optimization of designs for fmri
DESCRIPTION
Optimization of Designs for fMRI. IPAM Mathematics in Brain Imaging Summer School July 18, 2008. Thomas Liu, Ph.D. UCSD Center for Functional MRI. Why optimize?. Scans are expensive. Subjects can be difficult to find. fMRI data are noisy - PowerPoint PPT PresentationTRANSCRIPT

T.T. Liu July 18, 2008
Optimization of Designs for fMRIIPAM Mathematics in Brain Imaging Summer SchoolJuly 18, 2008
Thomas Liu, Ph.D.UCSD Center for Functional MRI

T.T. Liu July 18, 2008

T.T. Liu July 18, 2008
• Scans are expensive.• Subjects can be difficult to find.
• fMRI data are noisy• A badly designed experiment is unlikely to yield publishable results.
• Time = Money
Why optimize?
If your result needs a statistician then you should design a better experiment. --Baron Ernest Rutherford

T.T. Liu July 18, 2008
• Statistical Efficiency: maximize contrast of interest versus noise.
• Psychological factors: is the design too boring? Minimize anticipation, habituation, boredom, etc.
What to optimize?

T.T. Liu July 18, 2008
Which is the best design?
E
It depends on the experimental question.

T.T. Liu July 18, 2008
• Where is the activation?• What does the hemodynamic response function (HRF) look like?
Possible Questions

T.T. Liu July 18, 2008
1)Assume we know the shape of the HRF but not its amplitude.
2)Assume we know nothing about the HRF (neither shape nor amplitude).
3)Assume we know something about the HRF (e.g. it’s smooth).
Model Assumptions

T.T. Liu July 18, 2008
General Linear Model
y = Xh + Sb + n
Parameters of
Interest
DesignMatrix
NuisanceParameters
NuisanceMatrixData
AdditiveGaussianNoise

T.T. Liu July 18, 2008
Example 1: Assumed HRF shape
€
y =
0
0
0.5
1
1
1
0.5
0
0
⎡
⎣
⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢
⎤
⎦
⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥
h1 +
1 1
1 2
1 3
1 4
1 5
1 6
1 7
1 8
1 9
⎡
⎣
⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢
⎤
⎦
⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥
b1
b2
⎡
⎣ ⎢
⎤
⎦ ⎥+
−1
−2
0
3
−1
1
2
.5
−.2
⎡
⎣
⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢
⎤
⎦
⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥
Design matrix depends on both stimulus and HRF
Parameter = amplitude of response
Stimulus
Convolve w/ HRF

T.T. Liu July 18, 2008
Design Regressor
=
The process can be modeled by convolving the activity curve with a "hemodynamic response function" or HRF
HRF Predicted neural activity
Predicted response
Courtesy of FSL Group and Russ Poldrack

T.T. Liu July 18, 2008
Example 2: Unknown HRF shape
€
y =
0 0 0 0
0 0 0 0
0 0 0 0
1 0 0 0
1 1 0 0
1 1 1 0
0 1 1 1
0 0 1 1
0 0 0 1
⎡
⎣
⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢
⎤
⎦
⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥
h1
h2
h3
h4
⎡
⎣
⎢ ⎢ ⎢ ⎢
⎤
⎦
⎥ ⎥ ⎥ ⎥
+
1 1
1 2
1 3
1 4
1 5
1 6
1 7
1 8
1 9
⎡
⎣
⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢
⎤
⎦
⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥
b1
b2
⎡
⎣ ⎢
⎤
⎦ ⎥+
−1
−2
0
3
−1
1
2
.5
−.2
⎡
⎣
⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢
⎤
⎦
⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥
h1
h2
h3
h4
Unknown shape and amplitude
Note: Design matrix only depends on stimulus, not HRF

T.T. Liu July 18, 2008
FIR design matrix
FIR estimates
Courtesy of Russ Poldrack
T.T. Liu July 18, 2008
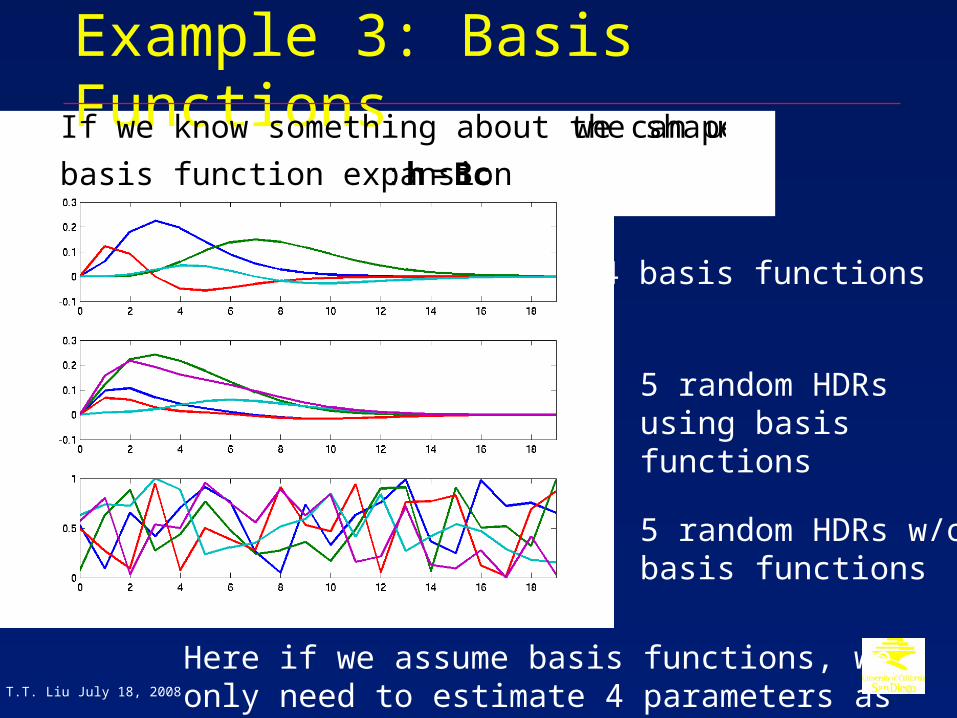
Example 3: Basis Functions
€
If we know something about the shape, we can use a
basis function expansion : h = Bc
4 basis functions
5 random HDRs using basis functions
5 random HDRs w/o basis functions
Here if we assume basis functions, we only need to estimate 4 parameters as opposed to 20.

T.T. Liu July 18, 2008
Test Statistic
€
t ∝ parameter estimate
variance of parameter estimate
Thermal noise, physiological noise, low frequency drifts, motion
Stimulus, neural activity, field strength, vascular state
Also depends on Experimental Design!!!

T.T. Liu July 18, 2008
Efficiency
€
Efficiency∝1
Variance of Parameter Estimate

T.T. Liu July 18, 2008
Known
Covariance Matrix
€
cov ˆ h ( ) =
var ˆ h 1( ) cov ˆ h 1,ˆ h 2( ) L cov ˆ h 1,
ˆ h N( )
cov ˆ h 2,ˆ h 1( ) var ˆ h 2( ) L cov ˆ h 2,
ˆ h N( )M M O M
cov ˆ h N , ˆ h 1( ) cov ˆ h N , ˆ h 2( ) L var ˆ h N( )
⎡
⎣
⎢ ⎢ ⎢ ⎢ ⎢
⎤
⎦
⎥ ⎥ ⎥ ⎥ ⎥
€
Efficiency ∝1
Trace cov ˆ h ( )[ ]
Known as an A-optimal design

T.T. Liu July 18, 2008
Efficiency
€
Example 1:
Efficiency∝1
Var ˆ h 1( )
€
Example 2 :
Efficiency∝1
Var ˆ h 1( ) + Var ˆ h 2( ) + Var ˆ h 3( ) + Var ˆ h 4( )

T.T. Liu July 18, 2008
What does a matrix do?
€
y = Xh
N-dimensional vector
N x k matrix
k-dimensional vector
The matrix maps from a k-dimensional space to a N-dimensional space.

T.T. Liu July 18, 2008
Matrix Geometry
Xv = u1 1 1
v1
u1 1
Geometric fact: The image of the a k-dimensional unit sphere under any N x k matrix is an N-dimensional hyperellipse.
k-dimensional unit sphere
N-dimensional hyperellipse

T.T. Liu July 18, 2008
Singular Value Decomposition
Xv = u1 1 1
v1
v2 u
u1 1
2 2
€
The right singular vectors v1 and v 2 are transformed
into scaled vectors σ 1u1 and σ 2u2 , where u1 and u2 are
the left singular vectors and σ 1 and σ 2 are the singular values.
€
The singular values are the k square roots of the
eigenvalues of the kxk matrix XT X.

T.T. Liu July 18, 2008
Assumed HDR shape
Xv = u1 1 1
1v
Parameter Space
u1 1
Data Space
ParameterNoise Space
h0
Efficiency here is optimized by amplifying the singular vector closest to the assumed HDR. This corresponds to maximizing one singular value while minimizing the others.
Good forDetectionh0
Xh0

T.T. Liu July 18, 2008
No assumed HDR shape
v1
u1 1Xv = u1 1 1
Parameter Space
Data Space
ParameterNoise Space
Here the HDR can point in any direction, so we don’t want to preferentially amplify any one singular value. This corresponds to an equal distribution of singular values.

T.T. Liu July 18, 2008
Some assumptions about shape
If we know the the HDR lies within a subspace spanned by a set of basis functions, we should maximize the singular values in this subspace and minimize outside of this subspace.
If no assumptions, then use equal singular values.

T.T. Liu July 18, 2008
Knowledge (Assumptions) about HRF
None Some Total
Make singular values as equal as possible
Maximize singular values associated with subspace that contains HDR
Maximize singular value associated with right singular vector closest to HDR

T.T. Liu July 18, 2008
Singular Values and Power Spectrum
€
The singular values σ i are the k square roots of
the eigenvalues of the kxk matrix XT X.
€
The eigenvalues of the kxk matrix XT X asymptotically
approach the the power spectral coefficients of the first
row of XT X - - i.e. the power spectrum of the design.
*(assume mean has been removed from design)

T.T. Liu July 18, 2008
Knowledge (Assumptions) about HRF
None Some Total
Equally distributed singular values = flat power spectrum f
One dominant singular value = one dominant power spectral component
f
Set of dominant singular values = spread of power spectral components f
Power Spectra

T.T. Liu July 18, 2008
Frequency Domain Interpretation
BoxcarRandomized ISI single-event
Regressor
FFT
Low-pass Low-pass
Adapted From S. Smith and R. Poldrack

T.T. Liu July 18, 2008
Which is the best design?
E

T.T. Liu July 18, 2008
E
€
Given an assumed
shape h0,
which design
maximizes Xh0 ?
Xv = u1 1 1
1v
u1 1
h0
Xh0

T.T. Liu July 18, 2008
€
Which design will have
the most equal spread
of singular values?
E€
Which design will have
the flattest power spectrum?
f

T.T. Liu July 18, 2008
€
Which design will have
a tailored spread
of singular values?
E
€
Which design will have
a shaped power spectrum?
f

T.T. Liu July 18, 2008
Detection Power
When detection is the goal, we want to answer the question: is an activation present or not? When trying to detect something, one needs to specify some knowledge about the “target”. In fMRI, the target is approximated by the convolution of the stimulus with the HRF. Once we have specified our target (e.g. stimuli and assumed HRF shape), the efficiency for estimating the amplitude of that target can be considered our detection power.

T.T. Liu July 18, 2008
Theoretical Trade-off
Detection Power
HDREstimationEfficiency
Equal Singular values
One DominantSingular value
T.T. Liu July 18, 2008
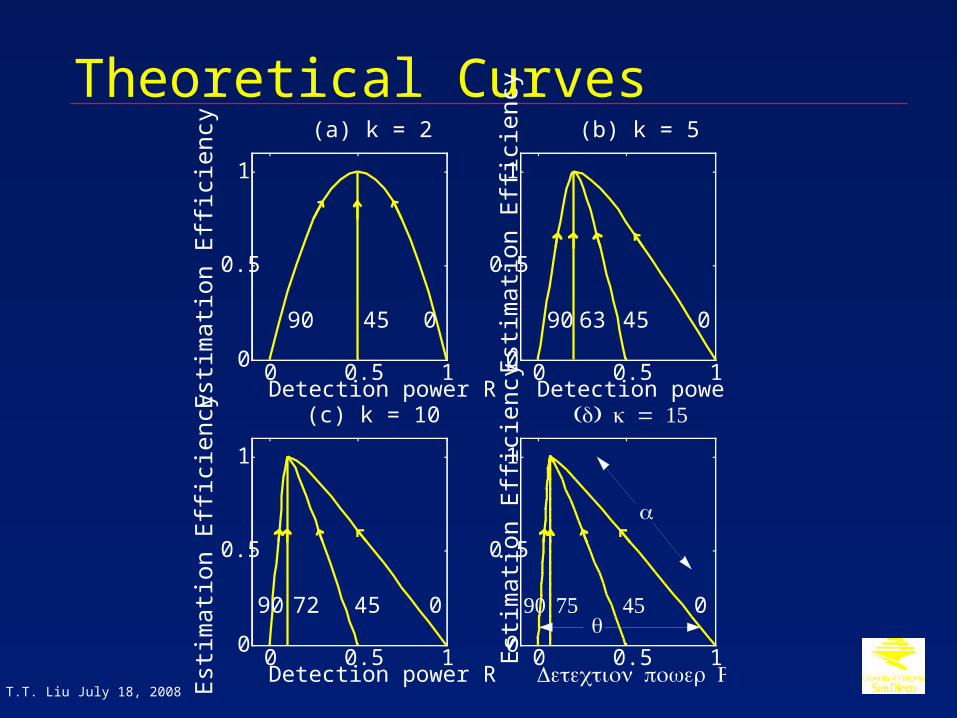
Theoretical Curves
0 0.5 10
0.5
1
Detection power R
(a) k = 2
90 45 0
0 0.5 10
0.5
1
Detection power R
(b) k = 5
90 63 45 0
0 0.5 10
0.5
1
Detection power R
(c) k = 10
90 72 45 0
0 0.5 10
0.5
1
0
α
45
( ) = 15d k
Detection power R
θ7590
Estimation Efficiency
Estimation Efficiency
Estimation Efficiency
Estimation Efficiency

T.T. Liu July 18, 2008
Efficiency vs. Power
0 0.2 0.4 0.6 0.8 1 1.2
-0.2
0
0.2
0.4
0.6
0.8
1
1.2
D
C
B
A
12481632
random
Periodic Single Trial
Detection Power
Estimation Efficiency
T.T. Liu July 18, 2008
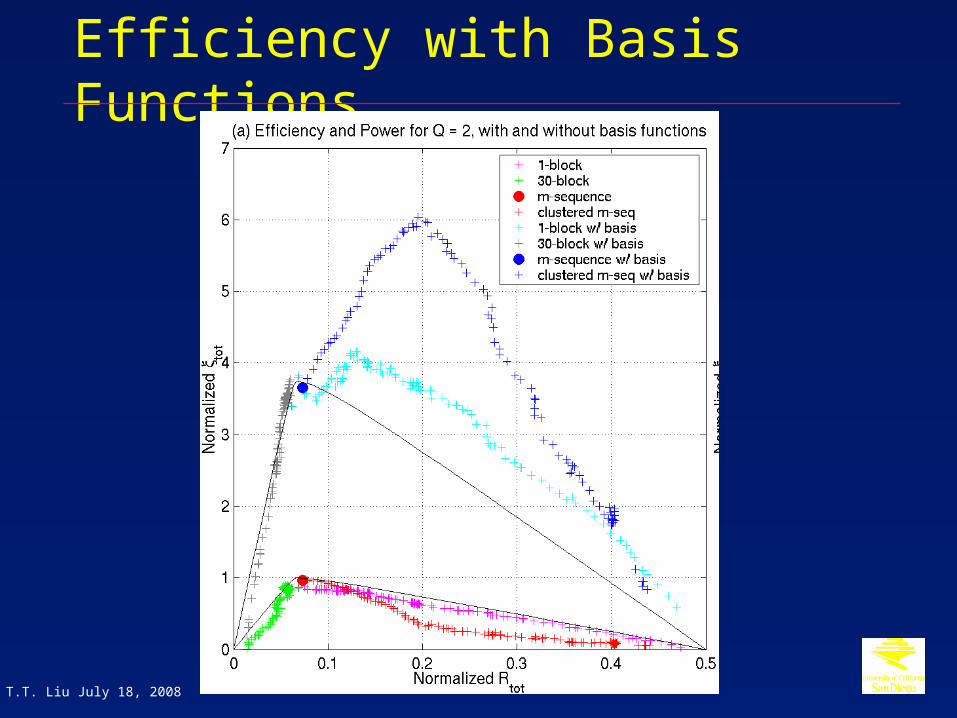
Efficiency with Basis Functions

T.T. Liu July 18, 2008
Knowledge (Assumptions) about HRF
None Some Total
Experiments where you want to characterize in detail the shape of the HDR.
Experiments where you have a good guess as to the shape (either a canonical form or measured HDR) and want to detect activation.
A reasonable compromise between 1 and 2. Detect activation when you sort of know the shape. Characterize the shape when you sort of know its properties

T.T. Liu July 18, 2008
Question
If block designs are so good for detecting activation, why bother using other types of designs?
Problems with habituation and anticipation
Less Predictable

T.T. Liu July 18, 2008
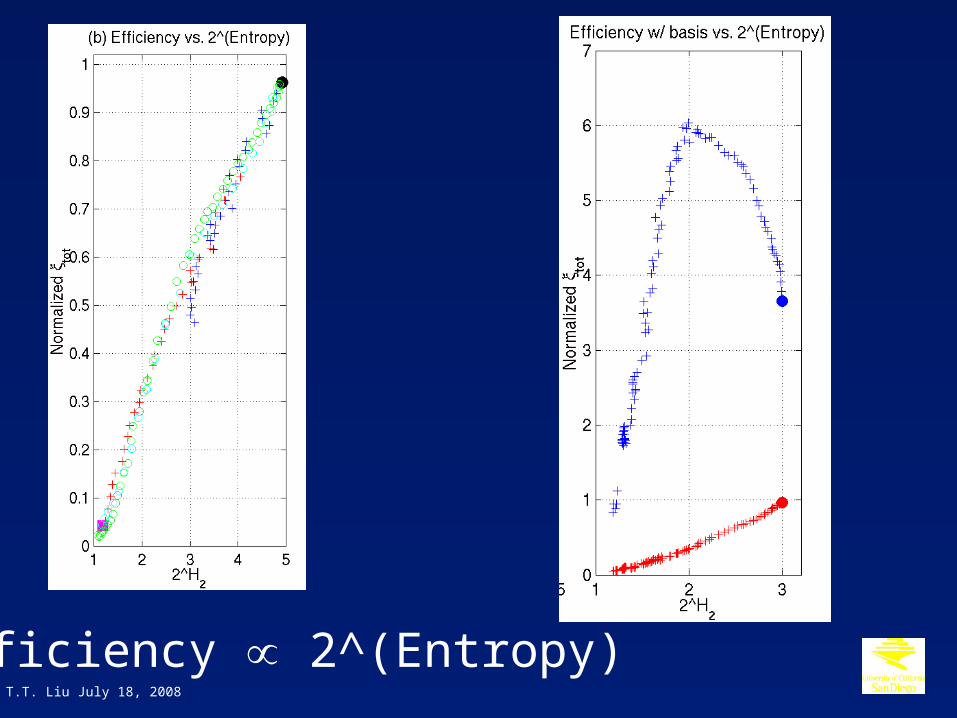
EntropyPerceived randomness of an experimental design is an important factor and can be critical for circumventing experimental confounds such as habituation and anticipation.
€
2H ris a measure of the average number of possible outcomes.
Conditional entropy is a measure of randomness in units of bits.
Rth order conditional entropy (Hr) is the average number of binary (yes/no) questions required to determine the next trial type given knowledge of the r previous trial types.

T.T. Liu July 18, 2008
Entropy Example
Maximum entropy is 1 bit, since at most one needs to only ask one question to determine what the next trial is (e.g. is the next trial A?). With maximum entropy, 21 = 2 is the number of equally likely outcomes.
Maximum entropy is 2 bits, since at most one would need to ask 2 questions to determine the next trial type. With maximum entropy, the number of equally likely outcomes to choose from is 4 (22).
A A N A A N A A A N
A C B N C B A A B C N A

T.T. Liu July 18, 2008
T.T. Liu July 18, 2008
Efficiency 2^(Entropy)

T.T. Liu July 18, 2008
Multiple Trial Types
1 trial type + control (null)A A N A A N A A A N
Extend to experiments with multiple trial typesA B A B N N A N B B A N A N A
B A D B A N D B C N D N B C N

T.T. Liu July 18, 2008
Multiple Trial Types GLM
y = Xh + Sb + n
X = [X1 X2 … XQ]
h = [h1T h2
T … hQT]T

T.T. Liu July 18, 2008
Multiple Trial Types OverviewEfficiency includes individual trials and also contrasts between trials.
€
Rtot =K
average variance of HRF amplitude estimates
for all trial types and pairwise contrasts
⎛
⎝ ⎜
⎞
⎠ ⎟
€
ξtot =1
average variance of HRF estimates
for all trial types and pairwise contrasts
⎛
⎝ ⎜
⎞
⎠ ⎟

T.T. Liu July 18, 2008
Multiple Trial Types Trade-off

T.T. Liu July 18, 2008
Optimal Frequency Can also weight how much you care about individual trials or contrasts. Or all trials versus events. Optimal frequency of occurrence depends on weighting.Example: With Q = 2 trial types, if only contrasts are of interest p = 0.5. If only trials are of interest, p = 0.2929. If both trials and contrasts are of interest p = 1/3.
€
p =Q(2k1 −1)+ Q 2 (1 − k1)+ k1
1/2 Q(2k1 −1)+ Q 2 (1 − k1)( )1/2
Q(Q −1)(k1Q −Q − k1)

T.T. Liu July 18, 2008
DesignAs the number of trial types increases, it becomes more difficult to achieve the theoretical trade-offs. Random search becomes impractical.
For unknown HDR, should use an m-sequence based design when possible.
Designs based on block or m-sequences are useful for obtaining intermediate trade-offs or for optimizing with basis functions or correlated noise.

T.T. Liu July 18, 2008
Optimality of m-sequences

T.T. Liu July 18, 2008
Clustered m-sequences

T.T. Liu July 18, 2008
Genetic Algorithms
QuickTime™ and a decompressor
are needed to see this picture.
Wager and Nichols 2003

T.T. Liu July 18, 2008
Genetic Algorithms
Wager and Nichols 2003
QuickTime™ and a decompressor
are needed to see this picture.

T.T. Liu July 18, 2008
Genetic Algorithms
Wager and Nichols 2003
QuickTime™ and a decompressor
are needed to see this picture.

T.T. Liu July 18, 2008
Genetic Algorithms
QuickTime™ and a decompressor
are needed to see this picture.
Kao et al. available at http://aaron.stat.uga.edu/~amandal

T.T. Liu July 18, 2008
Topics we haven’t covered.
The impact of correlated noise -- this will change the optimal design.
Impact of nonlinearities in the BOLD response.
Designs where the timing is constrained by psychology.

T.T. Liu July 18, 2008
Summary
• Efficiency as a metric of design performance.
• Efficiency depends on both experimental design and assumptions about HRF.
• Inherent tradeoff between power (detection of known HRF) and efficiency (estimation of HRF)