nosql in the enterprise - jp-redhat.comjp-redhat.com/forum/2012/pdf/3-a.pdf · 10/20/2012 · nosql...
TRANSCRIPT

NoSQL in the EnterpriseDr. Paul Pedersen
Deputy CTO, 10gen
Saturday, October 20, 12

Welcome
• The Computing Landscape• The Database Landscape• MongoDB in the Enterprise• MongoDB and Big Data
Saturday, October 20, 12

Welcome
• The Computing Landscape• The Database Landscape• MongoDB in the Enterprise• MongoDB and Big Data
Saturday, October 20, 12

The world has changed
1970 2012
Main memory Intel 1103, 128 bytes 4GB of RAM costs $25.99
Mass storage IBM 3330 Model 1, 100 MB 3TB Superspeed USB for $129
Microprocessor Nearly – 4004 being developed; 92,000 instructions per second
AMD Opteron available with 16 cores, 3.5GHz overclocked
Saturday, October 20, 12

Changes in computing
Data Volume
Agile Development
New Hardware Architectures• Commodity servers• Cloud Computing
• 1012 records• 106 qps• ‘Big Data’
• Iterative dev• Continuous dev
Saturday, October 20, 12

• The Computing Landscape• The Database Landscape• MongoDB in the Enterprise• MongoDB and Big Data
Saturday, October 20, 12

• The Computing Landscape• The Database Landscape• MongoDB in the Enterprise• MongoDB and Big Data
Saturday, October 20, 12

Success brings rising costs ofdb infrastructure
Launch+6
Months+18
Months+24
Months+2
Years
Saturday, October 20, 12

… and lower productivity
• de-normalization• no joins• custom caching layer• custom sharding (partitioning)• rigid schema constraint
Saturday, October 20, 12
Saturday, October 20, 12

Is there a better way?
Saturday, October 20, 12

Yes: non-relational DB
Size of function set
Scal
e, p
erfo
rman
ce memcachedKey / Value
RDBMS
-10
+100
Saturday, October 20, 12

• The Computing Landscape• The Database Landscape• MongoDB in the Enterprise• MongoDB and Big Data
Saturday, October 20, 12

• The Computing Landscape• The Database Landscape• MongoDB in the Enterprise• MongoDB and Big Data
Saturday, October 20, 12

• general-purpose document database
• agile and schema-independent
• high-performance / scalable
• maximizes tradeoff of non-SQL db
What is MongoDB?
Saturday, October 20, 12

13
General Purpose
Agile, Easy to
Use
Fast, Scalable
Powerful query language
Full featured indexes
Rich data model
Simple to setup and manage
Native language drivers
Easy mapping to object
oriented code
Dynamically add / remove
capacity
Replication and
sharding
Operates at in-memory speed
wherever possible
MongoDB summary
Saturday, October 20, 12

MongoDB data modelSelf-describing, atomic documents
RDBMS MongoDBdatabase databasetable collectionrow document column field
Saturday, October 20, 12
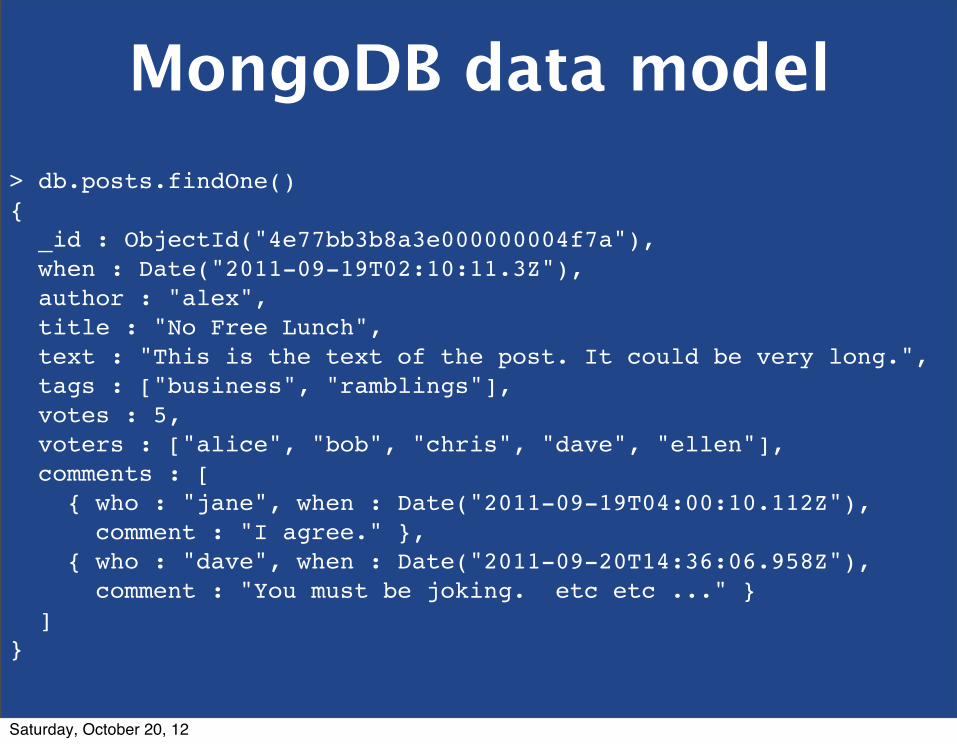
MongoDB data model> db.posts.findOne(){ _id : ObjectId("4e77bb3b8a3e000000004f7a"), when : Date("2011-09-19T02:10:11.3Z"), author : "alex", title : "No Free Lunch", text : "This is the text of the post. It could be very long.", tags : ["business", "ramblings"], votes : 5, voters : ["alice", "bob", "chris", "dave", "ellen"], comments : [ { who : "jane", when : Date("2011-09-19T04:00:10.112Z"), comment : "I agree." }, { who : "dave", when : Date("2011-09-20T14:36:06.958Z"), comment : "You must be joking. etc etc ..." } ]}
Saturday, October 20, 12

MongoDB queryQuery Model When to Use
query language• simple• fast• use data as stored
aggregation pipeline• select, transform, group, sort• low latency• highly extensible
built-in map/reduce• general-purpose• integrated• use when run-time < mtbf
mongo-hadoop connector• maximum flexibility• tolerates run-time ~ mtbf• high latency, far-from-rt
Saturday, October 20, 12

Query examples // select documents where last_name == 'Smith’ db.users.find( {last_name : 'Smith'} );
// select docs where last_name == 'Smith’, project onto ‘ssn’ db.users.find( {last_name : 'Smith'}, {ssn : 1} );
// select all docs, sort by ‘last_name’ ascending/descending db.users.find().sort( {last_name : ±1} );
// select all docs, limit output db.users.find().skip( 20 ).limit( 10 );
Saturday, October 20, 12

MongoDB indexingfor fast query
• index one scalar field > db.things.ensureIndex({j:1});
• index embedded fields > db.things.ensureIndex({"address.city": 1})
• index a concatenated field list > db.things.ensureIndex({j:1, name:-1});
• index a field with list value > db.articles.save( { name: "Warm Weather", author: "Steve", tags: ['weather', 'hot', 'record', 'april'] } ) > db.articles.ensureIndex( { tags : 1 } )
Saturday, October 20, 12

Aggregation example
db.runCommand({ aggregate : "article", pipeline : [ { $project : { author : 1, tags : 1 }},
{ $unwind : "$tags" }, { $group : {
_id : { tags : 1 }, authors : { $addToSet : "$author" } }}]});
Saturday, October 20, 12

Map Reduce example // sample doc { username: "jones", likes: 20, text: "Hello world!" }
// map function function() { emit( this.username, {count: 1, likes: this.likes} ); }
// reduce function function(key, values) { var result = {count: 0, likes: 0};
values.forEach(function(value) { result.count += value.count; result.likes += value.likes; });
return result; }
Saturday, October 20, 12

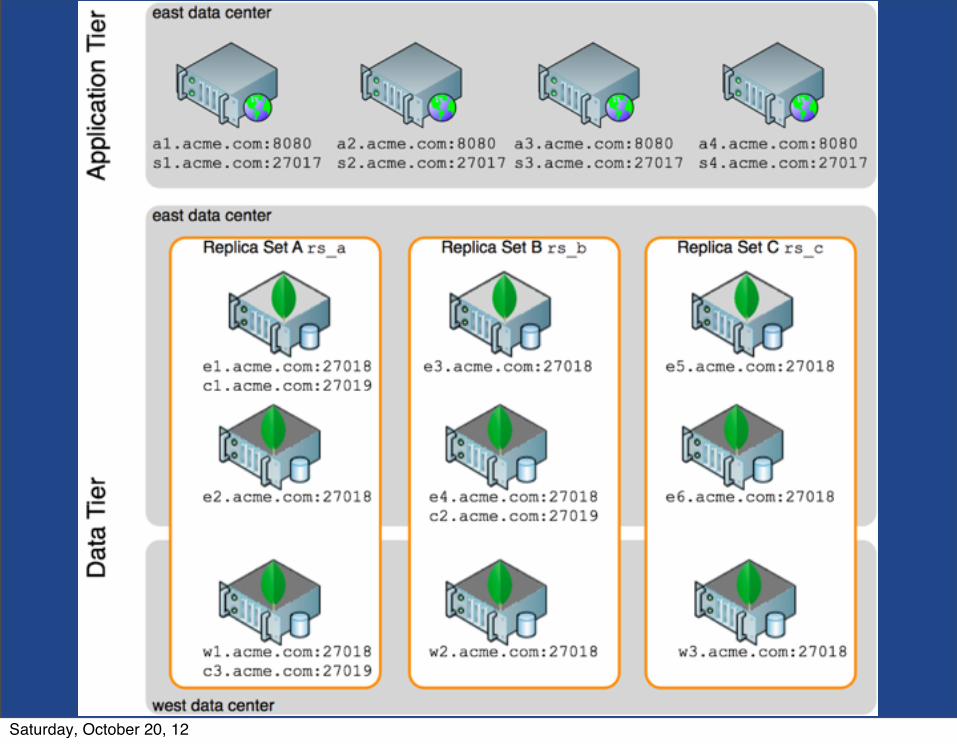
MongoDB cluster DB
Saturday, October 20, 12

MongoDB cluster DB
Saturday, October 20, 12
Saturday, October 20, 12

Many use cases of MongoDB
User Data Management High Volume Data Feeds
Content Management Operational Intelligence Product Data Management
In-Q-Tel
Saturday, October 20, 12

23
Inflexible MySQL with hodgepodge schema and lengthy delays for making changes
Archive-ready data would pile up for months in the production database
Deteriorated performance for live database
Problem
Flexible document-based storage
Horizontal scalability without having to write complex code
Easy to use especially for their relational database team
Proven supported technology including a Perl interface
Why MongoDB
Initial deployment held over 5 billion documents and 10 TB of data
Automated failover of nodes provides high availability
Schema changes on the live database no longer require lengthy and expensive schema migrations
Impact
Craigslist relies on MongoDB to store years of accumulated ever-changing data so its users can quickly find what they are looking for
among its 1.5 million new listings a day
“It’s friendly. By friendly, I mean that coming from a relational background, specifically a MySQL background, a lot of the concepts carry over.... It makes it very easy to get started.”
Jeremy Zawodny, Lead DeveloperSaturday, October 20, 12

24
Managing 20TB of data (six billion images for millions of customers) partitioning by function.
Home-grown key value store on top of their Oracle database offered sub-par performance
Codebase for this hybrid store became hard to manage
High licensing, HW costs
Problem
The “really great reason” for using MongoDB is its rich JSON-based data structure, which offers Shutterfly an agile approach to develop software. With MongoDB, the Shutterfly team can quickly develop and deploy new applications, especially Web 2.0 and social features.
JSON-based data structure
Provided Shutterfly with an agile, high performance, scalable solution at a low cost.
Works seamlessly with Shutterfly’s services-based architecture
Why MongoDB
500% cost reduction and 900% performance improvement compared to previous Oracle implementation
Accelerated time-to-market for nearly a dozen projects on MongoDB
Improved Performance by reducing average latency for inserts from 400ms to 2ms.
Impact
Kenny Gorman, Director of Data Services
Shutterfly uses MongoDB to safeguard more than six billion images for millions of customers in the form of photos and videos, and turn everyday pictures into keepsakes
Saturday, October 20, 12

• The Computing Landscape• The Database Landscape• MongoDB in the Enterprise• MongoDB and Big Data
Saturday, October 20, 12

• The Computing Landscape• The Database Landscape• MongoDB in the Enterprise• MongoDB and Big Data
Saturday, October 20, 12

What is “Big Data”?
• Stuff like Google, Amazon exploit
• V3 = Volume × Velocity × Variety
• “As-is” data, fast-changing, cross-collection, heterogeneous- (e.g.) log files, web user activity, sensor data, cell phone traffic
• Valuable in the aggregate
• Data that drives business optimization
Saturday, October 20, 12

Requirements map
• Variety = schema-free storage = JSON
• Velocity = high update = memory DB
• Volume = horizontal scale-out = cluster DB
• Analytics = map / reduce
• Visualization = analytics tool integration
• Agility = wide language, dev env support
• Security = LDAP, SSL, kerberos integration
Saturday, October 20, 12

MongoDB Big Data volumeNeed share-nothing architectures:• horizontal scaling
- avoid distributed joins select x.p,y.q where x.a=y.b- avoid complex distributed transactions- document / object as unit of atomicity
• in-memory database- write-back algorithm- read-ahead algorithm
Saturday, October 20, 12

MongoDB Big Data volume
• horizontal scaling with commodity hardware cluster DB:- sharding = key range partitioning
- automatic query routing
- automatic data balancing
- smooth path to capacity expansion
Saturday, October 20, 12

Mongo Big Data variety
Insert, index, query can all correctly and transparently handle heterogenous docs within the same collection.
Saturday, October 20, 12

HA with replication
• replica sets- single master, <= 6 active secondaries
- oplog replication
- cross-dc replication
- replica-safe writes
- secondary-preferred reads
Saturday, October 20, 12

MongoDB Big Data velocity• In-memory database- RT or near-RT performance
- 50+K random access queries / sec on SSD
- uses OS-supported memory mapping
- durability levels: fire-and-forget, journal, replication to majority, cross-dc replication
Saturday, October 20, 12

Conclusions:
Saturday, October 20, 12
Launch+6
Months+18
Months+24
Months+2
Years
Saturday, October 20, 12

Is there a better way?
Saturday, October 20, 12

Thank you
36
Saturday, October 20, 12