nlp and ir: coming closer or moving apart pushpak bhattacharyya computer science and engineering...
TRANSCRIPT

NLP and IR: Coming Closer or Moving Apart
Pushpak Bhattacharyya
Computer Science and Engineering Department
IIT Bombay
www.cse.iitb.ac.in/~pb
Acknowledgement: Manoj Chinnakotla, Arjun Atreya, Mitesh Khapra and many others

NLP and IR Perspective
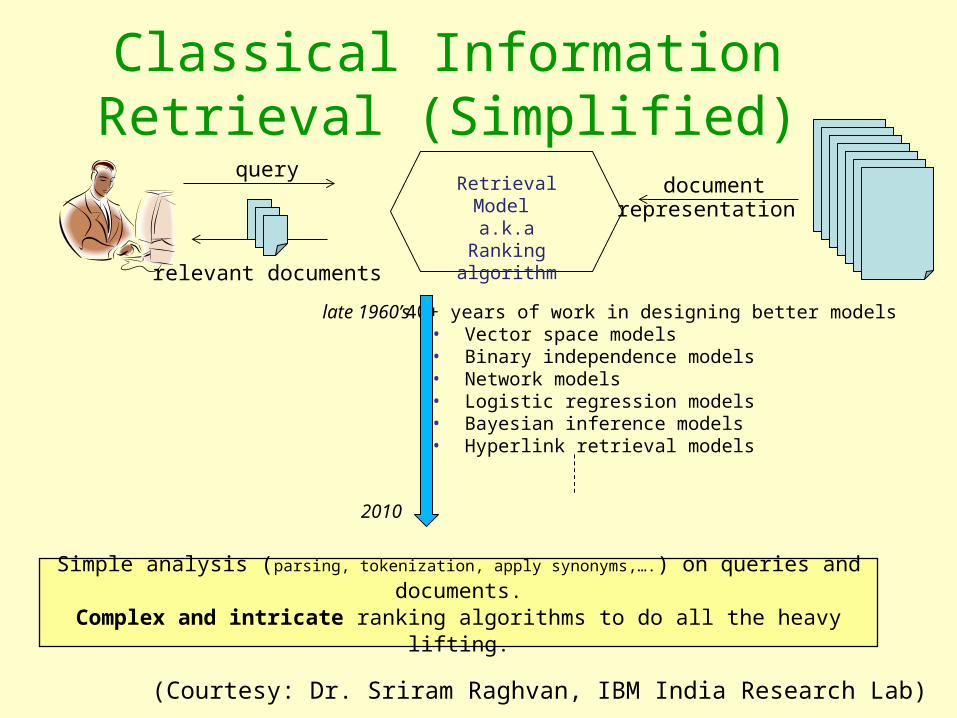
Classical Information Retrieval (Simplified)
Retrieval Model a.k.a
Ranking algorithm
query
relevant documents
40+ years of work in designing better models• Vector space models• Binary independence models• Network models• Logistic regression models • Bayesian inference models• Hyperlink retrieval models
late 1960’s
2010
Simple analysis (parsing, tokenization, apply synonyms,….) on queries and documents.Complex and intricate ranking algorithms to do all the heavy lifting.
documentrepresentation
(Courtesy: Dr. Sriram Raghvan, IBM India Research Lab)

The elusive user satisfaction
Ranking
Correctnessof
Query ProcessingCoverage
NER
StemmingMWE
Crawling Indexing

Example: Semantically precise search for relations/events
Query: afghans destroying opium poppies

How NLP has used IR
• Web looked upon as a huge repository of evidence for language phenomena.
• PMI measure used for Co occurence, Collocation leading to interesting NLP problems like Malapropism detection (Bolshakov and Gelbukh, 2003), evaluation of synsets quality (outlier)
• Page rank used for WSD• Recent important problem: getting dictionary from
comparable corpora which abound in the web – (Bo Li & Eric Gaussier: Improving corpus comparability for
bilingual lexicon extraction from comparable corpora. COLING 2010)

How IR has used NLP• Query disambiguation
– WSD: very necessary, but does it make a difference– Different technique than in NLP, very small context
• Morphology: better than statistical stemmer? (McNamee et al SIGIR 2009)
• Capture Term Relationships – Random walk (Kevyn Collins-Thompson and Jamie
Callan, CIKM 2005)– Lexical Semantic Association/Indexing (Deerwester et
al, 1990)• Search Quality Management: Understanding Queries
(Fagin et al, PODS 2010)

Road map
1. A perspective on the relationship between NLP and IR
a) How NLP has used IR
b) How IR has used NLP
2. NLP using IR
Into the Heartland of NLP: Malapropism
3. IR using NLP
MultiPRF: a way of disambiguation in IR leveraging multilinguality
4. Conclusions and future directions

NLP using IR

Into the heartland of NLP: Malapropism detection (Gelbuk et. Al,
2003)• Unintended replacement of one content word by another
existing content word similar in sound but semantically incompatible
• Immortalized by Mrs. Malaprop in Sheridan’s The Rival– “Why, murder's the matter! slaughter's the matter!
killing's the matter! But he can tell you the perpendiculars.“
– "He is the very pineapple of politeness.“
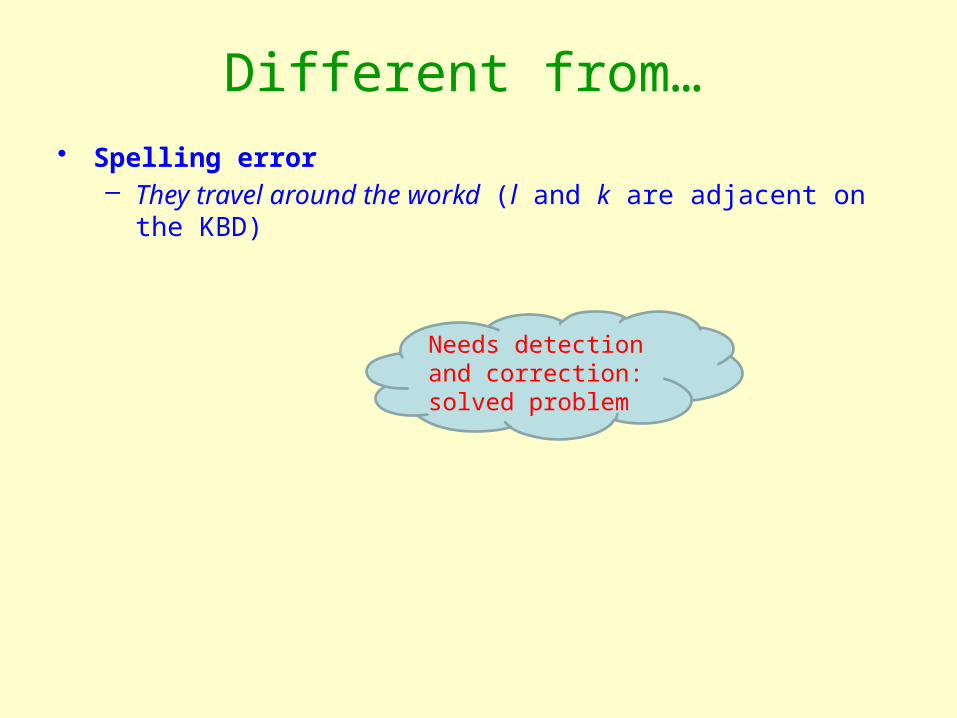
Different from… • Spelling error
– They travel around the workd (l and k are adjacent on the KBD)
Needs detection and correction: solved problem

Different from… • Eggcorn (idiosyncratic substitution, but plausible)
– ex-patriot instead of expatriate– on the spurt of the moment instead of on the spur of the moment
Needs detection and correction, but not critical: needs to be solved

Different from… • Spoonerism (error in speech or deliberate play on words in which
corresponding consonants, vowels, or morphemes are switched)– "The Lord is a shoving leopard." (a loving shepherd) – "A blushing crow." (crushing blow)– "You have hissed all my mystery lectures.
Needs detection and correction: needs to be solved

Different from… • Pun
– Is life worth living? That depends a lot on the liver (both meanings plausible)
– We're not getting anywhere in geometry class. It feels like we're going in circles.
Should NOT be corrected

Motivation for Malapropism Detection
• Interactive (manual) editing• Detect and correct errors• Spell checking and correction is practically a solved
problem• Grammar checking and correction still needs vast
improvement• Semantic incoherence, very difficult to detect and correct

Solution proposed using Google Search and Mutual Information
A pair (V,W) is collocation if it satisfies the above formula N(V,W) is the number of web-pages where V and W co-occur N(V) and N(W) are numbers of the web-pages evaluated
separately Nmax is the total web-page number managed by Google for the
given language.
As a bottom approximation to Nmax, the number N(MFW) of the pages containing the most frequent word MFW can be taken
For English, MFW is ‘the,’ and N(‘the’) is evaluated to 2.5 billions of pages
This inequality rejects a potential collocation, if its components co-occur in a statistically insignificant quantity.

Experimental ResultsPossible collocation Correct version Malapropos version1 travel around the word 55400 202 swim to spoon 23 03 take for granite 340000 154 bowels are pronounced 767 05 loose vowels 2750 13206 (a) wear turbines 3640 306 (b) turbines on the heads 25 07 ingenuous machine 805 68 affordable germs 1840 99 dielectric materialism 1080 410 (a) equal excess 457000 99010 (b) excess to school 19100 411 Ironic columns 5560 2812 activated by irritation 22 1013 histerical center 90000 714 scientific hypotenuse 7050 0

IR using NLP

Cross Lingual Search: Motivation• English still the most dominant
language on the web Contributes 72% of the
content• Number of non-English users
steadily rising all over the world
• English penetration in India Estimated to be around 3-4% Mostly the urban educated
class• Need to enable access to
above information through local languages
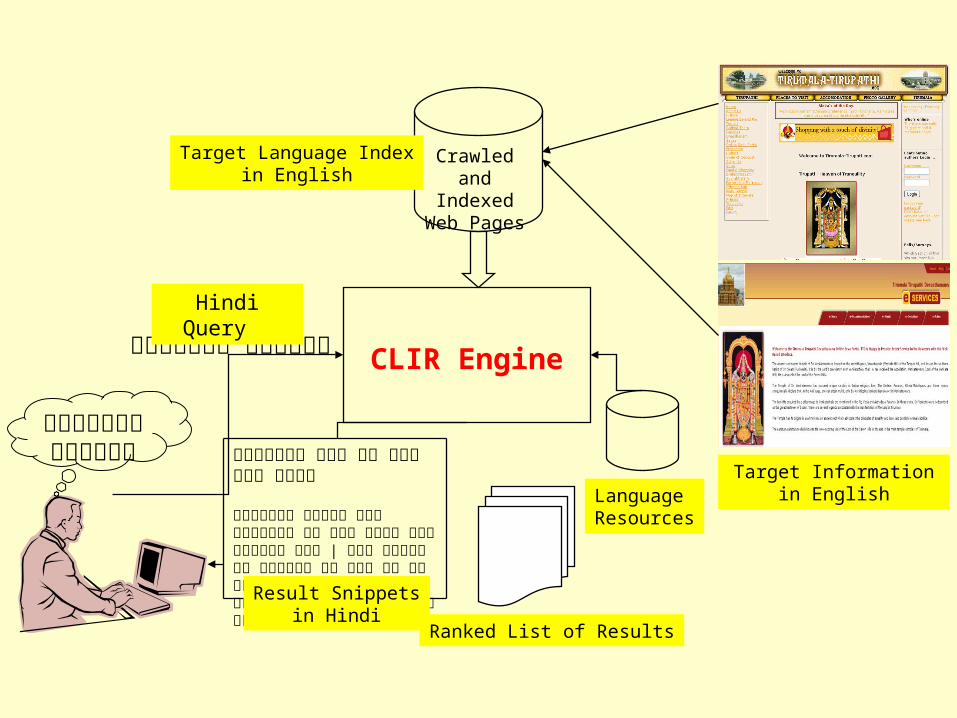
Crawled and Indexed
Web Pages
Target Informationin English
ति�रूपति� या�त्रा�
Hindi Query
CLIR Engine
Target Language Indexin English
Ranked List of Results
Language Resources
ति�रूपति� आने के लि ए रे सा�धने
ति�रूपति� प�ण्य नगर पहुँ�चन� के� लि�ए बहुँ� र�� उप�ब्ध हैं� | अगर मुं��बई से� य�त्रा� केर रहैं� हैं� � मुं��बई- च�न्नई एक्सेप्रे�से ग�ड़ी% से� प्रेवा�से केर सेके�� हैं� |
ति�रूपति� या�त्रा�
Result Snippetsin Hindi

v vTranslation
DisambiguationMachine
Transliteration
QueryTranslation
NER Identification
Language Analysis (Stemming &
Stopword)
FocusedCrawler
FontTranscoder CMLifier
LanguageIdentifier
NE and MWEIdentification
MWEIdentify
The Web (WWW)
CLIA GUI
SnippetGeneration and
Translation
Template BasedInformation Extraction
MLIRIndex
Search and Ranking
MultilingualDictionary
Results with Summary
and Snippet
OutputPresentation
Crawling and Indexing
Input Query Processing
DocumentSummarization
Translatedand
DisambiguatedQuery

IR using Language Typology and NLP:
Multilingual Pseudo Relevance Feedback
(Manoj Chinnakotla, Karthik Raman and Pushpak Bhattacharyya, Multilingual Relevance Feedback: One Language Can Help Another, Conference of Association of Computational Linguistics (ACL 2010), Uppsala, Sweden, July 2010.)

User Information Need
• Expressed as short query (average length 2.5 words)• Need query expansion• Lexical resources based expansion did not deliver
(Voorhees 1994) – Paradigmatic association (synonyms, antonyms, hypo
and hypernyms)– Introduces severe topic drift through unrelated senses
of expansion terms– Also through irrelevant senses of query terms

Illustration
Query word: “Madrid bomb blast case”
{case, container}
{case, suit, lawsuit}
{suit, apparel}
Drifted topic due to expanded term!!!
Drifted topic due to inapplicable sense!!!

Query Expansion: Current Dominant Practice
• Syntagmatic Expansion• Through Pseudo Relevance Feedback• We show
– Mutlilingual PRF helps– Familially related language helps still more– Result of insight from linguistics and NLP– Disambiguation by leveraging multilinguality

Language Modeling Approach to IR
• Offers a principled approach to IR• Each document modeled as a probability distribution –
Document Language Model• User information need is modeled as a probability
distribution – Query Model
Importance of term in Query
Importance of term in Document
Score(D) ( , )
( | ) log ( | )
R
Rw
KL D
P w P w D
Ranking Function – KL Divergence
Problem of Retrieval ↔ Problem of Estimating P(w|ΘR) and P(w|D)

The Challenge - Estimating Query Model ΘR
• Average length of query: 2.5 words
• Relevance Feedback to the rescue–User marks some documents from initial
ranked list as “relevant”–Usually difficult to obtain
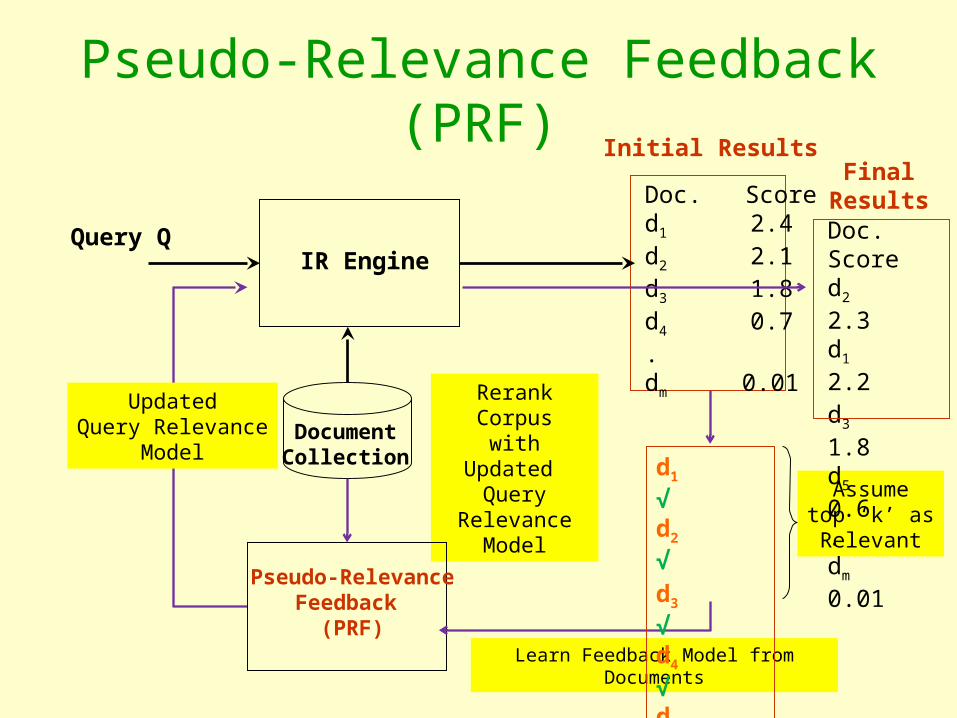
Pseudo-Relevance Feedback (PRF)
DocumentCollection
IR Engine
Doc. Scored1 2.4d2 2.1
d3 1.8d4 0.7.dm 0.01
Initial Results
Query Q
Rerank Corpuswith Updated
Query Relevance
Model
UpdatedQuery Relevance
Model
Pseudo-RelevanceFeedback
(PRF)Learn Feedback Model from Documents
d1 √d2 √
d3 √d4 √dk √
Assumetop ‘k’ asRelevant
Doc. Scored2 2.3d1 2.2
d3 1.8d5 0.6.dm 0.01
Final Results

Limitations of PRF: Lexical and Semantic Non-Exclusion
Accession to European Union
Initial Retrieval Documents
europeunionaccessnationrussiapresidgettiyearstate
Relevant documents with terms like “Membership”, “Member”, “Country” not
ranked high enough
Final ExpandedQuery
Stemmed Query“access europe union”
Previous Attempts • Voorhees et al. used Wordnet –
Negative results
• Random walk models on Wordnet, Morphological variants, co-occurrence terms (Zhai et al., Collins-Thompson and Callan)

Limitations of PRF: Lack of Robustness
Olive Oil Production in
Mediterranean
Initial Retrieved Documents
OilOlivMediterraneanProducCookSaltPepperServCup
Causes Query Drift
Final ExpandedQuery
Stemmed Query“oliv oil mediterranean”
Documents about
Cooking
Previous Attempts• Refining top document set• Refining initial terms obtained
through PRF• Selective query expansion• TREC Robustness Track –
improving robustness

Can both Semantic Non-inclusion and Lack of Robustness be solved?
• Harnesses “Multilinguality”:– Take help of a collection in a different language called
“assisting language”– Expectation of increased robustness, since searching
in two collections
• An attractive proposition for languages that have poor monolingual performance due to– Resource constraints like inadequate coverage– Morphological complexity

Related Work
• Gao et al. (2009) use English to improve Chinese language ranking– Demonstrate only on a subset of queries– Experimentation on a small dataset– Uses cross-document similarity

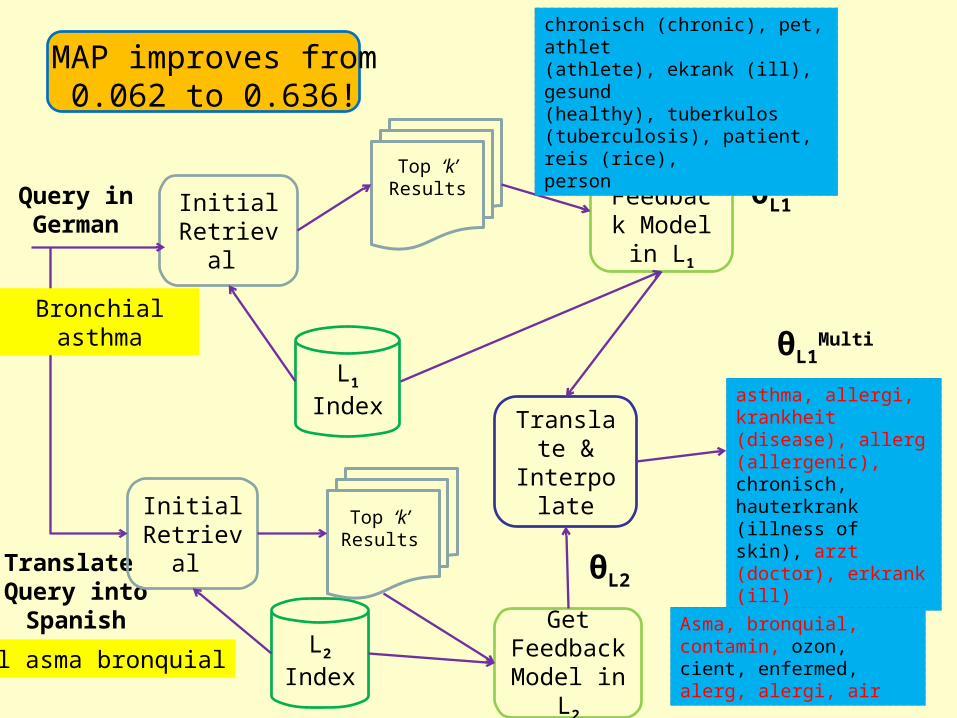
Multilingual PRF: System Flow
Query in L1
Initial Retrieval
Translate Query into L2
Initial Retrieval
L1 Index
L2
Index
Top ‘k’ Results
Top ‘k’ Results
Get Feedback Model in
L1
Get Feedback Model in
L2
θL1
θL2
Translate Feedback
Model into L1
θL1Trans
InterpolateModels
Ranking using Final
Model

Feedback Model Translation
• Feedback model estimated in L2 (ΘFL2) translated back
into L1 (ΘTransL1)
– Using probabilistic bi-lingual dictionary from L2 to L1
– Learnt from parallel sentence-aligned corpora
• Back Translation Step

Semantically Related Terms through Feedback Model Translation
Feedback Model
Translation Step
Nation
Nation
Country
State
UN
English-French Word Alignments
Nation, CountryState, UN, United
United
Flugzeug
Aircraft
Plane
Aeroplane
Air
German-English Word Alignments
Aircraft, PlaneAeroplane, Air, Flight
Flight

SIGIR Findings: English Lends a Helping Hand!
• English used as assisting language– Good monolingual performance– Ease of processing
• MultiPRF consistently and significantly outperforms monolingual PRF baseline
(Manoj Chinnakotla, Karthik Raman and Pushpak Bhattacharyya, Multilingual PRF: English Lends a Helping Hand, SIGIR 2010, Geneva, Switzerland, July, 2010.)
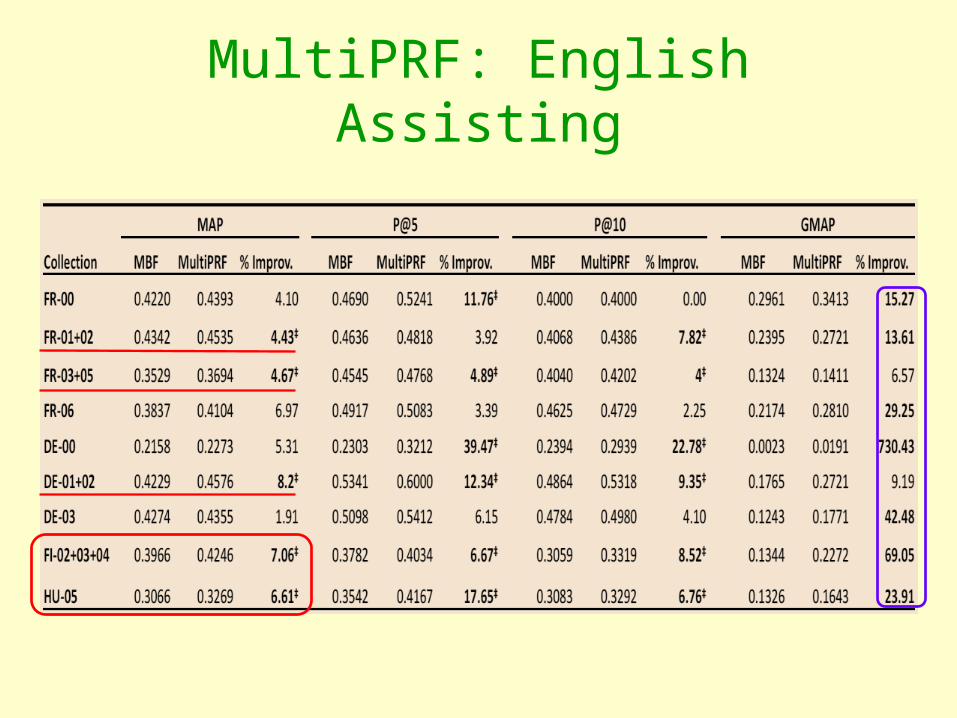
MultiPRF: English Assisting

Performance Study of Assisting Languages
• Do the results hold for languages other than English?• What are the characteristics of a good assisting
language?• Can any language be used to improve the PRF
performance of another language?• Can this be extended to multiple assisting languages?

Language Typology

Experimental Setup
• European languages chosen• Europarl corpora• CLEF dataset
– Six languages from different language families– French, Spanish (Romance), – German, English, Dutch (West Germanic), – Finnish (Baltic-Finnic)– On more than 600 topics
• Use Google Translate for Query Translation
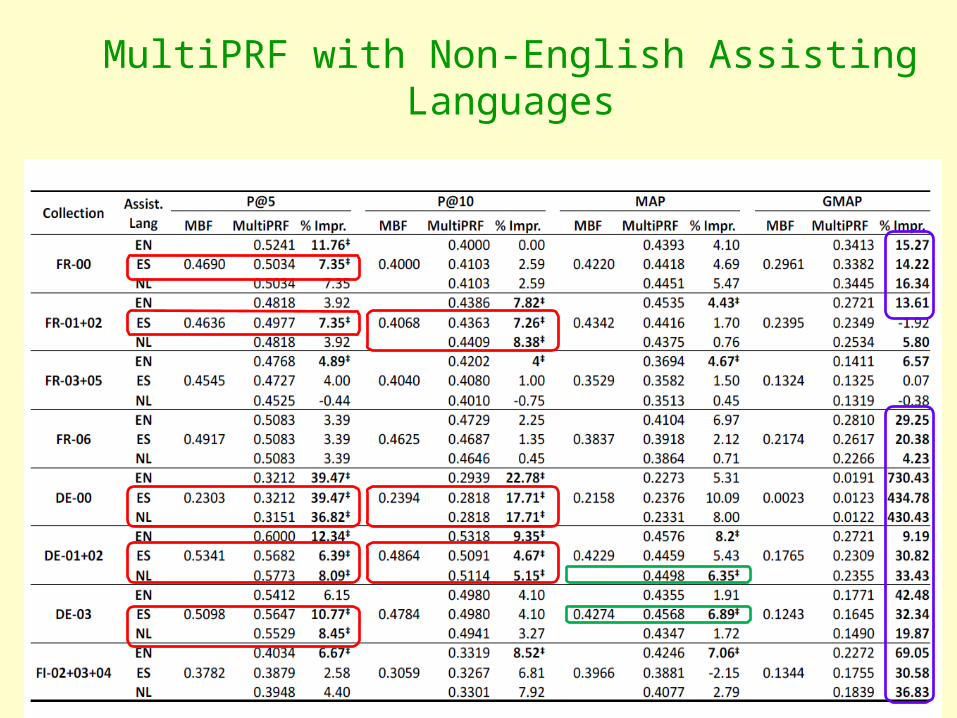
MultiPRF with Non-English Assisting Languages
Query in German Initial
Retrieval
Translate Query into
Spanish
Initial Retrieval
L1 Index
L2
Index
Top ‘k’ Results
Top ‘k’ Results
Get Feedback Model in
L1
Get Feedback Model in
L2
θL1
θL2
θL1Multi
Bronchial asthma
El asma bronquial
chronisch (chronic), pet, athlet(athlete), ekrank (ill), gesund(healthy), tuberkulos(tuberculosis), patient, reis (rice),person
asthma, allergi, krankheit (disease), allerg (allergenic), chronisch, hauterkrank (illness of skin), arzt (doctor), erkrank (ill)
Asma, bronquial, contamin, ozon, cient, enfermed, alerg, alergi, air
Translate &
Interpolate
MAP improves from0.062 to 0.636!

Query in French Initial
Retrieval
Translate Query into
Dutch
Initial Retrieval
L1 Index
L2
Index
Top ‘k’ Results
Top ‘k’ Results
Get Feedback Model in
L1
Get Feedback Model in
L2
θL1
θL2
θL1Multi
Ingénierie Génétique
GenetischeManipulatie
développ (developed), évolu(evolved), product, produit(product), moléculair (molecular)
génet, ingénier, manipul, animal, pêcheur (fisherman), développ (developed), gen
genetisch, manipulatie, exxon, dier (animal), visser (fisherman), gen
Translate &
Interpolate
MAP improves from0.145 to 0.357!

Results

More than one assisting language
• Tried parallel composition for two assisting languages
• Uniform interpolation weights used
• Exhaustively tried all 60 combinations
• Improvements reported over best performing PRF of L1 or L2

Conclusions• NLP and IR: seems to be needing each other
– NLP needs IR: for large scale evidence for language phenomena
– IR needs NLP: for high quality sophisticated search• Very likely useful in extended-text query situation: Question
Answering, Topic-Description-Narration• MultiPRF uses another language to improve robustness and
performance• Can be looked upon as a way of disambiguation• Robust, Large Scale, Language Independent WSD methods needed
in the face of resource constrained situation (not-so-large amount of sense marked corpora)

URLs
• For resources
www.cfilt.iitb.ac.in• For publications
www.cse.iitb.ac.in/~pb

Thank you
Questions and comments?

Tracing the Development of IR Models from
Term Presence-Absence to Query Meaning
Ranking: can NLP help IR

Description AND, OR and NOT operators
Features Based on term presence/absence. 1/0 decision
Query Collection of Logical Expressions
Relevance True or False
Term weighting NA
Benefits Easy to implement, high efficiency and clarity
Limitations Unnatural query formation. Too severe (All or nothing).
Standard Boolean Model

Description Query is in natural language. Converted to boolean query automatically.
Features Less strict than standard booleanRanking of output
Query Collection of Logical Expressions
Parameters Boolean operators andTerm frequency
Relevance True or False with relevance
Term weighting Term frequency
Benefits No need of boolean operators.Assist in query reformulation
Limitations Formulating extended boolean queries needs domain and query expertise.
Extended Boolean Model

Description Ranking based on similarity between query vector and document vector
Features Simplifies query formulation Provides ability to control output.
Query Collection of independent terms
Parameters Term frequencyInverse document frequency
Relevance Cosine Similarity
Term weighting tf * idf
Benefits Term weights are not binary.Allows ranking of documents according to similarity.
Limitations Less clarity. Assumes terms are independent. False positives and False negatives.
Vector Space Model
i
j
dj
q

Description Ranking based on conditional probability of relevance
Features Addresses uncertainty in query representation.
Query Collection of independent terms
Parameters Probabilities of a term appearing in relevant and non-relevant document
Relevance Model based relevance
Term weighting Relevance feedback
Benefits Multiple models with different tuning of parameters.
Limitations Estimation of needed probabilities is difficult.Assumes terms to be independent.
Probabilistic Model (e.g., OKAPI BM25)

Description Every term is associated with a concept. Term dependencies handled.
Features Based on term document matrix
Query Considers some amount of term dependencies
ParametersTerm Matrix TDocument Matrix DSingular value Matrix S
Relevance Based on each entry of matrix A
Term weighting Based on document category
Benefits Association among terms and documents.Terms generalized to concepts
Limitations Computation expensive.Finding optimal dimension of A is difficult.
A k=T k S k D kT
Latent Semantic Indexing

Description Query meaning used. Retrieval at concept level
Features Each document corresponds to a language model.
Query Collection of dependent words
Parameters Probability of query under the language model.
Relevance
Term weighting
Benefits Clusters dependent terms
Limitations Difficult to exploit feedback to improve ranking.High computational complexity.
Query likelihood Model

Summary: Tracing IR Models
• Set theoretic, Algebraic and Probabilistic Models• Underlying current of attempt trying to capture “Query
Meaning”• Started with Karen Spark-Jones’ thesis titled “Synonyms
and Semantic Search” in Cambridge in the 90s• The effort continues

Does WSD help or hurt IR?

WSD Definition
• Obtain the sense of – A set of target words, or of– All words (all word WSD, more difficult)
• Against a – Sense repository (like the wordnet), or– A thesaurus (not same as wordnet, does not have
semantic relations)

Elaboration (example word: operation)
• Operation, surgery, surgical operation, surgical procedure, surgical process -- (a medical procedure involving an incision with instruments; performed to repair damage or arrest disease in a living body; "they will schedule the operation as soon as an operating room is available"; "he died while undergoing surgery") TOPIC->(noun) surgery#1
• Operation, military operation -- (activity by a military or naval force (as a maneuver or campaign); "it was a joint operation of the navy and air force") TOPIC->(noun) military#1, armed forces#1, armed services#1, military machine#1, war machine#1
• Operation -- ((computer science) data processing in which the result is completely specified by a rule (especially the processing that results from a single instruction); "it can perform millions of operations per second") TOPIC->(noun) computer science#1, computing#1
• mathematical process, mathematical operation, operation -- ((mathematics) calculation by mathematical methods; "the problems at the end of the chapter demonstrated the mathematical processes involved in the derivation"; "they were learning the basic operations of arithmetic") TOPIC->(noun) mathematics#1, math#1, maths#1

To do or not to do WSD?
• Persuasive arguments against WSD (e.g., Voorhees, 1999)
• Investigations still continue• One such compelling investigation: WSD in the context
of query expansion in IR• While good quality expansion terms can increase recall,
bad expansion terms introduce topic drift and drastically bring down precision

To do or not to do WSD? (contd)
• Given query words, expanding them into accurate paradigmatically related words- synonyms, hypernyms, meronyms, troponyms, derived_forms etc. depends on WSD
• Syntagmatic expansion terms to come from Pseudo Relevance Feedback (Buckley et. al., 1994; Xu and Croft, 2000; Mitra et al., 1998)

Our direct experience of need for WSD in CLIR
• Recurring experience: Incorrect mapping of query words into English reduces the map score by at least 0.2 points
• Another need: Pages retrieved by the search engine are preferably presented in the language of the query
• Usefulness of WSD is well established in Machine Translation (Chang et. al., 2007 and Capuat and Wu, 2007).

Hindi-English Marathi-English0
5
10
15
20
25
30
35
40
45
50
43.75 43.75
25
31.25
18.75
6.25
12.5
0
TransliterationTranslation DisambiguationStemmerDictionaryRanking
Err
or
Pe
rce
nta
ge
Our observationsOn error PercentagesDue to variousFactorsCLEF 2007

Shared Tasks/Competition
• CLEF initiated competitions to determine quantitatively the performance gain or otherwise of WSD in CLIR- since 2007
• SemEval-2007 Task 01: Evaluating WSD on Cross-Language Information Retrieval (Agirre et. al., 2007): – Earliest attempt at evaluation of WSD for IR– SpanishEnglish– Best map value was obtained when the first sense of
a word from wordnet 1.6 was picked up and all the words in the synset were translated
– Performance badly hit when all synsets and all translations were chosen

Shared Tasks/Competition (contd.)
• Robust WSD task@CLEF2008: SpanishEnglish• Query expansion with synonyms from the first sense
helped• Effect of WSD most pronounced for those words which
are highly polysemous and have high IDF value, reported in– http://www.clef-campaign.org/2008/working_notes/CLEF2008WN-Conte
nts.html
• Clough and Stevenson (2004) observed that WSD (manual or automatic) introduced in CLIR can go towards monolingual retrieval performance (Eurowordnet used)

Robust WSD task@CLEF2009
• English and Spanish Monolingual IR• SpanishEnglish CLIR• Documents:
– LA Times 1994 (with word sense disambiguated data); ca 113,000 documents, 425 MB without WSD, 1,448 MB (UBC) or 2,151 MB (NUS) with WSD;
– Glasgow Herald 95 (with word sense disambiguated data); ca 56,500 documents, 154 MB without WSD, 626 MB (UBC) or 904 MB (NUS) with WSD.

Robust WSD task@CLEF2009 (contd)
• CLEF Topics from years 2001, 2002 and 2004 were used as training topics (relevance assessments were offered to participants)
• Topics from years 2003, 2005 and 2006 were used for the test
• All topics were offered both with and without WSD• Relevance data
– CLEF 2003: 23,674 documents, 1,006 relevant– CLEF 2005: 19,790 document, 2,063 relevant– CLEF 2006: 21,247 document, 1,258 relevant

Robust WSD task@CLEF2009 (Observations)
CLEF 2009 Working notes on robust track: WSD: Agirre et. al.

Observations from the task
• Inconclusive!• Exact techniques used for WSD were not revealed• Teams consisted mostly of IR people• Little NLP awareness• WSD used as blackbox
link

(Raghuvar Nadig, J. Ramanand and Pushpak Bhattacharyya, ICON 2008)
NLP using IR:
Web based validation
of
Wordnet Hypernyms

Anatomy of a wordnet
A graph of “synsets”
Synset: a collection of synonyms
Relations:
synonymy { icon – picture – image - ikon }
antonymy { … opposite of … }
hypernymy { icon is a type of representation }
holonymy { … part of … }

Anatomy of a synset
Relational semantics
Words in a synset disambiguate each other
icon (three meanings: computer term, image, religion)
icon, ikon (two meanings: image, religion)
picture, icon, ikon, (we have a winner!)

Are the hypernym-nyponyms in the wordent correct?
“is-a” relation between noun synsets
Given 2 synsets, check if they share a hypernym-hyponym relationship
Hypernym DiscoveryHearst: syntactic patterns
Snow: hypernymy dependency trees
Sumida: Wikipedia-based extraction

Hypernym validation - 3 Steps
{synset X}
1. Common head
2. Hearst patterns
3. Coordinate Terms
valid
valid
Could not validate
{synset Y}
WWW
Wiki-pedia

Step 1: common head
If a term of synset X is a proper suffix of a term in synset Y
X is a hypernym of Y
Task 1:
Synset A: {racing}
Synset B: {auto racing, car racing}
Task 2:
Synset A: {work}
Synset B: {paper work}

Step 2: Web evidence using Hearst patterns
If words from synsets X and Y in the form of a Hearst pattern show sufficient number of search results
X is a hypernym of Y
Hearst Patterns
9 types, e.g.:
“W_x such as W_y” (“Games such as cricket”)
“W_y and other W_x” (“Cricket and other games”)
Test
Query WWW for all Hearst patterns for pairs of words from synsets X & Y
If at least two patterns show non-zero results, validated

Step 3: Coordinate terms from Wikipedia
Find coordinate terms for words in Synset Y
Use Wikipedia
Repeat Step 2 (web evidence using Hearst Patterns) using coordinate terms
Example
Synset A: {medical science}
Synset B: {radiology}
Assume Step 2 does not succeed
Search Wikipedia for patterns
w_1, w_2, …, w_n-1 and w_n
w_1, w_2, …, w_n-1 or w_n
where w_k = “radiology”

Step 3: Coordinate terms from Wikipedia
Example
Synset A: {medicine, medical specialty}
Synset B: {radiology}
Wikipedia results
“categories such as radiology, pathology, or anaesthesia” (src: http://en.wikipedia.org/wiki/Medicine#Specialties)
Step 2 with Hearst Pattern search (medicine, radiology)

Hypernym validation – ResultsTested on Princeton Wordnet 2.1
Noun synsets
79297 hypernym-hyponym pairs
Search Queries
Microsoft Live Search
Coordinate Terms from Wikipedia
Indexed content for coordianate term retrieval

Hypernym validation – Results
Rule % of validated
pairs
1 – Suffix match 21.35%
2 – Search using Hearst Patterns
46.84%
3 – Use Coordinate terms 02.68%
Observations
71% of all synsets validated
Validation is a strong indicator of hypernymy correctness
Treat failure to validate as a flag for human inspection
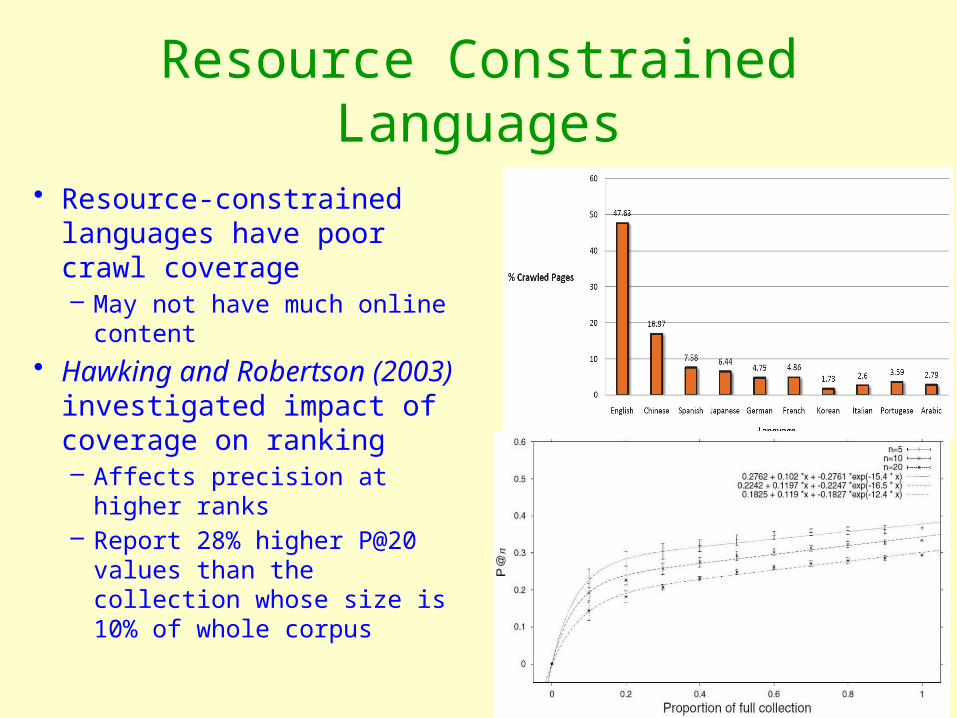
Resource Constrained Languages
• Resource-constrained languages have poor crawl coverage– May not have much online
content
• Hawking and Robertson (2003) investigated impact of coverage on ranking– Affects precision at higher
ranks– Report 28% higher P@20
values than the collection whose size is 10% of whole corpus
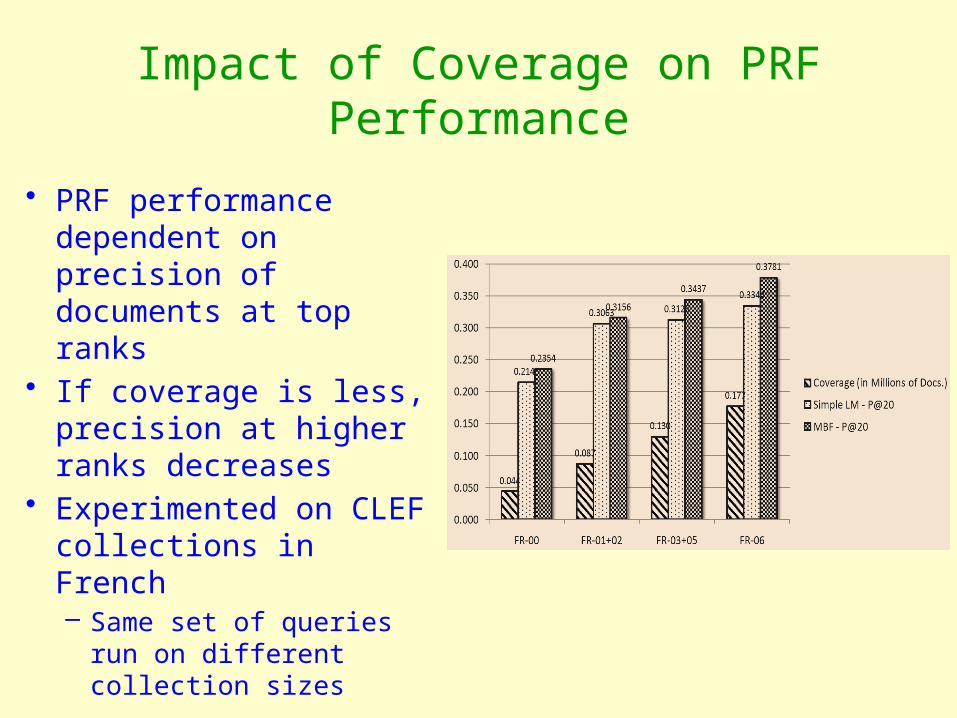
Impact of Coverage on PRF Performance
• PRF performance dependent on precision of documents at top ranks
• If coverage is less, precision at higher ranks decreases
• Experimented on CLEF collections in French– Same set of queries run
on different collection sizes

Use assisting collection in the same language?