old books new science
DESCRIPTION
Old Book, New Science: A Road to Data DiscoveryTRANSCRIPT

A Road to Data Discovery
Old Books, New Science

Technical Goals
•Our data must be open, interoperable, user-friendly, community-friendly, preservation-friendly
•What does that mean?• Open access: “everyone” can read and download the data• Interoperable: data adheres to standards (IIIF, OA, RDF) so other projects can
access and reuse it• Usability: data is accessible by human beings through a user-friendly,
community-friendly platform (that has community traction, is easy to use, is well-documented, and enables and recognizes collaboration)
• Preservation: data is separable from implementation, reduced to lowest common denominator, and deposited with the library via a preservation platform

Open?
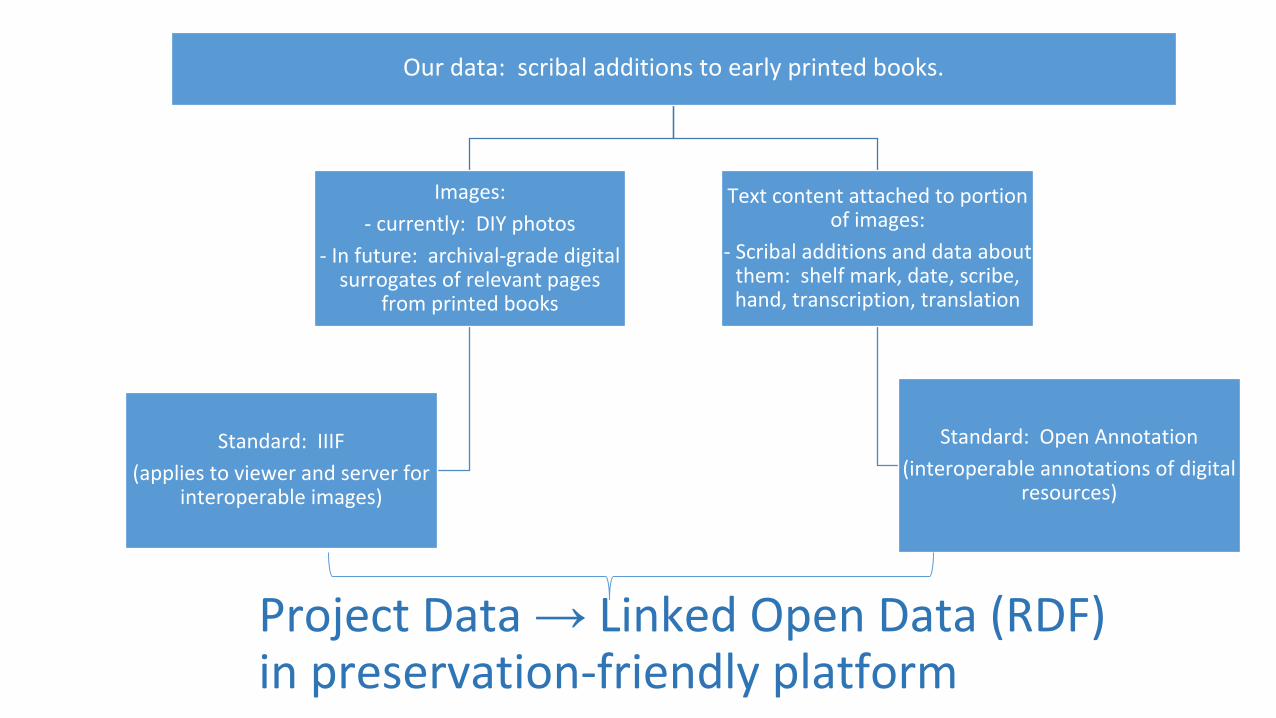
Project Data → Linked Open Data (RDF) in preservation-friendly platform
Our data: scribal additions to early printed books.
Images:
- currently: DIY photos
- In future: archival-grade digital surrogates of relevant pages
from printed books
Standard: IIIF
(applies to viewer and server for interoperable images)
Text content attached to portion of images:
- Scribal additions and data about them: shelf mark, date, scribe, hand, transcription, translation
Standard: Open Annotation
(interoperable annotations of digital resources)

IIIF• Framework/standard for serving or viewing images and portions of images
reliably, uniformly, across multiple repositories, by indicating the image’s region, size, etc. via the image URL
• Scholars working with manuscript images would be able to work across multiple image repositories (e.g. British Library, Bodleian, e-codices, Princeton University Library, Stanford University) and pull images into the viewer/annotator software of their choice… without the indignity of screen shots
• As a result, they would be able to use the platform of their choice, and also robustly share the results of their work on these images (by referencing digital images on their original repositories under multiple aspects, reliably, in a standard way)

IIIF ExampleIf the URL indicates a region /125, 15, 120, 140/, then what you get at the end of that URL is a region of the original image starting 125 pixels right, 15 down, 120 wide, and 140 high.
Image IIIF Image API 2.0
(http://iiif.io/api/image/2.0/#image-request-uri-syntax)

Who uses IIIF?• ARTstor
• Bayerische Staatsbibliothek (Bavarian State Library)
• Biblissima
• Bodleian Libraries, Oxford University
• British Library
• e-codices – Virtual Manuscript Library of Switzerland
• Cornell University
• DPLA
• Europeana
• Harvard University
• Johns Hopkins University
• La Bibliothèque nationale de France
• National Library of Austria
• Nasjonalbiblioteket (National Library of Norway)
• National Library of Denmark
• National Library of Israel
• National Library of New Zealand
• National Library of Poland
• National Library of Serbia
• National Library of Wales
• Princeton University Library
• St. Louis University
• Stanford University
• Wellcome Trust
• Yale University

Open Annotation
•Open Annotation: a common, RDF-based, specification for annotating digital resources
•This specification will facilitate interoperability for annotations: the sharing of annotations for digital objects across clients, servers, and applications
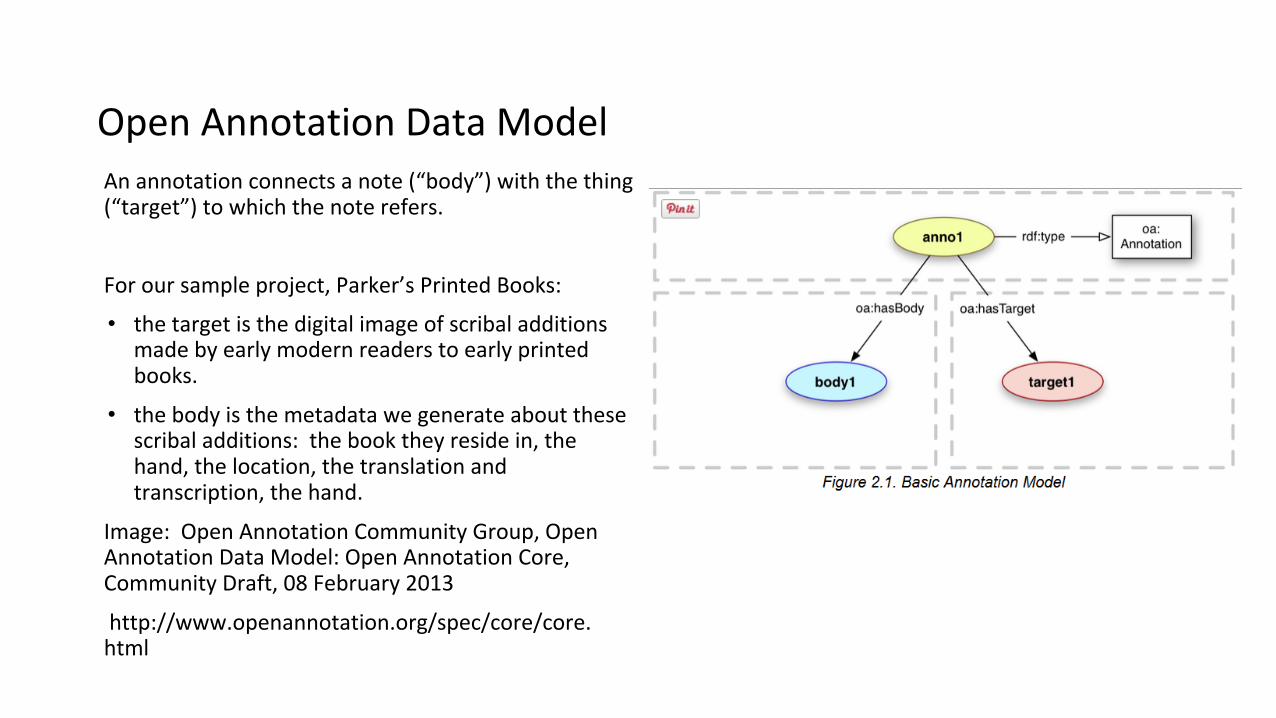
Open Annotation Data ModelAn annotation connects a note (“body”) with the thing (“target”) to which the note refers.
For our sample project, Parker’s Printed Books:
• the target is the digital image of scribal additions made by early modern readers to early printed books.
• the body is the metadata we generate about these scribal additions: the book they reside in, the hand, the location, the translation and transcription, the hand.
Image: Open Annotation Community Group, Open Annotation Data Model: Open Annotation Core, Community Draft, 08 February 2013
http://www.openannotation.org/spec/core/core.html

ExampleAnnotation that annotates a web pages (right) with a video (left). The web page is the target; the video is the body.
Source: Open Annotation Core Data Model Example List, http://www.w3.org/community/openannotation/wiki/Sopa_Target_Resource

Linked Open Data and RDF: De-Siloing Digital ResourcesTraditional (relational) databases represent data as sets of records with standard properties (e.g. books have author, title, date of publication, etc). Relationships between records and things are implicit, to be deduced by humans from the database schema.
Linked data puts the relationships in the foreground, enabling computer-readable meaning-bearing links to be made from one resource to another.
Instead of isolated, unique metadata schemas (databases) or even standard metadata schemas describing “enclosed-garden” or “siloed” resources (e.g. library catalogues that all have MARC records, with the same fields, but that do not “talk to one another”), linked open data forms a giant database with a unified “lingua franca”, RDF, standardizing across domains the metadata vocabulary used to describe things.

Linked Data and RDF
Relational databases: imagine these as a table, or collection of tables, where the records are table rows and the metadata is column headings
Problem: to reuse someone else’s data within my project, I have to (a) get a copy of their data (provided that is possible); (b) understand and translate their metadata schema to mine (provided it is documented). Both of these require extensive human intervention.
Title Author
Ulysses James Joyce

Linked Data and RDFImagine linked data as statements about relationships between people, texts, things, and concepts, of the form:
Subject Predicate Object
(Or: Title hasCreator “Author Name”)
• Things (authors, titles, digitized manuscripts, annotations) have unique URIs
• Relationships are expressed according to standard metadata schemas
• Things and relationships live in the same space, the web
• As a result, linked data becomes a web-wide searchable database
Image by Trevor Thornton, NYPL, “Linked Open Data Fundamentals for Libraries, Archives, Museums”

Benefits of Linked Open Data
•Discovery: Other researchers and projects can discover the data
•Reuse: Other researchers can reuse the data, linking to it, enriching it with their data, and using it for different research questions
•Repurposing: Other researchers can aggregate this data and theirs for querying purposes
•Growth & Interoperability: this data becomes part of a growing “forest” or ecosystem of linked open data that provides an ever richer context for this data
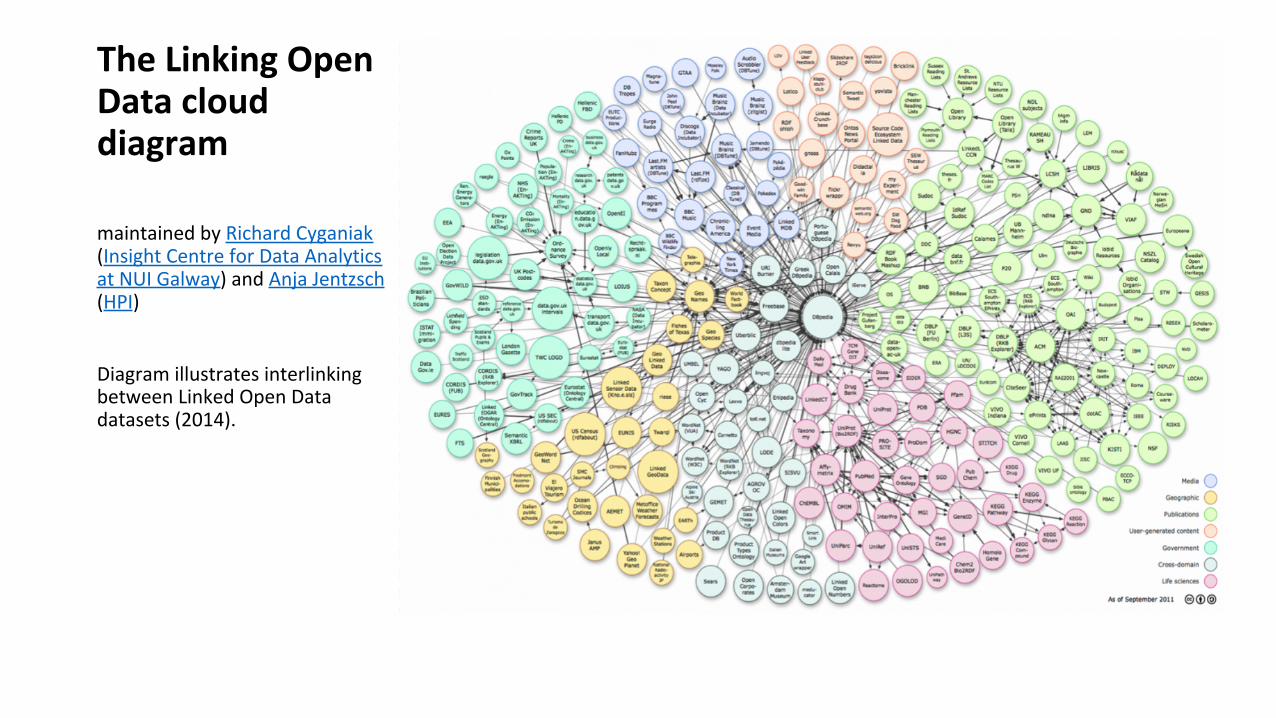
The Linking Open Data cloud diagram
maintained by Richard Cyganiak (Insight Centre for Data Analytics at NUI Galway) and Anja Jentzsch (HPI)
Diagram illustrates interlinking between Linked Open Data datasets (2014).

Old Books, New Science: Goals
• Interoperable data
•Usable platforms
• Standards-based data
• Standards-based data creation and publication platforms: IIIF viewing & serving

Goals
We want to produce IIIF-compliant images and a triplestore of OAC-compliant annotations within a library-based content management and preservation system, e.g. Islandora.
However:
- IIIF: Islandora does not yet have a shim to IIIF-compliant image viewers and image server
-OAC: robust OAC-compliant image annotation tools are still under development (Hypothes.is’s Annotator 2.0 is forthcoming; MIT’s AnnotationStudio produces OAC-compliant annotations, but not of images)

Stage 1a: Data under Construction
•We explore printed books and their annotations via DIY digital images.
•We house our data in a preservation-friendly, lowest-common-denominator structured data format (.csv)
•We zealously separate data from platform.

Stage 1b: Prototyping
•We describe our data via a simple data model: Books and Scribal Additions.
•We use two rapid prototyping solutions to expose the data: • a library-based Omeka site • a static webpage that uses open-source tools (Jekyll) to present .csv data as .
html.
•We use the prototypes to enable collaboration, explore affordances, and study usability

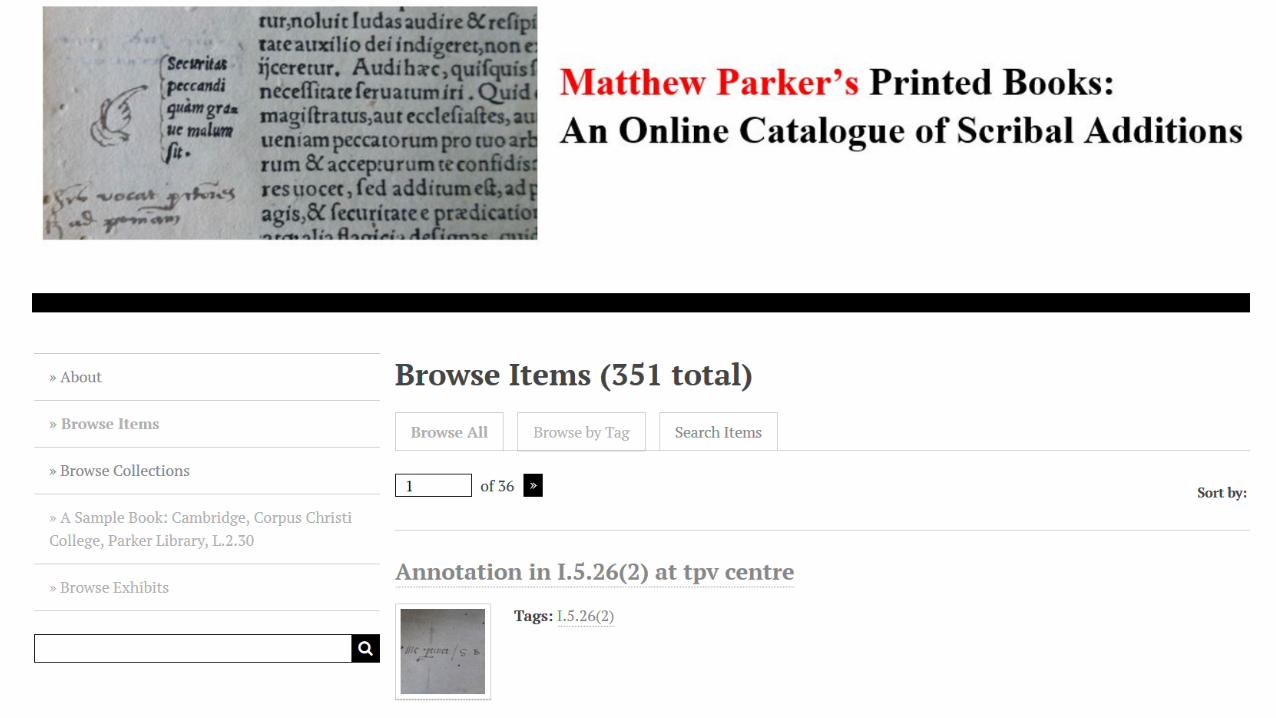
Omeka
•Omeka = “Wordpress for museums”: a free, open-source content management system for digital collections, created by the Roy Rosenzweig Centre for History and New Media, at George Mason University• Allows users to curate collections of digital
items (manuscript facsimiles, photographs, texts, videos, sound recordings, etc.)• Allows users to create rigorous metadata
(Dublin Core standard) for each item, ensuring the collection’s discoverability and interoperability with aggregators and library catalogues.

Omeka
• Enables collaboration by managing user roles and recognizing user contributions to digital collections.
• Supported by University of Toronto library
• Wide traction in DH community
• Extensive user community, documentation, and plugins
• Allows import of structured data (via .csv) and, in the next few weeks, export of structured data (as .csv): so we can get our data in and out of this platform
• Missing: IIIF compliance, OAC compliance, heavy-duty data preservation

Prototype: Static Website (from .csv + Jekyll)
• Jekyll (open-source static site generator): turns structured data (.csv file) into static web page
•Very minimalistic and very efficient: unlike Wordpress or Omeka, it does not come with predefined templates or metadata schemas; instead, it draws its categories from our content directly

Prototype: Static Website (.csv + Jekyll)
•Allows users to publish via git (and thus track changes to the files robustly)
•Allows users to host their material freely on GitHub Pages.
•Allows users to make changes to the .csv file and see these changes instantly reflected in the website – no need to import anything
•Missing: IIIF compliance, OAC compliance, heavy-duty data preservation, user management, library involvement


Stage 3: Migration
•Within UTL’s data repository, we migrate the project data to a digital ecology that • is housed in, and maintained by, the library• complies with discipline-specific standards (IIIF, OAC) • satisfies the functionalities identified via prototyping
• Currently, we envision this digital ecology as follows:• Islandora (Drupal + Fedora) as a content management system and preservation
platform• Omeka (linked to Islandora) as a digital exhibit platform• IIIF-compliant viewer with a shim to Islandora (not available yet)• OAC-compliant annotator with a shim to Islandora: perhaps AnnotationStudio (once
it can annotate images) or Annotator 2.0 (once it is released) (not available yet)
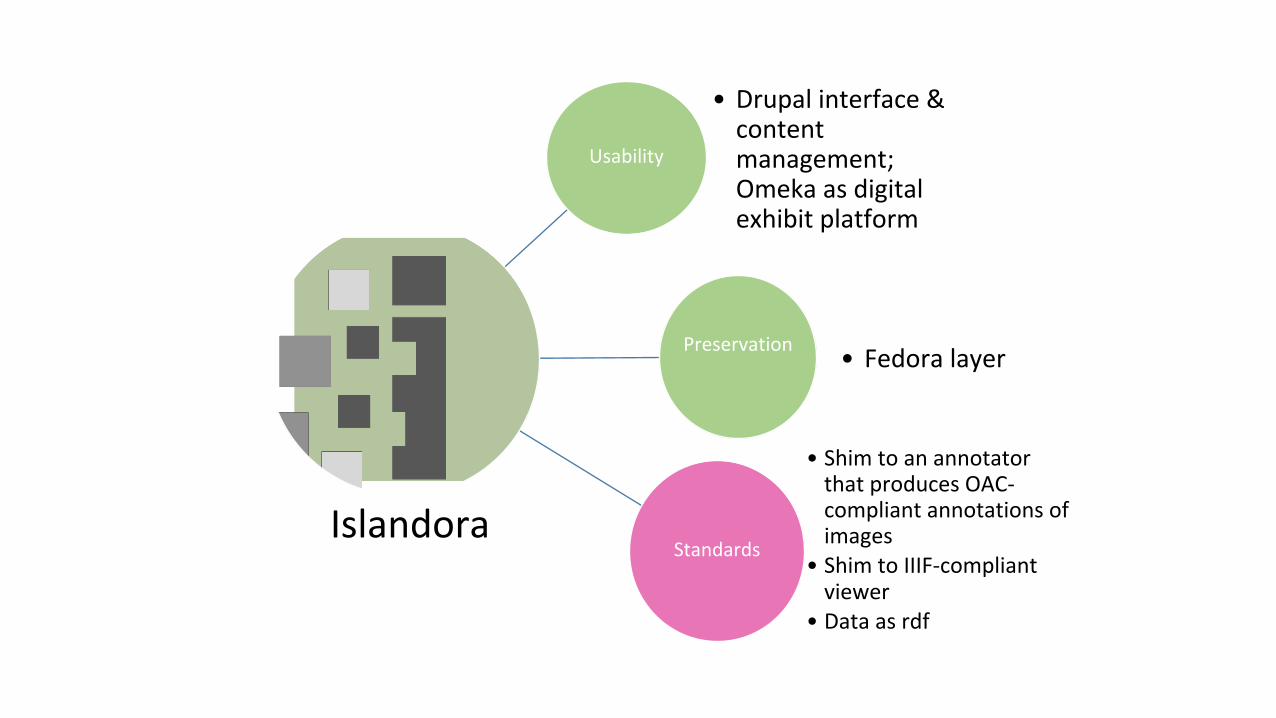
Usability
• Drupal interface & content management; Omeka as digital exhibit platform
Preservation• Fedora layer
Standards
• Shim to an annotator that produces OAC-compliant annotations of images
• Shim to IIIF-compliant viewer
• Data as rdf
Islandora

Questions
• Linked data (the semantic web) has been presented as the solution to the “too much data” problem – a way to make amorphous big data intelligible and open to computational knowledge discovery.
• But within a humanities context, we do not have Big Data for our projects. We have tiny data that we drill down into, in depth and detail and from a multiplicity of perspectives. Can linked data, by opening our projects to interlinking and computational knowledge discovery, enhance our work? Or does it foreclose avenues of investigation? Does linked data, by requiring so much technical overhead (building viewers, annotators, interfaces, etc.), become a barrier rather than a bridge? Does it promise potential computational knowledge discovery at the cost of human control over tiny, human-readable, granular data?
• As we develop our project, we remain aware that projects and technologies live and die by the communities of practice they invite in – or shut out. Like Matthew Parker’s books, our data and platforms must enable and invite the readings, thoughts, and annotations of future readers.