multilingual support to a proposed semantic web architecture andrea ferrato top-uic ms thesis,...
TRANSCRIPT

Multilingual supportto a proposed Semantic Web
architecture
Andrea FerratoTOP-UIC MS Thesis, 2003/’04
Advisor: Laura Farinetti

A. Ferrato, TOP-UIC 2003-'04 2
Purpose of this work
Design and (partially) implement multilingual support on a pre-existing Semantic Web platform Provide an approach as generical as
possible Exploit features of the pre-existing
architecture Cope with the average chaotic
structure of resources currently available

A. Ferrato, TOP-UIC 2003-'04 3
Outline
Semantic WebMultilingualityThe DOSE platformProposed solutionGiven implementationExperimental resultsConclusions

A. Ferrato, TOP-UIC 2003-'04 4
Semantic Web
The next evolutionary stage for WWWGoal: make network data usable by
intelligent agentsDeployable only on top of existing
infrastructureTwo pressing tasks
Transform existing contents to include semantics
Setup ad hoc user agents to work on them

A. Ferrato, TOP-UIC 2003-'04 5
Transform existing contents
Basic data units: resources Every single information entity that
can be semantically isolatedFeatures to be given
Identification: URI Structure: XML Meaning: RDF Knowledge: ontologies

A. Ferrato, TOP-UIC 2003-'04 6
Set up ad hoc user agents
Major players in Semantic Web deployment
Invoked by users, can proceed autonomously
Key facilities to be supported Logic Proof Trust

A. Ferrato, TOP-UIC 2003-'04 7
Dig
ital
sig
natu
res
Semantic Web: layer cake view(Berners-Lee)
Unicode URI
XML + NS + XMLschema
RDF + RDFschema
Ontology vocabulary
Logic
Proof
Trust
Self desc
. doc.
Data D
ata R
ule s

A. Ferrato, TOP-UIC 2003-'04 8
Multilinguality
The extension to multiple languages of tasks already performed in a monolingual context
Typical issues from cross-language mapping Lexical gaps Role of the context Lack of pre-acquired knowledge

A. Ferrato, TOP-UIC 2003-'04 9
Multilinguality and Semantic Web
A problem of Text Retrieval in multiple languages (NLP) Start from popular approaches
(Controlled Vocabulary, Free text, etc.)
Two main requirements Recognize language ID of resources Map contents independently from
language

A. Ferrato, TOP-UIC 2003-'04 10
Language ID retrieval
Two possible scenarios Retrieve a given ID via resource
parsing Recreate the ID via resource analysis
When recollecting a given language attribute, conform to existing language specification standards

A. Ferrato, TOP-UIC 2003-'04 11
Language ID specification
Content-language
CSS-leveldeclarations
“lang”attribute
Languageinheritance
+

A. Ferrato, TOP-UIC 2003-'04 12
Language-independent contents mapping
Investigate the form/meaning relationship Ontology design is crucial Three main requirements
1. Consistency (based on linguistic evidence)
2. Flexibility (meaningful for all languages)
3. Extendibility (easy addition of new languages)

A. Ferrato, TOP-UIC 2003-'04 13
Ontology models
Conceptual founded upon general knowledge
Language-based Built on a particular language
Interlingua A combination of the above two
None is definitely superior for multilinguality

A. Ferrato, TOP-UIC 2003-'04 14
The DOSE platform
Distributed Open Semantic Elaboration platform
Key features Modularity Scalability Semantic integration
Main functionalities offered Annotation Search

A. Ferrato, TOP-UIC 2003-'04 15
DOSE: layered view
Indexer SearchEngine
SemanticMapper
FragmentRetriever
Substructure
Extractor AnnotationRepository
Onto-logy Syn-
set
Servicelayer
Back-endlayer
Front-endlayer

A. Ferrato, TOP-UIC 2003-'04 16
DOSE: distributed view
Onto-logy
Syn-set
Fragment Retriever
Substructure Extractor
SemanticMapper
AnnotationRepository
Indexer SearchEngine
XML-RPC infrastructure

A. Ferrato, TOP-UIC 2003-'04 17
13
4
5
8
7
6
9 1011
DOSE: annotation
SemanticMapper
Substructure
Extractor
AnnotationRepository
The Web
2
Indexer FragmentRetriever
A. Ferrato, TOP-UIC 2003-'04 18
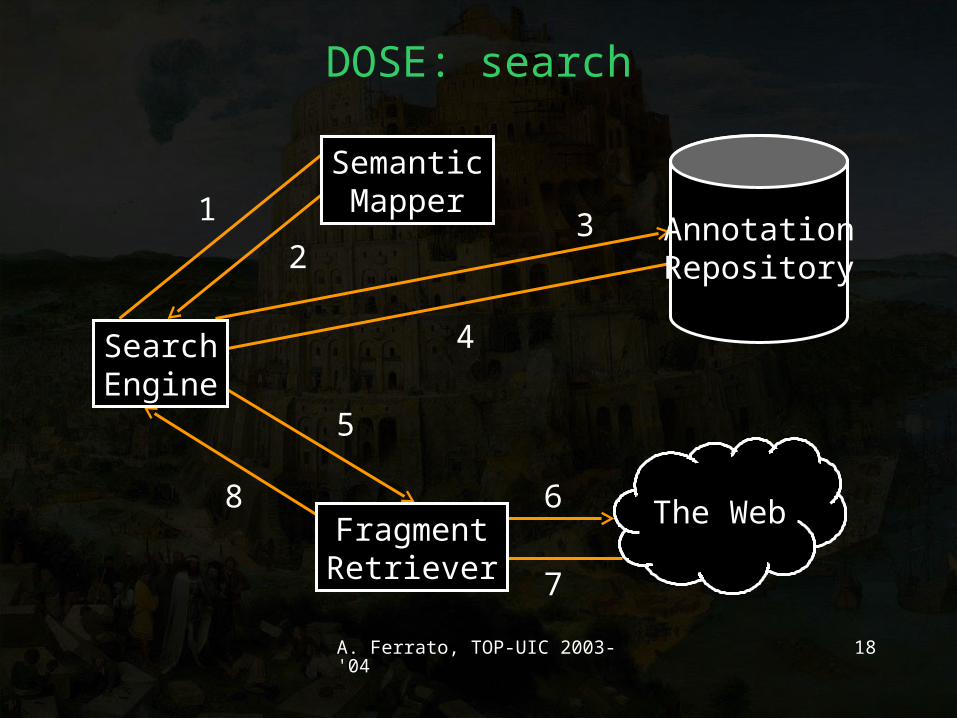
1
23
4
5
6
7
8
DOSE: search
SearchEngine
AnnotationRepository
The WebFragmentRetriever
SemanticMapper

A. Ferrato, TOP-UIC 2003-'04 19
DOSE and multilinguality
Traditionally: a new ontology for each different language
DOSE: the ontology language is totally independent of the synset language Use synsets to store lexical
representations only Let the ontology focus on knowledge
modelization

A. Ferrato, TOP-UIC 2003-'04 20
Practical requirements for multilinguality
Indexing Recognize language of resources to
consequently setup the system Store language IDs with annotations
Search Interpret user queries coming in
natural languages Allow for cross-language search tasks

A. Ferrato, TOP-UIC 2003-'04 21
Extension to language
Proposed approach: one ontology, many synsets A concept is expressed by a different
synset for each supported language Each synset contains multiple lexical
representations of a related concept in a single language
Separate semantic and textual layers

A. Ferrato, TOP-UIC 2003-'04 22
lavorostipendiodatore di lavoro…
salaryjobemployment…
travailchomeur…
Extension to language (cont’d)
job
(one concept,three synsets)

A. Ferrato, TOP-UIC 2003-'04 23
Advantages
Reduced implementation requirements Ontology design Resource occupation
Simplicity (in ontology management)Flexibility
A new language just brings a new bag of synsets
Expansion of indexing word set

A. Ferrato, TOP-UIC 2003-'04 24
Language recognition
Proposed approach Retrieve language IDs whenever present Otherwise, recognize language(s)
Design constraints To be activated in the annotation phase Refined at the document substructure level Has to deal with the average low authoring
quality of Web documents

A. Ferrato, TOP-UIC 2003-'04 25
Language recognition (cont’d)
1. Validate explicit request
2. Retrieve “lang” value
3. Guess via heuristics
4. Retrieve from ancestor
5. Accept default
<P lang=“ru”>
Russian
There was an Old Man of Coblenz,The length of whose legs was immense…
English
default = “it”
Italian
<H1 lang=“fr”>Le Bilboquet</H1><P>C’était un vieux passe-temps…
<P> is French
Hindi
Hindisynset
?

A. Ferrato, TOP-UIC 2003-'04 26
Current implementation
A new English synset to couple with a disability ontology (~500 concepts)
A set of 20 bilingual documents (Italian, English) on disability
A basic Language Detector XML-RPC module implemented in Java
Testing scenarios Parallel annotation Language recognition

A. Ferrato, TOP-UIC 2003-'04 27
Implementation work
Language Detector module (Java, ~1000 lines of code)
Additions to pre-existing modules (Java, ~1000 lines of code)
English synset (RDF, ~3500 lines of code)~ 24 Mb of annotations producedSimulation results analysis (A 600x40 .XLS
for <BODY>, a 925x250 .XLS for <Hx>)

A. Ferrato, TOP-UIC 2003-'04 28
Multilingual DOSE in action

A. Ferrato, TOP-UIC 2003-'04 29
Parallel annotation
Two parallel documents have The same structure elements with the
same contents Two different languages of expression
Goal: demonstrate that two sets of parallel documents are (almost) simmetrically mapped to the same concepts (“parallel annotation”)
Both sets indexed separately, with language explicitly specified

A. Ferrato, TOP-UIC 2003-'04 30
Parallel annotation (cont’d)
Test methodology: “Vector Space Model”Document fragments described as vectors
Dimensions are ontology concepts Components are weighted (tf/idf)
occurrencies of such conceptsThe correlation between two fragments is
quantified as the cosine of the angle between their vectors

A. Ferrato, TOP-UIC 2003-'04 31
Parallel annotation (cont’d)
IT/html/body/p[3]X:Part-time job (2.5)Y:Retirement (0)
EN/html/body/p[3]X:Part-time job (1.5)Y:Retirement (1.5)
Y
XX
Y
X
Y
CorrelationItalian
English

A. Ferrato, TOP-UIC 2003-'04 32
Parallel annotation results at <BODY> level
0
0,05
0,1
0,15
0,2
0,25
0,3
0,35
0,4
0,45
0 0,1 0,2 0,3 0,4 0,5 0,6 0,7 0,8 0,9 1
Correlation factor
Norm
aliz
ed fre
que
ncy
Parallel fragments Others

A. Ferrato, TOP-UIC 2003-'04 33
Correlation results at <BODY> level
1 4 7 10 13 16 19
S1
S3
S5
S7
S9
S11
S13
S15
S17
S19
Correlation factor
Italian pages
English pages
0-0,2 0,2-0,4 0,4-0,6 0,6-0,8

A. Ferrato, TOP-UIC 2003-'04 34
Correlation results at <BODY> level (alt)
1
7
13
19 S1
S6
S11
S160
0,2
0,4
0,6
0,8
Correlation factor
Italianpages
Englishpages
0,6-0,8
0,4-0,6
0,2-0,4
0-0,2

A. Ferrato, TOP-UIC 2003-'04 35
Parallel annotation results at <Hx> level
0
0,1
0,2
0,3
0,4
0,5
0,6
0 0,1 0,2 0,3 0,4 0,5 0,6 0,7 0,8 0,9 1
Correlation factor
Norm
aliz
ed fre
quen
cy
Parallel fragments Others

A. Ferrato, TOP-UIC 2003-'04 36
Parallel annotation: notes
Parallel and nonparallel pairs can be grouped as two different distributions i.e. Gaussian distributions
Average values of the two distributions are clearly separated, both for <BODY> and <Hx> levels This proves that the indexing system is
able to annotate relevant document fragments independently from language

A. Ferrato, TOP-UIC 2003-'04 37
Language recognition
Separate testing on the same document setItalian and English documents are
alternated in batch processing Avoid reuse of default settings for
contiguous documents of the same language
Two ways to retrieve ancestor language Via Annotation Repository (acceptable) Via a “Language Stack” (still inefficient)

A. Ferrato, TOP-UIC 2003-'04 38
Annotation Repository vs. Language Stack
<BODY lang="en">
<H1 lang="it">Passatempi</H1>
<H2 lang="en">Board Games</H2>
<P>Gomuku</P><P>Dama</P>…
All cyan, underlined words are to annotate (included in the synsets)Language Stack: Dama is ignored (language “en” inherited by <H2>)Annotation Repository: Dama is annotated (language “it” inherited by <H1>, annotated)

A. Ferrato, TOP-UIC 2003-'04 39
Language recognition results(via Annotation Repository)
0
20
40
60
80
100
120
1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31 33 35 37 39
Analyzed pages
Rec
ogn
itio
n pe
rcen
tage
Hit percentage (%) Hit average (%)

A. Ferrato, TOP-UIC 2003-'04 40
Conclusions
Typical issues discussedOverall validity of the approach shownFurther work and improvements
Synset composition Annotation testing with more
languages Optimize proposed language
recognition techniques, add new ones

A. Ferrato, TOP-UIC 2003-'04 41
Thank you…
Questions?

A. Ferrato, TOP-UIC 2003-'04 42
Language recognition (2)
0
20
40
60
80
100
120
1 4 7 10 13 16 19 22 25 28 31 34 37 40
Analyzed pages
Rec
ogn
itio
n pe
rcen
tage
Percentage Anno
Percentage Stack
Average Anno
Average Stack