object category detection part ii: deep networksaz/lectures/aims-cv/detection-part2.pdfjifeng dai,...
TRANSCRIPT

Object Category Detection
Part II: Deep Networks
Andrew Zisserman
Visual Geometry Group
University of Oxford
http://www.robots.ox.ac.uk/~vgg
AIMS-CDT Computer Vision
Hilary 2020

Part II Outline
1.Object category detection using CNNs
• Two-stage methods: Faster R-CNN
• One-stage methods: SSD
• Evaluation: PASCAL, COCO
2.State of the art methods – recent improvements
• Modules: Deformable Convolutional Networks, Feature Pyramid Networks
• Architectures: TridentNet, CornerNet, Mask R-CNN, ….

Object Category Dection using CNNs

AlexNet (Krizhevsky et al. 2012)
60 Million parameters
image
classification
code
Reminder: Classification CNNs
convolutional layers fully connected
layers

1000 categories
• Training: 1000 images
for each category
• Testing: 100k images
ImageNet Image Classification Challenge
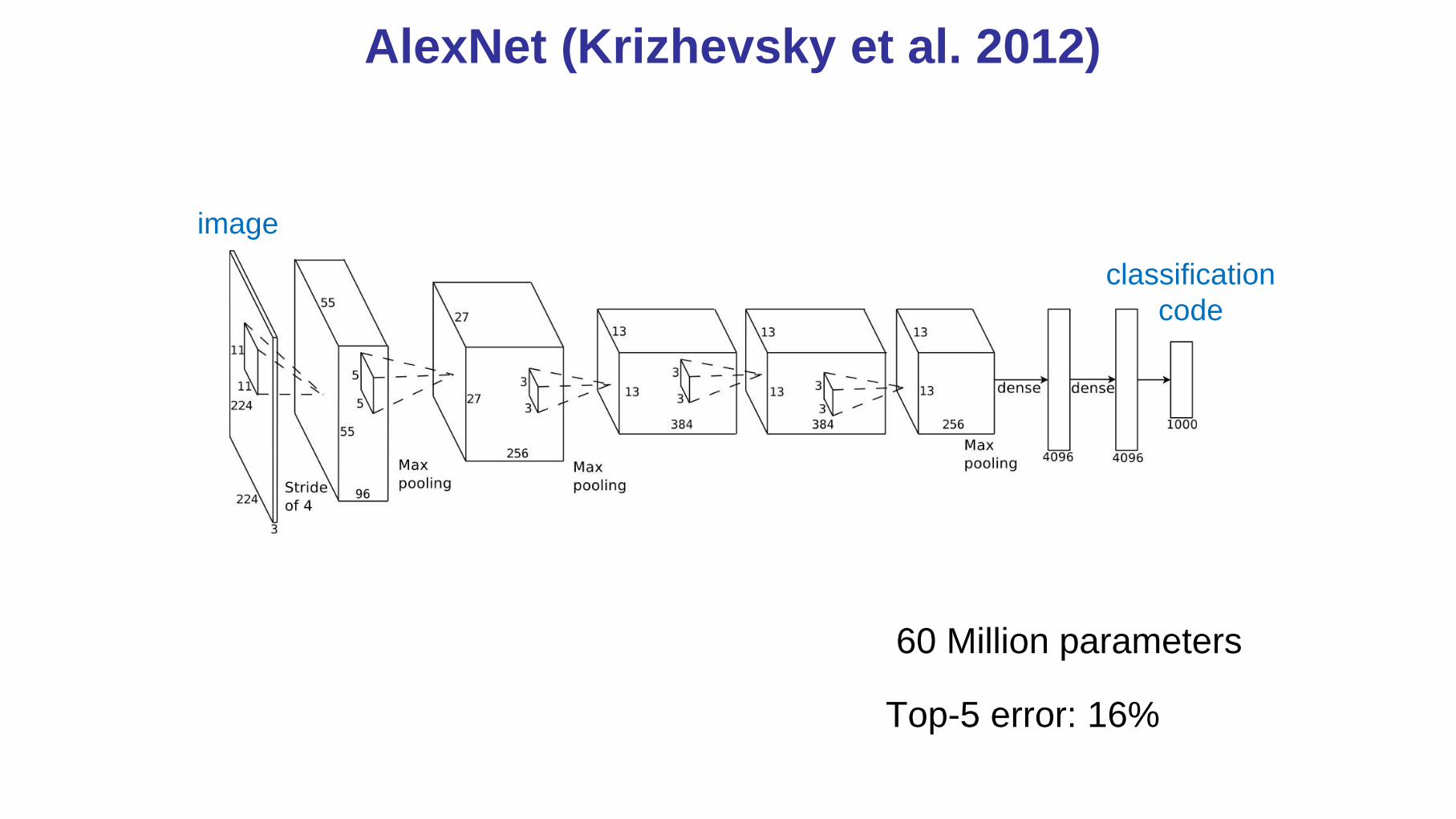
AlexNet (Krizhevsky et al. 2012)
60 Million parameters
Top-5 error: 16%
image
classification
code
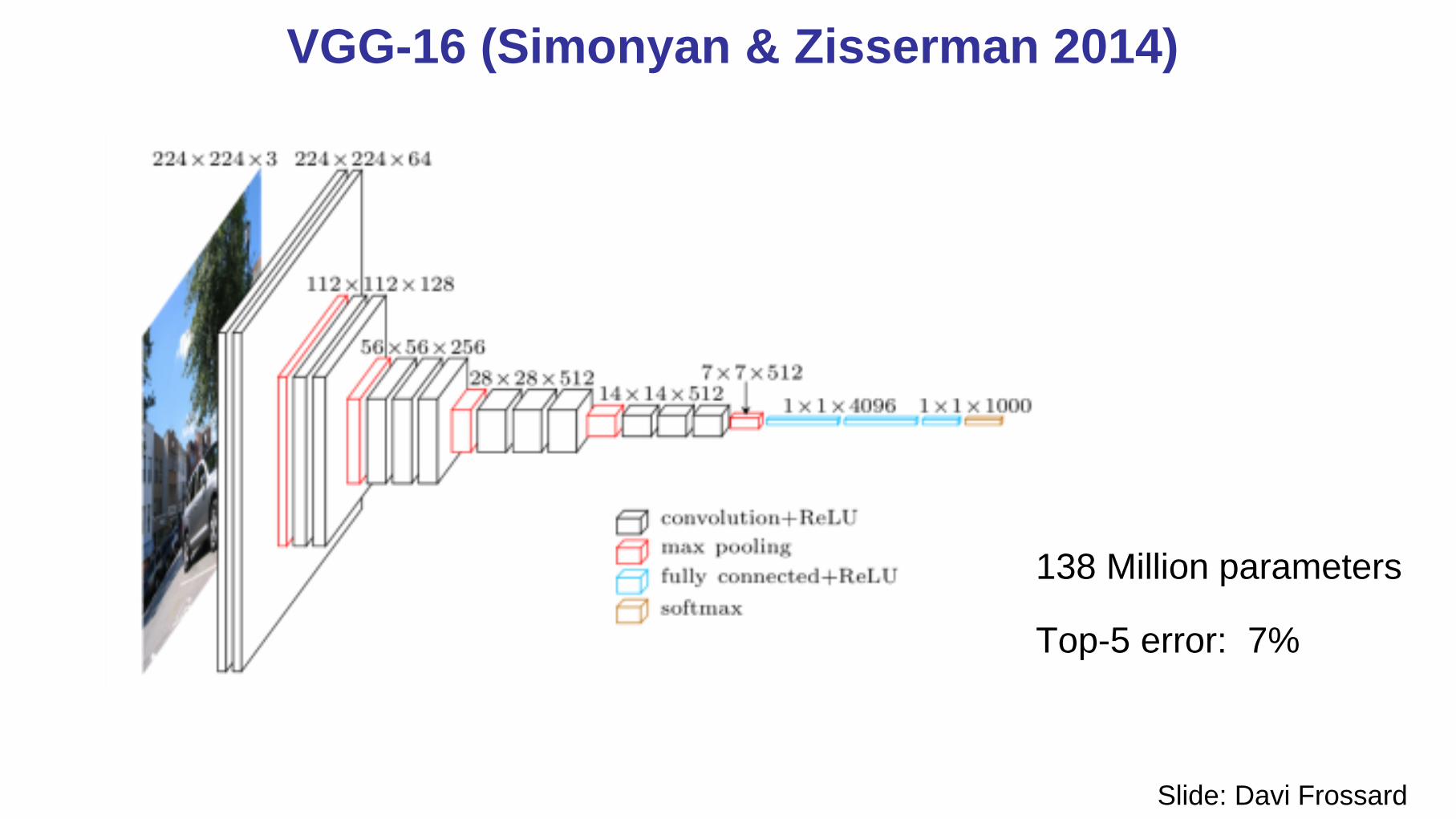
VGG-16 (Simonyan & Zisserman 2014)
Slide: Davi Frossard
138 Million parameters
Top-5 error: 7%

ResNet (He et al. 2015)
152 layers
Top-5 error: 4%
He et al, Deep Residual Learning for Image Recognition, CVPR 2016

Squeeze & Excitation (Hu et al. 2017)
S & E ResNext-152
Top-5 error: 2.3%
Squeeze-and-Excitation Networks, Hu, Shen & Sun, ArXiv 2017
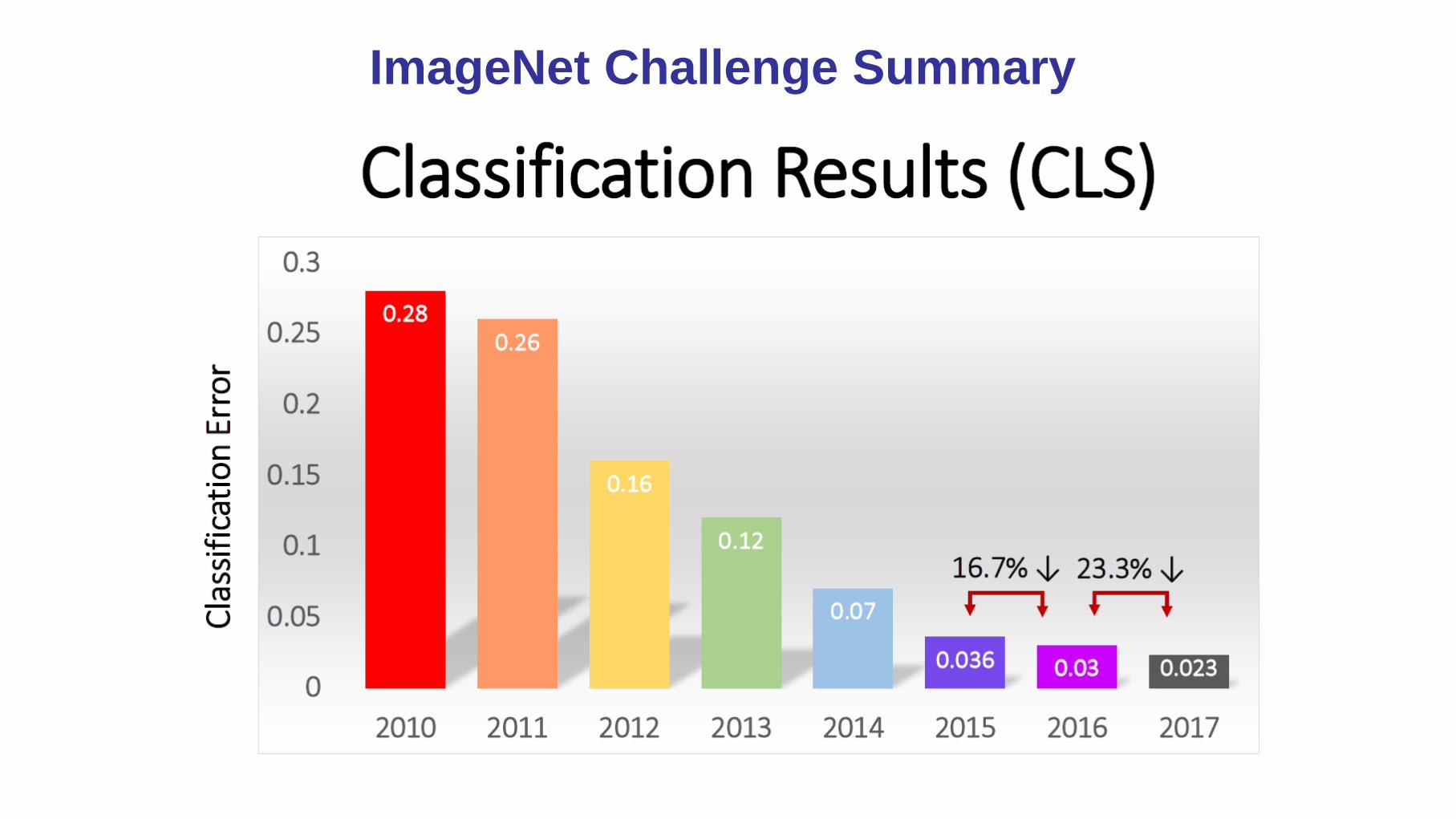
ImageNet Challenge Summary

CNNs for detection – intuition I
Modern classification architectures, such as ResNet or Inception, use convolutional
layers throughout
– no fully connected layers in the final layers
– reduces the number of parameters
– obtain feature vector by spatial pooling

CNNs for detection – intuition II
• Is object localization for free?-weakly-supervised learning with convolutional neural networks, M Oquab, L Bottou, I Laptev,
J Sivic, CVPR 2015
• Learning deep features for discriminative localization, B Zhou, A Khosla, A Lapedriza, A Oliva, A Torralba, CVPR 2016

CNNs for detection – intuition III

Object Detection Networks
Reminder: classical object detectors use two stages:
1. Propose class agnostic regions in the image
2. Classify regions into object classes or background
• How to capture this in a deep network?

Faster R-CNN
image
CNN
feature map
proposals
Two stages:
1. The region proposal network (RPN)
2. Classifying/regressing the regions
Base network: VGG16
RoI pooling
ROI classifier and regressor
Ren, He, Girshick, & Sun. “Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks”. NIPS 2015.

Region Proposal Network
• Slide a small window on the feature map
• Position of the sliding window provides localizationinformation with reference to the image
• Box regression provides finer localization information with reference to this sliding window
convolutional feature map
sliding window
classify obj./not-obj.
regress box locations
Ren, He, Girshick, & Sun. “Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks”. NIPS 2015.

“Anchors": pre-defined candidate regions
• Multi-scale/size anchors are used at each position:3 scales (1282, 2562, 5122) and 3 aspect ratios (2:1, 1:1, 1:2) yields 9 anchors
256-d
n scores 4n coordinates
9 anchors
• each anchor has its own prediction function
• single-scale features, multi-scale predictions
Ren, He, Girshick, & Sun. “Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks”. NIPS 2015.
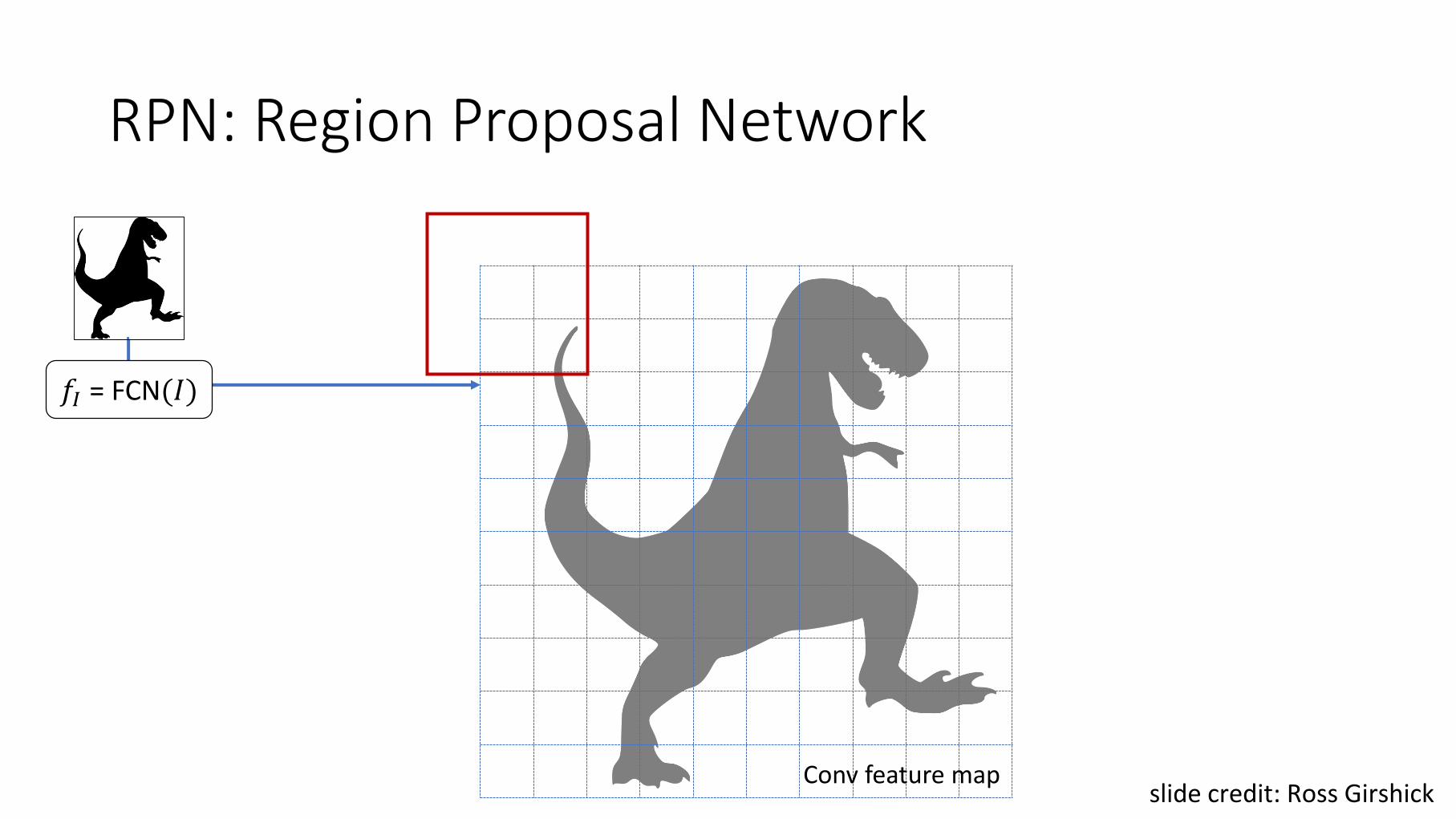
RPN: Region Proposal Network
𝑓𝐼 = FCN(𝐼)
Conv feature mapslide credit: Ross Girshick

RPN: Region Proposal Network
3x3 “sliding window”Scans the feature maplooking for objects
𝑓𝐼 = FCN(𝐼)
Conv feature mapslide credit: Ross Girshick

RPN: Anchor BoxAnchor box: predictions are w.r.t. this box, not the 3x3sliding window
3x3 “sliding window”Scans the feature maplooking for objects
Conv feature map
𝑓𝐼 = FCN(𝐼)
slide credit: Ross Girshick

RPN: Anchor Box
3x3 “sliding window” Objectness classifier [0, 1]
Box regressorpredicting (dx, dy, dh, dw)
Conv feature map
𝑓𝐼 = FCN(𝐼)
Anchor box: predictions are w.r.t. this box, not the 3x3sliding window
slide credit: Ross Girshick

RPN: Prediction (on object)
3x3 “sliding window” Objectness classifier [0, 1]
Box regressorpredicting (dx, dy, dh, dw)
P(object) = 0.94Objectness score
slide credit: Ross Girshick

RPN: Prediction (on object)Anchor box: transformed bybox regressor
3x3 “sliding window” Objectness classifier [0, 1]
Box regressorpredicting (dx, dy, dh, dw)
P(object) = 0.94
slide credit: Ross Girshick
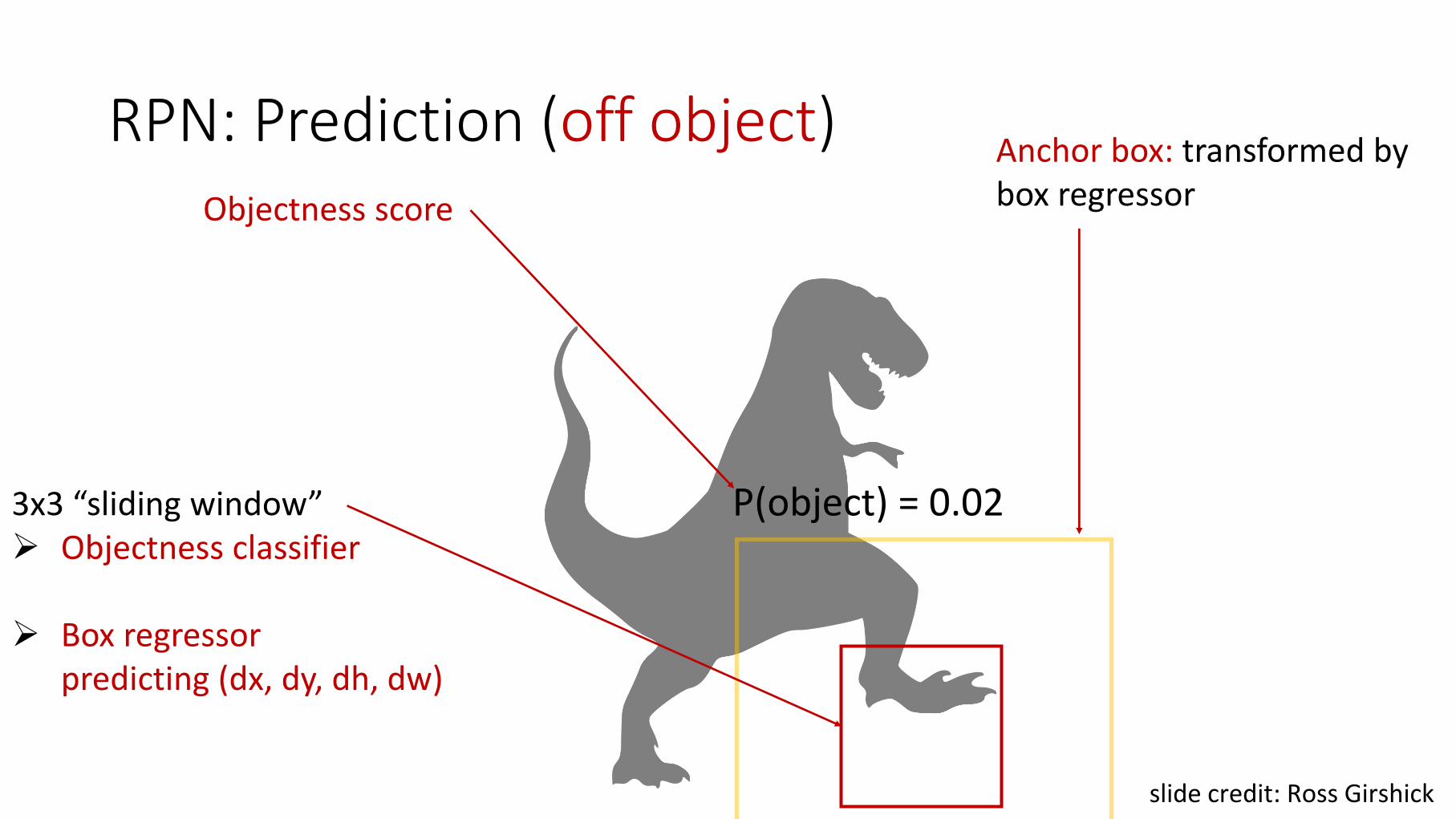
RPN: Prediction (off object)Anchor box: transformed bybox regressor
3x3 “sliding window” Objectness classifier
Box regressorpredicting (dx, dy, dh, dw)
P(object) = 0.02
Objectness score
slide credit: Ross Girshick

RPN: Multiple Anchors
3x3 “sliding window” K objectness classifiers
K box regressors
Conv feature map
𝑓𝐼 = FCN(𝐼)
Anchor boxes: K anchorsper location with differentscales and aspect ratios
slide credit: Ross Girshick

Based on overlap with ground truth bounding box – class agnostic
Positive and negative training regions
a positive training region
overlap > 70%
a negative training region
overlap < 30%
Ren, He, Girshick, & Sun. “Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks”. NIPS 2015.
the ground-truth region
Pre-train VGG16 CNN on ImageNet

Figure from: "Contextual Priming and Feedback for Faster R-CNN", Shrivastava & Gupta, ECCV 16
Faster R-CNN
Stage 1 Stage 2

Stage 2: The Spatial Pooling (SP) layer
• The spatial pooling layer (SP) max-pools the convolutional feature responses in a given region
• This can be used to extract many region-specific feature vectors by reusing the same convolutional
features.
He, Zhang,Ren & Sun, “Spatial Pyramid Pooling (SPP) in Deep Convolutional Networks for Visual Recognition”, ECCV 2014
any given region
c5c1 c2 c3 c4
feature
vector
maxpooling
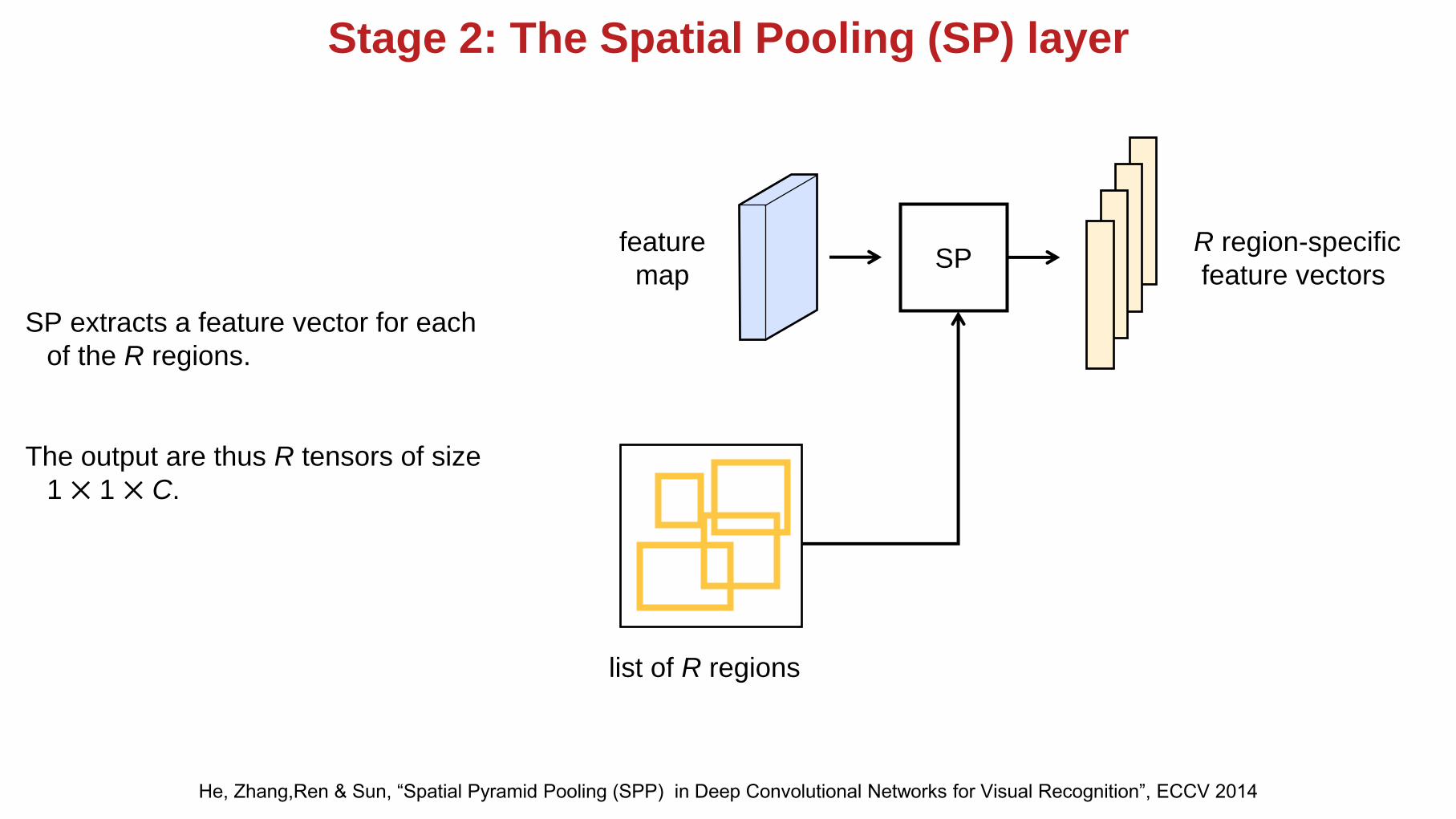
Stage 2: The Spatial Pooling (SP) layer
SP extracts a feature vector for each
of the R regions.
The output are thus R tensors of size
1 ⨉ 1 ⨉ C.
SPfeature
map
list of R regions
R region-specific
feature vectors
He, Zhang,Ren & Sun, “Spatial Pyramid Pooling (SPP) in Deep Convolutional Networks for Visual Recognition”, ECCV 2014

SP with multiple subdivisions
Stage2: The Spatial Pyramid Pooling Layer
SPP is similar to SP, but pools features in the tiles of a grid-like subdivision of the region.
The resulting feature vector captures the spatial layout of the original region.
Converts the region to a fixed size vector
max pooling
He, Zhang,Ren & Sun, “Spatial Pyramid Pooling (SPP) in Deep Convolutional Networks for Visual Recognition”, ECCV 2014
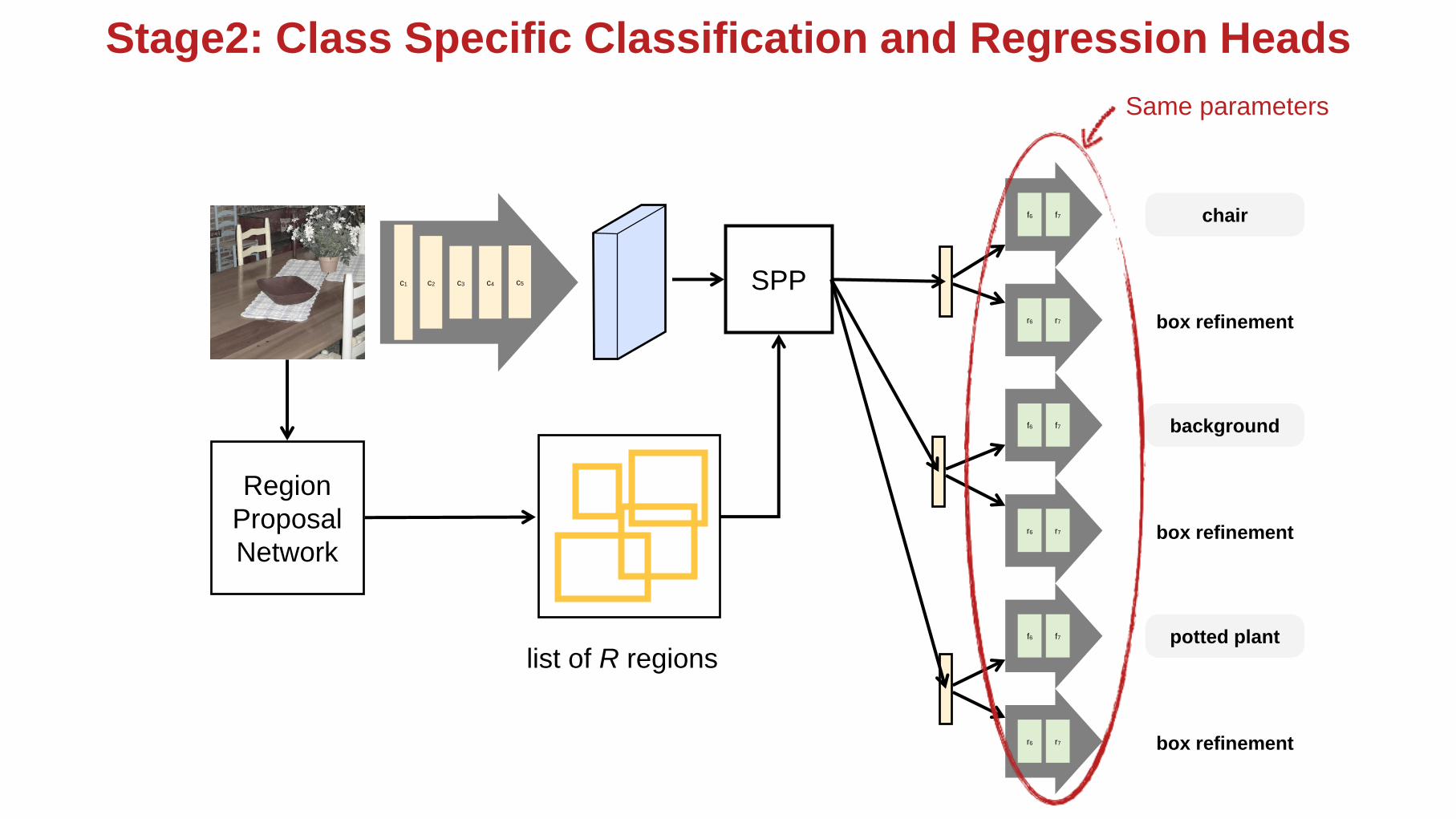
c5c1 c2 c3 c4
f6 f7 chair
Region
Proposal
Network
SPP
r6 r7 box refinement
f6 f7 background
r6 r7 box refinement
f6 f7 potted plant
r6 r7 box refinement
Same parameters
Stage2: Class Specific Classification and Regression Heads
list of R regions
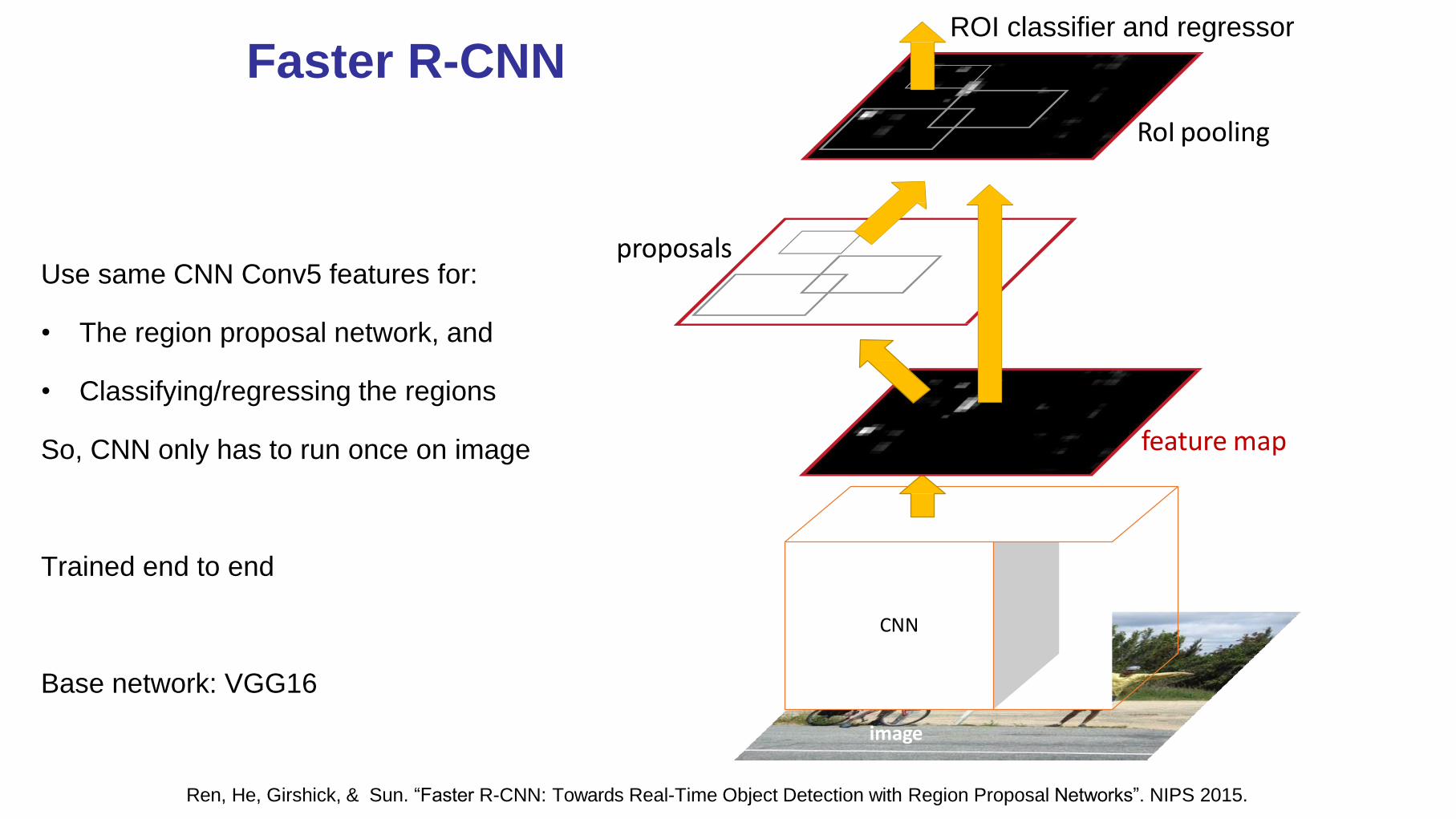
Faster R-CNN
image
CNN
feature map
proposals
RoI pooling
ROI classifier and regressor
Ren, He, Girshick, & Sun. “Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks”. NIPS 2015.
Use same CNN Conv5 features for:
• The region proposal network, and
• Classifying/regressing the regions
So, CNN only has to run once on image
Trained end to end
Base network: VGG16

Example detections
bus:0.980
car :1.000
dog: 0.989
person :0.992
person :0.974
horse: 0.993
boat : 0.853 person :0.993
person :0.981
person :0.972
person :0.907
cat : 0.928
dog: 0.983
person :0.753

Evaluation
The PASCAL Visual Object Classes (VOC) Dataset
and Challenge 2007 – 2012
Mark Everingham, Luc Van Gool, Chris
Williams, John Winn, Andrew Zisserman

Dataset Content
• 20 classes: aeroplane, bicycle, boat, bottle, bus, car, cat, chair, cow, dining table, dog,
horse, motorbike, person, potted plant, sheep, train, TV
• Real images downloaded from flickr, not filtered for “quality”
• Complex scenes, scale, pose, lighting, occlusion, ...

Examples
Aeroplane
Bus
Bicycle Bird Boat Bottle
Car Cat Chair Cow

Examples
Dining Table
Potted Plant
Dog Horse Motorbike Person
Sheep Sofa Train TV/Monitor

Dataset statistics: VOC 2012
• Minimum ~600 training objects per category
• ~2,000 cars, 1,500 dogs, 8,500 people
• Approximately equal distribution across training and test datasets
Training Testing
Images 11,540 10,994
Objects 27,450 27,078

• Area based measure
• For multiple detections of the same ground truth box, only one considered a true positive
• Evaluation: Average precision per class on predictions
Evaluation for Detection: Intersection over Union
Detection correct if “intersection over union” > Threshold = 50%
Ground truth Bgt
Predicted Bp
Bgt Bp
Intersection over union = Area(GT ∩ Pred) / Area(GT ∪ Pred)

PASCAL VOC Leaderboard Dec 2015
Detection challenge comp4: train on own data
Mean: 83.8

PASCAL VOC Leaderboard Dec 2017
Detection challenge comp4: train on own data
Mean: 88.6

PASCAL VOC Leaderboard Dec 2019
Detection challenge comp4: train on own data
Mean: 92.9

Application: Faster R-CNN face detector
- VGG16 pre-trained on ImageNet
- Trained on the WIDER face dataset: 12,880 images and 159,424 faces
Credits: Sam Albanie,
Qiong Cao

Example: tracking by detection on Sherlock
- VGG16 pre-trained on ImageNet
- Trained on the WIDER face dataset: 12,880 images and 159,424 faces
Credits: Sam Albanie,
Qiong Cao

Two strands of detection architectures
1. Those that use a Region Proposal Network (RPN)
– Two stages:
(i) RPN, followed by
(ii) features from regions for classification and regression of box
– Possibly slow because of the two steps
– Examples: Faster R-CNN, R-FCN, Mask-RCNN, TridentNet
2. Those that use a unified framework (no explicit RPN)
– Single Stage
– Regions are built into the architecture (convolutional layers)
– Can be fast
– Examples:
• Anchor based, e.g. YOLO, SSD, RetinaNet
• Point based, e.g. CornerNet, CenterNet
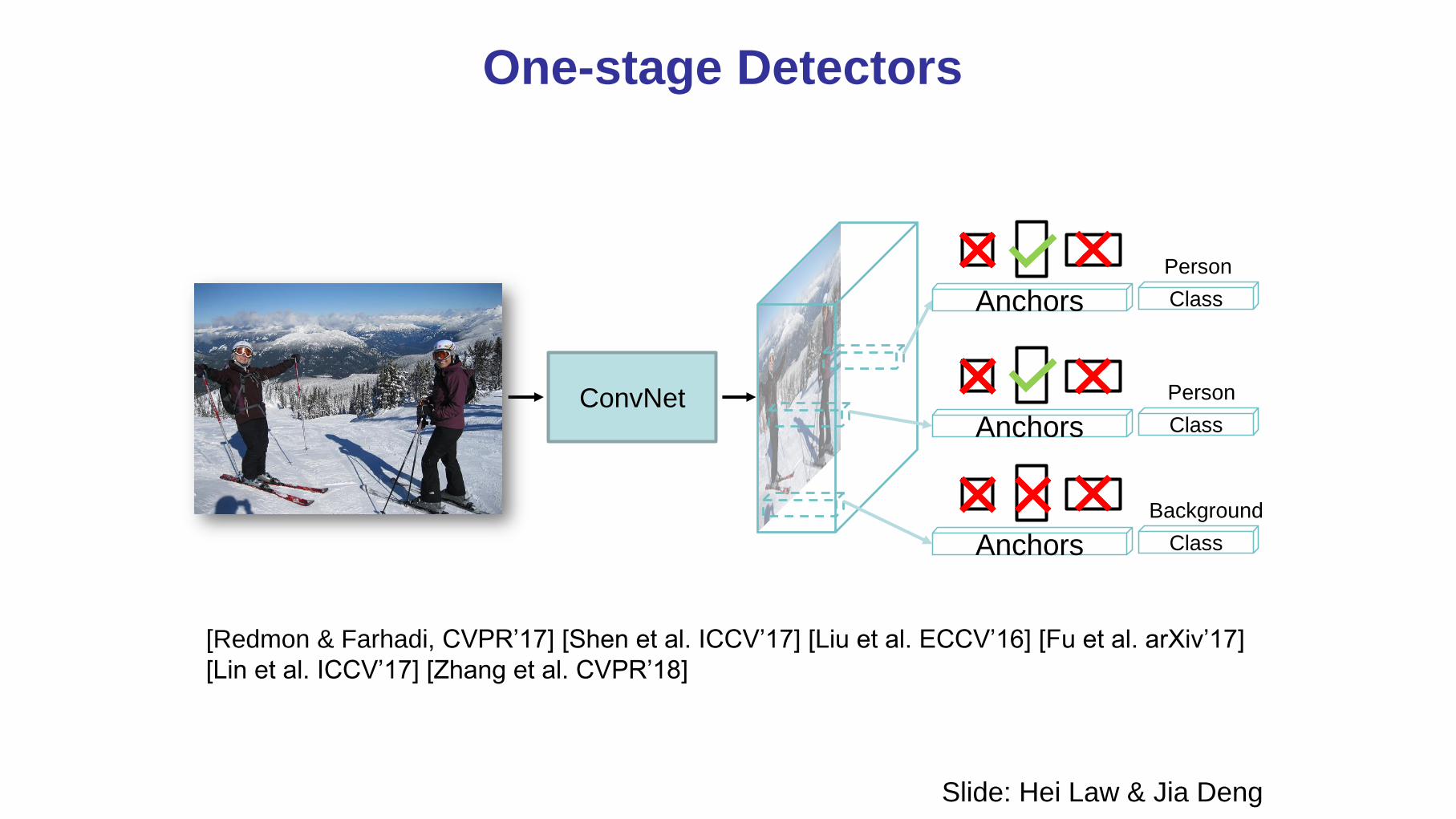
One-stage Detectors
Class
Person
Class
Person
Class
Background
Anchors
Anchors
Anchors
[Redmon & Farhadi, CVPR’17] [Shen et al. ICCV’17] [Liu et al. ECCV’16] [Fu et al. arXiv’17]
[Lin et al. ICCV’17] [Zhang et al. CVPR’18]
ConvNet
Slide: Hei Law & Jia Deng

Single Shot MultiBox Detector (SSD)
• Fully convolutional detection network – no RPN
SSD: Single Shot MultiBox Detector, W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C.-Y. Fu, and A. Berg, ECCV 2016.
SSD runs at 59 fps
cf 7 fps for Faster R-CNN
Pre-defines regions:
• Predicts categories and box offsets
• Multiple aspect ratios per cell.
• Similar to Faster R-CNN Anchor Boxes.


COCO Detection Evaluation Metrics

COCO Detection Evaluation Metrics

Object Detection on COCO test-dev
Visit: https://paperswithcode.com/sota/object-detection-on-coco

Object Detection on COCO test-dev
slide credit: Weidi Xie

Significant improvements
1. Key ideas
1. Deformable convolutional networks (DCNs)
2. Feature Pyramid Networks (FPNs)
3. Focal Loss
2. Architectures
– Two Stage
• Trident network
• Mark R-CNN
– Single Stage
• RetinaNet
• CornerNet
• CenterNet
Many of these ideas can be used to improve other tasks such as segmentation and tracking

Deformable Convolutional Networks
• Addresses limitation of regular grid convolutions
• Plug in module to replace regular convolutions
• Offsets depend on image content
Deformable Convolutional Networks
Jifeng Dai, Haozhi Qi, Yuwen Xiong, Yi Li, Guodong Zhang, Han Hu, Yichen Wei, ICCV, 2017
regular deformed scale & aspect ratio rotation

Deformable Convolutional Networks
• Addresses limitation of regular grid convolutions
• Plug in module to replace regular convolutions
• Offsets depend on image content
Deformable Convolutional Networks
Jifeng Dai, Haozhi Qi, Yuwen Xiong, Yi Li, Guodong Zhang, Han Hu, Yichen Wei, ICCV, 2017
Sampling Locations of Deformable Convolution

Scale in object category detection
• Object detectors have to classify and localize over a wide range of scales
• How to handle multiple scales in a single network?
Peiyun Hu, Deva Ramanan, Finding Tiny Faces, CVPR 2017

Scale in object category detection
Network for each image scale as in HOG
Reuse classifier network at each scale
Too slow
Only compute regions at highest feature map
as in Faster R-CNN
Problems of resolution for small objects

Scale in object category detection
Feature Pyramid Networks (FPNs)
Feature Pyramid Networks for Object Detection, T.-Y. Lin, P. Dollár, R. Girshick, K. He, B. Hariharan, S. Belongie, ICVPR, 2017
Low resolution,
Strong features
High resolution,
Weak features
Use the internal feature pyramids
Weak features for higher resolutionTop down enrichment for higher resolution features

Low resolution,
Strong features
High resolution,
Strong features
FPN pyramid
Scale in object category detection
Feature Pyramid Networks (FPNs)
Light weight top-down refinement (fast)
Feature Pyramid Networks for Object Detection, T.-Y. Lin, P. Dollár, R. Girshick, K. He, B. Hariharan, S. Belongie, ICVPR, 2017

Scale in object category detection
Two stage: Trident Network
Scale-Aware Trident Networks for Object Detection, Yanghao Li, Yuntao Chen, Naiyan Wang, Zhaoxiang Zhang ICCV 2019

Focal Loss
• “Soft” hard example mining
• Addresses class imbalance in training (particularly for single stage detectors)
Focal Loss for Dense Object Detection, Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Dollar. ICCV, 2017

Example Single Stage Detector: RetinaNet
• Backbone with FPN + class-specific anchors (final detections)
• Trained with focal loss
Focal Loss for Dense Object Detection, Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Dollar. ICCV, 2017

Example Single Stage Detector: RetinaNet
• Backbone with FPN + class-specific anchors (final detections)
• Trained with focal loss
Focal Loss for Dense Object Detection, Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Dollar. ICCV, 2017

Single Stage Detector: CornerNet
CornerNet: Detecting Objects as Paired Keypoints, Hei Law, Jia Deng, ECCV 2018
• Detecting Objects as Paired Keypoints
• Avoids problem of requiring many anchors in order to overlap with a true detection

Person
Top-LeftCorner?
ConvNet
Class
Whose Top-Left?
Bottom-RightCorner? Class
Whose Bottom-Right?
Yes No
Yes Person
Yes Person
No
No
Yes PersonNo
CornerNet: Detecting Objects as Paired Keypoints, Hei Law, Jia Deng, ECCV 2018
CornerNet: Detecting Objects as Paired Keypoints

Person
Top-LeftCorner? Class
Whose Top-Left?
Bottom-RightCorner? Class
Whose Bottom-Right?
Yes No
Yes Person
Yes Person
No
No
Yes PersonNo
CornerNet: Detecting Objects as Paired Keypoints, Hei Law, Jia Deng, ECCV 2018
CornerNet: Detecting Objects as Paired Keypoints

Advantages of Detecting Corner
Represent 𝑂(𝑤2ℎ2) possible proposals using only 𝑂 𝑤ℎ corners
h
w
𝑂(𝑤ℎ) corners
𝑂(𝑤2ℎ2) possible proposals
CornerNet: Detecting Objects as Paired Keypoints, Hei Law, Jia Deng, ECCV 2018
CornerNet: Detecting Objects as Paired Keypoints

Corner Pooling
CornerNet: Detecting Objects as Paired Keypoints, Hei Law, Jia Deng, ECCV 2018
CornerNet: Detecting Objects as Paired Keypoints

CornerNet: Detecting Objects as Paired Keypoints, Hei Law, Jia Deng, ECCV 2018
CornerNet: Detecting Objects as Paired Keypoints
Top-left corner heatmap Bottom-right corner heatmap

CornerNet: Detecting Objects as Paired Keypoints, Hei Law, Jia Deng, ECCV 2018
CornerNet: Detecting Objects as Paired Keypoints

CenterNet: Keypoint triplets for object detection, Kaiwen Duan, Song Bai, Lingxi Xie, Honggang Qi, Qingming Huang, Qi Tian. ICCV 2019
Single Stage Detector: CenterNet

Objects as points, Xingyi Zhou, Dequan Wang, and Philipp Krahenbuhl. https://arxiv.org/pdf/1904.07850.pdf, 2019
Single Stage Detector: “CenterNet” – Objects as Points

Instance Segmentation
• Given an image produce instance-level segmentation:
– which class does each pixel belong to? And
– which instance does each pixel belong to?

Two Stage Dectector: Mask R-CNNExtend Faster R-CNN to predict mask as well as box
Mask R-CNN, Kaiming He, Georgia Gkioxari, Piotr Dollár, Ross Girshick, CVPR 2017

Mask R-CNN Demo
Object detection along Singapore Park Connector Network using Mask R-CNN
Mask R-CNN, Kaiming He, Georgia Gkioxari, Piotr Dollár, Ross Girshick, CVPR 2017

Object Detection on COCO test-dev
slide credit: Weidi Xie

Further Reading
Credit: Weidi Xie
[1] R. B. Girshick, J. Donahue, T. Darrell, and J. Malik. Rich feature hierarchies for accurate object detection
and semantic segmentation. In Proc. CVPR, 2014.
[2] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Spatial pyramid pooling in deep convolutional
networks for visual recognition. In Proc. ECCV, 2014.
[3] R. B. Girshick. Fast R-CNN. In Proc. ICCV, 2015.
[4] S. Ren, K. He, R. Girshick, and J. Sun. Faster R-CNN: Towards real-time object detection with region
proposal networks. In NIPS, 2016.
[5] Abhinav Shrivastava, Abhinav Gupta, and Ross Girshick. Training Region-based Object Detectors with
Online Hard Example Mining. In Proc. CVPR, 2016.
[6] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In Proc. CVPR, 2016.
[7] Jifeng Dai, Yi Li, Kaiming He, and Jian Sun. R-FCN: Object Detection via Region-based Fully Convolu-
tional Networks. In NIPS, 2016.
[8] Tsung-Yi Lin, Piotr Dollr, Ross Girshick, He Kaiming, Bharath Hariharan, and Serge Belongie. Feature
Pyramid Networks for Object Detection. In Proc. CVPR, 2017.
[9] Jifeng Dai, Haozhi Qi, Yuwen Xiong, Yi Li, Guodong Zhang, Han Hu, and Yichen Wei. Deformable
Convolutional Networks. In Proc. ICCV, 2017.
[10] Kaiming He, Georgia Gkioxari, Piotr Dollr, and Ross Girshick. Mask R-CNN. In Proc. ICCV, 2017.
[11] Yuxin Wu and Kaiming He. Group Normalization. In Proc. ECCV, 2018.
[12] Bharat Singh, Mahyar Najibi, and Larry S Davis. SNIPER: Efficient multi-scale training. In NIPS, 2018.
[13] Xizhou Zhu, Han Hu, Stephen Lin, and Jifeng Dai. Deformable ConvNets v2: More Deformable, Better
Results. In Proc. CVPR, 2019.
[14] Yanghao Li, Yuntao Chen, Naiyan Wang, and Zhaoxiang Zhang. Scale-Aware Trident Networks for Object
Detection. In Proc. ICCV, 2019.
[15] Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, Scott Reed, Cheng-Yang Fu, and Alexan-
der Berg. SSD: Single Shot MultiBox Detector. In Proc. ECCV, 2016.
[16] Joseph Redmon and Ali Farhadi. Yolo9000: Better, faster, stronger. arXiv preprint arXiv:1612.08242,
2016.
[17] Joseph Redmon and Ali Farhadi. Yolov3: An incremental improvement. 2018.
[18] Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Dollr. Focal Loss for Dense Object
Detection. In Proc. ICCV, 2017.
[19] Hei Law and Jia Deng. CornerNet: Detecting Objects as Paired Keypoints. In Proc. ECCV, 2018.
[20] Xingyi Zhou, Jiacheng Zhuo, and Philipp Kraehenbuehl. Bottom-up object detection by grouping extreme
and center points. In CVPR, 2019.
[21] Xingyi Zhou, Dequan Wang, and Philipp Kreahenbuehl.
https://arxiv.org/pdf/1904.07850.pdf, 2019.
Objects as points.
[22] Kaiwen Duan, Song Bai, Lingxi Xie, Honggang Qi, Qingming Huang, and Qi Tian. Centernet: Keypoint
triplets for object detection. In Proc. ICCV, 2019.

Further Reading
• Really useful blog on mask R-CNN (also includes FPN)
– https://engineering.matterport.com/splash-of-color-instance-segmentation-with-mask-r-cnn-and-
tensorflow-7c761e238b46
• RetinaNet and Focal Loss
– https://towardsdatascience.com/review-retinanet-focal-loss-object-detection-38fba6afabe4
• Ross Girshick’s tutorial on Object Category Detection (2019)
– https://instancetutorial.github.io/