neural networks and backpropagation sebastian thrun 15-781, fall 2000
TRANSCRIPT

Neural Networks andBackpropagation
Sebastian Thrun
15-781, Fall 2000

Outline
Perceptrons Learning Hidden Layer Representations Speeding Up Training Bias, Overfitting and Early Stopping (Example: Face Recognition)

ALVINN drives 70mph on highways
Dean PomerleauCMU
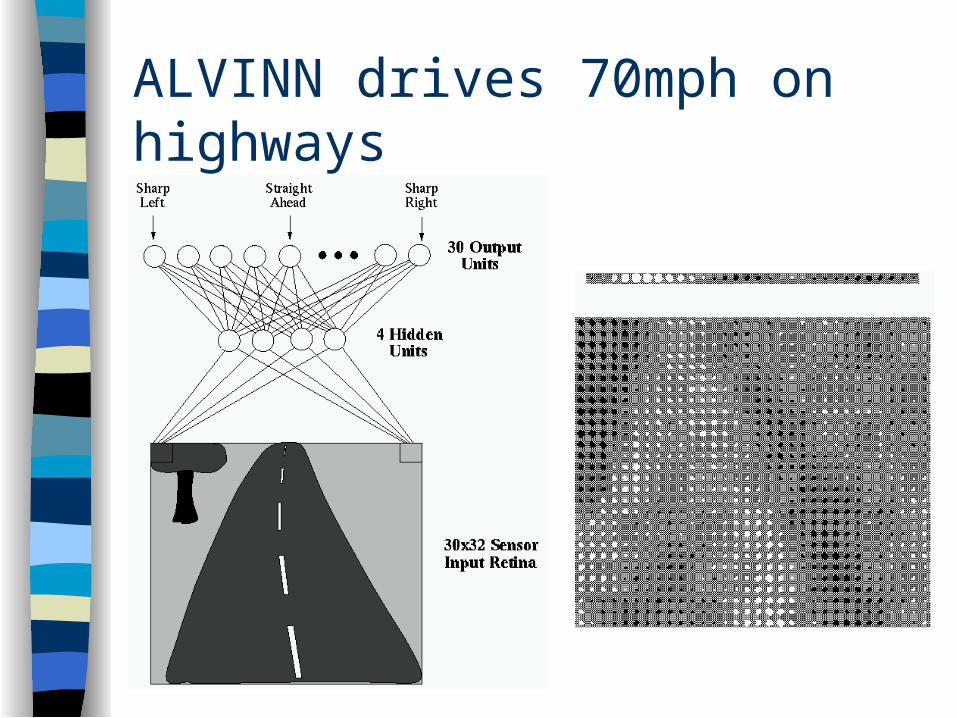
ALVINN drives 70mph on highways
Human Brain
Neurons

Human Learning
Number of neurons: ~ 1010
Connections per neuron: ~ 104 to 105
Neuron switching time: ~ 0.001 second Scene recognition time: ~ 0.1 second
100 inference steps doesn’t seem much

The “Bible” (1986)
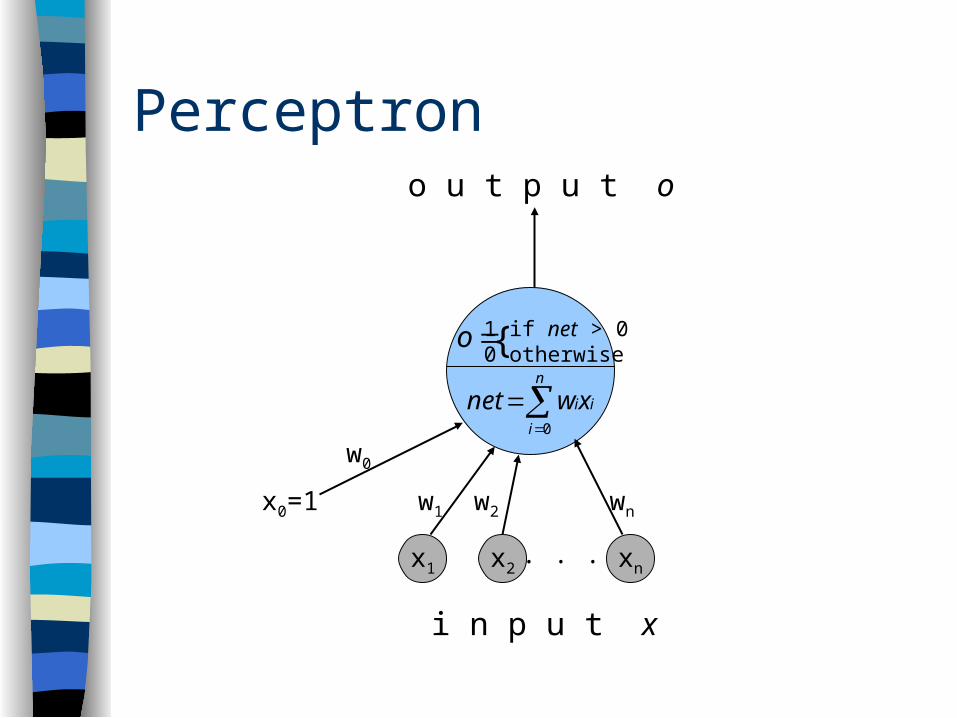
Perceptron
w2 wnw1
w0
x0=1
o u t p u t o
x2 xnx1. . .
i n p u t x
n
i
iixwnet0
o 1 if net > 00 otherwise{
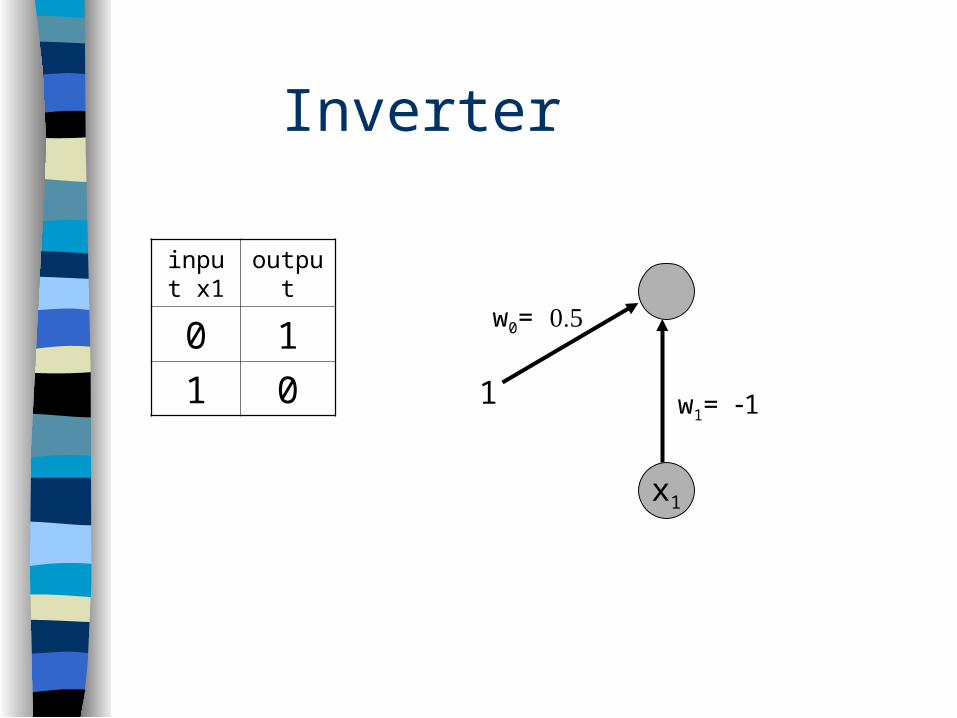
Inverter
input x1
output
0 1
1 0
x1
w1= 11
w0=
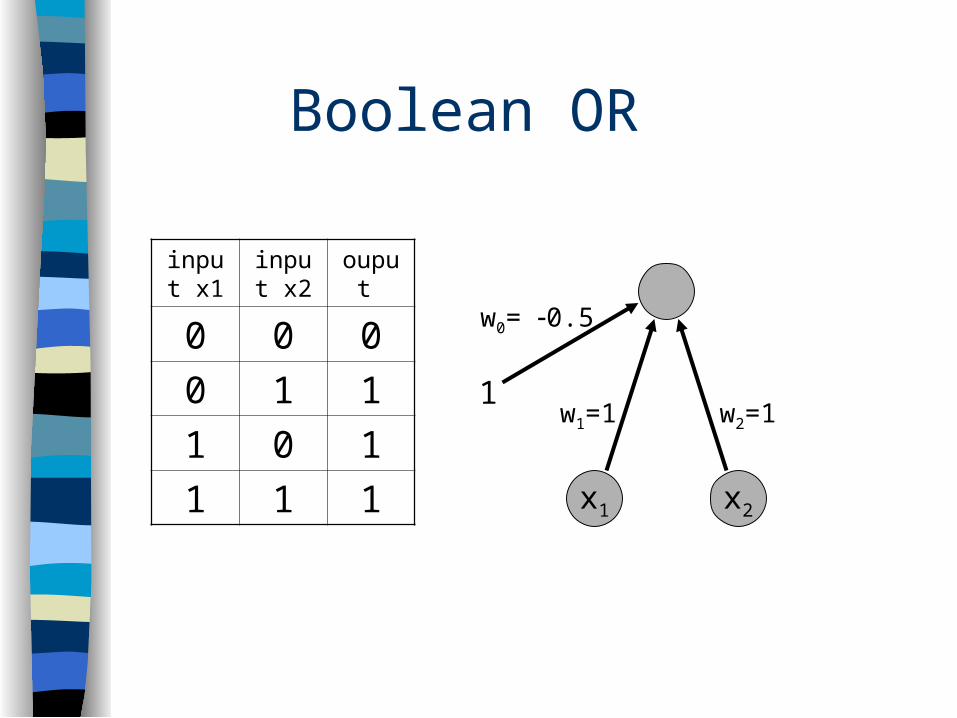
Boolean OR
input x1
input x2
ouput
0 0 0
0 1 1
1 0 1
1 1 1 x2x1
w2=1w1=1
w0= 0.5
1
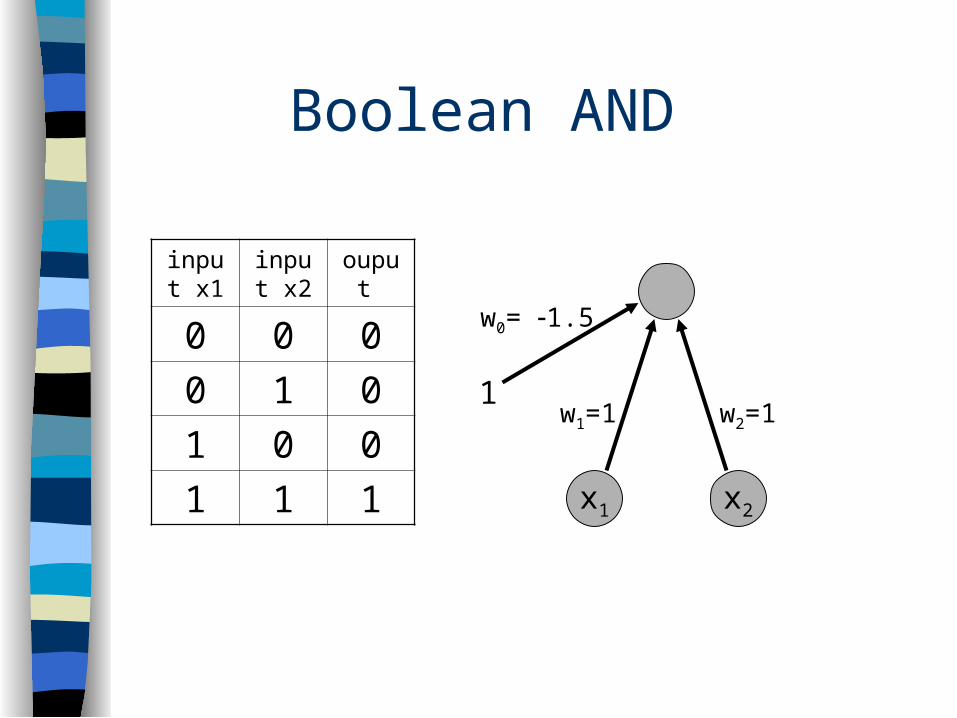
Boolean AND
input x1
input x2
ouput
0 0 0
0 1 0
1 0 0
1 1 1 x2x1
w2=1w1=1
w0= 1.5
1
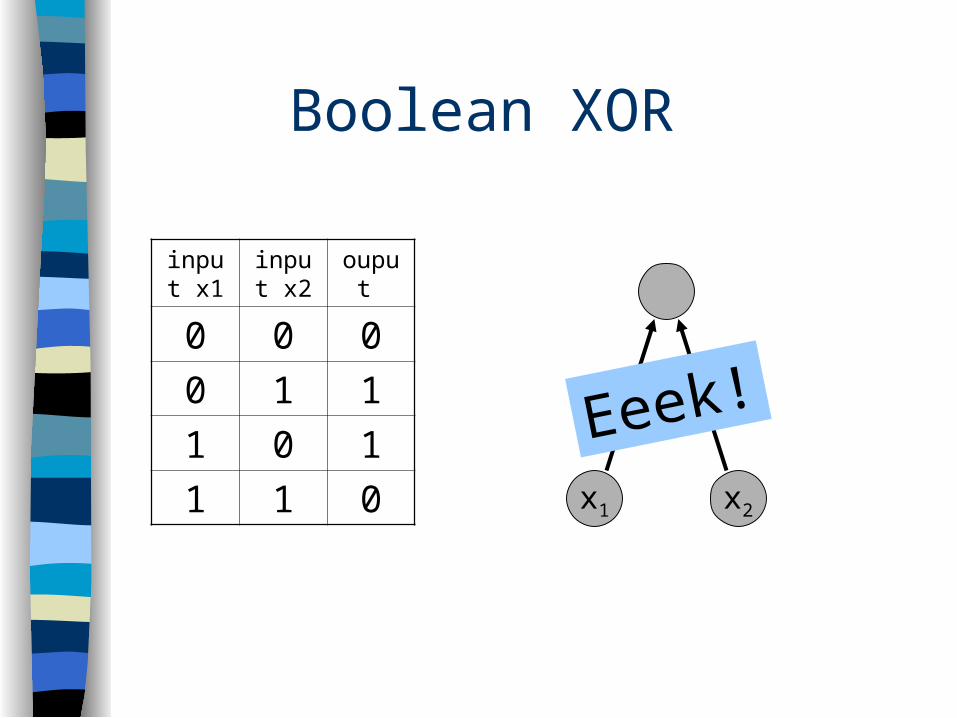
Boolean XOR
input x1
input x2
ouput
0 0 0
0 1 1
1 0 1
1 1 0 x2x1
Eeek!
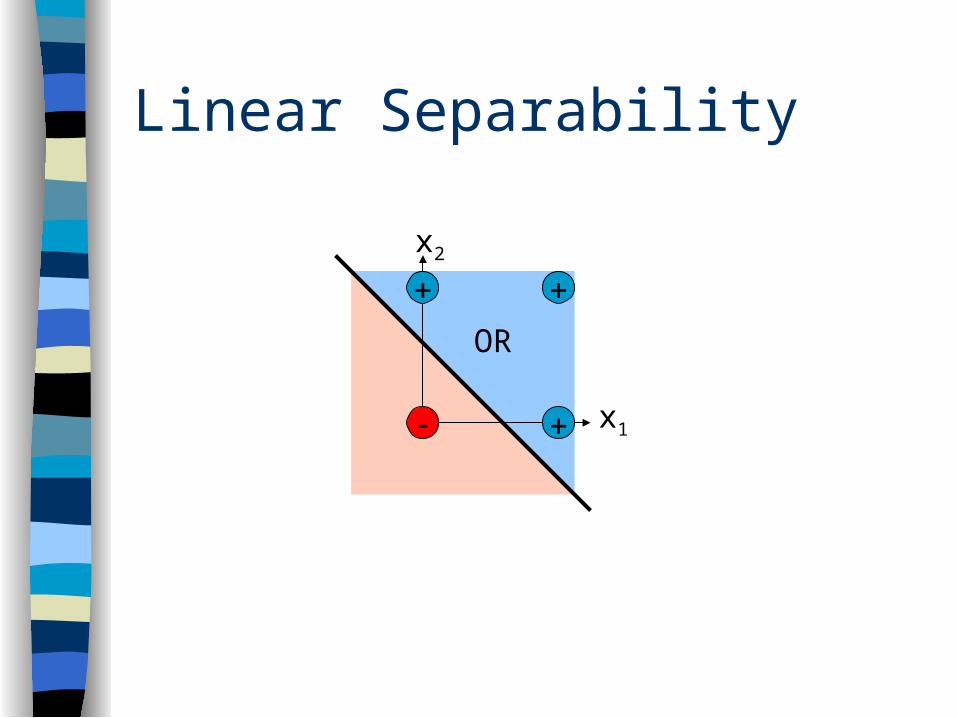
Linear Separability
x1
x2
OR
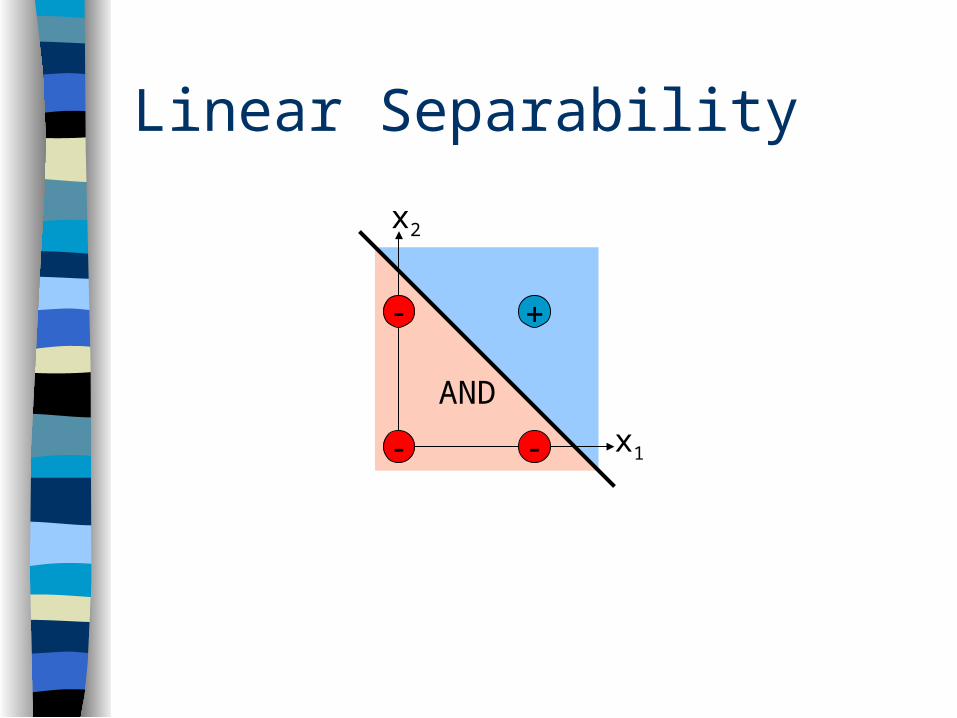
Linear Separability
x1
x2
AND
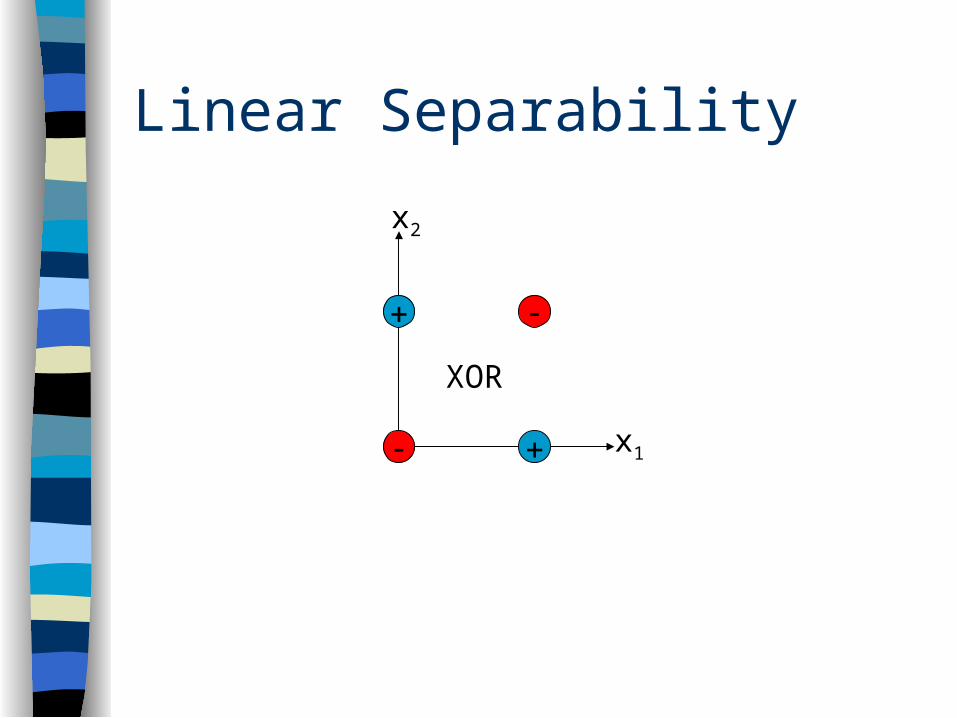
Linear Separability
x1
x2
XOR
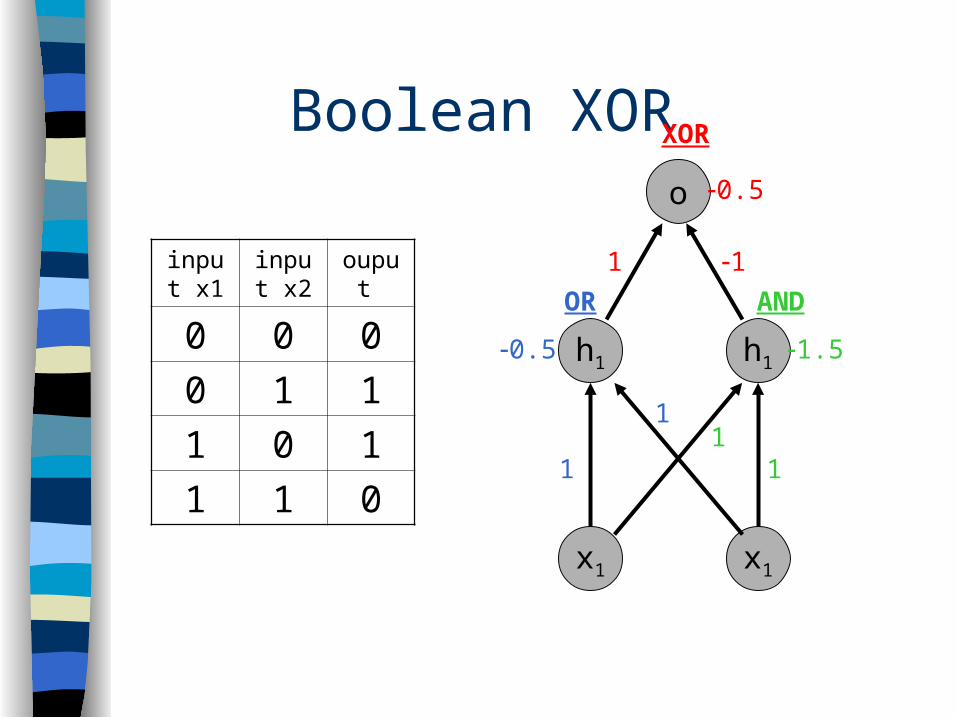
Boolean XOR
input x1
input x2
ouput
0 0 0
0 1 1
1 0 1
1 1 0
h1
x1
o
x1
h1
1
1.5
AND
11
0.5
OR
1
1
0.5
XOR
1

Perceptron Training Rule
iii www
ii xotw )(
step size
perceptronoutput
input
target
increment
new weight incrementold weight

Converges, if…
… training data linearly separable
… step size sufficiently small
… no “hidden” units
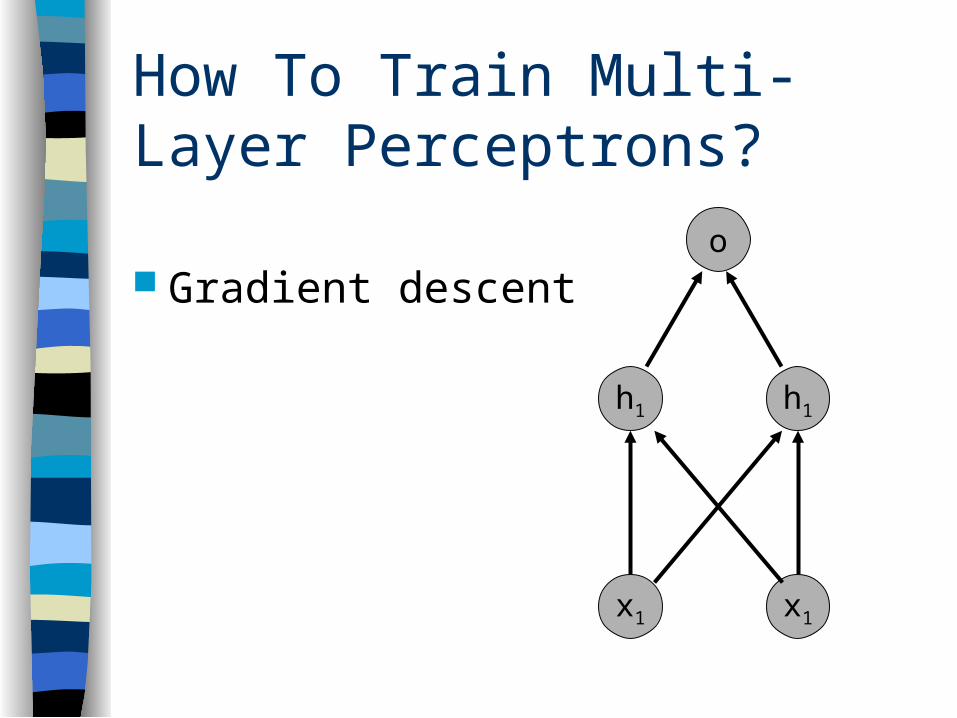
How To Train Multi-Layer Perceptrons?
Gradient descent
h1
x1
o
x1
h1
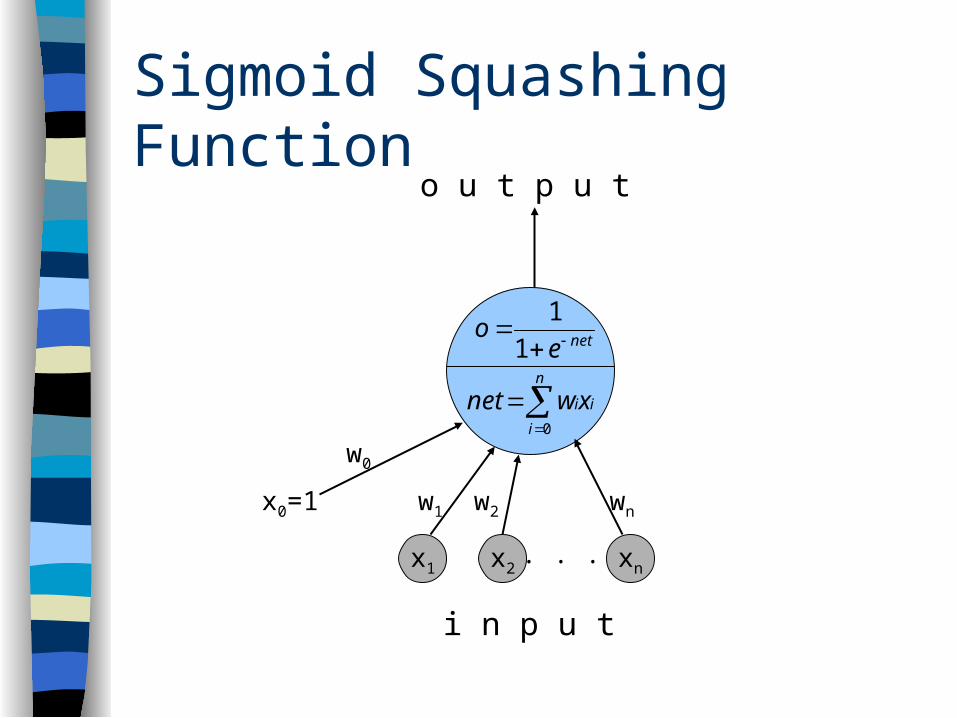
Sigmoid Squashing Function
w2 wnw1
w0
x0=1
o u t p u t
x2 xnx1. . .
i n p u t
n
i
iixwnet0
neteo
1
1
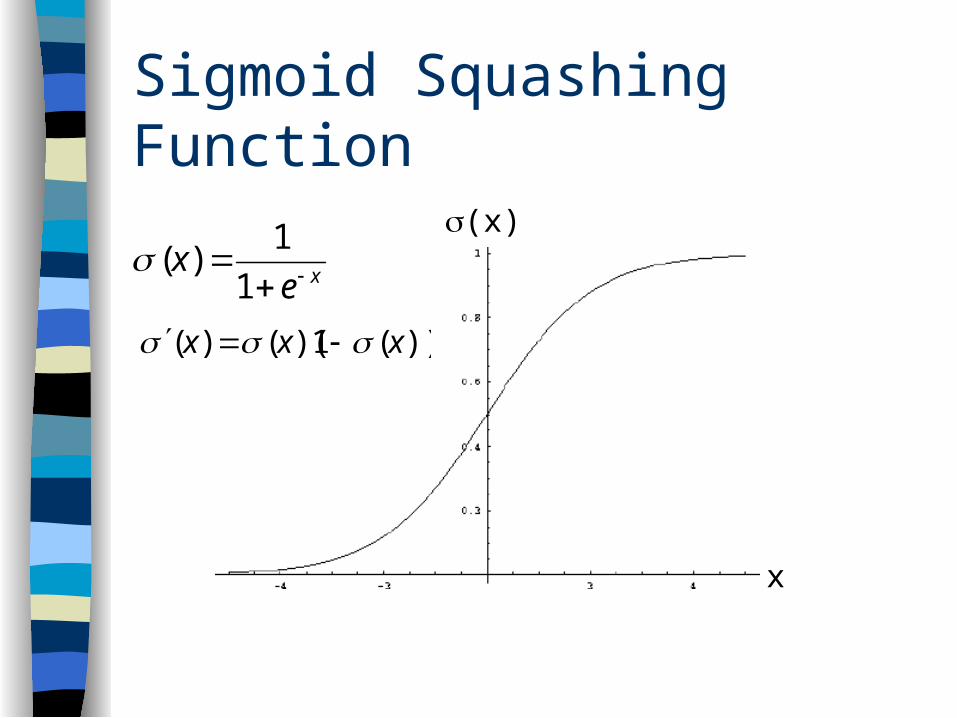
Sigmoid Squashing Function
x
(x)
xex
1
1)(
))(1)(()( xxx

Gradient Descent
Learn wi’s that minimize squared error
2)(2
1][
Dddd otwE
D = training data
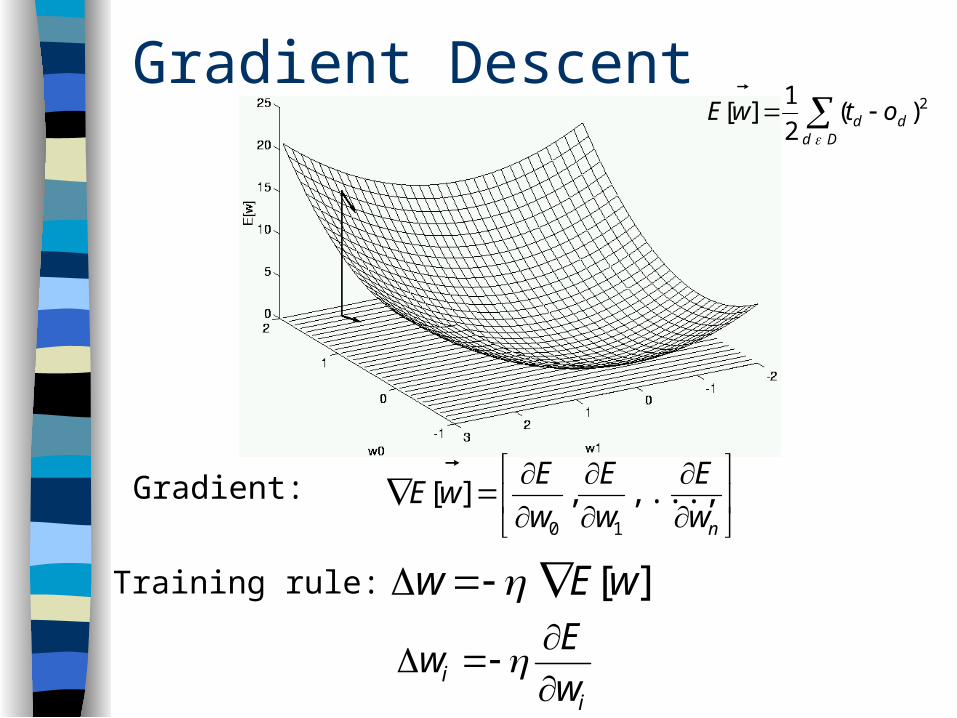
Gradient Descent
Gradient:
nw
E
w
E
w
EwE ,...,,][
10
ii w
Ew
Training rule: ][wEw
2)(2
1][
Dddd otwE

Gradient Descent (single layer)
diddd
dd
did
dd
ddd i
dd
ddd i
dd
ddd i
ddd
ii
xxwxwot
xww
ot
xwtw
ot
otw
ot
otw
otww
E
,
2
2
))(1()()(
))(()(
))(()(
)()(22
1
)(2
1
)(2
1

Batch Learning
Initialize each wi to small random value
Repeat until termination:wi = 0
For each training example d do
od (i wi xi,d)
wi wi + (td od) od (1-od) xi,d
wi wi + wi

Incremental (Online) Learning
Initialize each wi to small random value
Repeat until termination:For each training example d do
wi = 0
od i wi xi,d
wi wi + (td od) od (1-od) xi,d
wi wi + wi

Backpropagation Algorithm
Generalization to multiple layers and multiple output units

Backpropagation Algorithm
Initialize all weights to small random numbers For each training example do
– For each hidden unit h:
– For each output unit k:
– For each output unit k:
– For each hidden unit h:
– Update each network weight wij:
ijjij xw
i
ihih xwo )(
k
hkhk xwo )(
)()1( kkkkk otoo
k
khkhhh woo )1(
withijijij www
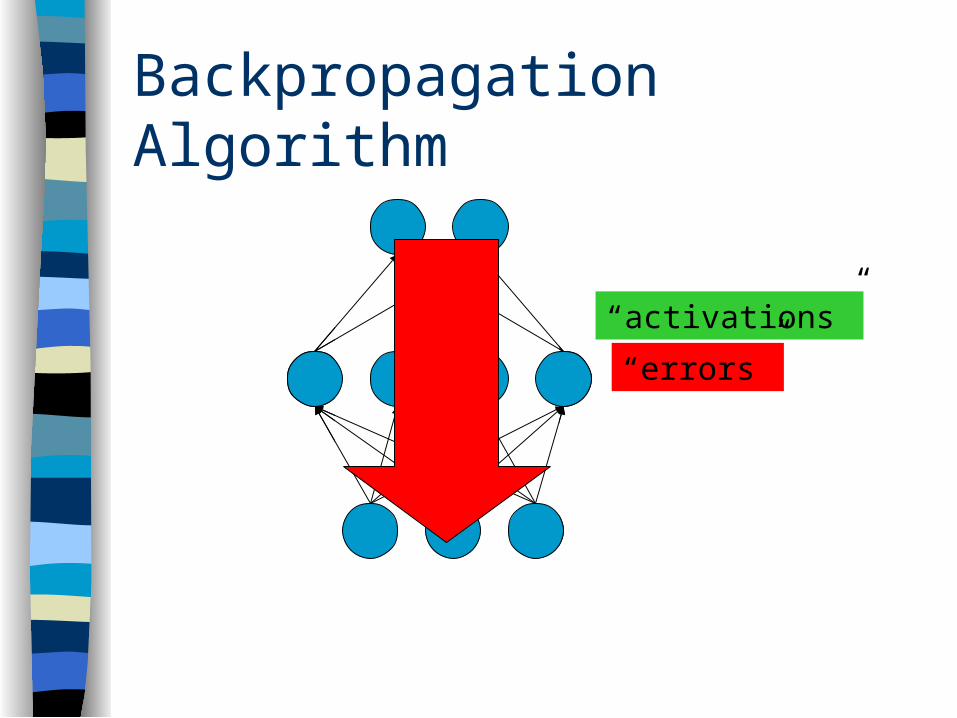
Backpropagation Algorithm
“activations”
“errors”
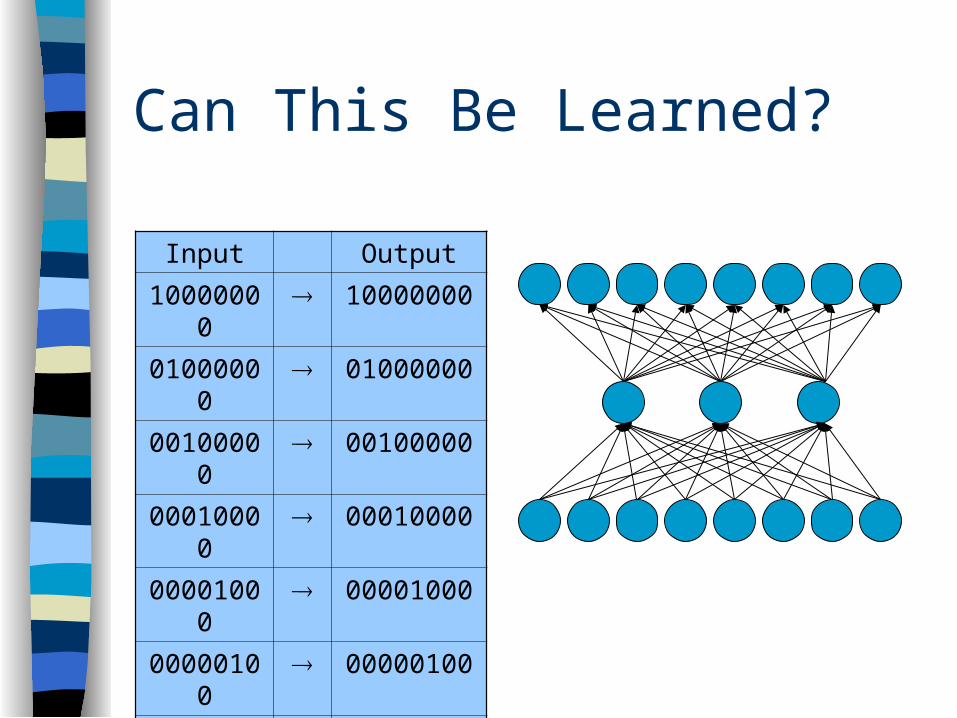
Can This Be Learned?
Input Output
10000000 10000000
01000000 01000000
00100000 00100000
00010000 00010000
00001000 00001000
00000100 00000100
00000010 00000010
00000001 00000001
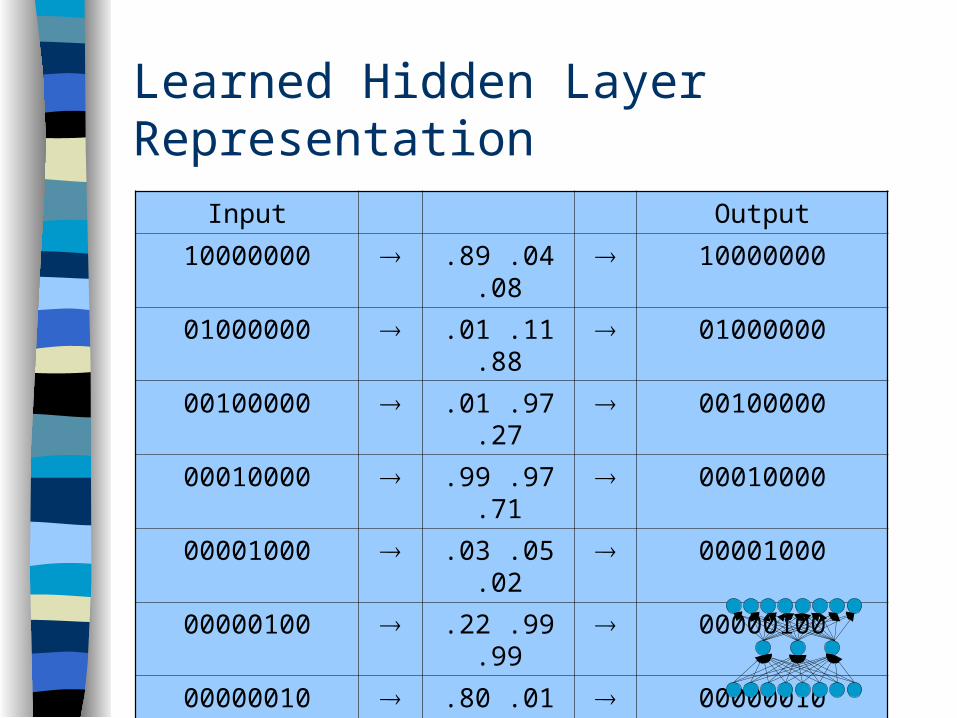
Learned Hidden Layer Representation
Input Output
10000000 .89 .04 .08 10000000
01000000 .01 .11 .88 01000000
00100000 .01 .97 .27 00100000
00010000 .99 .97 .71 00010000
00001000 .03 .05 .02 00001000
00000100 .22 .99 .99 00000100
00000010 .80 .01 .98 00000010
00000001 .60 .94 .01 00000001
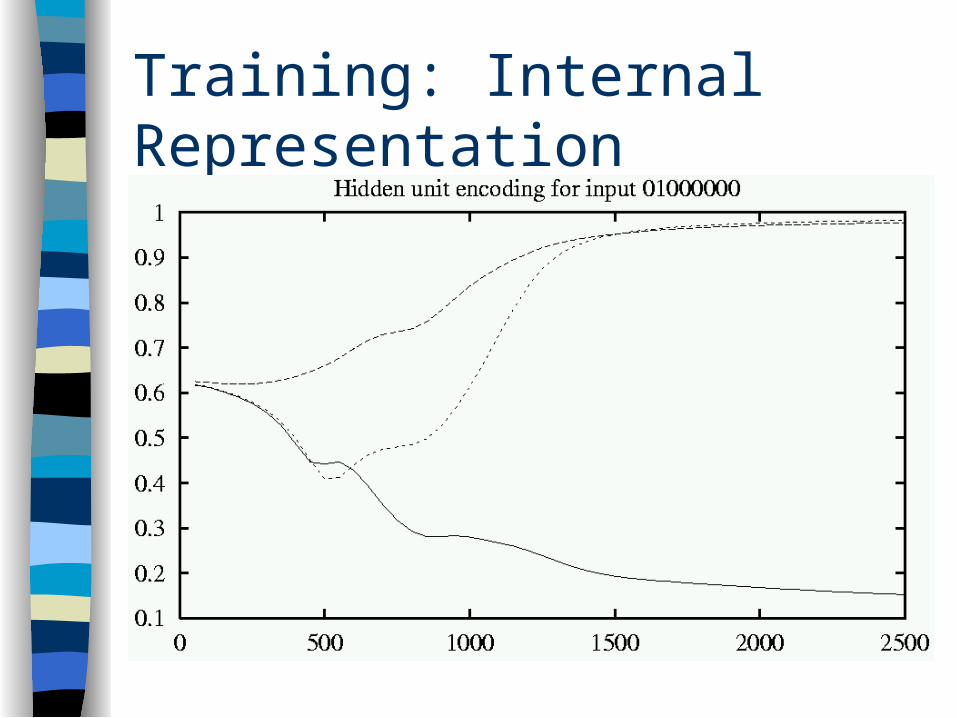
Training: Internal Representation
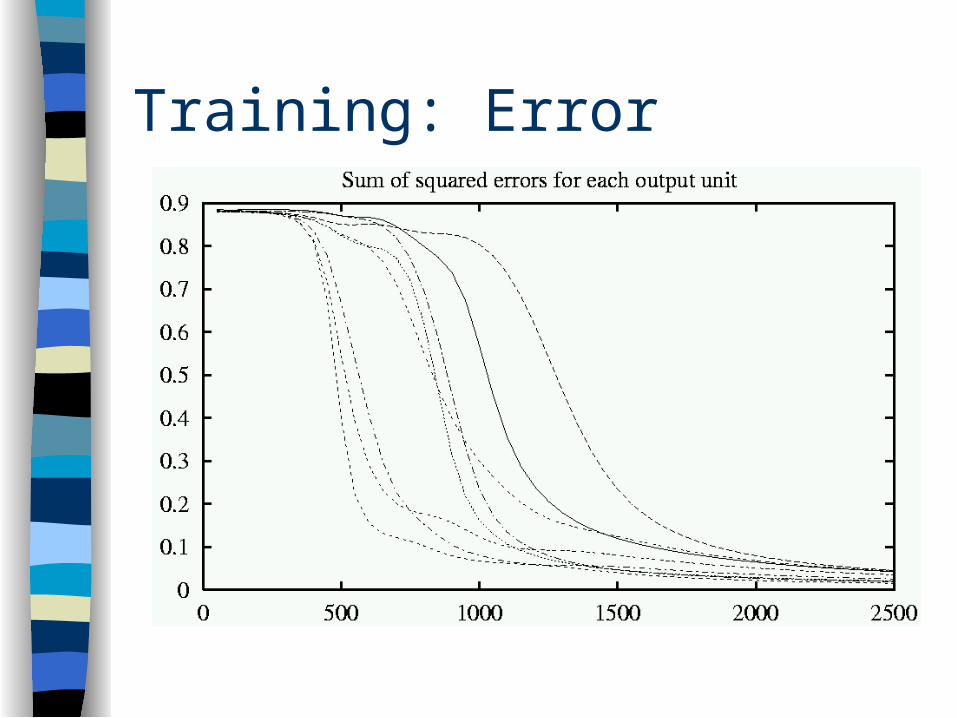
Training: Error
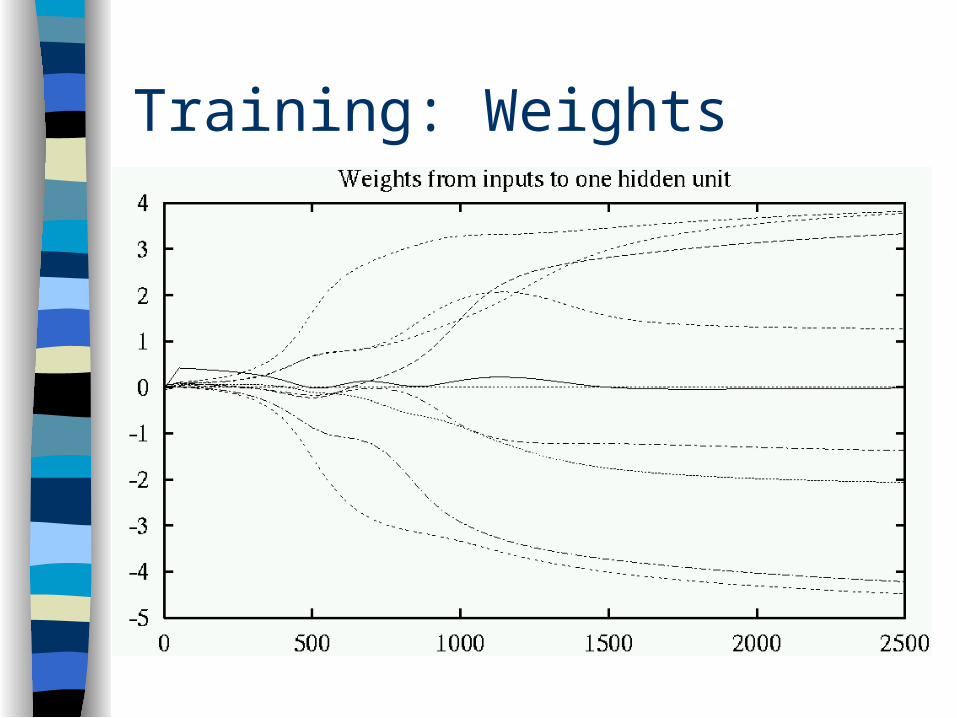
Training: Weights

ANNs in Speech Recognition
[Haung/Lippman 1988]
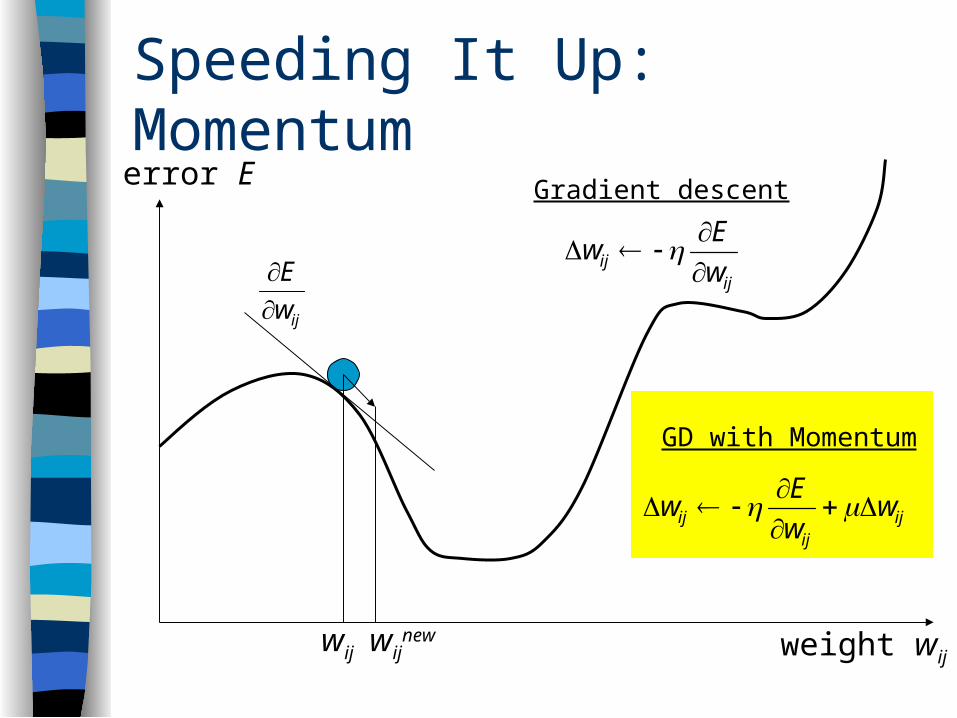
Speeding It Up: Momentumerror E
weight wijwij wij
new
ijw
E
ij
ij w
Ew
Gradient descent
ijij
ij ww
Ew
GD with Momentum

Convergence
May get stuck in local minima Weights may diverge
…but works well in practice
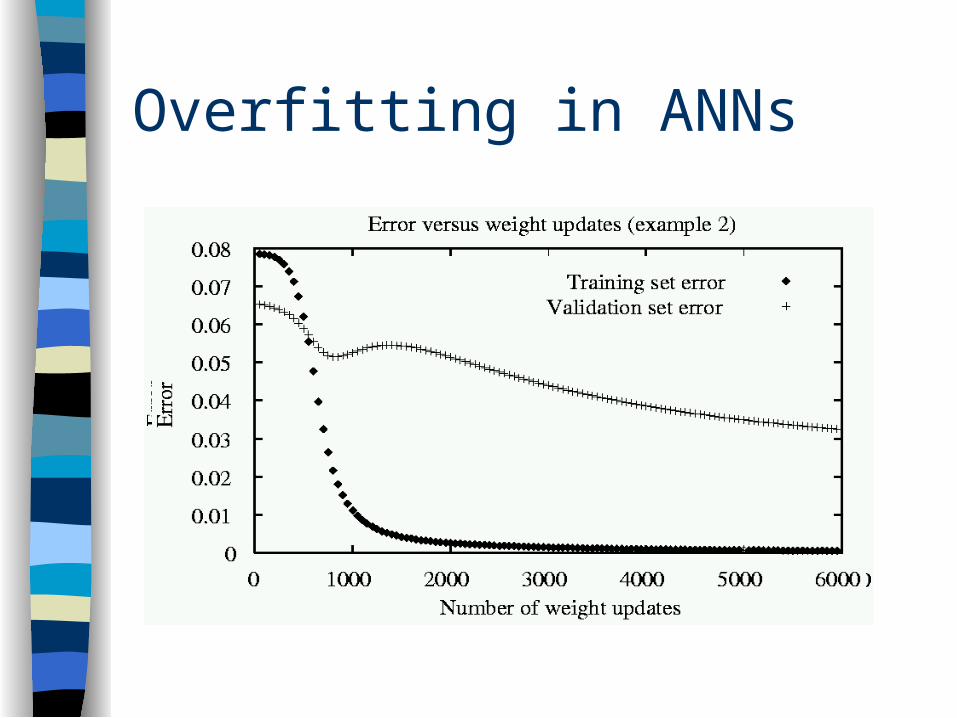
Overfitting in ANNs

Early Stopping (Important!!!)
Stop training when error goes up on validation set
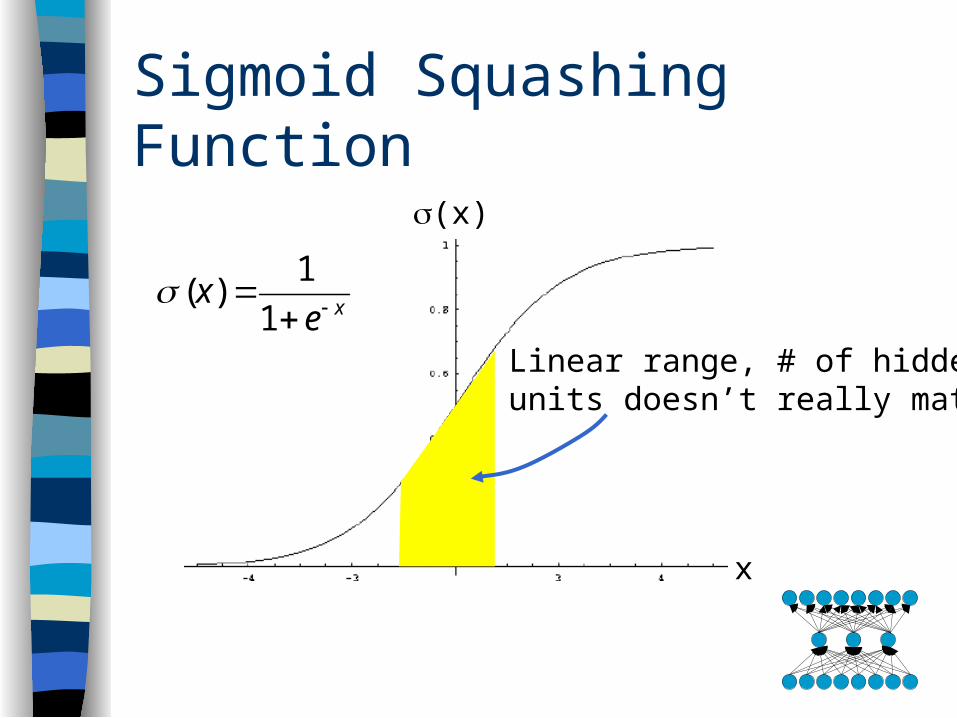
Sigmoid Squashing Function
x
(x)
xex
1
1)(
Linear range, # of hiddenunits doesn’t really matter

left strt right up
Typical input images
Head pose (1-of-4): 90% accuracyFace recognition (1-of-20): 90% accuracy
ANNs for Face Recognition

ANNs for Face Recognition
left strt right up
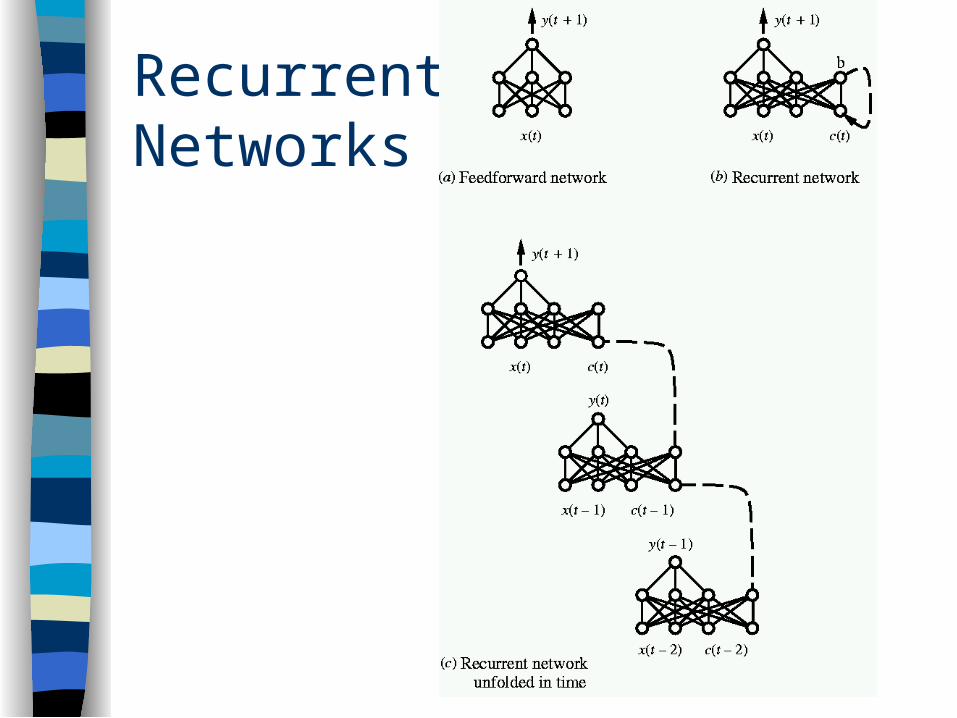
Recurrent Networks