optimization principles and application performance...
TRANSCRIPT

Optimization Principles and Optimization Principles and
Application Performance Evaluation Application Performance Evaluation
of a Multithreaded GPU Using CUDAof a Multithreaded GPU Using CUDA
Shane Ryoo, Christopher I. Rodrigues, Sara S. Baghsorkhi,
Sam S. Stone, David B. Kirk, and Wen-mei H. Hwu
Center for Reliable and High-Performance Computing
University of Illinois at Urbana-Champaign
and NVIDIA Corporation
PPoPP 2008 – February 21, 2008
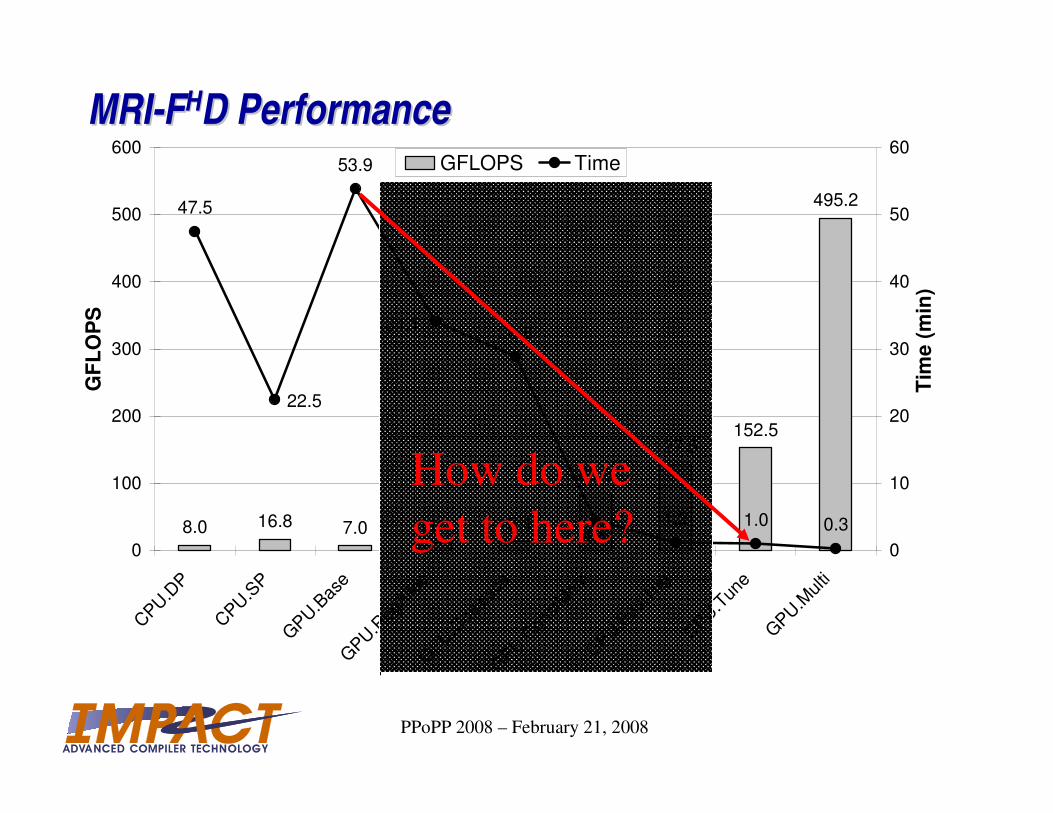
MRIMRI--FFHHD PerformanceD Performance
8.0 16.8 7.0 11.1 13.1
85.8
127.5152.5
495.247.5
53.9
28.8
1.2 1.0 0.3
22.5
4.4
34.1
0
100
200
300
400
500
600
CPU
.DP
CPU
.SP
GPU
.Bas
eG
PU.R
egAllo
cG
PU.C
oale
sce
GPU
.Con
stM
emG
PU.F
astT
rig
GPU
.Tun
e
GPU
.Mul
ti
Loop Unrolling Factor
GF
LO
PS
0
10
20
30
40
50
60
Tim
e (
min
)
GFLOPS Time
How do we
get to here?

PPoPP 2008 – February 21, 2008
PrinciplesPrinciples
• Leverage zero-overhead thread scheduling
• Inter-thread communication possible locally, not
globally
• Optimize use of on-chip memory
• Group threads to avoid SIMD penalties and memory
port/bank conflicts
• Further optimization involves tradeoffs between
resources

PPoPP 2008 – February 21, 2008
Managing Memory LatencyManaging Memory Latency
• Global memory latency is 200+ cycles
• 8 instructions/cycle
• Need 1600 instructions to avoid
stalling
• Decompose work into a fine
granularity for TLP
• ILP and MLP within each thread
have a multiplicative effect
Ctemp = 0;
for (i = 0; i < widthA; i++) { Ctemp += A[indexA] * B[indexB]; indexA++; indexB += widthB; }
C[indexC] = Ctemp;
Matrix multiplication
Each thread – 1 result element
1024x1024 matrix:
1M threads

PPoPP 2008 – February 21, 2008
Global Bandwidth SaturationGlobal Bandwidth Saturation
Ctemp = 0;
for (i = 0; i < widthA; i++) { Ctemp += A[indexA] * B[indexB]; indexA++; indexB += widthB; }
C[indexC] = Ctemp;
• 2 global loads for every 6 instructions
• Requires more than 2X the available bandwidth
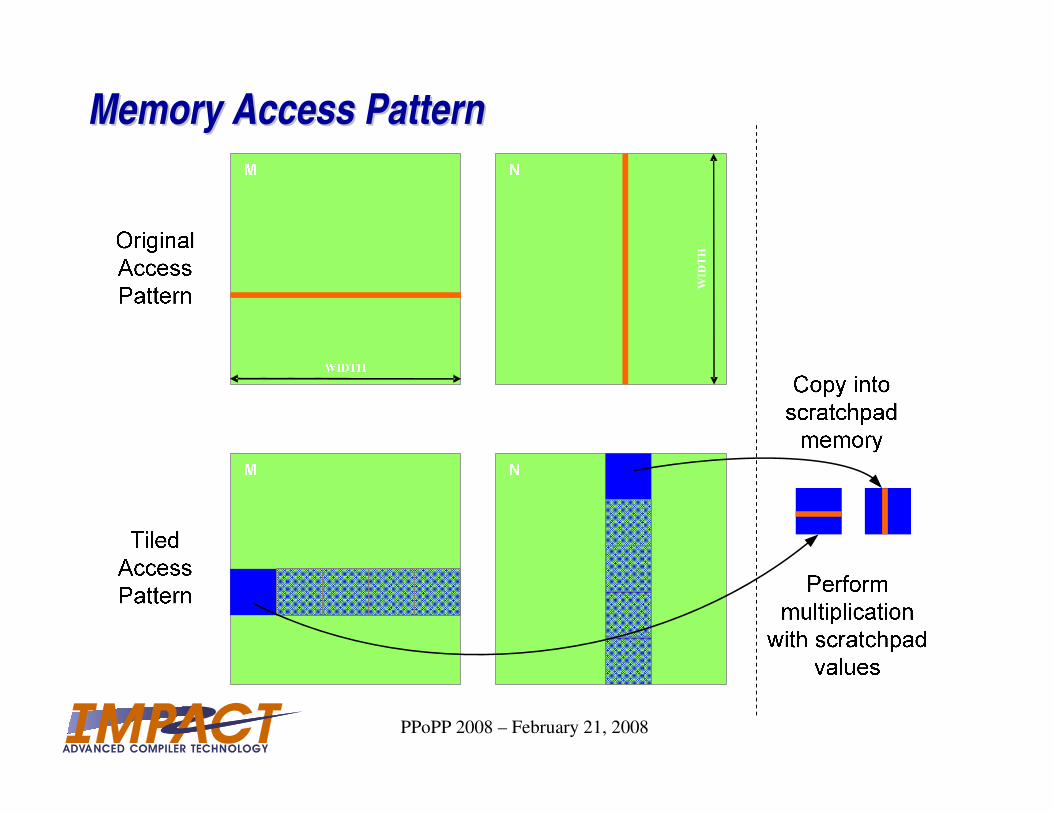
• Inter-thread data reuse: local
scratchpad memory can reduce
global bandwidth usage
PPoPP 2008 – February 21, 2008
Memory Access PatternMemory Access Pattern
WIDTH
PPoPP 2008 – February 21, 2008
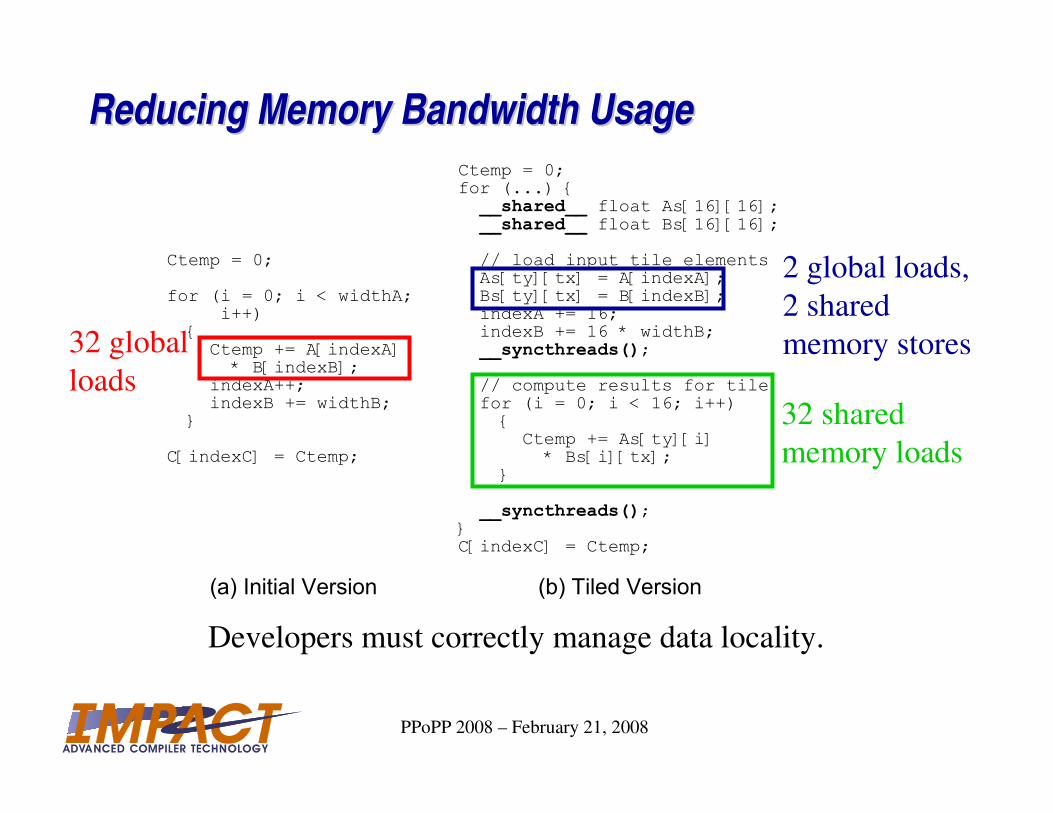
Reducing Memory Bandwidth UsageReducing Memory Bandwidth Usage
Ctemp = 0;
for (i = 0; i < widthA; i++) { Ctemp += A[indexA] * B[indexB]; indexA++; indexB += widthB; }
C[indexC] = Ctemp;
Ctemp = 0;for (...) {__shared__ float As[16][16];__shared__ float Bs[16][16];
// load input tile elements As[ty][tx] = A[indexA]; Bs[ty][tx] = B[indexB]; indexA += 16; indexB += 16 * widthB;__syncthreads();
// compute results for tile for (i = 0; i < 16; i++) { Ctemp += As[ty][i] * Bs[i][tx]; }
__syncthreads();}C[indexC] = Ctemp;
(a) Initial Version (b) Tiled Version
2 global loads,
2 shared
memory stores
32 shared
memory loads
Developers must correctly manage data locality.
32 global
loads
PPoPP 2008 – February 21, 2008
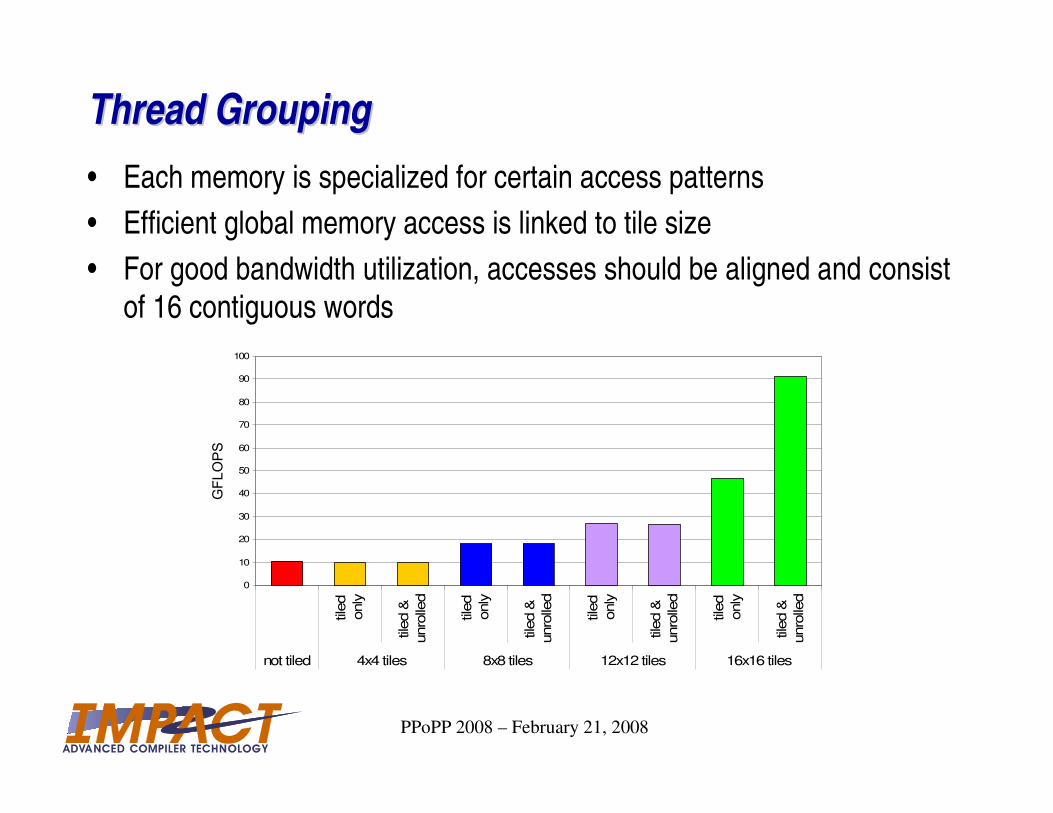
Thread GroupingThread Grouping
• Each memory is specialized for certain access patterns
• Efficient global memory access is linked to tile size
• For good bandwidth utilization, accesses should be aligned and consist of 16 contiguous words
GFLO
PS
0
10
20
30
40
50
60
70
80
90
100
tiled
only
tiled &
unro
lled
tiled
only
tiled &
unro
lled
tiled
only
tiled &
unro
lled
tiled
only
tiled &
unro
lled
not tiled 4x4 tiles 8x8 tiles 12x12 tiles 16x16 tiles

PPoPP 2008 – February 21, 2008
Further ImprovementFurther Improvement
• Reduce non-computation instructions
– Loop unrolling
– Change threading granularity to eliminate redundancy
• TLP vs. per-thread performance: prefetching, register
tiling, traditional optimizations
• Difficult to estimate performance without performing
the optimization and executing the kernel

PPoPP 2008 – February 21, 2008
UnrollingUnrollingCtemp = 0;for (...) {
__shared__ float As[16][16];__shared__ float Bs[16][16];
// load input tile elements As[ty][tx] = A[indexA]; Bs[ty][tx] = B[indexB]; indexA += 16; indexB += 16 * widthB;
__syncthreads();
// compute results for tile for (i = 0; i < 16; i++) { Ctemp += As[ty][i] * Bs[i][tx]; }
__syncthreads();}C[indexC] = Ctemp;
Ctemp = 0;for (...) {
__shared__ float As[16][16];__shared__ float Bs[16][16];
// load input tile elements As[ty][tx] = A[indexA]; Bs[ty][tx] = B[indexB]; indexA += 16; indexB += 16 * widthB;
__syncthreads();
// compute results for tile Ctemp += As[ty][0] * Bs[0][tx]; ... Ctemp += As[ty][15] * Bs[15][tx];
__syncthreads();}C[indexC] = Ctemp;
(b) Tiled Version (c) Unrolled Version
Removal of branch instructions and address calculations
Does this use
more registers?
PPoPP 2008 – February 21, 2008
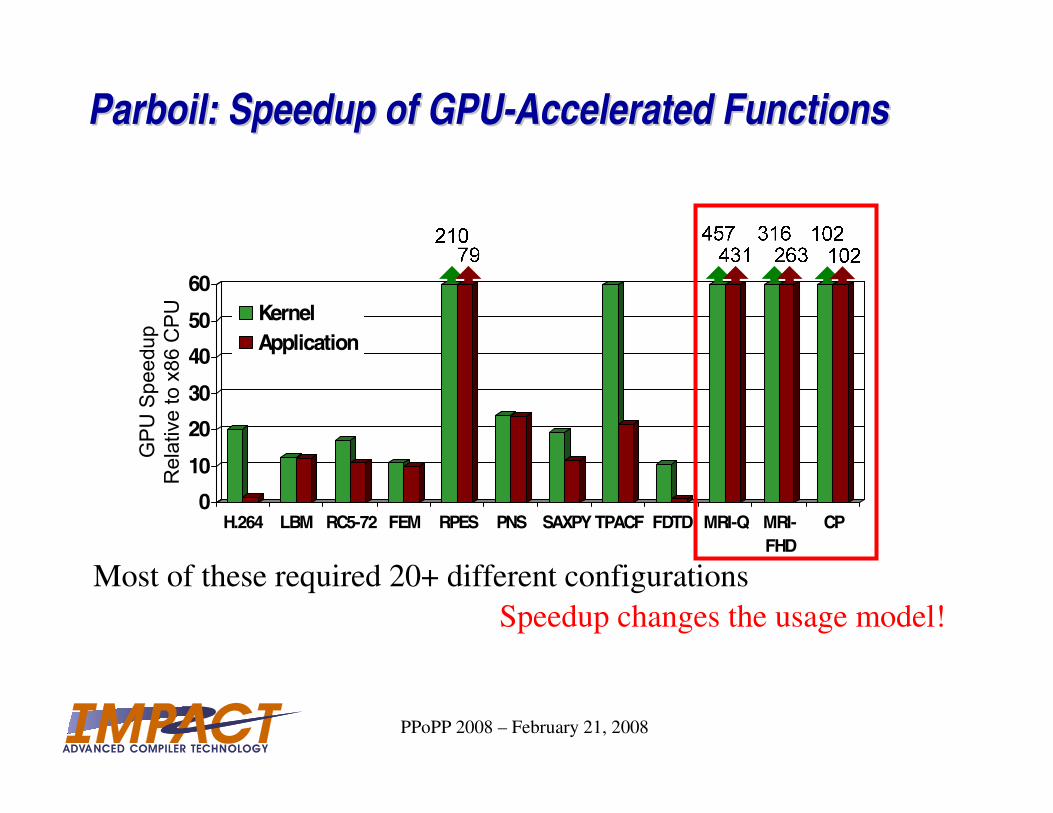
Parboil: Speedup of GPUParboil: Speedup of GPU--Accelerated FunctionsAccelerated Functions
0
10
20
30
40
50
60
H.264 LBM RC5-72 FEM RPES PNS SAXPYTPACF FDTD MRI-Q MRI-
FHD
CP
Kernel
Application
GP
U S
peedup
Rela
tive to x
86 C
PU
Speedup changes the usage model!
Most of these required 20+ different configurations

PPoPP 2008 – February 21, 2008
LBM Fluid Simulation (from SPEC CPU 2006)LBM Fluid Simulation (from SPEC CPU 2006)
• Simulation of fluid flow in a grid
• Synchronization required after
each time step
• Can reduce bandwidth usage by
caching in shared memory
• But can hold data for only 200 grid cells – global memory latency is
exposedFlow through a cell (dark
blue) is updated based on its
flow and the flow in 18
neighboring cells (light blue).

PPoPP 2008 – February 21, 2008
ConclusionsConclusions
• Naïve mapping to GeForce 8800 does not
always buy significant performance
• By following the presented principles, 10X or
more performance advantage over a single-core
CPU can be achieved
• Remaining speedup involves using specialized
resources or trading off use of resources

Program Optimization Space Pruning
for a Multithreaded GPU
Center for Reliable and High-Performance Computing
University of Illinois at Urbana-Champaign
Shane Ryoo, Christopher I. Rodrigues,
Sam S. Stone, Sara S. Baghsorkhi, Sain-Zee Ueng,
John A. Stratton, and Wen-mei W. Hwu

6CGO – April 9th, 2008
Optimization
• First order principles [PPoPP ‘08]
– Enough threads for TLP
– Little or no inter-thread communication
– Good use of on-chip memory to reduce bandwidth
pressure
– Thread grouping to optimize SIMD & memory banking
• Second order – balancing instruction stream
efficiency and hardware utilization

7CGO – April 9th, 2008
Examples of Optimizations
• Instruction stream efficiency
– Loop unrolling
– TLP granularity changes
– Traditional optimization
• Hardware utilization
– Prefetching
– ILP-extraction transformations
– Scheduling for MLP
– Increasing TLP

8CGO – April 9th, 2008
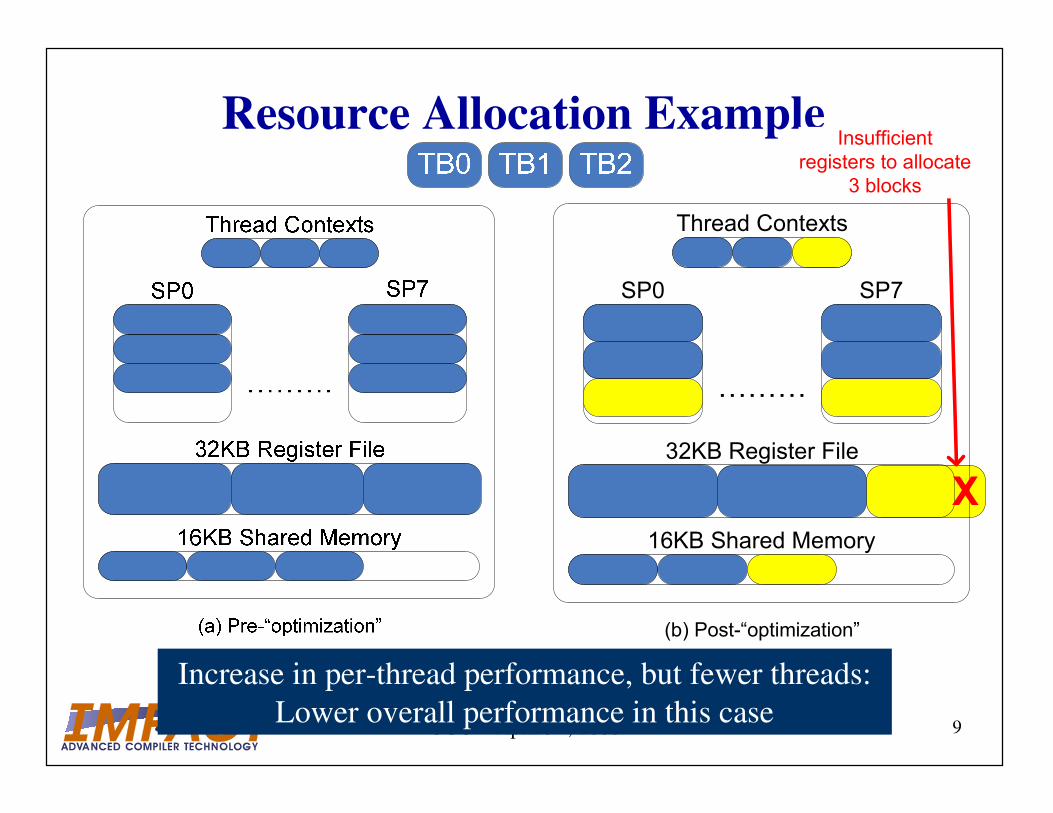
Discontinuous Optimization Space
• Begin with a version with 3 thread blocks per SM
– 256 threads per thread block, 10 registers per thread
– 3 * 256 * 10 = 7680 total registers
• Perform an optimization that uses an additional
register per thread
– 3 * 256 * 11 = 8448 > 8k!
– Performance per thread has increased
– But this version has only 2 thread blocks per SM
• Is the optimized version better or worse?
9CGO – April 9th, 2008
Resource Allocation Example
32KB Register File
16KB Shared Memory
………
SP0 SP7
(b) Post-“optimization”
Insufficient
registers to allocate
3 blocks
Thread Contexts
X
Increase in per-thread performance, but fewer threads:
Lower overall performance in this case

10CGO – April 9th, 2008
How Close Are We to Best Performance?
• Investigated applications with many optimizations
• Exhaustive optimization space search
– Applied many different, controllable optimizations
– Parameterized code by hand
• Hand-optimized code is deficient
– Generally >15% from the best configuration
– Trapped at local maxima
– Often non-intuitive mix of optimizations
11CGO – April 9th, 2008
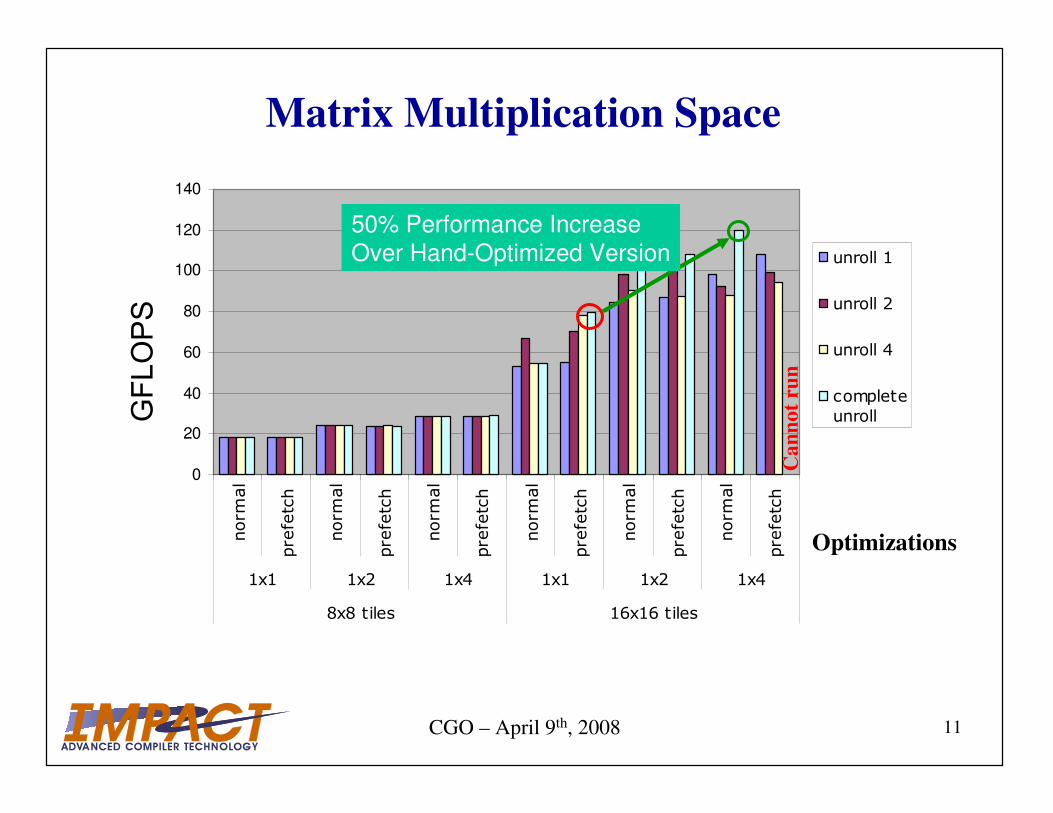
Matrix Multiplication SpaceG
FLO
PS
0
20
40
60
80
100
120
140
normal
prefetch
normal
prefetch
normal
prefetch
normal
prefetch
normal
prefetch
normal
prefetch
1x1 1x2 1x4 1x1 1x2 1x4
8x8 tiles 16x16 tiles
unroll 1
unroll 2
unroll 4
complete
unroll
50% Performance Increase
Over Hand-Optimized Version
Ca
nn
ot
run
Optimizations

12CGO – April 9th, 2008
SAD Thread Block Size
2
3
4
5
6
7
8
9
32 64 96 128 160 192 224 256 288 320 352 384
Tim
e (m
s)
Threads per Thread Block
What happens if the application or runtime changes?
Probably need to rerun the search.

13CGO – April 9th, 2008
Solution: Evaluate All Likely Configurations
• Begin with a complete, parameterized
optimization space per kernel
– Tile size and shape
– Thread block size, work per thread block
– Other optimizations, such as manual register spilling
• Compile all configurations to find resource usage
• Generate metric values for each configuration
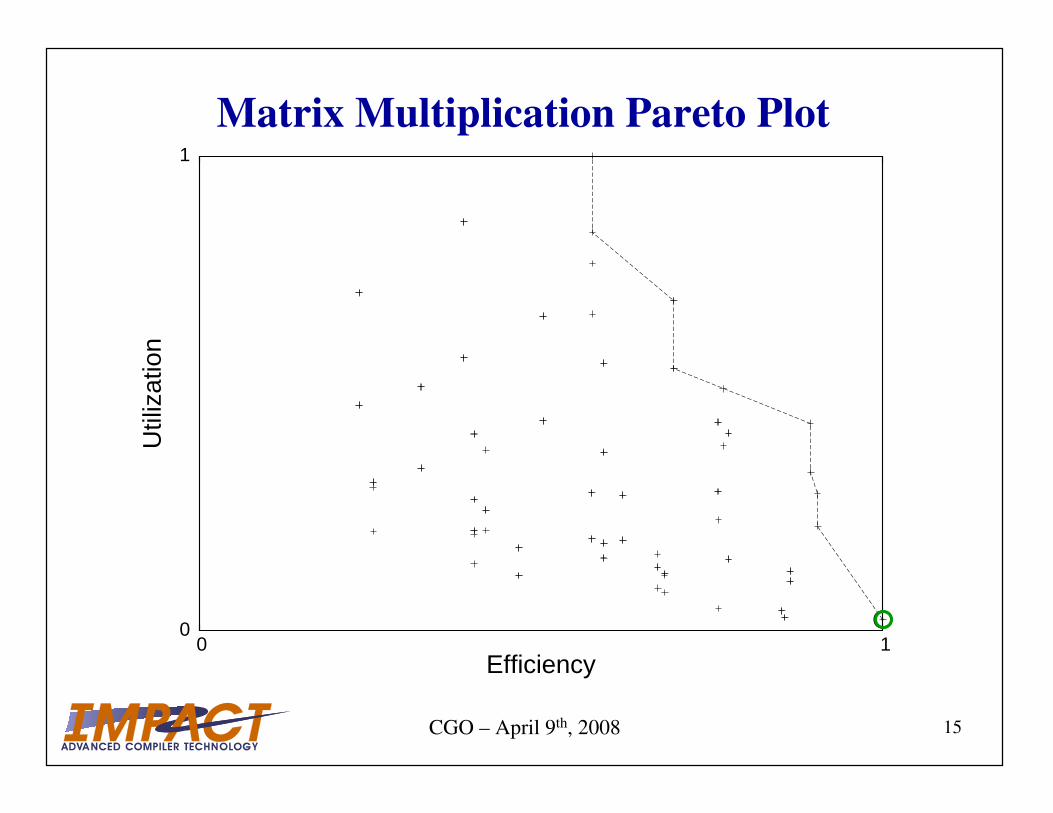
• Prune space using a Pareto-optimal curve

14CGO – April 9th, 2008
Metrics for the GeForce 8800
How efficient is our instruction stream?
Can we keep the processors utilized?
These capture first-order effects of applications.
15CGO – April 9th, 2008
1
0 1 0
Util
izat
ion
Efficiency
Matrix Multiplication Pareto Plot

16CGO – April 9th, 2008
1
0 1 0
Util
izat
ion
Efficiency
1
0 1 0
Util
izat
ion
Efficiency
MRI-FHD and SAD Plots
MRI-FHD SAD
17CGO – April 9th, 2008
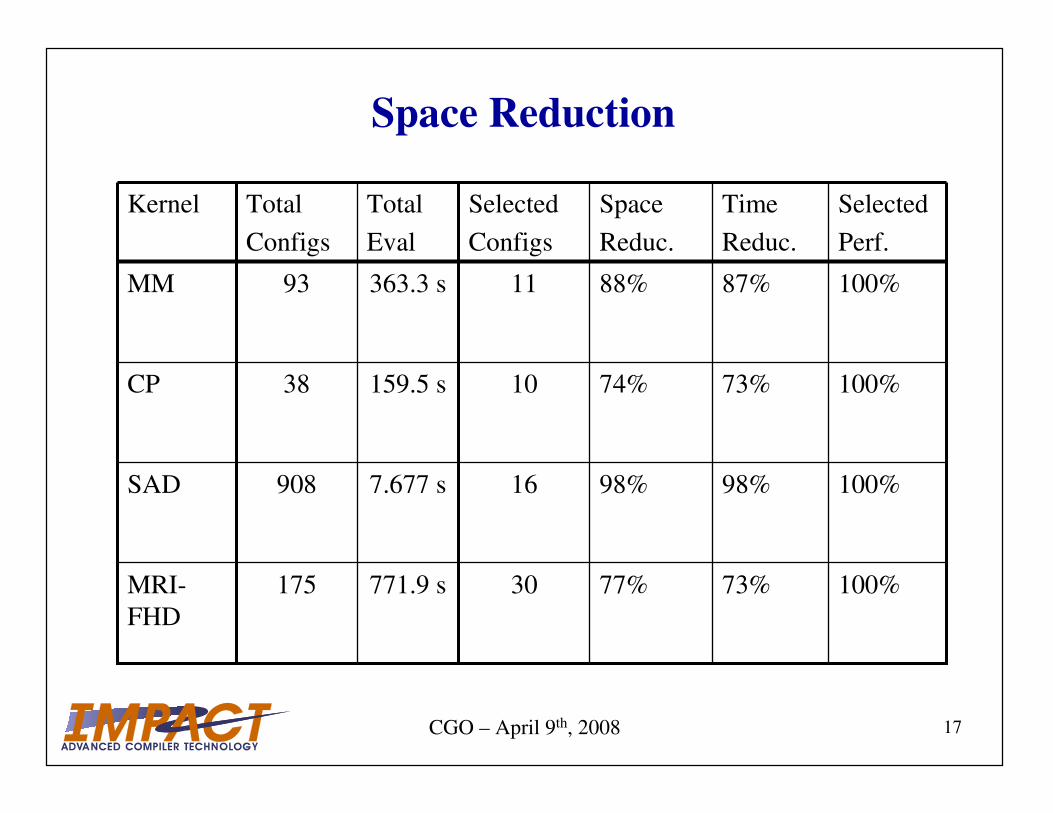
Space Reduction
100%98%98%167.677 s908SAD
100%73%77%30771.9 s175MRI-
FHD
100%73%74%10159.5 s38CP
100%87%88%11363.3 s93MM
Selected
Perf.
Time
Reduc.
Space
Reduc.
Selected
Configs
Total
Eval
Total
Configs
Kernel

19CGO – April 9th, 2008
Summary and Conclusion
• Performance tuning involves tradeoffs between
instruction efficiency and HW utilization
• Manual, iterative optimization usually leaves
performance on the table
• Reoptimization needed for new hardware,
application, or runtime
• Pareto-based pruning removes up to 98% of the
optimization space, still finds best configuration
• Ryoo Ph.D. dissertation contains further work:
http://www.crhc.uiuc.edu/IMPACT.