overview - freie universitätuserpages.fu-berlin.de/digga/06/06_regex.pdf · overview day one 0....
TRANSCRIPT
Overview
day one
0. getting set up
1. text output and manipulation
day two
2. reading and writing files
3. lists and loops
day three
4. writing functions
5. conditional statements
today
6. regular expressions
7. dictionaries
day five
8. files, programs and user input
day six
9. biopython
This course (apart from chapter 9) is based on the book "Python for Biologists":
http://pythonforbiologists.com/

from scratch
A primer for scientists working with Next-Generation-Sequencing data
CHAPTER 6
Regular expressions
Overview
day one
0. getting set up
1. text output and manipulation
day two
2. reading and writing files
3. lists and loops
today
4. writing functions
5. conditional statements
day four
6. regular expressions
7. dictionaries
day five
8. files, programs and user input
day six
9. biopython
This course (apart from chapter 9) is based on the book "Python for Biologists":
http://pythonforbiologists.com/

Searching for patterns in strings
In biological data, many things of interest can be regarded as string patterns:
● protein domains
● DNA transcription factor binding motifs
● restriction enzyme cut sites
● degenerate PCR primer sites
● runs of mononucleotides
Regular expressions are a tool for searching patterns in strings, also referred to as pattern matching

Regular expressions in the Unix world
Linux/Unix tools that use regular expressions:
● grep → basically a regex search engine
● awk
● sed
● Perl
● less
actually programming languages, but can be called from the command line

Regular expressions are powerful
We already searched for simple patterns in chapter 5:
Testing the same conditions using a regular expression:
if name.startswith('k') and name.endswith('h'):[...]
if re.match("k.*h", name):[...]

Python modules
● regular expressions are made available as a module
● modules are a way to provide additional functionality when you need it
● advantages of modules:
– the python language is extensible
– avoiding overhead → better performance (most programs do only need basic functionality)
● modules contain
– functions
– data types (+ methods)
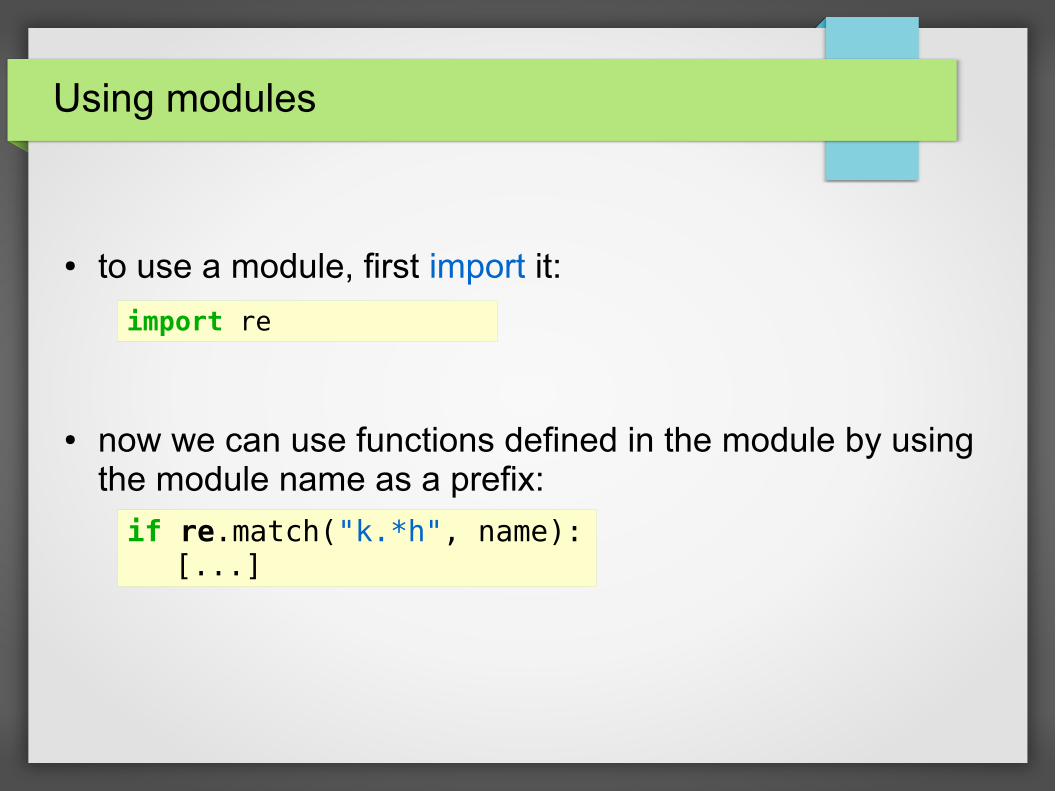
Using modules
● to use a module, first import it:
● now we can use functions defined in the module by using the module name as a prefix:
import re
if re.match("k.*h", name):[...]

Raw strings
● brevity comes at a price: we need a lot of special characters
● to avoid ambiguities in regex's, we can tell python to ignore special characters:
(the 'r' means "raw")
● this way, regex special characters cannot clash with python ones
print("\t\n") vs. print(r"\t\n")print("\t\n")

Searching for patterns
● Let's find a restriction enzyme's recognition site within a DNA sequence (EcoRI cuts the pattern "GAATTC"):
● a more interesting case (AvaII cuts the pattern "GGWCC"):
→ "(A|T)" = "A" or "T"
dna = "CTTAGAATTCCG"if re.search(r"GAATTC", dna):
print("EcoRI recognition site found!")
dna = "CTTAGAATTCCG"if re.search(r"GG(A|T)CC", dna):
print("AvaII recognition site found!")

Character classes
● This regex will match BisIs recognition site(BisI cuts the pattern "GCNGC"):
● But we can make it shorter by using a character class:
→ "[ACGT]" = "A" or "C" or "G" or "T"
dna = "CTTAGAATTCCG"if re.search(r"GC(A|C|G|T)GC", dna):
print("BisI recognition site found!")
dna = "CTTAGAATTCCG"if re.search(r"GC[ACGT]GC", dna):
print("BisI recognition site found!")

Matching arbitrary characters
● If we do not care about a certain position, we use a dot ('.') which matches any character:
● "GC.GC" matches the same strings as "GC[ACGT]GC", but also other ones, e.g.
– "GCNGC", "GCWGC", "GCXGC", "GC8GC", "GC#GC"
→ "." = any alphanumeric character(letters, numbers, symbols)
except newlines ('\n')
dna = "CTTAGAATTCCG"if re.search(r"GC.GC", dna):
print("BisI recognition site found!")

Excluding characters
● Sometimes you want to specify what not to match; this can be done by negating a character class with a caret ('^'):
● "GC[^N]GC" matches the same strings as "GC.GC", except it specifically excludes "GCNGC"
→ "[^N]" = any alphanumeric character(letters, numbers, symbols)
except 'N' (and newlines ('\n')...)
dna = "CTTAGAATTCCG"if re.search(r"GC[^N]GC", dna):
print("BisI recognition site found!")

Quantifiers
● what if we have (sub)patterns of variable length?
● quantifiers enable us to specify how often a certain part of a pattern can be repeated
● remember our earlier example:
matches a string starting with 'k' and ending with 'h',
having an arbitrary number (0 to infinity) of characters in between
● quantifiers (in this case '*') are specified after the pattern (here: '.') they belong to
if re.match("k.*h", name):[...]

More quantifiers
The following operators can be used in simple comparisons:
quantifier ocurrences examples
? 0 to 1 "ACG?T" ~ "ACT", "ACGT"
* 0 to infinity"ACG*T" ~ "ACT", "ACGT", "ACGGT", "ACGGGT", ...
+ 1 to infinity"ACG+T" ~ "ACGT", "ACGGT", "ACGGGT", ...
{n} exactly n times "ACG{2}T ~ "ACGGT"
{n,m} n to m times"ACG{2,4} ~ "ACGGT", "ACGGGT", "ACGGGGT"
{n,} n to infinity times "ACG{2,4} ~ "ACGGT", "ACGGGT", "ACGGGGT", ...

Positions
● Sometimes it is important where the pattern is found
● There are two positional operators:
● These operators make sense when used with re.search but not with re.match (always matches entire string or not)
quantifier matches
^ beginning of string
$ end of string
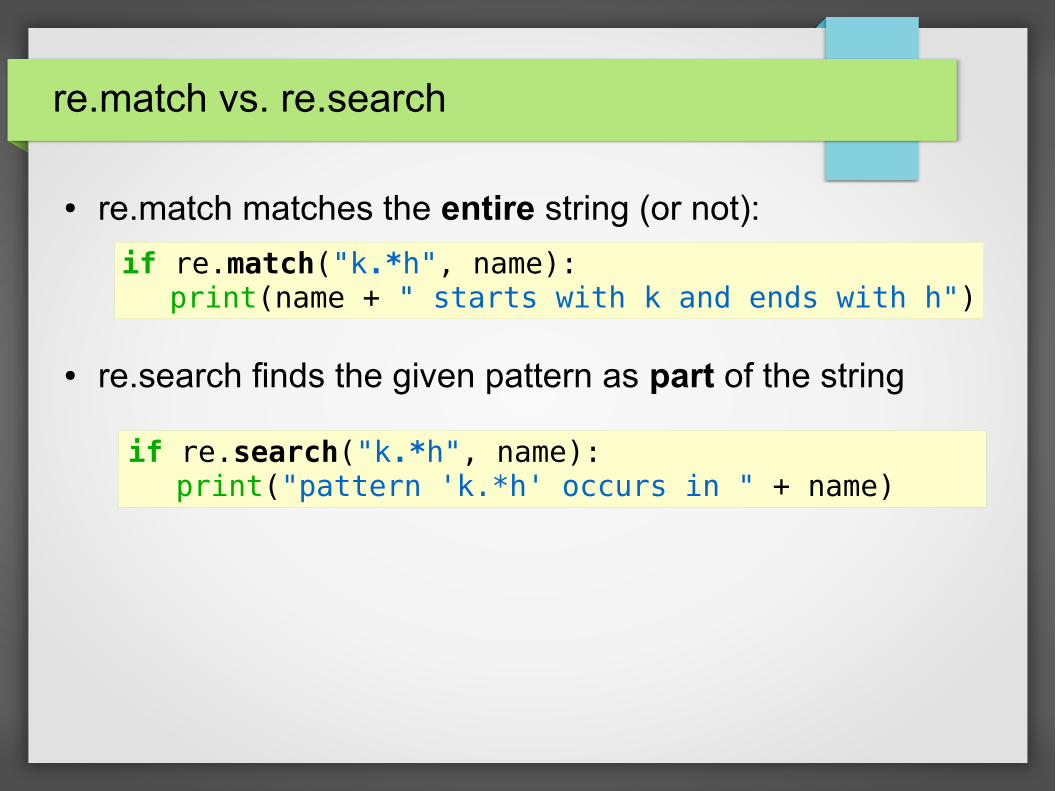
re.match vs. re.search
● re.match matches the entire string (or not):
● re.search finds the given pattern as part of the string
if re.match("k.*h", name):print(name + " starts with k and ends with h")
if re.search("k.*h", name):print("pattern 'k.*h' occurs in " + name)

Combinations
● the true power of regexes lies in the combination of the different operators
● Here's an example regex that identifies eukariotic messenger RNA sequences:
"^AUG[ACGU]{30,1000}A{5,10}$"
● Read from left to right:
– ^AUG: starts with AUG
– [ACGU]{30,1000}: followed by 30 to 1000 nucleotides
– A{5,10}$: ended by 5 to 10 A's

Quantifiers
● what if we have (sub)patterns of variable length?
● quantifiers enable us to specify how often a certain part of a pattern can be repeated
● remember our earlier example:
matches a string starting with 'k' and ending with 'h',
having an arbitrary number (0 to infinity) of characters in between
● quantifiers (in this case '*') are specified after the pattern (here: '.') they belong to
if re.match("k.*h", name):[...]
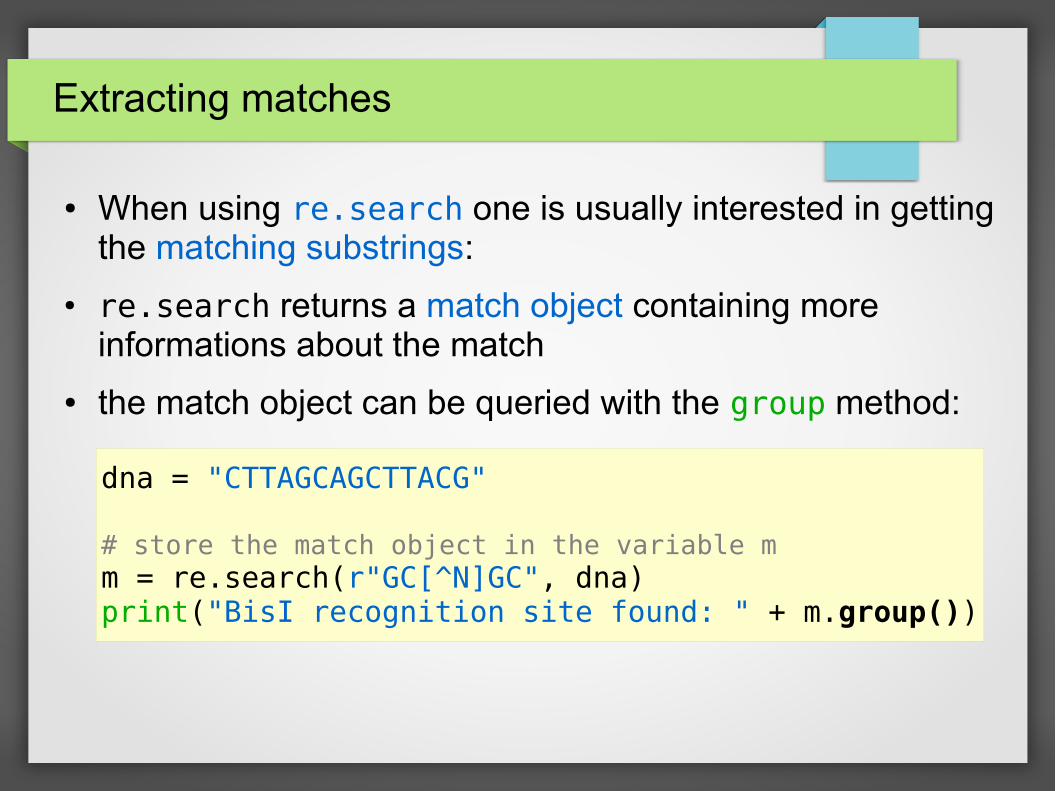
Extracting matches
● When using re.search one is usually interested in getting the matching substrings:
● re.search returns a match object containing more informations about the match
● the match object can be queried with the group method:
dna = "CTTAGCAGCTTACG"
# store the match object in the variable mm = re.search(r"GC[^N]GC", dna)print("BisI recognition site found: " + m.group())
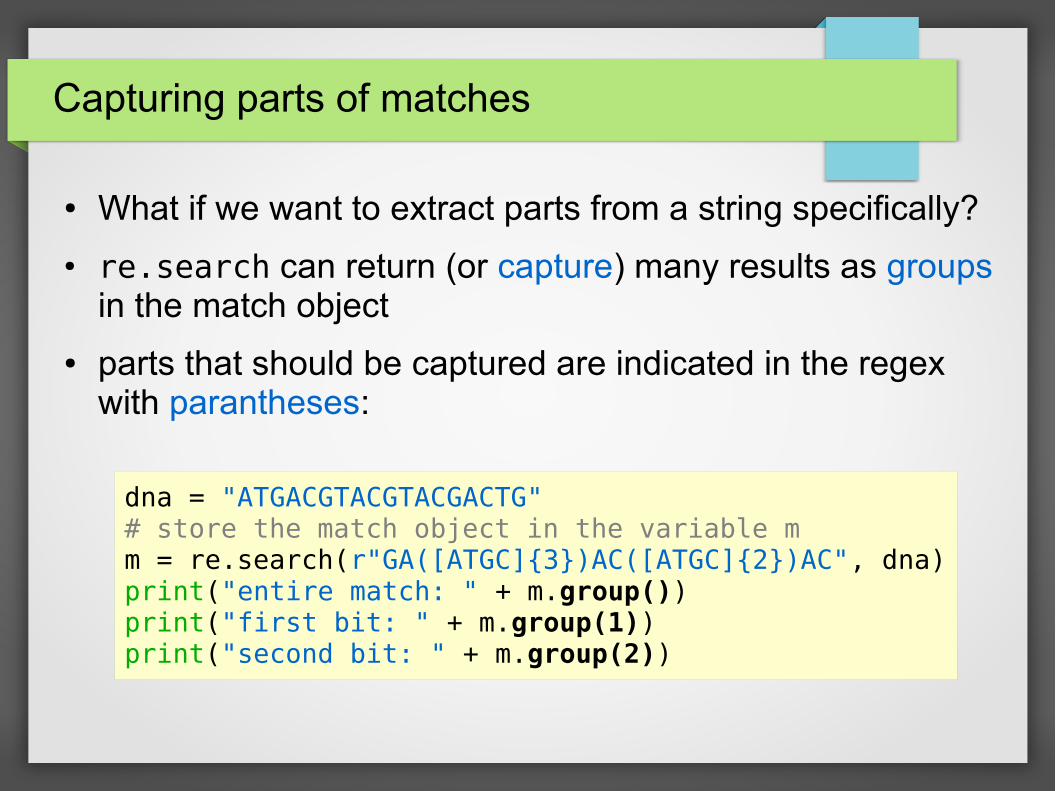
Capturing parts of matches
● What if we want to extract parts from a string specifically?
● re.search can return (or capture) many results as groups in the match object
● parts that should be captured are indicated in the regex with parantheses:
dna = "ATGACGTACGTACGACTG"# store the match object in the variable mm = re.search(r"GA([ATGC]{3})AC([ATGC]{2})AC", dna)print("entire match: " + m.group())print("first bit: " + m.group(1))print("second bit: " + m.group(2))
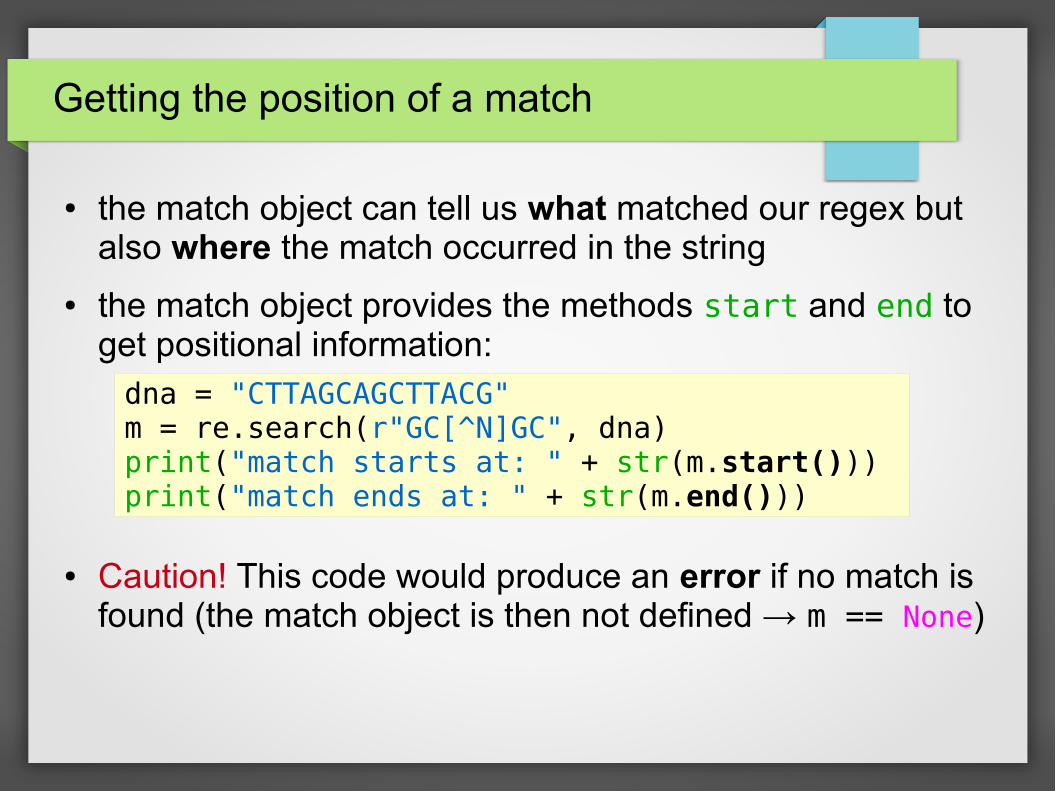
Getting the position of a match
● the match object can tell us what matched our regex but also where the match occurred in the string
● the match object provides the methods start and end to get positional information:
● Caution! This code would produce an error if no match is found (the match object is then not defined → m == None)
dna = "CTTAGCAGCTTACG"m = re.search(r"GC[^N]GC", dna)print("match starts at: " + str(m.start()))print("match ends at: " + str(m.end()))

Getting the position of multiple matches
● as with group, we can access information about each match by addressing it by its index:
● Caution! This code would produce an error if no match is found (the match object is then not defined → m == None)
dna = "ATGACGTACGTACGACTG"m = re.search(r"GA([ATGC]{3})AC([ATGC]{2})AC", dna)print("whole match: "+str(m.start())+" to "+str(m.end()))print("1st bit: "+str(m.start(1))+" to "+str(m.end(1)))print("2nd bit: "+str(m.start(2))+" to "+str(m.end(2)))
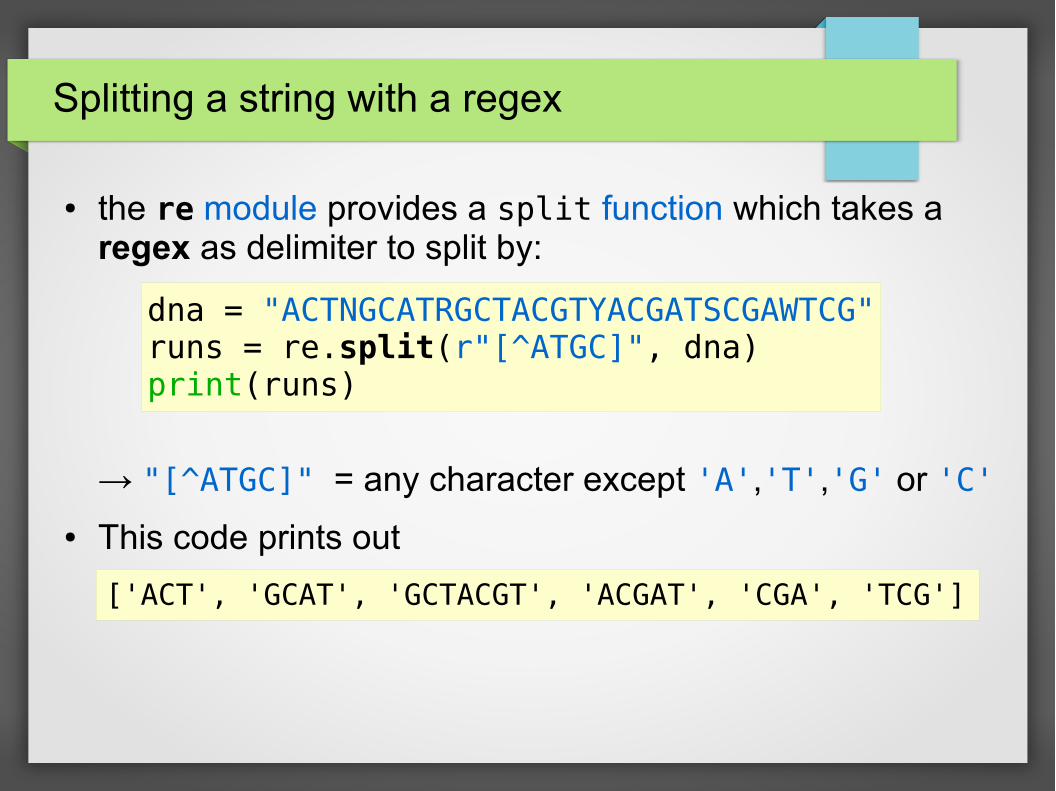
Splitting a string with a regex
● the re module provides a split function which takes a regex as delimiter to split by:
→ "[^ATGC]" = any character except 'A','T','G' or 'C'
● This code prints out
dna = "ACTNGCATRGCTACGTYACGATSCGAWTCG"runs = re.split(r"[^ATGC]", dna)print(runs)
['ACT', 'GCAT', 'GCTACGT', 'ACGAT', 'CGA', 'TCG']
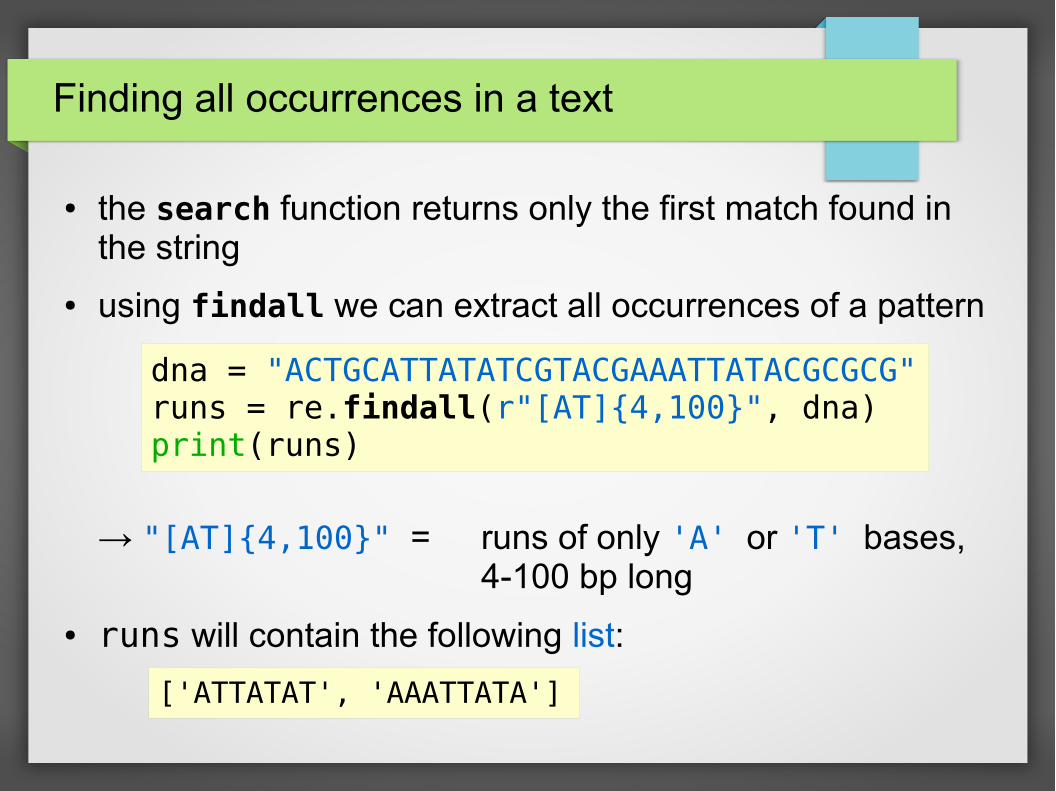
Finding all occurrences in a text
● the search function returns only the first match found in the string
● using findall we can extract all occurrences of a pattern
→ "[AT]{4,100}" = runs of only 'A' or 'T' bases,4-100 bp long
● runs will contain the following list:
['ATTATAT', 'AAATTATA']
dna = "ACTGCATTATATCGTACGAAATTATACGCGCG"runs = re.findall(r"[AT]{4,100}", dna)print(runs)
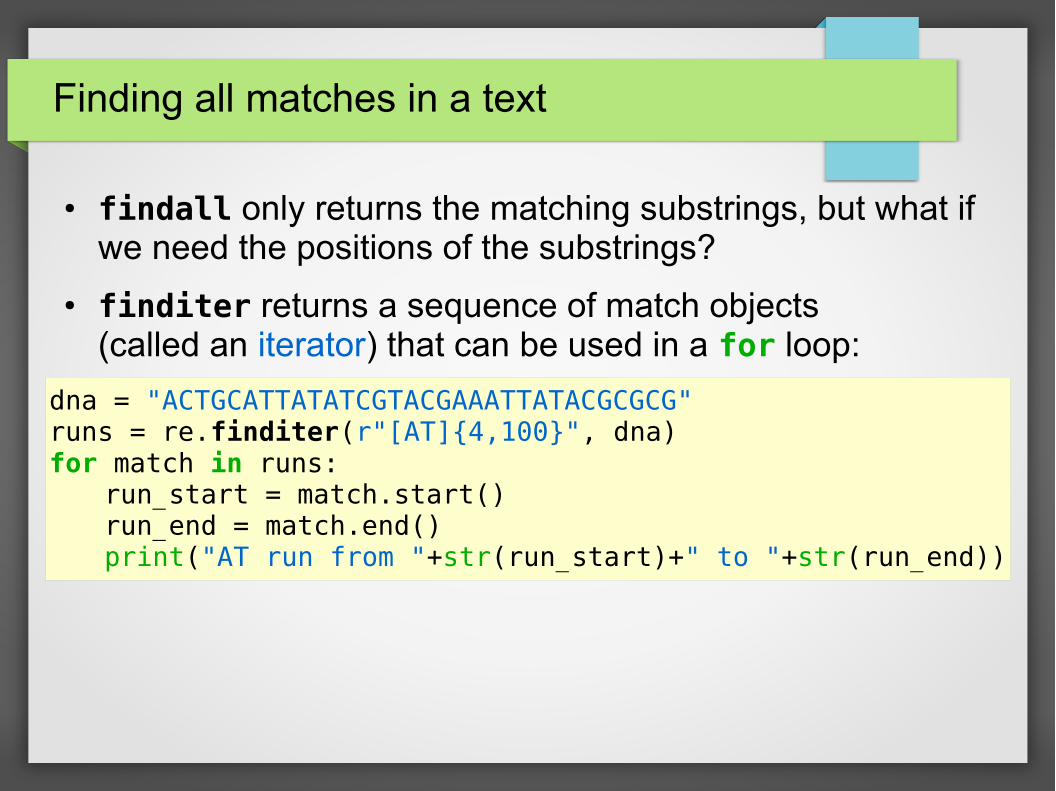
Finding all matches in a text
● findall only returns the matching substrings, but what if we need the positions of the substrings?
● finditer returns a sequence of match objects (called an iterator) that can be used in a for loop:
dna = "ACTGCATTATATCGTACGAAATTATACGCGCG"runs = re.finditer(r"[AT]{4,100}", dna)for match in runs:
run_start = match.start()run_end = match.end()print("AT run from "+str(run_start)+" to "+str(run_end))

Recap
In this unit you learned about:
● the notion of modules in python
● the concept and syntax of regular expressions
● using raw strings to avoid special character clashes
● how to use the re module to find occurrences of patterns in a text
● how to extract information from match objects
● splitting strings with regular expressions

Recap
Here is a shortlist of functions provided by the re module:
function applicationre.match returns a match object if the pattern matches the
whole string
re.search returns the first matching substring for a pattern
re.findall returns a list of all substrings matching the pattern
re.finditer returns a sequence of match objects representing all occurrences of the pattern
re.split splits a text at each occurrence of the pattern

Recap
These methods can be used to extract information from a match object:
method applicationgroup returns the substring matching the pattern
(indexable, i.e. if more than one group was captured by the regex, each group can be addressed by its index)
start returns the start position of a (sub)match (indexable)
end returns the end position of a (sub)match (indexable)

Exercise 6-1: Accession names
● Write a script that reads a set of succession names from file "accessions.txt" (comma-separated list)
● print the accessions fulfilling the following criteria:
a) contain the number 5
b) contain the letter d or e
c) contain the letters d and e (in that order)
d) contain the letters d and e (in that order) with a letter in between
e) contain the letters d and e (in any order)
f) start with x or y and end with e
g) contain 3 or more numbers in a row
h) end with d followed by either a, r or p

Exercise 6-2: Double digest
● read the DNA sequence in file dna.txt
● predict the fragments lengths we would get by digesting the sequence with the (made-up) restriction enzymes
– AbcI: cutting site "ANT*AAT"
– AbcII: cutting site "GCRW*TG"
(asterisks indicate where the enzyme cuts the DNA)