘Yousuke Hagiwara’ ‘clock’, ‘driver’, ‘design’, ‘low-power’, ‘high-speed’, ‘90-nm’, ‘cmos’,
‘register’, ‘array’
No. Retrieved_community
Figure 4a ‘Yang Song’, ‘Jian-Feng Zhou’, ‘Jiming Xie’, ‘Yong Ye’, ‘Yuan-Zhi
Song’
Figure 5a ‘Yousuke Hagiwara’, ‘Tadayoshi Enomoto’, ‘SuguruNagayama’,
‘Hiroaki Shikano’
No. Relevant_community
Figure 4b ‘Ji-Min Xie’, ‘Jian-Feng Zhou’, ‘Yuan-Zhi Song’, ‘Yong Ye’, ‘Feng-Xia Zhu’
Figure 5b ‘Makoto Takahashi’, ‘Takayoshi Shimazawa’, ‘Hideho Arakida’, ‘Manabu Watanabe’, ‘Hirokazu
Ezawa’, ‘Hiroyuki Hara’, ‘Masatoshi Fukuda’, ‘Tomohisa Maeda’, ‘Yu Kikuchi’, ‘Hideaki Yamamoto’, ‘Masafumi
Takahashi’, ‘Yousuke Hagiwara’, ‘Yasuo Ohara’, ‘Yasuhiro Koshio’, ‘Mototsugu Hamada’, ‘Takashi Miyamori’,
‘Tetsuya Fujita’, ‘Yukihito Oowaki’
Table 5. Average performance matrix (in %) for 1000-random
AuthorSet1.
Precision Recall
Rival system 17.948571 17.351479
Proposed system 19.964588 19.190202
Table 6. Average performance matrix (in %) for 1000-random
AuthorSet2.
Precision Recall
Rival system 16.252593 16.331243
Proposed system 18.851046 18.944374
Table 7. Average performance matrix (in %) for 1000-random
AuthorSet3.
Precision Recall
Rival system 13.251771 13.441303
Proposed system 16.276614 16.529017
243 Page 10 of 18 Sådhanå (2021) 46:243

for a sample attributed query set. Whereas figures 4b and 5b
show the actual collaborations for the above query set
(based on the dataset set2). We present one random fifty
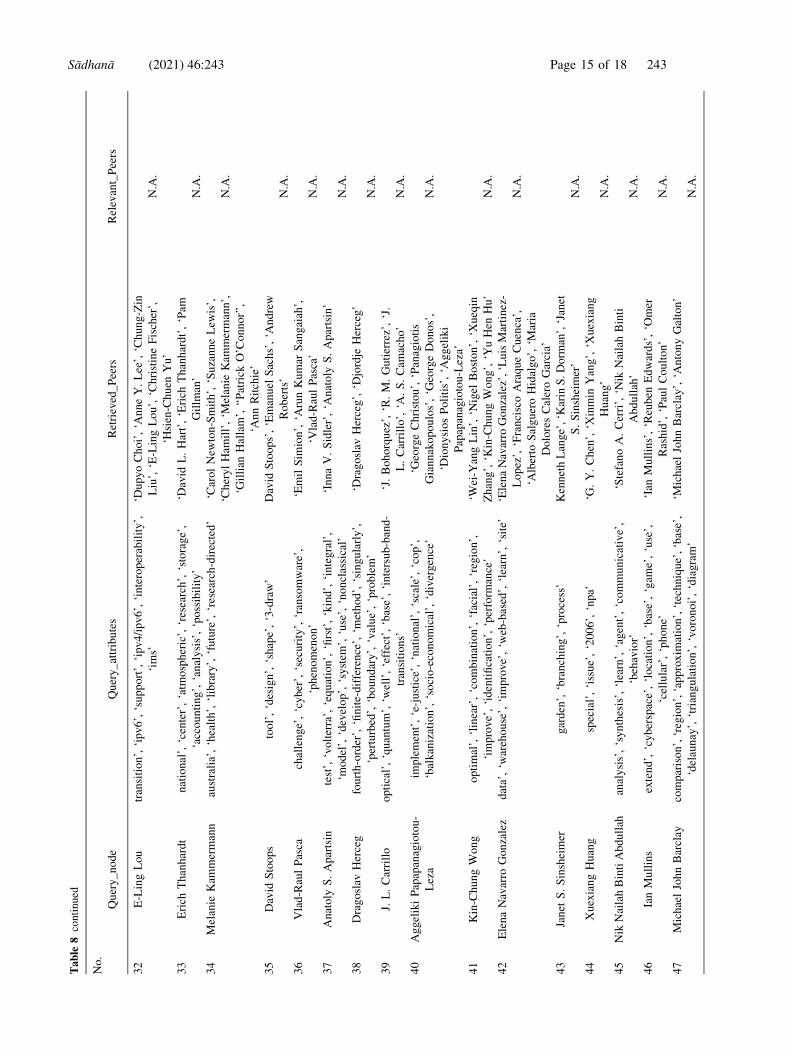
authors set results in Appendix A, where N.A. denotes
authors not available. We use precision and recall to
measure the accuracy of recommendations.
Suppose Aia is the retrieved recommendation for an
author a in a query i , and Bia is a relevant recommendation.
If the number of queries are m:
precisionia ¼ nðAia \ BiaÞ=nðAiaÞ ð6Þ
recallia ¼ nðAia \ BiaÞ=nðBiaÞ ð7Þ
Average precision ¼ ðXm
l¼1
precisionlaÞ=m ð8Þ
Average recall ¼ ðXm
l¼1
recalllaÞ=m ð9Þ
We compared the proposed system with our earlier system
[15]. We calculate precision and recall for all the random
1000 AuthorSeti. We use equation 6 and equation 7 to
calculate the precision and recall respectively for each
author in every AuthorSeti. Equations 8 and 9 are used to
calculate the average precision and average recall respec-
tively. The average precision and average recall of
AuthorSet1, AuthorSet2 and AuthorSet3 are given in
tables 5, 6 and 7 respectively. From our experiments, we
observed that authors are not only exploring the peers in the
area they worked in the past but also exploring the peers
from the new areas of interest.
Our observations based on the results of the proposed
model:
1. In this model, the graph ensures dynamism by updating
its attributes whenever any change occurs in the graph.
2. The final retrieved community need not be connected.
The nodes are connected in the real graph because of the
co-authorships, but the retrieved community has to
satisfy only the keyword cohesiveness property. It can
make member nodes disconnected, as they could not
work together for related attributes.
3. This model has a certain degree of robustness due to the
proposed query reformulation strategy.
We have included the results based on three sets of 1000
random queries. We select random queries along with their
attributes. The random selection of queries from two mil-
lion nodes is time-consuming and complex to the system.
The average running time for each query is 4.32 seconds.
We experimented on three random sets of sizes 150, 350,
500, and 1000 query sets and included the results of 1000
random queries in this paper. We found that the trend in the
results is similar for all these query sets irrespective of the
size of the sets.
5. Conclusion
In this paper, we model peer recommendation as an
attributed community query (ACQ) problem. Peer recom-
mendation is performed over dynamic graphs that ensure
updations of the data. We propose two features named
importance and attention to measuring the expertise of a
peer in a subdomain. Also, we propose to use negative
relevance feedback for community search in a dynamic
collaboration graph. Using these approaches, we refine peer
recommendation where each peer is interested in the same
knowledge as the peer seeker, and some or all have
expertise in it. The model checks the relevance of recom-
mendations that make this system effective when no rele-
vant peers are received. Our model refines the initially
retrieved results through query reformulation in order to get
better results. To the best of our knowledge, this is the first
attempt to use negative relevance feedback for query
reformulation in peer recommendation. Our results are
encouraging.
There are multiple ways to improve the performance of
the proposed model-
(a) We would like to explore the performance of the
proposed model by using intelligent machine learning-
based algorithms.
(b) We intend to apply the peer recommendations to other
collaboration graphs (for example, peer recommenda-
tion in sports graph) with respective domain-specific
features.
(c) To find a better trade-off among importance, attention,
relevance, and proximity will be exciting work.
(d) The current features of an author are taken from the
titles of the publications. This may result in inadequacy
about the interest of an author. The way of getting better
attributes is to take attributes from the title and abstract
of publications.
Appendix A Results for peer recommendation
See Table 8.
Sådhanå (2021) 46:243 Page 11 of 18 243
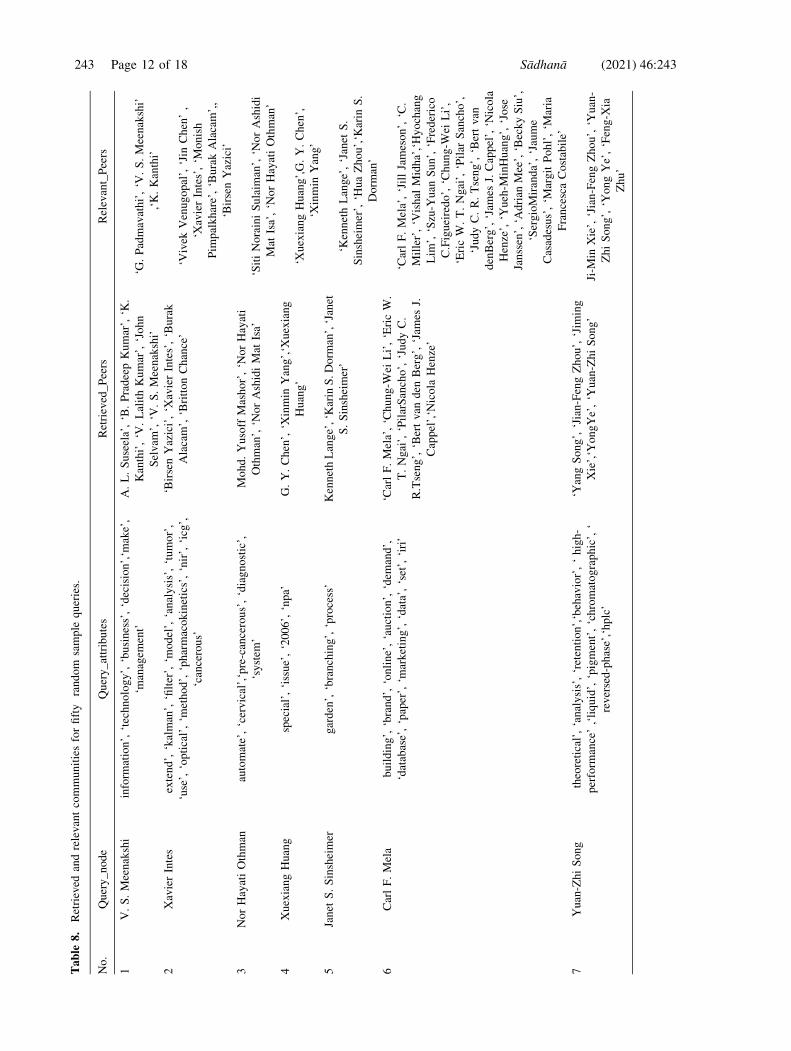
Table
8.
Retrieved
andrelevantcommunitiesforfifty
random
sample
queries.
No.
Query_node
Query_attributes
Retrieved_Peers
Relevant_Peers
1V.S.Meenakshi
inform
ation’,‘technology’,‘business’,‘decision’,‘m
ake’,
‘managem
ent’
A.L.Suseela’,‘B.PradeepKumar’,‘K
.
Kanthi’,‘V
.LalithKumar’,‘John
Selvam
’,‘V
.S.Meenakshi’
‘G.Padmavathi’,‘V
.S.Meenakshi’
,‘K.Kanthi’
2XavierIntes
extend’,‘kalman’,‘filter’,‘m
odel’,‘analysis’,‘tumor’,
‘use’,‘optical’,‘m
ethod’,‘pharmacokinetics’,‘nir’,‘icg’,
‘cancerous’
‘BirsenYazici’,‘X
avierIntes’,‘Burak
Alacam’,‘BrittonChance’
‘Vivek
Venugopal’,‘Jin
Chen’,
‘XavierIntes’,‘M
onish
Pim
palkhare’,‘BurakAlacam’,,
‘BirsenYazici’
3NorHayatiOthman
automate’,‘cervical’,‘pre-cancerous’,‘diagnostic’,
‘system
’
Mohd.Yusoff
Mashor’,‘N
orHayati
Othman’,‘N
orAshidiMat
Isa’
‘SitiNorainiSulaim
an’,‘N
orAshidi
Mat
Isa’,‘N
orHayatiOthman’
4XuexiangHuang
special’,‘issue’,‘2006’,‘npa’
G.Y.Chen’,‘X
inmin
Yang’,‘X
uexiang
Huang’
‘XuexiangHuang’,G.Y.Chen’,
‘Xinmin
Yang’
5Janet
S.Sinsheimer
garden’,‘branching’,‘process’
KennethLange’,‘K
arin
S.Dorm
an’,‘Janet
S.Sinsheimer’
‘KennethLange’,‘Janet
S.
Sinsheimer’,‘H
uaZhou’,‘K
arin
S.
Dorm
an’
6CarlF.Mela
building’,‘brand’,‘online’,‘auction’,‘dem
and’,
‘database’,‘paper’,‘m
arketing’,‘data’,‘set’,‘iri’
‘CarlF.Mela’,‘Chung-W
eiLi’,‘EricW.
T.Ngai’,‘PilarSancho’,‘JudyC.
R.Tseng’,‘Bertvan
den
Berg’,‘Jam
esJ.
Cappel’,‘N
icola
Henze’
‘CarlF.Mela’,‘JillJameson’,‘C.
Miller’,‘V
ishal
Midha’,‘Hyochang
Lim
’,‘Szu-Y
uan
Sun’,‘Frederico
C.Figueiredo’,‘Chung-W
eiLi’,
‘EricW.T.Ngai’,‘Pilar
Sancho’,
‘JudyC.R.Tseng’,‘Bertvan
denBerg’,‘Jam
esJ.Cappel’,‘N
icola
Henze’,‘Y
ueh-M
inHuang’,‘Jose
Janssen’,‘A
drian
Mee’,‘BeckySiu’,
‘SergioMiranda’,‘Jaume
Casadesus’,‘M
argitPohl’,‘M
aria
FrancescaCostabile’
7Yuan-ZhiSong
theoretical’,‘analysis’,‘retention’,‘behavior’,‘high-
perform
ance’,‘liquid’,‘pigment’,‘chromatographic’,‘
reversed-phase’,‘hplc’
‘YangSong’,‘Jian-FengZhou’,‘Jim
ing
Xie’,‘Y
ongYe’,‘Y
uan-ZhiSong’
Ji-M
inXie’,‘Jian-FengZhou’,‘Y
uan-
ZhiSong’,‘Y
ongYe’,‘Feng-X
ia
Zhu’
243 Page 12 of 18 Sådhanå (2021) 46:243
Table
8.
continued
No.
Query_node
Query_attributes
Retrieved_Peers
Relevant_Peers
8YousukeHagiwara
clock’,‘driver’,‘design’,‘low-power’,‘high-speed’,‘90-
nm’,‘cmos’,‘register’,‘array’
YousukeHagiwara’,‘Tadayoshi
Enomoto’,‘SuguruNagayam
a’,‘H
iroaki
Shikano’
‘Makoto
Takahashi’,‘Takayoshi
Shim
azaw
a’,‘HidehoArakida’,
‘ManabuWatanabe’,‘H
irokazu
Ezawa’,‘H
iroyukiHara’,‘M
asatoshi
Fukuda’,‘TomohisaMaeda’,‘Y
u
Kikuchi’,‘H
ideakiYam
amoto’,
‘MasafumiTakahashi’,
‘YousukeH
agiwara’,‘Y
asuoOhara’,
‘YasuhiroKoshio’,‘M
ototsugu
Ham
ada’,‘TakashiMiyam
ori’,
‘TetsuyaFujita’,‘Y
ukihitoOowaki’
9Andreas
Muller’
real-tim
e’,‘statistic’,‘baustein’,‘fur’,‘ein’,‘selbst’,
‘verwaltendes’,‘datenbanksystem
’,‘db2’,‘z/os’,‘und’,
‘os/390’
‘DanielCruz-Suarez’,‘RaulMontes-de-
Oca’,‘EnriqueLem
us-Rodriguez’
‘Andreas
Muller’,‘RobertVilzm
ann’,
‘LajosH
anzo’,‘ChristianHartm
ann
0001’,‘K
atsutoshiKusume’,
‘GerhardBauch
0001’
10
DanielCruz-Suarez
discount’,‘m
arkov’,‘decision’,‘process’,‘condition’,
‘uniqueness’,‘optimal’,‘policy’
FranciscoSalem
-Silva’,‘D
anielCruz-
Suarez’,‘RaulMontes-de-Oca’
‘DanielCruz-Suarez’,‘RaulMontes-
de-Oca’,‘EnriqueLem
us-
Rodriguez’
11
HuiZhuang
(‘complete’,‘nucleotide’,‘sequence’,‘hepatitis’,‘virus’,
’isolated’,‘xinjiang’,‘epidem
ic’,‘1986-1988’,‘china’
‘FusaeIida’,‘H
uiZhuang’,‘Toshikazu
Uchida’,‘TheinT.Aye’,‘Toshio
Shikata’,
‘Xue-ZhungMa’,‘K
hin
MaungWin’
N.A.
12
Per-O
lofWestlund
quantum’,‘description’,‘stern-gerlach’,‘experim
ent’
‘Per-O
lofWestlund’,‘H
akan
Wennerstrom’
N.A.
13
DasariKarunaSagar
point’,‘spread’,‘function’,‘optical’,‘system
’,‘apodized’,
‘sem
icircular’,‘array’,‘aperture’,‘asymmetric’,
‘apodization’
‘DasariKarunaSagar’,‘A
ndra
Naresh
Kumar
Reddy’
N.A.
14
W.R.Walter
large-scale’,‘seism
ic’,‘signal’,‘analysis’,‘hadoop
‘DouglasA.Dodge’,‘T.G.Addair’,‘W
.
R.Walter’,‘StanD.Ruppert’
N.A.
15
Jose
GuilhermeCecatti
mobile’,‘technology’,‘health’,‘m
health’,‘antenatal’,
‘care-searching’,‘apps’,‘available’,‘solution’,
‘system
atic’,‘review’
‘Jose
GuilhermeCecatti’,‘Sam
iraM.
Haddad’,‘RenatoT.Souza’
N.A.
16
DianeMichelfelder
sustain’,‘engineering’,‘code’,‘ethic’,‘twenty-first’,
‘century’
‘DianeMichelfelder’,‘SharonA.Jones’
N.A.
17
MuneerahR.Aldhafian
toward’,‘design’,‘li-fi-based’,‘hierarchical’,‘iot’,
‘architecture’
‘Afnan
A.Aljaser’,‘Lam
iaAl-Braheem’,
‘Lam
iaH.Alhudaithy’,‘M
uneerahR.
Aldhafian’,‘G
hadaM.Bahliwah’
N.A.
Sådhanå (2021) 46:243 Page 13 of 18 243
Table
8continued
No.
Query_node
Query_attributes
Retrieved_Peers
Relevant_Peers
18
AkihikoTaw
ara
tolerance’,‘range’,‘binocular’,‘disparity’,‘‘display’,
‘base’,‘physiological’,‘characteristic’,‘ocular’,
‘accommodation’
‘TsunetoIw
asaki’,‘A
kihikoTaw
ara’,
‘ToshiakiKubota’
N.A.
19
Yuan
Hou
redundant’,‘heterogeneity’,‘group’,‘perform
ance’
‘LiliTian’,‘Y
ingLiu’,‘Y
angLi’,‘Y
uan
Hou’,‘Lei
Liu’,‘EdwardBishopSmith’,
‘AthanasiosV.Vasilakos’,‘Tao
Zhou’,
‘Yao
Wang0001’
N.A.
20
RebekkaS.Renner
perception’,‘egocentric’,‘distance’,‘virtual’,
‘environment’,‘review’
‘JingWang’,‘Jean-Louis
Vercher’,
‘RebekkaS.Renner’,‘Christophe
Bourdin’,‘BorisM.Velichkovsky’,‘‘Jens
R.Helmert’
N.A.
21
DominikaPolkowska
pac’,‘bound’,‘substructure’,‘stable’,‘structure’
‘Sanjeev
R.Kulkarni’,‘D
ominika
Polkowska’,‘A
nandPillay’
N.A.
22
Peter
Tomaszewski
mismatch’,‘sim
ulation’,‘layout’,‘sensitive’,‘param
eter’,
‘component’,‘device’
‘LiZhang’,‘G
erhardTroster’,‘Peter
Tomaszewski’
N.A.
23
MariosPolitis
analysis’,‘dynam
ical’,‘m
odel’,‘hiv’,‘infection’,‘one’,
‘two’,‘input’
‘MariosPolitis’,‘Ioannis
Kafetzis’,
‘LazarosMoysis’
N.A.
24
RichardS.Drake
survey’,‘video’,‘gam
e’,‘preference’,‘adult’,‘building’,
‘well’,‘old’
‘JoshuaP.Salmon’,‘RichardS.Drake’,
‘GailA.Eskes’,
N.A.
25
TiefengPeng
surface’,‘interaction’,‘nanoscale’,‘w
ater’,‘film
’,
‘computational’,‘sim
ulation’,‘thermodynam
ics’
‘Chao
He’,‘LonghuaXu’,‘Q
ibin
Li’,
‘LiqunLuo’,‘TiefengPeng’
N.A.
26
Basavaraj
Hirem
ath
bayesian’,‘approach’,‘alignment’,‘high-resolution’,
‘nmr’,‘spectrum’
‘SeoungBum
Kim
’,‘BasavarajHirem
ath’,
‘ZhouWang’
N.A.
27
JiguangZhu
new
’,‘approach’,‘detect’,‘active’,‘rule’,‘confluence’,
‘exclusive’,‘process’,‘indeterminable’
‘HongchunYuan’,‘ShijunHe’,‘H
uiwen
Wei’,‘Zhongmin
Xiong’,‘JiguangZhu’
N.A.
28
HuanglongTeng
multi-hop’,‘delay’,‘reduction’,‘safety-related’,‘m
essage’,
‘broadcasting’,‘vehicle-to-vehicle’,‘communication’
‘Hongbin
Chen’,‘Bin-Jie
Hu’,‘X
iaohuan
Li’,‘H
uanglongTeng’,‘BingLi0016’,
‘Manman
Cui’
N.A.
29
Kevin
K.Parker
actuator’,‘robotics’,‘review’,‘device’,‘actuate’,‘living’,
‘cell’,‘biohybrid’
‘Paolo
Dario’,‘RituRam
an’,‘K
evin
K.
Parker’,‘A
riannaMenciassi’,‘Rashid
Bashir’,‘M
etin
Sitti’,‘Barry
Trimmer’,
‘SylvainMartel’,‘A
dam
W.Feinberg’
N.A.
30
HongjingLiu
analytical’,‘study’,‘m
ulti-tier’,‘heterogeneous’,‘small’,
‘cell’,‘network’,‘coverage’,‘perform
ance’,‘energy’,
‘efficiency’
‘ZhuHan’,‘TongLi0013’,‘H
ongjing
Liu’,‘M
oham
ed-Slim
Alouini’,‘V
ictorC.
M.Leung’,‘Ekram
Hossain’,‘D
ongWang
0016’,‘ZhuXiao’,‘Rahim
Tafazolli’,
‘VincentHavyarim
ana’
N.A.
31
RuiShantilau
socio-technical’,‘approach’,‘address’,‘inform
ation’,
‘security’,‘use’,‘m
anager’,‘artefact’,‘27001’
‘RuiShantilau’,‘A
nacleto
Correia’,
‘Antonio
Goncalves’
N.A.
243 Page 14 of 18 Sådhanå (2021) 46:243
Table
8continued
No.
Query_node
Query_attributes
Retrieved_Peers
Relevant_Peers
32
E-LingLou
transition’,‘ipv6’,‘support’,‘ipv4/ipv6’,‘interoperability’,
‘ims’
‘DupyoChoi’,‘A
nneY.Lee’,‘Chung-Zin
Liu’,‘E-LingLou’,‘ChristineFischer’,
‘Hsien-Chuen
Yu’
N.A.
33
Erich
Thanhardt
national’,‘center’,‘atm
ospheric’,‘research’,‘storage’,
‘accounting’,‘analysis’,‘possibility’
‘David
L.Hart’,‘Erich
Thanhardt’,‘Pam
Gillm
an’
N.A.
34
Melanie
Kam
mermann
australia’,‘health’,‘library’,‘future’,‘research-directed’
‘CarolNew
ton-Smith’,‘SuzanneLew
is’,
‘CherylHam
ill’,‘M
elanie
Kam
mermann’,
‘Gillian
Hallam’,‘‘Patrick
O’Connor’’,
‘AnnRitchie’
N.A.
35
David
Stoops
tool’,‘design’,‘shape’,‘3-draw’
David
Stoops’,‘Emanuel
Sachs’,‘A
ndrew
Roberts’
N.A.
36
Vlad-RaulPasca
challenge’,‘cyber’,‘security’,‘ransomware’,
‘phenomenon’
‘EmilSim
ion’,‘A
runKumar
Sangaiah’,
‘Vlad-RaulPasca’
N.A.
37
Anatoly
S.Apartsin
test’,‘volterra’,‘equation’,‘first’,‘kind’,‘integral’,
‘model’,‘develop’,‘system
’,‘use’,‘nonclassical’
‘InnaV.Sidler’,‘A
natoly
S.Apartsin’
N.A.
38
Dragoslav
Herceg
fourth-order’,‘finite-difference’,‘m
ethod’,‘singularly’,
‘perturbed’,‘boundary’,‘value’,‘problem’
‘Dragoslav
Herceg’,‘D
jordje
Herceg’
N.A.
39
J.L.Carrillo
optical’,‘quantum’,‘w
ell’,‘effect’,‘base’,‘intersub-band-
transitions’
‘J.Bohorquez’,‘R.M.Gutierrez’,‘J.
L.Carrillo’,‘A
.S.Cam
acho’
N.A.
40
AggelikiPapapanagiotou-
Leza
implement’,‘e-justice’,‘national’,‘scale’,‘cop’,
‘balkanization’,‘socio-economical’,‘divergence’
‘GeorgeChristou’,‘Panagiotis
Giannakopoulos’,‘G
eorgeDonos’,
‘DionysiosPolitis’,‘A
ggeliki
Papapanagiotou-Leza’
N.A.
41
Kin-ChungWong
optimal’,‘linear’,‘combination’,‘facial’,‘region’,
‘improve’,‘identification’,‘perform
ance’
‘Wei-Y
angLin’,‘N
igel
Boston’,‘X
ueqin
Zhang’,‘K
in-ChungWong’,‘Y
uHen
Hu’
N.A.
42
ElenaNavarro
Gonzalez
data’,‘w
arehouse’,‘improve’,‘w
eb-based’,‘learn’,‘site’
‘ElenaNavarro
Gonzalez’,‘LuisMartinez-
Lopez’,‘FranciscoAraqueCuenca’,
‘Alberto
SalgueroHidalgo’,‘M
aria
DoloresCaleroGarcia’
N.A.
43
Janet
S.Sinsheimer
garden’,‘branching’,‘process’
KennethLange’,‘K
arin
S.Dorm
an’,‘Janet
S.Sinsheimer’
N.A.
44
XuexiangHuang
special’,‘issue’,‘2006’,‘npa’
‘G.Y.Chen’,‘X
inmin
Yang’,‘X
uexiang
Huang’
N.A.
45
Nik
NailahBintiAbdullah
analysis’,‘synthesis’,‘learn’,‘agent’,‘communicative’,
‘behavior’
‘StefanoA.Cerri’,‘N
ikNailahBinti
Abdullah’
N.A.
46
IanMullins
extend’,‘cyberspace’,‘location’,‘base’,‘gam
e’,‘use’,
‘cellular’,‘phone’
‘Ian
Mullins’,‘Reuben
Edwards’,‘O
mer
Rashid’,‘PaulCoulton’
N.A.
47
MichaelJohnBarclay
comparison’,‘region’,‘approxim
ation’,‘technique’,‘base’,
‘delaunay’,‘triangulation’,‘voronoi’,‘diagram’
‘MichaelJohnBarclay’,‘A
ntonyGalton’
N.A.
Sådhanå (2021) 46:243 Page 15 of 18 243

Acknowledgements
The support and the resources provided by ‘PARAM
Shivay Facility’ under the National Supercomputing Mis-
sion, Government of India at the Indian Institute of
Technology, Varanasi are gratefully acknowledged.
References
[1] Yixiang Fang, Xin Huang, Lu Qin, Ying Zhang, Wenjie
Zhang, Reynold Cheng and Xuemin Lin 2020 A survey of
community search over big graphs. VLDB J. 29(1): 353–392[2] Yixiang Fang, Yixing Yang, Wenjie Zhang, Xuemin Lin and
Xin Cao 2020 Effective and efficient community search over
large heterogeneous information networks. Proc. VLDBEndow. 13(6): 854–867
[3] Xin Huang and Laks V S Lakshmanan 2017 Attribute-driven
community search. Proc. VLDB Endow. 10(9): 949–960[4] Lu Chen, Chengfei Liu, Rui Zhou, Jianxin Li, Xiaochun
Yang and Bin Wang 2018 Maximum co-located community
search in large scale social networks. Proc. VLDB Endow.11(10): 1233–1246
[5] Jianxin Li, Xinjue Wang, Ke Deng, Xiaochun Yang, Timos
Sellis and Jeffrey Xu Yu 2017 Most influential community
search over large social networks. In: 33rd IEEE Interna-tional Conference on Data Engineering, ICDE 2017,San Diego, CA, USA, April 19-22, 2017, pages 871–882.
IEEE Computer Society
[6] Xin Huang, Laks V S Lakshmanan and Jianliang Xu 2017
Community search over big graphs: Models, algorithms, and
opportunities. In 33rd IEEE International Conference onData Engineering, ICDE 2017, San Diego, CA, USA, April
19–22, 2017, pages 1451–1454. IEEE Computer Society
[7] Jian Wei, Jianhua He, Kai Chen, Yi Zhou and Zuoyin Tang
2017 Collaborative filtering and deep learning based recom-
mendation system for cold start items. Expert Syst. Appl. 69:29–39
[8] Xingjuan Cai, Zhaoming Hu, Peng Zhao, Wensheng Zhang
and Jinjun Chen 2020 A hybrid recommendation system with
many-objective evolutionary algorithm. Expert Syst. Appl.159: 113648
[9] Carlo De Medio, Carla Limongelli, Filippo Sciarrone and
Marco Temperini 2020 Moodlerec: A recommendation
system for creating courses using the moodle e-learning
platform. Comput. Hum. Behav. 104: 106168[10] Hyunwoo Hwangbo, Yang Sok Kim and Kyung Jin Cha
2018 Recommendation system development for fashion
retail e-commerce. Electron. Commer. Res. Appl. 28: 94–101[11] Renata Lopes Rosa, Gisele M. Schwartz, Wilson Vicente
Ruggiero and Demostenes Zegarra Rodrıguez 2019 A
knowledge-based recommendation system that includes
sentiment analysis and deep learning. IEEE Trans. Ind.Informatics 15(4): 2124–2135
[12] Yixiang Fang, Reynold Cheng, Yankai Chen, Siqiang Luo
and Jiafeng Hu 2017 Effective and efficient attributed
community search. VLDB J. 26(6): 803–828[13] Yixiang Fang, Zheng Wang, Reynold Cheng, Xiaodong Li,
Siqiang Luo, Jiafeng Hu and Xiaojun Chen 2019 On spatial-
Table
8continued
No.
Query_node
Query_attributes
Retrieved_Peers
Relevant_Peers
48
HironobuKaw
akoe
estimation’,‘contact’,‘shape’,‘quadric’,‘environment’,
‘object’,‘probe’,‘operation’
HironobuKaw
akoe’,‘Showzow
Tsujio’,
‘YoshiyukiKam
o’,‘Y
ongYu0003’
N.A.
49
Hongwei
Cheng
compression’,‘low’,‘rank’,‘m
atrix’,‘w
ideband’,‘fast’,
‘multipole’,‘m
ethod’,‘helmholtz’,‘equation’,‘three’,
‘dim
ension’
‘Zydrunas
Gim
butas’,‘V
ladim
irRokhlin’,
‘Hongwei
Cheng’
N.A.
50
AgnieszkaSwierczewska
flow’,‘incompressible’,‘fluid’,‘discontinuous’,‘rheology’,
‘large’,‘eddy’,‘sim
ulation’,‘turbulence’,‘m
odel’,
‘young’,‘m
easure’,‘power-law
-like’
‘PiotrGwiazda’,‘A
gnieszka
Swierczewska’
N.A.
243 Page 16 of 18 Sådhanå (2021) 46:243

aware community search. IEEE Trans. Knowl. Data Eng.31(4): 783–798
[14] Yunbo Rao, Wei Liu, Bojiang Fan, Jiali Song and Yang
Yang 2018 A novel relevance feedback method for CBIR.
World Wide Web 21(6): 1505–1522
[15] Vivek Sourabh and C Ravindranath Chowdary 2019 Peer
recommendation in dynamic attributed graphs. Expert Syst.Appl. 120: 335–345
[16] Xuanhui Wang, Hui Fang and ChengXiang Zhai 2008 A
study of methods for negative relevance feedback. In: SIGIR,pp. 219–226. ACM
[17] Jie Lu, Dianshuang Wu, Mingsong Mao, Wei Wang and
Guangquan Zhang 2015 Recommender system application
developments: A survey. Decis. Support Syst. 74: 12–32[18] Charu C Aggarwal 2016 Content-Based Recommender Sys-
tems, pp. 139–166. Springer International Publishing, Cham.
[19] Panagiotis Symeonidis, Alexandros Nanopoulos, Apos-
tolos N. Papadopoulos and Yannis Manolopoulos 2008
Collaborative recommender systems: Combining effective-
ness and efficiency. Expert Syst. Appl. 34(4): 2995–3013[20] Sriharsha Dara, C Ravindranath Chowdary and Chintoo
Kumar 2020 A survey on group recommender systems. J.Intell. Inf. Syst. 54(2): 271–295
[21] Akshita Agarwal, Manajit Chakraborty and C Ravindranath
Chowdary 2017 Does order matter? effect of order in group
recommendation. Expert Syst. Appl. 82: 115–127[22] Jae Kyeong Kim, Hyea Kyeong Kim, Hee Young Oh and
Young U Ryu 2010 A group recommendation system for
online communities. Int. J. Inf. Manag. 30(3): 212–219[23] Andrew Crossen, Jay Budzik and Kristian J Hammond 2002
Flytrap: intelligent group music recommendation. In: IUI,pp. 184–185. ACM
[24] Inma Garcia, Laura Sebastia and Eva Onaindia 2011 On the
design of individual and group recommender systems for
tourism. Expert Syst. Appl. 38(6): 7683–7692[25] Lara Quijano-Sanchez, Christian Severin Sauer and Juan A
Recio-Garcıa and Juan A Recio-Garciıa 2017 Make it
personal: A social explanation system applied to group
recommendations. Expert Systems with Applications,76(Supplement C): 36–48, 2017
[26] Sarik Ghazarian and Mohammad Ali Nematbakhsh 2015
Enhancing memory-based collaborative filtering for group
recommender systems. Expert Systems with Applications42(7): 3801–3812
[27] Y Y Chen, A J Cheng and W H Hsu 2013 Travel recom-
mendation by mining people attributes and travel group
types from community-contributed photos. IEEE Transac-tions on Multimedia 15(6): 1283–1295
[28] R Sotelo, Y Blanco, M Lopez, A Gil and J Pazos 2009 Tv
program recommendiation for groups based on multidimen-
sional tv-anytime classifications. In: 2009 Digest of Techni-cal Papers International Conference on ConsumerElectronics, pages 1–2
[29] Raheem Sarwar, Norawit Urailertprasert, Nattapol Vanna-
boot, Chenyun Yu, Thanawin Rakthanmanon, Ekapol
Chuangsuwanich and Sarana Nutanong 2020 CAG: stylo-
metric authorship attribution of multi-author documents
using a co-authorship graph. IEEE Access 8: 18374–18393[30] Leila Esmaeili, Shahla Mardani, Seyyed Alireza Hashemi
Golpayegani and Zeinab Zanganeh Madar 2020 A novel
tourism recommender system in the context of social
commerce. Expert Syst. Appl. 149: 113301[31] Yiteng Pan, Fazhi He and Haiping Yu 2020 Learning social
representations with deep autoencoder for recommender
system. World Wide Web 23(4): 2259–2279
[32] Francois Bouchet, Hugues Labarthe, Kalina Yacef and Remi
Bachelet 2017 Comparing peer recommendation strategies in
a MOOC. In: UMAP (Adjunct Publication), pages 129–134.ACM
[33] Qintai Hu, Zhongmei Han, Xiaofan Lin, Qionghao Huang
and Xiaomei Zhang 2019 Learning peer recommendation
using attention-driven CNN with interaction tripartite graph.
Inf. Sci. 479: 231–249[34] Xiang Sean Zhou and Thomas S Huang 2003 Relevance
feedback in image retrieval: A comprehensive review.
Multim. Syst. 8(6): 536–544[35] Xuehua Shen, Bin Tan and ChengXiang Zhai 2005 Context-
sensitive information retrieval using implicit feedback. In:
SIGIR, pages 43–50. ACM[36] Francesco Colace, Massimo De Santo, Luca Greco and
Paolo Napoletano 2015 Improving relevance feedback-based
query expansion by the use of a weighted word pairs
approach. J. Assoc. Inf. Sci. Technol. 66(11): 2223–2234[37] R Attar and Aviezri S Fraenkel 1977 Local feedback in full-
text retrieval systems. J. ACM 24(3): 397–417
[38] Jinxi Xu and W Bruce Croft 2017 Quary expansion using
local and global document analysis. SIGIR Forum 51(2):
168–175
[39] Guihong Cao, Jian-Yun Nie, Jianfeng Gao and Stephen
Robertson 2008 Selecting good expansion terms for pseudo-
relevance feedback. In: SIGIR, ACM pages 243–250
[40] Abdulmohsen Algarni, Yuefeng Li, Sheng-Tang Wu and
Yue Xu 2012 Text mining in negative relevance feedback.
Web Intell. Agent Syst. 10(2): 151–163[41] Yuefeng Li, Xiaohui Tao, Abdulmohsen Algarni and Sheng-
Tang Wu 2009 Mining specific and general features in both
positive and negative relevance feedback. In: TREC, volume
500–278 of NIST Special Publication. National Institute of
Standards and Technology (NIST)
[42] Rianne Kaptein, Jaap Kamps and Djoerd Hiemstra 2008 The
impact of positive, negative and topical relevance feedback.
In: TREC, volume 500–277 of NIST Special Publication.National Institute of Standards and Technology (NIST)
[43] Shun Kawahara, Kazuhiro Seki and Kuniaki Uehara 2015
Detecting vital documents using negative relevance feedback
in distributed realtime computation framework. PACLING;In volume 593 of Communications in Computer andInformation Science, pages 193–208. Springer
[44] Abdulmohsen Algarni, Yuefeng Li, Yue Xu and Raymond
Y K Lau 2009 An effective model of using negative
relevance feedback for information filtering. In: CIKM,
pages 1605–1608. ACM
[45] Jaakko Peltonen, Jonathan Strahl and Patrik Floreen 2017
Negative relevance feedback for exploratory search with
visual interactive intent modeling. In: IUI, pages 149–159.
ACM
[46] Abir Gallas, Walid Barhoumi and Ezzeddine Zagrouba
2014 Negative relevance feedback for improving retrieval
in large-scale image collections. In: 2014 IEEE Interna-tional Symposium on Multimedia, ISM 2014, Taichung,
Sådhanå (2021) 46:243 Page 17 of 18 243

Taiwan, December 10-12, 2014, pages 1–8. IEEE
Computer Society
[47] Henning Muller, Wolfgang Muller, Stephane Marchand-
Maillet, Thierry Pun and David Squire 2000 Strategies for
positive and negative relevance feedback in image
retrieval. In: ICPR, pages 5043–5042. IEEE Computer
Society
[48] Yixiang Fang, Reynold Cheng, Siqiang Luo and Jiafeng Hu
2016 Effective community search for large attributed graphs.
Proc. VLDB Endow. 9(12): 1233–1244[49] Hongwei Wang, Fuzheng Zhang, Jialin Wang, Miao Zhao,
Wenjie Li, Xing Xie and Minyi Guo 2018 Ripplenet:
Propagating user preferences on the knowledge graph for
recommender systems. In: CIKM, pages 417–426. ACM
243 Page 18 of 18 Sådhanå (2021) 46:243