pearl: a programmable virtual router platform
TRANSCRIPT

IEEE Communications Magazine • July 2011 710163-6804/11/$25.00 © 2011 IEEE
INTRODUCTIONDeploying, experimenting, and testing new
protocols and systems over the Internet havealways been major issues. While, one could usesimulation tools for the evaluation of a new sys-tem aimed at large-scale deployment, real exper-imentation in an experimental environment withrealistic enough settings, such as real trafficworkload and application mix, is mandatory.Therefore, easy programmable platforms thatcan support high-performance packet forwardingand enable parallel deployment and experimentof different research ideas are highly demanded.
Moreover, we are moving toward a futureInternet architecture that seems to be polymor-phic rather than monolithic: the architecture willhave to accommodate simultaneous coexistenceof several architectures (the Named Data Net-work (NDN) [1], etc.) including the currentInternet. Therefore, the future Internet shouldbe based on platforms running different archi-tectures in virtual slices enabling independentprogramming and configuration of the functionsof each individual slice.
Current commercial routers, the most impor-tant building blocks in the Internet, while attain-ing very high performance, offer only verylimited access to researchers and developers for
their internal components to implement anddeploy innovative networking architectures. Incontrast, open-software-based routers naturallyfacilitate access to and adaptation of almost allof their components, although frequently withlow packet processing performance.
As an example, recent OpenFlow switchesprovide flexibility by allowing programmers toconfigure the 10-tuple of flow table entries,enabling the change of packet processing of aflow. OpenFlow switches are not ready for non-IP-based packet flows, such as NDN. Moreover,while the switches allow a number of slices fordifferent routing protocols through the FlowVi-sor, the slices are not isolated in terms of pro-cessing capacity, memory, and bandwidth.
Motivated by these facts, we have designedand built a programmable virtual router platform,PEARL, that can guarantee high performance.The challenges are twofold: first to manage theflexibility vs. performance trade-off that translatesinto pushing functionality to hardware for perfor-mance vs. programming them in software for flex-ibility, and second to ensure isolation betweenvirtual router instances in both hardware andsoftware with low performance overhead.
This article describes the PEARL router’sarchitecture, its key components, and the perfor-mance results. It shows that PEARL meets thedesign goals of flexibility, high performance, andisolation. In the next section, we describe thedesign goals of the PEARL platform. Thesegoals can be taken as the main features of ourdesigned platform. We then detail the designand implementation of the platform, includingboth hardware and software platforms. In thenext section, we evaluate the performance of aPEARL-based router using the Spirent TestCen-ter by injecting into it both IPv4 and IPv6 traffic.Finally, we briefly summarize related work andconclude the article.
DESIGN GOALSIn the past few years, several future Internetarchitectures and protocols at different layershave been proposed to cope with the challenges
ABSTRACT
Programmable routers supporting virtualiza-tion are a key building block for bridging the gapbetween new Internet protocols and theirdeployment in real operational networks. Thisarticle presents the design and implementationof PEARL, a programmable virtual router plat-form with relatively high performance. It offershigh flexibility by allowing users to control theconfiguration of both hardware and softwaredata paths. The platform makes use of fastlookup in hardware and software exceptions incommodity multicore CPUs to achieve high-speed packet processing. Multiple isolated pack-et streams and virtualization techniques ensureisolation among virtual router instances.
FUTURE INTERNET ARCHITECTURES: DESIGN ANDDEPLOYMENT PERSPECTIVES
Gaogang Xie, Peng He, Hongtao Guan, Zhenyu Li, Yingke Xie, Layong Luo, Jianhua Zhang, and Yong-
gong Wang, Chinese Academy of Sciences
Kavé Salamatian, University of Savoie
PEARL: A Programmable Virtual Router Platform
LI2 LAYOUT 6/20/11 4:16 PM Page 71

IEEE Communications Magazine • July 201172
the current Internet faces [1]. Evaluating thereliability and performance of these proposedinnovative mechanisms is mandatory beforeenvisioning real-scale deployment. Besides theo-retically evaluating the performance of a systemand simulating these implementations, one needsto deploy them in a production network with areal user behavior, traffic workload, resourcedistribution, and applications mixture. However,a major principle in experimental deployment isthe “no harm” principle that states that normalservices on a production network should not beimpacted by the deployment of a new service.Moreover, no unique architecture or protocolstack will be able to support all actual and futureInternet services and we might need specificpacket processing for given services. Obviously, aflexible router platform with high-speed packetprocessing ability and support of multiple paral-lel and virtualized independent architectures isextremely attractive for both Internet researchand operation. Based on this observation onecan define isolation, flexibility, and high perfor-mance as the needed characteristics and designgoals of a router platform future Internet.
In particular, the platform should be able tocope with various types of packets includingIPv4, IPv6, and even non-IP, and be able toapply packet routing as well as circuit switching.Various software solutions like Quagga orXORP [2] have provided such flexible platformthat is able to adapt their packet-processingcomponents as well as to customize the function-alities of their data, control and managementplanes. However, these approaches fail to be fastenough to be used in operational context wherea wire-speed is needed. Nevertheless, by addingand configuring convenient hardware packetprocessing resources such as FPGA, CPU coresand memory storage one can hope to meet theperformance requirements. Indeed, flexibilityand high performance are in conflict in most sit-uations. Flexibility requires more functionalitiesto be implemented in software to maximize theprogrammability. On other hand, high perfor-mance cannot be reached in software and needs
custom hardware. A major challenge for PEARLis to allocate enough hardware and multi-coresin order to achieve both flexibility and high per-formance.
Another design goal is relative to isolation.By isolation we mean a mechanism that enablesdifferent architectures or protocols running inparallel on separate virtual router instances with-out impacting each other’s performance. Inorder to achieve isolation, we should provide amechanism to ensure that one instance can onlyuse its allocated hardware (CPU cores andcycles, memory, resources, etc.) and softwareresources (lookup routing tables, packet queue,etc.), and is forbidden to access resources ofother instances even when they are idle. We alsoneed a dispatching component to ensure that IPor non-IP packets are delivered to specifiedinstances following custom rules defined overmedium access control (MAC) layer parameters,protocols, flow labels, or packet header fields.
PEARL offers high flexibility through thecustom configurations of both the hardware andsoftware data paths. Multiple isolated packetstreams and virtualization techniques enable iso-lation among virtual router instances, while thefast lookup hardware provides the capacity toachieve high performance
PLATFORM DESIGN ANDIMPLEMENTATION
SYSTEM OVERVIEW
PEARL uses commodity multicore CPU hard-ware platforms that run generic software as wellas specialized packet processing cards for high-performance packet processing as shown in Fig.1. The virtualization environment is built usingthe Linux-based LXC solution. This enablesmultiple virtual router instances to run in paral-lel over a CPU core or one router instance overmultiple CPU cores. Each virtual machine canbe logically viewed as a separate host. The hard-ware platform contains a field programmablegate array (FPGA)-based packet processing cardwith embedded TCAM and SRAM. This cardenables fast packet processing and strong isola-tion.
Isolation — PEARL implements multiple simul-taneous fast virtual data planes by allocating sep-arate hardware resources to each virtual dataplane. This facilitates strong isolation among thehardware virtual data planes. Moreover, LXCtakes advantage of a group of the kernel feature(namespace, Cgroup) to ensure isolation in soft-ware between virtual router instances. A multi-stream high-performance DMA engine is alsoused in PEARL, which receives and transmitspackets via high-speed PCI Express bus betweenhardware and software platforms. Each IOstream can be either assigned to a dedicated vir-tual router or shared by several virtual routersusing a net IO proxy.
Flexibility — We use TAP/TUN device as thenetwork interface in each virtual machine. Eachvirtual machine could be considered as a stan-
Figure 1. Overview of the PEARL architecture.
Hardware platform
MA
Cand PH
Y
RX process
TX process
DMA interface
PCIE bus
IO stream
IO stream
IO stream
IO stream
Generalized multi-core CPUs
Specialized packetprocessing card
VM 1
Protocol(IP/
Non-IP)
APPs
VM 2
Protocol(IP/
Non-IP)
APPs
VM 3 VM4
Software platform
Protocol(IP/
Non-IP)
APPs
VM5
Net IO proxy
VMN
LI2 LAYOUT 6/20/11 4:16 PM Page 72

IEEE Communications Magazine • July 2011 73
dard Linux host containing multiple networkports. Thus, the IPv4, IPv6, OpenFlow, and evennon-IP protocol stacks can easily be loaded.Adding new functions to a router is also conve-nient though programming Linux applications.For example, to load IPv4 or IPv6, the Quaggarouting software suite can be used as the controlplane inside each Linux container.
High Performance — The operations of rout-ing table lookup and packet dispatch to differentvirtual machines are always performance bottle-necks. PEARL offloads these two operationsinto hardware to achieve high-speed packet for-warding. In addition, since LXC is a lightweightvirtualization technique with low overhead, theperformance is further improved.
HARDWARE PLATFORMTo provide both high performance and strongisolation in PEARL, we design a specializedpacket processing card. Figure 2 shows the archi-tecture of hardware data plane. It is a pipeline-based architecture, which consists of two maindata paths: transmitting and receiving. Thereceiving data path is responsible for processingthe ingress packets, and the transmitting datapath processes the egress packets. In the follow-ing, the processing stages of the pipeline aredetailed.
Header Extractor — For each incoming packet,one or many fields are extracted from the packetheader. These fields are used for virtual routerID (VID) lookup in the next processing stage.For IP-based protocols, a 10-tuple, defined fol-lowing OpenFlow [3], is extracted, while for non-IP protocols, the MAC address is extracted.
VID Lookup — Each virtual router in the plat-form is marked by a unique VID. This stageclassifies the packet based on the fields extractedin the previous stage. We use TCAM for thestorage and lookup of the fields, which can beconfigured by the users. Due to the special fea-tures of TCAM, each field of the rules in a VIDlookup table can be a wildcard. Hence, PEARL
can classify packets of any kind of protocol intodifferent virtual routers as long as they are Eth-ernet based, such as IPV4, IPv6 and non-IP pro-tocols. The VID lookup table is managed by asoftware controller which enables users to definethe fields as needed. The VID of the virtualrouter to which a packet belongs is appended onthe packet as a custom header.
Routing Table Lookup — In a network virtual-ization environment, each virtual router shouldhave a distinct routing table. Since there are nostandards for non-IP protocols until now, weonly consider the storage and lookup of routingtables for IP-based protocols in hardware. It isworth noting that routing tables for non-IP pro-tocols can be accommodated through FPGA inthe cards.
Given limited hardware resources, we imple-ment four routing tables in the current design.The tables are stored in TCAM as well. We takethe VID combined with the destination IPaddress as a search key. The VID part of the keyis performed exact matching and the IP part isperformed the longest prefix matching in TCAM.Once a packet matches in the hardware, itneedn’t be sent to the kernel for further process-ing, greatly improving the packet forwarding per-formance.
For non-IP protocols or the IP-based proto-cols that are not accommodated in the hardware,we integrate a CPU transceiver module. Themodule is responsible for transmitting the packetto the CPU directly without looking up routingtables. Whether a packet should be transmittedby the CPU transceiver module is completelydetermined by software. With the flexibilityoffered by the CPU transceiver module, it iseasy to integrate more flexible software virtualdata planes into PEARL.
Action Logic — The result of routing tablelookup is the next hop information, includingoutput card number, output port number, thedestination MAC address, and so on, which isstored in an SRAM-based table. It defines howto process the packet, so it can be considered as
Figure 2. The architecture of PEARL's hardware data plane.
MultistreamDMA
Rx engine
MultistreamDMA
Tx engineOut portscheduler
Outputqueues
MAC TxQ
MAC TxQ
MAC TxQ
MAC TxQ
MAC RxQ
MAC RxQ Headerextractor
VR 0routing table
Routing tablelookup
VR 1routing table
CPUtransceiver
VIDlookup
Mapping10-tupleto virtualrouter ID
MAC RxQ
MAC RxQ
PCIE
bus
Action logic1
Action logic
Action logic2
......
CPU action
The operations of
routing table lookup
and packet dispatch
to different virtual
machines are always
the performance
bottleneck. PEARL
offloads these two
operations into
hardware to achieve
high speed packet
forwarding.
LI2 LAYOUT 6/20/11 4:16 PM Page 73

IEEE Communications Magazine • July 201174
an action associated with each entry of the rout-ing tables. Based on the next hop information,this stage performs some decisions such as for-warding, dropping, broadcasting, decrementingtime to live (TTL), or updating MAC address.
Multi-Stream DMA Engine — To acceleratethe IO performance and greatly exploit the par-allel processing power of a multicore processor,we design a multistream high-performance DMAengine in PEARL. It can receive packets of dif-ferent virtual routers from the network card todifferent memory regions in the host, and trans-mit packets in the opposite direction via high-speed PCI Express bus. From a softwareprogrammer’s perspective, there are multipleindependent DMA engines, and the packets ofdifferent virtual routers are directed into differ-ent memory regions, which is convenient andlockless for programming. Meanwhile, we makea trade-off between flexibility and high perfor-mance of DMA transfer mechanism, and care-fully redesign the DMA engine in FPGA. TheDMA engine can transfer packets to the pre-allocated huge static buffer at contiguous memo-ry locations. It greatly decreases the number ofmemory accesses required to transfer a packet toCPU. Each packet transported between theCPU and the network card is equipped with acustom header, which is used for carrying pro-cessing information to the destination, such asthe matching results.
Output Scheduler — The egress packets sentback by the CPU are scheduled based on theiroutput port number, which is a specific field inthe custom header of the packet. Each physicaloutput port is equipped with an output queue.The scheduler puts each packet in the appropri-ate output queue for transmitting.
SOFTWARE PLATFORMOur software platform of PEARL consists ofseveral components, as shown in Fig. 3. Theseinclude vmmd, to provide the basic managementfunctions for the virtual routers and packet pro-cessing cards; nacd, to offer a uniform interface
to the underlying processing cards outside thevirtual environment; routed, to translate the for-warding rules generated by the kernel or userapplications into a uniform format in each virtu-al router, and install these rules into the TCAMof the processing cards; netio_proxy, to transmitthe packets between the physical interfaces andvirtual interfaces, and low_proxy, to dispatchpackets into low-priority virtual routers thatshare one pair of DMA Rx/Tx buffers. With dif-ferent configurations and combinations of theseprograms, PEARL can generate different typesof virtual routers to achieve flexibility.
There are two types of virtual routers in ourPEARL: high- and low-priority virtual routers.Each high-priority virtual router is assigned onepair of DMA Rx/Tx buffers and an independentTCAM space for lookup. With the high-speedlookup based on TCAM, and efficient IO chan-nels provided by the hardware, the virtual routercan achieve the maximum throughput in PEARLplatform. For low-priority virtual routers, all thevirtual routers share only one pair of DMARx/Tx buffers and they can’t utilize TCAM forlookup. The macvlan mechanism is adopted todispatch packets between multiple virtualrouters. The applications inside the low priorityvirtual routers can use the socket applicationprogramming interfaces (APIs) to capture pack-ets from the virtual interfaces. Note that eachpackets needs to go through a context switch(system calls) at least two times during transmis-sion to the user application, resulting in relative-ly low IO performance.
We take IPv4 and IPv6 as two Internet proto-cols to show how the virtual routers can easily beimplemented on PEARL.
High-Priority IPv4 Virtual Router — To cre-ate a high-priority IPv4 virtual router in ourplatform, the vmmd process first starts a newLinux container with several virtual interfaces,and collects the MAC address of each virtualinterface, installs these addresses in the underly-ing cards via the nacd process so that the hard-ware can identify the packets heading to thisvirtual router, and copy the packet into the cer-
Figure 3. Packet path in the software.
Driver
Kernel space
User space
Network cards
Applications
veth0..4tap0macvlan
netio_proxy
Plug-in
veth0..4
low_proxy
DMA Tx/Rx
naed
RegistersDMA Tx/RxDMA Tx/Rx
vmmdRouted
High-priorityvirtual router Physical machine Low-priority
virtual routerNew
protocols
The DMA engine can
transfer packets to
the pre-allocated
huge static buffer at
contiguous memory
locations. It greatly
decreases the
number of memory
accesses required
to transfer a packet
to CPU.
LI2 LAYOUT 6/20/11 4:16 PM Page 74
IEEE Communications Magazine • July 2011 75
tain DMA Tx buffer which assigned to this virtu-al router.
Then, the routed process is launched in thenew container. It extracts the routes through theNETLINK socket inside the virtual router andinstalls routes and the forwarding action in hard-ware, so the hardware can fill a little structure inthe memory to notify the netio_proxy processwhen a packet match a route in TCAM. Thenetio_proxy process delivers the packets eitherto the virtual interface or directly to the physicalinterface according to the forwarding action inmemory.
For example, most of time, normal packetswill match a route in the hardware. When thenetio_proxy receive these packets, it will directlysend them through a DMA Tx buffer. An ARPrequest packet will not match any rules in theTCAM, the netio_proxy process will deliver thispacket to the virtual interface, receive the corre-sponding ARP reply packet from the virtual inter-face, and then send it to the physical interface.
Low-Priority Virtual Router — To create low-priority virtual routers, a tap device is set up bythe vmmd process (tap0). Low priority virtualrouters are configured to share the network traf-fic of this tap device through the macvlan mecha-nism. The low_proxy process acts like a bridge,transmitting packets between DMA buffers andthe tap device in both directions. As the MACaddresses of the virtual interfaces are generatedrandomly, we can encode the MAC addresses toidentify the virtual interface from which a packetcomes. For example, we can use the last byte ofthe MAC address to identify the virtual inter-faces,: if the low_proxy process receives a packetwith source MAC address 02:00:00:00:00:00, itknows that the packet is from the first virtualinterface in one of the low-priority virtualrouters, and transmits the packet to the firstphysical interface immediately. We adopted thismethod in the low_proxy and vmmd processes,and use the second byte to identify the differentlow virtual routers. It not only saves the timeconsumed by the inefficient MAC hash lookupto determine where the packet comes from, butalso saves the space in TCAM, because all thelow priority virtual routes only need one rule inTCAM (02:*:00:00:00:*).
IPv4/IPv6 Virtual Router With Kernel For-warding — In this configuration, the routedprocess does not extract the route from the ker-nel routing table; instead, it enables the ip_for-ward options of the kernel. As a result, allpackets will match the default route in TCAMwithout the forwarding action. The netio_proxyprocess transmits all these packets into the virtu-al interfaces so that the kernel will forward thepacket instead of the underlying hardware. Thetap/tun device is used as the virtual interface.Since the netio_proxy is a user space process,each packet needs two system calls to completethe whole forwarding.
User-Defined Virtual Router — User-definepacket process procedure can be implemented asa plug-in loaded by the netio_proxy process,which makes the PEARL extensible. We opened
the basic packet APIs to users, such asread_packet(), send_packet(). Users can writetheir own process module in C and run it in theindependent virtual routers. For lightweightapplications that do not need to deal with hugeamounts of network traffic, users can also writea socket program in either high- or low-priorityvirtual routers.
EVALUATION AND DISCUSSIONWe implemented a PEARL prototype using acommon server with our specialized networkcard. The common server is equipped with aXeon 2.5GHz 64-bit CPU and 16G DDR2RAM. The OS-level virtualization techniqueLinux Containers (LXC) is used to isolate thedifferent virtual routers (VRs).
In order to demonstrate the performance andflexibility of PEARL, our implementation isevaluated in three different configurations: ahigh-performance IPv4 VR, a kernel-forwardingIPv4/IPv6 VR, and IPv4 forwarding in a low-pri-ority VR.
We conducted four independent subnetworkswith Spirent TestCenter to measure the perfor-mance of the three configurations in one to fourVRs. Three different packet lengths (64, 512,and 1518) were used (for IPv6 packet, the pack-et length is 78, 512, and 1518.; 78 bytes is theminimal IPv6 packet length supported by Test-Center).
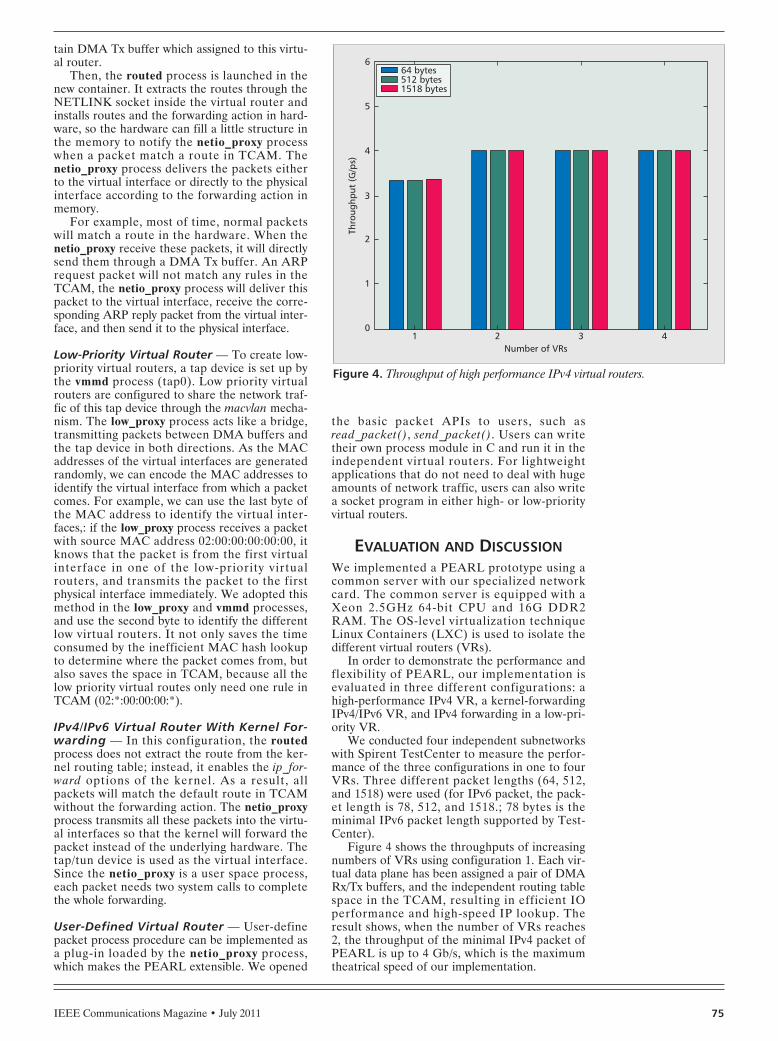
Figure 4 shows the throughputs of increasingnumbers of VRs using configuration 1. Each vir-tual data plane has been assigned a pair of DMARx/Tx buffers, and the independent routing tablespace in the TCAM, resulting in efficient IOperformance and high-speed IP lookup. Theresult shows, when the number of VRs reaches2, the throughput of the minimal IPv4 packet ofPEARL is up to 4 Gb/s, which is the maximumtheatrical speed of our implementation.
Figure 4. Throughput of high performance IPv4 virtual routers.
Number of VRs1
1
0
Thro
ughp
ut (
G/p
s)
2
3
4
5
6
2 3 4
64 bytes512 bytes1518 bytes
LI2 LAYOUT 6/20/11 4:16 PM Page 75
IEEE Communications Magazine • July 201176
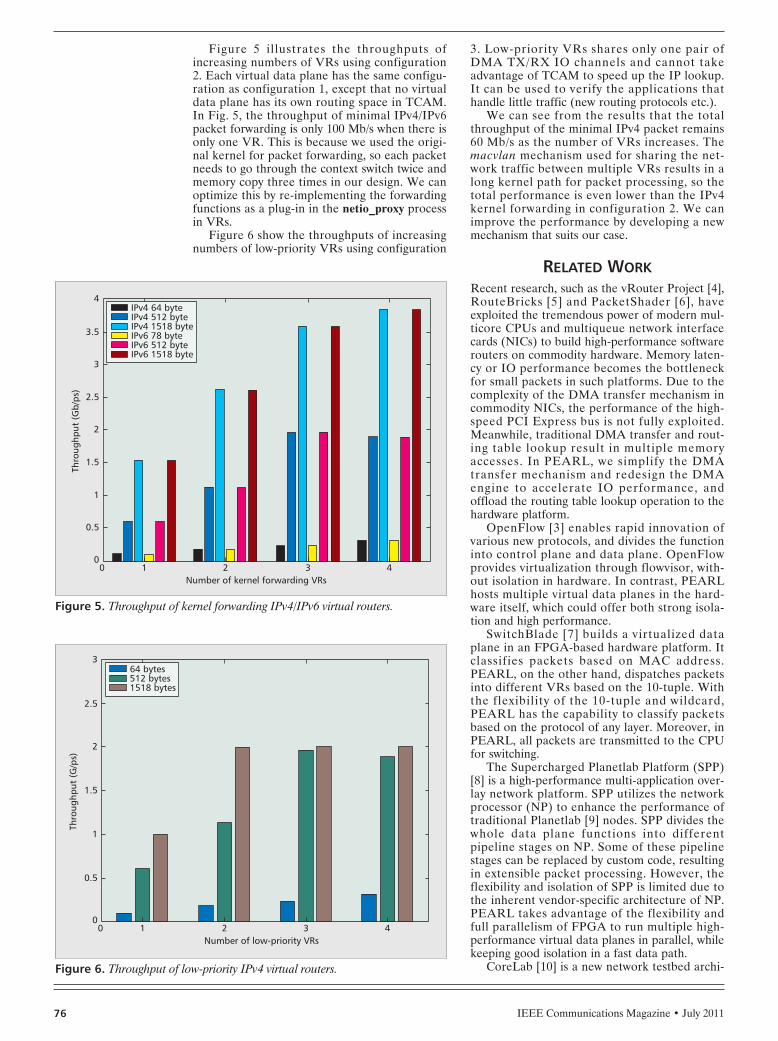
Figure 5 illustrates the throughputs ofincreasing numbers of VRs using configuration2. Each virtual data plane has the same configu-ration as configuration 1, except that no virtualdata plane has its own routing space in TCAM.In Fig. 5, the throughput of minimal IPv4/IPv6packet forwarding is only 100 Mb/s when there isonly one VR. This is because we used the origi-nal kernel for packet forwarding, so each packetneeds to go through the context switch twice andmemory copy three times in our design. We canoptimize this by re-implementing the forwardingfunctions as a plug-in in the netio_proxy processin VRs.
Figure 6 show the throughputs of increasingnumbers of low-priority VRs using configuration
3. Low-priority VRs shares only one pair ofDMA TX/RX IO channels and cannot takeadvantage of TCAM to speed up the IP lookup.It can be used to verify the applications thathandle little traffic (new routing protocols etc.).
We can see from the results that the totalthroughput of the minimal IPv4 packet remains60 Mb/s as the number of VRs increases. Themacvlan mechanism used for sharing the net-work traffic between multiple VRs results in along kernel path for packet processing, so thetotal performance is even lower than the IPv4kernel forwarding in configuration 2. We canimprove the performance by developing a newmechanism that suits our case.
RELATED WORKRecent research, such as the vRouter Project [4],RouteBricks [5] and PacketShader [6], haveexploited the tremendous power of modern mul-ticore CPUs and multiqueue network interfacecards (NICs) to build high-performance softwarerouters on commodity hardware. Memory laten-cy or IO performance becomes the bottleneckfor small packets in such platforms. Due to thecomplexity of the DMA transfer mechanism incommodity NICs, the performance of the high-speed PCI Express bus is not fully exploited.Meanwhile, traditional DMA transfer and rout-ing table lookup result in multiple memoryaccesses. In PEARL, we simplify the DMAtransfer mechanism and redesign the DMAengine to accelerate IO performance, andoffload the routing table lookup operation to thehardware platform.
OpenFlow [3] enables rapid innovation ofvarious new protocols, and divides the functioninto control plane and data plane. OpenFlowprovides virtualization through flowvisor, with-out isolation in hardware. In contrast, PEARLhosts multiple virtual data planes in the hard-ware itself, which could offer both strong isola-tion and high performance.
SwitchBlade [7] builds a virtualized dataplane in an FPGA-based hardware platform. Itclassifies packets based on MAC address.PEARL, on the other hand, dispatches packetsinto different VRs based on the 10-tuple. Withthe flexibility of the 10-tuple and wildcard,PEARL has the capability to classify packetsbased on the protocol of any layer. Moreover, inPEARL, all packets are transmitted to the CPUfor switching.
The Supercharged Planetlab Platform (SPP)[8] is a high-performance multi-application over-lay network platform. SPP utilizes the networkprocessor (NP) to enhance the performance oftraditional Planetlab [9] nodes. SPP divides thewhole data plane functions into differentpipeline stages on NP. Some of these pipelinestages can be replaced by custom code, resultingin extensible packet processing. However, theflexibility and isolation of SPP is limited due tothe inherent vendor-specific architecture of NP.PEARL takes advantage of the flexibility andfull parallelism of FPGA to run multiple high-performance virtual data planes in parallel, whilekeeping good isolation in a fast data path.
CoreLab [10] is a new network testbed archi-
Figure 5. Throughput of kernel forwarding IPv4/IPv6 virtual routers.
Number of kernel forwarding VRs10
0.5
0
Thro
ughp
ut (
Gb/
ps)
1
1.5
2
2.5
3
3.5
4
2 3 4
IPv4 64 byteIPv4 512 byteIPv4 1518 byteIPv6 78 byteIPv6 512 byteIPv6 1518 byte
Figure 6. Throughput of low-priority IPv4 virtual routers.
Number of low-priority VRs10
0.5
0
Thro
ughp
ut (
G/p
s)
1
1.5
2
2.5
3
2 3 4
64 bytes512 bytes1518 bytes
LI2 LAYOUT 6/20/11 4:16 PM Page 76

IEEE Communications Magazine • July 2011 77
tecture supporting a full-featured developmentenvironment. It enables excellent flexibility byoffering researchers a fully virtualized environ-ment on each node for any arrangement.PEARL can support similar flexibility in thesoftware data path. Meanwhile, PEARL offers ahigh-performance hardware data path for per-formance-critical virtual network applications.
CONCLUSIONSWe aim at flexible routers to bridge the gapbetween new Internet protocols and practicaltest and deployment. To this end, this work pre-sents a programmable virtual router platform,PEARL. The platform allows users to easilyimplement new Internet protocols and run mul-tiple isolated virtual data planes concurrently. APEARL router consists of a hardware data planeand a software data plane with DMA engines forpacket transmission. The hardware data plane isbuilt on top of an FPGA-based packet process-ing card with TCAM embedded. The card facili-tates fast packet processing and IO virtualization.The software plane is built by a number of mod-ular components and provides easy programinterfaces. We have implemented and evaluatedthe virtual routers on PEARL.
ACKNOWLEDGMENTThis work was supported by the National BasicResearch Program of China under grant no.2007CB310702, the National Natural ScienceFoundation of China (NSFC) under grant no.60903208, the NSFC-ANR Agence Nationale deRecherche, France) under grant no.61061130562, and the Instrument DevelopingProject of the Chinese Academy of Sciencesunder grant no. YZ200926.
REFERENCES[1] V. Jacobson et al., “(PARC) Networking Named Con-
tent,” ACM CoNEXT 2009, Rome, Dec. 2009.[2] M. Handley, O. Hodson, E. Kohler, “XORP: an Open
Platform for Network Research,” ACM SIGCOMMComp. Commun., vol. 33, issue 1, Jan. 2003.
[3] N. McKeown et al., “OpenFlow: Enabling Innovation inCampus Networks,” Comp. Commun. Rev., vol. 38, Apr.2008, pp. 69–74.
[4] N. Egi et al., “Towards High Performance VirtualRouters on Commodity Hardware,” Proc. 2008 ACMCoNEXT Conf., Madrid, Spain, 2008.
[5] M. Dobrescu et al., “RouteBricks: Exploiting Parallelismto Scale Software Routers,” Proc. ACM SIGOPS 22ndSymp. Op. Sys. Principles, Big Sky, Montana, 2009.
[6] S. Han et al., “PacketShader: a GPU-Accelerated Soft-ware Router,” ACM SIGCOMM Comp. Commun. Rev.,vol. 40, 2010, pp. 195–206.
[7] M. Anwer et al., “SwitchBlade: A Platform for RapidDeployment of Network Protocols on ProgrammableHardware,” ACM SIGCOMM Comp. Commun. Rev., vol.40, 2010, pp. 183–94.
[8] J. Turner et al., “Supercharging PlanetLab — A High Perfor-mance, Multi-Application, Overlay Network Platform,”ACM SIGCOMM ’07, Kyoto, Japan, Aug. 27–31, 2007.
[9] B. Chun et al., “Planetlab: an Overlay Testbed forBroad-Coverage Services,” ACM SIGCOMM ’03, Karl-sruhe, Germany, Aug. 25–29, 2003.
[10] CoreLab, http://www.corelab.jp/
BIOGRAPHIESGAOGANG XIE ([email protected]) received a Ph.D. degree incomputer science from Hunan University in 2002. He is aprofessor at the Institute of Computing Technology (ICT),Chinese Academy of Sciences (CAS). His research inter-ests include future Internet architecture, programmablevirtual router platforms, and Internet measurement andmodeling.
PENG HE ([email protected]) received his B.S. degree inelectronic and information engineering from HuazhongUniversity of Science and Technology in 2004. He is nowpursuing a Ph.D. degree in computer architecture at theICT, CAS. His research interests include high-performancepacket processing and virtual router design.
HONGTAO GUAN ([email protected]) is currently anassistant professor of ICT, CAS. His research interestsinclude visualization technology of computer networks androuters. He studied computer science at Tsinghua Universi-ty from 1999 to 2010 and obtained B.E. and Ph.D. degrees.He took part in the BitEngine12000 project from 2002 to2005, which was the first IPv6 core router in China.
ZHENYU LI ([email protected]) received a Ph.D. degree fromICT/CAS in 2009, where he serves as an assistant professor.His research interests include future Internet design, P2Psystems, and online social networks.
YINGKE XIE ([email protected]) received his Ph.D. degree fromICT, CAS, where he serves as an associate professor. Hisresearch interests include high-performance packet pro-cessing, reconfigurable computing, and future networkarchitecture.
LAYONG LUO ([email protected]) is currently workingtoward his Ph.D. degree at ICT, CAS. He is currently aresearch assistant in the Future Internet Research Group ofICT. His research interests include programmable virtualrouter, reconfigurable computing (FPGA), and network vir-tualization.
JIANHUA ZHANG ([email protected]) received his B.S.and M.S. from University of Science & Technology Beijing,China, in 2006 and 2009, respectively. He is currently aPh.D. student at ICT, CAS. His research interest is in thefuture Internet.
YONGGONG WANG ([email protected]) received hisB.S. and M.S. from Xidian Univiserty, Xi’an, China, in 2005and 2008, respectively. He is currently a Ph.D. student atICT, CAS. His research interest is in the future Internet.
KAVÉ SALAMATIAN ([email protected]) is a profes-sor at the University of Savoie. His main areas of researchare Internet measurement and modeling and networkinginformation theory. He was previously a reader at Lancast-er University, United Kingdom, and an associate professorat Université Pierre et Marie Curie. He graduated in 1998from Paris SUD-Orsay University, where he worked on jointsource channel coding applied to multimedia transmissionover Internet for his Ph.D. He is currently a visiting profes-sor at the Chinese Academy of Science.
PEARL takes
advantage of the
flexibility and full
parallelism of FPGA
to run multiple
high-performance
virtual data planes in
parallel, while
keeping good
isolation in fast
data path.
LI2 LAYOUT 6/20/11 4:16 PM Page 77