mpi: advanced topics and future trends
TRANSCRIPT

MPI: Advanced Topics and Future Trends
Dhabaleswar K. (DK) Panda
The Ohio State University
E-mail: [email protected]
http://www.cse.ohio-state.edu/~panda
A Presentation at HPC Advisory Council Workshop, Lugano 2012
by

• MPI is a dominant programming model for HPC Systems
• Introduced some of the MPI Features and their Usage
• Introduced MVAPICH2 stack
• Illustrated many performance optimizations and tuning techniques for
MVAPICH2
• Most default settings are geared towards generic applications
– Default values are chosen after careful study across a wide variety of applications
• Default settings may be further tuned based on
– Application needs
– Specific system characteristics
– Other needs (like memory limits, etc.)
2
Recap of Yesterday’s Presentation (03/13/12)
HPC Advisory Council, Lugano Switzerland '12

• Challenges in designing Exascale Systems
• Overview of new MPI-3 features
• Overview of Latest and Upcoming MVAPICH2 features
– Optimized support for GPU to GPU communication
– Collective Communication: Network Offload, Non-blocking,
Topology-Aware, Power-Aware
– Support for PGAS (UPC and OpenShmem) and Hybrid Programming
– Support for MPI-3 RMA Model
– Future Plans
• Conclusions
3
Presentation Overview
HPC Advisory Council, Lugano Switzerland '12

• Exaflop = 1018 floating point operations per second
• Represents a factor of 100-1000x from current state of the
art
• Goal – Reach Exaflop levels by 2019-2020
• Exaflop computing is expected to spur research into high
performance technologies
• Discover new technologies to enable next generation of
science
HPC Advisory Council, Lugano Switzerland '12 4
Exaflop Computing

Exascale System Targets
Systems 2010 2018 Difference Today & 2018
System peak 2 PFlop/s 1 EFlop/s O(1,000)
Power 6 MW ~20 MW (goal)
System memory 0.3 PB 32 – 64 PB O(100)
Node performance 125 GF 1.2 or 15 TF O(10) – O(100)
Node memory BW 25 GB/s 2 – 4 TB/s O(100)
Node concurrency 12 O(1k) or O(10k) O(100) – O(1,000)
Total node interconnect BW 3.5 GB/s 200 – 400 GB/s (1:4 or 1:8 from memory BW)
O(100)
System size (nodes) 18,700 O(100,000) or O(1M) O(10) – O(100)
Total concurrency 225,000 O(billion) + [O(10) to O(100) for latency hiding]
O(10,000)
Storage capacity 15 PB 500 – 1000 PB (>10x system memory is min)
O(10) – O(100)
IO Rates 0.2 TB 60 TB/s O(100)
MTTI Days O(1 day) -O(10)
Courtesy: DOE Exascale Study and Prof. Jack Dongarra
5 HPC Advisory Council, Lugano Switzerland '12

• Supercomputers require a lot of energy
– Power consumption by processors for computation
– Power required by memory and other devices to move data
– Power required to cool the system
• Power requirement by current generation is already high
• Design constraint on Exaflop systems: must reach exaflops
using a total of around 20MW of power
HPC Advisory Council, Lugano Switzerland '12 6
Power Constraints for Exascale Systems

• DARPA Exascale Report – Peter Kogge, Editor and Lead
• Energy and Power Challenge
– Hard to solve power requirements for data movement
• Memory and Storage Challenge
– Hard to achieve high capacity and high data rate
• Concurrency and Locality Challenge
– Management of very large amount of concurrency (billion threads)
• Resiliency Challenge
– Low voltage devices (for low power) introduce more faults
HPC Advisory Council, Lugano Switzerland '12 7
What are the basic design challenges for Exascale Systems?

• Power required for data movement operations is one of
the main challenges
• Non-blocking collectives
– Overlap computation and communication
• Much improved One-sided interface
– Reduce synchronization of sender/receiver
• Manage concurrency
– Improved interoperability with PGAS (e.g. UPC, Global Arrays,
OpenShmem)
• Resiliency
– New interface for detecting failures
HPC Advisory Council, Lugano Switzerland '12 8
How does MPI plan to meet these challenges?

• Challenges in designing Exascale Systems
• Overview of new MPI-3 features
• Overview of Latest and Upcoming MVAPICH2 features
– Optimized support for GPU to GPU communication
– Collective Communication: Network Offload, Non-blocking,
Topology-Aware, Power-Aware
– Support for PGAS (UPC and OpenShmem) and Hybrid Programming
– Support for MPI-3 RMA Model
– Future Plans
• Conclusions
9
Presentation Overview
HPC Advisory Council, Lugano Switzerland '12

• Non-blocking Collectives
• Improved One-Sided (RMA) Model
• MPI Tools Interface
HPC Advisory Council, Lugano Switzerland '12 10
Major New Features

• Enables overlap of computation with communication
• Removes synchronization effects of collective operations
(exception of barrier)
• Completion when local part is complete
• Completion of one non-blocking collective does not imply
completion of other non-blocking collectives
• No “tag” for the collective operation
• Issuing many non-blocking collectives may exhaust
resources
– Quality implementations will ensure that this happens for only
pathological cases
HPC Advisory Council, Lugano Switzerland '12 11
Non-blocking Collective operations

• Non-blocking calls do not match blocking collective calls
– MPI implementation may use different algorithms for blocking and
non-blocking collectives
– Therefore, non-blocking collectives cannot match blocking
collectives
– Blocking collectives: optimized for latency
– Non-blocking collectives: optimized for overlap
• User must call collectives in same order on all ranks
• Progress rules are same as those for point-to-point
• Example new calls: MPI_Ibarrier, MPI_Iallreduce, …
HPC Advisory Council, Lugano Switzerland '12 12
Non-blocking Collective Operations (cont’d)

• Easy to express irregular pattern of communication
– Easier than request-response pattern using two-sided
• Decouple data transfer with synchronization
• Better overlap of communication with computation
HPC Advisory Council, Lugano Switzerland '12 13
Recap of One Sided Communication
Rank 0
Rank 2
Rank 1
Rank 3
mem
mem
mem
mem
window

• Remote Memory Access (RMA)
• New proposal has major
improvements
• MPI-2: public and private windows
– Synchronization of windows explicit
• MPI-2: works for non-cache
coherent systems
• MPI-3: two types of windows
– Unified and Separate
– Unified window leverages hardware
cache coherence
HPC Advisory Council, Lugano Switzerland '12 14
Improved One-sided Model
Processor
Private
Window
Public
Window
Incoming RMA Ops
Synchronization
Local Memory Ops

• MPI_Win_create_dynamic
– Window without memory attached
– MPI_Win_attach to attach memory to a window
• MPI_Win_allocate_shared
– Windows with shared memory
– Allows direct loads/store accesses by remote processes
• MPI_Rput, MPI_Rget, MPI_Raccumulate
– Local completion by using MPI_Wait on request objects
• MPI_Get_accumulate, MPI_Fetch_and_op
– Accumulate into target memory, return old data to origin
• MPI_Compare_and_swap
– Atomic compare and swap
HPC Advisory Council, Lugano Switzerland '12 15
Highlights of New MPI-3 RMA Calls

• MPI_Win_lock_all
– Faster way to lock all members of win
• MPI_Win_flush / MPI_Win_flush_all
– Flush all RMA ops to target / window
• MPI_Win_flush_local / MPI_Win_flush_local_all
– Locally complete RMA ops to target / window
• MPI_Win_sync
– Synchronize public and private copies of window
• Overlapping accesses were “erroneous” in MPI-2
– They are “undefined” in MPI-3
HPC Advisory Council, Lugano Switzerland '12 16
Highlights of New MPI-3 RMA Calls (Cont’d)

HPC Advisory Council, Lugano, Switzerland '12 17
MPI Tools Interface
• Extended tools support in MPI-3, beyond the PMPI interface
• Provide standardized interface (MPIT) to access MPI internal
information • Configuration and control information
• Eager limit, buffer sizes, . . .
• Performance information
• Time spent in blocking, memory usage, . . .
• Debugging information
• Packet counters, thresholds, . . .
• External tools can build on top of this standard interface

HPC Advisory Council, Lugano, Switzerland '12 18
Miscellaneous features
• New FORTRAN bindings
• Non-blocking File I/O
• Remove C++ bindings
• Support for large data counts
• Scalable sparse collectives on process topologies
• Topology aware communicator creation
• Support for multiple “MPI processes” within single “operating
system process” (in progress)
• Support for helper threads (in progress)
• Numerous fixes in the existing proposal

• Challenges in designing Exascale Systems
• Overview of new MPI-3 features
• Overview of Latest and Upcoming MVAPICH2 features
– Optimized support for GPU to GPU communication
– Collective Communication: Network Offload, Non-blocking,
Topology-Aware, Power-Aware
– Support for PGAS (UPC and OpenShmem) and Hybrid Programming
– Support for MPI-3 RMA Model
– Future Plans
• Conclusions
19
Presentation Overview
HPC Advisory Council, Lugano Switzerland '12

Data movement in GPU+IB clusters
• Many systems today want to use systems that have both GPUs and high-speed networks such as InfiniBand
• Steps in Data movement in InfiniBand clusters with GPUs
– From GPU device memory to main memory at source process, using CUDA
– From source to destination process, using MPI
– From main memory to GPU device memory at destination process, using CUDA
• Earlier, GPU device and InfiniBand device required separate memory registration
• GPU-Direct (collaboration between NVIDIA and Mellanox) supported common registration between these devices
• However, GPU-GPU communication is still costly and programming is harder
20 HPC Advisory Council, Lugano Switzerland '12
PCIe
GPU
CPU
NIC
Switch

PCIe
GPU
CPU
NIC
Switch
At Sender:
cudaMemcpy(sbuf, sdev, . . .);
MPI_Send(sbuf, size, . . .);
At Receiver:
MPI_Recv(rbuf, size, . . .);
cudaMemcpy(rdev, rbuf, . . .);
Sample Code - Without MPI integration
• Naïve implementation with standard MPI and CUDA
• High Productivity and Poor Performance
21 HPC Advisory Council, Lugano Switzerland '12

PCIe
GPU
CPU
NIC
Switch
At Sender: for (j = 0; j < pipeline_len; j++)
cudaMemcpyAsync(sbuf + j * blk, sdev + j * blksz,. . .);
for (j = 0; j < pipeline_len; j++) {
while (result != cudaSucess) {
result = cudaStreamQuery(…);
if(j > 0) MPI_Test(…);
}
MPI_Isend(sbuf + j * block_sz, blksz . . .);
}
MPI_Waitall();
Sample Code – User Optimized Code
• Pipelining at user level with non-blocking MPI and CUDA interfaces
• Code at Sender side (and repeated at Receiver side)
• User-level copying may not match with internal MPI design
• High Performance and Poor Productivity
HPC Advisory Council, Lugano Switzerland '12 22

Can this be done within MPI Library?
• Support GPU to GPU communication through standard MPI
interfaces
– e.g. enable MPI_Send, MPI_Recv from/to GPU memory
• Provide high performance without exposing low level details
to the programmer
– Pipelined data transfer which automatically provides optimizations
inside MPI library without user tuning
• A new Design incorporated in MVAPICH2 to support this
functionality
23 HPC Advisory Council, Lugano Switzerland '12

At Sender:
MPI_Send(s_device, size, …);
At Receiver:
MPI_Recv(r_device, size, …);
inside MVAPICH2
Sample Code – MVAPICH2-GPU
• MVAPICH2-GPU: standard MPI interfaces used
• High Performance and High Productivity
24 HPC Advisory Council, Lugano Switzerland '12

Design considerations
• Memory detection
– CUDA 4.0 introduces Unified Virtual Addressing (UVA)
– MPI library can differentiate between device memory and
host memory without any hints from the user
• Overlap CUDA copy and RDMA transfer
– Data movement from GPU and RDMA transfer are DMA
operations
– Allow for asynchronous progress
25 HPC Advisory Council, Lugano Switzerland '12

MPI-Level Two-sided Communication
• 45% improvement compared with a naïve user-level implementation
(Memcpy+Send), for 4MB messages
• 24% improvement compared with an advanced user-level implementation
(MemcpyAsync+Isend), for 4MB messages
0
500
1000
1500
2000
2500
3000
32K 64K 128K 256K 512K 1M 2M 4M
Tim
e (
us)
Message Size (bytes)
Memcpy+Send
MemcpyAsync+Isend
MVAPICH2-GPU
H. Wang, S. Potluri, M. Luo, A. Singh, S. Sur and D. K. Panda, MVAPICH2-GPU: Optimized GPU to GPU Communication for InfiniBand Clusters, ISC ‘11
26 HPC Advisory Council, Lugano Switzerland '12

Other MPI Operations and Optimizations for GPU Buffers
• Similar approaches can be used for
– One-sided
– Collectives
– Communication with Datatypes
• Designs can also be extended for multi-GPUs per node
– Use CUDA IPC (in CUDA 4.1), to avoid copy through host memory
27
• H. Wang, S. Potluri, M. Luo, A. Singh, X. Ouyang, S. Sur and D. K. Panda, Optimized Non-contiguous MPI Datatype Communication for GPU Clusters: Design, Implementation and Evaluation with MVAPICH2, IEEE Cluster '11, Sept. 2011
HPC Advisory Council, Lugano Switzerland '12
• A. Singh, S. Potluri, H. Wang, K. Kandalla, S. Sur and D. K. Panda, MPI Alltoall Personalized Exchange on GPGPU Clusters: Design Alternatives and Benefits, Workshop on Parallel Programming on Accelerator Clusters (PPAC '11), held in conjunction with Cluster '11, Sept. 2011
• S. Potluri et al. Optimizing MPI Communication on Multi-GPU Systems using CUDA Inter-Process Communication, Workshop on Accelerators and Hybrid Exascale Systems(ASHES), to be held in conjunction with IPDPS 2012, May 2012

MVAPICH2 1.8a2 Release
• Supports point-to-point and collective communication
• Supports communication between GPU devices and
between GPU device and host
• Supports communication using contiguous and non-
contiguous MPI Datatypes
• Supports GPU-Direct through CUDA support (from 4.0)
• Takes advantage of CUDA IPC for intra-node (intra-I/OH)
communication (from CUDA 4.1)
• Provides flexibility in tuning performance of both RDMA
and shared-memory based designs based on predominant
message sizes in applications
28 HPC Advisory Council, Lugano Switzerland '12

OSU MPI Micro-Benchmarks (OMB) 3.5.1 Release
• OSU MPI Micro-Benchmarks provides a comprehensive suite of
benchmarks to compare performance of different MPI stacks
and networks
• Enhancements done for three benchmarks – Latency
– Bandwidth
– Bi-directional Bandwidth
• Flexibility for using buffers in NVIDIA GPU device (D) and host
memory (H)
• Flexibility for selecting data movement between D->D, D->H and
H->D
• Available from http://mvapich.cse.ohio-state.edu/benchmarks
• Available in an integrated manner with MVAPICH2 stack
29 HPC Advisory Council, Lugano Switzerland '12

HPC Advisory Council, Lugano Switzerland '12 30
MVAPICH2 vs. OpenMPI (Device-Device, Inter-node)
0
500
1000
1500
2000
1 16 256 4K 64K 1M
Latency
MVAPICH2
OpenMPI
Late
ncy
(u
s)
Message Size (bytes)
0
1000
2000
3000
4000
1 16 256 4K 64K 1M
Bandwidth
MVAPICH2
OpenMPI
Ban
dw
idth
(MB
/s)
Message Size (bytes)
MVAPICH2 1.8 a2 and OpenMPI (Trunk nightly snapshot on Feb 3, 2012) Westmere with ConnectX-2 QDR HCA, NVIDIA Tesla C2075 GPU and CUDA Toolkit 4.1
0
1000
2000
3000
4000
1 16 256 4K 64K 1M
Bi-directional Bandwidth
MVAPICH2
OpenMPI
Ban
dw
idth
(MB
/s)
Message Size (bytes)
BE
TT
ER
BE
TT
ER
BE
TT
ER

HPC Advisory Council, Lugano Switzerland '12 31
MVAPICH2 vs. OpenMPI (Device-Host, Inter-node)
0
500
1000
1500
2000
1 16 256 4K 64K 1M
Latency
MVAPICH2
OpenMPI
Late
ncy
(u
s)
Message Size (bytes)
0
1000
2000
3000
4000
1 16 256 4K 64K 1M
Bandwidth
MVAPICH2
OpenMPI
Ban
dw
idth
(MB
/s)
Message Size (bytes)
0
1000
2000
3000
4000
1 16 256 4K 64K 1M
Bi-directional Bandwidth
MVAPICH2
OpenMPI
Ban
dw
idth
(MB
/s)
Message Size (bytes)
MVAPICH2 1.8 a2 and OpenMPI (Trunk nightly snapshot on Feb 3, 2012) Westmere with ConnectX-2 QDR HCA, NVIDIA Tesla C2075 GPU and CUDA Toolkit 4.1
Host-Device
Performance is
Similar B
ET
TE
R
BE
TT
ER
BE
TT
ER

HPC Advisory Council, Lugano Switzerland '12 32
MVAPICH2 vs. OpenMPI (Device-Device, Intra-node, Multi-GPU)
0
1000
2000
3000
4000
1 16 256 4K 64K 1M
Latency
MVAPICH2
OpenMPI
Late
ncy
(u
s)
Message Size (bytes)
0
1000
2000
3000
4000
5000
1 16 256 4K 64K 1M
Bandwidth
MVAPICH2
OpenMPI
Ban
dw
idth
(MB
/s)
Message Size (bytes)
0
2000
4000
6000
8000
1 16 256 4K 64K 1M
Bi-directional Bandwidth
MVAPICH2
OpenMPI
Ban
dw
idth
(MB
/s)
Message Size (bytes)
BE
TT
ER
BE
TT
ER
BE
TT
ER
MVAPICH2 1.8 a2 and OpenMPI (Trunk nightly snapshot on Feb 3, 2012) Westmere with ConnectX-2 QDR HCA, NVIDIA Tesla C2075 GPU and CUDA Toolkit 4.1

HPC Advisory Council, Lugano Switzerland '12 33
Applications-Level Evaluation (Lattice Boltzmann Method (LBM))
0
20
40
60
80
100
128x512x64 256x512x64 512x512x64 1024x512x64
Tim
e f
or
LB S
tep
(u
s)
Matrix Size XxYxZ
MVAPICH2 1.7
MVAPICH2 1.8a2
24.2% 24.2%
23.5%
23.5%
• LBM-CUDA (Courtesy: Carlos Rosale, TACC) is a parallel distributed CUDA implementation of a Lattice Boltzmann Method for multiphase flows with large density ratios • NVIDIA Tesla C2050, Mellanox QDR InfiniBand HCA MT26428, Intel Westmere Processor with 12 GB main memory; CUDA 4.1, MVAPICH2 1.7 and MVAPICH2 1.8a2 • Run one process on each node for one GPU (8-node cluster)

HPC Advisory Council, Lugano Switzerland '12 34
Application-Level Evaluation (AWP-ODC)
0
10
20
30
40
50
60
70
4 8
Tota
l Ex
ecu
tio
n T
ime
(se
c)
Number of Processes
MVAPICH2 1.7
MVAPICH2 1.8a2
• AWP-ODC simulates the dynamic rapture and wave propagation that occur during an earthquake • A Gordon Bell Prize Finalist at SC 2010 • Originally a Fortran code, a new version is being written in C and CUDA • NVIDIA Tesla C2050, Mellanox QDR IB, Intel Westmere Processor with 12 GB main memory • CUDA 4.1, MVAPICH2 1.7 and MVAPICH2 1.8a2 • One process on each node with one GPU. 128x128x1024 data grid per process/GPU.
12.5% 13.0%

• Challenges in designing Exascale Systems
• Overview of new MPI-3 features
• Overview of Latest and Upcoming MVAPICH2 features
– Optimized support for GPU to GPU communication
– Collective Communication: Network Offload, Non-blocking,
Topology-Aware, Power-Aware
– Support for PGAS (UPC and OpenShmem) and Hybrid Programming
– Support for MPI-3 RMA Model
– Future Plans
• Conclusions
35
Presentation Overview
HPC Advisory Council, Lugano Switzerland '12

• Mellanox’s ConnectX-2 and ConnectX-3 adapters feature
“task-list” offload interface
– Extension to existing InfiniBand APIs
• Collective communication with `blocking’ feature is usually a
scaling bottleneck
– Matches with the need for non-blocking collective in MPI
• Accordingly MPI software stacks need to be re-designed to
leverage offload in a comprehensive manner
• Can applications be modified to take advantage of non-
blocking collectives and what will be the benefits?
Collective Offload in ConnectX-2 and ConnectX-3
36 HPC Advisory Council, Lugano Switzerland '12

Application
Collective Offload Support in ConnectX-2 (Recv followed by Multi-Send)
• Sender creates a task-list consisting of only
send and wait WQEs
– One send WQE is created for each registered
receiver and is appended to the rear of a
singly linked task-list
– A wait WQE is added to make the ConnectX-2
HCA wait for ACK packet from the receiver
HPC Advisory Council, Lugano Switzerland '12
InfiniBand HCA
Physical Link
Send Q
Recv Q
Send CQ
Recv CQ
Data Data
MC
Q MQ
37
Task List Send Wait Send Send Send Wait

P3DFFT Application Performance with Non-Blocking Alltoall based on CX-2 Collective Offload
38
00.5
11.5
22.5
33.5
44.5
5
512 600 720 800
Ap
plic
atio
n R
un
-Tim
e (
s)
Data Size
P3DFFT Application Run-time Comparison. Overlap version with Offload-Alltoall does up to 17% better than default blocking version
K. Kandalla, H. Subramoni, K. Tomko, D. Pekurovsky, S. Sur and D. K. Panda, High-Performance and Scalable
Non-Blocking All-to-All with Collective Offload on InfiniBand Clusters: A Study with Parallel 3D FFT, Int'l
Supercomputing Conference (ISC), June 2011.
128 Processes
HPC Advisory Council, Lugano Switzerland '12
17%
Experimental Setup: • 8 core Intel Xeon(2.53 GHz) 12MB L3 Cache, 12 GB Memory per node, 64 nodes • MT26428 QDR ConnectX-2, PCI-Ex interfaces, 171-port Mellanox QDR switch

Non-Blocking Broadcast with Collective
Offload and Impact on HPL Performance
39
0
0.2
0.4
0.6
0.8
1
1.2
10 20 30 40 50 60 70
No
rmal
ize
d H
PL
Pe
rfo
rman
ce
HPL Problem Size (N) as % of Total Memory
HPL-Offload HPL-1ring HPL-Host
HPL Performance Comparison with 512 Processes
4.5%
K. Kandalla, H. Subramoni, J. Vienne, K. Tomko, S. Sur and D. K. Panda, Designing Non-blocking Broadcast with
Collective Offload on InfiniBand Clusters: A Case Study with HPL, Hot Interconnect '11, Aug. 2011.
HPC Advisory Council, Lugano Switzerland '12

Pre-conditioned Conjugate Gradient (PCG) Solver Performance with Non-Blocking Allreduce based on CX-2 Collective Offload
40
0
2
4
6
8
10
12
14
16
64 128 256 512
Ru
n-T
ime
(s)
Number of Processes
PCG-Default Modified-PCG-Offload
64,000 unknowns per process. Modified PCG with Offload-Allreduce performs
21% better than default PCG
21.8%
K. Kandalla, U. Yang, J. Keasler, T. Kolev, A. Moody, H. Subramoni, K. Tomko, J. Vienne and D. K. Panda, Designing Non-blocking Allreduce with Collective Offload on InfiniBand Clusters: A Case Study with Conjugate Gradient Solvers, Accepted for publication at IPDPS ’12, May 2012.
HPC Advisory Council, Lugano Switzerland '12

Non-contiguous Allocation of Jobs
• Supercomputing systems organized
as racks of nodes interconnected
using complex network
architectures
• Job schedulers used to allocate
compute nodes to various jobs
Line Card Switches
Line Card Switches
Spine Switches
- Busy Core
- Idle Core
New Job
- New Job
41 HPC Advisory Council, Lugano Switzerland '12

Non-contiguous Allocation of Jobs
• Supercomputing systems organized
as racks of nodes interconnected
using complex network
architectures
• Job schedulers used to allocate
compute nodes to various jobs
• Individual processes belonging to
one job can get scattered
• Primary responsibility of scheduler is
to keep system throughput high
Line Card Switches
Line Card Switches
Spine Switches
- Busy Core
- Idle Core
- New Job
42 HPC Advisory Council, Lugano Switzerland '12

.
. . .
. .
Compute Node
Compute Node
Compute Node
Compute Node
Switch
. .
Compute Node
Compute Node
Compute Node
Compute Node
. .
Compute Node
Compute Node
Compute Node
Compute Node
. .
Compute Node
Compute Node
Compute Node
Compute Node
. .
Compute Node
Compute Node
Compute Node
Compute Node
Switch Switch
Switch
Switch Switch
Job 1 Job 2 Job 3
Network Contention
43
Topology Aware Collectives
HPC Advisory Council, Lugano Switzerland '12

HPC Advisory Council, Lugano Switzerland '12
Topology-Aware Collectives
Default (Binomial) Vs Topology-Aware Algorithms with 296 Processes
44
K. Kandalla, H. Subramoni, A. Vishnu and D. K. Panda, “Designing Topology-Aware Collective Communication
Algorithms for Large Scale Infiniband Clusters: Case Studies with Scatter and Gather,” CAC ‘10
0
100
200
300
400
500
2K
4K
8K
16
K
32
K
64
K
12
K
25
6K
51
2K
12
8K
Late
ncy
(m
sec)
Message Size (Bytes)
Scatter-Default
Scatter-Topo-Aware
0100200300400500600700
2K
4K
8K
16
K
32
K
64
K
12
8K
25
6K
51
2K
12
8K
Late
ncy
(m
sec)
Message Size (Bytes)
Gather-Default
Gather-Topo-Aware
0
20
40
60
80
100
2R 4R 8R 16R 32R
Late
ncy
(u
sec)
System Size – Number of Racks
Default
Topo-Aware
Estimated Latency Of Default and Topology Aware Algorithms for small messages and varying system sizes
22% 54%
Experimental Setup: • 8 core Intel Xeon “Clovertown” (2.53 GHz) 4MB L2 Cache, 5 GB Memory per node, 64 nodes • MT25418 DDR ConnectX-2, PCI-Ex interfaces, 171-port Mellanox DDR switch
Generic Fat-Tree System

Impact of Network-Topology Aware Algorithms on Broadcast Performance
0
5
10
15
20
25
30
35
40
128K 256K 512K 1M
Late
ncy
(m
s)
Message Size (Bytes)
No-Topo-Aware
Topo-Aware-DFT
Topo-Aware-BFT
HPC Advisory Council, Lugano Switzerland '12 45
0
0.2
0.4
0.6
0.8
1
1.2
128 256 512 1K
No
rmal
ize
d L
ate
ncy
Job Size (Processes)
• Impact of topology aware schemes more pronounced as
• Message size increases
• System size scales
• Upto 14% improvement in performance at scale
14%
H. Subramoni, K. Kandalla, J. Vienne, S. Sur, B. Barth, K.Tomko, R. McLay, K. Schulz, and D. K. Panda, Design and Evaluation of Network Topology-/Speed- Aware Broadcast Algorithms for InfiniBand Clusters, Cluster ‘11

Power-Aware Collective Algorithms
Default (No Power Savings): Run each core at peak frequency/throttling state
Frequency Scaling Only: Dynamically detect communication phases. Treat them as a black-box and scale the CPU frequency
MVAPICH2 Approach: Consider the communication
characteristics of different collectives, intelligently use both
DVFS and CPU Throttling to deliver fine-grained power-
savings
46 HPC Advisory Council, Lugano Switzerland '12

0
100
200
300
400
500
600
Late
ncy
(m
sec)
Message Size (Bytes)
Default
DVFS
Proposed
47
Power and Energy Savings with Power-Aware Collectives
0
5
10
15
20
25
0.7 6.5 12.2 18.0 23.8 29.5 35.3 41.0 46.8 52.6
Po
we
r (
KW
)
Time (s) Performance and Power Comparison : MPI_Alltoall with 64 processes on 8 nodes
1.4E+13
5.014E+15
1.001E+16
1.501E+16
2.001E+16
2.501E+16
8K 16K 32K 64K 128K 256K
Ene
rgy
(KJ)
System Size (Number of Processes)
Estimated Energy Consumption during an MPI_Alltoall operation with 128K Message size and varying System Size
30%
32%
K. Kandalla, E. Mancini, Sayantan Sur and D. K. Panda, “Designing Power Aware Collective Communication
Algorithms for Infiniband Clusters”, ICPP ‘10
5%
HPC Advisory Council, Lugano Switzerland '12
Experimental Setup: • 8 core Intel Xeon “Nehalem” (2.40 GHz) 8MB L3 Cache, 12 GB Memory per node, 8nodes • MT26428 QDR ConnectX-2, PCI-Ex interfaces, 171-port Mellanox QDR switch

Power Savings at application level (CPMD with 32 and 64 Processes)
0
50
100
150
200
250
300
Applic
ation R
un-T
ime (
s)
Default Freq-Scaling Proposed Approach
0
10
20
30
40
50
60
70
32 Processes 64 ProcessesP
ow
er
Consum
ption (
KJ)
Estimated power savings - 7.7% Performance degradation - 2.6%
48 HPC Advisory Council, Lugano Switzerland '12

• Challenges in designing Exascale Systems
• Overview of new MPI-3 features
• Overview of Latest and Upcoming MVAPICH2 features
– Optimized support for GPU to GPU communication
– Collective Communication: Network Offload, Non-blocking,
Topology-Aware, Power-Aware
– Support for PGAS (UPC and OpenShmem) and Hybrid Programming
– Support for MPI-3 RMA Model
– Future Plans
• Conclusions
49
Presentation Overview
HPC Advisory Council, Lugano Switzerland '12

• Partitioned Global Address Space (PGAS) models provide a
different complementary interface as compared to
message passing
– Idea is to decouple data movement with process synchronization
– Processes should have asynchronous access to globally distributed
data
– Well suited for irregular applications and kernels that require
dynamic access to different data
• Different libraries and compilers exist that provide this
model
– Global Arrays (library), UPC (compiler), CAF (compiler)
– HPCS languages: X10, Chapel, Fortress
HPC Advisory Council, Lugano Switzerland '12 50
PGAS Models

• Currently UPC and MPI do not share runtimes
– Duplication of lower level communication mechanisms
– GASNet unable to leverage advanced buffering mechanisms developed for MVAPICH2
• Our novel approach is to enable a truly unified communication library
Unifying UPC and MPI Runtimes: Experience with MVAPICH2
Network Interface
MPI Runtime, Buffers, Queue Pairs, and other
resources
GASNet Runtime, Buffers, Queue Pairs, and other
resources
MPI Interface GASNet Interface
UPC Compiler
MPI Interface
Network Interface
Unified MVAPICH + GASNet Runtime,
Buffers, Queue Pairs, and other resources
GASNet Interface
UPC Compiler
HPC Advisory Council, Lugano Switzerland '12 51

• BUPC micro-benchmarks from latest release 2.10.2
• UPC performance is identical with both native IBV layer and new UCR
layer
• Performance of GASNet-MPI conduit is not very good
– Mismatch of MPI specification and Active messages
• GASNet-UCR is more scalable compared native IBV conduit
0
2
4
6
8
10
1 2 4 8
16
32
64
128
256
512
1024
2048
Late
ncy
(u
s)
Message Size (bytes)
UPC Memput Latency
HPC Advisory Council, Lugano Switzerland '12 52
UPC Micro-benchmark Performance
GASNet-UCR GASNet-IBV GASNet-MPI
0
500
1000
1500
2000
2500
3000
3500
1 4
16 64
256
1K
4K
16K
64K
256K 1M
Ban
dw
idth
(M
Bp
s)
Message Size (bytes)
UPC Memput Bandwidth
200
210
220
230
240
250
260
270
16 32 64 128 256
Mem
ory
Fo
otp
rin
t (M
B)
Number of Processes
UPC Memory Scalability
J. Jose, M. Luo, S. Sur and D. K. Panda, “Unifying UPC and MPI Runtimes: Experience with MVAPICH”, International
Conference on Partitioned Global Address Space (PGAS), 2010

Evaluation using UPC NAS Benchmarks
• GASNet-UCR performs equal or better than GASNet-IBV
• 10% improvement for CG (B, 128)
• 23% improvement for MG (B, 128)
0
0.5
1
1.5
2
2.5
3
3.5
4
4.5
5
B-64 C-64 B-128 C-128
Tim
e (s
ec)
Class-Processes
Performance of MG, Class B and C
0
5
10
15
20
25
30
35
B-64 C-64 B-128 C-128Class-Processes
Performance of FT, Class B and C
0
5
10
15
20
25
30
B-64 C-64 B-128 C-128Class-Processes
Performance of CG, Class B and C
GASNet-UCR GASNet-IBV GASNet-MPI
53 HPC Advisory Council, Lugano Switzerland '12

Evaluation of Hybrid MPI+UPC NAS-FT
0
5
10
15
20
25
30
35
B-64 C-64 B-128 C-128
Tim
e (s
ec)
Class-Processes
GASNet-UCR
GASNet-IBV
GASNet-MPI
Hybrid
• Modified NAS FT UPC all-to-all pattern using MPI_Alltoall
• Truly hybrid program
• 34% improvement for FT (C, 128)
54 HPC Advisory Council, Lugano Switzerland '12

Graph500 Results with new UPC Queue Design
• Workload – Scale:24, Edge Factor:16 (16 million vertices, 256 million edges)
• 44% Improvement over base version for 512 UPC-Threads
• 30% Improvement over base version for 1024 UPC-Threads
44%
30%
J. Jose, S. Potluri, M. Luo, S. Sur and D. K. Panda, UPC Queues for Scalable Graph Traversals: Design and Evaluation on
InfiniBand Clusters, Fifth Conference on Partitioned Global Address Space Programming Model (PGAS '11), Oct. 2011.
HPC Advisory Council, Lugano Switzerland '12 55

HPC Advisory Council, Lugano, Switzerland '12 56
Hybrid (MPI and OpenSHMEM) design
Hybrid MPI+OpenSHMEM
• Based on OpenSHMEM Reference Implementation http://openshmem.org/
• Hybrid MPI +OpenSHMEM Model
• Current Model – Separate Runtimes for OpenSHMEM and MPI
• Possible deadlock if both runtimes are not progressed
• Consumes more network resource
• Our Approach – Single Runtime for MPI and OpenSHMEM
Hybrid (OpenSHMEM+MPI) Application
InfiniBand Network
OSU Design
OpenSHMEM
InterfaceMPI
Interface
OpenSHMEM
callsMPI calls
HPC Advisory Council, Lugano, Switzerland '12 57
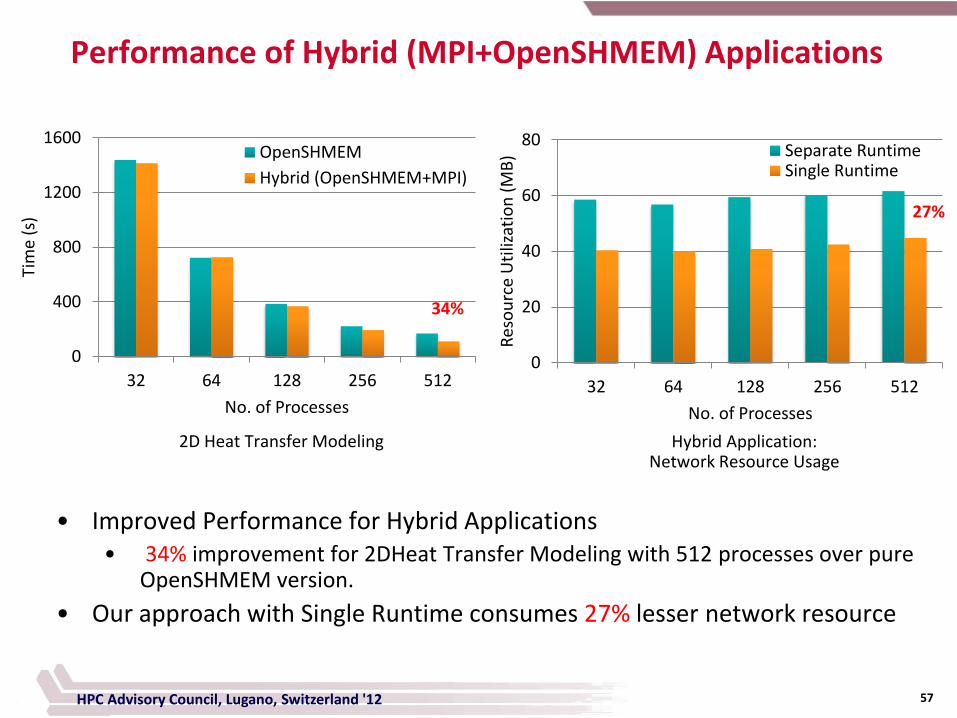
Performance of Hybrid (MPI+OpenSHMEM) Applications
0
400
800
1200
1600
32 64 128 256 512
Tim
e (s
)
No. of Processes
OpenSHMEM
Hybrid (OpenSHMEM+MPI)
34%
2D Heat Transfer Modeling
0
20
40
60
80
32 64 128 256 512
Res
ou
rce
Uti
lizat
ion
(M
B)
No. of Processes
Separate RuntimeSingle Runtime
27%
Hybrid Application: Network Resource Usage
• Improved Performance for Hybrid Applications • 34% improvement for 2DHeat Transfer Modeling with 512 processes over pure
OpenSHMEM version.
• Our approach with Single Runtime consumes 27% lesser network resource

• Challenges in designing Exascale Systems
• Overview of new MPI-3 features
• Overview of Latest and Upcoming MVAPICH2 features
– Optimized support for GPU to GPU communication
– Collective Communication: Network Offload, Non-blocking,
Topology-Aware, Power-Aware
– Support for PGAS (UPC and OpenShmem) and Hybrid Programming
– Support for MPI-3 RMA Model
– Future Plans
• Conclusions
58
Presentation Overview
HPC Advisory Council, Lugano Switzerland '12
HPC Advisory Council, Lugano Switzerland '12 59
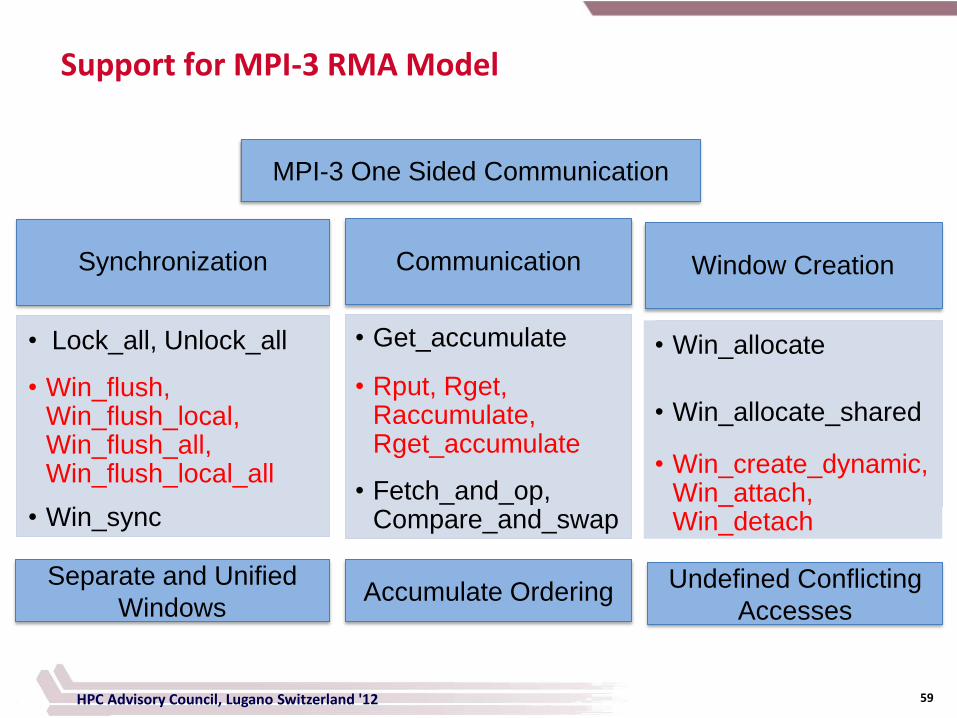
Support for MPI-3 RMA Model
MPI-3 One Sided Communication
Accumulate Ordering Undefined Conflicting
Accesses
Separate and Unified
Windows
Window Creation
• Win_allocate
• Win_allocate_shared
• Win_create_dynamic, Win_attach, Win_detach
Synchronization
• Lock_all, Unlock_all
• Win_flush, Win_flush_local, Win_flush_all, Win_flush_local_all
• Win_sync
Communication
• Get_accumulate
• Rput, Rget, Raccumulate, Rget_accumulate
• Fetch_and_op, Compare_and_swap

HPC Advisory Council, Lugano Switzerland '12 60
Support for MPI-3 RMA Model
• Flush Operations
– Local and remote completions bundled in MPI-2
– Considerable overhead on networks like IB - semantics and cost
of local and remote completions are different
– Flush operations allow more efficient check for completions
• Request-based Operations
– Current semantics provide bulk synchronization
– Request based operations return an MPI Request, can be polled
individually
– Allow for better overlap with direct one-sided design in MVAPICH2
• Dynamic Windows
– Allows users to attach and detach memory dynamically, key is to hide
the overheads (exchange of RDMA key exchange)

HPC Advisory Council, Lugano Switzerland '12 61
0
1
2
3
4
5
6
7
8
9
1 4 16 64 256 1K 4K
Tim
e (
use
c)
Message Size (Bytes)
Put+Unlock Put+Flush_local Put+Flush
0
20
40
60
80
100
2K 8K 32K 128K 512K 2M
Pe
rce
nta
ge O
verl
ap
Message Size (Bytes)
Lock-Unlock Request Ops
• Flush_local allows for a faster check on local completions
• Request-based operations provide much better overlap than
Lock-Unlock, in a Get-Compute-Put communication pattern
Support for MPI-3 RMA Model
S. Potluri, S. Sur, D. Bureddy and D. K. Panda – Design and Implementation of Key Proposed MPI-3 One-Sided Communication Semantics on InfiniBand, EuroMPI 2011, September 2011

• Challenges in designing Exascale Systems
• Overview of new MPI-3 features
• Overview of Latest and Upcoming MVAPICH2 features
– Optimized support for GPU to GPU communication
– Collective Communication: Network Offload, Non-blocking,
Topology-Aware, Power-Aware
– Support for PGAS (UPC and OpenShmem) and Hybrid Programming
– Support for MPI-3 RMA Model
– Future Plans
• Conclusions
62
Presentation Overview
HPC Advisory Council, Lugano Switzerland '12

• Performance and Memory scalability toward 500K-1M cores
• Hybrid programming (MPI + OpenSHMEM, MPI + UPC, MPI + CAF …) • Enhanced Optimization for GPU Support and Accelerators
– Extending the GPGPU support
– Support for Intel MIC (A paper will be presented at Intel-TACC Symposium in April ‘12)
• Taking advantage of Collective Offload framework – Including support for non-blocking collectives (MPI 3.0)
• Extended topology-aware collectives
• Power-aware collectives
• Enhanced Multi-rail Designs
• Automatic optimization of collectives – LiMIC2, XRC, Hybrid (UD-RC/XRC) and Multi-rail
• Support for MPI Tools Interface
• Checkpoint-Restart and migration support with incremental checkpointing
• Fault-tolerance with run-through stabilization (being discussed in MPI 3.0)
• QoS-aware I/O and checkpointing
• Automatic tuning and self-adaptation for different systems and applications
MVAPICH2 – Plans for Exascale
63 HPC Advisory Council, Lugano Switzerland '12

• Presented challenges for designing Exascale systems
• Overview of MPI-3 Features
• How MVAPICH2 is planning to address some of these challenges
• MVAPICH2 plans for Exascale systems
Conclusions
64 HPC Advisory Council, Lugano Switzerland '12

• Programming models like MPI have taken advantage of
RDMA to design high-performance and scalable libraries
• Can similar things be done for other middleware being
used for processing Big Data?
• Present challenges and provide initial designs for
– Memcached
– HBase and HDFS in Hadoop framework
65
Tomorrow’s (March 15th) Presentation
HPC Advisory Council, Lugano, Switzerland '12

HPC Advisory Council, Lugano Switzerland '12
Funding Acknowledgments
Funding Support by
Equipment Support by
66

HPC Advisory Council, Lugano Switzerland '12
Personnel Acknowledgments
Current Students – J. Chen (Ph.D.)
– V. Dhanraj (M.S.)
– N. Islam (Ph.D.)
– J. Jose (Ph.D.)
– K. Kandalla (Ph.D.)
– M. Luo (Ph.D.)
– X. Ouyang (Ph.D.)
– S. Potluri (Ph.D.)
– R. Rajachandrasekhar (Ph.D.)
– M. Rahman (Ph.D.)
– A. Singh (Ph.D.)
– H. Subramoni (Ph.D.)
Past Students – P. Balaji (Ph.D.)
– D. Buntinas (Ph.D.)
– S. Bhagvat (M.S.)
– L. Chai (Ph.D.)
– B. Chandrasekharan (M.S.)
– N. Dandapanthula (M.S.)
– T. Gangadharappa (M.S.)
– K. Gopalakrishnan (M.S.)
– W. Huang (Ph.D.)
– W. Jiang (M.S.)
– S. Kini (M.S.)
– M. Koop (Ph.D.)
– R. Kumar (M.S.)
– S. Krishnamoorthy (M.S.)
– P. Lai (Ph. D.)
– J. Liu (Ph.D.)
– A. Mamidala (Ph.D.)
– G. Marsh (M.S.)
– V. Meshram (M.S.)
– S. Naravula (Ph.D.)
– R. Noronha (Ph.D.)
– S. Pai (M.S.)
– G. Santhanaraman (Ph.D.)
– J. Sridhar (M.S.)
– S. Sur (Ph.D.)
– K. Vaidyanathan (Ph.D.)
– A. Vishnu (Ph.D.)
– J. Wu (Ph.D.)
– W. Yu (Ph.D.)
67
Past Research Scientist – S. Sur
Current Post-Docs – J. Vienne
– H. Wang
Current Programmers – M. Arnold
– D. Bureddy
– J. Perkins
Past Post-Docs – X. Besseron
– H.-W. Jin
– E. Mancini
– S. Marcarelli

HPC Advisory Council, Lugano Switzerland '12
Web Pointers
http://www.cse.ohio-state.edu/~panda
http://nowlab.cse.ohio-state.edu
MVAPICH Web Page
http://mvapich.cse.ohio-state.edu
68