patterns of usage a window to language cognition -...
TRANSCRIPT

Patterns of usage – A window to language cognition
Galit W. Sassoon
Bar Ilan University, Ramat Gan

Patterns of usage – A window to language cognition
1. Introduction (8)
2. ‘Small’ balanced & annotated corpora (15)
3. The magic of large corpora (7)

1. Introduction

Studying patterns of usage
• Corpus linguistics concerns with the usage patterns as revealed in corpora: collections of naturally occurring uses of language, written texts and/or transcriptions of recorded speech.
• Chomsky's distinction between competence and performance
• Competence: Universal Grammar – A set of rules and parameters which generates an infinite number of
sentences: Those and only those we judge acceptable.
– UG is autonomous: independent of external—conceptual, cognitive, communicative, or social—factors.
• Performance: Language use, language behavior.
• So why study corpora??

Studying patterns of usage
• Provides a (relatively) objective view of language
• Reveals issues not accessible through introspection
• Can address almost any language aspect (syntax, semantic, pragmatics, psycholinguistics, sociolinguistics …)
• Very specific agendas: – male versus female usage of tag questions
– children's acquisition of irregular past participles
– counterfactual statement error patterns of Japanese students.
• Reveals contextual factors influencing variability in language use. – contextual preferences/ distribution of synonyms like begin/start or big/large/great.
– Adverbs/ aspectual verb forms in speaking/writing, newspapers/fiction
– To give Mary the book / the book to Mary
• Example:
Most vs. More than half (Solt 2014)

Studying patterns of usage • Diachronic development: Corpora from different times.
Has the frequency of a particular word/construction/meaning increased/decreased over time?
• Sociolinguistics: Corpora from different populations/genres.
Does usage vary by gender/ age/ social identity/ dialect/ register (= a variety of language used for a particular type of situations)
– fiction, academic prose, newspapers, blogs, casual phone conversations, …
– sub-registers within academic prose: scientific texts, literary criticism, ...
Language often behaves differently according to the register/speaker type, each with some unique patterns and rules.
• Acquisition: Child speech; child oriented speech.
• Aphasia: Language usage after brain damage
• …

Balanced vs. Large corpora • http://en.wikipedia.org/wiki/Corpus_linguistics:
– The LOB Corpus (1960s British English),
– Kolhapur (Indian English), Wellington (New Zealand English),
– Australian Corpus of English (Australian English),
– The Frown Corpus (early 1990s American English),
– The FLOB Corpus (1990s British English),
– International Corpus of English,
– British National Corpus (a 100 million word collection of a range of spoken and written texts, created in the 1990s by a consortium of publishers, universities Oxford and Lancaster),
– The British Library
– The American National Corpus
– Corpus of Contemporary American English (1990–present; 400+ million words; now available through a web interface).
– Wordnet: A large dictionary encoding synonym, antonym and subtype relations between words.
– The wordsketch engine: Collocates of words counted separately for each semantic-syntactic relation.
– Google e-books; All the books ever written
– The web
The corpus has to fit your purpose / research question

Annotation: Information added to the corpus
• Lemmatizing and POS tagging (annotating):
• Works work(V, SG, 3rdP, present),
• worked work(V, past)
• Lemmatizing is important if we are to extract
subcategorization frames of a verb considering
all its forms together, that is, searching by its
lemma.

Methods for annotation (classification by syntactic/ semantic category; as errors, …)
• Automatic classification (typically, in large corpora):
Some software programs searches corpora and lists the results.
You can program a software to classify data according to your criteria.
• Manual classification (in small corpora):
Especially useful for semantics & pragmatics, where automatic tools produce more noise than results.
• Classification using participants
Ask speakers for their judgment and follow the statistics.

Any level of linguistic information can be annotated
• The Andersen-Forbes database of the Hebrew Bible, is developed since the 1970s, in which every clause is represented with up to 7 levels of syntax, and every segment tagged with 7 information fields.
• The Quranic Arabic Corpus is annotated with multiple layers including morphological segmentation, part-of-speech tagging, and syntactic analysis (using dependency grammar).
-Andersen, Francis I.; Forbes, A. Dean (2003), "Hebrew Grammar Visualized: I. Syntax", Ancient Near Eastern Studies 40: 43–61 .
-Dukes, K., Atwell, E. and Habash, N. 'Supervised Collaboration for Syntactic Annotation of Quranic Arabic'. Language Resources and Evaluation Journal. 2011..
• The card corpus (Potts 2011?): Pragmatic annotation.

• Stanley Dubinsky and Paul Reed: Double Modal auxiliary verb distribution in various dialects of southern American English (1753 tokens).
• We need to know the frequency of each modal separately to make sense of this table!
Results: Frequencies – out of what?
First\Second Can Could Might Oughta Should Will Would
Can 0 0 2 0 0 0 1 3
Could 0 0 5 0 0 0 0 5
May 84 46 3 5 21 10 15 186
Might 171 883 1 74 60 15 148 1360
Ought to 0 2 0 0 0 1 1 4
Shall 0 0 0 0 0 0 0 0
Should 1 0 0 18 0 0 0 19
Useta 0 131 1 0 0 0 39 171 Will 4 0 1 0 0 0 0 5
Would 0 2 6 0 0 0 0 8
260 1064 19 97 81 26 204

2. A ‘small’ balanced corpus
• The Corpus of Contemporary American English (COCA; Mark Davies, Brigham
Young University) is the largest freely-available corpus of English, and the
only large and balanced corpus of American English.
• COCA is used by tens of thousands of users every month (linguists, teachers,
translators, and other researchers).
• COCA is also related to other large corpora.
• more than 450 million words of text
• equally divided to spoken, fiction, popular magazines, newspapers, and
academic texts.
• 20 million words each year from 1990-2012, updated regularly.
http://corpus.byu.edu/coca/

Searching COCA

Searching COCA
[j*] eyes to find two word strings composed of eyes preceded by an adjective.
[beat].[v*] to find just the verbal uses of beat.
[=clever] to find synonyms (intelligent, wise,…)
• Interface allows you to search for exact words/phrases, lemmas, part of speech,
surrounding words (collocates; e.g. all nouns somewhere near faint, all
adjectives near woman, …), synonyms.
• You can limit searches by frequency, or compare frequencies by genre, sub-
genres (or domain: movie scripts, sports magazines, …) or time (different years
1990-present).
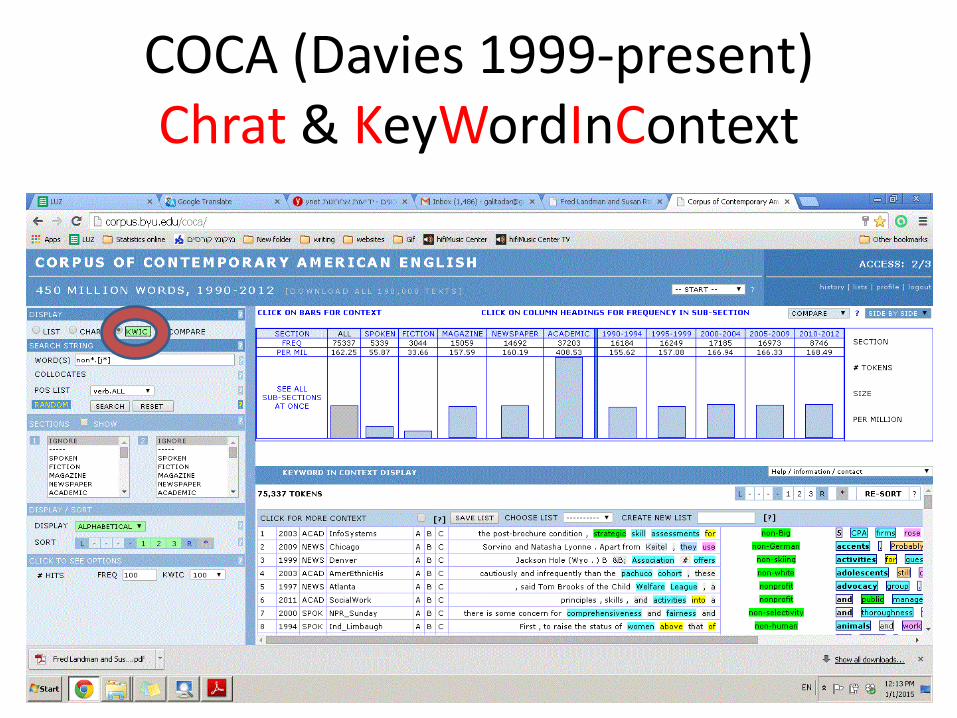
COCA (Davies 1999-present) Chrat & KeyWordInContext

COCA (Davies 1999-present) Different registers
-Coca searches ‘un-’ and ‘non-’
in spoken vs. academic genres
-Similarly for adverbs: ‘a bit’, ‘a
little’ vs. ‘slightly’, ‘somewhat’

COCA (Davies 1999-present) Sociology; Sociolinguistics
Corpora of dialogues/ conversations:
-Turn taking
-Who speaks longer
-Who interrupts, who waits politely to her turn
-Who uses which speech acts (commands, requests, statements, questions)
Corpus usage in education: Second language teaching

Corpus usage in education: Second language teaching
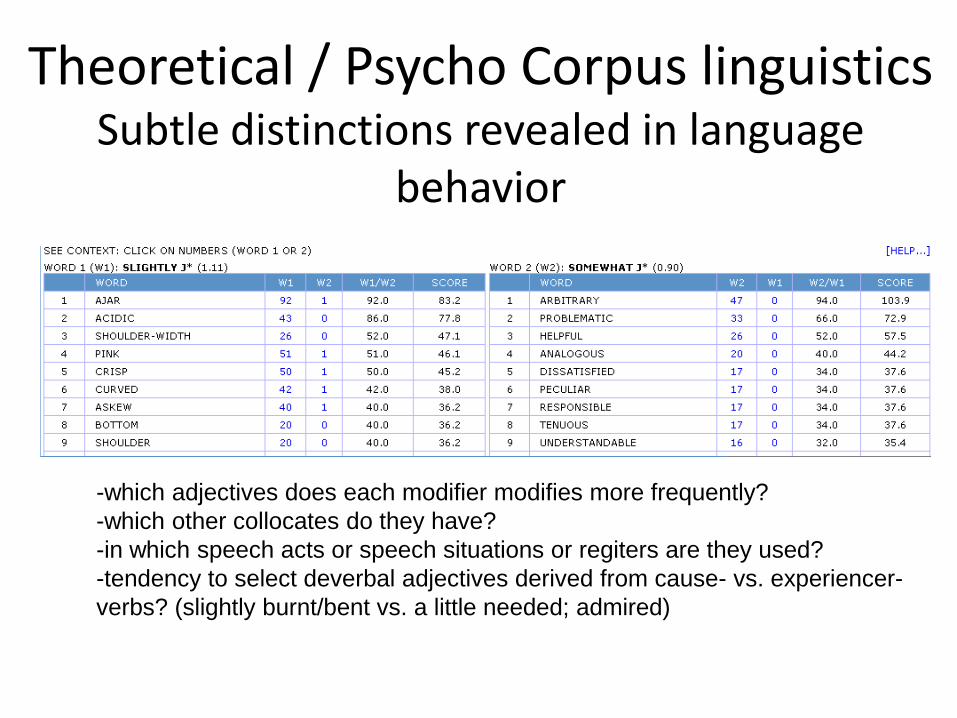
Theoretical / Psycho Corpus linguistics Subtle distinctions revealed in language
behavior
-which adjectives does each modifier modifies more frequently?
-which other collocates do they have?
-in which speech acts or speech situations or regiters are they used?
-tendency to select deverbal adjectives derived from cause- vs. experiencer-
verbs? (slightly burnt/bent vs. a little needed; admired)

Acquisition & Atypical speech
http://childes.psy.cmu.edu MacWhinney, B. (2000). The CHILDES Project: Tools for analyzing talk. Third
Edition. Mahwah, NJ: Lawrence Erlbaum Associates.
The biggest collection of data on child language & tools for its research
• Transcripts, audio, and video materials In over 20 languages;
• 130 different corpora, all of which are publicly available.
• Spontaneous speech, narratives
• Part of the larger corpus TalkBank, which includes data from: • Aphasia
• Dementia
• SLI
• Second language acquisition
• Conversation analysis
• Classroom language learning.

The availability of corpora and tools to search them changed the theoretical view of many:
Revealed high overlap between child and caregiver production
suggestive of learning of concrete items as opposed to setting abstract parameters. Abstract categories only occur later
• Parisse & Le Normand (2000) studied the lexical overlap between child and adult language.
• More specifically, they compared 33 hours of speech produced by Philippe and the adults he is talking to (data taken from the Léveillé database in CHILDES).
• “72% of the bi-words [i.e. two consecutive words] produced by Philippe at 2;1 (in type, and 82% in tokens) correspond exactly to adult bi-words”

The availability of corpora and tools to search them changed the theoretical view of many:
• The Léveillé database in CHILDES

Limitations
• Linguistic analyses that use the methods and tools of corpus linguistics do not represent the entire language.
• Low frequency words/ constructions reveal interesting patterns of use, but you need to work harder to find data.

Deb Roy’s child’s lexicon’s development
http://www.ted.com/talks/deb_roy_the_birth
_of_a_word#t-363391
The birth of a word

2. The Magic of Large corpora

Studying patterns of usage • Large corpora:
Consist of millions or even billions of words.
• Computational corpus linguistics
– Use of computers to determine what rules govern language use.
– Various software programs and analytical tools allow the researchers to analyze a large number of parameters simultaneously and very fast.
– Practical applications: NLP ( enabling computers to interact with humans verbally), Machine translation ( the use of software to translate text or speech from one NL to another.); sense disambiguation; question answering help programs; speaking cellphones, robots; …

The web is the largest corpus • Problems:
– Non native speech
– Dependency on search engines such as Google which choose examples in non random ways.
– Repeated examples
– Non reliable estimations of counts of examples
– You don’t know who the speaker is (gender, age, languages, …)
– No annotations [except natural ones]
– …
• Advantages: – The web is big in size
– Web frequencies and judgments (Lapata & Keller 2003):
• Adj + N combinations extracted from the BNC vs. the web (using
google and altavista) were each compared to plausibility evaluations.
• Higher correlations of plausibility judgments with web searches than
BNC searches (between 0.6 to 0.7, vs. 0.5 coefficients)

Searching the internet Hebrew:
1. Ktiv male/xaser ( גבה, גבוה )
2. Problem with similarly written words (tall/eyebrow)
3. The problem of non native speakers is perhaps less pronounced
(e.g., fewer Chinese speakers that learn Hebrew as a second
language, as compared to English).
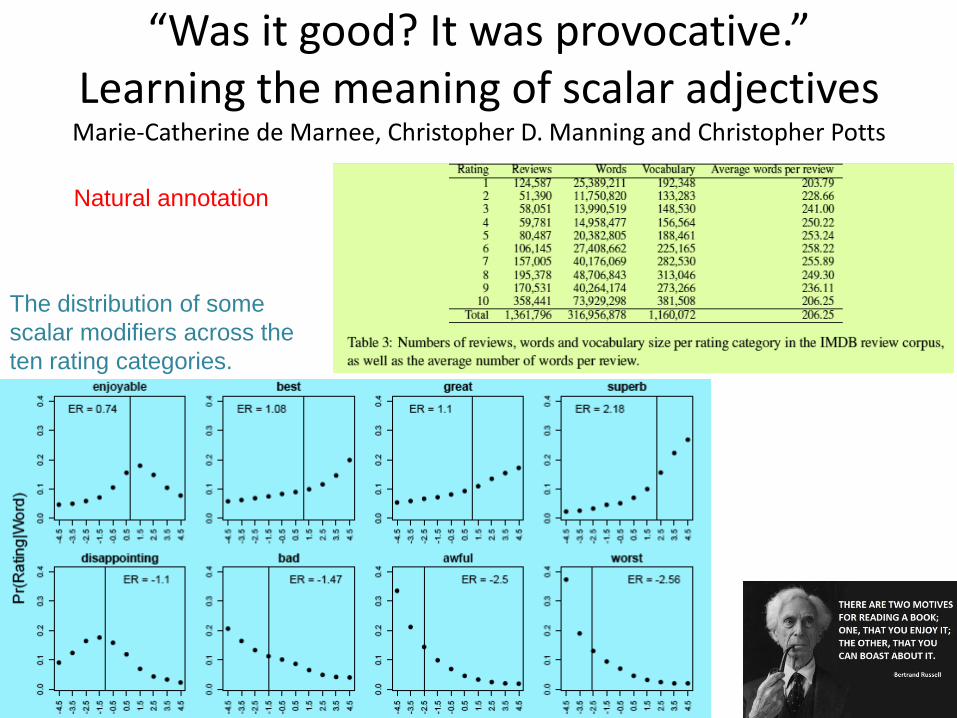
“Was it good? It was provocative.” Learning the meaning of scalar adjectives
Marie-Catherine de Marnee, Christopher D. Manning and Christopher Potts
The distribution of some
scalar modifiers across the
ten rating categories.
Natural annotation
