part-of-speech tagging - resource centre for indian ... · what is part of speech? a category of...
TRANSCRIPT

Part-of-Speech Tagging
Diptesh Kanojia
Pushpak Bhattacharyya

What is Part of Speech?
A category of words which have similar grammatical properties
Nouns → denotes Abstract/real things
Verbs → denotes action
Adjective → modifies noun
Adverb → qualifies action (manner, time, place, etc.)
Pronoun → shorthand for some nouns referred to
Preposition → indicate spatial or temporal relations
Conjunction → join phrases, clauses and sentences
Interjection → oh, alas, etc.

Open class vs closed class
Open class: New words can be added to this set
Nouns, verbs, adjectives, adverbs are open class
Closed class: New words are rarely added and there are few of these
Conjunctions, prepositions, pronouns, interjections are closed class

How many Parts of speech are there?
Depends on who you ask?
First a few questions -
What is POS for can, not, should, will, etc. ?
What is the POS tag for घरासमोरचा → Noun, Preposition, Both ??

Designing the set of parts of speech is important
This set is called the tagset

Penn Treebank Tagset
One of the most popular tagsets

Bureau of Indian Standards (BIS) Tagset for Indian languages
Hierarchical
Tagset

Twitter POS tagset
Twitter language
specific tags

Why is it important to know POS of a word?
Basic building block for Natural Language Understanding
Following tasks require POS as input:
Chunking
Parsing
… and then the whole stack is built on this

POS Tagging in NLP applications
POS tagging is relatively easier to to than full language understanding
Statistical POS taggers require less data compared to other tasks like parsing
For NLP applications, even POS information is very useful:
Sentiment Analysis
Sarcasm Detection
Named Entity Recognition
Some Information Extraction tasks

What is Part of Speech (POS) tagging?

Is it not enough to look up a dictionary and markup
POS tags?Ace can be noun too.
e.g. Nadal served an aceBatsman modifies Arvinda De Silva, can be J

Statistical POS tagging

Called the “Noisy Channel Model”
Y has been converted to X while passing the message through a channel (probably with some
errors)
Task is to recover Y given X
A very core abstraction in machine learning

Independence Assumptions to simplify things ...
Markov assumption:
current tag depends on
previous k tags only
This is the heart of the design of any ML system → the modelling
Lexical independence
assumption: Word
depends on its POS
tag! - strange!!
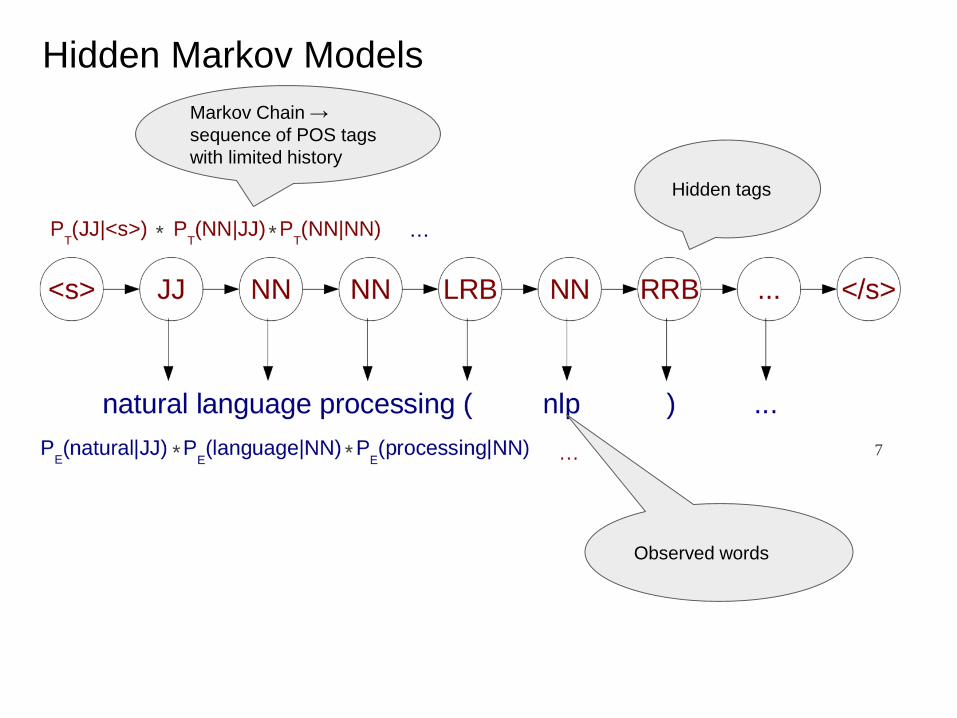
Hidden Markov Models
Hidden tags
Observed words
Markov Chain →
sequence of POS tags
with limited history

Training HMM models
Goal: Learn a “model” from this corpus, so new unseen sentences can be tagged
What does learning a model mean?
Learning the values of:
P(yi|yi-1) → transition probabilities
P(xi|yi) → emission probabilities
Input: POS tagged corpus of many sentences
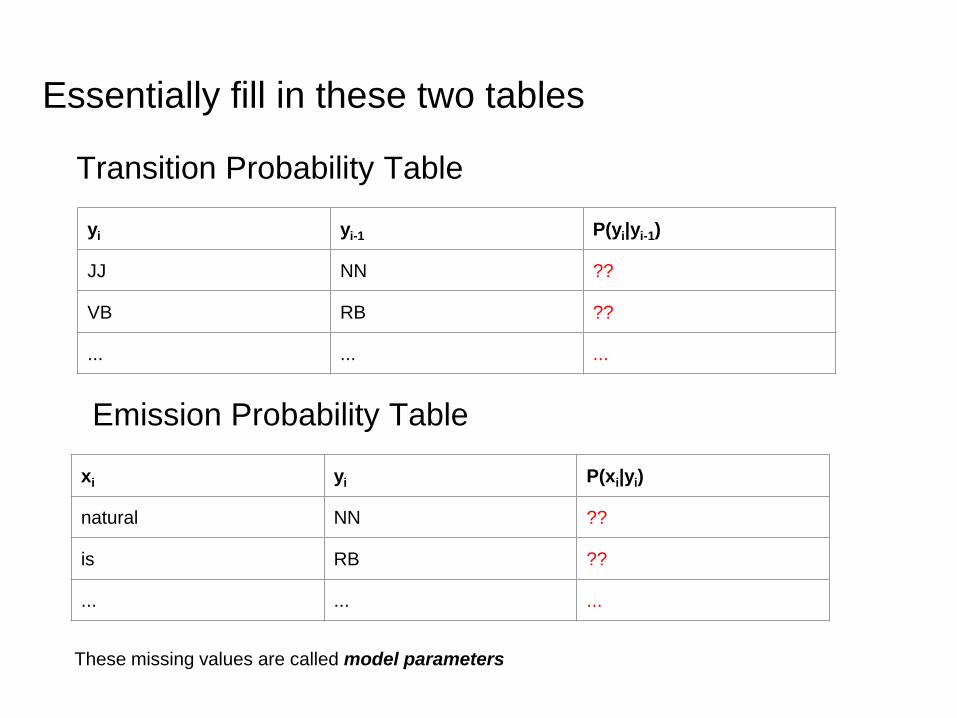
Essentially fill in these two tables
yi yi-1 P(yi|yi-1)
JJ NN ??
VB RB ??
... ... ...
Transition Probability Table
Emission Probability Table
xi yi P(xi|yi)
natural NN ??
is RB ??
... ... ...
These missing values are called model parameters

Given a tagged corpus, it’s easy to find the parameters

Except, not all words occur in the training corpus?
How do we estimate emission probabilities for
these?
We need to do some “smoothing”
What is that ???

Smoothing
Set aside some probability mass for unseen words
For unseen words PML= 0, so its emission probability will be:
This is the simplest smoothing method … not the best one .. there are many other
better ones
Not for today though ...

Why is smoothing not very important for transition
probabilities?
Because tagset is generally small ...

Now, we have trained the model ….
How do we find the POS tags for a new sentence?
This problem is called “decoding”
We use the ‘Viterbi Algorithm’
You will encounter this guy, Andrew Viterbi, everywhere in machine learning

First, visualize a graph of possible POS tags for input sentence

Find the best path → path with maximum P(Y|X)
This gives the best POS tag for the sentence

Trying all possible combinations is very costly … you have to
evaluate L|V| paths
where L: number of words
|V|: size of POS tagset
For a 40 tagset and sentence of 10 words, you have to
evaluate 1040 possible sequences

Viterbi Algorithm to the rescue ….
It is just a dynamic programming algorithm that exploits the
optimal substructure of the problem
Key Property:
If the best tag sequence at position k contains the tag T at
position k-1 …
then the sequence of positions 1 to k-1 is the best sequence
ending in T

This means if you have found best sequence till position k-
1 ending in every POS tag, it is efficient to do the same for
position k
Done in two steps:
● Forward step: Find the best value through the graph
● Backward step: Backtrack to find the best path




Backward step
During forward step, keep track of the best edge at every computation
Now, you just have to backtrack from the final best tag at position (l+1) to find the best POS sequence

Acknowledgements
Graham Neubig: http://www.phontron.com/slides/nlp-programming-en-04-hmm.pdf

Thank You!Questions?