operating systems references: (1) operating systems, 3/e, gary nutt addison wesley, isbn...
TRANSCRIPT

Operating Systems
References:(1) Operating Systems, 3/e, Gary Nutt Addison Wesley, ISBN 0-201-77344-9(2) Operating Systems, 2/e, Andrew S. Tanenbaum Prentice Hall, ISBN 0-13-031358-0
Fenghui Yao

Definition
“An operating system is a collection of programs that acts as an intermediary between the hardware and its user(s), providing a high-level interface to low level hardware resources, such as CPU, memory, and I/O devices. The operating system provides various facilities and services that make the use of the hardware convenient, efficient, and safe.”
Lazowska, E.D.

The layered model
• A computer system consists of– hardware– system programs– application programs
Application Programs: Solve problems for their users
System programs: Manage the operations of the computer itself.
OS: most fundamental of all the system program, control all computer resources, provides the base upon which the application programs can be run.

What is an Operating System• Top-down view: what a programmer wants is simple, high-level abstraction
to deal with
– OS as an extended/virtual machine
– OS hiding details in order to
• make programming easier
• portability: making programs independent of hardware details
• Bottom-up view
– OS as a resource manager
– OS control and schedule the resources
• keep track of who is using which resource
• grant resource requests
• account for resource usage
• mediate conflicting requests
- e.g., concurrent write operation on a printer

History of Operating Systems
• OS versus developments in computer architecture
• Modern OS development started between late 70s and early 80s

• First generation 1945 - 1955– vacuum tubes, plug boards– No operating system

Second generation 1955 - 1965transistors, batch systems
Early batch system– bring cards to 1401– read cards to tape– put tape on 7094 which does computing– put tape on 1401 which prints output
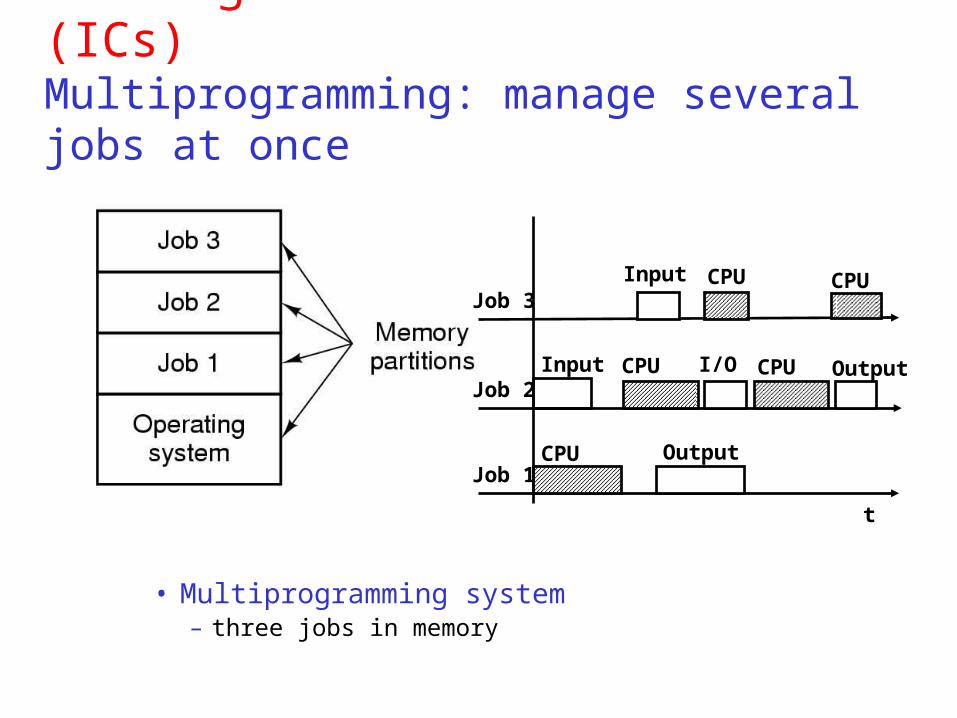
Third generation 1965 – 1980 (ICs)Multiprogramming: manage several jobs at once
• Multiprogramming system – three jobs in memory
CPU Output Job 1
Input CPU Job 2
CPU Input Job 3
I/O CPU Output
CPU
t

• Another major feature: SPOOL (Simultaneous Peripherals Operation On Line)
• A variant of multiprogramming: TSS (Time Sharing System) • Key TSS development: CTSS developed by MIT, TSS by IBM, MULTICS: developed at MIT, GE, and Bell, successor of CTSS• Minicomputers: phenomenal growth, PDP series Ken Thompson (Bell Labs, worked on MULTICS project) wrote a stripped-down, one-user MULTICS on PDP-7 UNIX
I/O Job 1
Job 2
Job 3
t
CPU Processing

Fourth generation: 1980-present• CP/M (Control Program for Microcomputers)• MS-DOS (Microsoft Disk Operating System)
- command line• Windows 9X, Windows NT, Windows 2000, XP
- GUI• Mac OS – GUI • UNIX
- Command line
- X Windows, Motif
All computers running network operating system.

OS Concepts – Process (1) (Chap 6, Chap7)
A process is basically a program in execution.
Each process has a well-defined context – program counter – stack pointer – registers – … Process table maintains an entry for each process: all
information about each process Each process needs some CPU time to perform – scheduling: assign a process to CPU FIFO, round-robin, …, – goals: fairness, high utilization

OS Concepts – Process (2)
• Process can create one or more other processes
– child processes
– process tree structure
• Interprocess communication: related processes that are cooperating to get some job done often need to communicate with one another and synchronize their activity.
– between the processes in the same tree, i.e., same owner
– between the processes in the different trees, i.e., different owners
– semaphore, message passing, …

OS Concepts – deadlock
(a) A potential deadlock. (b) an actual deadlock.

OS Concepts – Memory Management
Memory address space management

OS Concepts – Input/Output
• I/O subsystem for managing its I/O devices• I/O software
– device independent: apply to many or all I/O devices equally well
– device dependent: specific to particular I/O device, e.g., device driver
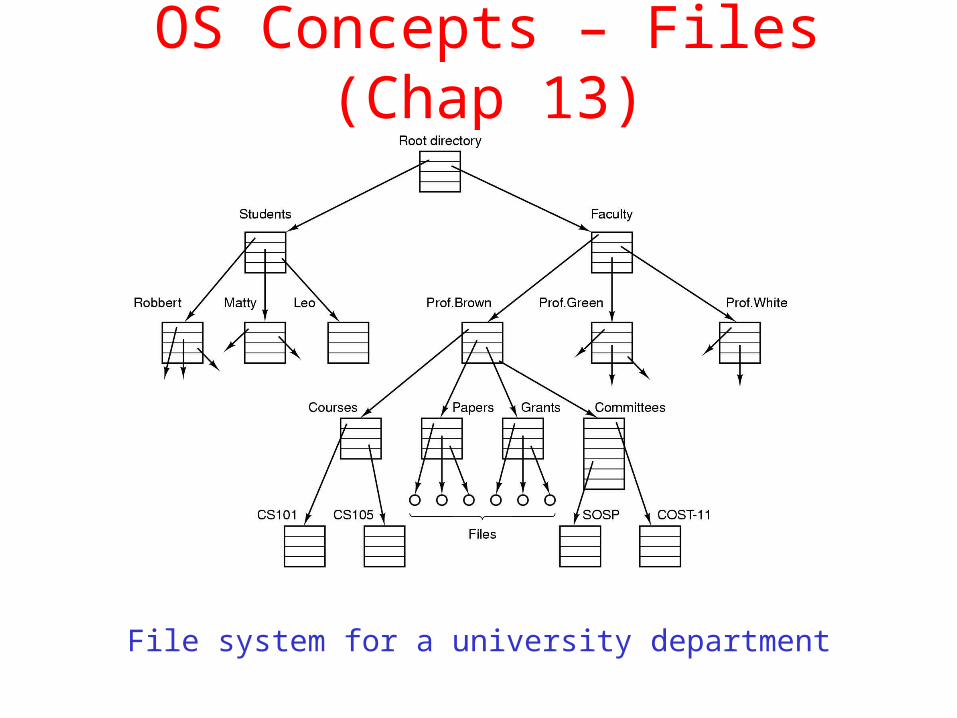
OS Concepts – Files (Chap 13)
File system for a university department
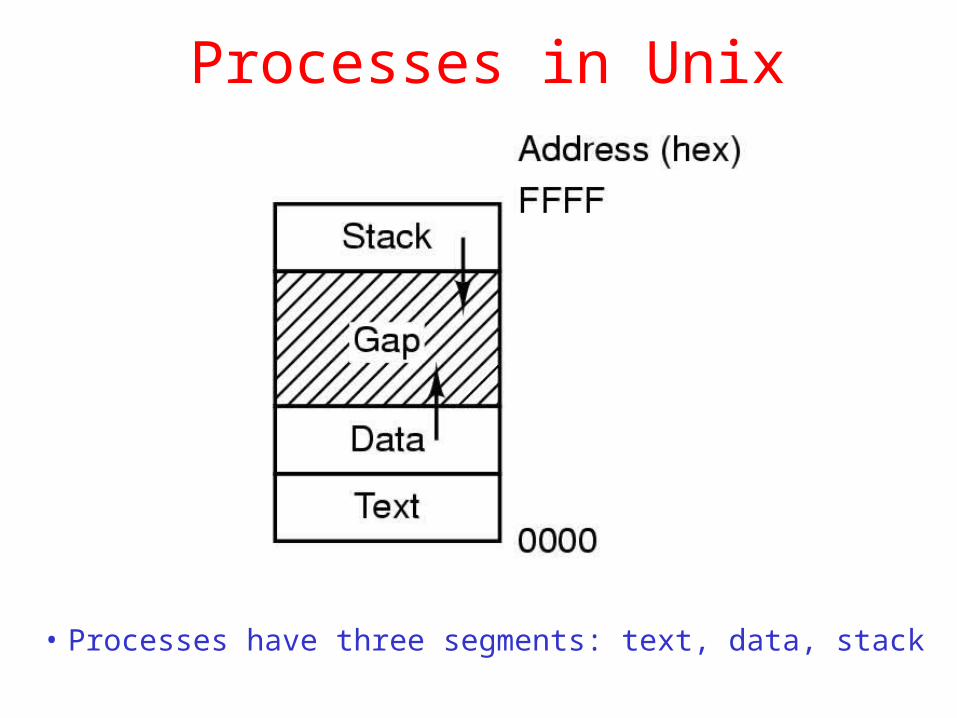
Processes in Unix
• Processes have three segments: text, data, stack

• Kernel: The software that contains the core components of operating system is called the kernel.
• Core components
– Process scheduler: when and for how long a process execute.
– Memory manager:when and how memory is allocated to processes and what to do when main memory becomes full.
– I/O manager: which serves input and output requests from and to hardware devices, respectively.
– IPC manager: which allow processes to communicate with one another.
– File system manager: which organized named collections of data on storage devices and provides an interface for accessing data on those devices
• Microkernel : process management, file system interaction, networking – execute outside the kernel.

Processes and Threads
Processes Threads Interprocess communication Classical IPC problems Scheduling

Process
OS AddressSpace
OS AddressSpace
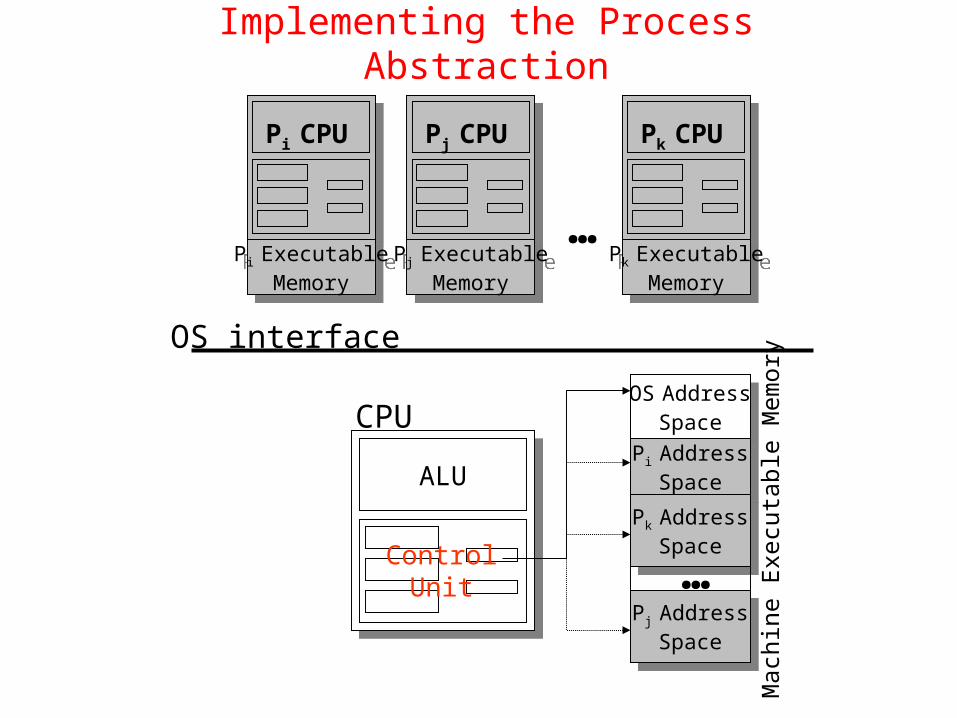
Implementing the Process Abstraction
ControlUnit
OS interface
…
Mac
hine
Exe
cuta
ble
Mem
ory
ALU
CPUPi Address
Space
Pi AddressSpace
Pi CPU
Pi ExecutableMemory
Pi ExecutableMemory
Pk AddressSpace
Pk AddressSpace
…
Pk CPU
Pk ExecutableMemory
Pk ExecutableMemory
Pj AddressSpace
Pj AddressSpace
Pj CPU
Pj ExecutableMemory
Pj ExecutableMemory
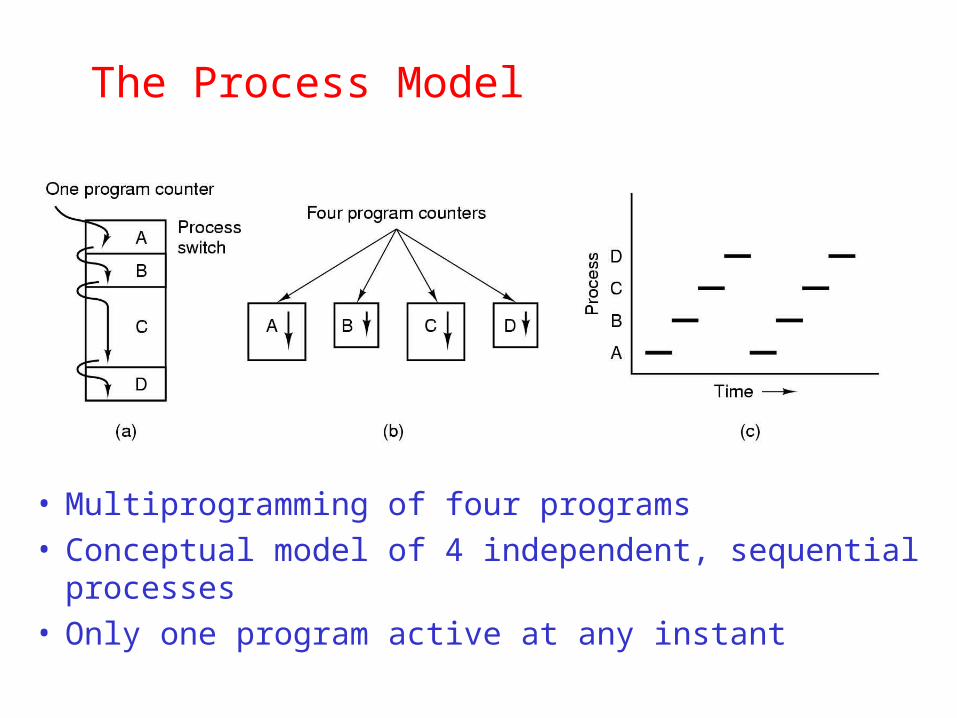
The Process Model
• Multiprogramming of four programs• Conceptual model of 4 independent, sequential processes• Only one program active at any instant

Process Creation
Four Principal events that cause process creation
1. System initialization
2. Execution of a process creation system
3. User request to create a new process
4. Initiation of a batch job

Process Termination
Conditions which terminate processes
1. Normal exit (voluntary)
2. Error exit (voluntary)
3. Fatal error (involuntary)
4. Killed by another process (involuntary)

Process Hierarchies
• Parent creates a child process, child processes can create its own processes
• Forms a hierarchy
– UNIX calls this a "process group" (process tree)
– process in UNIX cannot disinherit their children.
• Windows has no concept of process hierarchy
– all processes are equal.
– When a process is created, the parent is given a special token (handle) that it can use to control child.
– It is free to pass the handle to some other process, thus invalidating the hierarchy.

Process States - (1)
Example
cat chapter1 | grep tree
– two processes: cat, grep
– grep must wait, if there is no input waiting for it

Process States (2)
• Possible process states
– Running: actually using the CPU at that time.
– Ready: runnable; temporarily stopped to let another process run.
– Blocked: unable to run until some external event happens.
• Transitions between states

UNIX State Transition Diagram
Runnable
UninterruptibleSleep
Running
Start
Schedule
Request
Done
I/O Request
Allocate
zombie
Wait byparent
Sleeping
Traced or Stopped
Request
I/O Complete Resume
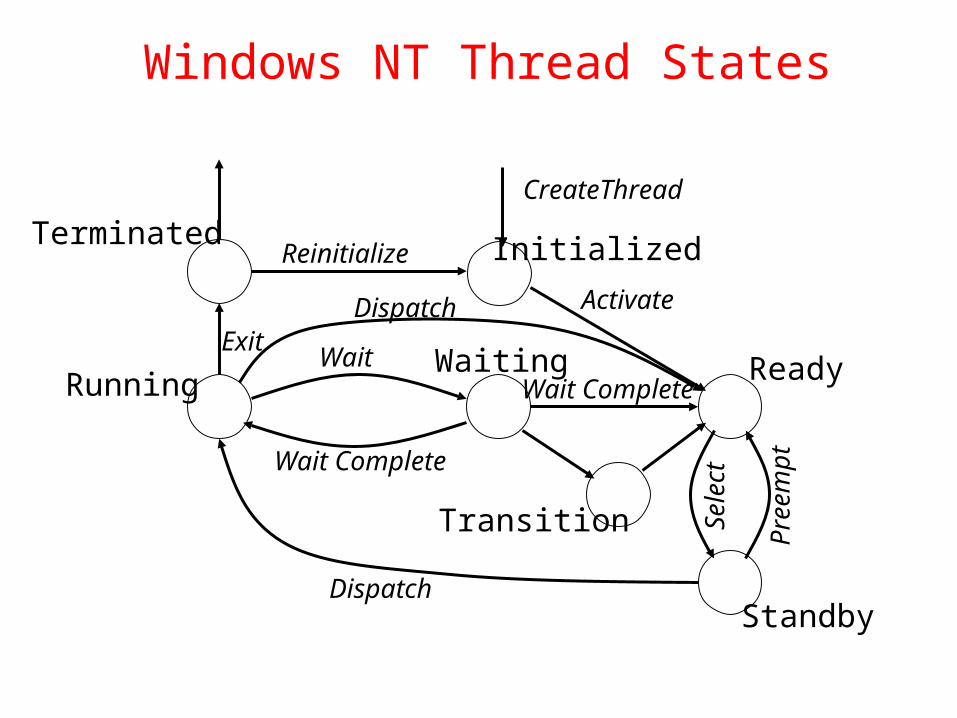
Windows NT Thread States
Initialized
CreateThread
Ready
Activate
Sele
ct
Standby
Running
Terminated
Waiting
Transition
Reinitialize
Exit
Pre
empt
Dispatch
WaitWait Complete
Wait Complete
Dispatch
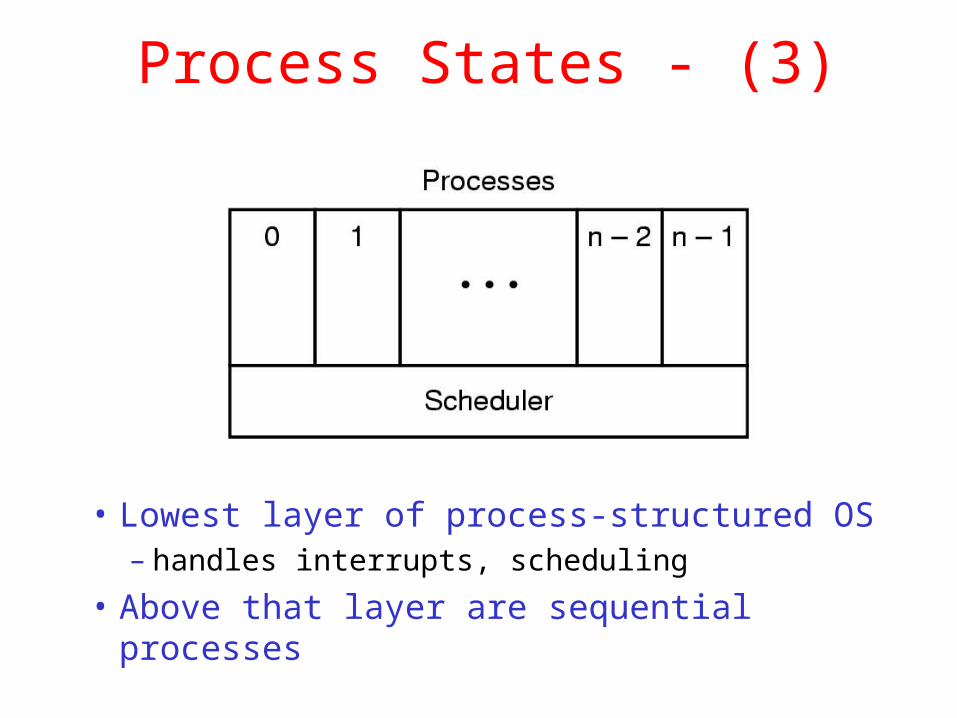
Process States - (3)
• Lowest layer of process-structured OS– handles interrupts, scheduling
• Above that layer are sequential processes

Implementation of Processes - (1)
Some of the fields of a typical process table entry

Thread

The Thread Model - (1)
Definition: A thread is a single sequential flow of control within a program (also called thread of execution or thread of control).
(a)
(b)
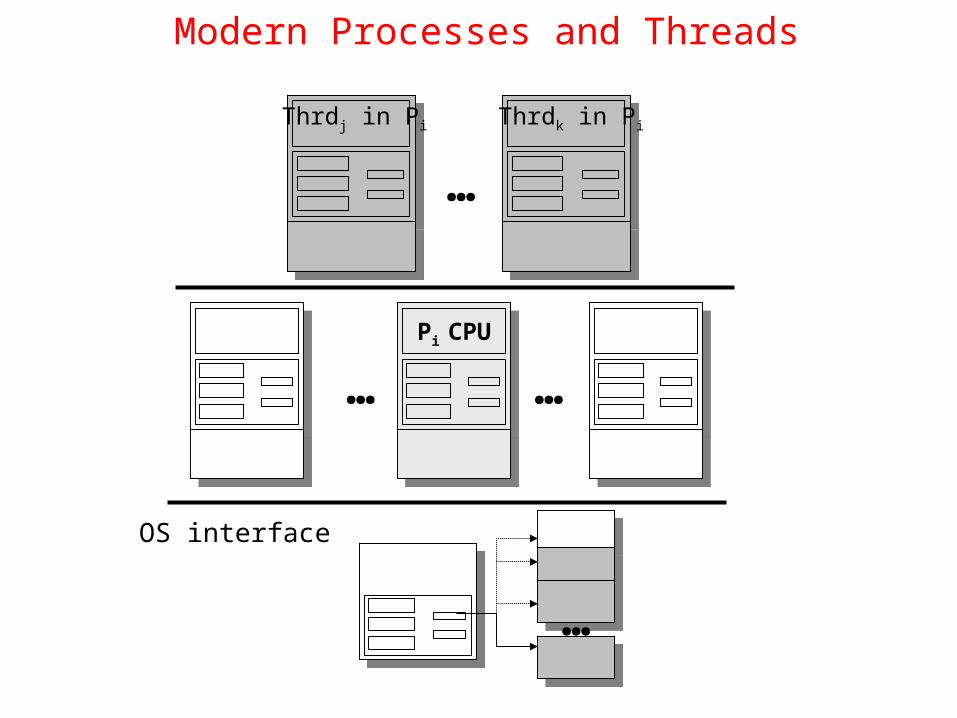
Modern Processes and Threads
OS interface
…
…
…Pi CPU
Thrdj in Pi Thrdk in Pi
…
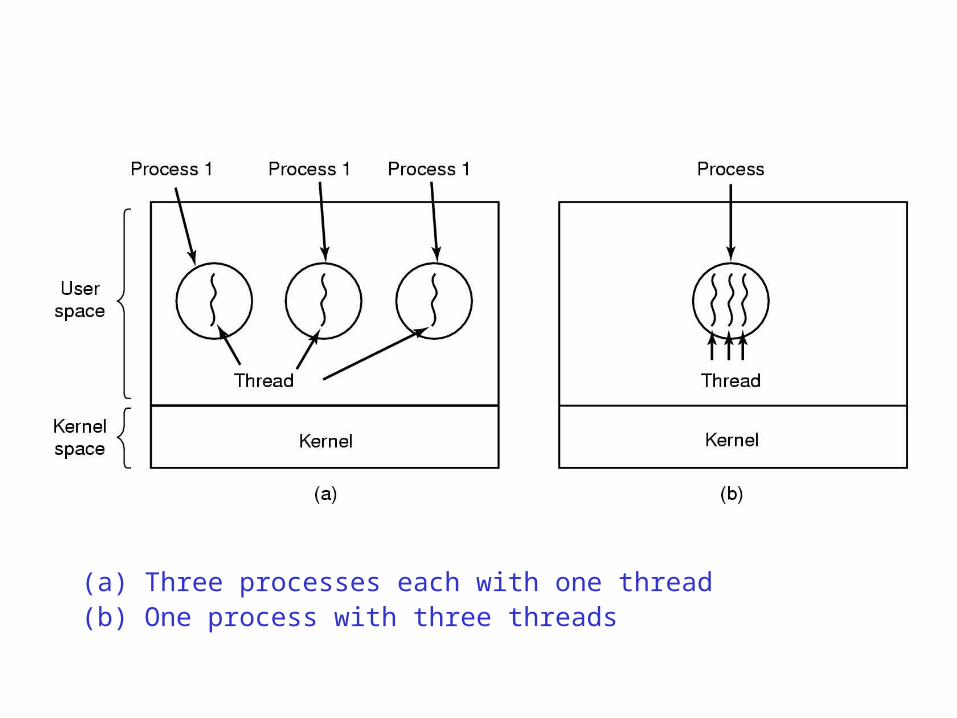
(a) Three processes each with one thread(b) One process with three threads

The Thread Model - (2)
• Threads have some of the properties of processes, they are sometimes called light processes. The term multithreading is used to describe the situation of allowing multiple threads in the same process.
• Items shared by all threads in a process
• Items private to each thread
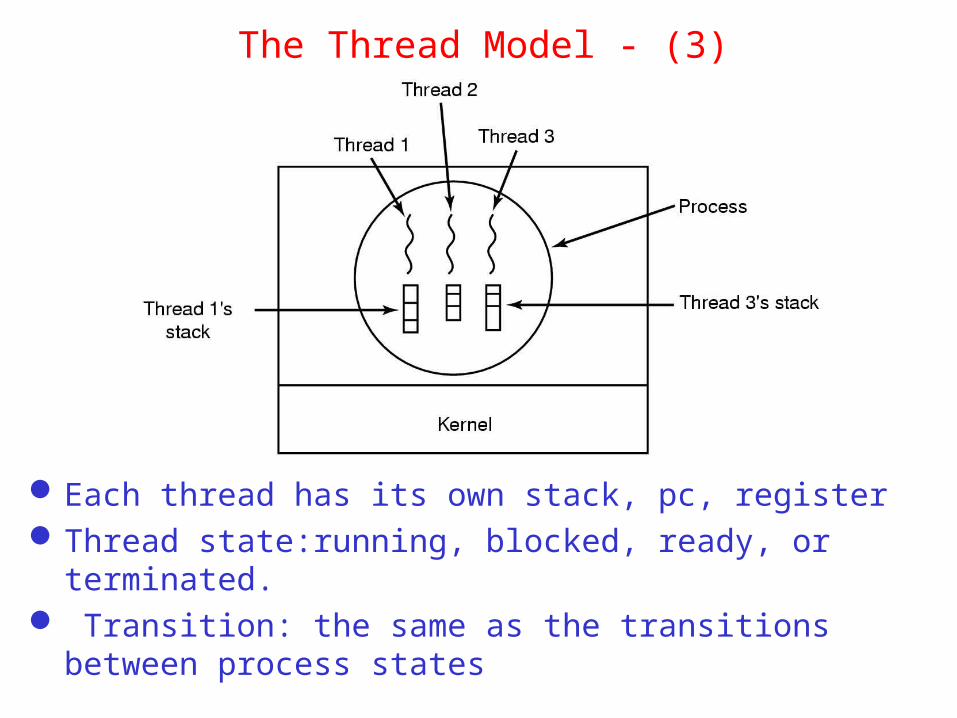
The Thread Model - (3)
Each thread has its own stack, pc, registerThread state:running, blocked, ready, or terminated. Transition: the same as the transitions between process states

The Thread Model - (4)
Why necessary ?
By decomposing an application into multiple sequential threads that run in quasi-parallel, the programming model become simpler.
They do not have any resource attached to them, they are easier to create and destroy than process. (100 times faster )
Performance: when there is substantial computing and also substantial I/O, having threads allows activities to overlap, thus speed up the application.
Threads are useful on systems with multiple CPUs, where real parallelism is possible.
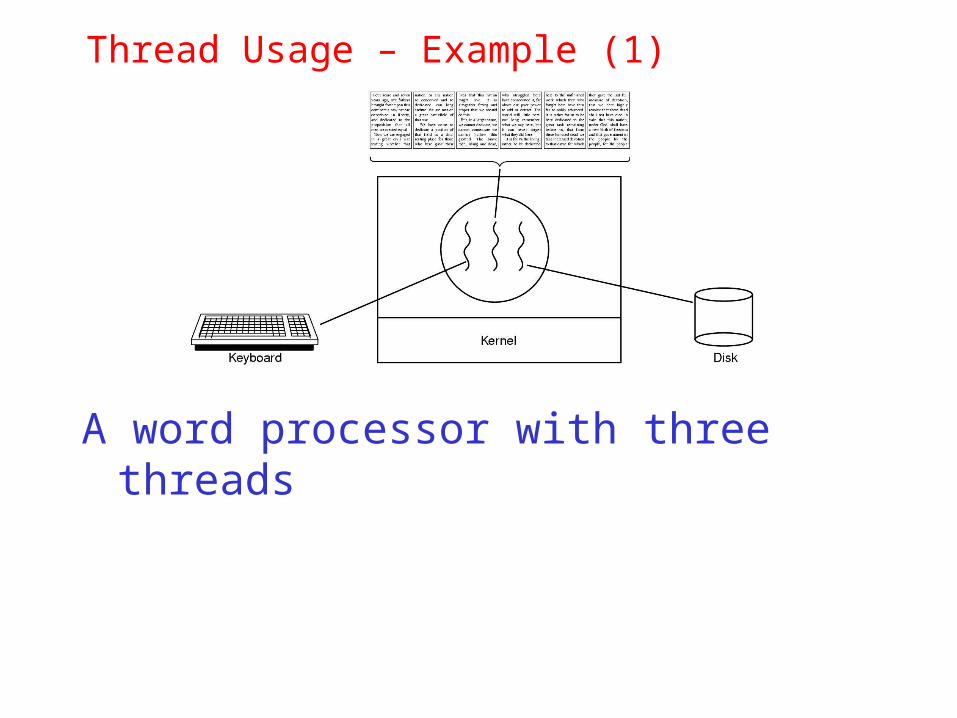
Thread Usage – Example (1)
A word processor with three threads
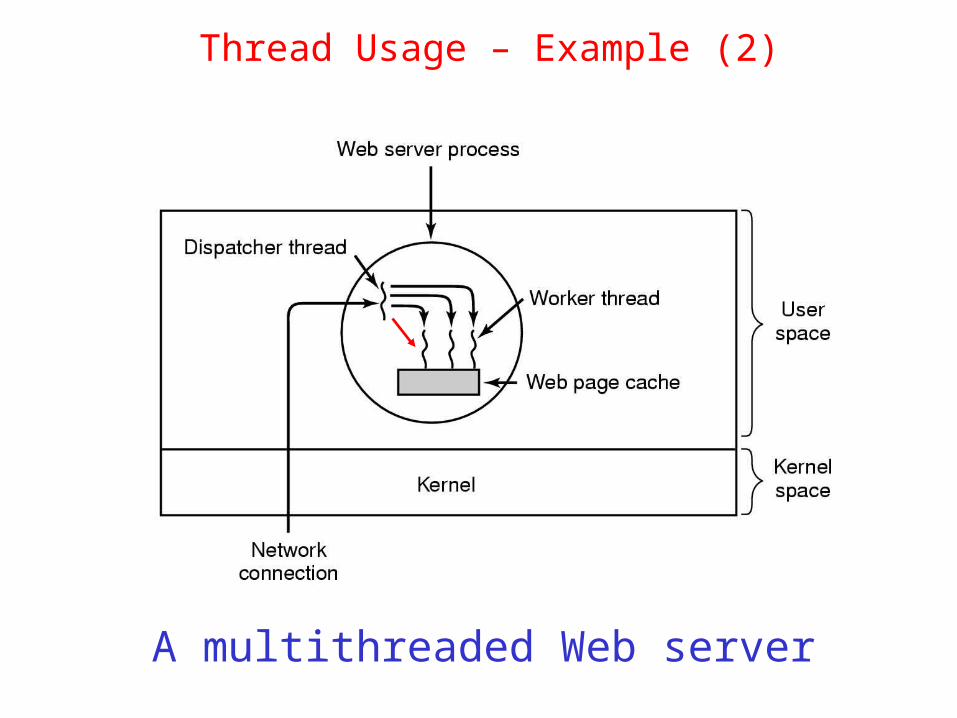
Thread Usage – Example (2)
A multithreaded Web server
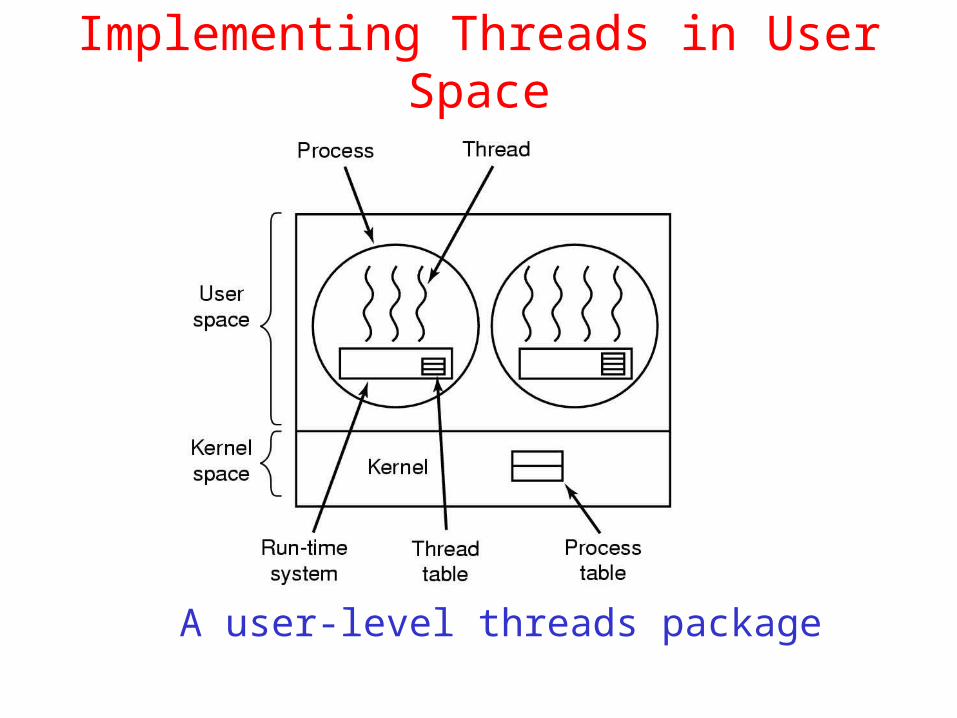
Implementing Threads in User Space
A user-level threads package

Implementing Threads in User Space Advantages:
- can be implemented on an operating system that does not support threads.
- thread switching is fast (if a machine has an instruction to store all registers and one to load them all).
- thread scheduling is fast.
- allow each process to have its own customized scheduling algorithm. Problems:
- how blocking system calls are implemented.
Ans: change all system calls to nonblocking, but unattractive.
- thread scheduling. If a thread starts running, no other thread in that process will ever run unless the first thread voluntarily gives up the CPU.
Ans: to have the run-time system request a clock signal (interrupt) once a second to give it control, but is crude and messy to the program.

Implementing Threads in the Kernel
A threads package managed by the kernel

Hybrid Implementations
Multiplexing user-level threads onto kernel- level threads

Comparison (benefits)
user-level threads kernel-level threads
User-level threads are more portable because they don’t rely on a particular OS’s threading.
The kernel can dispatch a process’s threads to several processors at once, this can improve performance designed for current execution.
Run-time system procedure controls how the threads are scheduled, programmers can tune scheduling algorithm to meet the needs.
Kernel manages each thread individually, applications that perform blocking I/O can execute other threads while waiting for I/O operation.
Because user-level threads don’t invoke the kernel for scheduling, user-level threaded processes benefit low overhead relative to threads that rely on the kernel.
Kernel-level threads enable OS’s dispatcher to recognize each user thread individually. A process that uses kernel-level threads can adjust the level of service each thread receives from OS.

Comparison (deficiencies)
user-level threads kernel-level threads
The entire process blocks when any of its threads requests a blocking I/O operation, because the entire multithreaded process is the only thread that OS recognizes. This can slow the progress for multithreaded processes.
Less efficient than user-level thread implementation, because scheduling and synchronization operation invoke kernel, which increase overhead.
If a thread starts running, no other thread in that process will ever run unless the first thread voluntarily gives up CPU. One possible solution is to have run-time system request periodic clock interrupt. total overhead increase.
Software that employs kernel-level threads is often less portable.

Windows threads are scheduled at kernel space.
( Intel extends Hyper-Threading Technology† to a variety of desktop PCs, with the new Intel® Pentium® 4 processor, featuring an advanced 800 MHz system bus and speeds ranging from 2.40C to 3.20 GHz. Hyper-Threading Technology enables the processor to execute two threads (parts of a software program) in parallel - so your software can run more efficiently and you can multitask more effectively.)
User-level thread examples
POSIX Pthreads (POSIX: IEEE developed a standard for UNIX)Mach C-threads
(Mach, the operating system of all NeXT computers, was designed by researchers at Carnegie Mellon University (CMU). Mach is based on a simple communication-oriented kernel, and is designed to support distributed and parallel computation while still providing UNIX 4.3BSD compatibility.)
Sun Solaris combines both.

How about Java thread? Let’s discuss !! JVM (Java virtual machine) is a run-time system. Run-time system manages the threads. OS (Windows,
MacOS, UNIX) does nothing. Java applications are portable (OS independent).
Questions

Interprocess Communication

Interprocess Communication
There are three issues here
(1) How one process can pass information to another.
(2) The second has to do with making sure two or more processes
do not get into each other’s way when engaging in critical
activities.
(3) The third concerns proper sequencing when dependencies are
present.
We will discuss the problem in the context of processes, but the same problems and solutions also apply to threads.

Race Conditions
What is race condition?
It occurs when multiple processes simultaneously compete for the same serially reusable resource, and that resource is allocated to these processes in an indeterminate order. This can cause subtle program errors when the order in which processes access a resource is important.
Race conditions should be avoided because they can cause subtle error and are difficult to debug.
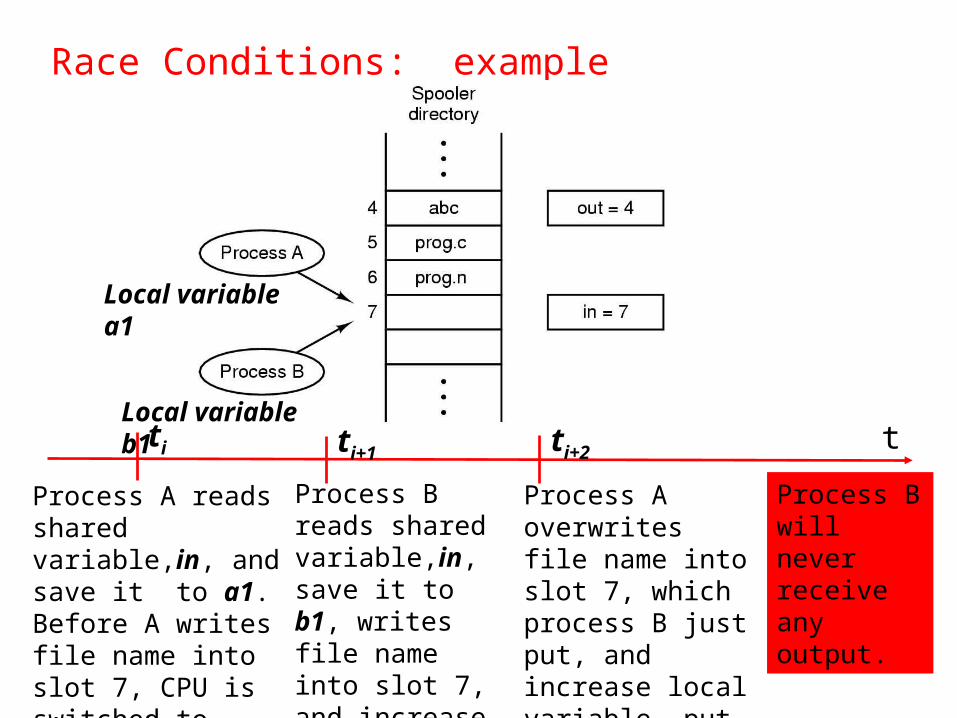
Race Conditions: example
t
Process A reads shared variable,in, and save it to a1. Before A writes file name into slot 7, CPU is switched to process B.
ti ti+1
Process B reads shared variable,in, save it to b1, writes file name into slot 7, and increase in to 8. CPU is switched to process A.
ti+2
Process A overwrites file name into slot 7, which process B just put, and increase local variable, put it back to in.
Process B will never receive any output.
Local variable a1
Local variable b1

Critical Regions - (1)
How to avoid race condition?
Ans: to find some way to prohibit more than one process from reading and writing the shared data at the same time. Mutual exclusion is required.
Mutual exclusion: some way of making sure that if one process is using a shared variable or file, the other processes will be excluded from doing the same thing.

The problem of avoiding race conditions can also be formulated in an abstract way – critical section.
Critical section (or critical region): Section of program that perform operation on shared resource.
Four conditions to provide mutual exclusion No two processes simultaneously in critical region No assumptions made about speeds or numbers of CPUs No process running outside its critical region may block another process No process must wait forever to enter its critical region
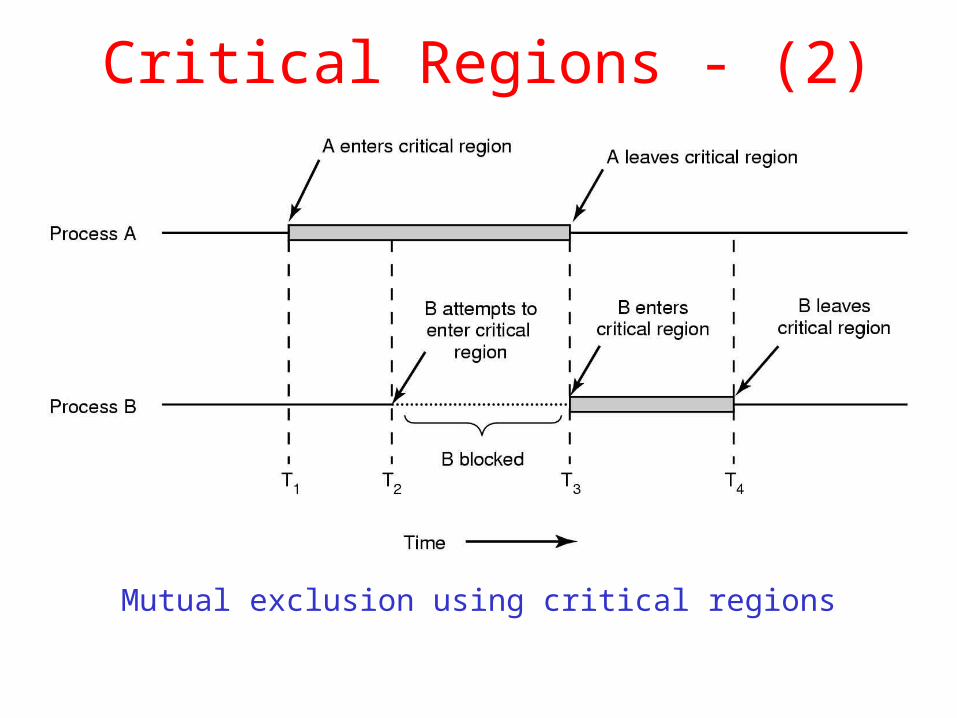
Critical Regions - (2)
Mutual exclusion using critical regions

Mutual Exclusion with Busy Waiting
Disable interrupts
To have each process disable all interrupts just after entering its critical region and re-enable them just before leaving it.
— Not attractive, because it is unwise to give user processes the power to turn off interrupts.

Lock variables
Use a shared variable, lock, initially 0. When a process wants to enter its critical region, it first tests lock. If lock =0 (no process is in its critical region), the process sets it to 1 and enter critical region. Otherwise (lock =1, some process is in its critical region), the process just waits until lock becomes 0 (set by other process).
— Does not work well. The situation as given in printer spooler may happen.

Strict alternation (spin lock)
(a) Process 0. (b) Process 1.
This algorithm does avoid all races. But busy waiting will waste CPU power. And it may violates the condition 3 (“no process running outside its critical region (c.r.) may block another process”). — Not really a serious candidate.
P1 is working in n.c.r.. P0 leaves c.r., set turn to 1, and enter n.c.r.
P0 and P1 run their n.c.r.
P0 finishes its n.c.r. quickly, and go to c.r., but is locked by P1

Peterson's solution- combine the idea of taking turn with the idea of lock variables
Before entering its critical region, each process calls enter_region(). After it has finished critical region, the process calls leave_region().

Using TSL Instruction (multiple processors)
TSL RX, LOCK
TSL(Test and Set Logic) reads the contents of memory word lock into register RX and then stores a nonzero value at the memory address lock. The operations of reading the word and storing into it are indivisible.
CPU executing TSL instruction locks the memory bus to prohibit other CPUs from accessing memory until it is done.


Semaphores Defect of Peterson’s solution: requiring busy waiting Defect of method using TSL: requiring busy waiting IPC primitives that block instead of wasting CPU time: “sleep” and
“wakeup”.Sleep: a system call that cause caller to block, that is, be suspended until
another process wakes it up.Wakeup: to wake up the sleep process.
What is semaphore? A protected integer variable that determines if processes may enter their
critical region. It use two atomic operations, P and V. down: check to see if the value is greater than 0. If so, decrease the value. If
the value is 0, the process is put to sleep, without completing “down” for the moment.
up: increase the value of the semaphore. One of the sleeping processes is chosen by the system, and is allowed its down operation.

package concurrency.semaphore;// The Semaphore Class// up() is the V operation// down() is the P operationpublic class Semaphore { private int value; public Semaphore (int initial) { value = initial; } synchronized public void up() { ++value; notifyAll(); // should be notify() but does not work in some browsers } synchronized public void down() throws InterruptedException { while (value==0) wait(); --value; }}
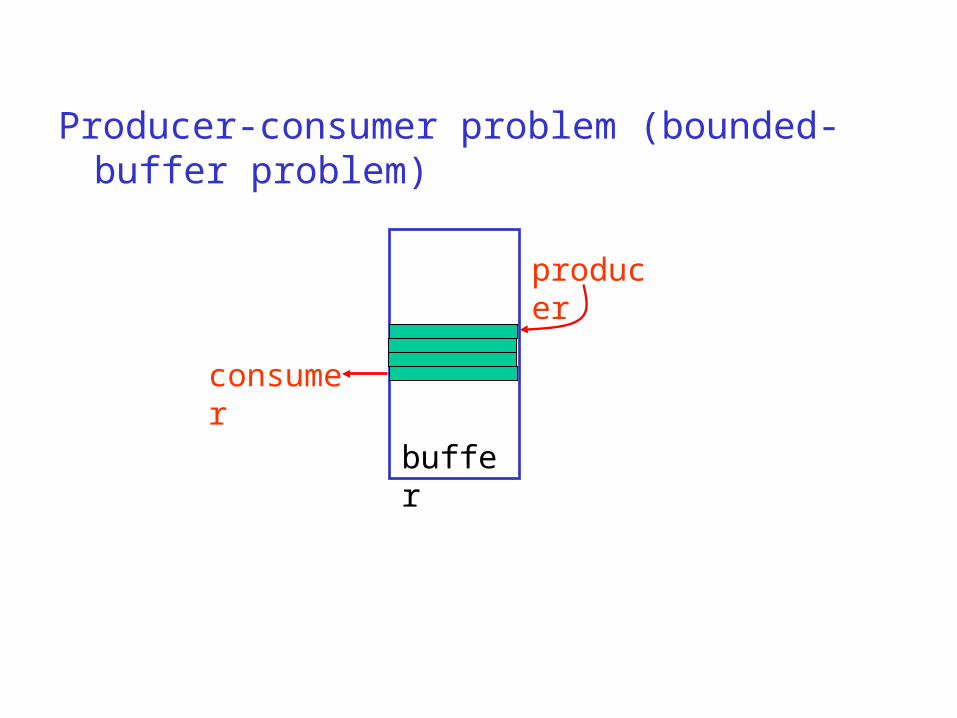
Producer-consumer problem (bounded-buffer problem)
buffer
producer
consumer

The producer-consumer problem using semaphores

Mutexes
What is mutex?
A mutex is a variable that can be in one of two states: uncloked or locked. it is a simplified version of the semaphore.

Implementation of mutex_lock and mutex_unlock

Scheduling

Scheduler - The part of OS that decides which process to run next.Scheduling Algorithm - The algorithm that the scheduler uses.Scheduling before the advent of PCs - A great deal of work has gone into devising clever and efficient
scheduling algorithms. Scheduling on PCs - Scheduling does not matter much on PCs (one active process;
computers have gotten faster). Scheduling on high-end networked workstations and servers - The scheduling matters again (processes compete for CPU)
Introduction to Scheduling
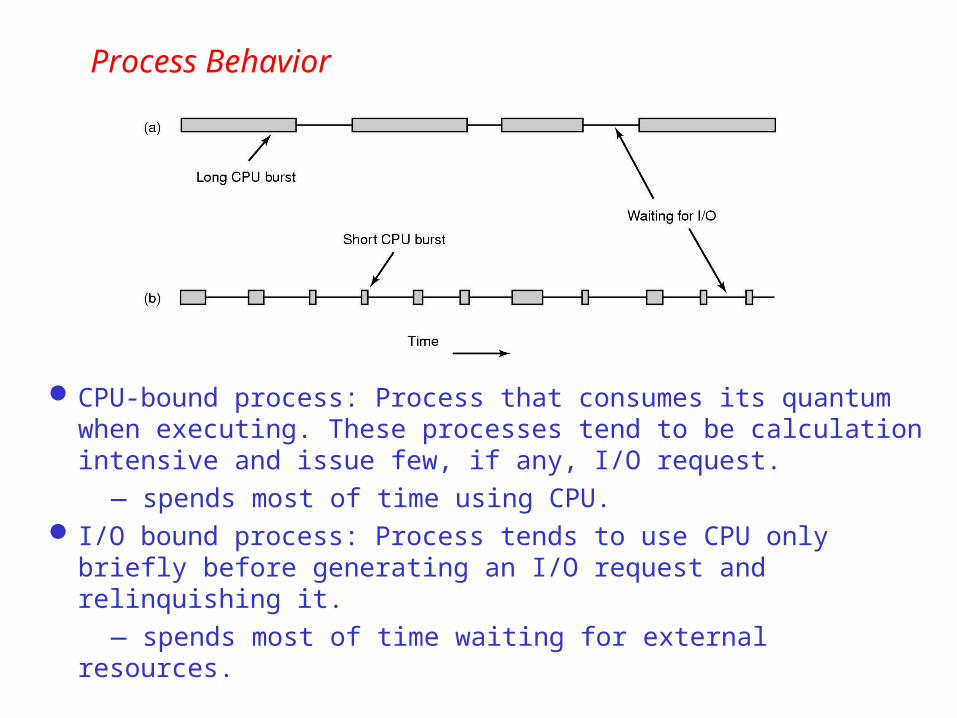
Process Behavior
CPU-bound process: Process that consumes its quantum when executing. These processes tend to be calculation intensive and issue few, if any, I/O request.
— spends most of time using CPU. I/O bound process: Process tends to use CPU only briefly before
generating an I/O request and relinquishing it.
— spends most of time waiting for external resources.

When to Schedule
When to schedule - when a process is created. - when a process exists. - when a process blocks on I/O, semaphore, or for some other
reason. - when an I/O interrupts. Categories with respect to how to deal with clock interrupts - Nonpreemptive scheduling algorithm: Scheduling policy that
does not allow the system to remove a processor from a process until that process voluntarily relinquishes its processor or turn to completion.
- Preemptive scheduling algorithm: Scheduling policy that allows the system to remove a processor from a process.

Categories of Scheduling Algorithms
Three environments worth distinguishing are:
1. Batch System: processes execute without user interaction.
- Nonpreemptive algorithms or preemptive algorithms with long time periods for each process are often acceptable.
2. Interactive system: That requires user input as it executes.
- Preemption is essential to keep one process from hogging the CPU and denying service to others.
3. Real-time system: That attempt to service request within a specified time period.
- Preemption is, oddly enough, sometimes not needed because the processes know that they may not run for long periods of time and usually do their work and block quickly.

Scheduling Algorithm Goals

Throughput: amount of work performed per unit time. It can be measured as the number of processes per unit time.
Tournaround time: the average time from the moment that a job is submitted until the moment it is completed. It measures how long the average user has to wait for output.
CPU utilization Response time: In an interactive systems, the time from when a
user press an Enter or clicks a mouse until the system delivers a final response.

Scheduling in Batch Systems
First-Come First Served (FCFS) Scheduling
That places arriving process in a queue; the process at the head of queue executes until it freely relinquishes CPU.
C B A Take out to run
Put into queue waiting for executionAdvantages
– Easy to understand and easy to program.Disadvantage
– Performance is not good, in some cases.
e.g., CPU-bound process runs for 1 second, followed by many I/O-bound processes that use little CPU time but perform 1000 disk reads. I/O-bound process takes 1000S to finish.

Shortest Job First — pick the shortest job first
Important: Shortest job first is only optimal when all jobs are available simultaneously.
FCFS algorithm (A is first) Shortest Job First (B is first)
A: 8
B: 8+4=12
C: 8+4+4=16
D: 8+4+4+4=20
Average=(8+12+16+20)/4=14
B: 4
C: 4+4=8
D: 4+4+4=12
A: 4+4+4+8=20
Average=(4+8+12+20)/4=11
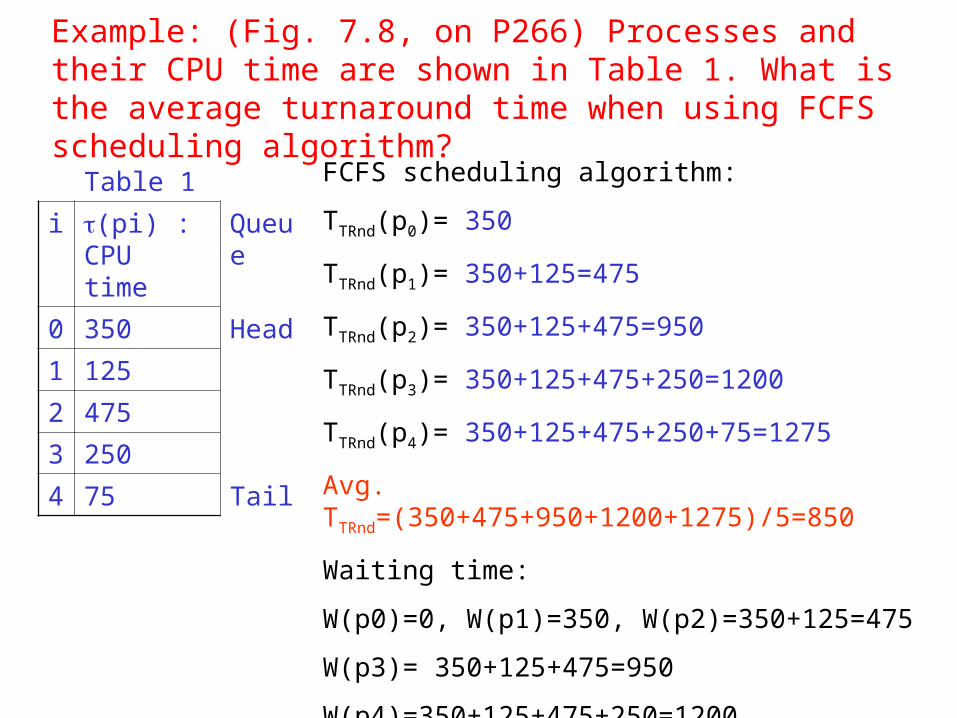
Example: (Fig. 7.8, on P266) Processes and their CPU time are shown in Table 1. What is the average turnaround time when using FCFS scheduling algorithm?
Table 1
i (pi) : CPU time
Queue
0 350 Head
1 125
2 475
3 250
4 75 Tail
FCFS scheduling algorithm:
TTRnd(p0)= 350
TTRnd(p1)= 350+125=475
TTRnd(p2)= 350+125+475=950
TTRnd(p3)= 350+125+475+250=1200
TTRnd(p4)= 350+125+475+250+75=1275
Avg. TTRnd=(350+475+950+1200+1275)/5=850
Waiting time:
W(p0)=0, W(p1)=350, W(p2)=350+125=475
W(p3)= 350+125+475=950
W(p4)=350+125+475+250=1200
Avg. W=(0+350+475+950+1200)/5=595

Table 2
i (pi) : CPU time
Queue
0 350 Head
1 125
2 475
3 250
4 75 Tail
SJN scheduling algorithm:
TTRnd(p4)= 75
TTRnd(p1)= 75+125=200
TTRnd(p3)= 75+125+250=450
TTRnd(p0)= 75+125+250+350=800
TTRnd(p2)= 75+125+250+350+475=1275
Avg. TTRnd=(75+200+450+800+1275)/5=560
Waiting time:
W(p4)=0, W(p1)=75, W(p3)=75+125=200
W(p0)= 75+125+250=450
W(p2)=75+125+250+350=800
Avg. W=(0+75+200+450+800)/5=305
Example: (Fig. 7.9, on P268) Processes and their CPU time are shown in Table 2. What is the average turnaround time when using FCFS scheduling algorithm?

Shortest Remaining First — preemptive version of shortest job first
With this algorithm, the scheduler always chooses the process whose remaining run time is the shortest.
Again, the run time has to be known in advance.

Three-Level Scheduling
Admission scheduler: decide which jobs to admit to system. Memory scheduler: decide which processes should be kept in memory,
and which one kept on disk. The number of processes in memory is called degree of multiprogramming.
CPU scheduler: pick one of the ready processes in main memory and run next.

Scheduling in Interactive Systems
Round Robin SchedulingScheduling policy that permits each ready process to execute for at
most one quantum per round. The interesting issue: the length of the quantum. e.g., context switch takes 1ms, quantum is set at 4ms, then 20%
of CPU time is wasted on context switching. Too much! A quantum around 20 – 50 ms is reasonable (context switch: saving and loading registers and memory maps,
updating various tables, flushing and reloading the memory maps, etc.)
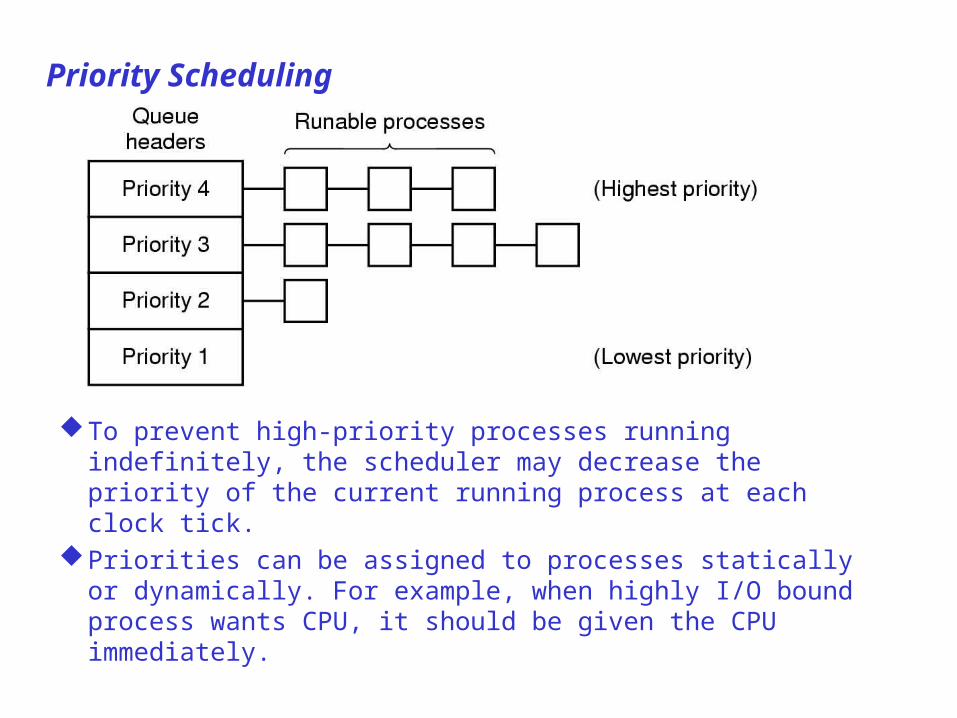
Priority Scheduling
To prevent high-priority processes running indefinitely, the scheduler may decrease the priority of the current running process at each clock tick.
Priorities can be assigned to processes statically or dynamically. For example, when highly I/O bound process wants CPU, it should be given the CPU immediately.

Lottery Scheduling
The basic idea is to give processes lottery tickets for various system resources, such as CPU time.
Interesting properties: New process has opportunity to run next. Cooperating processes may exchange tickets if they wish. e.g., client process server process exchange tickets. To solve problems that are difficult to handle with other
methodse.g., a video server in which several processes are feeding
video stream at different frame rates, 10, 20, 25 frames / s, allocate these processes 10, 20, 25 tickets.

Fair-share Scheduling
The basic idea is to take into account who owns a process before scheduling.
e.g., user1 has four processes, A, B, C, and D, user2 has one process, E.
(1) Scheduling without regard to who its owner is:
A B C D E A B C D E …
User 1 gets 80% CPU time, user 2 gets 20%. Unfair.
(2) Scheduling with regard to who its owner is. Suppose each user has been promised 50% CPU time.
A E B E C E D E A E …
User 1 gets 50% CPU time, user 2 gets 50%. fair.
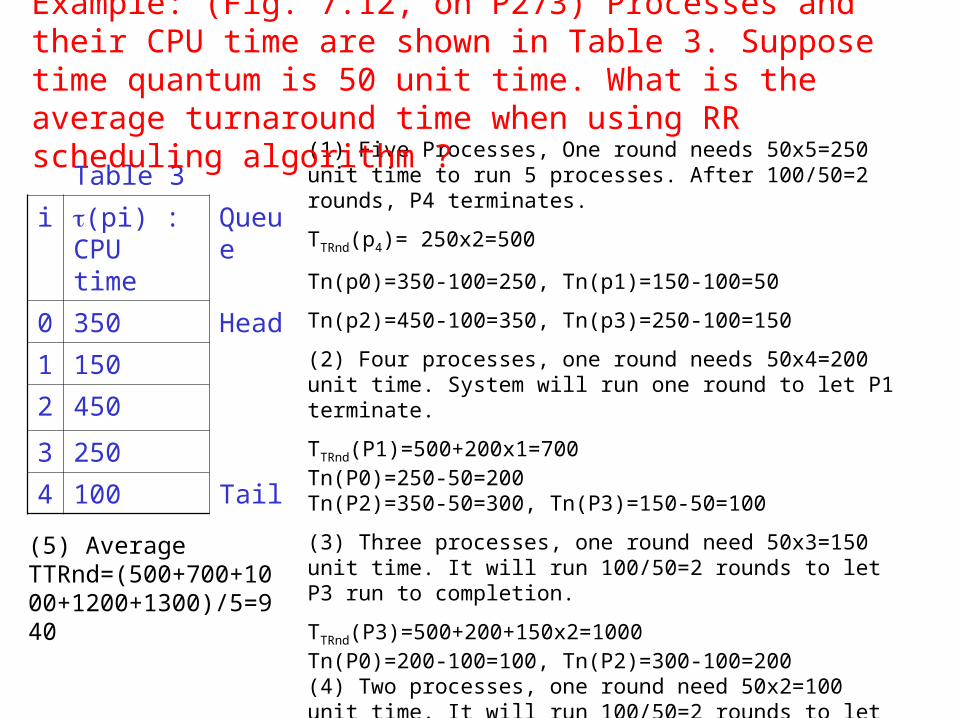
Table 3
i (pi) : CPU time
Queue
0 350 Head
1 150
2 450
3 250
4 100 Tail
(1) Five Processes, One round needs 50x5=250 unit time to run 5 processes. After 100/50=2 rounds, P4 terminates.
TTRnd(p4)= 250x2=500
Tn(p0)=350-100=250, Tn(p1)=150-100=50
Tn(p2)=450-100=350, Tn(p3)=250-100=150
(2) Four processes, one round needs 50x4=200 unit time. System will run one round to let P1 terminate.
TTRnd(P1)=500+200x1=700Tn(P0)=250-50=200 Tn(P2)=350-50=300, Tn(P3)=150-50=100
(3) Three processes, one round need 50x3=150 unit time. It will run 100/50=2 rounds to let P3 run to completion.
TTRnd(P3)=500+200+150x2=1000Tn(P0)=200-100=100, Tn(P2)=300-100=200(4) Two processes, one round need 50x2=100 unit time. It will run 100/50=2 rounds to let P0 run to completion.
TTRnd(P0)=500+200+300+100x2=1200
(5) TTRnd(P2)=500+200+300+200+50x2=1300
Example: (Fig. 7.12, on P273) Processes and their CPU time are shown in Table 3. Suppose time quantum is 50 unit time. What is the average turnaround time when using RR scheduling algorithm ?
(5) Average TTRnd=(500+700+1000+1200+1300)/5=940

Thread Scheduling
Possible scheduling of user-level threads• 50-msec process quantum• threads run 5 msec/CPU burst
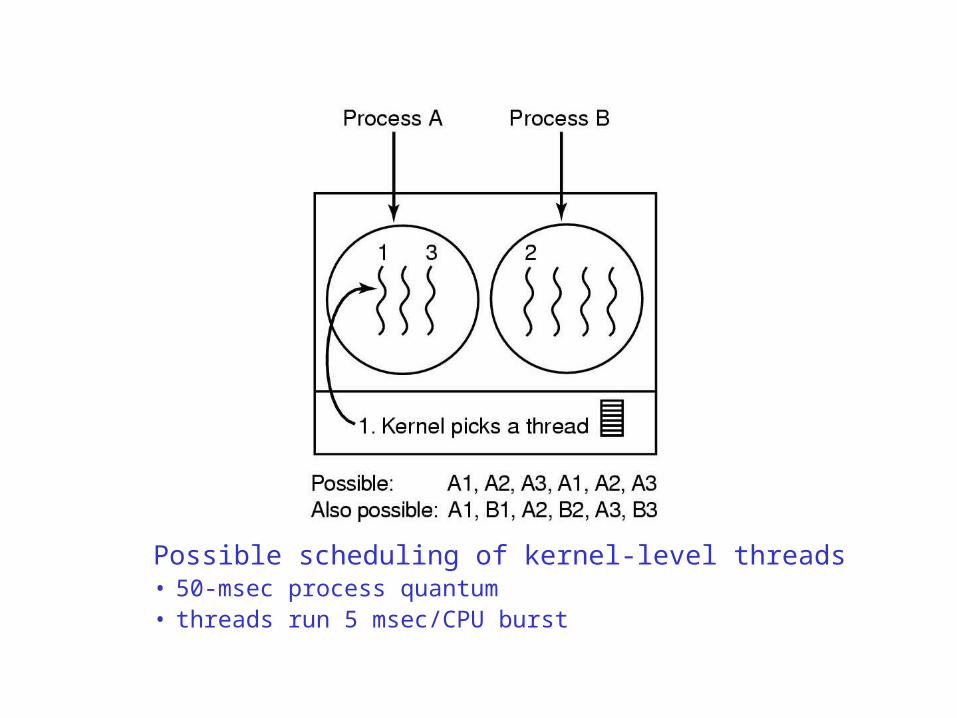
Possible scheduling of kernel-level threads• 50-msec process quantum• threads run 5 msec/CPU burst