parallel application memory scheduling eiman ebrahimi * rustam miftakhutdinov *, chris fallin ‡...
Post on 21-Dec-2015
223 views
TRANSCRIPT

Parallel Application Memory Scheduling
Eiman Ebrahimi*
Rustam Miftakhutdinov*, Chris Fallin‡
Chang Joo Lee*+, Jose Joao*
Onur Mutlu‡, Yale N. Patt*
* HPS Research Group The University of Texas at
Austin‡ Computer Architecture Laboratory
Carnegie Mellon University+ Intel Corporation
Austin

2
Background
Core 0 Core 1 Core 2 Core N
Shared Cache
Memory Controller
DRAMBank 0
DRAMBank 1
DRAM Bank 2
... DRAMBank K
...
Shared MemoryResources
Chip BoundaryOn-chipOff-chip
2

Background
Memory requests from different cores interfere in shared memory resources
Multi-programmed workloads System Performance and Fairness
A single multi-threaded application?
3
Core 0
Core 1
Core 2
Core N
Shared Cache
Memory Controller
...DRAMBank
K
...
Shared MemoryResources
Chip Boundary
3
DRAMBank
0
DRAMBank
1
DRAMBank
2

Memory System Interference in A Single Multi-Threaded Application
Inter-dependent threads from the same application slow each other down
Most importantly the critical path of execution can be significantly slowed down
Problem and goal are very different from interference between independent applications Interdependence between threads Goal: Reduce execution time of a single application No notion of fairness among the threads
of the same application
4
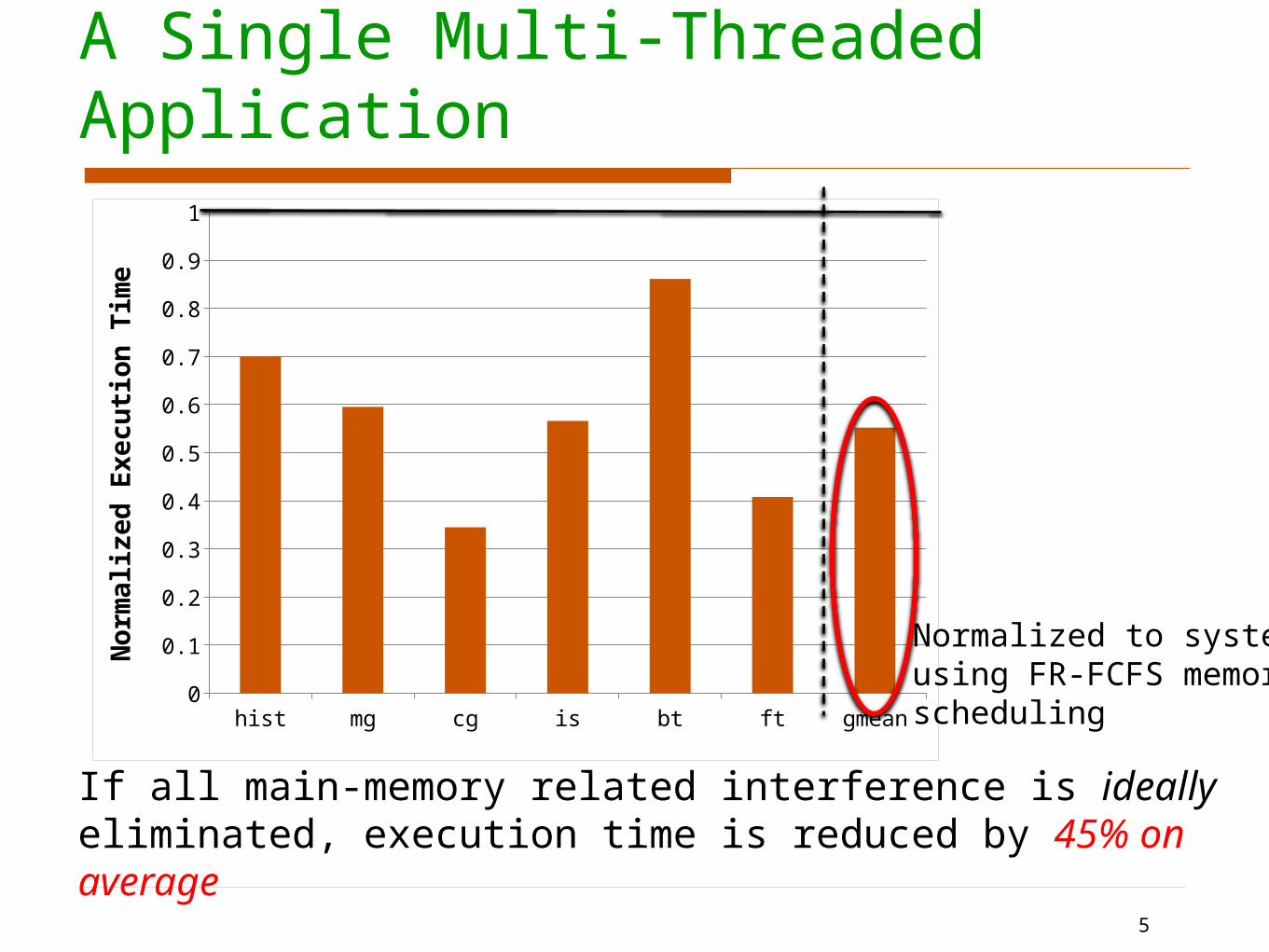
Potential inA Single Multi-Threaded Application
hist mg cg is bt ft gmean0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Norm
alize
d E
xecu
tion
Tim
e
If all main-memory related interference is ideally eliminated, execution time is reduced by 45% on average
5
Normalized to systemusing FR-FCFS memoryscheduling

Outline
Problem Statement Parallel Application Memory Scheduling Evaluation Conclusion
6

Outline
Problem Statement Parallel Application Memory Scheduling Evaluation Conclusion
7

Parallel Application Memory Scheduler
Identify the set of threads likely to be on the critical path as limiter threads Prioritize requests from limiter threads
Among limiter threads: Prioritize requests from latency-sensitive threads
(those with lower MPKI)
Among non-limiter threads: Shuffle priorities of non-limiter threads to reduce
inter-thread memory interference Prioritize requests from threads falling behind
others in a parallel for-loop
8

Parallel Application Memory Scheduler
Identify the set of threads likely to be on the critical path as limiter threads Prioritize requests from limiter threads
Among limiter threads: Prioritize requests from latency-sensitive threads
(those with lower MPKI)
Among non-limiter threads: Shuffle priorities of non-limiter threads to reduce
inter-thread memory interference Prioritize requests from threads falling behind
others in a parallel for-loop
9

Runtime System Limiter Identification
Contended critical sections are often on the critical path of execution
Extend runtime system to identify thread executing the most contended critical section as the limiter thread Track total amount of time all threads wait on
each lock in a given interval Identify the lock with largest waiting time as
the most contended Thread holding the most contended lock is a limiter and
this information is exposed to the memory controller
10

Prioritizing Requests from Limiter Threads
11
Critical Section 1 BarrierNon-Critical Section
Waiting for Sync or Lock
Thread D
Thread C
Thread B
Thread A
Time
Barrier
Time
Barrier
Thread D
Thread C
Thread B
Thread A
Critical Section 2 Critical Path
SavedCycles Limiter Thread: DBCA
Most ContendedCritical Section:1
Limiter Thread Identification

Parallel Application Memory Scheduler
Identify the set of threads likely to be on the critical path as limiter threads Prioritize requests from limiter threads
Among limiter threads: Prioritize requests from latency-sensitive threads
(those with lower MPKI)
Among non-limiter threads: Shuffle priorities of non-limiter threads to reduce
inter-thread memory interference Prioritize requests from threads falling behind
others in a parallel for-loop
12

Time-based classification of threads as latency- vs. BW-sensitive
13
Critical Section
Barrier
Non-Critical Section
Waiting for Sync
Thread D
Thread C
Thread B
Thread A
Time
BarrierTime Interval 1
Time Interval 2
Thread Cluster Memory Scheduling (TCM) [Kim et. al., MICRO’10]

Terminology
A code-segment is defined as: A program region between two consecutive
synchronization operations Identified with a 2-tuple:
<beginning IP, lock address>
Important for classifying threads as latency- vs. bandwidth-sensitive Time-based vs. code-segment based
classification
14

Code-segment based classification of threads as latency- vs. BW-sensitive
15
Thread D
Thread C
Thread B
Thread D
Thread C
Thread B
Thread A
Time
Code-Segment Changes
Barrier
Thread A
Time
BarrierTime Interval 1
Time Interval 2
CodeSegment 1
CodeSegment 2
Critical Section
Barrier
Non-Critical Section
Waiting for Sync

Parallel Application Memory Scheduler
Identify the set of threads likely to be on the critical path as limiter threads Prioritize requests from limiter threads
Among limiter threads: Prioritize requests from latency-sensitive threads
(those with lower MPKI)
Among non-limiter threads: Shuffle priorities of non-limiter threads to reduce
inter-thread memory interference Prioritize requests from threads falling behind
others in a parallel for-loop
16

Shuffling Priorities of Non-Limiter Threads
Goal: Reduce inter-thread interference among a set of threads
with the same importance in terms of our estimation of the critical path
Prevent any of these threads from becoming new bottlenecks
Basic Idea: Give each thread a chance to be high priority in the memory
system and exploit intra-thread bank parallelism and row-buffer locality
Every interval assign a set of random priorities to the threads and shuffle priorities at the end of the interval
17

Shuffling Priorities of Non-Limiter Threads
BarrierThread AThread BThread CThread D
Barrier
Time
Thread AThread BThread CThread D
Time
Thread AThread BThread CThread D
Time
Thread AThread BThread CThread D
Barrier Barrier
Time
Thread AThread BThread CThread D
Time
Thread AThread BThread CThread D
Time
4321
321
2
1
1
Saved Cycles
Saved Cycles Saved
Lost Cycles
18
Baseline(No shuffling)
Policy 1
Threads with similar memory behavior
Policy 2
Shuffling Shuffling
4231
12
3
2
1 1
Cycles
ActiveWaiting
Legend Threads with different memory behavior
PAMS dynamically monitors memory intensities and chooses appropriate
shuffling policy for non-limiter threads at runtime

Outline
Problem Statement Parallel Application Memory Scheduling Evaluation Conclusion
19

Evaluation Methodology
x86 cycle accurate simulator
Baseline processor configuration Per-core
- 4-wide issue, out-of-order, 64 entry ROB
Shared (16-core system)- 128 MSHRs- 4MB, 16-way L2 cache
Main Memory- DDR3 1333 MHz- Latency of 15ns per command (tRP, tRCD, CL)- 8B wide core to memory bus
20

PAMS Evaluation
hist mg cg is bt ft gmean0
0.2
0.4
0.6
0.8
1
1.2
Thread cluster memory scheduler [Kim+, MICRO'10]Thread criticality prediction (TCP)-based memory schedulerParallel application memory scheduler
Norm
alize
d E
xecu
tion
Tim
e
(norm
alize
d t
o F
R-F
CFS
) 13%
21
7%
Thread criticality predictors (TCP) [Bhattacherjee+, ISCA’09]

22
Sensitivity to system parameters
-10.5%-15.9%-16.7%
L2 Cache Size
4 MB 8 MB 16 MB
Δ FR-FCFS Δ FR-FCFS Δ FR-FCFS
-10.4%-11.6%-16.7%
Number of Memory Channels
1 Channel 2 Channels 4 Channels
Δ FR-FCFS Δ FR-FCFS Δ FR-FCFS

Conclusion
Inter-thread main memory interference within a multi-threaded application increases execution time
Parallel Application Memory Scheduling (PAMS) improves a single multi-threaded application’s performance by Identifying a set of threads likely to be on the critical path and
prioritizing requests from them Periodically shuffling priorities of non-likely critical threads to
reduce inter-thread interference among them
PAMS significantly outperforms Best previous memory scheduler designed for
multi-programmed workloads A memory scheduler that uses a state-of-the-art
thread criticality predictor (TCP)
23

Parallel Application Memory Scheduling
Eiman Ebrahimi*
Rustam Miftakhutdinov*, Chris Fallin‡
Chang Joo Lee*+, Jose Joao*
Onur Mutlu‡, Yale N. Patt*
* HPS Research Group The University of Texas at
Austin‡ Computer Architecture Laboratory
Carnegie Mellon University+ Intel Corporation
Austin