padi plataformas e aplicações distribuídas na internet · padi plataformas e aplicações...
TRANSCRIPT

4.1 ©2005-15 PJPF, LAV, PR INESC-ID/IST
Distributed Transactions
PADI Plataformas e Aplicações Distribuídas na Internet

4.2
Agenda
Concurrency Control in Distributed Transactions Locking, timestamps ordering, optimistic
Distributed Deadlocks Distributed deadlocks detection, phantom deadlocks, Edge-chasing deadlock detection

4.3
Concurrency control in distributed transactions
Each server manages a set of objects and is responsible for ensuring that they remain consistent when accessed by concurrent transactions
therefore, each server is responsible for applying concurrency control to its own objects. servers involved in processing of distributed transactions are jointly responsible for ensuring their serializability therefore if transaction T is before transaction U in their conflicting access to objects at one of the servers then … they must be in that order at all of the servers whose objects are accessed in a conflicting manner by both T and U

4.4
Concurrency control in distributed transactions: Locking
In a distributed transaction, the locks on an object are held by the server that manages it.
The local lock manager decides whether to grant a lock or make the requesting transaction wait. it cannot release any locks until
it knows that the transaction has been committed or aborted at all the servers involved in the transaction.
the objects remain locked and are unavailable for other transactions during the atomic commit protocol
an aborted transaction releases its locks after phase 1 of the protocol.

4.5
Concurrency control in distributed transactions: Locking
E.g., Interleaving of transactions T , U at servers X , Y we have T before U at server X and U before T at server Y different orderings lead to cyclic dependencies and distributed deadlock (detection and resolution in next section)
T U Write(A) at X locks A
Write(B) at Y
locks B
Read(B) at Y waits for U
Read(A) at X waits for T

4.6
Timestamp ordering concurrency control Single server transactions
coordinator issues a unique timestamp to each transaction before it starts serial equivalence ensured by committing objects in order of timestamps
Distributed transactions first coordinator accessed by a transaction issues a globally unique timestamp as before the timestamp is passed with each object access the servers are jointly responsible for ensuring serial equivalence
that is if T access an object before U, then T is before U at all objects coordinators must agree on timestamp ordering
a timestamp consists of a pair <local timestamp, server-id>. the agreed ordering of pairs of timestamps is based on a comparison in which the server-id part is less significant alternative: use some centralized timestamp ordering

4.7
Timestamp ordering concurrency control The same ordering can be achieved at all servers even if their clocks are not synchronized
for efficiency it is better if local clocks are roughly synchronized then the ordering of transactions corresponds roughly to the real time order in which they were started
Timestamp ordering conflicts are resolved as each operation is performed if this leads to an abort, the coordinator will be informed
it will abort the transaction at all the participants any transaction that reaches the client request to commit should always be able to do so
participant will normally vote yes unless it has crashed and recovered during the transaction

4.8
Optimistic Concurrency Control each transaction is validated before it is allowed to commit
transaction numbers assigned at start of validation transactions serialized according to transaction numbers validation takes place in phase 1 of 2PC protocol
it can be much slower than in single-server transactions consider the following interleavings of T and U
T before U at X and U before T at Y (who validates first? deadlock?)
T U Read(A) at X Read(B) at Y Write(A) Write(B) Read(B) at Y Read(A) at X Write(B) Write(A)

4.9
Optimistic Concurrency Control If only one transaction performs validation at each server:
commitment deadlocks might occur, between transactions that need to be validated at various sites and waiting for others to commit or abort
Servers of distributed transactions do parallel validation parallel validation also checks conflicts between write operations of the transaction being validated against the write operations of other concurrent transactions. therefore rule 3 must be validated as well as rule 2
write set of Tv is checked for overlaps with write sets of earlier transactions
this prevents commitment deadlock and avoids delaying 2PC protocol To ensure transactions at different servers are globally serializable:
conduct global validation (checking there is no cyclic ordering) or use the same globally unique transaction number for the same transaction.

4.10
Distributed Deadlocks Even single server transactions can experience deadlocks
prevent or detect and resolve use of timeouts is clumsy, detection is preferable.
using wait-for graphs. Distributed transactions can lead to distributed deadlocks
in theory one can construct global wait-for graph from local ones distributed deadlock is: a cycle in a global wait-for graph that is not in local wait-for graphs
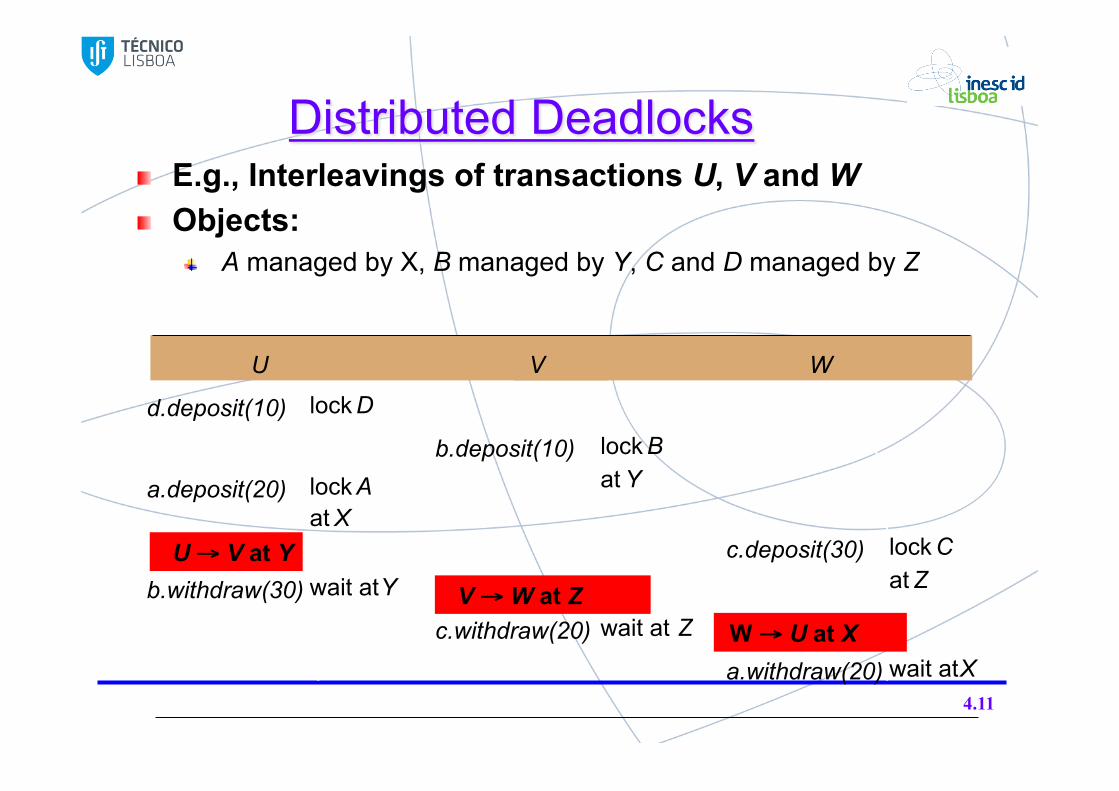
Distributed Deadlocks E.g., Interleavings of transactions U, V and W Objects:
A managed by X, B managed by Y, C and D managed by Z
4.11
U V W
d.deposit(10) lock D
b.deposit(10) lock B
a.deposit(20) lock A at Y at X
c.deposit(30) lock C
b.withdraw(30) wait at Y at Z
c.withdraw(20) wait at Z
a.withdraw(20) wait at X
• U → V at Y
• V → W at Z • W → U at X

4.12
Distributed Deadlocks • a deadlock cycle has alternate edges showing:
• transactions wait-for and objects held-by transactions • wait-for added in order: U → V at Y; V → W at Z and W → U at X
D
Waits for
Waits for
Held by
Held by
B Waits for Held
by
X
Y
Z
Held by
W
U V
A C
W
V
U

4.13
Distributed Deadlocks: Local Wait-for Graphs
Local wait-for graphs can be built, e.g. server Y: U → V added when U requests b.withdraw(30) server Z: V → W added when V requests c.withdraw(20) server X: W → U added when W requests a.withdraw(20)
But to find a global cycle, communication between the servers is needed Possible Approach: centralized deadlock detection
one server may take the role of global deadlock detector the other servers send it their local graphs from time to time it detects deadlocks, makes decisions about which transactions to abort and informs the other servers problems: usual ones with a centralized service - poor availability, lack of fault tolerance and no ability to scale

4.14
Distributed Deadlocks: Local Wait-for Graphs
Phantom-deadlock a ‘deadlock’ that is “detected”, but is not really a true deadlock i.e., when there appears to be a cycle, but one of the transactions has already released a lock, it appears due to time lags in distributing wait-for graphs E.g., suppose U releases the object at X then waits for V at Y
and the global detector gets Y’s graph before X’s global detector observes (T → U → V → T) that never really occurred 2PL forbids release and then wait but could still happen when transactions abort and information about locks in server is not renewed at central server
X
T U
Y
V T T
U V
local wait-for graph local wait-for graph global deadlock detector

4.15
Distributed Deadlocks: Distributed Detection with Edge-chasing a global graph is not constructed, but each server knows about some of the edges
servers try to find cycles by sending probes which follow the edges of the graph through the distributed system when should a server send a probe? edges were added in order U → V at Y; V → W at Z and W → U at X
when W → U at X was added, U was waiting, but when V → W at Z, W holds locks but was still not waiting
approach: send a probe when an edge T1 → T2 when T2 is waiting each coordinator records whether its transactions are active or waiting
the local lock manager tells coordinators if transactions start/stop waiting when a transaction is aborted to break a deadlock, the coordinator informs the participants: locks are removed and edges taken from wait-for graphs

4.16
Distributed Deadlocks: Distributed Detection with Edge-chasing
Algorithm steps: Initiation:
When a server notes that T starts waiting for U, where U is waiting at another server, it initiates detection by sending a probe containing the edge < T → U > to the server where U is blocked. If U is sharing a lock, probes are sent to all the holders of the lock.
Detection: Detection consists of receiving probes and deciding whether deadlock has occurred and whether to forward the probes.
• e.g. when server receives probe < T → U > it checks if U is waiting, e.g. U → V, if so it forwards < T → U → V > to server where V waits
• when a server adds a new edge, it checks whether there is a cycle Resolution:
When a cycle is detected, one of the transactions in the cycle is aborted to break the deadlock.

Distributed Deadlocks: Distributed Detection with Edge-chasing E.g., deadlock detection with edge-chasing
4.17
V
Held by W
Waits for Held by
Waits for
Waits for Deadlock detected
U
C A
B
Initiation
W U V W
W U
W U V
Z
Y
X
→ → →
→ →
→

4.18
Distributed Deadlocks: Distributed Detection with Edge-chasing
Algorithm Correctness: the edge-chasing algorithm detects deadlock provided that
waiting transactions do not abort no process crashes, no lost messages to be realistic it would need to allow for the above failures
Algorithm Performance: a probe to detect a cycle with N transactions will require 2(N-1) messages. Database studies show that average deadlock involves only 2 transactions.

4.19
Distributed Deadlocks: Distributed Detection with Edge-chasing Issues: Algorithm may lead to the same cycle being detected more than once
Safety Issues: none Performance Issues: multiple detections may lead to the unnecessary aborting of multiple transactions in the same deadlock.
A single one would be enough to break the cycle. How to avoid this performance penalty ?
(a) initial situation (b) detection initiated at object requested by T
U
T
V
W
Waits for
Waits for
V
W
U
T
T → U → W → V T → U → W
T → U Waits for
U
V
T
W
W → V → T W → V → T → U
W → V
Waits for
(c) detection initiated at object requested by W

4.20
Distributed Deadlocks: Distributed Detection with Edge-chasing How to prevent unnecessary aborts?
ensuring every server decides on the same transaction as selected for abort and break the deadlock
Approach: Transactions are given priorities so that transactions are totally ordered when deadlock is detected:
transaction with lower priority in the wait-for cycle is aborted even if several different servers detect the same cycle
• they will reach same decision on transaction to abort e.g., if T>U>V>W, then W will be the only one aborted
detections may start only when higher-priority starts to wait for lower-priority transactions (reducing messages to half)

4.21
Distributed Concurrency Control and Deadlock Handling
each server is responsible for the serializability of transactions that access its own objects. additional protocols are required to ensure that transactions are serializable globally.
timestamp ordering requires a globally agreed timestamp ordering optimistic concurrency control requires global validation or a means of forcing a global ordering on transactions. two-phase locking can lead to distributed deadlocks.
distributed deadlock detection looks for cycles in the global wait-for graph. edge chasing is a non-centralized approach to the detection of distributed deadlocks
4.22
Summary
Concurrency Control in Distributed Transactions Locking, timestamps ordering, optimistic
Distributed Deadlocks Distributed deadlocks detection, phantom deadlocks, Edge-chasing deadlock detection

Distributed Deadlocks: Distributed Detection with Edge-chasing coordinators save probes received in a probe queue forwards the probes only when it starts waiting for an object server of the object propagates probes on “down-hill” routes
(a) V stores probe when U starts waiting (b) Probe is forwarded when V starts waiting
4.23
U
W
V probe queue U V
Waits for B Waits for
B
Waits for C
V W U V
V U V
U V U
W probe queue
→ →
→
→
→

4.24
Distributed Deadlocks: Distributed Detection with Edge-chasing How to prevent unnecessary aborts?
ensuring every server decides on the same transaction as selected for abort and break the deadlock
Approach: Probes travel only “down-hill” from transactions with higher-priority to lower-priority ones servers do not forward any probe to holder with higher priority than the initiator
If holder is waiting for another transaction, it must have sent a probe when it started waiting
but order of start waiting may influence deadlock detection solution requires queueing probe messages at coordinators