no more big data hacking—time for a complete etl solution with oracle data integrator 12c
TRANSCRIPT

[email protected] www.rittmanmead.com @rittmanmead
Jerome Francoisse | Oracle OpenWorld 2015
No Big Data Hacking—Time for a Complete ETL Solution with Oracle Data Integrator 12c
1

[email protected] www.rittmanmead.com @rittmanmead
Jérôme Françoisse• Consultant for Rittman Mead
‣ Oracle BI/DW Architect/Analyst/Developer
• ODI Trainer
• Providing ODI support on OTN Forums
• ODI 12c Beta Program Member
• Blogger at http://www.rittmanmead.com/blog/
• Email : [email protected]
• Twitter : @JeromeFr
2

[email protected] www.rittmanmead.com @rittmanmead
About Rittman Mead
3
•World’s leading specialist partner for technical excellence, solutions delivery and innovation in Oracle Data Integration, Business Intelligence, Analytics and Big Data
•Providing our customers targeted expertise; we are a company that doesn’t try to do everything… only what we excel at
• 70+ consultants worldwide including 1 Oracle ACE Director and 3 Oracle ACEs
•Founded on the values of collaboration, learning, integrity and getting things done
Optimizing your investment in Oracle Data Integration
•Comprehensive service portfolio designed to support the full lifecycle of any analytics solution

[email protected] www.rittmanmead.com @rittmanmead
User Engagement
4
Visual Redesign Business User Training
Ongoing SupportEngagement Toolkit
Average user adoption for BI platforms is below 25%
Rittman Mead’s User Engagement Service can help

[email protected] www.rittmanmead.com @rittmanmead
The Oracle BI, DW and Big Data Product Architecture
5

[email protected] www.rittmanmead.com @rittmanmead
The place of Big Data in the Reference Architecture
6

[email protected] www.rittmanmead.com @rittmanmead
Hive
• SQL Interface over HDFS• Set-based transformation• SerDe to map complex file structure
7

[email protected] www.rittmanmead.com @rittmanmead
HiveQLCREATE TABLE apachelog (
host STRING,
identity STRING,
user STRING,
time STRING,
request STRING,
status STRING,
size STRING,
referer STRING,
agent STRING)
ROW FORMAT SERDE 'org.apache.hadoop.hive.contrib.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
"input.regex" = "([^ ]*) ([^ ]*) ([^ ]*) (-|\\[[^\\]]*\\]) ([^ \"]*|\"[^\"]*\") (-|[0-9]*) (-|[0-9]*)(?: ([^ \"]*|\"[^\"]*\") ([^ \"]*|\"[^\"]*\"))?",
"output.format.string" = "%1$s %2$s %3$s %4$s %5$s %6$s %7$s %8$s %9$s"
)
STORED AS TEXTFILE;
LOAD DATA INPATH '/user/jfrancoi/apache_data/FlumeData.1412752921353' OVERWRITE INTO TABLE apachelog;
8

[email protected] www.rittmanmead.com @rittmanmead
Pig
9
• Dataflow language• Pipeline of transformations• Can benefit from UDF

[email protected] www.rittmanmead.com @rittmanmead
Pig Latinregister /opt/cloudera/parcels/CDH/lib/pig/piggybank.jar
raw_logs = LOAD '/user/mrittman/rm_logs' USING TextLoader AS (line:chararray);
logs_base = FOREACH raw_logs
GENERATE FLATTEN
(REGEX_EXTRACT_ALL(line,'^(\\S+) (\\S+) (\\S+) \\[([\\w:/]+\\s[+\\-]\\d{4})\\] "(.+?)" (\\S+) (\\S+) "([^"]*)" "([^"]*)"')
)AS
(remoteAddr: chararray, remoteLogname: chararray, user: chararray,time: chararray, request: chararray, status: chararray, bytes_string: chararray,referrer:chararray,browser: chararray);
logs_base_nobots = FILTER logs_base BY NOT (browser matches '.*(spider|robot|bot|slurp|bot|monitis|Baiduspider|AhrefsBot|EasouSpider|HTTrack|Uptime|FeedFetcher|dummy).*');
logs_base_page = FOREACH logs_base_nobots GENERATE SUBSTRING(time,0,2) as day, SUBSTRING(time,3,6) as month, SUBSTRING(time,7,11) as year, FLATTEN(STRSPLIT(request,' ',5)) AS (method:chararray, request_page:chararray, protocol:chararray), remoteAddr, status;
logs_base_page_cleaned = FILTER logs_base_page BY NOT (SUBSTRING(request_page,0,3) == '/wp' or request_page == '/' or SUBSTRING(request_page,0,7) == '/files/' or SUBSTRING(request_page,0,12) == '/favicon.ico');
logs_base_page_cleaned_by_page = GROUP logs_base_page_cleaned BY request_page;
page_count = FOREACH logs_base_page_cleaned_by_page GENERATE FLATTEN(group) as request_page, COUNT(logs_base_page_cleaned) as hits;
page_count_sorted = ORDER page_count BY hits DESC;
page_count_top_10 = LIMIT page_count_sorted 10;
10

[email protected] www.rittmanmead.com @rittmanmead
Spark
11
• Open-source Computing framework• Dataflow processes• RDDs• in-Memory• Scala, Python or Java

[email protected] www.rittmanmead.com @rittmanmead
Sparkpackage com.cloudera.analyzeblog
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.sql.SQLContext
(…)
def main(args: Array[String]) {
val sc = new SparkContext(new SparkConf().setAppName("analyzeBlog"))
val sqlContext = new SQLContext(sc)
import sqlContext._
val raw_logs = "/user/mrittman/rm_logs"
//val rowRegex = """^([0-9.]+)\s([\w.-]+)\s([\w.-]+)\s(\[[^\[\]]+\])\s"((?:[^"]|\")+)"\s(\d{3})\s(\d+|-)\s"((?:[^"]|\")+)"\s"((?:[^"]|\")+)"$""".r
val rowRegex = """^([\d.]+) (\S+) (\S+) \[([\w\d:/]+\s[+\-]\d{4})\] "(.+?)" (\d{3}) ([\d\-]+) "([^"]+)" "([^"]+)".*""".r
val logs_base = sc.textFile(raw_logs) flatMap {
case rowRegex(host, identity, user, time, request, status, size, referer, agent) =>
Seq(accessLogRow(host, identity, user, time, request, status, size, referer, agent))
case _ => Nil
}
val logs_base_nobots = logs_base.filter( r => ! r.request.matches(".*(spider|robot|bot|slurp|bot|monitis|Baiduspider|AhrefsBot|EasouSpider|HTTrack|Uptime|FeedFetcher|dummy).*"))
val logs_base_page = logs_base_nobots.map { r =>
val request = getRequestUrl(r.request)
val request_formatted = if (request.charAt(request.length-1).toString == "/") request else request.concat("/")
(r.host, request_formatted, r.status, r.agent)
}
val logs_base_page_schemaRDD = logs_base_page.map(p => pageRow(p._1, p._2, p._3, p._4))
logs_base_page_schemaRDD.registerAsTable("logs_base_page")
val page_count = sql("SELECT request_page, count(*) as hits FROM logs_base_page GROUP BY request_page").registerAsTable("page_count")
val postsLocation = "/user/mrittman/posts.psv"
val posts = sc.textFile(postsLocation).map{ line =>
val cols=line.split('|')
postRow(cols(0),cols(1),cols(2),cols(3),cols(4),cols(5),cols(6).concat("/"))
}
posts.registerAsTable("posts")
val pages_and_posts_details = sql("SELECT p.request_page, p.hits, ps.title, ps.author FROM page_count p JOIN posts ps ON p.request_page = ps.generated_url ORDER BY hits DESC LIMIT 10")
pages_and_posts_details.saveAsTextFile("/user/mrittman/top_10_pages_and_author4")
}
}
12

[email protected] www.rittmanmead.com @rittmanmead
How it’s done
• A few experts writing code• Hard to maintain• No Governance• New tools every month
13

[email protected] www.rittmanmead.com @rittmanmead
Déjà vu?DECLARE
CURSOR c1 IS
SELECT account_id, oper_type, new_value FROM action
ORDER BY time_tag
FOR UPDATE OF status;
BEGIN
FOR acct IN c1 LOOP -- process each row one at a time
acct.oper_type := upper(acct.oper_type);
IF acct.oper_type = 'U' THEN
UPDATE accounts SET bal = acct.new_value
WHERE account_id = acct.account_id;
IF SQL%NOTFOUND THEN -- account didn't exist. Create it.
INSERT INTO accounts
VALUES (acct.account_id, acct.new_value);
UPDATE action SET status =
'Update: ID not found. Value inserted.'
WHERE CURRENT OF c1;
ELSE
UPDATE action SET status = 'Update: Success.'
WHERE CURRENT OF c1;
END IF;
ELSIF acct.oper_type = 'I' THEN
BEGIN
INSERT INTO accounts
VALUES (acct.account_id, acct.new_value);
UPDATE action set status = 'Insert: Success.'
WHERE CURRENT OF c1;
EXCEPTION
WHEN DUP_VAL_ON_INDEX THEN -- account already exists
UPDATE accounts SET bal = acct.new_value
WHERE account_id = acct.account_id;
UPDATE action SET status =
'Insert: Acct exists. Updated instead.'
WHERE CURRENT OF c1;
END;
ELSIF acct.oper_type = 'D' THEN
DELETE FROM accounts
WHERE account_id = acct.account_id;
IF SQL%NOTFOUND THEN -- account didn't exist.
UPDATE action SET status = 'Delete: ID not found.'
WHERE CURRENT OF c1;
ELSE
UPDATE action SET status = 'Delete: Success.'
WHERE CURRENT OF c1;
END IF;
ELSE -- oper_type is invalid
UPDATE action SET status =
'Invalid operation. No action taken.'
WHERE CURRENT OF c1;
END IF;
END LOOP;
COMMIT;
END;
14
source : docs.oracle.com




[email protected] www.rittmanmead.com @rittmanmead
Can we do that for Big Data?
• Yes! ODI provides an excellent framework for running Hadoop ETL jobs
- ODI uses all the natives technologies, by pushing down the transformations to Hadoop
16

[email protected] www.rittmanmead.com @rittmanmead
Can we do that for Big Data?
• Yes! ODI provides an excellent framework for running Hadoop ETL jobs
- ODI uses all the natives technologies, by pushing down the transformations to Hadoop
• Hive, Pig, Spark, HBase, Sqoop and OLH/OSCH KMs provide native Hadoop loading / transformation - Requires BigData Option
16

[email protected] www.rittmanmead.com @rittmanmead
Can we do that for Big Data?
• Yes! ODI provides an excellent framework for running Hadoop ETL jobs
- ODI uses all the natives technologies, by pushing down the transformations to Hadoop
• Hive, Pig, Spark, HBase, Sqoop and OLH/OSCH KMs provide native Hadoop loading / transformation - Requires BigData Option
• Also benefits from everything else in ODI- Orchestration and Monitoring - Data firewall and Error handling
16

[email protected] www.rittmanmead.com @rittmanmead
Can we do that for Big Data?
17
Files - Logs
NoSQLDatabase
OLTPDatabase
FilesAPI
FlumeSqoop
ODI
HiveHBaseHDFS
HiveHBaseHDFS
EnterpriseDWH
BigData SQLOLH/OSCH
Sqoop

[email protected] www.rittmanmead.com @rittmanmead
Import Hive Table Metadata into ODI Repository
• Connections to Hive, Hadoop (and Pig) set up earlier• Define physical and logical schemas, reverse-engineer the
table definitions into repository- Can be temperamental with tables using non-standard SerDes;
make sure JARs registered
18
1
2
3



[email protected] www.rittmanmead.com @rittmanmead
HiveQLINSERT INTO TABLE default.movie_rating
SELECT
MOVIE.movie_id movie_id ,
MOVIE.title title ,
MOVIE.year year ,
ROUND(MOVIEAPP_LOG_ODISTAGE_1.rating) avg_rating
FROM
default.movie MOVIE JOIN (
SELECT
AVG(MOVIEAPP_LOG_ODISTAGE.rating) rating ,
MOVIEAPP_LOG_ODISTAGE.movieid movieid
FROM
default.movieapp_log_odistage MOVIEAPP_LOG_ODISTAGE
WHERE
(MOVIEAPP_LOG_ODISTAGE.activity = 1
)
GROUP BY
MOVIEAPP_LOG_ODISTAGE.movieid
) MOVIEAPP_LOG_ODISTAGE_1
ON MOVIE.movie_id = MOVIEAPP_LOG_ODISTAGE_1.movieid
21


[email protected] www.rittmanmead.com @rittmanmead
PigMOVIE = load 'default.movie' using org.apache.hive.hcatalog.pig.HCatLoader as (movie_id:int, title:chararray, year:int, budget:int, gross:int, plot_summary:chararray);
MOVIEAPP_LOG_ODISTAGE = load 'default.movieapp_log_odistage' using org.apache.hive.hcatalog.pig.HCatLoader as (custid:int, movieid:int, genreid:int, time:chararray, recommended:int, activity:int, rating:int, sales:float);
FILTER0 = filter MOVIEAPP_LOG_ODISTAGE by activity == 1;
AGGREGATE = foreach FILTER0 generate movieid as movieid, rating as rating;
AGGREGATE = group AGGREGATE by movieid;
AGGREGATE = foreach AGGREGATE generate
group as movieid,
AVG($1.rating) as rating;
JOIN0 = join MOVIE by movie_id, AGGREGATE by movieid;
JOIN0 = foreach JOIN0 generate
MOVIE::movie_id as movie_id, MOVIE::title as title, MOVIE::year as year, ROUND(AGGREGATE::rating) as avg_rating;
store JOIN0 into 'default.movie_rating' using org.apache.hive.hcatalog.pig.HCatStorer;
23
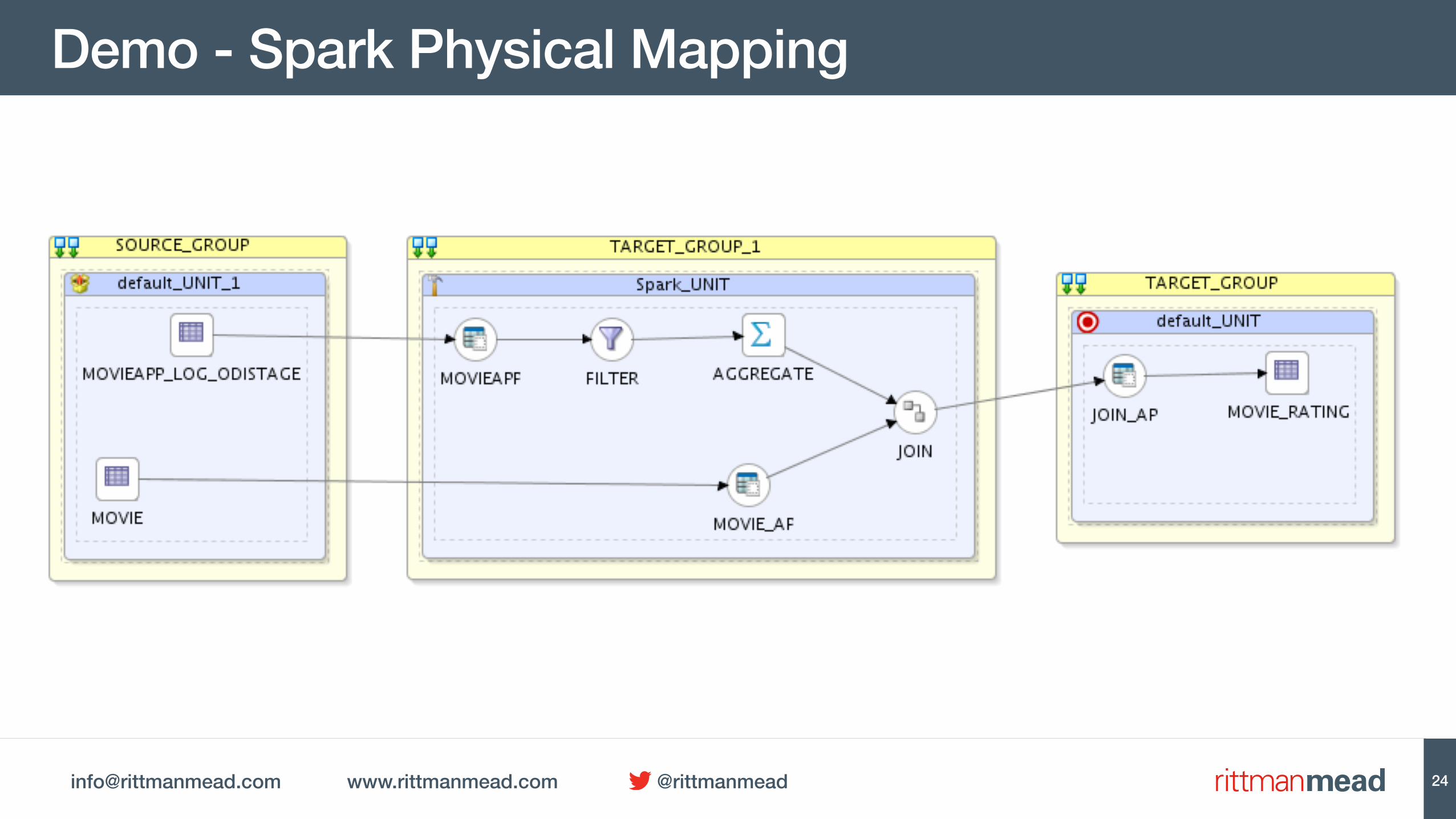

[email protected] www.rittmanmead.com @rittmanmead
pySparkOdiOutFile -FILE=/tmp/C___Calc_Ratings__Hive___Pig___Spark_.py -CHARSET_ENCODING=UTF-8
# -*- coding: utf-8 -*-
from pyspark import SparkContext, SparkConf
from pyspark.sql import *
config = SparkConf().setAppName("C___Calc_Ratings__Hive___Pig___Spark_").setMaster("yarn-client")
sc = SparkContext(conf = config)
sqlContext = SQLContext(sc)
sparkVersion = reduce(lambda sum, elem: sum*10 + elem, map(lambda x: int(x) if x.isdigit() else 0, sc.version.strip().split('.')), 0)
import sys
from datetime import *
hiveCtx = HiveContext(sc)
def convertRowToDict(row):
ret = {}
for num in range(0, len(row.__FIELDS__)) :
ret[row.__FIELDS__[num]] = row[num]
return ret
from pyspark_ext import *
#Local defs
#Replace None RDD element to new defined 'NoneRddElement' object, which overload the [] operator.
#For example, MOV["MOVIE_ID"] return None rather than TypeError: 'NoneType' object is unsubscriptable when MOV is none RDD element.
def convert_to_none(x):
return NoneRddElement() if x is None else x
#Transform RDD element from dict to tuple to support RDD subtraction.
#For example (MOV, (RAT, LAN)) transform to (tuple(sorted(MOV.items())),(tuple(sorted(RAT.items())),tuple(sorted(LAN.items())))
def dict2Tuple(t):
return tuple(map(dict2Tuple, t)) if isinstance(t, (list, tuple)) else tuple(sorted(t.items()))
#reverse dict2Tuple(t)
def tuple2Dict(t):
return dict((x,y) for x,y in t) if not isinstance(t[0][0], (list, tuple)) else tuple(map(tuple2Dict, t))
from operator import is_not
from functools import partial
def SUM(x): return sum(filter(None,x));
def MAX(x): return max(x);
def MIN(x): return min(x);
def AVG(x): return None if COUNT(x) == 0 else SUM(x)/COUNT(x);
def COUNT(x): return len(filter(partial(is_not, None),x));
def safeAggregate(x,y): return None if not y else x(y);
def getValue(type,value,format='%Y-%m-%d'):
try:
if type is date:
return datetime.strptime(value,format).date()
else: return type(value)
except ValueError:return None;
def getScaledValue(scale, value):
try: return '' if value is None else ('%0.'+ str(scale) +'f')%float(value);
except ValueError:return '';
def getStrValue(value, format='%Y-%m-%d'):
if value is None : return ''
if isinstance(value, date): return value.strftime(format)
if isinstance(value, str): return unicode(value, 'utf-8')
if isinstance(value, unicode) : return value
try: return unicode(value)
25

[email protected] www.rittmanmead.com @rittmanmead
pySpark
OdiOSCommand "-OUT_FILE=/tmp/C___Calc_Ratings__Hive___Pig___Spark_.out" "-ERR_FILE=/tmp/C___Calc_Ratings__Hive___Pig___Spark_.err" "-WORKING_DIR=/tmp"
/usr/lib/spark/bin/spark-submit --master yarn-client /tmp/C___Calc_Ratings__Hive___Pig___Spark_.py --py-files /tmp/pyspark_ext.py --executor-memory 1G --driver-cores 1 --executor-cores 1 --num-executors 2
26

[email protected] www.rittmanmead.com @rittmanmead
Can we do that for Big Data?
27
Files - Logs
NoSQLDatabase
OLTPDatabase
FilesAPI
FlumeSqoop
ODI
HiveHBaseHDFS
HiveHBaseHDFS
EnterpriseDWH
BigData SQLOLH/OSCH
Sqoop

[email protected] www.rittmanmead.com @rittmanmead
Oozie
28
• workflow scheduler system to manage Apache Hadoop jobs• execution, scheduling, monitoring• integrated in hadoop ecosystem• no additional footprint• Limitation - No Load Plans


[email protected] www.rittmanmead.com @rittmanmead
Can we do that for Big Data?
30
Files - Logs
NoSQLDatabase
OLTPDatabase
FilesAPI
FlumeSqoop
ODI
HiveHBaseHDFS
HiveHBaseHDFS
EnterpriseDWH
BigData SQLOLH/OSCH
Sqoop

[email protected] www.rittmanmead.com @rittmanmead
Oracle Big Data SQL
31
• Gives us the ability to easily bring in Hadoop (Hive) data into Oracle-based mappings
• Oracle SQL to transform and join in Hive• Faster access to Hive data for real-time ETL scenarios
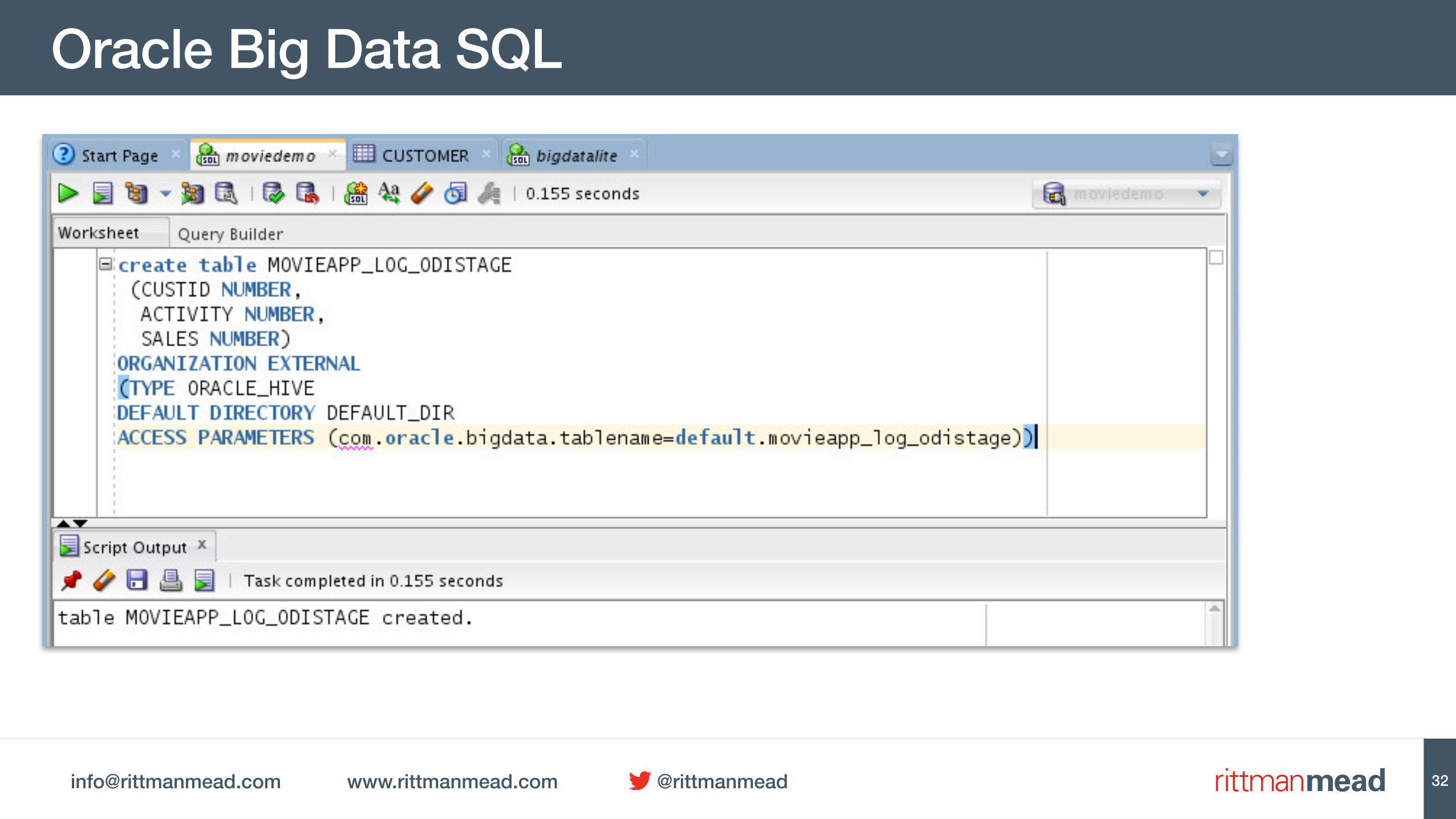



[email protected] www.rittmanmead.com @rittmanmead
Supplement with Oracle Reference Data - SQOOP
• Mapping physical details specify Sqoop KM for extract (LKM SQL to Hive Sqoop)
• IKM Hive Append used for join and load into Hive target
33



[email protected] www.rittmanmead.com @rittmanmead
Can we do that for Big Data?
34
Files - Logs
NoSQLDatabase
OLTPDatabase
FilesAPI
FlumeSqoop
ODI
HiveHBaseHDFS
HiveHBaseHDFS
EnterpriseDWH
BigData SQLOLH/OSCH
Sqoop

[email protected] www.rittmanmead.com @rittmanmead
Missing?
35
• Streaming Capabilities• Spark Streaming• Kafka

[email protected] www.rittmanmead.com @rittmanmead
Further Reading / Testing
36
• http://www.rittmanmead.com/2015/04/odi12c-advanced-big-data-option-overview-install/
• http://www.rittmanmead.com/2015/04/so-whats-the-real-point-of-odi12c-for-big-data-generating-pig-and-spark-mappings/
• Oracle BigData Lite VM - 4.2.1


[email protected] www.rittmanmead.com @rittmanmead
Questions?
38
• Blogs:- www.rittmanmead.com/blog
• Contact:- [email protected] - [email protected] • Twitter- @rittmanmead - @JeromeFr

[email protected] www.rittmanmead.com @rittmanmead
Questions?
38
• Blogs:- www.rittmanmead.com/blog
• Contact:- [email protected] - [email protected] • Twitter- @rittmanmead - @JeromeFr

[email protected] www.rittmanmead.com @rittmanmead
Rittman Mead Sessions
39
No Big Data Hacking—Time for a Complete ETL Solution with Oracle Data Integrator 12c [UGF5827]
Jérôme Françoisse | Sunday, Oct 25, 8:00am | Moscone South 301
Empowering Users: Oracle Business Intelligence Enterprise Edition 12c Visual Analyzer [UGF5481]
Edelweiss Kammermann | Sunday, Oct 25, 10:00am | Moscone West 3011
A Walk Through the Kimball ETL Subsystems with Oracle Data Integration Solutions [UGF6311]
Michael Rainey | Sunday, Oct 25, 12:00pm | Moscone South 301
Oracle Business Intelligence Cloud Service—Moving Your Complete BI Platform to the Cloud [UGF4906]
Mark Rittman | Sunday, Oct 25, 2:30pm | Moscone South 301
Oracle Data Integration Product Family: a Cornerstone for Big Data [CON9609]
Mark Rittman | Wednesday, Oct 28, 12:15pm | Moscone West 2022
Developer Best Practices for Oracle Data Integrator Lifecycle Management [CON9611]
Jérôme Françoisse | Thursday, Oct 29, 2:30 pm | Moscone West 2022