parallel computers1 risc and parallel computers prof. sin-min lee department of computer science
TRANSCRIPT

Parallel Computers 1
RISC and Parallel Computers
Prof. Sin-Min LeeDepartment of Computer
Science

Parallel Computers 2
The Basis for RISC Use of simple instructions One of their key realizations was that a
sequence of simple instructions produces the same results as a sequence of complex instructions, but can be implemented with a simpler (and faster) hardware design. Reduced Instruction Set Computers---RISC machines---were the result.

Parallel Computers 3
Instruction Pipeline Similar to a manufacturing assembly
line1. Fetch an instruction2. Decode the instruction3. Execute the instruction4. Store results
Each stage processes simultaneously (after initial latency)
Execute one instruction per clock cycle

Parallel Computers 4
Pipeline Stages Some processors use 3, 4, or 5 stages

Parallel Computers 5

Parallel Computers 6
RISC characteristics Simple instruction set. In a RISC machine, the instruction
set contains simple, basic instructions, from which more complex instructions can be composed.
Same length instructions.

Parallel Computers 7
RISC characteristics Each instruction is the same length, so
that it may be fetched in a single operation.
1 machine-cycle instructions. Most instructions complete in one
machine cycle, which allows the processor to handle several instructions at the same time. This pipelining is a key technique used to speed up RISC machines.

Parallel Computers 8
Instructions Pipelines It is to prepare the next instruction
while the current instruction is still executing.
A Three states RISC pipelines is :1. Fetch instruction 2. Decode and select registers 3. Execute the instruction
ClockStage
1 2 3 4 5 6 7
1 i1 i2 i3 i4 i5 i6 i7
2 - i1 i2 i3 i4 i5 i6
3 - - i1 i2 i3 i4 i5

Parallel Computers 9
RISC vs. CISC RISC have fewer and simpler instructions,
therefore, they are less complex and easier to design. Also, it allow higher clock speed than CISC. However, When we compiled high-level language. RISC CPU need more instructions than CISC CPU.
CISC are complex but it doesn’t necessarily increase the cost. CISC processors are backward compactable.

Parallel Computers 10
Demand for Computational Speed
Continual demand for greater computational speed from a computer system than is currently possible
Areas requiring great computational speed include numerical modeling and simulation of scientific and engineering problems.
Computations must be completed within a “reasonable” time period.

Parallel Computers 11
Grand Challenge ProblemsOne that cannot be solved in a reasonable amount of time with today’s computers. Obviously, an execution time of 10 years is always unreasonable.
Examples Modeling large DNA structures Global weather forecasting Modeling motion of astronomical bodies.

Parallel Computers 12
Weather Forecasting Atmosphere modeled by dividing it
into 3-dimensional cells. Calculations of each cell repeated
many times to model passage of time.

Parallel Computers 13
Global Weather Forecasting Example Suppose whole global atmosphere divided into cells of
size 1 mile 1 mile 1 mile to a height of 10 miles (10 cells high) - about 5 108 cells.
Suppose each calculation requires 200 floating point operations. In one time step, 1011 floating point operations necessary.
To forecast the weather over 7 days using 1-minute intervals, a computer operating at 1Gflops (109 floating point operations/s) takes 106 seconds or over 10 days.
To perform calculation in 5 minutes requires computer operating at 3.4 Tflops (3.4 1012 floating point operations/sec).

Parallel Computers 14
Modeling Motion of Astronomical Bodies Each body attracted to each other body by
gravitational forces. Movement of each body predicted by calculating total force on each body.
With N bodies, N - 1 forces to calculate for
each body, or approx. N2 calculations. (N log2 N for an efficient approx. algorithm.)
After determining new positions of bodies, calculations repeated.

Parallel Computers 15
A galaxy might have, say, 1011 stars.
Even if each calculation done in 1 ms (extremely optimistic figure), it takes 109 years for one iteration using N2 algorithm and almost a year for one iteration using an efficient N log2 N approximate algorithm.

Parallel Computers 16
Astrophysical N-body simulation by Scott Linssen (undergraduate UNC-Charlotte student).

Parallel Computers 17

Parallel Computers 18
Parallel Computing Using more than one computer, or a computer with
more than one processor, to solve a problem.
Motives Usually faster computation - very simple idea - that
n computers operating simultaneously can achieve the result n times faster - it will not be n times faster for various reasons.
Other motives include: fault tolerance, larger amount of memory available, ...

Parallel Computers 19

Parallel Computers 20
Background Parallel computers - computers
with more than one processor - and their programming - parallel programming - has been around
for more than 40 years.

Parallel Computers 21
Gill writes in 1958:
“... There is therefore nothing new in the idea of parallel programming, but its application to computers. The author cannot believe that there will be any insuperable difficulty in extending it to computers. It is not to be expected that the necessary programming techniques will be worked out overnight. Much experimenting remains to be done. After all, the techniques that are commonly used in programming today were only won at the cost of considerable toil several years ago. In fact the advent of parallel programming may do something to revive the pioneering spirit in programming which seems at the present to be degenerating into a rather dull and routine occupation ...”
Gill, S. (1958), “Parallel Programming,” The Computer Journal, vol. 1, April, pp. 2-10.

Parallel Computers 22
Trends Moore’s Law: Number of
transistors per square inch in an integrated circuit doubles every 18 months
Every decade – computer performance increases 2 order of magnitude

Parallel Computers 23
Goal of Parallel Computing Solve bigger problems faster Often bigger is more important
than faster P-fold speedups not as important!
Challenge of Parallel Computing
Coordinate, control, and monitor the computation

Parallel Computers 24
Speedup Factor
where ts is execution time on a single processor and tp is execution time on a multiprocessor.
S(p) gives increase in speed by using multiprocessor.
Use best sequential algorithm with single processor system. Underlying algorithm for parallel implementation might be (and is usually) different.
S(p) = Execution time using one processor (best sequential algorithm)Execution time using a multiprocessor with p processors
=ts
tp

Parallel Computers 25
Speedup factor can also be cast in terms of computational steps:
Can also extend time complexity to parallel computations.
S(p) = Number of computational steps using one processor
Number of parallel computational steps with p processors

Parallel Computers 26
Maximum SpeedupMaximum speedup is usually p with p processors (linear speedup).
Possible to get superlinear speedup (greater than p) but usually a specific reason such as:
Extra memory in multiprocessor system Nondeterministic algorithm

Parallel Computers 27
Maximum Speedup Amdahl’s law
Serial section Parallelizable sections
(a) One processor
(b) Multipleprocessors
fts (1 - f)ts
ts
(1 - f)ts/ptp
p processors

Parallel Computers 28
P PP P P PMicrokernelMicrokernel
Multi-Processor Computing System
Threads InterfaceThreads Interface
Hardware
Operating System
ProcessProcessor ThreadPP
Applications
Computing Elements
Programming paradigms

Parallel Computers 29
Architectures System
Software/Compiler Applications P.S.Es Architectures System
Software Applications P.S.Es
SequentialEra
ParallelEra
1940 50 60 70 80 90 2000 2030
Two Eras of Computing
Commercialization R & D Commodity

Parallel Computers 30
History of Parallel Processing PP can be traced to a tablet
dated around 100 BC. Tablet has 3 calculating
positions. Infer that multiple positions:
Reliability/ Speed

Parallel Computers 31
Why Parallel Processing?
Computation requirements are ever increasing -- visualization, distributed databases, simulations, scientific prediction (earthquake), etc.
Sequential architectures reaching physical limitation (speed of light, thermodynamics)

Parallel Computers 32
No. of Processors
C.P
.I.
1 2 . . . .
Computational Power Improvement
Multiprocessor
Uniprocessor

Parallel Computers 33

Parallel Computers 34

Parallel Computers 35

Parallel Computers 36
The Tech. of PP is mature and can be exploited commercially; significant R & D work on development of tools & environment.
Significant development in Networking technology is paving a way for heterogeneous computing.
Why Parallel Processing?

Parallel Computers 37
Hardware improvements like Pipelining, Superscalar, etc., are non-scalable and requires sophisticated Compiler Technology.
Vector Processing works well for certain kind of problems.
Why Parallel Processing?

Parallel Computers 38
Parallel Program has & needs ...
Multiple “processes” active
simultaneously solving a given
problem, general multiple processors.
Communication and synchronization
of its processes (forms the core of
parallel programming efforts).

Parallel Computers 39
Parallelism in Uniprocessor Systems
• A computer achieves parallelism when it performs two or more unrelated tasks simultaneously

Parallel Computers 40
Uniprocessor Systems
Uniprocessor system may incorporate parallelism using:
an instruction pipeline a fixed or reconfigurable arithmetic
pipeline I/O processors vector arithmetic units multiport memory

Parallel Computers 41
Uniprocessor Systems
Instruction pipeline:
By overlapping the fetching, decoding, and execution of instructions
Allows the CPU to execute one instruction per clock cycle

Parallel Computers 42
Uniprocessor SystemsReconfigurable Arithmetic Pipeline: Better suited for general purpose computing Each stage has a multiplexer at its input The control unit of the CPU sets the selected data to
configure the pipeline Problem: Although arithmetic pipelines can perform many
iterations of the same operation in parallel, they cannot perform different operations simultaneously.

Parallel Computers 43
Uniprocessor Systems
Vectored Arithmetic Unit:
Provides a solution to the reconfigurable arithmetic pipeline problem
Purpose: to perform different arithmetic operations in parallel

Parallel Computers 44
Uniprocessor SystemsVectored Arithmetic Unit (cont.): Contains multiple functional
units- Some performs addition, subtraction, etc.
Input and output switches are needed to route the proper data to their properdestinations- Switches are set by the control unit

Parallel Computers 45
Uniprocessor SystemsVectored Arithmetic Unit (cont.):
How do we get all that data to the vector arithmetic unit?
By transferring several data values simultaneously using:- Multiple buses- Very wide data buses

Parallel Computers 46
Uniprocessor Systems
Improve performance:
Allowing multiple, simultaneous memory access
- requires multiple address, data, and control buses
(one set for each simultaneous memory access)- The memory chip has to be able to handle multiple transfers simultaneously

Parallel Computers 47
Uniprocessor Systems
Multiport Memory:
Has two sets of address, data, and control pins to allow simultaneous data transfers to occur
CPU and DMA controller can transfer data concurrently
A system with more than one CPU could handle simultaneous requests from two different processors

Parallel Computers 48
Uniprocessor Systems
Multiport Memory (cont.):CanCan- Multiport memory can handle two requests to read Multiport memory can handle two requests to read data from the same location at the same timedata from the same location at the same time
CannotCannot- Process two simultaneous requests to write data to Process two simultaneous requests to write data to the same memory locationthe same memory location
- Requests to read from and write to the same - Requests to read from and write to the same memory location simultaneouslymemory location simultaneously

Parallel Computers 49
Multiprocessors
I/O PortDeviceDevice
Controller
CPU
Bu
s
MemoryCPU
CPU

Parallel Computers 50
Multiprocessors Systems designed to have 2 to 8 CPUs The CPUs all share the other parts of the
computer Memory Disk System Bus etc
CPUs communicate via Memory and the System Bus

Parallel Computers 51
MultiProcessors Each CPU shares memory, disks,
etc Cheaper than clusters Not as good performance as clusters
Often used for Small Servers High-end Workstations

Parallel Computers 52
MultiProcessors OS automatically shares work
among available CPUs On a workstation…
One CPU can be running an engineering design program
Another CPU can be doing complex graphics formatting

Parallel Computers 53
Applications of Parallel Computers Traditionally: government labs,
numerically intensive applications Research Institutions Recent Growth in Industrial
Applications 236 of the top 500 Financial analysis, drug design and
analysis, oil exploration, aerospace and automotive

Parallel Computers 54
Multiprocessor SystemsFlynn’s Classification
Single instruction multiple data (SIMD):
MainMemory
ControlUnit
Processor
Processor
Processor
Memory
Memory
Memory
CommunicationsNetwork
• Executes a single instruction on multiple data values Executes a single instruction on multiple data values simultaneously using many processorssimultaneously using many processors• Since only one instruction is processed at any given time, it Since only one instruction is processed at any given time, it is not necessary for each processor to fetch and decode the is not necessary for each processor to fetch and decode the instructioninstruction• This task is handled by a single control unit that sends the This task is handled by a single control unit that sends the control signals to each processor.control signals to each processor.• Example: Array processorExample: Array processor

Parallel Computers 55
Why Multiprocessors?1. Microprocessors as the fastest CPUs
• Collecting several much easier than redesigning 1
2. Complexity of current microprocessors• Do we have enough ideas to sustain
1.5X/yr?• Can we deliver such complexity on
schedule?3. Slow (but steady) improvement in parallel
software (scientific apps, databases, OS)4. Emergence of embedded and server markets driving
microprocessors in addition to desktops• Embedded functional parallelism,
producer/consumer model• Server figure of merit is tasks per hour vs. latency

Parallel Computers 56
Parallel Processing Intro Long term goal of the field: scale number processors to size of
budget, desired performance Machines today: Sun Enterprise 10000 (8/00)
64 400 MHz UltraSPARC® II CPUs,64 GB SDRAM memory, 868 18GB disk,tape
$4,720,800 total 64 CPUs 15%,64 GB DRAM 11%, disks 55%, cabinet 16%
($10,800 per processor or ~0.2% per processor) Minimal E10K - 1 CPU, 1 GB DRAM, 0 disks, tape ~$286,700 $10,800 (4%) per CPU, plus $39,600 board/4 CPUs (~8%/CPU)
Machines today: Dell Workstation 220 (2/01) 866 MHz Intel Pentium® III (in Minitower) 0.125 GB RDRAM memory, 1 10GB disk, 12X CD, 17” monitor,
nVIDIA GeForce 2 GTS,32MB DDR Graphics card, 1yr service $1,600; for extra processor, add $350 (~20%)

Parallel Computers 57
Major MIMD Styles
1. Centralized shared memory ("Uniform Memory Access" time or "Shared Memory Processor")
2. Decentralized memory (memory module with CPU) • get more memory bandwidth, lower
memory latency• Drawback: Longer communication latency• Drawback: Software model more complex

Parallel Computers 58
Organization of Multiprocessor Systems
Three different ways to organize/classify systems:
• Flynn’s Classification
• System Topologies
• MIMD System Architectures

Parallel Computers 59
Multiprocessor SystemsFlynn’s Classification
Flynn’s Classification: Based on the flow of instructions and data
processing
A computer is classified by:- whether it processes a single instruction at a time or multiple instructions simultaneously- whether it operates on one more multiple data sets

Parallel Computers 60
Multiprocessor SystemsFlynn’s Classification
Four Categories of Flynn’s Classification:
SISD Single instruction single data SIMD Single instruction multiple data MISD Multiple instruction single data ** MIMD Multiple instruction multiple data
** The MISD classification is not practical to implement.In fact, no significant MISD computers have ever been build.It is included only for completeness.

Parallel Computers 61
Multiprocessor SystemsFlynn’s Classification
Single instruction single data (SISD):
Consists of a single CPU executing individual instructions on individual data values

Parallel Computers 62
Multiprocessor SystemsFlynn’s Classification
Multiple instruction Multiple data (MIMD):
Executes different instructions simultaneously Each processor must include its own control unit The processors can be assigned to parts of the
same task or to completely separate tasks Example: Multiprocessors, multicomputers

Parallel Computers 63
Popular Flynn Categories SISD (Single Instruction Single Data)
Uniprocessors MISD (Multiple Instruction Single Data)
???; multiple processors on a single data stream SIMD (Single Instruction Multiple Data)
Examples: Illiac-IV, CM-2 Simple programming model Low overhead Flexibility All custom integrated circuits
(Phrase reused by Intel marketing for media instructions ~ vector)
MIMD (Multiple Instruction Multiple Data) Examples: Sun Enterprise 5000, Cray T3D, SGI
Origin Flexible Use off-the-shelf micros
MIMD current winner: Concentrate on major design emphasis <= 128 processor MIMD machines

Parallel Computers 64
Multiprocessor SystemsSystem Topologies: The topology of a multiprocessor system refers to the pattern of
connections between its processors Quantified by standard metrics:
Diameter The maximum distance between two processors in the computer system
Bandwidth The capacity of a communications link multiplied by the number of such links in the system (best case)
Bisectional Bandwidth The total bandwidth of the links connecting the two halves of
the processor split so that the number of links between the two halves is minimized (worst case)

Parallel Computers 65
Multiprocessor SystemsSystem Topologies
Six Categories of System Topologies:
• Shared bus
• Ring
• Tree
• Mesh
• Hypercube
• Completely Connected

Parallel Computers 66
Multiprocessor SystemsSystem Topologies
Shared bus: The simplest topology Processors communicate
with each other exclusively via this bus
Can handle only one data transmission at a time
Can be easily expanded by connecting additional processors to the shared bus, along with the necessary bus arbitration circuitry
Shared Bus
GlobalMemory
M
P
M
P
M
P

Parallel Computers 67
Multiprocessor SystemsSystem Topologies
Ring: Uses direct dedicated
connections between processors
Allows all communication links to be active simultaneously
A piece of data may have to travel through several processors to reach its final destination
All processors must have two communication links
P
P P
P P
P
Parallel Computers 68
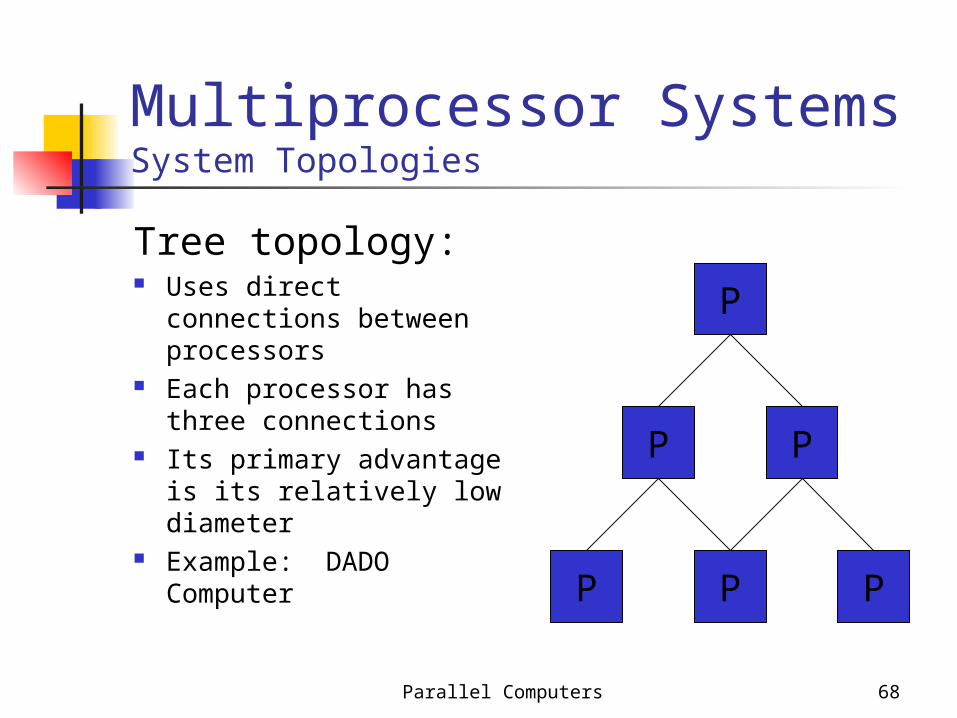
Multiprocessor SystemsSystem Topologies
Tree topology: Uses direct
connections between processors
Each processor has three connections
Its primary advantage is its relatively low diameter
Example: DADO Computer
P
P P
P P P

Parallel Computers 69
Multiprocessor SystemsSystem Topologies
Mesh topology: Every processor
connects to the processors above, below, left, and right
Left to right and top to bottom wraparound connections may or may not be present
P P P
P P P
P P P

Parallel Computers 70
Multiprocessor SystemsSystem Topologies
Hypercube:
Multidimensional mesh
Has n processors, each with log n connections

Parallel Computers 71
Multiprocessor SystemsSystem Topologies
Completely Connected:
• Every processor has n-1 connections, one to each of the other processors• The complexity of the processors increases as the system grows• Offers maximum communication capabilities

Parallel Computers 72
Architecture Details Computers MPPs
P MWorld’s simplest computer (processor/memory)
P MC DStandard computer (add cache,disk)
P MC DP MC D
P MC DNetwork

Parallel Computers 73
A Supercomputer at $5.2 million
Virginia Tech 1,100 node Macs.
G5 supercomputer

Parallel Computers 74
The Virginia Polytechnic Institute and State University has built a supercomputer comprised of a cluster of 1,100 dual-processor Macintosh G5 computers. Based on preliminary benchmarks, Big Mac is capable of 8.1 teraflops per second. The Mac supercomputer still is being fine tuned, and the full extent of its computing power will not be known until November. But the 8.1 teraflops figure would make the Big Mac the world's fourth fastest supercomputer

Parallel Computers 75
Big Mac's cost relative to similar machines is as noteworthy as its performance. The Apple supercomputer was constructed for just over US$5 million, and the cluster was assembled in about four weeks.
In contrast, the world's leading supercomputers cost well over $100 million to build and require several years to construct. The Earth Simulator, which clocked in at 38.5 teraflops in 2002, reportedly cost up to $250 million.

Parallel Computers 76
Srinidhi Varadarajan, Ph.D.Dr. Srinidhi Varadarajan is an Assistant Professor of Computer Science at Virginia Tech. He was honored with the NSF Career Award in 2002 for "Weaving a Code Tapestry: A Compiler Directed Framework for Scalable Network Emulation." He has focused his research on building a distributed network emulation system that can scale to emulate hundreds of thousands of virtual nodes.
October 28 2003Time: 7:30pm - 9:00pmLocation: Santa Clara Ballroom

Parallel Computers 77
Parallel Computers Two common types
Cluster Multi-Processor

Parallel Computers 78
Cluster Computers

Parallel Computers 79
Clusters on the Rise
Using clusters of small machines to build a supercomputer is not a new concept.
Another of the world's top machines, housed at the Lawrence Livermore National Laboratory, was constructed from 2,304 Xeon processors. The machine was build by Utah-based Linux Networx.
Clustering technology has meant that traditional big-iron leaders like Cray (Nasdaq: CRAY) and IBM have new competition from makers of smaller machines. Dell (Nasdaq: DELL) , among other companies, has sold high-powered computing clusters to research institutions.

Parallel Computers 80
Cluster Computers Each computer in a cluster is a
complete computer by itself CPU Memory Disk etc
Computers communicate with each other via some interconnection bus

Parallel Computers 81
Cluster Computers Typically used where one
computer does not have enough capacity to do the expected work Large Servers
Cheaper than building one GIANT computer

Parallel Computers 82
Although not new, supercomputing clustering technology still is impressive. It works by farming out chunks of data to individual machines, adding that clustering works better for some types of computing problems than others.
For example, a cluster would not be ideal to compete against IBM's Deep Blue supercomputer in a chess match; in this case, all the data must be available to one processor at the same moment -- the machine operates much in the same way as the human brain handles tasks.
However, a cluster would be ideal for the processing of seismic data for oil exploration, because that computing job can be divided into many smaller tasks.

Parallel Computers 83
Cluster Computers Need to break up work among the
computers in the cluster Example: Microsoft.com Search
Engine 6 computers running SQL Server
Each has a copy of the MS Knowledge Base Search requests come to one computer
Sends request to one of the 6 Attempts to keep all 6 busy

Parallel Computers 84
The Virginia Tech Mac supercomputer should be fully functional and in use by January 2004. It will be used for research into nanoscale electronics, quantum chemistry, computational chemistry, aerodynamics, molecular statics, computational acoustics and the molecular modeling of proteins.