parallel processing experience on low cost pentium machines · parallel computing parallel...
TRANSCRIPT

Parallel Processing Experience
on Low cost Pentium Machines
By
Syed Misbahuddin
Computer Engineering Department Sir Syed University of Engineering and
Technology, Karachi [email protected]
Presented in Open Source Series Workshop 2010
22-24 December, 2010 © ICOSST 2010

Presentation Outline
• Introduction to Parallel Processing concepts
• Hardware and Software Architecture of PC
cluster
• Demonstration of some simple applications
on PC Cluster
• Remote Access to PC Cluster via Internet
2
Presented in Open Source Series Workshop 2010
22-24 December, 2010 © ICOSST 2010

Parallel Computing
Parallel computing is the simultaneous use of multiple
compute resources to solve a computational problem
Parallel Programming is used to improve computational
speed for a given problem
In Parallel Computing, a problem is broken into
discrete parts that can be solved concurrently
3
Presented in Open Source Series Workshop 2010
22-24 December, 2010 © ICOSST 2010

Some Areas of Parallel Computing
• Weather forecasting
• Numerical simulation of engineering and
scientific problems
• Economic scenario analysis
• Data mining applications
• Modeling large DNA structures
• Speech recognition
• Image/Video Processing 4
Presented in Open Source Series Workshop 2010
22-24 December, 2010 © ICOSST 2010

Application Examples for Parallel Processing
• An oil exploration project can divide the sea-
floor into various areas. Nodes in a cluster can
process the seismic data from these areas in
parallel.
• An image can be broken into parts and given
to cluster nodes for image recognition
• DNA sequence search algorithms can be
mapped on cluster
5
Presented in Open Source Series Workshop 2010
22-24 December, 2010 © ICOSST 2010

Problem Decomposition for Parallel processing
6
Presented in Open Source Series Workshop 2010
22-24 December, 2010 © ICOSST 2010

Computing platforms for Parallel
Computing
• A single computer with multiple Internal
Processors
– Shared Memory multiprocessor model
• Multiple Interconnected computers
– Message passing Multi computer model
7
Presented in Open Source Series Workshop 2010
22-24 December, 2010 © ICOSST 2010

Shared Memory Multiprocessor Model
• Shared Memory Multiprocessor model is attractive
due to data access convenience
• Hardware implementation for fast memory access is
difficult
8
Presented in Open Source Series Workshop 2010
22-24 December, 2010 © ICOSST 2010

Shared Memory Model
9
Presented in Open Source Series Workshop 2010
22-24 December, 2010 © ICOSST 2010
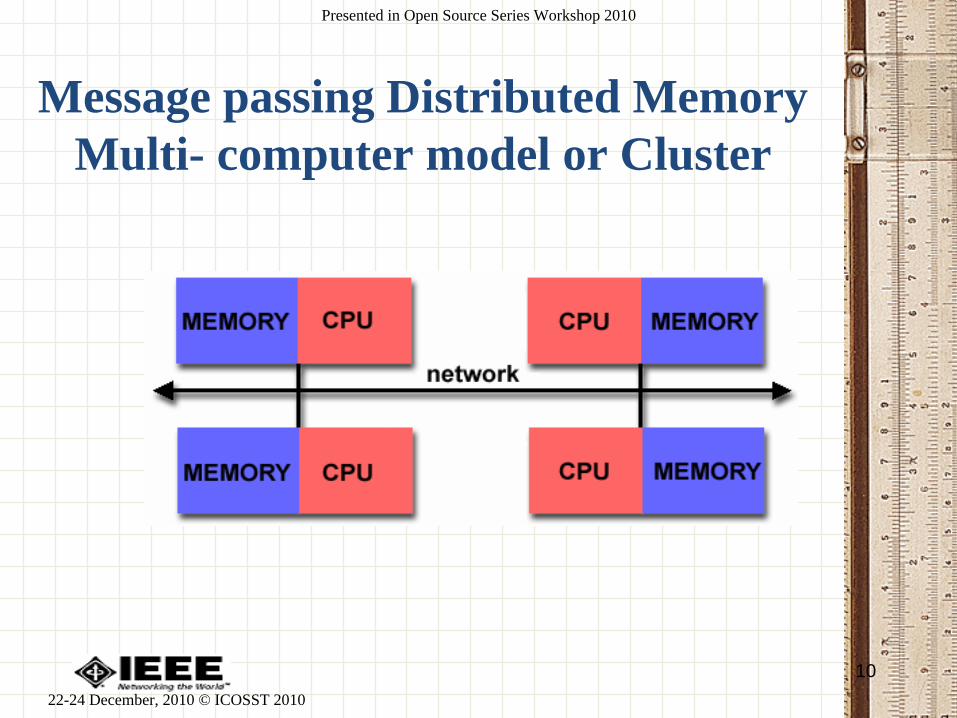
Message passing Distributed Memory
Multi- computer model or Cluster
10
Presented in Open Source Series Workshop 2010
22-24 December, 2010 © ICOSST 2010

Programming Models for Parallel
Computers
• OpenMP for shared memory programming
• MPI (Message Passing Interface) for
distributed memory programming
11
Presented in Open Source Series Workshop 2010
22-24 December, 2010 © ICOSST 2010

Advantage of Message Passing Cluster
Model
• Off-the-shelf normal Intel PCs can be configured to
form a Message Passing Multi computer model
• No special mechanism is needed for controlling
simultaneous data access like shared memory
multiprocessor model
• Clusters are very popular in universities and research
labs for teaching and experimenting Parallel
Processing concepts
12
Presented in Open Source Series Workshop 2010
22-24 December, 2010 © ICOSST 2010

PC cluster as Distributed Memory
Model
Sequential Applications
Parallel Applications
Parallel Programming Environment
Cluster Middleware
Cluster Interconnection Network/Switch
PC/Workstation
Network Interface
Hardware
Communications
Software
PC/Workstation
Network Interface
Hardware
Communications
Software
PC/Workstation
Network Interface
Hardware
Communications
Software
PC/Workstation
Network Interface
Hardware
Communications
Software
Sequential Applications Sequential Applications
Parallel Applications Parallel Applications
13
Presented in Open Source Series Workshop 2010
22-24 December, 2010 © ICOSST 2010

Hardware Architecture for PC
Cluster
Collection of Homogeneous or Heterogeneous
Pentium machines with Network connectivity
14
Presented in Open Source Series Workshop 2010
22-24 December, 2010 © ICOSST 2010

Steps to Build PC Cluster
• LINUX Operating System installations on all nodes to be included in cluster
• NFS/NIS Server Configuration
• NFS/NIS Clients Configurations
• Installation of Parallel Programming System (PPS)
• Commonly used PPS are:
– PVM from University of Tennessee
– MPI from MPI forum
– BSP from Oxford University
15
Presented in Open Source Series Workshop 2010
22-24 December, 2010 © ICOSST 2010
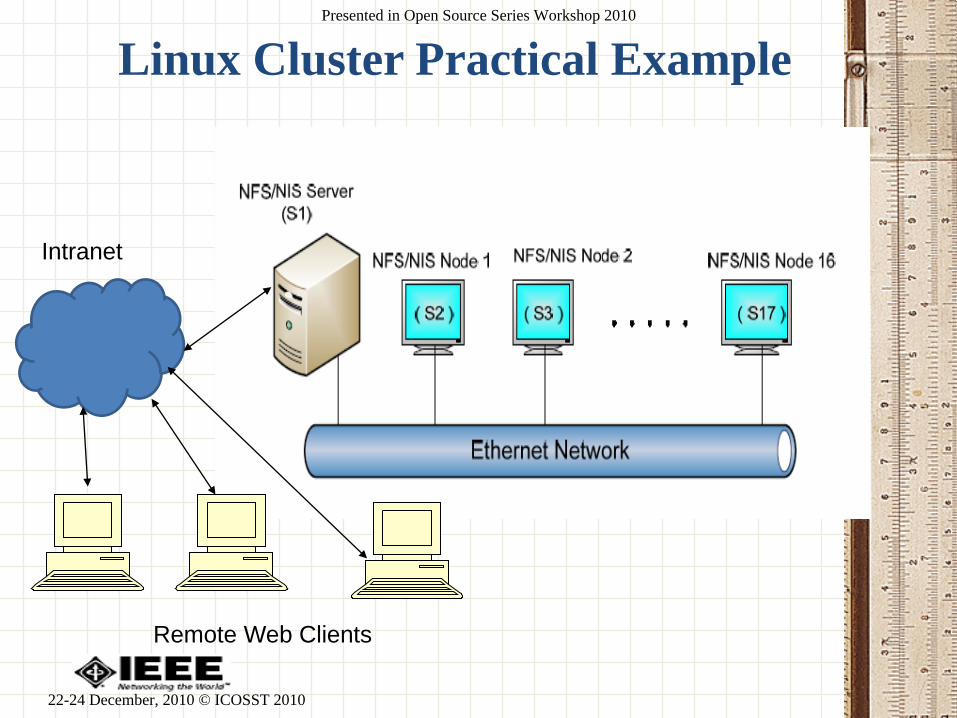
Linux Cluster Practical Example
Intranet
Remote Web Clients
Presented in Open Source Series Workshop 2010
22-24 December, 2010 © ICOSST 2010

17
Presented in Open Source Series Workshop 2010
22-24 December, 2010 © ICOSST 2010

Message Passing Interface (MPI)
MPI is a library of routines introduced by the Message-Passing Interface Forum in 1994
MPI is used for Parallel Processing on Cluster
MPI allows transmitting data from one process running on one machine to another process running on a different machine
The programmer is responsible for correctly identifying parallelism and implementing the resulting algorithm using MPI constructs
MPI subprograms that can be invoked by C/C++ or Fortran 77 program
18
Presented in Open Source Series Workshop 2010
22-24 December, 2010 © ICOSST 2010

Six Main MPI routines
1. MPI_INIT: initializes the MPI environment
2. MPI_COMM_SIZE: returns the number of processes
3. MPI_COMM_RANK: returns this process's number (rank)
4. MPI_SEND: sends a message
5. MPI_RECV: receives a message
6. MPI_FINALIZE
19
Presented in Open Source Series Workshop 2010
22-24 December, 2010 © ICOSST 2010

MPI_COMM_WORLD
20
•The MPI communicator specifies a group of processes inside which a communication occurs
• In A MPI Communicator world, each process gets a RANK_ID
• MPI Communicator world is created over all machines in the system
Presented in Open Source Series Workshop 2010
22-24 December, 2010 © ICOSST 2010

21
Presented in Open Source Series Workshop 2010
22-24 December, 2010 © ICOSST 2010

22
Process control over the Cluster
Rank_ID=0
Rank_ID=1 Rank_ID=2
Presented in Open Source Series Workshop 2010
22-24 December, 2010 © ICOSST 2010

23
A Parallel Computation Example
Problem:
F=(a-b)(a+b)(a*b)
Suboperation1=(a-b) done by Machine1 and send partial result to
Suboperation2=(a+b) done by Machine2
Suboperation3 =(a*b) done by Machine3
Each machine sends partial results to the head node or server
Server computes F= (a-b)*(a+b)*(a*b)
23
Presented in Open Source Series Workshop 2010
22-24 December, 2010 © ICOSST 2010

24
Server reads a,b
anc d
Tmp1=(a-b)
Server Node
Client Node1
Tmp2=(a+b) Tmp3=(a*b)
Client Node2 Client Node3
Server computes
(a-b)(a+b)(a*b)
24
Presented in Open Source Series Workshop 2010
22-24 December, 2010 © ICOSST 2010

MPI PROGRAM
25
Presented in Open Source Series Workshop 2010
22-24 December, 2010 © ICOSST 2010

Popular MPI Implementation
• MPICH by Argonne National Lab and
Mississippi State University
• Local Area Multicomputer MPI(LAM-MPI)
by Ohio Supercomputer center
• CHIMP by Edinburgh Parallel Computing
Center
26
Presented in Open Source Series Workshop 2010
22-24 December, 2010 © ICOSST 2010

LAM/MPI
• LAM/MPI is a high-quality open-source implementation of the Message Passing Interface specification
• LAM allows interconnected computers to act as one parallel computer for solving one compute intensive problem
• LAM features a full implementation of the MPI communication standard
27
Presented in Open Source Series Workshop 2010
22-24 December, 2010 © ICOSST 2010

Launching LAM on The Linux cluster
lamboot command is used to launch LAM daemons on a Linux cluster
LAM daemon running on each node provides process management, including signal handling and I/O management.
A textfile contains the names of machines on LAM is to be launched
$lamboot –v machinefile
LAM daemons are owned by the users
There can be several parallel machines on same clusters
28
Presented in Open Source Series Workshop 2010
22-24 December, 2010 © ICOSST 2010

Running Programs on Cluster
• A special compiler called Handle-C compiler
(hcc) is used to compile C codes for cluster
• $hcc –o exec_file mpi_prog.c
• mpirun -np 3 exec_file
29
Presented in Open Source Series Workshop 2010
22-24 December, 2010 © ICOSST 2010

Sample MPI Programs
• Example 1
Objective:
1. Two client nodes send Greeting messages to
the server node
2. Server node receives Greeting message and
prints on display
30
Presented in Open Source Series Workshop 2010
22-24 December, 2010 © ICOSST 2010

Code for Progarm1 1. MPI_Init(&argc, &argv);
2. MPI_Comm_rank(MPI_COMM_WORLD, &my_rank);
3. MPI_Comm_size(MPI_COMM_WORLD, &p);
4. gherr = gethostname( hname, silen);
5. if (my_rank != 0) {
6. /* Client code */
7. sprintf(message, "Greetings from process %d on %s!", my_rank, hname);
8. dest = 0;
9. MPI_Send(message, strlen (message)+1, MPI_CHAR, dest, tag, MPI_COMM_WORLD);
10. } else {
11. /* Server code */
12. printf ("Messages received by process %d on %s.\n\n", my_rank, hname);
13. for (source = 1; source < p; source++) {
14. MPI_Recv(message, 800, MPI_CHAR, source, tag, MPI_COMM_WORLD, &status);
15. printf("%s\n", message);} 31
Presented in Open Source Series Workshop 2010
22-24 December, 2010 © ICOSST 2010

Output of Program1 on Cluster
32
Presented in Open Source Series Workshop 2010
22-24 December, 2010 © ICOSST 2010

Example 2
• Objective: To find sum of an Integer array
• Server node reads Integer array and sends it to clients
• Client 1 finds partial sum of first half array elements and sends partial sum to server
• Client 2 finds partial sum of second half array elements and sends partial sum to server
• Sever node adds partial sums to find total sum of
input array
33
Presented in Open Source Series Workshop 2010
22-24 December, 2010 © ICOSST 2010

Output of Program2 on Cluster
34
Presented in Open Source Series Workshop 2010
22-24 December, 2010 © ICOSST 2010

Example 3: Matrix Multiplication on
Cluster
35
Presented in Open Source Series Workshop 2010
22-24 December, 2010 © ICOSST 2010

Example 4
Numerical Integration on Cluster
• Each nodes computes the area of a slice of
the curve and send the individual area to the
server
• Serve computes the area of the curve by
adding the individual areas.
36
Presented in Open Source Series Workshop 2010
22-24 December, 2010 © ICOSST 2010

• Questions ?
37
Presented in Open Source Series Workshop 2010
22-24 December, 2010 © ICOSST 2010