overview of nit hmm-based speech synthesis system for blizzard challenge 2011 kei hashimoto, shinji...
TRANSCRIPT

Overview of NIT HMM-basedspeech synthesis system
for Blizzard Challenge 2011
Kei Hashimoto, Shinji Takaki, Keiichiro Oura,
and Keiichi Tokuda
Nagoya Institute of Technology
2 September, 2011

Background
HMM-based speech synthesis Quality of synthesized speech depends on
acoustic models Model estimation is one of the most important
problem
Appropriate training algorithm is required Deterministic annealing EM (DAEM) algorithm
To overcome the local maxima problem Step-wise model selection
To perform the joint optimization of model structures and state sequences
2

Outline
HMM-based speech synthesis system
Deterministic annealing EM (DAEM) algorithm
Step-wise model selection
Experiments
Conclusion & future work
3

Overview of HMM-based system
4
Speech signal
Label
Contest-dependent HMMs & duration models Training part
Label
Spectralparameters
Synthesis part
Synthesizedspeech
Speechdatabase
Excitation parametersextraction
Spectral parametersextraction
Training of HMM
Parameter generationfrom HMM
Text analysis
Excitationparameters
Synthesisfilter
Excitationgeneration
TEXT

Base techniques
Hidden semi-Markov Model (HSMM) HMM with explicit state duration probability dist. Estimate state output and duration probability dists.
STRAIGHT A high quality speech vocoding method Spectrum, F0, and aperiodicity measures
Parameter generation considering GV Calculate GV features from only speech region
excluding silence and pause Context dependent GV models
5

Outline
HMM-based speech synthesis system
Deterministic annealing EM (DAEM) algorithm
Step-wise model selection
Experiments
Conclusion & future work
6

EM algorithm
Maximum likelihood (ML) criterion
Expectation Maximization (EM) algorithm
7
: Model parameter: Training data: HMM state seq.
・ E-step:
・ M-step:
Occur the local maxima problem

DAEM algorithm
Posterior probability
Model update process
8
: Temperature parameter
・ E-step:
・ M-step:
・ Increase temperature parameter

Optimization of state sequence
Likelihood function in the DAEM algorithm
9
Time
All state sequences have uniform probability
State output probability State transition probability

Optimization of state sequence
Likelihood function in the DAEM algorithm
10
Time
Change from uniform to sharp
State output probability State transition probability

Optimization of state sequence
Likelihood function in the DAEM algorithm
11
Time
State output probability
Estimate reliable acoustic models
State transition probability

Outline
HMM-based speech synthesis system
Deterministic annealing EM (DAEM) algorithm
Step-wise model selection
Experiments
Conclusion & future work
12

Problem of context clustering
Context-dependent model Appropriate model structures are required
Decision tree based context clustering
Assumption: state occupancies are not changed State occupancies depend on model structures State sequences and model structures should be
optimized simultaneously13
/a/? Silence?
Vowel?

Step-wise model selection
Gradually change the size of decision tree
Perform joint optimization of model structures and state sequences
Minimum Description Length (MDL) criterion
14: Dimension of feature vec.: Number of nodes
: Amount of training data assigned to the root node
: Tuning parameter

Model training process
1. Estimate monophone models (DAEM) # of temperature parameter updates is 10 # of EM-steps at each temperature is 5
2. Select decision trees by the MDL criterion using the tuning parameter
3. Estimate context-dependent models (EM) # of EM-steps is 5
4. Decrease the tuning parameter Tuning parameter decreases as 4, 2, 1
5. Repeat from step. 2
15

Outline
HMM-based speech synthesis system
Deterministic annealing EM (DAEM) algorithm
Step-wise model selection
Experiments
Conclusion & future work
16

Speech analysis conditions
17
Training data10,000 utterances
(pruned by the alignment likelihood)
Sampling rate 48 kHz
Window F0-adaptive Gaussian window
Frame shift 5 ms
Feature vector
49-dim. STRAIGHT mel-cepstrum, log F0
26 band-filtered aperiodicity measure
+ Δ + ΔΔ (231 dimension)
HMM5-state left-to-right HSMM
without skip transition
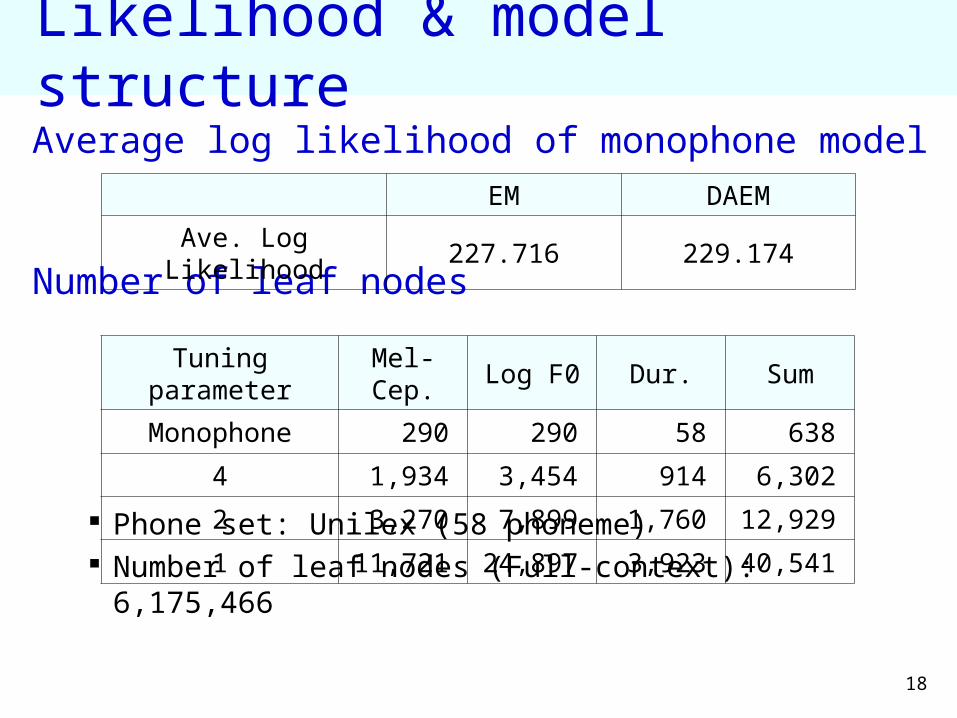
Likelihood & model structure
Average log likelihood of monophone model
Number of leaf nodes
Phone set: Unilex (58 phoneme) Number of leaf nodes (Full-context): 6,175,466
18
EM DAEM
Ave. Log Likelihood 227.716 229.174
Tuning parameter Mel-Cep. Log F0 Dur. Sum
Monophone 290 290 58 638
4 1,934 3,454 914 6,302
2 3,270 7,899 1,760 12,929
1 11,721 24,897 3,923 40,541
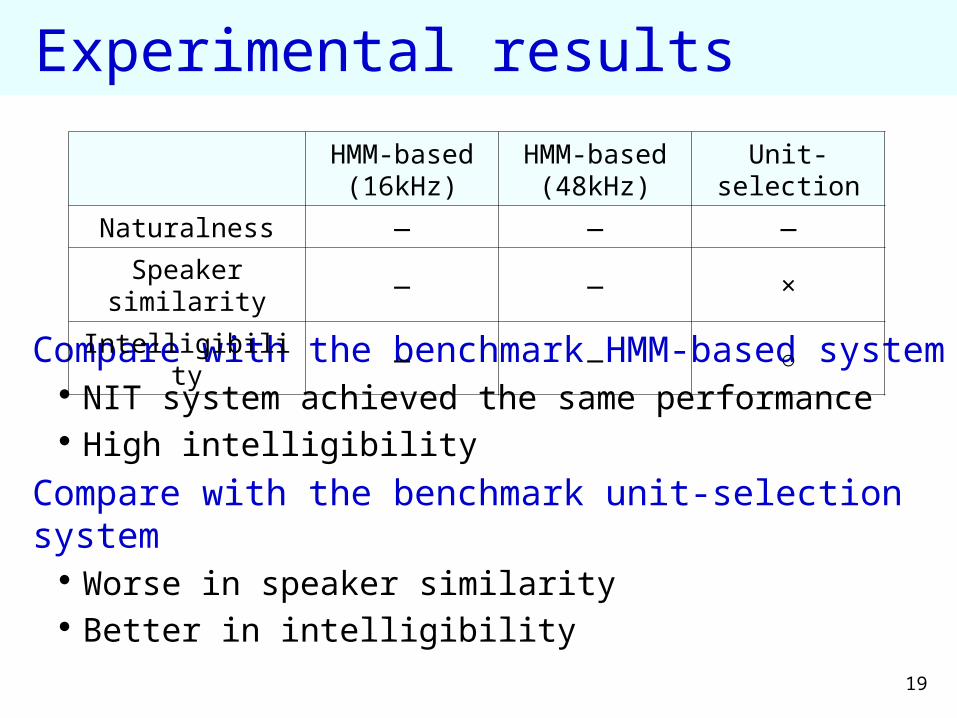
Experimental results
Compare with the benchmark HMM-based system NIT system achieved the same performance High intelligibility
Compare with the benchmark unit-selection system Worse in speaker similarity Better in intelligibility
19
HMM-based(16kHz)
HMM-based(48kHz)
Unit-selection
Naturalness ― ― ―
Speaker similarity ― ― ×
Intelligibility ― ― ○

Speech samples
Generate high intelligible speech Include voiced/unvoiced errors Need to improve feature extraction and excitation
20
Speech samples
Original
NIT system

Conclusion
NIT HMM-based speech synthesis system DAEM algorithm
Overcome the local maxima problem Step-wise model selection
Perform joint optimization of state sequences and model structures
Generate high intelligible speech
Future work Improve feature extraction and excitation Investigate the schedule of temperature parameters
and step-wise model selection21

Thank you