national sun yat-sen university. system support for scalable, reliable and highly manageable...
TRANSCRIPT

National Sun Yat-Sen UniversityNational Sun Yat-Sen University

System Support for Scalable, Reliable and Highly Manageable Internet Services
Chu-Sing Yang
Department of Computer Science and EngineeringNational Sun Yat-Sen University

3
OutlineOutline
Introduction Proposed System
– Request Routing Mechanism– Management System
Content-aware Intelligence Work in Progress Conclusion

4
BackgroundBackground
The Internet has become the most important client-server application platform
More and more Internet services emerge The trend toward exponential growth of Internet users
at higher speed continues The Internet is becoming a mission-critical business
delivery infrastructure The desire for using the Web to conduct business
transactions or deliver services is increasing at an amazing rate.
Huge demand for high performance, scalable, highly reliable Internet servers
5
Meeting the challengeMeeting the challenge
New Moore’s law?– Servers capacity doubles every 18 month for meeting the
explosive growth
Providers increase the network capacityMore users,
more demand,
faster modems
More contents, more servers,
faster feeds

6
Web has new requirementsWeb has new requirements
Before An economical platform for
Information sharing and publish (non-critical information)
90 percents of information represented by text and images
Unfrequent maintenance and updates
Security is not important No guarantee on service
availability Highly available performance
Now An important platform for
critical services More sophisticated content,
e.g., larger percentage or dynamic content or streaming data
Content change frequently Security becomes great
concern Companies are evaluated even
on the basis of their websites Explosive growth of user
population

7
Meeting the challengeMeeting the challenge
The first-generation Web infrastructure was never designed to handle the unique traffic patterns of the Web, which today accounts for 80% of Internet usage.
Most current medium & large Web service providers are suffering from server overload– Yahoo, Google, Altavista, CNN, Microsoft,….. – A single monolithic server system is difficult to cope with these
challenges.
We need a scalable Internet Service Architecture guaranteeing the service expectation of all Web service
s!

8
Essential Requirements of Internet Server Essential Requirements of Internet Server
High Performance Scalability High reliability Robustness QoS

9
Scalable Server ArchitectureScalable Server Architecture
Feasible solution: Server Cluster (server farm) Collection of independent computer systems working
together as if a single system. Advantages
– Scalable: grow on demand– Highly available: redundancy– Cost-effective
Most current medium & large Web service providers take this architecture.
This trend is accelerating!

10
Communication
RequestRouting
Design IssuesDesign Issues
We need an integrated system to support a successful Internet service on such a distributed server system
Internet
Clients
Server farm
HTTP request
System Management
Router

11
Our SolutionsOur Solutions---Content-aware Web Cluster System-Content-aware Web Cluster System
Content-aware Distributor (Server Load Balancer) – Content-aware routing (Layer-7 routing)– Sophisticated load balancing– Service Differentiation– QoS– Fault resilience– Transaction support
Distributed Server Management System– System management– Intelligent Content placement and management– Supporting differentiated service– Supporting QoS– Fault management

12
OutlineOutline
Introduction Proposed System
Request routing mechanismRequest routing mechanism– Management System
Content-aware Intelligence Work in Progress Conclusion

13
MotivationMotivation
Key Challenge: how to dispatch and route incoming requests to the server best suited to respond

14
Desirable Properties Desirable Properties
User transparency Backward compatible Fast Access Scalability Robustness Availability Reliability QoS Support
15
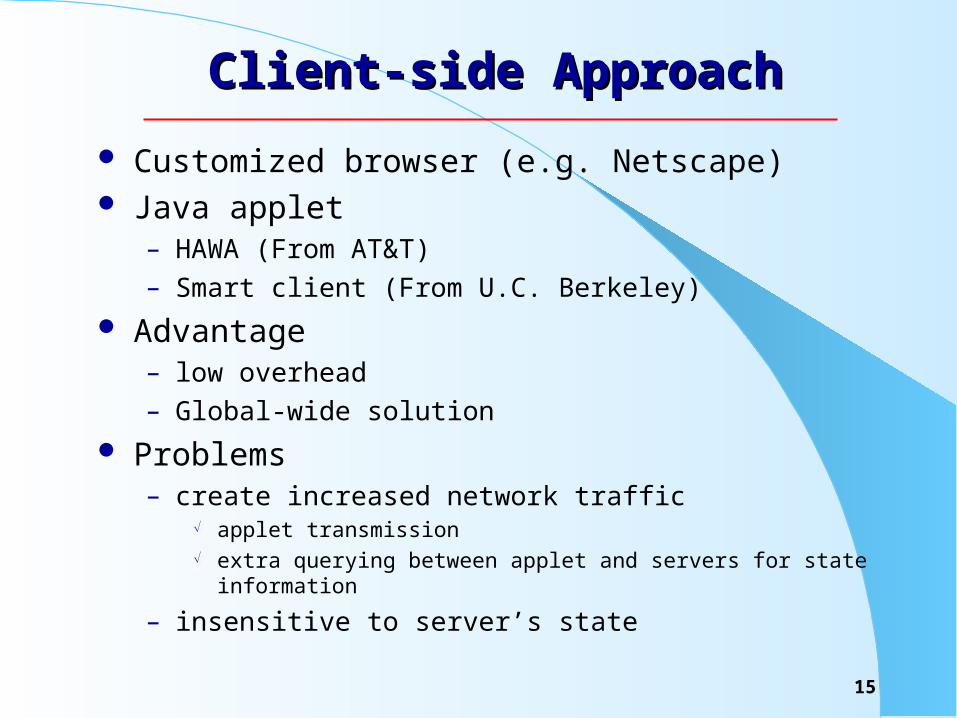
Client-side ApproachClient-side Approach
Customized browser (e.g. Netscape) Java applet
– HAWA (From AT&T) – Smart client (From U.C. Berkeley)
Advantage– low overhead– Global-wide solution
Problems– create increased network traffic
applet transmission extra querying between applet and servers for state information
– insensitive to server’s state

16
DNS-based ApproachDNS-based Approach
Internet
1
23
4
Router
Router
Server Farm
EnterpriseDatabase
DNS
Database
5
Who is www.nsysu.edu.tw ?
IP address of www.nsysu.edu.tw
Customized DNS

17
DNS-based ApproachDNS-based Approach
Advantage– Ease of implementation– Low overhead– Global-wide solution
Problems– Hostname to IP address mapping can be cached by DNS
server lead to significant load imbalance change in DNS information propagate slowly through the Internet. That
is, if the backend sever is failure or removed, Internet as a whole may not aware it.
– It is difficult to detect failure and load information of back-end nodes

18
HTTP RedirectionHTTP Redirection
One special response codes called redirection defined in the HTTP protocol can be used for directing a request.
Through HTTP redirection, we can make a server to instruct the client to send the request to another location instead of returning the requested data.
Problems– a request may require two or more connections for getting
the desired service, thus this approach will increase the response time and network traffic.
– the node serving this mechanism may become the impediment to scaling the server.

19
Single IP addressSingle IP address
‧‧
‧‧
‧‧‧
‧‧‧
Internet
Web Switch
Router
Server Farm
subnethttp://pds.cse.nsysu.edu.tw/job/
SVR.1
SVR.2
SVR.n
client
Internet
subnet
Virtual IP address

20
Layer-4 based approachLayer-4 based approach
Route request based on Source and destination IP address, port number, TCP flag (SYN/FIN)
Packets pertaining to the same connection must be routed to the same server
Fine grained control on request routing Scalability limited by the Internet access bandwidth Based on simple algorithms:
– Round-Robin, Weighted Round-Robin, Least connection..... Examples:
– Cisco LocalDirector– IBM Network Dispatcher– Foundry ServerIron– F5 network– HydraWeb

21
Issues Ignored by Existing SchemesIssues Ignored by Existing Schemes
Session Integrity Sophisticated Load Balancing Quality of Service Fault Resilience Content Deployment and Management
These observations lead to the inevitable conclusion : the request routing mechanism should factor in
content of request in making decisions
[Yang and Luo, IWI’99].
22
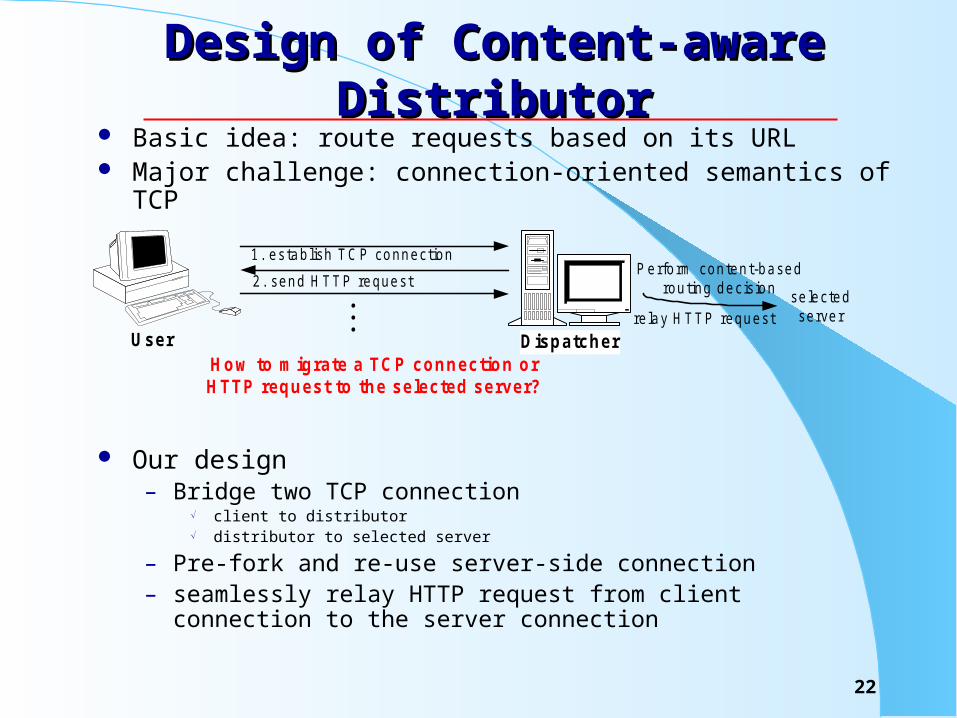
Design of Content-aware DistributorDesign of Content-aware Distributor Basic idea: route requests based on its URL Major challenge: connection-oriented semantics of TCP
Our design – Bridge two TCP connection
client to distributor distributor to selected server
– Pre-fork and re-use server-side connection– seamlessly relay HTTP request from client connection to the server
connection
DispatcherUser
1. estab lish TC P connection
2. send H TTP request...
se lectedserver
P erform content-basedrouting decis ion
re lay H TTP request
How to migrate a TCP connection orHTTP request to the selected server?
23
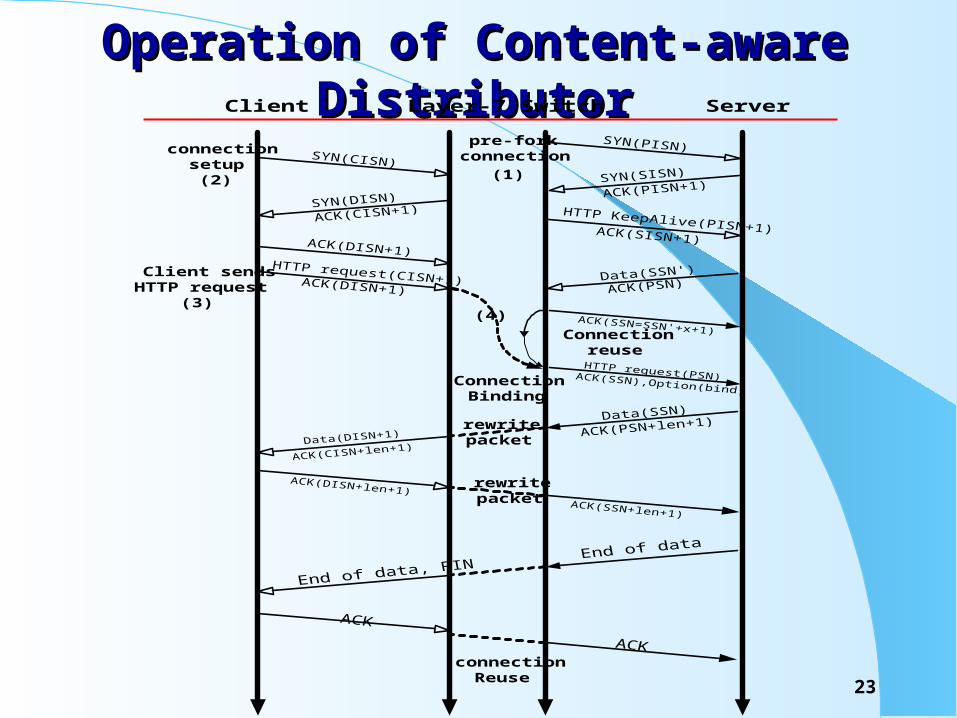
Operation of Content-aware DistributorOperation of Content-aware DistributorClient Layer-7 Switch Server
Connectionreuse
pre-forkconnection
connectionsetup
(2)
ConnectionBinding
Client sendsHTTP request
(3)
(1)
(4)
connectionReuse
rewritepacket
rewritepacket

24
Make Routing Decision Make Routing Decision
Parse HTTP Request Make routing decision
– Select a destination server– Select a pre-forked connection

25
Content-aware DistributorContent-aware Distributor
P acketA na lyzer
D ispatcher
H andshakeH andler
IP Input
P acketR ewrite r
N etworkIn terface
TC P
S ocket LayerW orkloadM anager
IP O utput
TC P
S ocket layer
P acketT ransm itte r
M appingT able
C luster T able
T im er
U R L T able
Adm inistra tor's C om m ands Adm inistra tor's C om m andsU per Layer U per Layer

26
Implementation StatusImplementation Status
The content-aware distributor is implemented as kernel loadable module
The distributor module inserts itself between network interface (NIC) driver and TCP/IP stack.
We have extended the Linux kernel (Version 2.2.16) with this module.
Because ideas and mechanisms adopted in content-aware distributor are generic, so it should be applicable to other system (e.g. BSD or Windows NT) as well.

27
Challenges of Content-aware RoutingChallenges of Content-aware Routing
How can we build the content-aware intelligence into the distributor for making routing decision?– Content type,size,priority,location,…– Should be configurable,extensible,comprehensive
How can the distributor perfom request distribution based on the content-aware intelligence?– Parsing HTTP header of each request– Should be fast,efficient

28
The idea of URL tableThe idea of URL table
‧‧‧
‧‧‧
‧‧‧
Internet
Distributor
Router
Server Farm
subnethttp://www.nsysu.edu.tw/pds/
SVR.1
SVR.2
SVR.n
client
Internet
subnet
URL TableURL
http://www.nsysu.edu.tw
http://www.yahoo.com
http://www.nctu.edu.tw
http://www.nsysu.edu.tw
http://www.yahoo.com
http://www.nsysu.edu.tw/pds/
serverSVR.1SVR.2SVR.4SVR.2SVR.2
priority
SVR.2SVR.2LowHigh

29
Design of URL TableDesign of URL Table
URL table holds the content-related information that enables the distributor to make intelligent routing decisions.– E.g., content type, size, priority, location…
The URL table is a multiple level hash tree that model the content tree
Such an idea is based on the observation that people generally organize content using a directory-based hierarchical structure.
The files in the same directory usually possess the same attributes.
For example, the files underneath the /CGI-bin/ directory generally are CGI scripts for generating dynamic content
To reduce the search time and the size of the table,we use an aggregation mechanism to specify a set of items that own the same properties

30
Modeling the Content TreeModeling the Content Tree
Ex: http://foo.com/special/dancer/img/main/01/21.jpg
businessweekly
1020 ~ 1030
img HTML files
Image files
img
Image files
Image files
HTML files
smart chatroom
Image files
img
HTML files
special
dancerstar
900201 ~ 900301
main submit
businessweekly
1020 ~ 1030
img
smart chatroom
special
dancerstar
900201 ~ 900301
URL Table
31
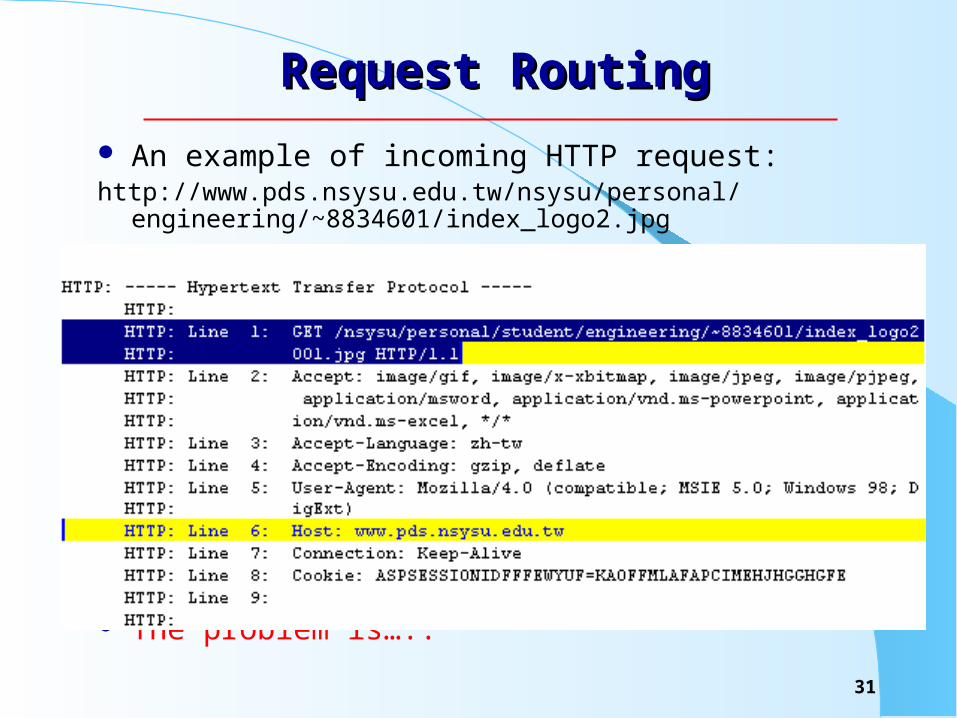
Request RoutingRequest Routing
An example of incoming HTTP request:http://www.pds.nsysu.edu.tw/nsysu/personal/engineering/~8834601/
index_logo2.jpg
The problem is…..

32

33
URL Parsing is expensive!!URL Parsing is expensive!!
Performing content-aware routing implies that some kind of string searching and matching algorithm is required. – Such a time-consuming function is expensive in a heavy
traffic web site. Our experience showed that the system performance
would be severely degraded if we implement some URL parsing functions in the distributor.
You will loss 7/8ths of your Web switch’s performance if you turn on its URL parsing function. ~~F5 Lab

34
The Idea of the URL FormalizationThe Idea of the URL Formalization
Generally, the reason for using the variable-length string to name a file or directory is just because it is mnemonic, thereby making it easier for humans to remember..
In most cases, an HTTP request is issued when the browser follows a link: either explicitly, when the user clicks on an anchor, or implicitly, via an embedded image or object.
Most URLs are invisible to the users,they don’t care about what name it has.
The name is only meaningful to the content provider. Therefore,we can convert the original name to a formalized form.

35
click

36
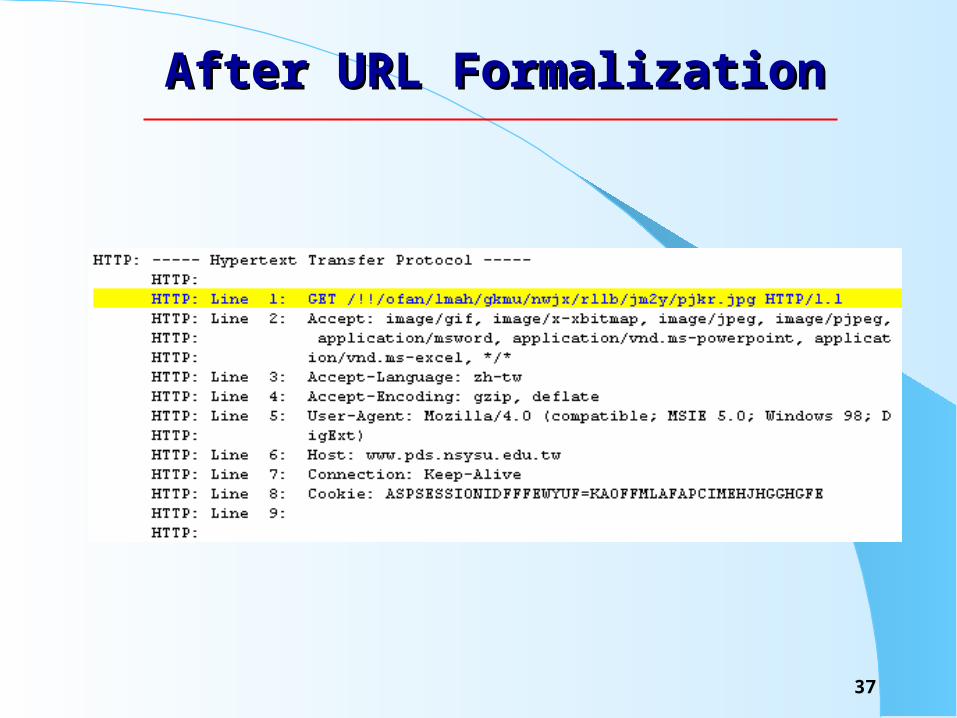
URL FormalizationURL Formalization
Convert user-friendly names to routing-friendly name. Basic idea: convert the original name of each file or
directory to a fixed-length and formalized name. The procedure of URL formalization
– Convert the original name of every directory and file into a fixed length and formatted name.
– Parse all html files and modify the embedded hyperlinks to conform to the new name.
– The new path name of each embedded link will be :
/preamble/formalized host name/formalized path name/…..
37
After URL FormalizationAfter URL Formalization

38
39
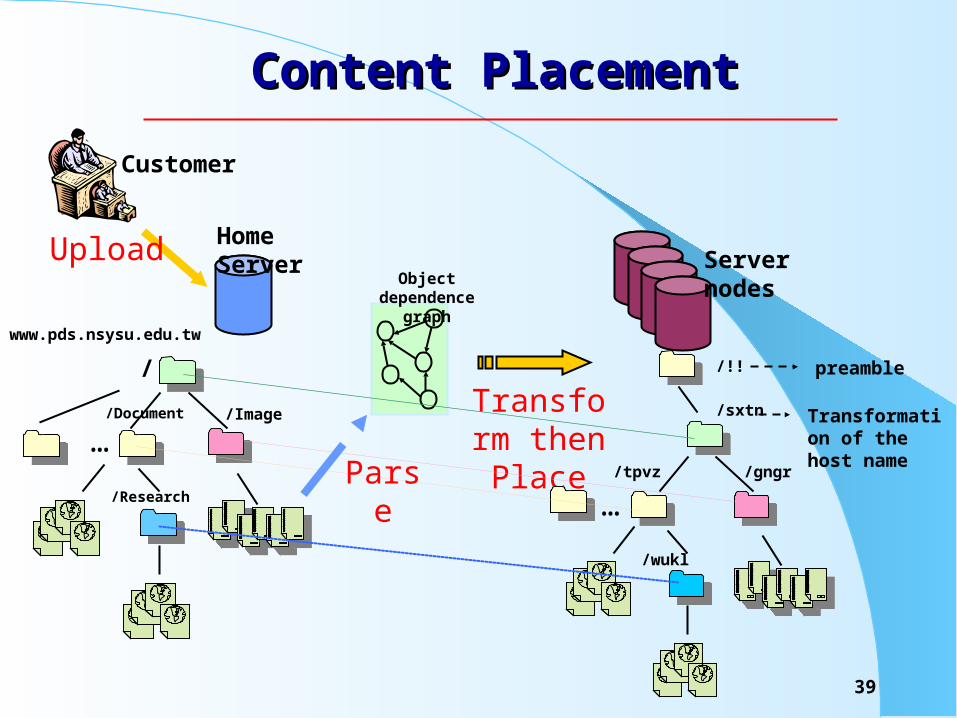
Content PlacementContent Placement
Transform then Place
Upload Home Server
Customer
/Image/Document
/Research
www.pds.nsysu.edu.tw
/
…
Server nodes
/tpvz /gngr
/wukl
/!!
/sxtn
preamble
Transformation of the host name
…
Object dependence graph
Parse
40
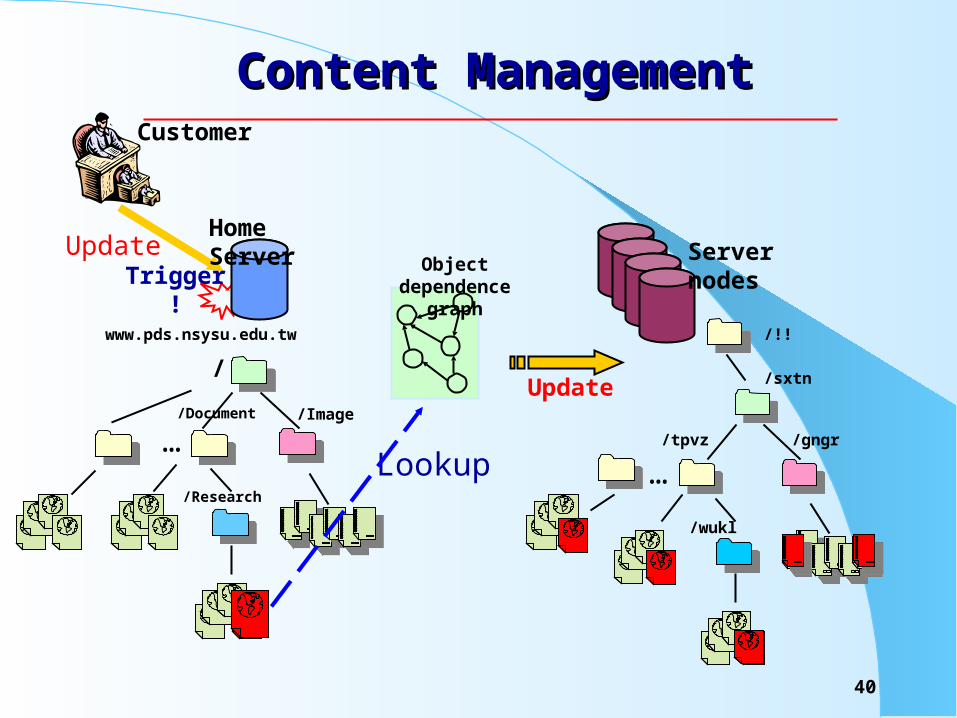
Content ManagementContent Management
Update
/tpvz /gngr
/wukl
/!!
/sxtn
Server nodes
…
Trigger!
/Image/Document
/Research
www.pds.nsysu.edu.tw
/
Home Server
Customer
…Lookup
Update
Object dependence graph
41
click
42

43
Advantages of URL FormalizationAdvantages of URL Formalization
The fixed-length formalized names are easier for the distributor to process.– We even can implement the routing function in hardware for
performance boosting.
Placing the host name in the first level of the path name can further speed up the routing decision.
Combined with the well-designed URL table, the dispatcher can quickly retrieve related information to make routing decision.
Be particularly useful in Web hosting service environment

44
OutlineOutline
Introduction Proposed System
– Request Routing MechanismManagement SystemManagement System
Content-aware Intelligence Work in Progress Conclusion
45
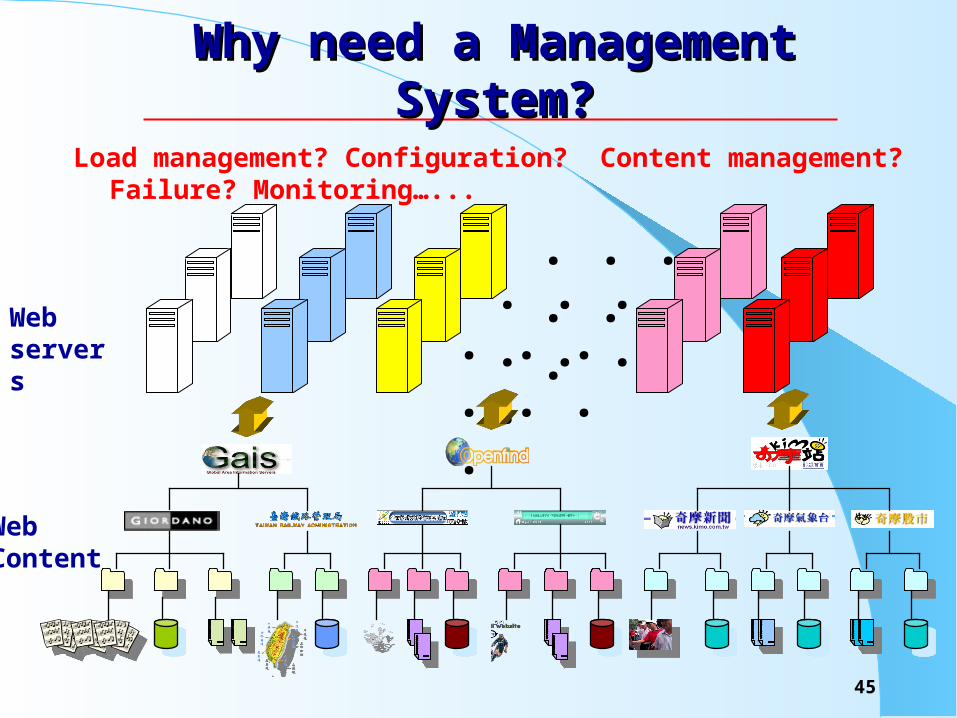
Why need a Management System?Why need a Management System?
Load management? Configuration? Content management? Failure? Monitoring…...
. . . . . . .. . . . . . .
. . . . . . .Web servers
Web Content

46
Required FunctionsRequired Functions
System configuration– ease to configure– status visualization
Content placement and management– be able to deploy content on each node according to its
capability– service differentiation– Dynamically change the content placement according to the
load – Support the content-aware routing
Monitoring– real-time statistics– log analysis– site usage statistics

47
Required Functions (cont’)Required Functions (cont’)
Performance management– monitoring– analysis and statistics– event (poor performance or overloaded)– automatic tuning
Failure management– diagnosis– server failure identification– network analysis and protocol analysis– content verification (object/link analysis)– monitoring and alarm

48
Our Management System Our Management System (Overview)(Overview)
Data
Internet
Broker
Agent CodeBase
Agent
Agent
1
2
3
4
GUIWebpage
RemoteConsole
LAN
Broker
Agent
Broker
Agent
Agent
Broker
Agent
Agent
Controller
Administrator
Agent
Server
Server
ServerServer

49
Our Management System Our Management System (Implementation)(Implementation)
Web page
Remote Console Applet
Java-enabled Browser
User
Administrative Operation Agent C ode Base
Distributor
H T T P R equest
W eb page
Invoke
Modefied Kernel
Controler
Administration Funtions
HTTP Daemon
Comm on Operatingsystem
Broker
HTTP Daemon
Web Server Node
Common Operating system
Broker
HTTP Daemon
Web Server Node
. . . . . . .
Agent
AgentAgentN etwork

50
Our Management SystemOur Management System
Controller(Java Application) – Communicate with the distributor– control center
Broker(Java Application)– running on Web server node– monitoring– execute downloading agent
Agent (Java class)– Each administrative function is implemented in the form of a
Java class termed agent
Remote console (Java Applet)– an easy-to-use GUI for web site manager to maintain and
manage the system.

51
Web Server ConfigurationWeb Server Configuration
52
Content ManagementContent Management
53
Performance Monitor OptionsPerformance Monitor Options
54
Performance Monitor Performance Monitor
55
Performance Monitor (cont’)Performance Monitor (cont’)
56
Performance Monitor (cont’)Performance Monitor (cont’)

57
Features of Our Management System Features of Our Management System
Platform independent– Implementing the daemon in Java can relieve the concerns
related to heterogeneity of the target platforms
Support comprehensive management functions Enables the complete management of a web site via
a standard browser (from any location)– Support tracking and visualization of the system’s
configuration and state– Produce a single, coherent view of the partitioned content
Extensibility Support URL Formalization

58
OutlineOutline
Introduction Proposed System
– Request Routing Mechanism– Management System
Content-aware Intelligence Work in Progress Conclusion

59
Current StatusCurrent Status
We have implemented the following content-aware intelligence in our system:
Affinity-Based request routing Content placement and management
– Dispersed Content Placement– Content Segregation
Fault Resilience

60
Affinity-Based Request RoutingAffinity-Based Request Routing
An important factor to consider: serving a request from the disk is far slower than serving the request from the memory cache.
With the content-aware mechanism, it is possible to direct requests for a given item of content to the server that already have data cached in main memory.
Achieving load balancing and locality

61
Benefits of Affinity-Based Routing Benefits of Affinity-Based Routing -- -- Test EnvironmentTest Environment
Heterogeneous servers cluster
– 4 Pentium-2 machines 350MHZ CPU 128M RAM 8G SCSI hard disk 100 Mbps Fast Ethernet Windows NT + IIS 4.0
– 3 Pentium-pro machine 200MHZ CPU 64M RAM 4G SCSI hard disk 100 Mbps Fast Ethernet LINUX + Apache
– 2 Pentium-pro machine 150 MHZ CPU 64M RAM 4G IE hard disk 100 Mbps Fast Ethernet LINUX + Apache
Workload generated by WebBench – 8 Pentium-2 machines serv
e as WebBench Client 350MHZ CPU 128M RAM 100 Mbps Fast Ethernet Windows NT
Each machine runs four WebBench client programs that emit a stream of Web requests, and measure the system response
The stream of requests is called the workload

62
Benefits of Affinity-Based Routing Benefits of Affinity-Based Routing -- -- Workload descriptionWorkload description
Workload
Total size of documents set >> memory size in each server node
Number of Files Average File Size (bytes) Request Percentage
CLASS_1 (gif) 301 223 16
CLASS_2 (gif) 200 735 7
CLASS_3 (gif) 361 1522 12
CLASS_4 (jpg) 665 2895 20
CLASS_5 (htm) 1865 6040 16
CLASS_6 (htm) 1705 11426 15
CLASS_7 (htm) 721 22132 6
CLASS_8 (htm) 265 41518 3
CLASS_9 (exe) 53 529k 3
CLASS_10 (Video) 27 1024k 2
63
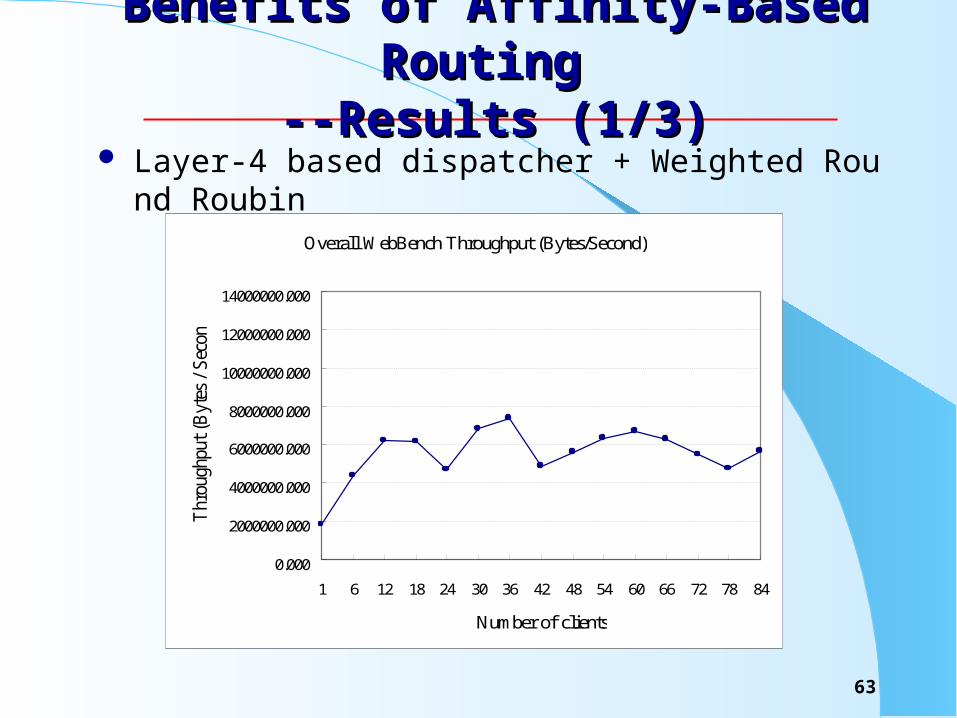
Benefits of Affinity-Based Routing Benefits of Affinity-Based Routing --Results (1/3)--Results (1/3)
Layer-4 based dispatcher + Weighted Round Roubin
Overall WebBench Throughput (Bytes/Second)
0.000
2000000.000
4000000.000
6000000.000
8000000.000
10000000.000
12000000.000
14000000.000
1 6 12 18 24 30 36 42 48 54 60 66 72 78 84
Number of clients
Thr
ough
put (
Byt
es /
Seco
nd)
64
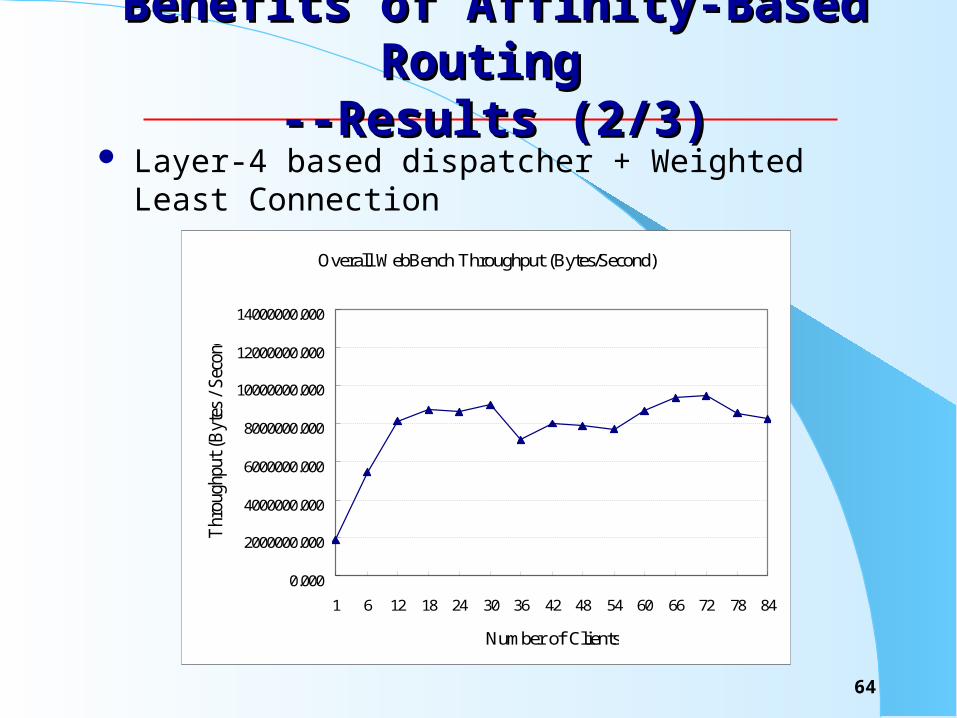
Benefits of Affinity-Based Routing Benefits of Affinity-Based Routing --Results (2/3)--Results (2/3)
Layer-4 based dispatcher + Weighted Least Connection
Overall WebBench Throughput (Bytes/Second)
0.000
2000000.000
4000000.000
6000000.000
8000000.000
10000000.000
12000000.000
14000000.000
1 6 12 18 24 30 36 42 48 54 60 66 72 78 84
Number of Clients
Thr
ough
put (
Byt
es /
Seco
nd)

65
Benefits of Affinity-Based Routing Benefits of Affinity-Based Routing --Results (3/3)--Results (3/3)
Affinity-Based Routing
Overall WebBench Throughput (Bytes/Second)
0.000
2000000.000
4000000.000
6000000.000
8000000.000
10000000.000
12000000.000
14000000.000
1 6 12 18 24 30 36 42 48 54 60 66 72 78 84
Number of Clients
Thr
ough
put (
Byt
es /
Seco
nd)

66
Content Placement and ManagementContent Placement and Management
An important factors in efficient utilization of a distributed server and achieving better performance is to be able to deploy content on each node according to its capability, and then direct clients to the best suited server.
Challenge: how to place and manage content in such a distributed server system, in particular, such servers tend to be more heterogeneous

67
Existing Content Placement SchemesExisting Content Placement Schemes
Place all content on a shared network file system– Advantage:
ease to maintain
– Disadvantage: suffer from the single-point-of-failure problem increase user perceived latency inability to support dynamic content
Replicate all content on each server node: – Advantage:
avoid the significant overhead associated with the previous scheme high availability due to data redundancy
– Disadvantage: expensive in terms of disk utilization pose great administrative burden on content management

68
Issues Ignored by Existing SchemesIssues Ignored by Existing Schemes
Variety of Web content Heterogeneity of server configuration Variety of access pattern (e.g., flash crowd) Need for differentiate content according different
priority or importance
Neither of the two schemes is a satisfactory solution for a heterogeneous distributed Web-server

69
Our SolutionOur Solution
Basic idea: content-aware routing + a content placement and management system, which enable the administrator to be free on deciding which node does what– content partition– partial replication for performance or availability – incorporate with two traditional scheme
Advantage– better resource utilization and scalability– ability to specialize some node to host certain content type– content segregation for preventing interference between
different type of requests– ability to exert explicit control over resource allocation
policies

70
Features of Content Management System Features of Content Management System
Support tracking and visualization of the system’s configuration and state
Produce a single, coherent view of the partitioned content
Implementing the daemon in Java can relieve the concerns related to heterogeneity of the target platforms
Ability to be tailored or extended for the different requirements of different system
Automatic content rearrangement facility to further ensure an even load distribution– Skew of access pattern may cause load imbalance

71
Benefits of Content Management System Benefits of Content Management System
-- -- Workload descriptionWorkload description Workload 2 (static content + dynamic content)
Number of Files Average File Size (bytes) Request Percentage
ASP 37 8
CGI 14 12
CLASS_1 (gif) 301 223 12
CLASS_2 (gif) 200 735 6
CLASS_3 (gif) 361 1522 8
CLASS_4 (jpg) 665 2895 15
CLASS_5 (htm) 1865 6040 12
CLASS_6 (htm) 1705 11426 14
CLASS_7 (htm) 721 22132 8
CLASS_8 (htm) 265 41518 1
CLASS_9 (exe) 53 529k 2
CLASS_10 (Video) 27 1024k 1

72
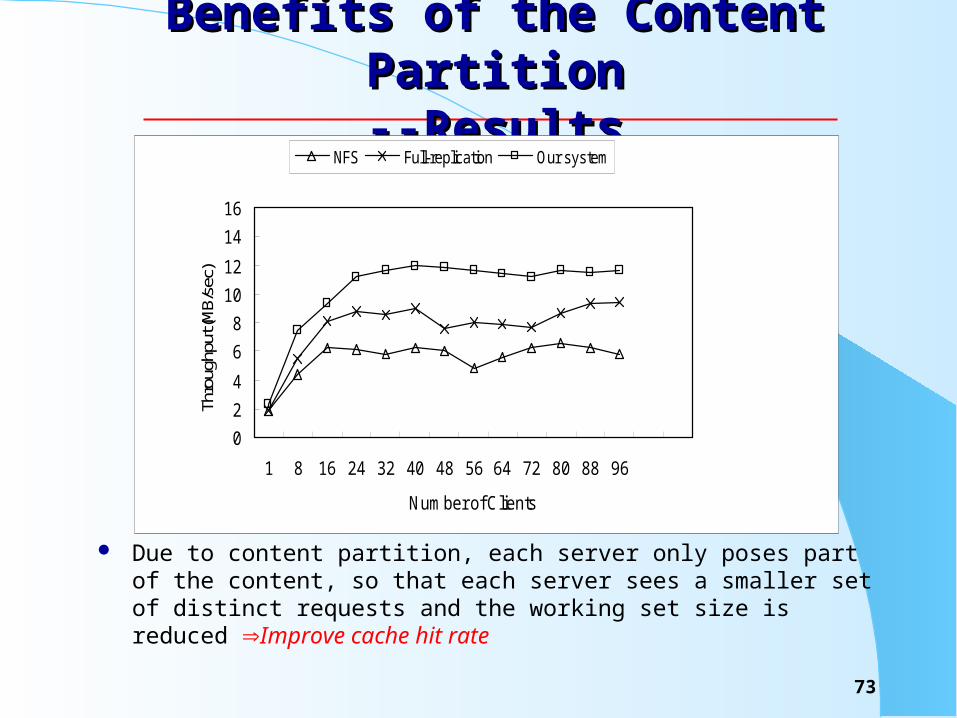
Benefits of the Content PartitionBenefits of the Content Partition----ConfigurationConfiguration
We used WebBench with workload 1 to perform the experiment on the following three configurations:– the entire set of files was replicated on each of the servers– the entire set of files shared using NFS– the document sets was dispersed with the content aware rou
ting
We roughly partitioned the document tree by content type in the configuration 3.
We also place large video file in the nodes with large volume and fast disk.
73
Benefits of the Content PartitionBenefits of the Content Partition--Results--Results
Due to content partition, each server only poses part of the content, so that each server sees a smaller set of distinct requests and the working set size is reduced Improve cache hit rate
0
2
4
6
8
10
12
14
16
1 8 16 24 32 40 48 56 64 72 80 88 96
Number of Clients
Thro
ughp
ut (M
B/se
c)
NFS Full-replication Our system

74
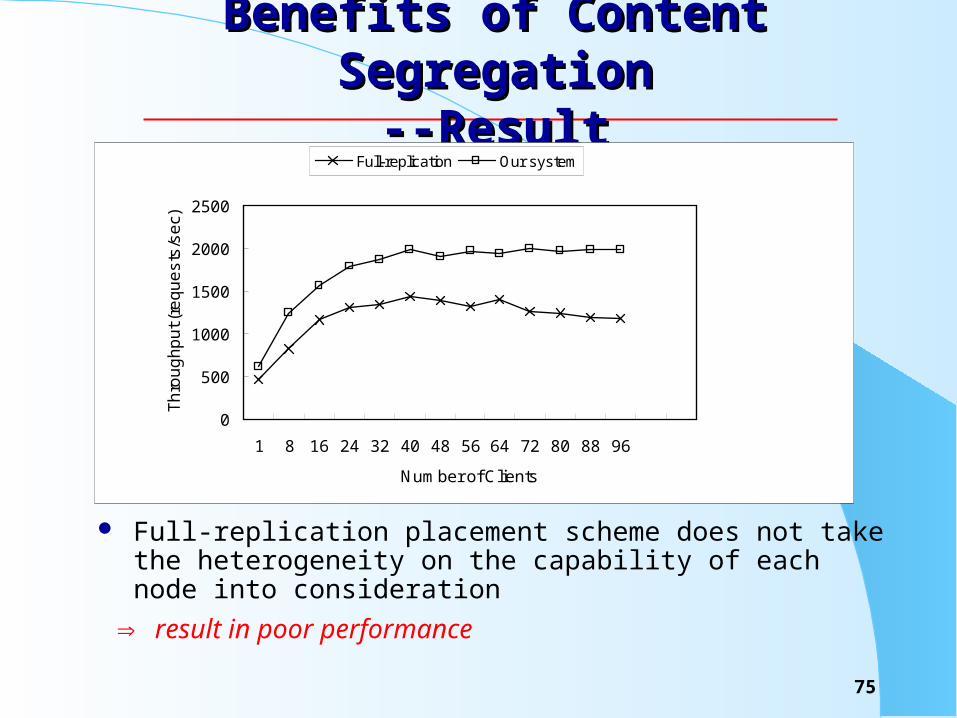
Benefits of Content SegregationBenefits of Content Segregation-- Configuration-- Configuration
We used WebBench with workload 2 to perform the experiment on the following two configurations:– the entire set of files was replicated on each of the servers– the document sets was dispersed with the content aware rou
ting
In our content-smart cluster (configuration 3):– separate dynamic content and static content on different ser
vers. – place dynamic content (CGI scripts and ASP) on the servers
with powerful CPU, plain html content on the nodes with slow processor and disk.
– separate large file (e.g., video file) on the server nodes with fast disk.
75
Benefits of Content SegregationBenefits of Content Segregation--Result--Result
Full-replication placement scheme does not take the heterogeneity on the capability of each node into consideration
result in poor performance
0
500
1000
1500
2000
2500
1 8 16 24 32 40 48 56 64 72 80 88 96
Number of Clients
Th
rou
gh
pu
t (re
qu
es
ts/s
ec)
Full-replication Our system

76
Benefits of Content SegregationBenefits of Content Segregation--Result--Result
The result shows the throughput when the server was saturated by 120 concurrent WebBench clients.
This experiment serves as a proof of the performance benefits of content-aware routing incorporated with content segregation.
C G I request
ASP request
1000
1500
2000
500
0
256
1524
(a)NAT Router w ith Content Replication (b)Content-aw are Router w ith Content Segregation
1000
1500
2000
500
0
176
962
138
R equest for static content
196
Nu
mb
er
of
requ
est
s
Nu
mb
er
of
requ
est
s

77
Fault ResilienceFault Resilience
The existing server-clustering solutions are not highly reliable, but merely highly available.
They offer no guarantee about fault resilience for the service. – Although the server failure can be easily detected and
transparently replaced with the available redundant component, however, any ongoing requests on the failed server will be lost.
In addition to detecting and masking the failures, an ideal fault-tolerant Internet server should enable the outstanding requests on the failed node to be smoothly migrated and then recovered on another working node.

78
AnalysisAnalysis
To support fault resilience, we think the routing mechanism should be extended to support two important capabilities: checkpointing and fault-recovery.
Challenges:– the cost is very expensive if we log every incoming request f
or checkpointing The request routing mechanism should be content-aware, s
o that it can differentiate varieties of requests and provide a corresponding fault-resilience guarantee.
– how to recover a Web request from a failed server node to continue execution in another working node
Request and its TCP connection should be smoothly and transparently migrated to another node

79
FT-capable DistributorFT-capable Distributor
Goal : enable the outstanding requests on the failed node to be smoothly migrated to and then recovered on another working node.
We think the request routing mechanism, needed in the sever cluster, is the suitable position to realize the fault-resilience capability.
We combine the capabilities of content-aware routing, checkpointing, and fault recovery to propose a new mechanism named Fault-Tolerance capable distributor.

80
Fault RecoveryFault Recovery
We divide web requests into two types, stateless and stateful request, and then provide corresponding solution to each category.
Stateless requests– static content– dynamic content
Stateful requests– transaction-based services– the heart of a large number of important web services (e.g.,
E-commerce)

81
Fault Recovery—Static RequestsFault Recovery—Static Requests
A majority of Web requests are to static objects, such as HTML files, images, and videos.
If one server node fails in the middle of a static request, we use the following mechanism to recover this request on another node.– select a new server– select an idle pre-forked connection connected with the
target server– infer how many bytes has been successfully received by the
client (from information in the mapping table)– issues a range request on the new server-side connection to
the selected server node.

82
Fault Recovery—Dynamic RequestsFault Recovery—Dynamic Requests
Dynamic content: response pages are created on demand (e.g., CGI scripts, ASP), mostly based on client-provided arguments.
Distributor will log user arguments conveyed in the dynamic requests.
Recovery mechanism– select a new server– select an idle pre-forked connection connected with the
target server– replay with the logged arguments

83
Fault Recovery—Dynamic RequestsFault Recovery—Dynamic Requests(cont’)(cont’)
We found the previous approach is problematic in some situations.
The major problem is that some dynamic requests are not “idempotent”.– the result of two successive requests with the same
arguments is different. It is needed to force the client to give up the data that
it has received and then re-receive the new response page. – it will not be user-transparent and compatible with the
existing browser. We tackle this problem by making the distributor
node to be a reverse proxy and “store-and-then-forward” the response page.

84
Stateful RequestsStateful Requests
In some cases, the user does not browse a number of independent statically or dynamically generated pages, but is guided through a session controlled by a server-side program (e.g., a CGI script) associated with some shared states.
These session-based services are generally based on so-called three-tier architecture.
Recovering a session in the three-tier architecture is a more challenging problem.

85
Fault Recovery—Stateful RequestsFault Recovery—Stateful Requests
First of all, the web site manager should define a session for which fault resilience is required.– Via the GUI of a management system– the configuration information will be stored in the URL table
When the distributor finds a request belonging to a session, it will “tag” this client and then direct all consequent requests from the client to one of the “twin servers”, until it finds a request conveying the “end” action.
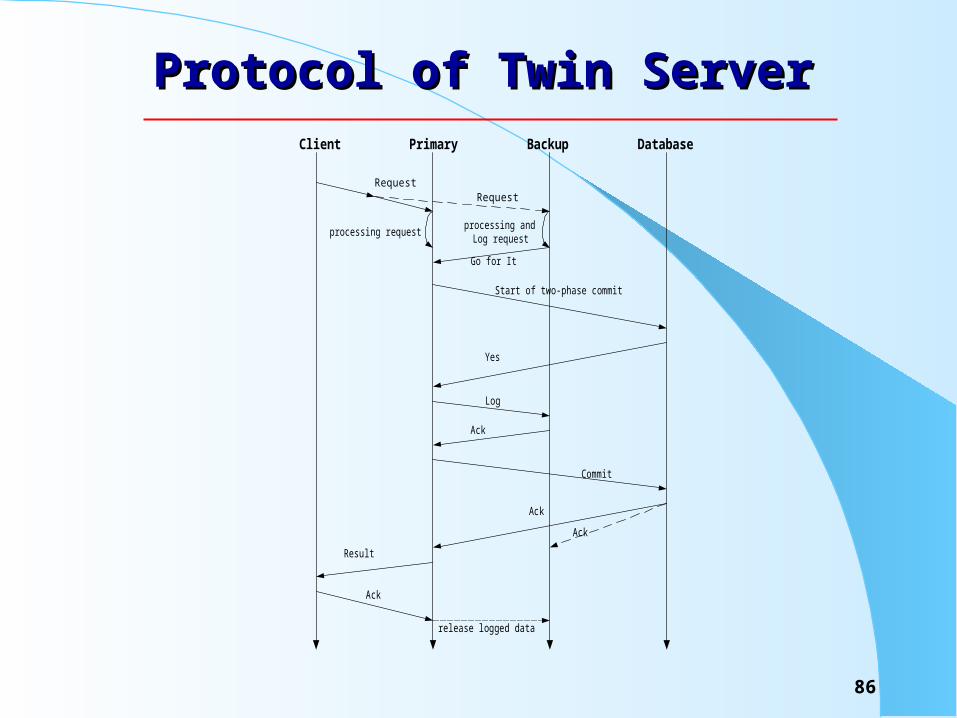
86
Protocol of Twin ServerProtocol of Twin ServerClient Primary Backup Database
RequestRequest
processing requestprocessing and
Log request
Go for It
Start of two-phase commit
Yes
Log
Ack
Commit
Ack
Ack
Result
Ack
release logged data

87
Workload DescriptionWorkload Description
We created a workload that models the workload characterization (e.g., file size, request distribution, file access frequency, etc.) of representative Web servers
About 6000 unique files of which the total size is about 116MB.
Number of Files Average File Size (bytes) Request Percentage
ASP 37 8
CGI 14 12
CLASS_1 (gif) 301 223 12
CLASS_2 (gif) 200 735 6
CLASS_3 (gif) 361 1522 8
CLASS_4 (jpg) 665 2895 15
CLASS_5 (htm) 1865 6040 12
CLASS_6 (htm) 1705 11426 14
CLASS_7 (htm) 721 22132 8
CLASS_8 (htm) 265 41518 1
CLASS_9 (exe) 53 529k 2
CLASS_10 (Video) 27 1024k 1

88
Fail-over TimeFail-over Time
We implemented a fault-injection program executing on each server nodes, which will shutdown and restart the system or HTTP daemon to simulate failures and repairs.
Static requests
Request size (Kb) 4K 8K 32KFailed request (ms) 887.64 954.74 1076.98
Baseline (ms) 24.12 33.48 172.42Fail-overtime (ms) 863.52 921.26 904.56
File size (Kb) 64K 256K 1024KFailed request (ms) 1241.61 2172.23 6915.01
Baseline (ms) 312.38 1143.97 5325.45Fail-overtime (ms) 929.23 1028.26 1589.56

89
Fail-over Time (Cont’)Fail-over Time (Cont’)
We think that the measured fail-over time may be overestimated.
Instrumentation
Result of instrumentationRequest size Tr (ms) Ts (ms) Tpars (ms) Tproc(ms) Tnet (ms)
4k 3.23 2.58 8.38 9.53 2.2584 3.12 2.35 8.52 8.89 3.01
32k 4.18 2.21 9.86 10.23 2.0564k 3.89 2.54 8.25 10.56 2.16
256k 3.56 2.39 7.89 42.56 2.381024k 3.09 2.64 8.69 225.23 2.53
FailureOccurrence
Failure isdetected
T d
Distributor sendspartial request
T r
Requestarrives
Parsingcomplete
Processingcomplete
Data receivedby distributor
T s T pars T proc T net
Request Migration

90
Overhead Overhead
Compared with a server system clustered by a Server Load Balancer (Layer-4 routing)
Distributor node – Pentium-II 350– 64M RAM
– 100 Mbps fast ethernet
Overhead associated with the Fault-Tolerance Mechanism (User perceived latency)– Static content
Request size (Kb) 4K 8K 32KOur system (ms) 27.19 36.07 174.58
Baseline (ms) 23.58 32.25 170.24Overhead (ms) 3.61 3.82 4.34
File size (Kb) 64K 256K 1024KOur system (ms) 312.9 1151.04 4824.1
Baseline (ms) 308.39 1145.62 4815.17Overhead (ms) 4.51 5.42 8.93

91
Overhead (cont’)Overhead (cont’)
Dynamic content
In terms of session-based requests, our protocol introduces an overhead of about 8% over the baseline system that does not offer any guarantee.
The experiment was performed over a local area network, where high-speed connections are the norm, resulting in short observed response time and then large relative overhead.
The overhead would be insignificant when compared with the latency over wide-area networks
Type Baseline Our systemLight 0.842 sec 0.851 sec
Moderate 3.128 sec 3.149 secHeavy 5.432 sec 1.246 sec

92
Overhead Overhead (Throughput)(Throughput)
Peak throughput– Layer-4 cluster: 2489 requests/sec– Our system : 2378 requests/sec– It shows that our fault tolerance mechanism does not cause
significant performance degradation. At the period of peak throughput, the CPU utilization
of the distributor is 67%, and the consumed memory of our system is slightly larger (only 2.3 Mbytes) than that of the layer-4 dispatcher.
This means that our mechanism is not a performance bottleneck. – In fact, we found the performance bottleneck in our
experiment is the network interface of the distributor node.
93
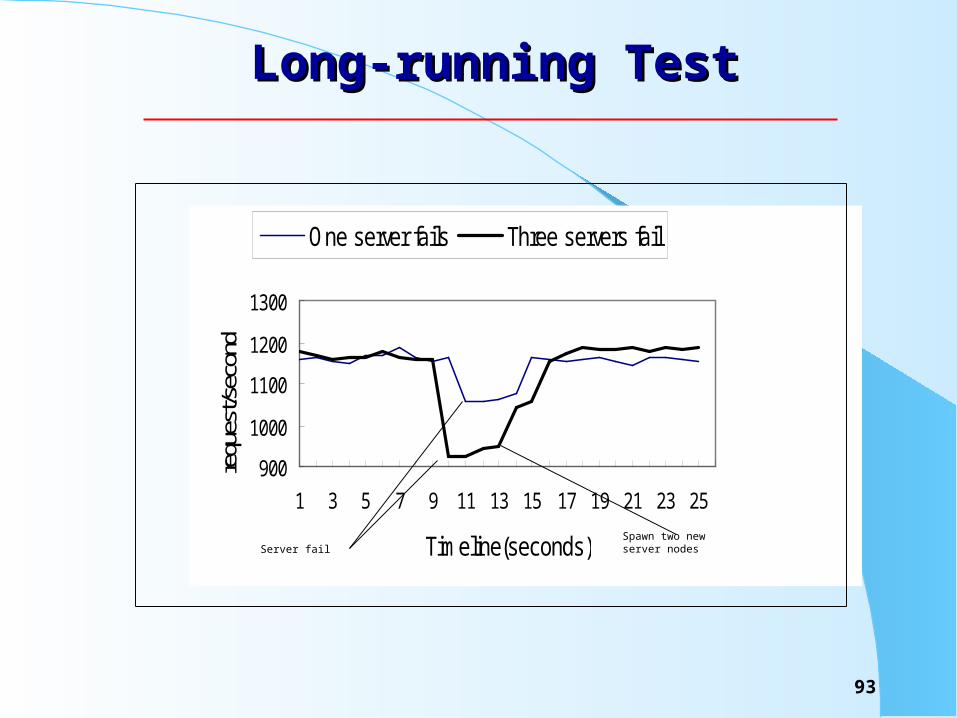
Long-running TestLong-running Test
900
1000
1100
1200
1300
1 3 5 7 9 11 13 15 17 19 21 23 25
Timeline(seconds)
requ
est/s
econ
dOne server fails Three servers fail
Server failSpawn two new server nodes

94
Service ReliabilityService Reliability
Our system guarantees service reliability at three levels: The management system provide a status detection
mechanism that can detect and mask the server failures. A request-failover mechanism enables an ongoing Web
request to be smoothly migrated and recovered on another server node in the presence of server failure or overload.
A mechanism to prevent the single-point-of-failure.

95
Work in progressWork in progress
Load Balancing– Sophisticated Load Balancing in distributor
– Dynamically content rearrangement facility to further ensure an even load distribution or QoS requirement
Security Quality of Service support Service Level Agreement
– enable the content owners to specify their specific requirements such as bandwidth usage, content type, number or placement of content replicas, or required degrees of service reliability.
We are implementing the related mechanisms to configure the management policy to meet the complex requirements of different customers.
Hardware Support

96
ContributionsContributions
Content-aware request routing mechanism Java-based management system Idea of URL table Performance speedup by URL formalization Enabling fault resilience for Web services Enhance reliability for Internet services Content-aware Load balancing algorithm QoS support Transaction-based services support System robustness Service Level Agreement and System policy

97
ConclusionConclusion
Web service providers must gradually move to more sophisticated services as the content of a Web site or e-business operations become more complex.
The Internet service supported by our system will be– Scalable
Cluster-based architecture Efficient content-aware routing
– Reliable Failure detection Request failover System robustness
– Highly manageable Java-based management system