nn cont’d. administrivia no news today... homework not back yet working on it... solution set out...
Post on 22-Dec-2015
214 views
TRANSCRIPT

NN Cont’d

Administrivia•No news today...
•Homework not back yet
•Working on it...
•Solution set out today, though

Whence & Whither•Last time:
•Learning curves & performance estimation
•Metric functions
•The nearest-neighbor classifier
•Today:
•Homework 2 assigned
•More on k-NN
•Probability distributions and classification
•(maybe) NN in your daily life

Homework 2•Due: Feb 16
•DH&S, Problems 4.9, 4.11, 4.19, 4.20
•Also:
•Prove that the square of Euclidean distance is still a metric
•Let W be a square matrix (dXd). Is
still a metric? Under what conditions on W?

Distances in classification•Nearest neighbor rule: find the nearest instance to the query point in feature space, return the class of that instance
•Simplest possible distance-based classifier
•With more notation:
•Distance here is “whatever’s appropriate to your data”

Properties of NN•Training time of NN?
•Classification time?
•Geometry of model?
d( , )
Closer to
Closer to

Properties of NN•Training time of NN?
•Classification time?
•Geometry of model?

Properties of NN•Training time of NN?
•Classification time?
•Geometry of model?

Eventually...

Gotchas•Unscaled dimensions
•What happens if one axis is measured in microns and one in lightyears?

Gotchas•Unscaled dimensions
•What happens if one axis is measured in microns and one in lightyears?
? x ? x

Gotchas•Unscaled dimensions
•What happens if one axis is measured in microns and one in lightyears?
•Usual trick is to scale each axis to [-1,1] range
? x ? x

NN miscellaney
•Slight generalization: k-Nearest neighbors (k-NN)
•Find k training instances closest to query point
•Vote among them for label

Geometry of k-NN
d(7)
Query point

What’s going on here?•One way to look at k-NN
•Trying to estimate the probability distribution of the classes in the vicinity of query point, x
•Quantity is called the posterior probability of
•Probability that class is , given that the data vector is x
•NN and k-NN are average estimates of this posterior
•So why is that the right thing to do?...

5 minutes of math
•Bayesian decision rule
•Want to pick the class that minimizes expected cost
•Simplest case: cost==misclassification
•Expected cost == expected misclassification rate

5 minutes of math
•Expectation only defined w.r.t. a probability distribution:
•Posterior probability of class i given data x:
•Interpreted as: chance that the real class is , given that the observed data is x

5 minutes of math•Expected cost is then:
•cost of getting wrong * prob of getting it wrong
•integrated over all possible outcomes (true classes)
•More formally:
•Want to pick that minimizes this

5 minutes of math•For 0/1 cost, reduces to:

5 minutes of math•For 0/1 cost, reduces to:
•To minimize, pick the that minimizes:

5 minutes of math•In pictures:

5 minutes of math•In pictures:
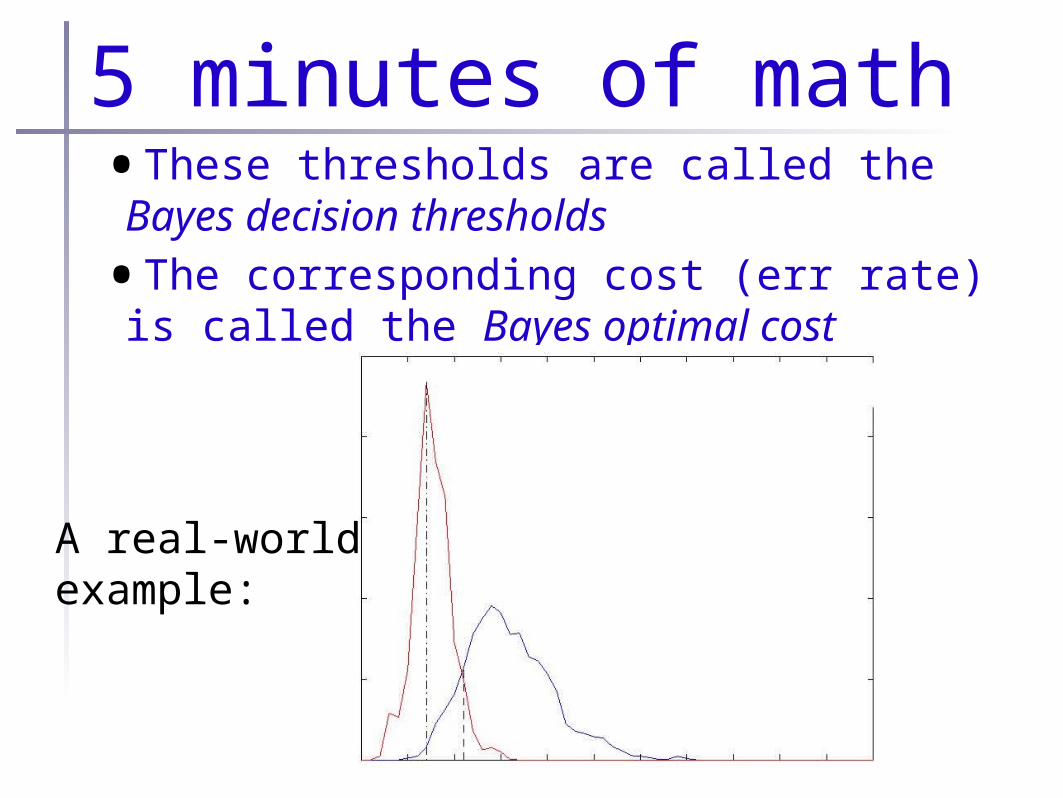
5 minutes of math•These thresholds are called the Bayes decision thresholds
•The corresponding cost (err rate) is called the Bayes optimal cost
A real-worldexample:

Back to NN•So the nearest neighbor rule is using the density of points around the query as an estimate
•Labels are an estimate of
•Assume that the majority vote corresponds to maximum
•As k grows, estimate gets better
•But there are problems with growing k...

Exercise•Geometry of k-NN
•Let V(k,N)=volume of sphere enclosing k neighbors of X, assuming N points in data set
•For fixed N, what happens to V(k,N) as k grows?
•For fixed k, what happens to V(k,N) as N grows?
•What about radius of V(k,N)?

The volume question•Let V(k,N)=volume of sphere enclosing k neighbors of X, assuming N points in data set
•Assume uniform point distribution
•Total volume of data is (1, w.l.o.g.)
•So, on average,

1-NN in practice•Most common use of 1-nearest neighbor in daily life?

1-NN & speech proc.•1-NN closely related to technique of Vector Quantization (VQ)
•Used to compress speech data for cell phones
•CD quality sound:•16 bit/sample•44.1 kHz•⇒ 88.2 kB/sec ⇒ ~705 kbps
•Telephone (land line) quality:•~10 bit/sample•10 kHz•⇒ ~12.5 kB/sec ⇒ 100 kpbs
•Cell phones run at ~9600 bps...

Speech compression via VQ
Speechsource
Raw audiosignal

Speech compression via VQ
Raw audio “Framed” audio

Speech compression via VQ
Framedaudio
Cepstral(~ smoothed frequency)
representation

Speech compression via VQ
Cepstrum
Downsampledcepstrum

Speech compression via VQ
D.S. cepstrumVector
representation
Vectorquantize(1-NN)
Transmittedexemplar
(cell centroid)

Compression ratio•Original:
•10 bits
•10 kHz; 250 samples/“frame” (25ms/frame)
•⇒ 100 kbps; 2500 bits/frame
•VQ compressed:
•40 frames/sec
•1 VC centroid/frame
•~1M centroids ⇒ ~20 bits/centroid
•⇒ ~800 bits/sec!

Signal reconstruction
Transmittedcell centroid
Look upcepstral
coefficients
Reconstructcepstrum
Convert to audio

Not lossless, though!