parallel programming for multicore and distributed systems...
TRANSCRIPT

Intro Multicore Distributed Conclusion
Parallel Programming for Multicore andDistributed Systems
10th Summer School in Statistics for Astronomers
Pierre-Yves Taunay
Research Computing and Cyberinfrastructure224A Computer Building
The Pennsylvania State UniversityUniversity Park
June 2014
1 / 67

Intro Multicore Distributed Conclusion
Introduction
2 / 67

Intro Multicore Distributed Conclusion
Objectives
1. Have a good understanding of1.1 Shared memory programs executed on multicore machines, and1.2 Distributed programs executed on multiple multicore machines
2. Get familiar with programming syntax for2.1 Shared memory programming, and2.2 Distributed programming
3 / 67

Intro Multicore Distributed Conclusion
Recap from last session – 1/2
I Multicore programming↪→ Possible to have 2 or more cores in a processor cooperate
through threads↪→ Thread libraries: OpenMP, POSIX, Boost
I Distributed programming↪→ Multiple compute nodes are cooperating↪→ MPI for communication paradigm
4 / 67

Intro Multicore Distributed Conclusion
Recap from last session – 2/2
Shared memory Distributed memoryLimited to 1 machine No limit
1 process = multiple cores 1 process = 1 coreMultiple cores can Memory local
access same memory to processor coreData exchange Data exchange
through memory bus through network
5 / 67

Intro Multicore Distributed Conclusion
Disclaimers
I C for multicore programmingI C for distributed programming
6 / 67

Intro Multicore Distributed Conclusion
Multicore programming withOpenMP
7 / 67
Intro Multicore Distributed Conclusion
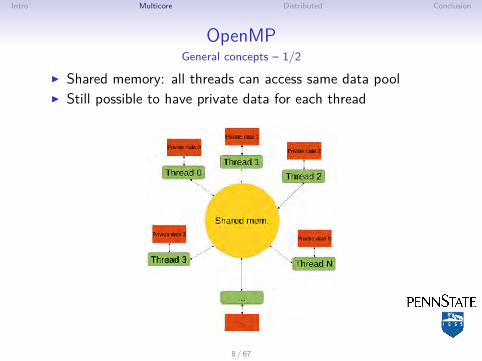
OpenMPGeneral concepts – 1/2
I Shared memory: all threads can access same data poolI Still possible to have private data for each thread
8 / 67

Intro Multicore Distributed Conclusion
OpenMPGeneral concepts – 1/2
9 / 67

Intro Multicore Distributed Conclusion
OpenMPGeneral concepts – 2/2
I Fork-join model of execution
I Directive based: give “hints” to the compiler
10 / 67

Intro Multicore Distributed Conclusion
OpenMPContent
11 / 67

Intro Multicore Distributed Conclusion
OpenMPCompiling a program
I Intel compiler: -openmp flagI GCC: -fopenmp flag
gcc -fopenmp -O3 myprogram.c -o myprogram
12 / 67

Intro Multicore Distributed Conclusion
OpenMPRunning a program
I Environment variables are set to control programI Number of threads to launch: OMP_NUM_THREADS
export OMP_NUM_THREADS = 4
setenv OMP_NUM_THREADS 4
13 / 67

Intro Multicore Distributed Conclusion
OpenMPTiming parts of a program
I Function omp_get_wtime()
1 double t i c = omp_get_wtime ( ) ;2 // Code to t ime . . .3 double toc = omp_get_wtime ( ) ;4 p r i n t f ( " Re s u l t : %f \n" , toc−t i c ) ;
14 / 67

Intro Multicore Distributed Conclusion
Parallel control structure
I In a parallel block, code is executed by all threads
1 #inc lude <s t d i o . h>2 #inc lude <omp.h>3
4 i n t main ( ) {5 #pragma omp p a r a l l e l6 p r i n t f ( " He l l o wor ld ! \n" ) ;7
8 re tu rn 0 ;9 }
15 / 67

Intro Multicore Distributed Conclusion
Multicore programming withOpenMPWork sharing
16 / 67

Intro Multicore Distributed Conclusion
Work sharingfor directive – 1/3
I Multiple ways to share workI Simple “for” loop: iterations are distributed amongst threads
1 #pragma omp p a r a l l e l2 #pragma omp f o r3 f o r ( i n t i = 0 ; i<N; i++)4 a [ i ] = b [ i ] + c [ i ] ;
17 / 67

Intro Multicore Distributed Conclusion
Work sharingfor directive – 2/3
I Additional options:↪→ reduction: to perform a reduction↪→ ordered: iterations are executed in same order as a serial core↪→ nowait: threads do not synchronize at end of loop
1 #pragma omp p a r a l l e l2 #pragma omp f o r r e d u c t i o n (+: out )3 f o r ( i n t i = 0 ; i<N; i++)4 out = out + a [ i ] ;
18 / 67

Intro Multicore Distributed Conclusion
Work sharingfor directive – 3/3
1 #pragma omp p a r a l l e l2 {3 #pragma omp f o r nowa i t4 f o r ( i n t i = 0 ; i<N; i++)5 c [ i ] = a [ i ] + b [ i ] ;6
7 #pragma omp f o r8 f o r ( i n t i = 0 ; i<N; i++)9 z [ i ] = x [ i ] + y [ i ] ;
10 } /∗ End o f p a r a l l e l ∗/
19 / 67

Intro Multicore Distributed Conclusion
Work sharingsections directive
I Distributes a set of structured blocks amongst a “team” ofthreads
I Does not have to have iterations, as in the for directiveI Synchronization is implied at the end of sectionsI Stand-alone section directives can be nested in a sectionsI Each section is executed once by a thread.
20 / 67

Intro Multicore Distributed Conclusion
Work sharingsections directive
1 #pragma omp p a r a l l e l2 {3 #pragma omp s e c t i o n s nowa i t4 {5 #pragma omp s e c t i o n6 f o r ( i n t i = 0 ; i<N; i++)7 c [ i ] = a [ i ] + b [ i ] ;8
9 #pragma omp s e c t i o n10 p r i n t f ( " He l l o !\ n" ) ;11 } /∗ End o f s e c t i o n s ∗/12 } /∗ End o f p a r a l l e l ∗/
21 / 67

Intro Multicore Distributed Conclusion
Work sharingsingle directive
I Single: only one thread executes that block
1 #pragma omp p a r a l l e l2 {3 #pragma omp s i n g l e4 {5 p r i n t f ( " S t a r t i n g o p e r a t i o n s . . . \ n" ) ;6 } /∗ End o f s i n g l e ∗/78 #pragma omp s e c t i o n s nowa i t9 {
10 #pragma omp s e c t i o n11 f o r ( i n t i = 0 ; i <N; i ++)12 c [ i ] = a [ i ] + b [ i ] ;1314 #pragma omp s e c t i o n15 f o r ( i n t i = 0 ; i <N; i ++)16 z [ i ] = x [ i ] + y [ i ] ;17 } /∗ End o f s e c t i o n s ∗/18 } /∗ End o f p a r a l l e l ∗/
22 / 67

Intro Multicore Distributed Conclusion
Parallel work sharing
I Combine directives
1 #pragma omp p a r a l l e l f o r2 f o r ( i n t i = 0 ; i < N ; i++)3 c [ i ] = a [ i ] + b [ i ] ;
23 / 67

Intro Multicore Distributed Conclusion
Multicore programming withOpenMPData control
24 / 67

Intro Multicore Distributed Conclusion
Data model
I Threads can access global shared data poolI Data can be also private to a thread
25 / 67

Intro Multicore Distributed Conclusion
Data controlprivate directive
I Control of data is made with pragmas too
1 i n t my_thread_num = 0 ;2
3 #pragma omp p a r a l l e l p r i v a t e (my_thread_num)4 {5 // Get the th r ead number6 my_thread_num = omp_get_thread_num ( )7
8 p r i n t f ( " He l l o from th r ead %d\n" ,my_thread_num) ;9 } /∗ End p a r a l l e l ∗/
I Remark: private creates a private variable for each thread,but does not copy the data. Use firstprivate or lastprivate todo so.
26 / 67

Intro Multicore Distributed Conclusion
Data controlDangers of shared resources
1 #pragma omp p a r a l l e l s ha r ed ( a , b , c , x , y , z )2 {3 #pragma omp f o r nowa i t4 f o r ( i n t i = 0 ; i < N; i++)5 a [ i ] = b [ i ] + c [ i ] ;6
7 #pragma omp f o r8 f o r ( i n t i = 0 ; i < N; i++)9 z [ i ] = a [ i ]∗ x [ i ] + y [ i ] ;
10 } /∗ End p a r a l l e l ∗/
I Can not ensure that “a” was updated before being used again:race condition
27 / 67

Intro Multicore Distributed Conclusion
Detecting race conditionsI valgrind with the helgrind toolI Compile with -g
gcc -g race.c -o race -fopenmp -std=c99I Run valgrind
valgrind - -tool=helgrind ./race
28 / 67

Intro Multicore Distributed Conclusion
Multicore programming withOpenMPControl flow
29 / 67

Intro Multicore Distributed Conclusion
Controlling the execution flowbarrier directive
1 #pragma omp p a r a l l e l s ha r ed ( a , b , c , x , y , z )2 {3 #pragma omp f o r nowa i t4 f o r ( i n t i = 0 ; i < N; i++)5 a [ i ] = b [ i ] + c [ i ] ;6
7 #pragma omp b a r r i e r8
9 #pragma omp f o r10 f o r ( i n t i = 0 ; i < N; i++)11 z [ i ] = a [ i ]∗ x [ i ] + y [ i ] ;12 } /∗ End p a r a l l e l ∗/
I ExpensiveI Wasted resourcesI ...but sometimes necessary !
30 / 67

Intro Multicore Distributed Conclusion
Controlling the execution flowOther directives
I masterI criticalI atomic
31 / 67

Intro Multicore Distributed Conclusion
Worked example II Want to calculate log–likelihood on several processes, at once
1 i n t main ( i n t argc , char ∗ a rgv [ ] ) {2 . . .3 // Parse the command l i n e4 r e t = parse_command_line ( argc , argv ,5 &nobs ,& s i z e x ,& nsample ,& l o c a t i o n ) ;67 // Parse the data on master8 double ∗buf fe r_X = ( double ∗) mal loc ( nobs∗ s i z e x ∗ s i z e o f ( double ) ) ;9 double ∗ i s i g m a = ( double ∗) mal loc ( s i z e x ∗ s i z e x ∗ s i z e o f ( double ) ) ;
10 double ∗mu = ( double ∗) mal loc ( s i z e x ∗ s i z e o f ( double ) ) ;11 double det_sigma = 0 . 0 ;1213 r e t = read_data ( buffer_X , i s i gma , &det_sigma , mu,14 &nobs , &s i z e x , l o c a t i o n ) ;1516 // Thread v a r i a b l e s17 i n t n t h r e a d s = 1 ;18 i n t th_num = 0 ;19 i n t th_nobs = nobs ;20 n t h r e a d s = get_num_threads ( ) ;21 // Timing v a r i a b l e s22 double t i c , toc , to t_t ime = 0 . 0 ;23
32 / 67

Intro Multicore Distributed Conclusion
Worked example II24 // // A r r ay s f o r a l l t h r e a d s25 // The poo l i s a l l o c a t e d i n s i d e the sha r ed memory26 double ∗pool_LV = ( double ∗) mal loc ( nobs∗ s i z e x ∗ s i z e o f ( double ) ) ; //
L e f t hand s i d e v e c t o r (X−mu)27 double ∗pool_tmp = ( double ∗) mal loc ( nobs∗ s i z e x ∗ s i z e o f ( double ) ) ; //
Temporary h o l d e r f o r (X−mu)∗SIG28 double ∗poo l_ones = ( double ∗) mal loc ( nobs∗ s i z e o f ( double ) ) ; //
Temporary h o l d e r to c r e a t e LV29 double ∗ p o o l _ r e s = ( double ∗) mal loc ( n t h r e a d s∗ s i z e o f ( double ) ) ; //
Each t h r e a d put s i t s r e s u l t i n p o o l _ r e s3031 // Use p o i n t e r s to ge t the c o r r e c t l o c a t i o n i n the a r r a y32 double ∗LV = NULL ;33 double ∗tmp = NULL ;34 double ∗ones = NULL ;35 double ∗X = NULL ;3637 // Ho lde r f o r f i n a l sum38 double f i na l_sum = 0 . 0 ;394041424344 // Main d r i v e r
33 / 67

Intro Multicore Distributed Conclusion
Worked example III45 #pragma omp p a r a l l e l p r i v a t e ( ones , LV , tmp , X, th_num , th_nobs )
d e f a u l t ( sha r ed )46 {47 // Get t h r e a d number48 th_num = omp_get_thread_num ( ) ;49 // Tota l number o f o b s e r v a t i o n s f o r t h a t t h r e a d50 th_nobs = nobs / n t h r e a d s ;5152 // Use the a d d r e s s to p o i n t to the c o r r e c t l o c a t i o n i n the
v e c t o r53 X = &buf fe r_X [ th_num∗nobs∗ s i z e x / n t h r e a d s ] ;54 LV = &pool_LV [ th_num∗ th_nobs∗ s i z e x ] ;55 tmp = &pool_tmp [ th_num∗ th_nobs∗ s i z e x ] ;56 ones = &pool_ones [ th_num∗ th_nobs ] ;5758 // Each p r o c e s s can now c a l c u l a t e the term i n the59 // exponent f o r a s u b s e t o f random v e c t o r s60 l o g _ l i k e l i h o o d (X, i s i gma , mu, det_sigma , th_nobs ,61 s i z e x ,& p o o l _ r e s [ th_num ] , LV , tmp , ones ) ;6263 #pragma omp b a r r i e r6465 // Reduct ion : sum a l l the i n t e r m e d i a r y r e s u l t s66 #pragma omp f o r r e d u c t i o n (+: f i na l_sum )67 f o r ( i n t i = 0 ; i < n t h r e a d s ; i ++)68 f i na l_sum = f ina l_sum + p o o l _ r e s [ i ] ;
34 / 67

Intro Multicore Distributed Conclusion
Worked example IV
69 } /∗ End o f p a r a l l e l ∗/70 toc = omp_get_wtime ( ) ;71 tot_t ime += toc−t i c ;72 . . .73 }
35 / 67

Intro Multicore Distributed Conclusion
Summary
I Multicore / shared memory: use OpenMPI Language extensions for C,C++, and FortranI Compiler directives
+ Relatively easy to use: speedup with not too much effort+ Good scalability on 1 node+ No network communication – low latency, high BW- Threads are heavy- Limited to one compute node- Overhead if not enough work for threads
36 / 67

Intro Multicore Distributed Conclusion
Going further with OpenMP
I OpenMP documentationhttp://openmp.org/wp/resources/
I LLNL OpenMP tutorialhttp://computing.llnl.gov/tutorials/openMP/
I RCC HPC Essentialshttp://rcc.its.psu.edu/education/seminars/pages/hpc_essentials/HPC2.pdf
37 / 67

Intro Multicore Distributed Conclusion
Distributed programming withMPI
38 / 67

Intro Multicore Distributed Conclusion
MPIGeneral concepts – 1/3
I Process work unit on a single coreI Rank process numberI Distributed memory multiple compute nodesI Message Passing communication paradigmI Send / ReceiveI Buffer space where data is stored for send / receive opsI Synchronous / Asynchronous wait / don’t wait for transfer to be
complete (ACK from receiver)I Blocking / Non-blocking completion of comm. is (in)dependent
of events (e.g. buffer that contained data is available for reuse)I Communicators, groups can specify topology –
MPI_COMM_WORLD
39 / 67

Intro Multicore Distributed Conclusion
MPIGeneral concepts – 2/3
I Distributed memory: each process has its own dataI Collaboration through message exchange
40 / 67

Intro Multicore Distributed Conclusion
MPIGeneral concepts – 2/3
I Distributed memory: each process has its own dataI Collaboration through message exchange
41 / 67

Intro Multicore Distributed Conclusion
MPIGeneral concepts – 2/3
42 / 67

Intro Multicore Distributed Conclusion
MPIGeneral concepts – 3/3
I Process is started on each specified core
43 / 67

Intro Multicore Distributed Conclusion
MPICompiling a program
I Choice 1: Use the MPI wrappers to compile and linkmpicc -c myfile1.c -o myfile1.ompicc -c myfile2.c -o myfile2.ompicc myfile1.o myfile2.o -o myprogram
I Choice 2: Use any compiler; have to provide include filelocation and libraries location as wellgcc -c myfile1.c -o myfile1.o -I/path/to/mpi/includegcc -c myfile2.c -o myfile2.o -I/path/to/mpi/include
gcc myfile1.o myfile2.o -o myprogram-L/path/to/mpi/libs -lmpi
44 / 67

Intro Multicore Distributed Conclusion
MPIRunning a program
I Use the command “mpirun”
> mpirun ./hello
45 / 67

Intro Multicore Distributed Conclusion
MPIProgram structure – 1/2
1. Include file1 #inc lude <mpi . h>
2. Program start...1 i n t main ( i n t argc , char ∗ a rgv [ ] ) {
3. Initialize the MPI environment1 MPI_Init(&argc ,& argv ) ;
4. Do stuff...5. “Finalize” the MPI environment
1 MPI_Finalize ( ) ;
46 / 67

Intro Multicore Distributed Conclusion
MPIProgram structure – 2/2
1 #inc lude <mpi . h>2 #inc lude <s t d i o . h>3
4 i n t main ( i n t argc , char ∗ a rgv [ ] ) {5
6 MPI_Init(&argc ,& argv ) ;7 p r i n t f ( " He l l o wor ld !\ n" ) ;8 MPI_Finalize ( ) ;9
10 re tu rn 0 ;11 }
Hello world !Hello world !
47 / 67

Intro Multicore Distributed Conclusion
MPISize and rank – 1/2
I What is the process ID ?1 MPI_Comm_rank(comm,∗ rank ) ;2 // Usage :3 i n t my_rank ;4 MPI_Comm_rank(MPI_COMM_WORLD,&my_rank ) ;
I How many processes did we launch ?1 MPI_Comm_size(comm,∗ s i z e ) ;2 // Usage :3 i n t number_proc ;4 MPI_Comm_size(MPI_COMM_WORLD,&number_proc ) ;
48 / 67

Intro Multicore Distributed Conclusion
MPISize and rank – 2/2
1 MPI_Init(&argc ,& argv ) ;2 i n t my_rank , number_proc ;3 MPI_Comm_rank(MPI_COMM_WORLD,&my_rank ) ;4 MPI_Comm_size(MPI_COMM_WORLD,&number_proc ) ;5
6 p r i n t f ( " He l l o from p r o c e s s %d o f %d !\ n" , my_rank ,number_proc ) ;
7 MPI_Finalize ( ) ;
Hello from process 1 of 2Hello from process 0 of 2
49 / 67

Intro Multicore Distributed Conclusion
MPISend / Recv – 1/4
I Message Passing: point-to-point
1 // Send ing data :2 MPI_Send(∗ bu f f e r , count , type , d e s t i n a t i o n , tag , comm) ;3 // Re c e i v i n g data :4 MPI_Recv(∗ bu f f e r , count , type , source , tag , comm, s t a t u s ) ;
50 / 67

Intro Multicore Distributed Conclusion
MPISend / Recv – 2/4
1 i n t my_rank , number_proc ;2 MPI_Comm_rank(MPI_COMM_WORLD,&my_rank ) ;3 // Proce s s 0 wants to send 10 i n t e g e r s to p r o c e s s 14 i f (my_rank == 0) {5 // Send 10 i n t e g e r s from v e c t o r V6 MPI_Send(V, 10 ,MPI_INT , 1 , 0 ,MPI_COMM_WORLD) ;7 } e l s e i f (my_rank == 1) {8 // Rece i v e 10 i n t e g e r s from v e c t o r V ; s t o r e i n U9 MPI_Recv(U, 10 ,MPI_INT , 0 , 0 ,MPI_COMM_WORLD) ;
10 }
51 / 67
Intro Multicore Distributed Conclusion
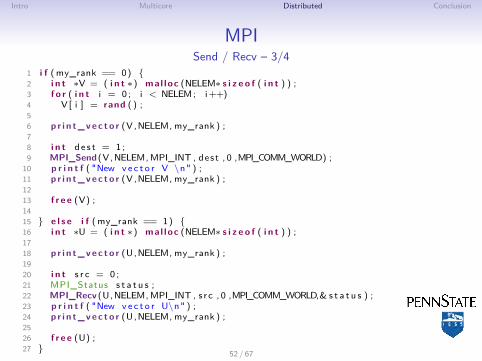
MPISend / Recv – 3/4
1 i f ( my_rank == 0) {2 i n t ∗V = ( i n t ∗) mal loc (NELEM∗ s i z e o f ( i n t ) ) ;3 f o r ( i n t i = 0 ; i < NELEM; i ++)4 V[ i ] = rand ( ) ;56 p r i n t_vec to r (V,NELEM, my_rank ) ;78 i n t d e s t = 1 ;9 MPI_Send(V,NELEM, MPI_INT , dest , 0 ,MPI_COMM_WORLD) ;
10 p r i n t f ( "New v e c t o r V \n" ) ;11 p r i n t_vec to r (V,NELEM, my_rank ) ;1213 f r e e (V) ;1415 } e l s e i f ( my_rank == 1) {16 i n t ∗U = ( i n t ∗) mal loc (NELEM∗ s i z e o f ( i n t ) ) ;1718 p r i n t_vec to r (U,NELEM, my_rank ) ;1920 i n t s r c = 0 ;21 MPI_Status s t a t u s ;22 MPI_Recv (U,NELEM, MPI_INT , s r c , 0 ,MPI_COMM_WORLD,& s t a t u s ) ;23 p r i n t f ( "New v e c t o r U\n" ) ;24 p r i n t_vec to r (U,NELEM, my_rank ) ;2526 f r e e (U) ;27 } 52 / 67

Intro Multicore Distributed Conclusion
MPISend / Recv – 4/4
OutputVector VProcess 0V[0] = 1918581883V[1] = 1004453085V[2] = 786820889
Vector UProcess 1V[0] = 24259120V[1] = 0V[2] = 24265808
New vector VProcess 0V[0] = 1918581883V[1] = 1004453085V[2] = 786820889
New vector UProcess 1V[0] = 1918581883V[1] = 1004453085V[2] = 786820889
53 / 67

Intro Multicore Distributed Conclusion
MPIA word on distributed memory
I Watch where you allocate memory !1 i n t ∗V;2 i f (my_rank == 0) {3 V = ( i n t ∗)malloc (N∗ s i z e o f ( i n t ) ) ;4 }5 . . .6 // Seg . f a u l t e r r o r −− on l y the p r o c e s s 0 has
a l l o c a t e d memory !7 i f (my_rank == 1) {8 V [ 0 ] = 1 ;9 }
54 / 67

Intro Multicore Distributed Conclusion
MPICollectives
I Involves all processes in a communicatorI Examples: broadcast, gather, scatter
55 / 67

Intro Multicore Distributed Conclusion
MPICollectives
56 / 67

Intro Multicore Distributed Conclusion
MPICollectives
I Message Passing: broadcast
1 MPI_Bcast (∗ data , count , type , root , comm)
1 . . .2 i n t data = rand ( ) ;3 // P r o c e s s 0 sends i t s v a l u e to eve r yon e4 MPI_Bcast(&data , 1 , MPI_INT , 0 ,MPI_COMM_WORLD) ;5 . . .
57 / 67

Intro Multicore Distributed Conclusion
MPICollectives
I Message Passing: scatter1 MPI_Scatter (∗ send_data , send_count , send_datatype ,2 ∗ recv_data , recv_count , r ecv_datatype ,3 root , comm)
1 . . .2 i n t ∗ data = NULL ; // S i z e = 2∗N e l ement s3 i n t ∗ r e c v _ b u f f e r = NULL ; // S i z e = 2 e l ement s4 . . .5 f o r ( i n t i = 0 ; i <2∗N; i ++)6 data [ i ] = rand ( ) ;78 // P r o c e s s 0 sends 2 v a l u e s to eve r y one9 // 0 : [ 0 , 1 ] , 1 : [ 2 , 3 ] , e t c .
10 MPI_Scatter ( data , 2 , MPI_INT , r e c v _ b u f f e r , 2 , MPI_INT , 0 ,MPI_COMM_WORLD) ;11 . . . 58 / 67

Intro Multicore Distributed Conclusion
MPICollectives
I Message Passing: gather1 MPI_Gather (∗ send_data , send_count , send_datatype ,2 ∗ recv_data , recv_count , r ecv_datatype ,3 root , comm)
1 . . .2 i n t ∗ data = NULL ; // S i z e = 2 e l ement s3 i n t ∗ r e c v _ b u f f e r = NULL ; // S i z e = 2∗N e l ement s4 . . .5 f o r ( i n t i = 0 ; i <2; i ++)6 data [ i ] = rand ( ) ;78 // P r o c e s s 0 r e c e i v e s 2 e l ement s from N p r o c e s s e s9 MPI_Gather ( data , 2 , MPI_INT , r e c v _ b u f f e r ,2∗N, MPI_INT , 0 ,MPI_COMM_WORLD) ;
10 . . .59 / 67

Intro Multicore Distributed Conclusion
MPICollectives
I Other efficient collective: reductions
60 / 67

Intro Multicore Distributed Conclusion
Worked example II Want to calculate log–likelihood on several processes, at once
1 i n t main ( i n t argc , char ∗ a rgv [ ] ) {2 // S t a r t MPI3 MPI_Init(&argc ,& argv ) ;4 // Get rank and number o f p roc .5 i n t myrank , nproc = 0 ;6 MPI_Comm_rank(COMM,&myrank ) ;7 MPI_Comm_size(COMM,& nproc ) ;89 i n t nobs , s i z e x , nsample = 0 ;
10 char ∗ l o c a t i o n = NULL ;11 i n t r e t = 0 ;1213 // Parse the command l i n e and s e t proc_nobs14 // Number o f o b s e r v a t i o n s pe r p r o c e s s15 i n t proc_nobs ;16 r e t = parse_command_line ( argc , argv ,& nobs ,& s i z e x ,& nsample ,17 &l o c a t i o n ,& proc_nobs , myrank , nproc ) ;1819 // A l l o c a t e the data f o r ALL p r o c e s s e s .20 double ∗ i s i g m a = ( double ∗) mal loc ( s i z e x ∗ s i z e x ∗ s i z e o f ( double ) ) ;21 double ∗mu = ( double ∗) mal loc ( s i z e x ∗ s i z e o f ( double ) ) ;22 double det_sigma = 0 . 0 ;23
61 / 67

Intro Multicore Distributed Conclusion
Worked example II24 // Only the f i r s t p r o c e s s w i l l p a r s e the data . Others w i l l wa i t25 double ∗buf fe r_X = NULL ;26 i f ( myrank == 0 ) {27 i n t r e t = 0 ;28 buf fe r_X = ( double ∗) mal loc ( nobs∗ s i z e x ∗ s i z e o f ( double ) ) ;29 r e t = read_data ( buffer_X , i s i gma , &det_sigma ,30 mu, &nobs , &s i z e x , l o c a t i o n ) ;31 }32 // Wait f o r the p r o c e s s 0 to f i n i s h p a r s i n g the f i l e s33 MPI_Barrier (COMM) ;3435 // Timing v a r i a b l e s36 double t i c , toc , to t_t ime = 0 . 0 ;3738 // Sums39 double f i na l_sum = 0 . 0 ;40 double my_sum = 0 . 0 ;4142 // I n d i v i d u a l a r r a y s43 double ∗X = ( double ∗) mal loc ( proc_nobs∗ s i z e x ∗ s i z e o f ( double ) ) ;44 double ∗LV = ( double ∗) mal loc ( proc_nobs∗ s i z e x ∗ s i z e o f ( double ) ) ;45 double ∗tmp = ( double ∗) mal loc ( proc_nobs∗ s i z e x ∗ s i z e o f ( double ) ) ;46 double ∗ones = ( double ∗) mal loc ( proc_nobs∗ s i z e o f ( double ) ) ;474849 // P r o c e s s 0 sends data to eve r yo ne wi th c o l l e c t i v e s
62 / 67

Intro Multicore Distributed Conclusion
Worked example III50 MPI_Bcast ( i s i gma , s i z e x ∗ s i z e x ,MPI_DOUBLE, 0 ,COMM) ;51 MPI_Bcast (mu, s i z e x ,MPI_DOUBLE, 0 ,COMM) ;52 MPI_Bcast(&det_sigma , 1 ,MPI_DOUBLE, 0 ,COMM) ;53 MPI_Scatter ( buffer_X , proc_nobs∗ s i z e x ,MPI_DOUBLE, X, proc_nobs∗ s i z e x ,
MPI_DOUBLE, 0 ,COMM) ;5455 t i c = omp_get_wtime ( ) ;56 f i na l_sum = 0 . 0 ;57 l o g _ l i k e l i h o o d (X, i s i gma , mu, det_sigma , proc_nobs , s i z e x ,&my_sum , LV ,
tmp , ones ) ;5859 // Combine a l l the i n t e r m e d i a r y sums i n a s i n g l e one60 MPI_Reduce(&my_sum,& f ina l_sum , 1 ,MPI_DOUBLE,MPI_SUM, 0 ,COMM) ;61 MPI_Barrier (COMM) ;62 toc = omp_get_wtime ( ) ;63 tot_t ime += toc−t i c ;64 . . .65 i f ( myrank == 0 ) {66 f r e e ( buf fe r_X ) ;67 }68 // Etc .69 MPI_Final ize ( ) ;70 r e t u r n EXIT_SUCCESS ;71 }
63 / 67

Intro Multicore Distributed Conclusion
Summary
I Distributed programming: use MPII Library for C, C++, and FortranI Programmer responsible for a lot of stuff !
+ Standard+ Optimized collective communication+ Can overlap communication and computation- Strong learning curve- Difficult (?) to debug- Communication through network = optimization issues
64 / 67

Intro Multicore Distributed Conclusion
Going further with MPI
I OpenMPI documentationhttp://www.open-mpi.org/doc/
I MPI tutorialhttp://mpitutorial.com/
I LLNL MPI tutorialhttps://computing.llnl.gov/tutorials/mpi/
I RCC HPC Essentialshttp://rcc.its.psu.edu/education/seminars/pages/hpc_essentials/HPC3.pdf
65 / 67

Intro Multicore Distributed Conclusion
Conclusion
I Covered two approaches for shared and distributed mem.I Shared memory or distributed memory ?
↪→ Depends on pb. size↪→ Amdahl’s law !
I Combine best of both worlds: hybrid approachI Other easier (?) distributed approaches
↪→ Python – MPI4py↪→ R – RMPI↪→ Julia
66 / 67

Intro Multicore Distributed Conclusion
Questions ?
67 / 67