optimizing costs and efficiency of aws services
TRANSCRIPT

New York
©2015, Amazon Web Services, Inc. or its affiliates. All rights reserved

©2015, Amazon Web Services, Inc. or its affiliates. All rights reserved
Optimizing Cost and Efficiency on AWS
Michael Snyder Partner Development Manager / Cloud Economics Virtual Team
A Couple Assumptions…
1. You’re using AWS… 2. You like it!!

But maybe you are spending more than you planned…

Or you’d just like to spend less
Cost Optimization Is…
Going From:
• Paying for what you use
To:
• Paying for what you need

What should you do?

We’ll Talk Through Some…
Frameworks Tools Best Practices

…And
Some examples from other
customers like you

Cost Optimization Strategies: Policies and Processes

1. Limit Resource Provisioning…

By Controlling Who Can Provision Resources…
2. Understand What is Deployed and What it Costs…

By Employing Tags…
• Key (Attribute): 127 Unicode characters
• Value (Detail/Description): 255 Unicode characters
• Tags per resource: 10 tags
Jane_Doe

…And Using The Different Types of Tags Appropriately
Resource Tags
• Provide the ability to organize and search within and across resources • Filterable and Searchable • Do not appear in Detail Billing Report
Cost Allocation Tags
• Provide the ability to map AWS charges to organizational attributes for accounting purposes
• Information presented in Detailed Billing Report and Cost Explorer (must be explicitly selected)
• Only available on certain services or limited to components within a service (e.g. S3 bucket but not objects)

Tag Key Examples
Cost Center
Business Unit
Environ. Tier
Owner
Dept./ Group
Product / Application
Shutdown Time
Support Contact Endpoint
Backup

Customer Example
Large Financial Services Customer
“No tags? No instance”

3. Proactively Monitor Your Account Billing Usage…

By Using Detailed Billing Reports and Enabling Billing Alerts…
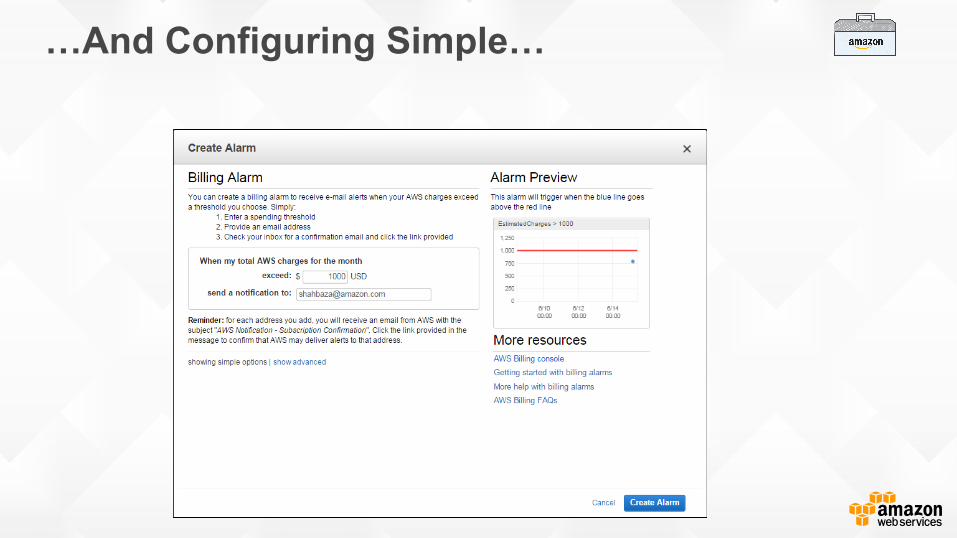
…And Configuring Simple…

…Or Advanced Alarms in CloudWatch…

…Alongside Cost Explorer
http://amzn.to/1zHE2Fj

Cost Explorer Example
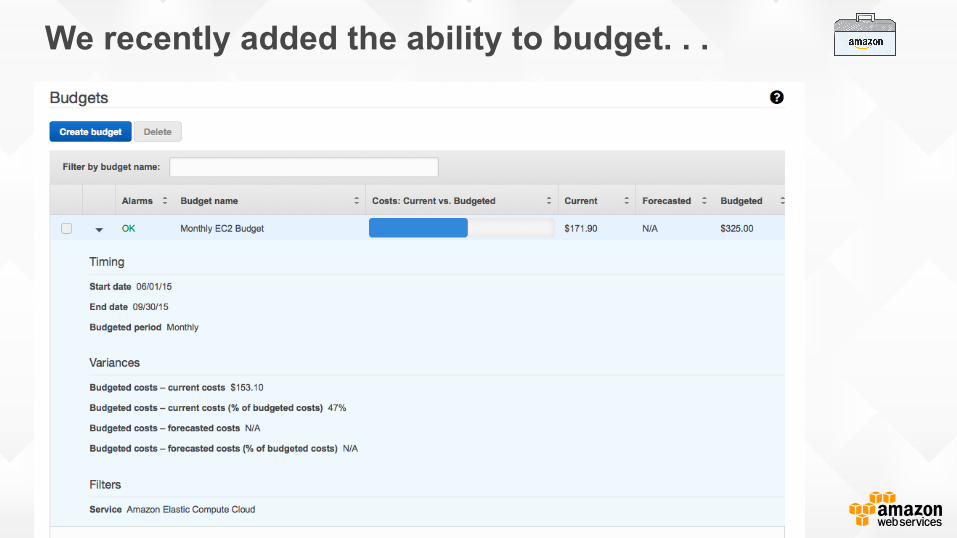
We recently added the ability to budget. . .

. . . and forecast within cost explorer

…Or Using an AWS Partner Tool…

Customer Example – Kellogg
“CloudWatch helps our people make better decisions around the capacity they need, so that they can avoid waste…” “We were never able to do that with our on-premises infrastructure. AWS breaks down usage and cost to such a granular level that we can identify which costs come from which department, like a toll model.”

Best Practice: Manage How Resources are Provisioned and Monitored
• Only allow specific groups or teams to deploy (certain) AWS resources
• Create different environment (e.g. Dev/Test vs. Production) with different policies for each
• Require tags in order to instantiate resources • Monitor and send alerts or shut down instances improperly tagged • Use CloudWatch to send alerts when billing thresholds are met • Analyze your spend using AWS or Partner tools

Cost Optimization Strategies: Architecture and Design
4. Design for Elasticity Rather Than Deploy for Peak…
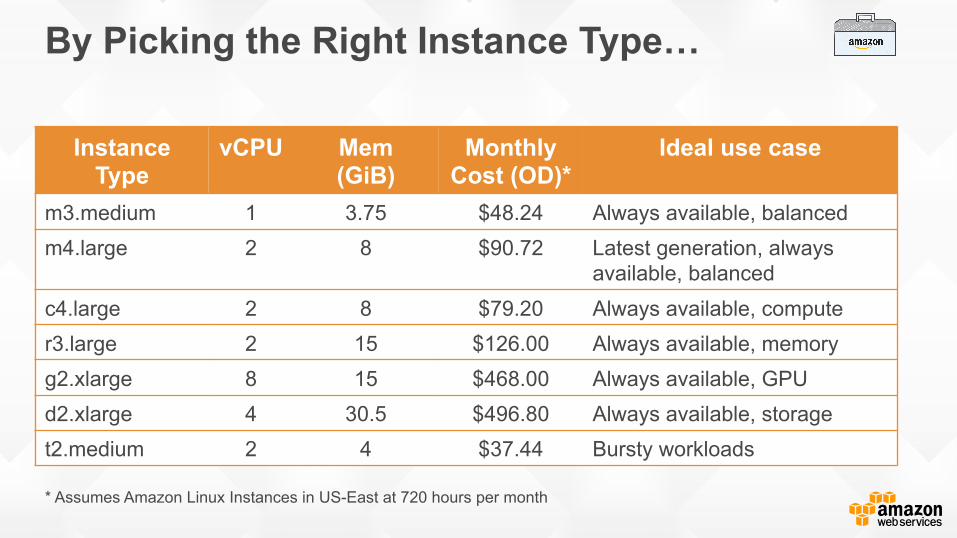
By Picking the Right Instance Type…
Instance Type
vCPU Mem (GiB)
Monthly Cost (OD)*
Ideal use case
m3.medium 1 3.75 $48.24 Always available, balanced m4.large 2 8 $90.72 Latest generation, always
available, balanced c4.large 2 8 $79.20 Always available, compute r3.large 2 15 $126.00 Always available, memory g2.xlarge 8 15 $468.00 Always available, GPU d2.xlarge 4 30.5 $496.80 Always available, storage t2.medium 2 4 $37.44 Bursty workloads
* Assumes Amazon Linux Instances in US-East at 720 hours per month

…And Determine if Bursting Works For You
• 2vCPU, 4 GiB RAM • Baseline performance: 40% (of a single core) • Bursts beyond this based on CPU credits • Less than $40 per month • Use Cases: Web servers, dev, small
databases • Additional Details: http://amzn.to/1sl2bKa t2.medium

Customer Example – Nomura Research
For Nomura Research, the t2 instance provides enough performance for a development environment, remote desktop of evaluation environment requiring occasional CPU bursting

Customer Example – Kaplan
We quickly converted a hefty percentage of our systems to run under this EC2 Instance type, and have seen major cost reductions without affecting performance whatsoever. For all instances built for Kaplan moving forward, the T2 is going to be the preferred option unless measured or load-tested computing needs demand otherwise.

Using Autoscaling….
Automatic resizing of compute clusters based on demand
Trigger autoscaling policy
Feature Details
Control Define minimum and maximum instance pool sizes and when scaling and cool down occurs.
Integrated to Amazon
CloudWatch
Use metrics gathered by CloudWatch to drive scaling.
Instance types Run Auto Scaling for On-Demand and Spot Instances.
AWS autoscaling create-autoscaling-group — Auto Scaling-group-name MyGroup — Launch-configuration-name MyConfig — Min size 4 — Max size 200 — Availability Zones us-west-2c

…And Adjusting for Utilization and Granularity More smaller instances vs. less larger instances
29 m4.large @ $0.126/hr $2,630.88 / mo*
59 t2.medium @ $0.052/hr $2,203.20 / mo*
*Assumes Linux instances in US-East at 720 hours per month

Customer Example
Large Aerospace Customer
Challenge Workloads arrive asynchronously and require isolation
Solution Use Amazon SQS and Autoscaling Groups to launch / terminate instances

5. Identify Idle Resources and Turn Off Unused Instances…

…Using Trusted Advisor…

…Or Amazon CloudWatch to Monitor, Collect and Track Metrics…
Amazon CloudWatch

…Or (Again) Using an AWS Partner Tool…

Customer Example – Samsung
We are using AWS Trusted Advisor to improve cost efficiency and to audit the configurations of service platforms

Best Practice: Match Your Usage and Capacity
Start Choose an instance that best meets your basic requirements
Start with memory & then choose closest virtual
cores
Look for peak IOPS storage requirements
Tune Use CloudWatch and
Trusted Advisor to assess
Change instance size up or down based upon
monitoring
Expand Run multiple instances in multiple Availability
Zones
Use Autoscaling to scale up and down based on
demand and usage (e.g. spikes)

6. Architect Your Workload with Cost in Mind

Select Reserved Instances for Steady State Workloads…
Commitment Level • 1 Year • 3 Year AWS Services Offering RIs • Amazon EC2 • Amazon RDS • Amazon DynamoDB • Amazon Redshift • Amazon ElastiCache
* Dependent on specific AWS Service, size/type and Region

Or Spot Instances for Non-Stateful (Time Insensitive or Fault Tolerant) Workloads…
Minimum Commitment • Commit to 1 hour
Tradeoff • Potential for interruption
* Compared to On Demand price based on specific EC2 instance type, region and availability zone

…Or A Combination of All Three
1. Start by using RIs for known/steady-state workloads
2. Set-up multiple autoscaling groups
3. Autoscale first using Spot first 4. If Spot instances are
unavailable (or priced too high), use On-Demand
0
2
4
6
8
10
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
/Spot Instances
On Demand Spot Reserved Instance

And When You Have Excess RIs…
Use the Amazon EC2 Reserved Instance Marketplace
http://amzn.to/1FkzUZp

Customer Example – Novartis
Goal: Screen 10 million compounds against a common cancer target in < 1 week Set Up: 10,600 AWS Instances (39 drug design years in 11 hours) Result: 3 promising compounds Cost: $4,232
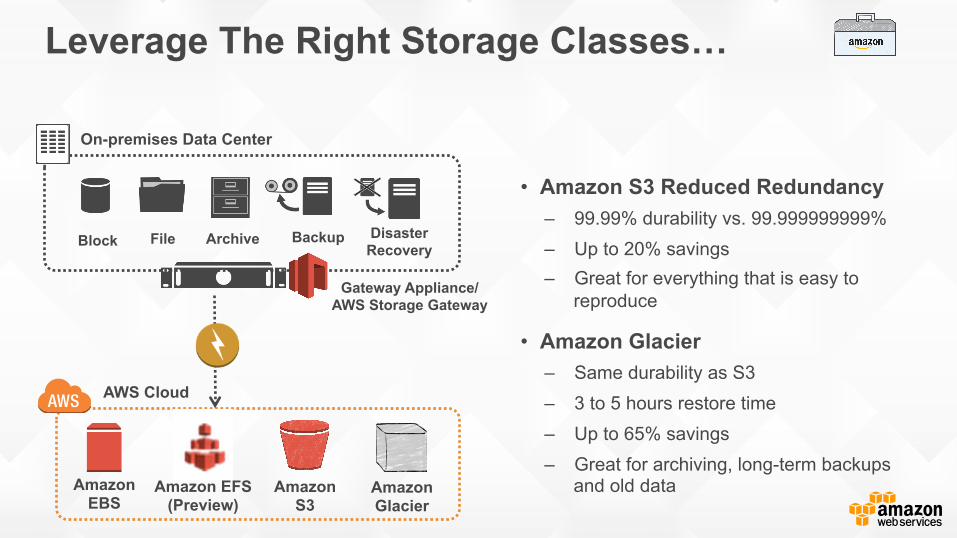
Leverage The Right Storage Classes…
AWS Cloud
Amazon Glacier
Gateway Appliance/ AWS Storage Gateway
Amazon S3
Block File
On-premises Data Center
Archive Backup Disaster Recovery
Amazon EBS
• Amazon S3 Reduced Redundancy ‒ 99.99% durability vs. 99.999999999% ‒ Up to 20% savings ‒ Great for everything that is easy to
reproduce
• Amazon Glacier ‒ Same durability as S3 ‒ 3 to 5 hours restore time ‒ Up to 65% savings ‒ Great for archiving, long-term backups
and old data Amazon EFS (Preview)
…Alongside AWS Managed or Application Services…
Elastic Load Balancing
(ELB)
Amazon Relational Database Service
(RDS)
Amazon ElastiCache
Amazon DynamoDB
Amazon Simple Queue Service
(SQS)
Amazon Simple Email Service
(SES)
Amazon Lambda
Amazon Elastic MapReduce
(EMR)
Amazon Simple Notification Service
(SNS)
Amazon Kinesis
Amazon Route 53
Amazon Redshift
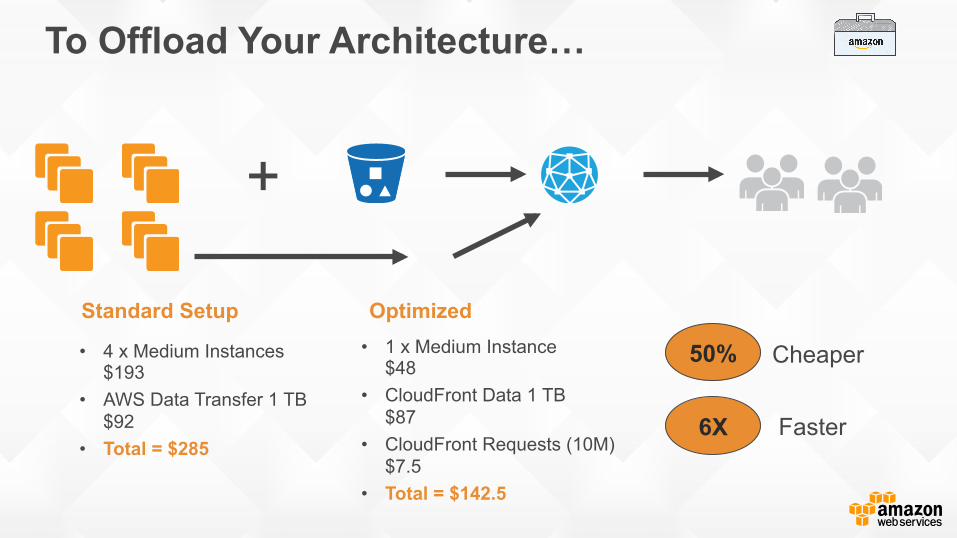
To Offload Your Architecture…
+
Standard Setup
• 4 x Medium Instances $193
• AWS Data Transfer 1 TB $92
• Total = $285
Optimized • 1 x Medium Instance
$48 • CloudFront Data 1 TB
$87 • CloudFront Requests (10M)
$7.5 • Total = $142.5
50%
6X
Cheaper
Faster

Customer Example – Infospace
• Chooses the right instance types (using Cloudwatch)
• Uses Reserved Instances (reduced monthly costs by 28%)
• Monitors and turns off unused instances (own tool – Junkyard Dog)
• Offloads architecture by moving to Cloudfront
• Leverages App services: ELB, SNS, SES
• Uses Trusted Advisor • Moves Data warehouse to Redshift

Cost Optimization Strategies: Technology Updates

7. Be Cognizant of Technology Lifecycle Updates

Including…
• New Instance Types/Families (e.g. m4s)
• New Technologies (e.g. Amazon RDS for Aurora, AWS Service Catalog)
New Prices

…And Remember to Use Consolidated Billing • Receive a single bill for all
charges incurred across all linked accounts ‒ Share RI discounts ‒ Combine tiering benefits /
Volume discounts • View & manage linked accounts • Add additional accounts

Best Practice: Pull all Levers Available When Architecting Your Solution
• Utilize On-Demand, Reserved and Spot Instances • Use the Amazon EC2 RI Marketplace when you have excess Ris • Use the appropriate storage class based on your requirements (not
on what you use today) • Use micro services where possible in your architecture • Review your architecture when new services or technologies are
announced • Use consolidated billing to take advantage of tiered pricing

Cost Optimization Strategies – Putting It All Together
Frameworks
ü Limit Resource Provisioning ü Understand What is Deployed and
What it Costs ü Proactively Monitor Your Account
Billing Usage ü Design for Elasticity Rather Than
Deploy for Peak ü Identify Idle Resources and Turn
Off Unused Instances ü Architect Your Workloads with
Cost in Mind ü Be Cognizant of Technology
Lifecycle Updates

New York