optimizing multilingual search in solr
TRANSCRIPT

Optimizing Multilingual Search
Principal Software Engineer, Basis Technology
David Troiano

Talk Overview
• The problem we’re trying to solve
• Natural language processing (NLP)
• Approaches to multilingual search in Solr

A Multilingual Search Example

The Goal
• Build a search engine where:
• Document corpus spans multiple languages
– Potentially mixed language documents
• Queries within a language, or potentially spanning multiple

NLP Meets Search (Querying)
Terms
Inverted Index
term document IDs
... ...
clinton …, 123, ...
... ...
speak …, 123, ...
query: “clinton speaking”
NLP pipeline
clinton, speak

NLP Meets Search (Indexing)
Document 123
Terms
Inverted Index
NLP pipeline
Bill Clinton spoke about ...
term document IDs
... ...
clinton …, 123, ...
... ...
speak …, 123, ...
bill, clinton, speak, about

NLP Meets Search
Terms
Inverted Index
term document IDs
... ...
clinton …, 123, ...
... ...
speak …, 123, ...
Document 123
NLP pipeline
Bill Clinton spoke about ...
bill, clinton, speak, about
query: “clinton speaking”
NLP pipeline
clinton, speak

The NLP Pipeline
• Language Detection
• Tokenization
• Decompounding
• Word Form Normalization

Language Detection
• Often required when indexing
• Typically not used at query time
– Lower accuracy on short strings
– Sometimes unsolvable even to humans, e.g., named entities
– End user applications often know query language upstream of search engine
– No readily available plugin pattern in Solr

Tokenization
• Breaking text into words
• Particularly difficult with CJK languages
– Find the words: 帰国後ハーバード大学に入学を認められていたもの

Decompounding
• Breaking compound words into subcomponents
• Common in German, Dutch, Korean
– Samstagmorgen Samstag, morgen

Word Form Normalization
• Reduce word form variations to a canonical representation
• Critical for recall
• Two approaches
– Stemming
– Lemmatization

Normalization: Stemming
• Simple rules-based approach
• “Chop off the end”
– arsenal, arsenic arsen

Normalization: Lemmatization
• Map words to their dictionary form via morphological analysis
• spoke, speaks, speaking speak
• Higher precision and recall compared to stemming

NLP Meets Search
Terms
Inverted Index
term document IDs
... ...
clinton …, 123, ...
... ...
speak …, 123, ...
Document 123
NLP pipeline
Bill Clinton spoke about ...
bill, clinton, speak, about
query: “clinton speaking”
NLP pipeline
clinton, speak
Solr

NLP Within Solr
• Maximal precision / recall requires NLP pipeline per language
• NLP pipeline (mostly) specified within Solr field type
• Index / query strategies in Solr
– Field per language
– Core per language
– A new approach: Single multilingual field

Field Per Language
schema.xml<field name="content_cjk" type="text_cjk" indexed="true" stored="true" /><field name="content_eng" type="text_eng" indexed="true" stored="true" />
<fieldType name="text_cjk" class="solr.TextField" positionIncrementGap="100"><analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/><filter class="solr.CJKWidthFilterFactory"/><filter class="solr.CJKBigramFilterFactory"/>
</analyzer></fieldType>
queryhttp://<solr
url>/solr/articles/select?q=serie%20a&defType=edismax&qf=content_cjk%20content_eng

Field Per Language
http://<solr url>/solr/articles/select?q=serie%20a&defType=edismax&qf=content_cjk%20content_engq=serie%20a

Field Per Language
http://<solr url>/solr/articles/select?q=serie%20a&defType=edismax&qf=content_cjk%20content_engdefType=edismax

Field Per Language
http://<solr url>/solr/articles/select?q=serie%20a&defType=edismax&qf=content_cjk%20content_engqf=content_cjk%20content_eng

Core Per Language
CJK core’s schema.xml
<field name="content" type="text_cjk" indexed="true" stored="true" multiValued="true"/>
<fieldType name="text_cjk" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.CJKWidthFilterFactory"/>
<filter class="solr.CJKBigramFilterFactory"/>
</analyzer>
</fieldType>
query
http://.../select?q=content:serie%20a&shards=<url>/articles_cjk,<url>/articles_eng

Core Per Language
http://.../select?q=content:serie%20a&shards=<url>/articles_cjk,<url>/articles_engq=content:serie%20a

Core Per Language
http://.../select?q=content:serie%20a&shards=<url>/articles_cjk,<url>/articles_engshards=<url>/articles_cjk,<url>/articles_eng
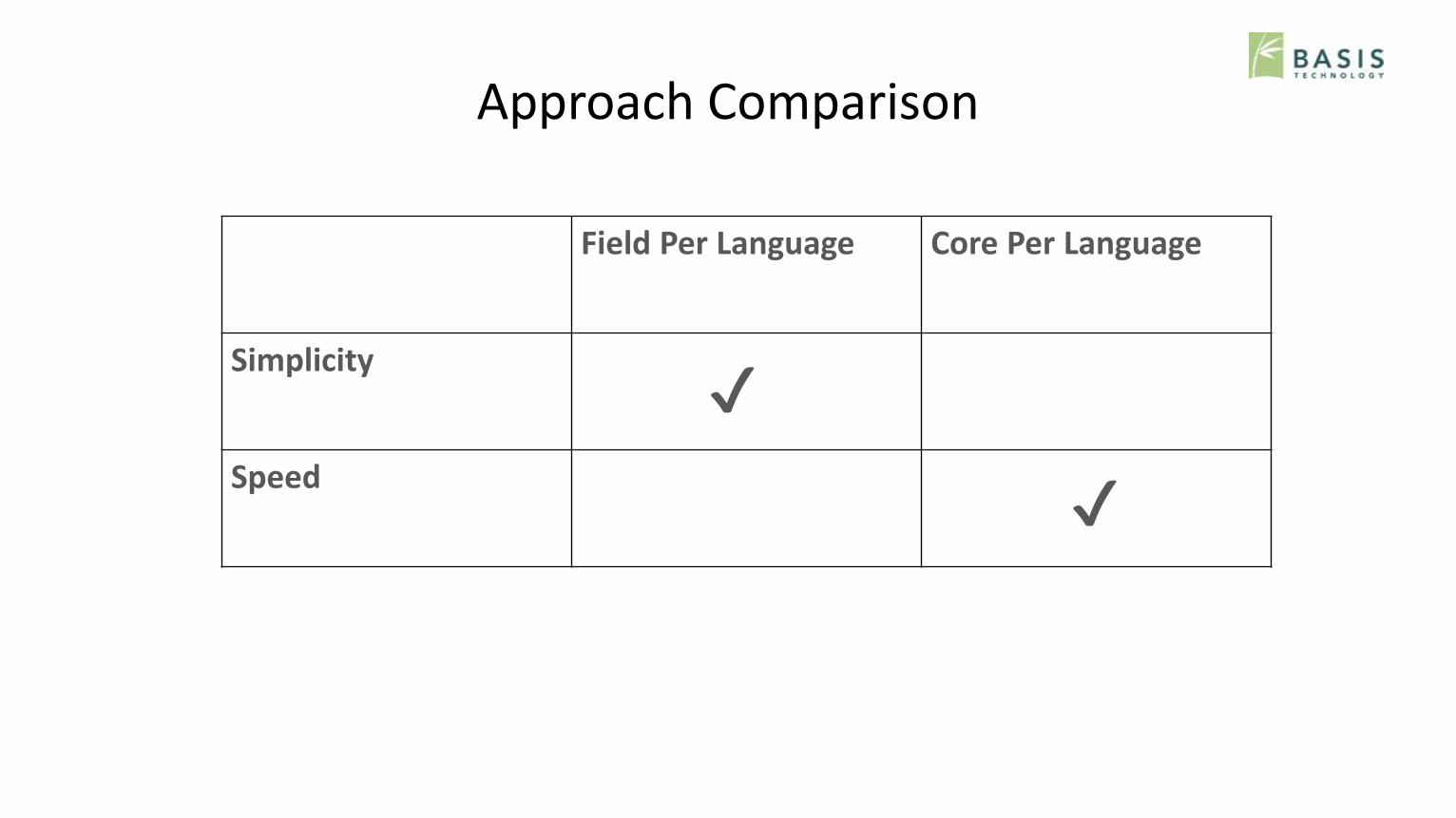
Approach Comparison
Field Per Language Core Per Language
Simplicity
Speed
✔
✔

Approach Comparison: Query Latency
• Experimental Setup
• Corpus: Wikipedia across 9 languages (9 million articles)
• Queries: 1000 most frequently used terms for each language, randomized
• JMeter running 1 hour for each of 6 test runs
0
20
40
60
80
100
120
140
160
1 4 9
Field per lang
Core per lang
Avg
late
ncy
(m
s)
# languages queried

An Alternative Approach
• All languages in a single field
• Requires custom meta field type that is applies per-language concrete field type(s)
• Patch submitted to Solr
• cf. Solr In Action / Trey Grainger
• https://github.com/treygrainger/solr-in-action

An Alternative Approach
Terms
Inverted Index
term document IDs
... ...
clinton …, 123, ...
... ...
speak …, 123, ...
query: “[en, es]clinton speaking”
Inspect [en, es], apply English and Spanish field types to “clinton speaking”, merge results
clinton, speak

An Alternative Approach
• Results scoring potentially worse than other approaches
• IDF thrown off with single field
– e.g., soy common in Spanish, relatively rare in English
– Consider a query for “soy dessert recipe” against a corpus of English and Spanish recipes
– Though IDF of named entity tokens perhaps better with a single field…

Enhancing NLP Pipeline
• Limitations of NLP in Solr out of the box
• Poor precision / performance of CJK tokenization
• Poor precision / recall of stemmers (no lemmatizers)
• Poor recall due to lack of decompounding
Rosette to the rescue!

CJK Tokenization
ケネディはマサチューセッツ
Rosette: ケネディ, は, マサチューセッツ
Bigrams: ケネ, ネデ, ディ, ィは, はマ, マサ, サチ, チュ, ュー, ーセ, セッ, ッツ
How does this impact precision, recall, index size, speed?

Rosette In Solr
<fieldType name="text_zho" class="solr.TextField"><analyzer type="index">
<tokenizerclass="com.basistech.rosette.lucene.BaseLinguisticsTokenizerFactory"rootDirectory="<rootDir>"language="zho" />
<filterclass="com.basistech.rosette.lucene.BaseLinguisticsTokenFilterFactory"rootDirectory="<rootDir>"language="zho" />
</analyzer></fieldType>
cf. http://www.basistech.com/search-essentials/

Wrapping Up
• Multilingual search is everywhere
• Solr as your multilingual search platform
• Search quality hinges on quality of NLP tools

Optimizing Multilingual Search
• David Troiano
• Principal Software Engineer, Basis Technology