ngs data generation dr laura emery. overview the ngs data explosion sequencing technologies an...
TRANSCRIPT

NGS Data Generation
Dr Laura Emery

Overview
• The NGS data explosion
• Sequencing technologies
• An example of a sequencing workflow
• Bioinformatics challenges

The NGS data explosion

EBI biological data
1996
1997
1998
1999
2000
2001
2002
2003
2004
2005
2006
2007
2008
2009
2010
2011
2012
0
2000
4000
6000
8000
10000
12000
14000
16000
18000
TB
of
da
ta

Bottlenecks to biological research
Source: Qiagen

NGS Technologies
• A variety of platforms available
• Differ in:
• Library preparation
• Sequencing chemistry

Comparison of NGS Technologies
Library preparation
Sequencing chemistry
Features
Roche 454 Emulsion PCR
Pyrosequencing
Longer read length, only available until 2016
Illumina HiSeq
Solid phase amplification
Reversible terminator
Best output to cost ratio, low error rates
Applied Biosciences SOLiD
Emulsion PCR
Sequencing by ligation
Highest accuracy
Pacific Biosciences RS II
Single molecule
Real time Very long read lengths, highest error rates

Example: Illumina NGS workflow
4. Data Analyses
3. Sequencing
2. Hybridisation and Amplification
1. Library Preparation

1. Library preparation
• RNA extraction
• Fragmentation and size selection
• cDNA synthesis
• Adapter ligation
RNA only
RNA only

1. Library preparation
• Alternative library preparation methods:
• Mate pair • Targeted • Strand specific

1. Library preparation
• Multiplexing (optional)

Example: Illumina NGS workflow
4. Data Analyses
3. Sequencing
2. Hybridisation and Amplification
1. Library Preparation
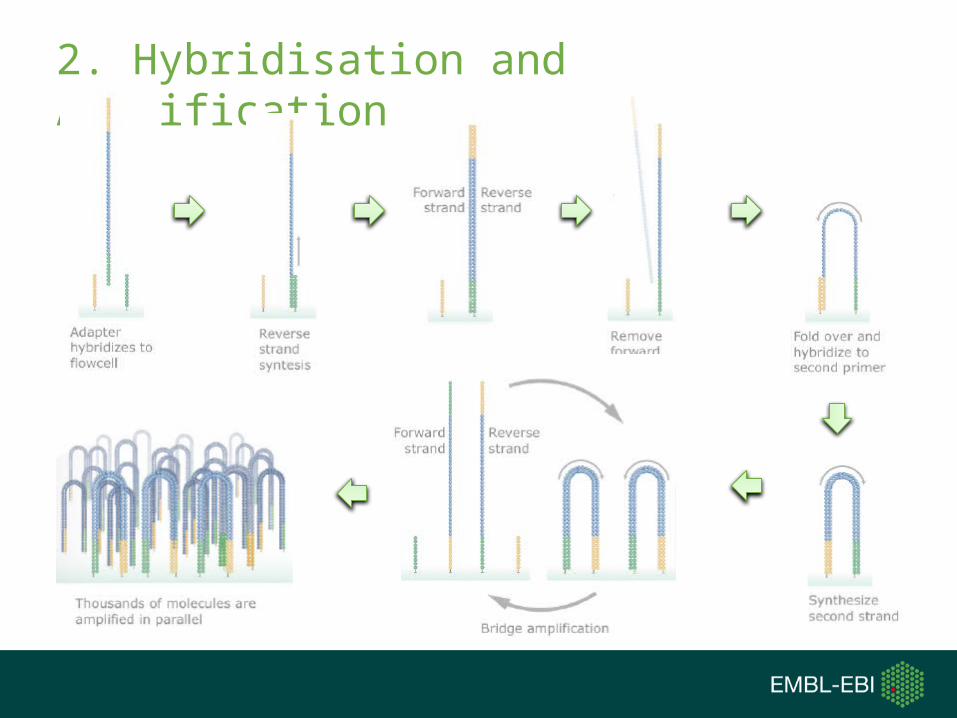
2. Hybridisation and Amplification

Example: Illumina NGS workflow
4. Data Analyses
3. Sequencing
2. Hybridisation and Amplification
1. Library Preparation
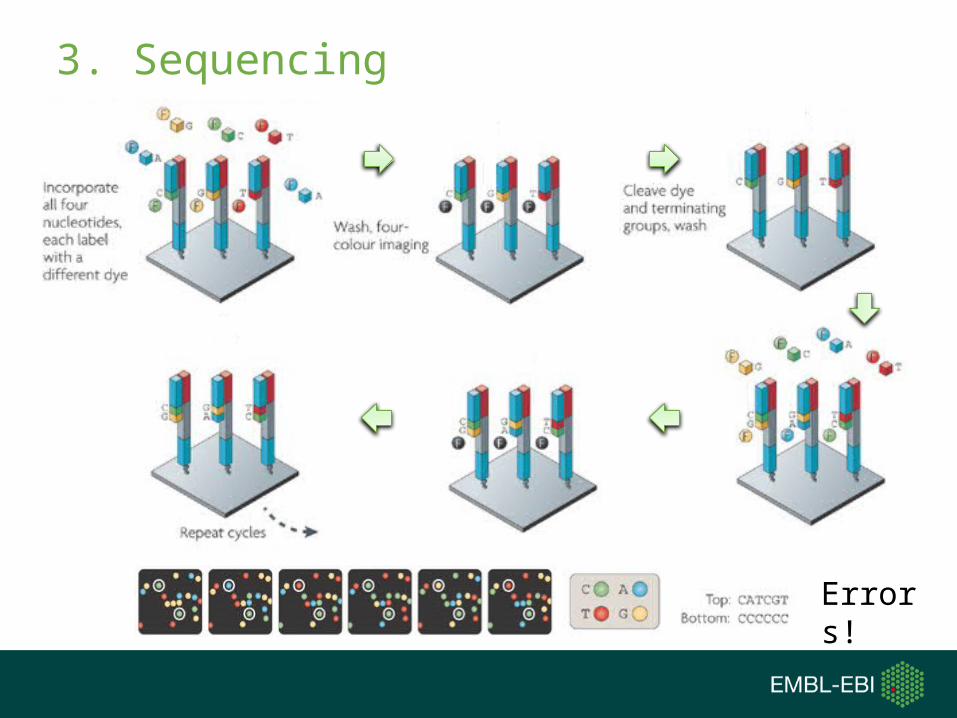
3. Sequencing
Errors!

3. Sequencing (Paired-end)

Example: Illumina NGS workflow
4. Data Analyses
3. Sequencing
2. Hybridisation and Amplification
1. Library Preparation

4. Data analyses: generalised pipeline
Data submission to public repository
Downstream analyses
Alignment and/or assembly
Filtering
QC
FASTQ
Otherdata

Bioinformatics challenges
• Library preparation biases
• Random hexamer priming
• GC content
• Data storage
• Data analysis
• Errors
• Mapping/assembly uncertainty

Bioinformatics challenges
• Library preparation biases
• Random hexamer priming
• GC content
• Data storage
• Data analysis
• Errors
• Mapping/assembly uncertainty
Sequence bias in the first 13 nucleotidesMethods for correction: Cufflinks, mmseq

Bioinformatics challenges
• Library preparation biases
• Random hexamer priming
• GC content
• Data storage
• Data analysis
• Errors
• Mapping/assembly uncertainty
GC-rich or AT-rich fragments have been found to be over/underrepresentedMethods for correction: EDASeq, CG correct

Bioinformatics challenges
• Library preparation biases
• Random hexamer priming
• GC content
• Data storage
• Data analysis
• Errors
• Mapping/assembly uncertainty

Conclusions
• NGS technologies provide us with new opportunities but new challenges
• You will learn more about overcoming these challenges during this course
• Furthermore, other omics technologies will be introduced

So over to Bernardo…