nitin mathur - accelerating innovation with spark and hadoop – harnessing the convergence of data...
TRANSCRIPT

NITIN MATHUR DIRECTOR – HADOOP COE SCOTIABANK

• Spark Overview
• High Level Architecture
• Hadoop MapReduce V/S Spark
• Use cases for Spark
• Spark Limitations
• Q&A
Agenda

Data Storage on
Punch Card
Drum & Tape Storage Hard Drive Low Cost Disk
Storage
Cheap
Memory
History of Data Storage…


Business wants Data-Driven Real-time Analytics
• Predict Product Revenue
• Customer Assessment • Targeted Advertising
• Fraud Detection • Risk Assessment
• Data-driven medicine - built a system at Toronto’s Sick Kids hospital to monitor newborns and predict dangerous infections 24 hours earlier than traditional visual
methods .

• Developed at the University of California, Berkerley’s AMPLab. It is open source cluster computing framework, developed in response to the limitation of MapReduce computing paradigm.
• Enables Low-latency with complex analytics!
• Fast, distributed, scalable and fault tolerant cluster compute system!
Spark – Overview

• Spark is 100x faster in memory than Hadoop Map Reduce on disk.
• Write 2-5 x less code.
• Provides Fault Tolerant Distributed Datasets.
• Integrates with Most File and Storage Options.
• Provides capability for both Batch and Streaming analysis.
Spark – In Memory Magic
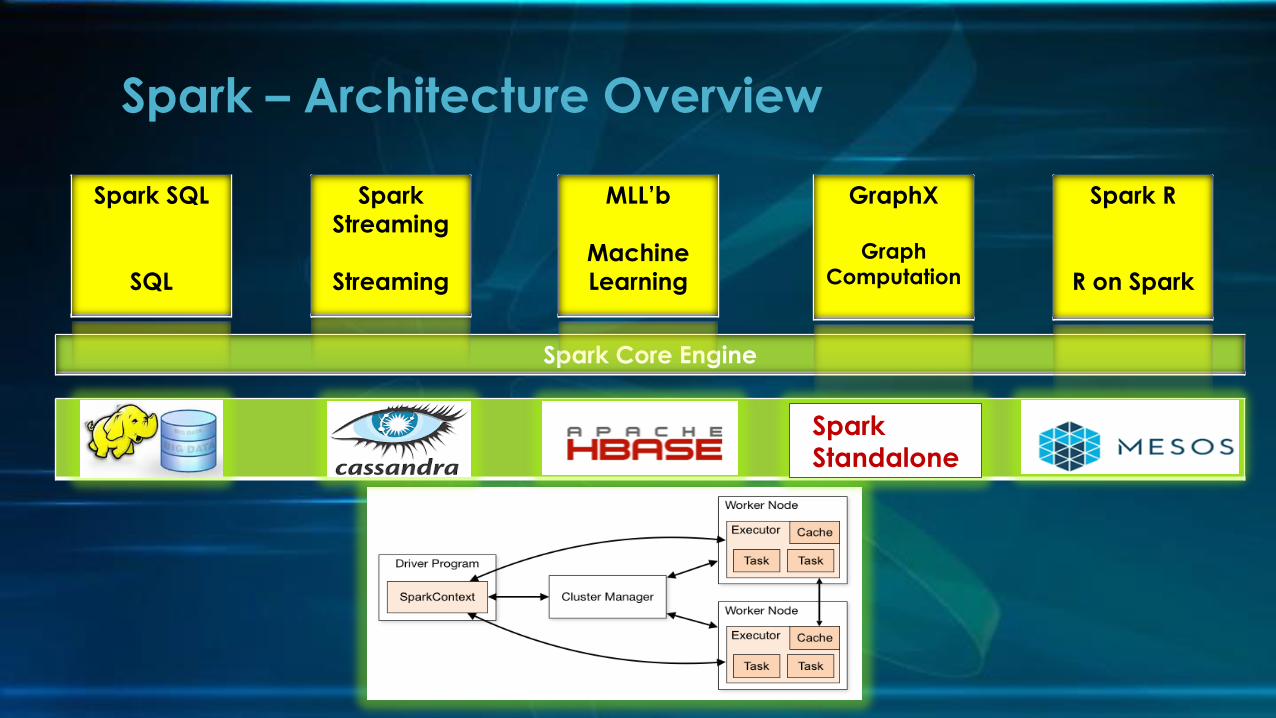
Spark – Architecture Overview
Spark Core Engine
Spark
Streaming
Streaming
MLL’b
Machine
Learning
Spark SQL
SQL
GraphX
Graph
Computation
Spark R
R on Spark
Spark Standalone

• They are build for Fault Tolerant and can re recalculate from any point of failure!
• Created through transformations on data (map,filter..) or other RDDs !
• Immutable
• Can be reused
• Partitioned
Spark - Resilient Distributed Dataset (RDD)
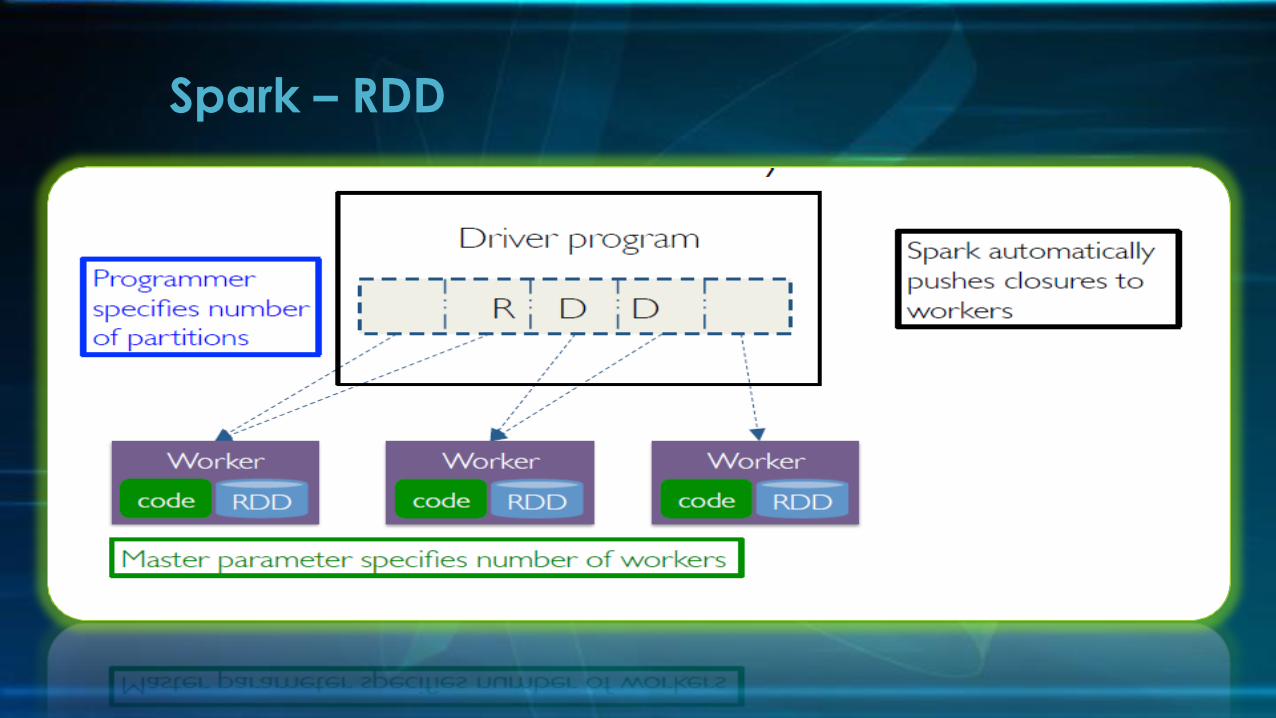
Spark – RDD
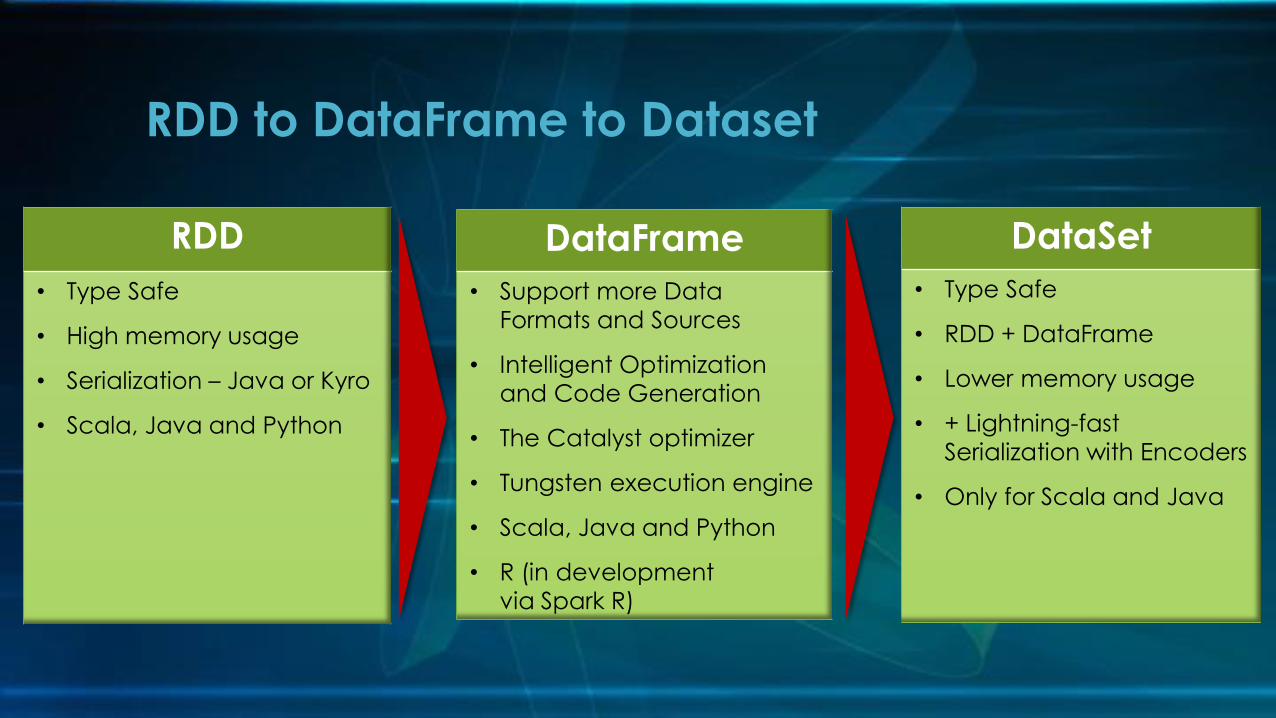
RDD
• Type Safe
• High memory usage
• Serialization – Java or Kyro
• Scala, Java and Python
RDD to DataFrame to Dataset
DataFrame
• Support more Data
Formats and Sources
• Intelligent Optimization
and Code Generation
• The Catalyst optimizer
• Tungsten execution engine
• Scala, Java and Python
• R (in development
via Spark R)
DataSet
• Type Safe
• RDD + DataFrame
• Lower memory usage
• + Lightning-fast
Serialization with Encoders
• Only for Scala and Java

Spark Hadoop
New and evolving . Mature with new features and capabilities to
make it easier to setup and use.
Spark keeps the Data in memory. Only goes to
Disk when needed. It also keeps the data in
memory between Map and Reduces phases.
Performance boost 10x-100x.
Hadoop promise is to boost performance by
having processer closer to Data. It process
data on Disk.
Unlike Hadoop, Spark can be run in a variety of
modes, standalone, Apache Mesos, Hadoop
YARN, and in the cloud.
Works on HDFS
Less coding as compare to Hadoop
Ease of Use
Develop applications quickly in Java, Scala,
Python, R. Offers over 80 high-level operators
that make it easy to build parallel apps.
Use it interactively from the Scala, Python and R
shells.
More Coding
Can’t change interactively
Spark V/S Hadoop

Spark – Use Cases

Business Problem : • Data volumes exceeding a total of 100TB, with a data ingest rate of 1.5TB per day,Eyeview began to see
performance problems which impacted its ability to efficiently mine the data.
• 30-day look-back query across all the user segments often required several hours, which was not acceptable to
its business needs.
• Legacy system was rigid and could not scale on-demand.
• Data scientists and engineers were spending a significant amount of time on DevOps duties
Solution : Hosted in the cloud (AWS), Databricks provided Eyeview with an unparalleled level of flexibility and performance.
Through Databricks’ interactive notebooks and Spark engine, Eyeview can quickly and easily explore and visualize
its data reducing the time to insights delivered .
Outcome : • Reduced query times on large data sets by a factor of 10, allowing data analysts to regain 20 percent of their
workday from waiting for results.
• Speed up data processing by fourfold without incurring additional operational costs.
• Team members with limited big data expertise can easily utilize Spark clusters without the need for DevOps.
• Easily spin up or down fully managed Spark clusters on-demand with a few clicks.
Spark – Case Study Databricks Case Study CEO - Matei Zaharia (CTO)
Custumer - Eyeview
Source: https://databricks.com/resources/case-studies

• Not fit for Multi User Environment - Adding more users further complicates this since the users will have to coordinate memory usage to run projects concurrently.
• Working with Small Data sets
Spark – When Not to use Spark

• In Memory Magic.
• 100x faster in memory than Hadoop Map Reduce on disk.
• Write 2-5 x less code to write.
• Spark can be run in a variety of modes, standalone, Apache Mesos, Hadoop.
• Spark provides capability for Real Time and Batch Analytics.
• Moving from RDD to DataFrame to Dataset.
Spark – Key take away

