on thursday, john will provide information about the project next homework: john will announce in...
TRANSCRIPT

• On Thursday, John will provide information about the project
• Next homework: John will announce in class on Thursday, and it’ll be due the following Thursday.
• Please hand in this week’s homework before you leave.
Announcements

Hypothesis Testing: 20,000 Foot View
1. Set up the hypothesis to test and collect data
Hypothesis to test: HO

Hypothesis Testing: 20,000 Foot View
1. Set up the hypothesis to testand collect data
2. Assuming that the hypothesis is true, are the observed data likely?
Data are deemed “unlikely” if the test statistics is in theextreme of its distribution when HO is true.
Hypothesis to test: HO

Hypothesis Testing: 20,000 Foot View
1. Set up the hypothesis to testand collect data
2. Assuming that the hypothesis is true, are the observed data likely?
3. If not, then the alternative to the hypothesis must be true.
Data are deemed “unlikely” if the test statistics is in theextreme of its distribution when HO is true.
Alternative to HO is HA
Hypothesis to test: HO

Hypothesis Testing: 20,000 Foot View
1. Set up the hypothesis to testand collect data
2. Assuming that the hypothesis is true, are the observed data likely?
3. If not, then the alternative to the hypothesis must be true.
4. P-value describes how likely the observed data are assuming HO is true. (i.e. answer to Q#2 above)
Data are deemed “unlikely” if the test statistics is in theextreme of its distribution when HO is true.
“Unlikely” if p-value < (smaller p-value = less likely)
Alternative to HO is HA
Hypothesis to test: HO

Large Sample Test for a Proportion:Taste Test Data
• 33 people drink two unlabeled cups of cola (1 is coke and 1 is pepsi)
• p = proportion who correctly identify drink
= 20/33 = 61%
• Question: is this statistically significantly different from 50% (random guessing) at = 10%?

Large Sample Test for a Proportion:Taste Test Data
• HO: p = 0.5HA: p does not equal 0.5
• Test statistic:z = | (p - .5)/sqrt( p(1-p)/n) |
= | (.61-.5)/sqrt(.61*.39/33) | = 1.25
• Reject if z > z0.10/2 = 1.645
• It’s not, so there’s not enough evidence to reject HO.

Large Sample Test for a Proportion:Taste Test Data
P-valuePr( |(P-p)/sqrt(P Q/n)| >
|(p-p)/sqrt(p q/n)| when H0 is true)=Pr( |(P-0.5)/sqrt(P Q/n) | > |1.25 | when H0 is true)=2*Pr( Z > 1.25) where Z~N(0,1)= 21%
i.e. “How likely is a test statistic of 1.25 when true p = 50%?”

The test
• The test statistic is:
z = | (p - .5)/sqrt( .5(1-.5)/n) |= | (.61-.5)/sqrt(.25/33) | = 1.22
Note that since .25 >= p(1-p) for any p, this is more conservative (larger denominator = smaller test statistic). Either way is fine.

Difference between two means
• PCB Data– Sample 1: Treatment is to expose cells to a certain
PCB (number 156)– Sample 2: Treatment is to expose the cells to PCB
156 and another chemical compound (estradiol)
• Response = estrogen produced by cells• Question: Can we conclude that average
estrogen produced in sample 1 is different from average by sample 2 (at = 0.05)?

• H0: 1 – 2 = 0HA: 1 – 2 does not = 0
• Test statistic:|(Estimate – value under H0)/Std Dev(Estimate)|
z = (x1 – x2)/sqrt(s12/n1 + s2
2/n2)
Reject if |z| > z/2
• P-value = 2*Pr[ Z > (x1 – x2)/sqrt(s1
2/n1 + s22/n2)] where
Z~N(0,1).
Form of the test

n x s
PCB156 96 1.93 1.00
PCB156+E 64 2.16 1.01
|z| = |-0.229/sqrt(1.002/96 + 1.012/64)| = |-1.41| = 1.41
z/2 = z0.05/2 = z0.025 = 1.96
So don’t reject.
P-value = 2*Pr(Z > 1.41) = 16%
Pr( Test statistic > 1.41 when HO is true)
Data

• Test statistic: |z| = |(Estimate – assumed value under H0)/(Std Dev of the Estimator)| (note that Std Dev of the estimator is the Standard Dev of the individual data points that go into the estimators divided by the square root of n)
• Reject if |z| > z/2
• P-value = 2*Pr( Z > z ) where Z~N(0,1).In the previous example, what was the estimator? What was its
standard error? Note the similarity to a confidence interval for the difference between two means.
In General, Large Sample 2 sided Tests:

Large Sample Hypothesis Tests: summary for means
Single meanHypotheses Test (level 0.05)
HO: = k Reject HO if |(x-k)/s/sqrt(n)|>1.96
HA: does not = k p-value: 2*Pr(Z>|(x-k)/s/sqrt(n)|)where Z~N(0,1)
Difference between two meansHypotheses Test (level 0.05)
HO: = D Let d = x1 – x2
HA: does not = D Let SE = sqrt(s12/n2 + s2
2/n2)Reject HO if |(d-D)/SE|>1.96
p-value: 2*Pr(Z>|(d-D)/SE|)where Z~N(0,1)

Large Sample Hypothesis Tests: summary for proportions
Single proportionHypotheses Test (level 0.05)
HO: true p = k Reject HO if |(p-k)/sqrt(p(1-p)/n)|>1.96
HA: p does not = k p-value: 2*Pr(Z>|(p-k)/sqrt(p(1-p)/n)|)where Z~N(0,1)
Difference between two proportionsHypotheses Test (level 0.05)
HO: p1-p2 = 0 Let d = p1 – p2
HA: p1-p2 does not = 0 Let p = total “success”/(n1+n2)Let SE = sqrt(p(1-p)/n1 + p(1-p)/n2)
Reject HO if |(d)/SE|>1.96p-value: 2*Pr(Z>|(d)/SE|)
where Z~N(0,1)

• A two sided level hypothesis test, H0: =k vs HA: does not equal k
is rejected if and only if k is not in a 1- confidence interval for the mean.
• A one sided level hypothesis test, H0: <=k vs HA: >k
is rejected if and only if a level 1-2 confidence interval is completely to the left of k.
Hypothesis tests versus confidence intervals
The following is discussed in the context of tests / CI’s for a single mean, but it’s true for all the confidence intervals / tests we have done.

• The previous slide said that confidence intervals can be used to do hypothesis tests.
• CI’s are “better” since they contain more information.
• Fact: Hypothesis tests and p-values are very commonly used by scientists who use statistics.
• Advice: 1. Use confidence intervals to do hypothesis testing2. know how to compute / and interpret p-values
Hypothesis tests versus confidence intervals

Project and Exam 2:• Work in groups. (preferably 2 or 3 people)• Collect and analyze data.
– Analysis should include: summary statistics and good graphical displays.
– Also, should include at least one of the following: confidence intervals, hypothesis tests, analysis of variance, regression, contingency tables. In many cases power calculations will be required too (I’ll tell you after reading your proposals).
– Write-up: General description of what you are doing and questions the statistics will address. Statistics and interpretation. (<6 pages)
• One page proposal (who and what) due this Thursday. Project due May 13th.
• Exam 2 is optional. If you want to take it, contact me to schedule a time.

We talked about Type 1 and Type 2 Errors generally before, now we’ll compute some of
the associated probabilities.
Truth
H0 True
HA True
Action
Fail to Reject H0 Reject H0
correct
correct
Type 1error
Type 2error
Significance level = =Pr(Making type 1 error)
Power = 1–Pr(Making type 2 error)

Example: Dietary Folate• Data from the Framingham Heart Study
0 200 400 600 800 1000 1200
0
20
40
60
80
100
Dietary Folate (micrograms / day, calorie adjusted to 2000 calorie diet)
Count
n = 333 Elderly Men
Mean = x = 336.4
Std Dev = s = 193.4
Can we conclude that the mean is greater than 300 at 5% significance? (same as 95% confidence)

In terms of our folate example, suppose we repeated the experiment
and sampled 333 new people
Pr( Type 1 error )= Pr( reject H0 when mean is 300 )= Pr( |Z| > z0.025 )= Pr( Z > 1.96 ) + Pr( Z < -1.96 ) = 0.05 =
When mean is 300, then Z, the test statistic, has a standard normal distribution.
Note that the test is designed to have type 1 error =

Power= Pr( reject H0 when mean is not 300 )= Pr( reject H0 when mean is 310)= Pr( |(X-300)/193.4/sqrt(333)| > 1.96)= Pr( (X-300)/10.6 > 1.96 )+Pr( (X-300)/10.6 < -1.96 )= Pr(X > 320.8) + Pr(X < 279.2)
= Pr( (X – 310)/10.6 > (320.8-310)/10.6 )+ Pr( (X – 310)/10.6 < (279.2-310)/10.6 )
= Pr( Z > 1.02 ) + Pr( Z < -2.90 ) where Z~N(0,1)= 0.15 + 0.00 = 0.15
What’s the power to detect an increase ofof least 10 units of folate for a new experiment? (using a 2 sided test for a single mean)

In other words, if the true mean is 310 and the standard error is 10.6, then there’s an 85% chance that we will not detect it in a new experiment at the 5% level.
If 310 is scientifically significantly different from 300, then this means that our experiment is likely to be wasted.

If all else is held constant, then:
As n increases, power goes up.
As standard deviation of x decreases, power goes up.
As increases, power goes up.
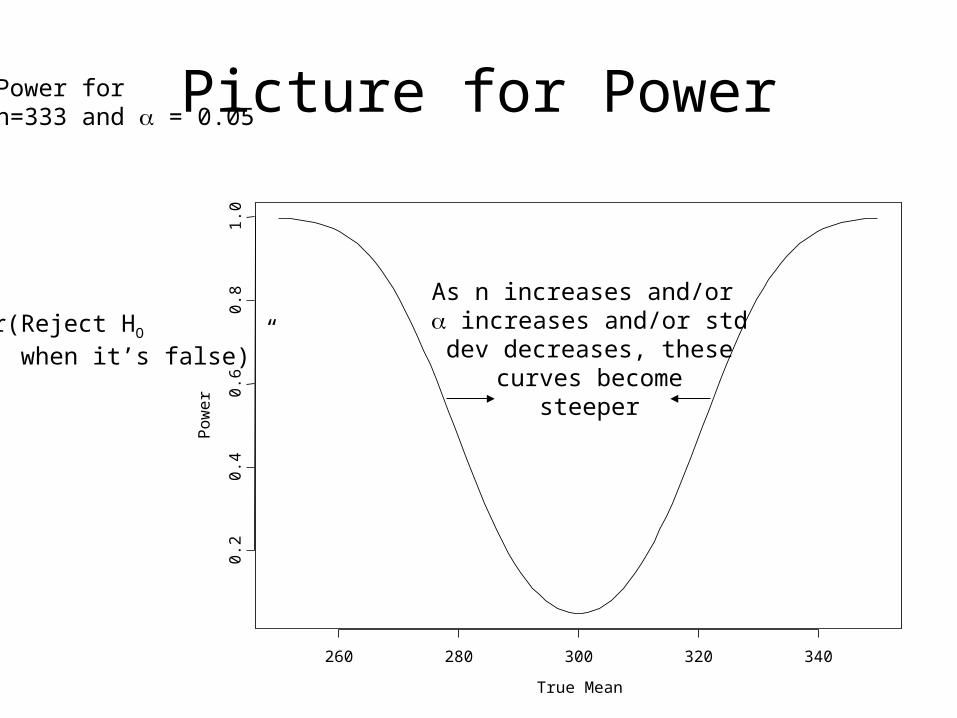
Picture for Power
True Mean
Po
we
r
260 280 300 320 340
0.2
0.4
0.6
0.8
1.0
Power forn=333 and = 0.05
“Pr(Reject HO when it’s false)”
As n increases and/or increases and/or stddev decreases, these
curves becomesteeper

Power calculations are an integral part of planning any experiment:
• Given:– a certain level of – preliminary estimate of std dev (of x’s that go
into x)– difference that is of interest
• Compute required n in order for power to be at least 85% (or some other percentage...)

“Post Hoc Power”
• Note that it is nonsense to do a power calculation after you have collected the data and conclude that you “would’ve seen significant results if you’d had a larger sample size (or lower standard deviation, etc).
• The fallacy is you would get the same x-bar if you collected more data. After the experiment, you only know that x-bar is likely to be in its confidence interval. You do not know where!

Power calculations are an integral part of planning any experiment:
• Bad News: Algebraically messy (but you should know how to do them)
• Good News: Minitab can be used to do them:• Menu: Stat: Power and Sample Size…
– Inputs:1. required power
2. difference of interest
– Output:Result = required sample size
– Options: Change , one sided versus 2 sided tests

Inference from Small SamplesChapter 10
• Data from a manufacturer of child’s pajamas
• Want to develop materials that take longer before they burn.
• Run an experiment to compare four types of fabrics. (They considered other factors too, but we’ll only consider the fabrics. Source: Matt Wand)

4321
18
17
16
15
14
13
12
11
10
9
Fabric
Bur
n T
ime
Fabric Data:Tried to light 4 samples of 4 different (unoccupied!) pajama fabrics on fire.
Higher #meanslessflamable
Mean=16.85std dev=0.94
Mean=10.95std dev=1.237 Mean=10.50
std dev=1.137
Mean=11.00std dev=1.299

Confidence Intervals?
• Suppose we want to make confidence intervals of mean “burn time” for each fabric type.
• Can I use: x +/- z/2s/sqrt(n) for each one?
• Why or why not?

Answer:
tn-1 is the “t distribution” with n-1 degrees of freedom (df)
• Sample size (n=4) is too small to justify central limit theorem based normal approximation.
• More precisely:– If xi is normal, then (x – )/[/sqrt(n)] is normal for any n.
– xi is normal, then (x – )/[s/sqrt(n)] is normal for n > 30.
– New: Suppose xi is approximately normal (and an independent sample). Then (x – )/[s/sqrt(n)] ~ tn-1
Parameter: (number of data points used to estimate s) - 1

“Student” t-distribution(like a normal distribution, but w/ “heavier tails”)
x
dens
ity
-4 -2 0 2 4
0.0
0.1
0.2
0.3
0.4
t dist’t with 3df
Normal dist’n
As df increases, tn-1 becomes the normal dist’n. Indistinguishable for n > 30 or so.
Idea: estimating stddev leads to “morevariability”. Morevariability = higher chance of “extreme”observation

t-based confidence intervals
• 1- level confidence interval for a mean:
x +/- t/2,n-1s/sqrt(n)
where t/2,n-1 is a number such thatPr(T > t/2,n-1) = /2 and T~tn-1
(see table opposite normal table inside of book cover…)

Back to burn time example
x s t0.025,3 95% CI
Fabric 1 16.85 0.940 3.182 (15.35,18.35)
Fabric 2 10.95 1.237 3.182 (8.98, 12.91)
Fabric 3 10.50 1.137 3.182 (8.69, 12.31)
Fabric 4 11.00 1.299 3.182 (8.93, 13.07)

t-based Hypothesis test for a single mean
• Mechanics: replace z/2 cutoff with t/2,n-1ex: fabric 1 burn time dataH0: mean is 15HA: mean isn’t 15Test stat: |(16.85-15)/(0.94/sqrt(4))| = 3.94Reject at =5% since 3.94>t0.025,3=3.182P-value = 2*Pr(T>3.94) where T~t3. This is between 2% and 5% since t0.025,3=3.182 and t0.01,3=4.541. (pvalue=2*0.0146) from software)
• See minitab: basis statistics: 1 sample t test• Idea: t-based tests are harder to pass than large
sample normal based test. Why does that make sense?