new approaches to extracting greater decision power from big data
TRANSCRIPT

Summary The organizations that most quickly draw the greatest rewards from Big Data will be those that look past its immense promise to tackle an equally large challenge. How Big Data ultimately delivers improved decisions and insights will depend critically on intelligent analytics, adaptive infrastructure and action. With data sets today coming rapidly from so many sources, and in so many structured and unstructured formats, an organization’s selection of technology in supplementing or replacing a data repository platform is critical to how well it will acquire and store the data and, most importantly, how quickly and effectively it can analyze the data. Without fast and powerful data analysis, Big Data can’t produce either big insights or better decisions.
This paper examines several important considerations in developing a Big Data infrastructure, including:
• How to determine value from data.
• How to streamline data acquisition and reduce time-to-insight.
• Why boutique systems cannot scale adequately to Big Data.
• What organizations can do to move from data silos to leveraging data assets across a variety of decisions and actions.
• The need for distributed and elastic data environments.
The paper concludes with a description of the key technology components and capabilities that will help organizations derive the most value from Big Data.
www.fico.com Make every decision countTM
New Approaches to Extracting Greater Decision Power from Big Data

©2014 Fair Isaac Corporation. All rights reserved. page 2
Pundits, technologists, C-level executives and everyone else seem to have something to say about Big Data these days, not to mention a strong financial interest. Investors are flocking to Big Data infrastructure, and to Big Data analytics providers, as more customers adopt distributed storage solutions like Hadoop to complement or replace existing data repository architectures. In fact, it’s the investments in Big Data analytics that highlight an important, yet often overlooked reality of Big Data—any data storage and retrieval solution may solve a data deluge challenge, but it doesn’t inherently provide an organization with better intelligence and insight, or ultimately empower better decision making. In other words, regardless of the architectural solution a business chooses, these new technology infrastructure solutions—namely Big Data repository and query solutions—exacerbate a known data problem: businesses have terabytes and petabytes of data and they don’t know what to do with it. Data by itself is neither useful nor meaningful; so thus, creating new storage paradigms for more data is only useful if there is a good mechanism for searching and analyzing the additional data, and operationalizing the data insights.
Big Data has been defined by a dramatic uptick in the three V’s of data: Volume, Velocity and Variety. The 21st century economy produces increasing volumes of data. Transactional data from retail consumers; instrument data from mobile and wearable devices; and, sensor data from facilities, smart equipment, and networked infrastructure all contribute to the growing volumes that need to be managed. It is estimated that many of the collectable datasets are growing by over 50% every year, and that an increasing number of CIOs are storing millions of gigabytes of data (see Figure 1 above). Data management methods and infrastructures in most organizations are not designed to deal with the explosion in the amount, diversity and speed of new data.
New Approaches to Extracting Greater Decision Power from Big Data
So Much Data, So Little Value
19%of CIOs (almost 1 in 5) store between 1 million and 499 million gigabytes of data
37% of CIOs store between 500,000 and 1 million gigabytes of data
How Much Data Organizations Currently Store
FIGURE 1: EXPLOSION IN ENTERPRISE DATA
Source: Storiant
©2014 Fair Isaac Corporation. All rights reserved. page 3
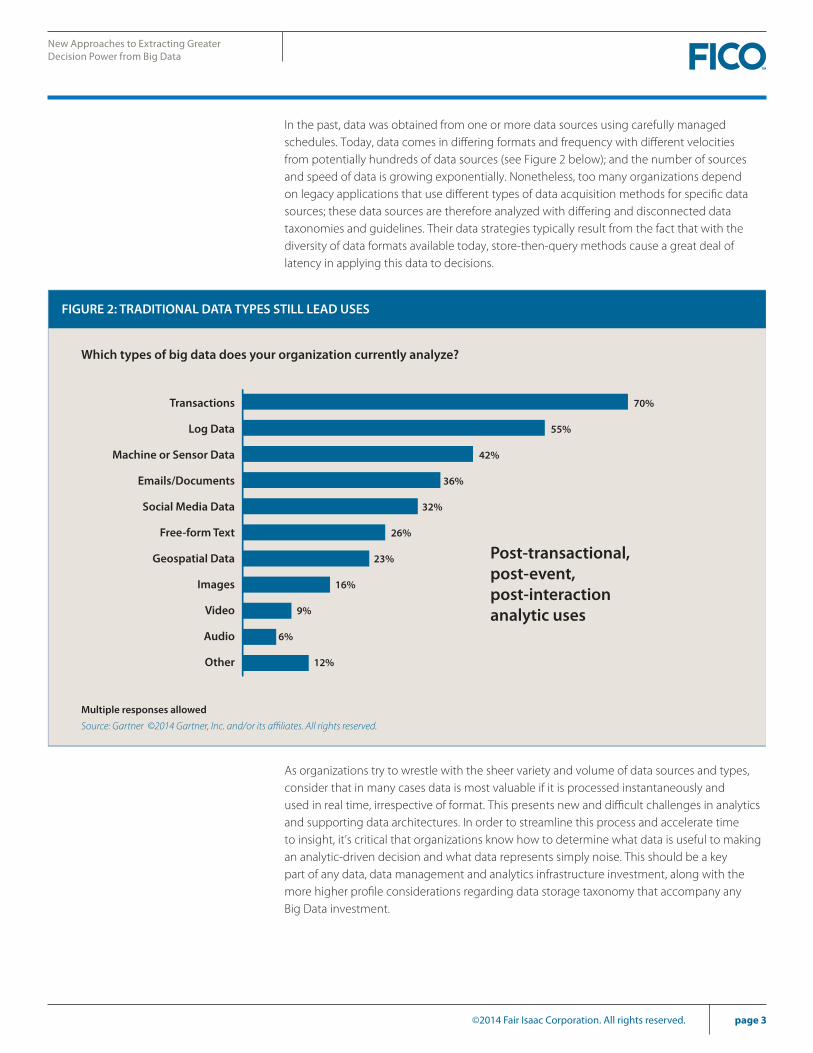
In the past, data was obtained from one or more data sources using carefully managed schedules. Today, data comes in differing formats and frequency with different velocities from potentially hundreds of data sources (see Figure 2 below); and the number of sources and speed of data is growing exponentially. Nonetheless, too many organizations depend on legacy applications that use different types of data acquisition methods for specific data sources; these data sources are therefore analyzed with differing and disconnected data taxonomies and guidelines. Their data strategies typically result from the fact that with the diversity of data formats available today, store-then-query methods cause a great deal of latency in applying this data to decisions.
As organizations try to wrestle with the sheer variety and volume of data sources and types, consider that in many cases data is most valuable if it is processed instantaneously and used in real time, irrespective of format. This presents new and difficult challenges in analytics and supporting data architectures. In order to streamline this process and accelerate time to insight, it’s critical that organizations know how to determine what data is useful to making an analytic-driven decision and what data represents simply noise. This should be a key part of any data, data management and analytics infrastructure investment, along with the more higher profile considerations regarding data storage taxonomy that accompany any Big Data investment.
New Approaches to Extracting Greater Decision Power from Big Data
Transactions
Log Data
Machine or Sensor Data
Emails/Documents
Social Media Data
Free-form Text
Geospatial Data
Images
Video
Audio
Other
70%
55%
42%
36%
32%
26%
23%
16%
9%
6%
12%
Which types of big data does your organization currently analyze?
Multiple responses allowed
Source: Gartner ©2014 Gartner, Inc. and/or its affiliates. All rights reserved.
Post-transactional, post-event, post-interaction analytic uses
FIGURE 2: TRADITIONAL DATA TYPES STILL LEAD USES

©2014 Fair Isaac Corporation. All rights reserved. page 4
Before an organization considers how it can create insights from data, several transformational steps are essential for making sense of and aligning the right data for the analytical inquiry. With so much data coming in so many forms and from so many sources—structured, unstructured, text, video, audio, machine-created, opted-in, confidential, streaming, at rest, batch and more—determining what data has value presents challenges. Of course, data value is also a relative proposition. But all organizations can value data by certain common measures. One is how rapidly it can be processed for analysis.
Data needs to be processed in various speeds in order to analyze it for value. In some cases, data value is measured by the speed by which it can be processed. If the process has too much latency, the data has lesser or little value. The approach to addressing this problem can be solved in two ways:
1. Filter and correlate all the data, then store and process it later by leveraging a larger and larger Hadoop cluster; or
2. Process the stream in real-time and cull only the data that you need before you store and model it for a decision.
The first method can be slower and more costly as time and resources are applied to data noise —data unnecessary for analysis. In addition, rapidly growing data volumes could exacerbate the problem of increasing and storing the amount of data that have negligible value.
The second method, the stream processing approach, is considerably more difficult, but it increases the decision value of the data, since data can be ingested, combined and enriched to improve how it is applied to solve real business problems. This approach also greatly lowers data latencies while improving time to insight by eliminating the problem of storing data that may have little or no value in the end decision.
The stream processing approach also allows organizations to continuously derive value from varied data sources and use them both proactively and reactively in decisions. Given the vast and ever-growing nature of data, it is challenging to evaluate, analyze or manually process every data set for its potential value in a decision. Today it is a challenge that data scientists, analytic scientists or anyone trying to make sense of enterprise data faces. Boutique approaches adopted by these scientists do not scale and therefore do not improve the time it takes to make a decision. An increase in data format and source varieties suggests that concurrent and real-time processing of the data stream is the optimal solution. Extracting value in data using such methodologies also lightens the burden on the data store, data scientists, frontline managers while simultaneously speeding time-to-insight. As such, creating the best analytic models or predictive insights is, in many ways, the more impactful approach to evolving analytically driven decision management.
New Approaches to Extracting Greater Decision Power from Big Data
It is not as if businesses have suddenly started to make “data-driven decisions.” Organizations across multiple industries have been using data to make many different kinds of decisions. Over 60% of organizations1 acknowledge that the ability to leverage data confers a distinct competitive advantage. But that doesn’t mean that the age of Big Data automatically guarantees better decision making.
In fact, the expression “Big Data” harbors both promise and confusion. What is important to remember is that Big Data is not very useful without the ability to rapidly collect it, analyze it, determine optimal actions from it and ultimately execute decisions with it. Yet, it is estimated that most organizations are only able to derive real value from approximately 12%2 of the data available to them. This is due to a variety of challenges that make it difficult for most organizations to bring this to fruition.
A Proper Perspective on Data and Big Data
Determining What Data Has Value
1 The Economist: Intelligence Unit report, Big Data and the Democratization of Decisions, 2012
2 Forrester Research data usage survey

©2014 Fair Isaac Corporation. All rights reserved. page 5
However, in what other ways do businesses typically value data? The answer to this question explains why many organizations’ current approaches to data acquisition, storage and analysis exist in disparate silos. Data value changes across the organization depending on who’s using the data, what they’re trying to achieve and when the data is analyzed.
Who is looking for insights? Data is collected and analyzed by siloed business functions in most organizations, with little (if any) consideration of how the collected data will serve overarching business goals. For example, marketing data is often not collected in correlation with sales data, supplier data or customer use data.
What kinds of insights are being explored? Analysis bias is particularly prevalent in siloed organizations. For example, marketing teams may only be interested in website usage data and not make a natural connection to product shipping times associated with manufacturing defects. That’s why the most valuable analytic models account for and weight relevant data sets not only across an organization, but also extra-company data when possible.
When is data analysis performed, and is it adaptive to rapid real-time changes? During the past several years, businesses have created data marts (defined as snapshots of larger data warehouses) to analyze historical patterns in order to predict future behaviors. There were many reasons to create data marts:
• Logistically it was difficult to continue collecting data while also analyzing the data.
• It was impossible to run analytics against large databases and return results in a timely manner.
• The necessary computational systems required to run the analytics exceeded what was available to most organizations.
Eliminating data silos is an essential step in becoming an analytically powered business. However, connecting storage arrays or linking business intelligence tools to larger data sets is only part of the challenge. Organizations also need to address multiple data types and requirements—for example, intermingling streaming data, unstructured data and batch data. Few organizations can quickly, easily and cost effectively address these technical and analytic hurdles.
Consider that data often exists in a patchwork of vendor-supplied solutions. Big Data automation requires a multi-pronged approach to acquire, implement and stitch together a variety of data integration solutions. No single existing solution tackles all the key challenges, requiring organizations to acquire multiple solutions that need to be staffed, implemented and operationalized, adding significant overhead that can potentially outweigh the benefits of developing a Big Data solution.
Another challenge is migrating disparate data and other data sources to a distributed data environment like Hadoop. In most cases, it’s not and it shouldn’t be an either/or architectural decision. Any new architectural decision is an incremental one. Often, maintaining a traditional RDBMS or batch storage environment in addition to a more optimized Hadoop Distributed File System (HDFS) solution may be preferable. Similarly, it’s important to consider analytic methodologies that are data repository/data type agnostic and can use whatever data is most relevant to the decisions that need to be made.
Adopting a distributed data architecture isn’t a panacea, however. Many data challenges transcend architectures and are too often lost in Big Data discussions. Most businesses have significant data and analytic challenges not easily resolved merely with infrastructure investments. These include:
New Approaches to Extracting Greater Decision Power from Big Data
A Legacy of Data Silos and Conflicting Data Values
Breaking Down Data Silos (And Other Challenges Facing an Analytically Driven Business)

©2014 Fair Isaac Corporation. All rights reserved. page 6
Data Rich, Decision Poor: Industries such as financial services, health care, pharmaceuticals and biotechnology have long relied on bringing together diverse data to make decisions, investing heavily in resources to improve data quality and/or veracity. Even with the best cleansing methods, however, data’s innate unpredictability limits the success of unifying the disparate data sources. Unification of this data requires correlation across many data sets to mine for patterns and turn raw data into “decision-ready data.” As a result, organizations often exclude uncorrelated data from their decisions.
For example, a recent executive survey3 revealed that most unstructured data is untapped and not used in the decision-making process. Deriving value from these datasets is difficult and, for many organizations, there is virtually no way to tie the datasets to more structured data. Nevertheless, many of these datasets contain valuable nuggets, and simply not dealing with them makes organizations less able to extract insights and enrich their decisions.
Smart Data, In-House Solutions and the Shortage of Skilled Talent: Even in organizations that have streamlined data acquisition processes, incorporating the data into decisions is hard. Data often needs to be transformed and analyzed by a skilled analyst or a data scientist in a separate application space. This reliance on specialized yet scarce skills contributes to the latency of identifying a timely data-driven decision.
Every organization with a Big Data effort has scientists building in-house solutions to turn raw data into “Smart Data,” which is critical in extracting insights or making key decisions. But these internal solutions are largely limited to boutique scale, and are insufficient for turning Big Data into Smart Data across the organization. While skilled data scientists are growing in numbers, their adoption will never occur at a rate that would enable organizations to become pervasively Smart Data-driven—there just aren’t enough of these resources to go around.
Real-Time Decisions: Most organizations today use descriptive analytics to analyze historical data without a forward-looking view. Typically, the use of this historical data occurs only after data has been ingested and stored, resulting in delays. This delay is insufficient for real-time decisioning and applying more advanced predictive and prescriptive analytics. Applications such as systems monitoring, intrusion detection, fraud detection and patient monitoring require constant polling for information that will alert to a change event. The lack of smarter real-time data processing impacts everything from accurate and up-to-date reporting, managing and responding to fraud and meeting regulatory compliance. Many of these impacts result in significant losses that make it harder to recover from or stay ahead of the consequences.
Elastic Solutions: While some data flows and business processes are reasonably well-defined and predictable, consumer activity, regulatory and economic shifts, and other factors can cause data volumes to dramatically increase—often well beyond organizations’ ability to invest the time and resources needed to address the fluctuations. Processing decision-ready data when it is needed, regardless of its volume or velocity, requires data-powered solutions capable of intelligent expansion without human intervention.
Interoperability: Diverse, proprietary solutions either take too much effort to integrate or remain untapped. Recent technologies are agnostic to data sources, but still require bespoke integration efforts with downstream applications. The ability to quickly and easily connect to applications and data sources is critical in handling Big Data’s high volume and real-time velocity of new data, as well as rapidly integrating new applications that can immediately fuel new data-driven insights.
New Approaches to Extracting Greater Decision Power from Big Data
3 The Deciding Factor: Big Data & Decision Making, Economic Intelligence Unit, 2012

©2014 Fair Isaac Corporation. All rights reserved. page 7
Today’s Big Data technologies can help organizations transform data to decisions, but not fast enough. New data solutions have recently emerged that can effectively address data acquisition and manage the wide variety of structured and unstructured data from both batch and streaming sources. However, while these solutions have resolved many data acquisition challenges, organizations still struggle to make data usable immediately across a wide variety of decisions.
The lack of availability of decision-ready data remains a critical bottleneck in most organizations. Solutions that improve decision time-to-value will yield significant value and competitive advantage to the organizations that adopt them. In order to optimize data ingestion to support the broadest range of data sources to best inform analytic powered decisioning, several solution capabilities and requirements are essential:
Unified Acquisition Modes: Solutions that generate decision-ready data require multiple data acquisition modes. Data sources may offer their data periodically as batched files of large collections of data, or streamed asynchronously and perpetually. Solutions that target either one of these modes independently limit organizations’ ability to collect valuable data from additional data sources. Organizations need a single solution for handling data irrespective of how it is collected and/or streamed in order to maximize the value of the data.
Stream Processing: While batch data retains value within specific use cases, it is generally limited in its ability to process just-in-time and ready-when-event data. New and emerging use case solutions require the collection and analysis of a continuous collection of streaming data. Stream processing—the analysis of data in almost real-time as it is gathered—offers numerous benefits that greatly expand the ability to deliver decision-ready data in an efficient, timely and varied manner. Streams enable always-connected customers to stream their data while allowing the consuming solutions to obtain and analyze events in almost real-time. Moreover, streams allow the ingestion of unfiltered raw data from many sources, which can then be effectively filtered and correlated to minimize data that needs to be stored and batched.
Multiple Data Sources: Partly due to the use of batched data from providers and the costs and difficulty of onboarding and marshaling new data sources, legacy solutions are limited to consume data from a few data sources. Today, data is everywhere and businesses need ways to quickly ingest data in a variety of ways and from multiple data sources. While applications typically need a dedicated and stable data source, some may require or benefit from the use of other data sources. In addition, multiple applications may need to share a single data source. A solution that can manage a large number of data sources across myriad applications, and deliver the data ready for consumption to those applications, is a critical component of a Big Data decision strategy.
Distributed Processing and Storage: In terms of reducing capital and operational costs, providing decision-ready data from many data sources can be realized with-well designed distributed processing and storage architectures. Traditional vertical scaling compute solutions typically deliver high performance, but tend to be proprietary and expensive. A more practical solution for Big Data consists of horizontally scaled and clustered compute architectures. With distributed processing and storage solutions, capital costs grow linearly with increased volume and velocity of data, while operational costs remain fairly constant. Moreover, such methods may provide additional value in redundancy, resilience and fault-tolerance.
Value Extraction: Increased data volume can translate to increased noise—namely redundant or irrelevant data. Valuable information is typically hidden in data and has to be identified and enhanced before it can be consumed in decisions. Simply dealing with large amounts or varieties of data alone is a step in the right direction; however, the real value is in translating and extracting noisy data. As such, the right technology needs to be in place to intelligently filter and analyze data to continuously create decision-ready data.
New Approaches to Extracting Greater Decision Power from Big Data
Building for the Future of “Big Data”

New Approaches to Extracting Greater Decision Power from Big Data
For more information North America Latin America & Caribbean Europe, Middle East & Africa Asia Pacificwww.fico.com +1 888 342 6336 +55 11 5189 8222 +44 (0) 207 940 8718 +65 6422 7700 [email protected] [email protected] [email protected] [email protected]
FICO and “Make every decision count” are trademarks or registered trademarks of Fair Isaac Corporation in the United States and in other countries. Other product and company names herein may be trademarks of their respective owners. © 2014 Fair Isaac Corporation. All rights reserved.
4064WP 10/14 PDF
Data Fusion: Differentiating what’s decision-ready and what’s not comes from quickly aggregating and correlating data across periods of time and across multiple data sources. Solutions that deliver a variety of data values need to fuse data from many sources over any period of time. This requires correlating disparate data and using complex event processing to identify intricate patterns in temporal and attributed streams.
Data Normalization: Multiple data sources introduce myriad data formats, schemas and levels of usability. While upstream systems offer data sources with structured, formatted and well-defined schemas and values, human-generated data is typically unstructured or semi-structured. Solutions that fuse data from many sources and extract value need to generate decision-ready data that is normalized when needed. In this case, normalized data must include automatically generated annotated metadata. This metadata also needs to be normalized based on well-defined nomenclatures and taxonomies.
Text Analytics: In the process of extracting value from unstructured data generated by humans (as opposed to machines), data fusion and normalization will depend on the use of text analytics to extract key entities, relationships, contexts and sentiments. Solutions that provide in-stream text analytics can greatly enhance the value of the decision-ready data. This will also dramatically impact the utilization rate of existing data that today exists as unparsable, unstructured data.
Data has been called the fourth factor of production, as essential as land, labor and capital. Big Data is not new to many organizations, yet efforts remain mired in multi-year roadmaps resulting in delays in time-to-value of this asset. As a long-time industry leader and innovator in predictive and prescriptive analytics, as well as in Decision Management, FICO is keenly aware of the ongoing data challenges facing its customers. As one of the only analytics vendors focused on operationalizing data intelligence, FICO understands that it is critical to be able to quickly ingest, identify and optimize data streams for use in decision management solutions. Since FICO and many of its customers don’t own the data necessary to make the ultimate analysis and decisions, providing solutions that connect to and are optimized for the broadest range of data inputs is vitally important. Addressing the latencies between ingesting data and analyzing best outcomes has long been a challenge that the company has invested significant time and resources in solving. As such, FICO has compiled a significant amount of intellectual property to address data connections, ingestion, streaming analytics and data processing.
By focusing on delivering a data connection and processing solution, FICO can help ensure that any customer with a data challenge can seamlessly connect to and analyze data in the fastest and most meaningful manner. This will ultimately mean that customers can use FICO Data Management solutions to:
• Become more decision-ready, agile, customer-centric and ultimately reduce losses by making better decisions faster.
• Better leverage resources—IT infrastructure, analytic systems, decision-making and specialized data and analytics knowledge—throughout an organization.
• Optimize usage of existing data-at-rest technologies.
• Elastically and more cost-effectively scale out solutions based on demand across a variety of analytics and decisions.
Delivering on a Prescriptive Analytic Promise